CWGAN-DNN:一种条件Wasserstein生成对抗网络入侵检测方法
2021-12-22贺佳星王晓丹宋亚飞
贺佳星, 王晓丹, 宋亚飞, 来 杰
(空军工程大学防空反导学院,西安,710051)
近年来,多种基于机器学习的入侵检测系统(intrusion detection system, IDS)得到了广泛的研究,这些入侵检测方法具备良好的检测性能。但是实际的网络活动中,正常的流量和行为中占绝对主导地位,异常行为的数量较少。正常行为和攻击行为、不同攻击行为之间的类不平衡问题在入侵检测的数据集中普遍存在,极大影响了IDS的检测性能[1]。
针对入侵检测中的数据集类不平衡问题,文献[2]和[3]分别使用随机欠采样(random under-sampling,RUS)和随机过采样(random over-sampling,ROS)来解决IDS中的类不平衡问题。文献[4]更进一步将RUS和ROS技术结合起来应用。合成少数过度采样技术(synthetic minority over-sampling technique, SMOTE)[5-6]在数据生成领域中表现良好,文献[7~9]将SMOTE技术应用在IDS模型中,平衡数据集,提升训练效果。但SMOTE本身依赖于插值进行过采样,生成样本的拟合度比较低。
生成对抗网络(generative adversarial networks,GAN)[10]技术,能够从给定数据中学习其分布,并根据学习到的分布生成新的样本数据。利用生成对抗网络技术,文献[11]提出了一种将GAN、粒子群算法和极限学习机结合的入侵检测方法,用GAN生成少数类样本。文献[12]提出一种基于CGAN的入侵检测技术,利用CGAN生成少数类样本,均衡训练数据集。
除类不平衡问题外,入侵检测数据集还存在着连续特征的混合模型问题。普通的GAN无法模拟一个2D数据集上的高斯混合分布的所有混合分量,学习到的数据分布存在失真[13]。例如,在入侵检测领域的常见数据集NSL-KDD数据集[14]包含3个离散特征和38个连续特征,共41维特征向量。本文利用核密度估计法对所有的连续特征进行估计后发现,38个连续特征中的22个都存在高斯混合分布的情况。文献[11]提出的基于GAN的入侵检测方法均未考虑连续特征的混合分布问题。
为解决上面提到的入侵检测数据集中的类不平衡问题和连续特征的混合分布问题,本文提出了一种基于条件Wasserstein生成对抗网络(conditional Wasserstein generative adversarial network,CWGAN)和DNN的方法。首先,CWGAN-DNN对原始数据集进行过滤,选择少数类样本,在训练的过程中使用条件向量控制生成样本的类别,保证只生成少数类样本;其次,对数据集中的连续特征利用变分高斯混合模型(variational Gaussian mixture model,VGM)[15]进行分解;最后,利用CWGAN学习处理后的数据集并生成新的少数类数据。达到平衡训练数据集,改善入侵检测系统性能的目的。
1 相关工作
1.1 数据生成技术
入侵检测数据集,如NSL-KDD[10]通常组织为一个二维的表格T,表格中的每一行代表一条流量,每一列代表一维特征。T中包含Nc个连续特征列{C1,C2,…,CNc}和Nd个离散特征列{D1,D2,…,DNd}。T中的每一列都可以看作是一个随机变量,所有随机变量遵循一个未知的联合分布:
P{C1,C2,…,CNc,D1,D2,…,DNd}
(1)
其中的任意一行可以表示为:
rj={c1,j,c2,j,…,cNc,j,d1,j,d2,j,…,dNdj},
j∈{1,2,…,n}
(2)
式中:rj是来自联合分布的一个观测样本。
在数据的生成领域,合成数据的通常做法是通过将表中的每一列视为随机变量,建模一个联合多元概率分布,然后从中取样进行生成[16]。定义输入原始数据集为s=(r,y),生成器输出合成样本为sG=[G(z,y′),y′],其中:y、z和y′分别表示原始类标签、高斯噪声和少数类标签。
1.2 生成对抗网络
条件生成对抗网络(conditional generative adversarial networks,CGAN)在原始GAN[10]的基础上引入类别信息,以生成指定类的样本。生成器同时将噪声和类别信息作为输入,鉴别器在接收样本的时候也会收到对应类别信息。CGAN的目标函数可以表示为:
Ez~pz[log(1-D(G(z|y)))]
(3)
式中:z为随机噪声;x为原始样本;y为类别信息;pz为z的分布;G为生成器;D为鉴别器;pr为真实数据x的分布;G(z)为G生成的伪数据;D(x)为D给样本打出的分数;E(·)为期望值。
GAN和CGAN中采用的Jensen-Shannon散度会导致模式崩溃和梯度消失问题[17]。针对该问题WGAN-GP[18](Wasserstein GAN-gradient penalty)将计算损失函数的JS数度改为泥土移动(earth mover, EM)距离,并增加了梯度惩罚项,来满足Lipschitz约束,避免训练过程中判别器无法收敛的情况出现,解决了GAN和CGAN中的梯度消失和模式崩溃问题。WGAN-GP的目标函数为:
V(G,D)=maxD∈1-lipschitz{Ex~pr[D(x)]-
Ex~pg[D(x)]-λEx~ppenaty[‖∇xD(x)‖-1]2}
(4)
式中:λ是人为指定的参数;‖∇xD(x)‖表示对D(x)中x的计算范式;x~ppenaty表示从pr上的一个点和pg的一个点的连线上取中间位置的x。
2 基于CWGAN的入侵检测方法
CWGAN-DNN的框架由数据预处理模块、CWGAN模块和深度神经网络(DNN)3个部分组成,如图1所示。第1步,将原始数据集进行处理;第2步,利用CWGAN模块生成均衡训练集;第3步,DNN模块使用均衡数据集进行训练,并在测试数据集上执行入侵检测。

