基于AHP-FCE的铁路数据 资产价值评估方法
2021-12-22马小宁孙思齐王沛然
吴 江,马小宁,邹 丹,孙思齐,王沛然
(1.中国铁道科学研究院 研究生部,北京 100081;2.中国铁道科学研究院集团有限公司 铁路大数据研究与应用创新中心,北京 100081)
0 引言
伴随着铁路数据采集技术的进步,铁路数据的总量呈现出指数级别的增长。传统的铁路数据资产价值评估方法依靠专家讨论的文字总结进行价值评估,其结果相对模糊且不能准确表达专家对各价值影响指标的评价,无法满足对新增数据进行价值评估的精准度要求。研究结合铁路数据资产特征创建指标体系,构建评估模型,使铁路数据资产价值评估的结果更加精确。
目前,国内在数据资产价值评估领域的研究处于探索阶段,研究方向可分为价值评估指标体系与价值评估模型两方面。在评估指标体系方面,张志刚等[1]在无形资产价值评估研究成果的基础上,提出了基于层次分析模型构建的指标评价体系与方法。李永红等[2]通过对数据资产进行定界与其价值体现的分析,将数据资产价值影响因素分为数据量与数据质量、数据分析能力2个方面。李菲菲等[3]将数据资产成本、应用与数据质量、效果相结合,尝试了混合评估指标体系。在评估模型方面,王静等[4]针对互联网金融企业数据资产搭建了评价指标体系,结合B-S理论进行评估。董祥千等[5]从市场交易的角度将数据资产作为一种商品进行分析,采用基于市场模型参与者利润建模方法进行了数据资产价值的评估。倪渊等[6]结合网络平台交易的数据构建了AGA-BP神经网络评估模型,结合实例证明该模型具有较好的评估效果。
综上所述,针对数据资产价值评估的研究取得了诸多成果。但在铁路领域内,相关研究较少,不足以实现对铁路数据资产的精确评估。因此,创建铁路数据资产价值评估指标体系,构建AHP-FCE模型进行权重分析与价值评价,使用铁路主数据字段进行仿真,实验结果表明模型具有良好的评估效果,能够较为精确地评估铁路数据资产的价值。
1 铁路数据资产价值构成
1.1 铁路数据资产特征
铁路数据资产是铁路行业内各单位在运营管理、人员管理、业务场景中产生、传输、存储的,具有价值的以图片、文字、视频、音频等方式为载体的数据集合。相较于政务、邮递、医疗等领域的数据资产,铁路数据资产具有产速快、类型多、数据量大、保密性强等特征。
(1)产速快。除了通用的人财物等管理信息系统数据外,铁路数据资产还包含设备设施维修维护系统和生产系统的数据。对设备设施维修维护系统来说,员工的每次维修都会产生工单;对生产系统来说,监测数据每时每刻都在发生变化。这些系统产生的数据动态性强、随机性强、颗粒度多样,且都以ms或μs的时间间隔变化。
(2)类型多。根据数据产生的来源,可以将数据分为内部数据和外部数据。内部数据包括安全生产数据、运营服务数据、维修维护数据、物资采购数据、人力资源数据、财务管理数据、企业管理数据;外部数据包括交通路况、天气数据、大型活动数据和其他相关公共数据等。
(3)数据量大。据粗略统计,目前,铁路数据资产总量达10 PB以上,日增长量超1 TB。其数据量庞大的主要原因包括以下几点:铁路数据采集设备的升级与采集数据的精度提高,使数据来源增多、采集间隔减小;新技术的开发使得铁路与其他领域的数据融合频率增多;数据治理将传统的纸质及其他形式的资料以数据形式存储。
(4)保密性强。铁路数据资产包括铁路行业内各单位管控类的人财物数据、生产系统等物联网系统采集终端传感器的数据等,具有极大的应用价值,牵扯到铁路日常管理、人事调动、调度安排等业务及流程。数据如若泄露,将对企业秘密和公共安全造成极大的危害,因此对保密性要求高。
1.2 铁路数据资产价值影响因素
鉴于铁路数据资产的诸多特征,进行价值评估时需从多个维度考虑。通过整理传统有形资产与无形资产价值评估中的评估因子,结合铁路数据资产特征选定影响铁路数据资产价值的主要因素包括数据成本、数据固有价值、数据应用价值3个方面。
(1)数据成本。基于数据生命周期模型,数据成本主要集中在数据收集、数据管理、数据应用3个阶段当中。数据收集阶段需一线人员对数据进行采集;数据管理阶段需数据管理员对数据进行数据确认、清洗、入库、整合;数据应用阶段需数据分析师对数据进行挖掘。整理上述流程中的成本费用,数据成本可分为数据建设成本、数据管理成本、数据使用成本。
(2)数据固有价值。数据固有价值指数据本身所蕴含的信息内容,包括数据质量、数据活性、数据规模。数据质量与数据规模是数据固有价值的直观体现,质量好的数据可以减少后续数据治理的成本,而规模大的数据则可以提供更多的挖掘样本。数据活性是数据固有价值的潜在体现,关联性越强的数据可与更多其他领域的数据进行融合。
(3)数据应用价值。铁路数据资产应用价值分为路内应用价值、路外应用价值。在路内,数据可直接应用,例如根据车辆的延误数据进行列车调度;同时也可间接应用,例如根据车站的人流量数据进行周边交通的管控。在路外,数据的价值取决于业务的需求程度与历史价值,例如在城际铁路一体化的智慧城市项目中,铁路数据是必需的,具有极高的价值。而根据铁路数据在该项目中的实际使用效果,可在将来为其他同类项目对铁路数据的价值评估提供参考。
2 铁路数据资产价值评估模型
铁路数据资产价值评估的关键在于整理价值影响因素以形成指标体系和定量描述指标。依据铁路数据资产特征,结合数据资产价值评估领域的研究现状,将层次分析法与模糊综合评价法相结合构建评估模型[7-8]。
层次分析法(Analytic Hierarchy Process,AHP)是一种将复杂多目标决策问题通过分解为多个层次与指标进行分析的决策方法,具有科学性、简洁性、所需定量数据信息较少等优点,能够形成铁路数据资产价值评估指标体系并计算出各指标的权重;模糊综合评价法(Fuzzy Comprehensive Evaluation,FCE)是一种基于模糊数学的隶属度理论把定性评价转化为定量评价,对受到多种因素制约的对象做出一个总体评价的方法,可以定量描述铁路数据资产的价值。
2.1 权值计算
(1)构建指标体系。铁路数据资产价值评估指标体系如图1所示,包括1个总目标、3个一级指标、8个二级指标、21个三级指标。

图1 铁路数据资产价值评估指标体系Fig.1 Index framework for value evaluation of railway data assets
数据成本是指在建设、管理、使用数据的过程中花费的人力、物力的总和,一般认为数据成本越高的数据,其价值越高。数据建设成本包括数据采集成本和现场数据损失。数据采集成本指获得数据所耗费的人力、物力总和,在现场数据的采集过程中,根据采集设备的费用确定数据的成本,费用越高,则采集成本越高;在统计数据的采集过程中,根据获取数据的难度确定数据的成本,数据获取流程越多,所需权限越大,则采集成本越高。不同业务中的数据由其特定的采集方式决定其采集成本。现场数据损失指在采集过程中部分数据未达到要求而被舍弃所产生的损失。数据管理成本包括数据传输成本、数据治理成本、数据存储成本。数据使用成本包括数据分析成本、技术使用成本、数据服务成本。数据分析成本指为分析技术所投入的费用,分析技术水平越高,所能挖掘的数据价值越多;技术使用成本、数据服务成本指为了配合数据的使用而进行的相关技术开发与技术服务等费用。
数据质量是数据固有价值的直接表现,参考国家标准GB/T 25000.12-2017《系统与软件工程 系统与软件质量要求和评价(SQuaRE)第12部分:数据质量模型》、GB/T 25000.24-2017《系统与软件工程系统与软件质量要求和评价(SQuaRE)第24部分:数据质量测量》等规定,结合铁路数据特征整理得到具体指标包括:完整性、准确性、规范性。数据活性描述了数据的影响与变化,包括关联性与贬值速率。关联性由数据来源与影响范围共同决定,数据可来源于局、段等单位,一般认为来源单位级别越高,影响范围越大,关联性越强。数据规模是对数据整体进行描述,包括数据量、增长率、更新率、多源异构性。多源异构性指由多个数据源所产生的不同结构的数据的结合,描述了数据结构的复杂程度。
路内应用价值包括直接应用价值、间接应用价值。间接应用价值指使用分析技术对数据进行挖掘,是数据深层价值的体现。路外应用价值包括需求程度、历史价值。历史价值是数据价值变动的参考依据,可根据以往数据实际使用效果做出价值判断,效果越好则数据价值越高。
(2)构建判断矩阵。邀请专家对同一准则下的指标xi与xj成对比较,用1-9标度法表示两者之间的重要程度,记为aij。遍历同准则下所有指标,合成判断矩阵A= (aij)n×n。
(3)计算最大特征根。最大特征根λmax计算如下。

式中:W为判断矩阵A的特征向量,wi为W的元素。
(4)一致性检验。判断矩阵的一致性指标CI计算如下。

RI值查询如表1所示。当CR≤ 0.1时,判断矩阵通过一致性检验;当CR> 0.1时,判断矩阵未通过一致性检验,需调整判断矩阵直至通过检验。一致性比CR计算如下。

表1 RI值查询Tab.1 RI value inquiry

式中:RI为平均随机一致性指标。
(5)全局权重。指标的全局权重为该指标至总目标的路径上,所对应准则的权重与其局部权重的乘积。
2.2 分数评估
(1)确定评价因素集和评语集。评价因素集U= {u1,u2,…,un}为评价指标因素所组成的集合,n为评价因素的数量。评语集V= {v1,v2,…,vm}为评价等级所组成的集合,m为评价等级数,需经过专家讨论后确定。经过与专家讨论取m= 5。
(2)确定评价指标权重。采用AHP法确定指标权重。
(3)一级模糊综合评价。首先构建模糊评价矩阵,模糊评价矩阵由各指标的隶属度子集合R= {r1,r2,…,rm}构成。其中,定性指标无法量化评价,采用“优”“良”等评语,由专家投票的方式进行计算。定性指标的隶属度rm计算如下。

式中:k为选择m级别的人数;N为参与评价的总人数。
定量指标可量化评价,选择半梯形分布函数作为隶属度函数,评语集V= {v1,v2,…,vm}中的vm的取值由专家商讨决定。定量指标的隶属度rm计算如下。


式中:x为定量指标ui的具体评价数值。
一级模糊评价向量Bi计算如下。
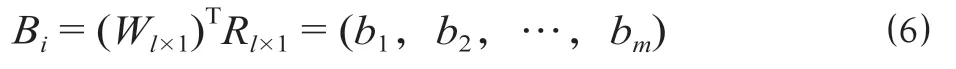
式中:Wl×1为l个下层指标对应的上层指标的特征向量;Rl×1为l个下层指标对应的隶属度子集合并形成的模糊评价矩阵。
(4)多级模糊综合评价。模糊综合评价法按照由下至上的顺序进行计算,下层的模糊评价向量构成中间层的模糊评价矩阵,将其与对应权值W相乘直至得到目标层的模糊评价向量B。
(5)评价结果分析。通过与专家讨论,以数据实际应用效果为标准确定了评价对象的分值分级表。分值分级表如表2所示。在此基础上以分级表的范围上限为标准,确定总目标的评语集V= {20,40,60,80,100}。评价目标的分值T计算如下。


表2 分值分级表Tab.2 Score grading
3 实例分析
3.1 实验数据描述
选择铁路主数据管理平台中的主数据字段进行仿真。主数据字段作为构成铁路各系统数据库的基础元素,可以描述铁路业务实体的特征,指导新建铁路的系统构建,具有较大的作用与影响。实验通过对铁路主数据字段进行价值评估,根据已有评估结果反证实验模型的准确性。
3.2 实验流程
(1)权值计算。以一级准则层的判断矩阵作为案例进行分析,统计整理出专家评分结果。专家评分表如表3所示。
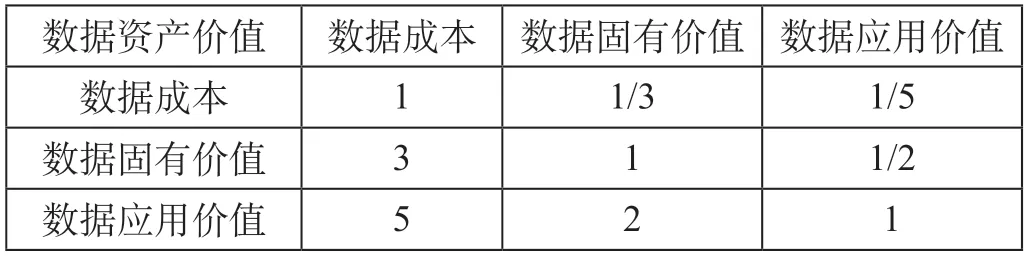
表3 专家评分表Tab.3 Expert scoring
根据表3可得判断矩阵A。
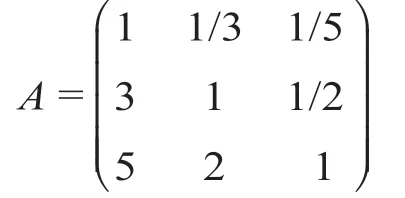
计算矩阵A的特征向量W。
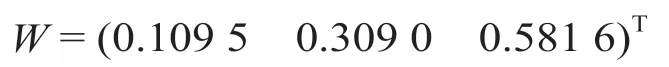
计算矩阵A的最大特征根λmax。
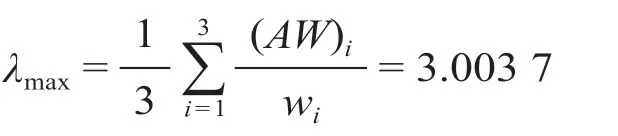
按公式(2)可得CI= 0.001 85,查询表1可知RI= 0.58,代入公式(3),计算一致性比CR= 0.003 2 < 0.1,通过一致性检验。同理可得其余因素权重。指标权重如表4所示。
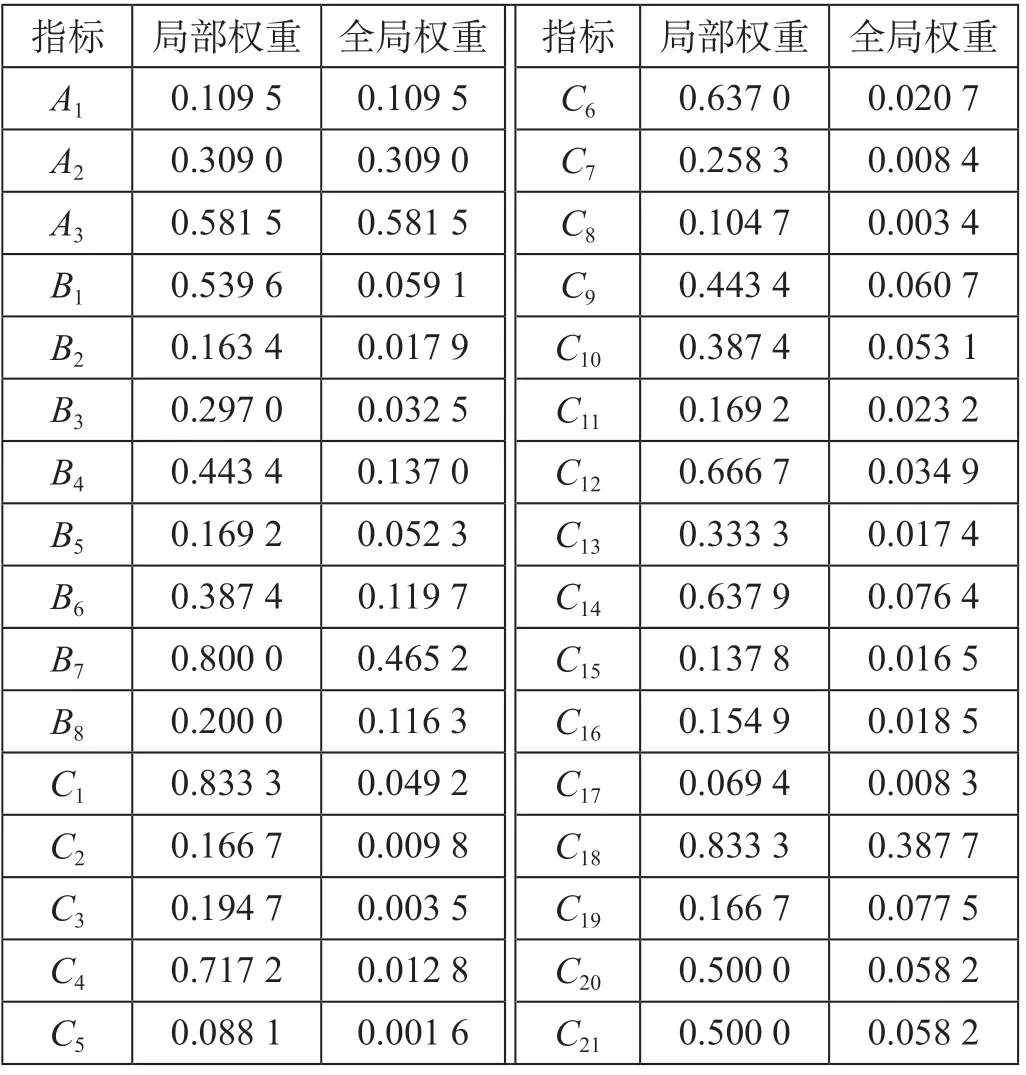
表4 指标权重Tab.4 Index weight
案例数据总计12个判断矩阵,其中最大CR= 0.090 4 < 0.1,整体满足一致性检验。对权值进行分析,发现对铁路数据资产价值影响最大的3个因素分别是直接应用价值、间接应用价值、数据量。这说明目前铁路领域对数据价值的认识依旧以数据的直接使用为主,可以增加间接应用价值的比重,挖掘数据深层价值,充分发挥铁路数据量巨大的优势。
(2)分数评估。将指标构成评价因素集,根据不同属性的指标构造评语集。以定性指标直接应用价值C18为例,请20位专家对其进行价值评估。专家投票结果如表5所示。

表5 专家投票结果Tab.5 Voting results of experts
根据公式(4)计算指标C18的隶属度:r1=r2=r3= 0;r4= 0.15;r5= 0.85。
以定量指标数据采集成本C1为例,其值为12.31万元,根据公式(5)计算指标C1的隶属度:r1= 0.769;r2= 1 -r1= 0.231;r3=r4=r5= 0。
同理可得其余指标隶属度,整理可得隶属度子集。将指标按性质分为定性与定量两类。定量指标隶属度子集结果如表6所示。因定性指标的评价等级一致,直接计算其隶属度子集即可。定性指标隶属度子集如表7所示。
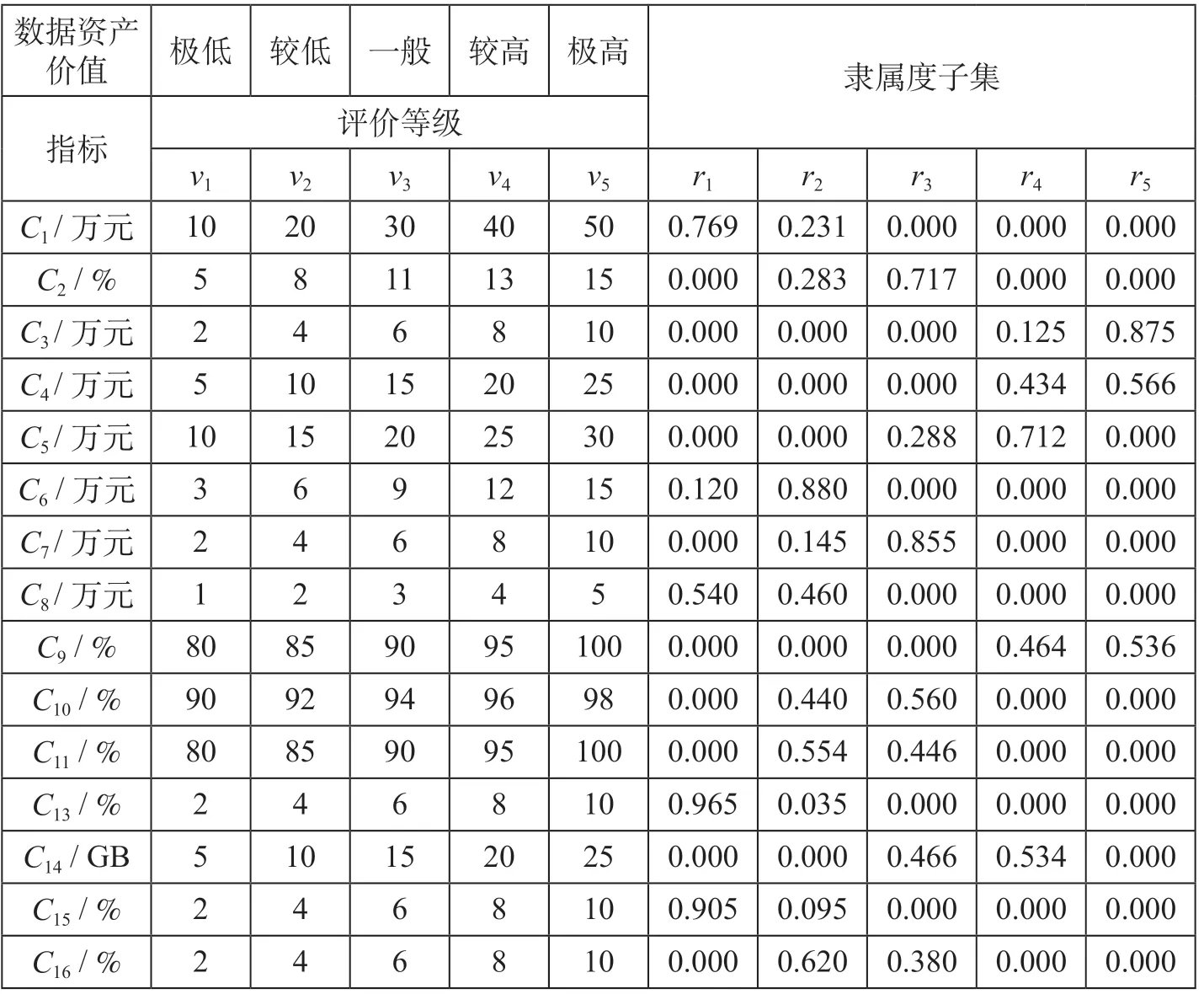
表6 定量指标隶属度子集Tab.6 Quantitative index membership subset
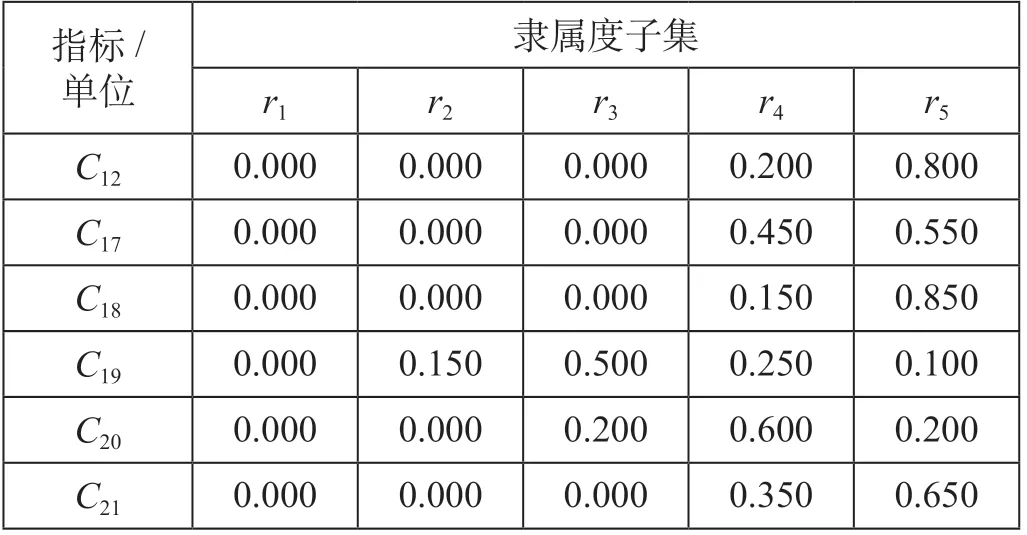
表7 定性指标隶属度子集Tab.7 Qualitative index membership subset
以数据建设成本B1为例,根据公式(6)计算指标BB1的中间模糊评价向量。

同理可得其余准则及总目标对应的模糊评价向量。

按公式(7)计算分值T。

结合模糊评价向量与实际场景进行分析,主数据字段由铁路各个系统中的字段整理总结而得,涉及到人工调查、收集等一系列流程工作,中间需经过多次数据传输与清洗,经过整理后可直接描述铁路业务实体,故其花费主要集中在传输、治理方面,成本极低;主数据字段由实际需求确定,其范围覆盖整个铁路的业务流程,关联多个相关领域,然而由于标准的落实仍处于初步阶段,其在各个系统中的表现形式、数据结构差异较大,导致其固有价值一般;主数据字段作为铁路系统字段的归纳总结,能够为后续铁路系统的建设起到指导作用,具有较高的应用价值。通过该模型对铁路数据资产的价值进行评估,不仅可以为铁路数据资产分类分级提供新的标准,也有助于推动与其他领域的数据资产等值共享,充分发挥铁路数据的价值。
4 结束语
随着数据量指数级的增长,数据资产在铁路领域的作用日益增强。在构建铁路数据资产价值评估指标体系的基础上,根据权重计算、量化模糊评价等需求,选择层次分析法及模糊综合评价法建立评估模型。结合铁路实际业务场景,选择具有较高价值的主数据字段进行实例验证,根据已有的模糊评价反向验证实验结果的精确性。结果表明该模型可以较为准确地描述数据资产的价值,有利于进一步挖掘铁路数据的价值,提高铁路行业数据资产管理水平。