图1 CWGAN-DNN入侵检测方法的结构
2.1 数据预处理
数据预处理部分提取少数类信息,并对混合分布的连续特征进行分解。以原始样本s=(r,y)为输入,首先筛选出需要进行增强的少数类数据(r,y′),而后进行VGM分解得到少数类样本数据s′=(r′,y′)。
对于高斯混合分布的连续特征列,利用VGM来进行处理。入侵检测数据集中,离散特征可以表示为one-hot向量[19],而高斯混合分布的连续特征难以全面地表示,本文选择将其利用VGM分解。
连续特征列中的每个值,通过VGM都将其转换为一个指示所在分量的one-hot向量v*和一个指示在分量下值大小的标量a*的并联。
利用VGM分解连续特征的混合分布,首先对于每一个连续列,使用VGM估计其分量的个数,并训练高斯混合模型;其次,对于Ci中的每个值ci,j,计算其在每个分量下的概率;最后在所求得的概率最大的子分布上采样并进行归一化。

vNc,j⊕aNc,j⊕d1,j⊕…⊕dNd
(5)
2.2 CWGAN模块
CWGAN的整个训练过程见表1,其中θG、ηθG、θD、ηθD分别为生成器的网络参数、梯度和鉴别器的网络参数、梯度。

表1 CWGAN训练过程
训练CWGAN过程中,依次交替训练生成器和鉴别器,训练主要的步骤如下:
1)首先将随机噪声向量z与类别标签y′输入G,训练并得到生成样本sG;
2)固定生成器G,对D进行训练,更新θD;
3)固定鉴别器D,对G进行训练,更新θG;
4)在鉴别器的损失值未达到0.5之前,循环执行步骤1)~3),G和D交替训练,使得生成的样本不断接近真实样本。
2.2.1 鉴别器D
鉴别器D由一个3层的全连接网络组成。在训练的过程中,将s′和sG混合作为判别器D的输入,输出为样本属于真实样本s′和伪样本sG的分类概率值,然后通过激活函数将概率值转换为预测标签。对于一个特定的输入(r,y),需要判断它来自s′而不是sG的概率D(r,y),见表1中第7、8行。
在WGAN模型当中,不再对鉴别器的值取对数。得到损失值后,可以计算梯度ηθD,通过Adam算法更新鉴别器的网络参数θD。
2.2.2 生成器G
生成器G同样采用一个全连接网络,将少数类标签y′和高斯噪声z作为输入,训练过程中将类别信息y′与噪声z连接为(z,y′),G生成样本为sG=[G(z,y′),y′]。表1中第11、12行给出了公式。
2.3 DNN部分
深度神经网络模块(DNN)被用来执行入侵检测。在CWGAN-DNN当中,DNN被设计为一个包含2个隐藏层的全连接网络。
在训练阶段,DNN模型以均衡训练集作为输入。最终给出它们在不同入侵类别上的概率分布p(y|r)。在测试阶段,DNN模块以测试数据集上未曾出现过的样本作为输入,检测CWGAN对于DNN网络的提升效果。
3 实验及分析
本文过实验来评估CWGAN-DNN的性能。将CWGAN-DNN与传统的入侵检测方法、基于类均衡的方法和一些先进的入侵检测方法进行了比较。
3.1 基准数据集
采用NSL-KDD数据集对CWGAN-DNN进行评估。NSL-KDD是评估入侵检测领域的经典基准数据集,剔除了KDDCUP99中的冗余数据,并对训练集和测试集的构成进行了调整,更适用于网络入侵检测的研究。NSL-KDD中的每条数据包括41个特征。将NSL-KDD预先划分为训练集和测试集,分别为KDDTrain+_20和KDDTest+。NSL-KDD数据集的详细信息如表2所示。
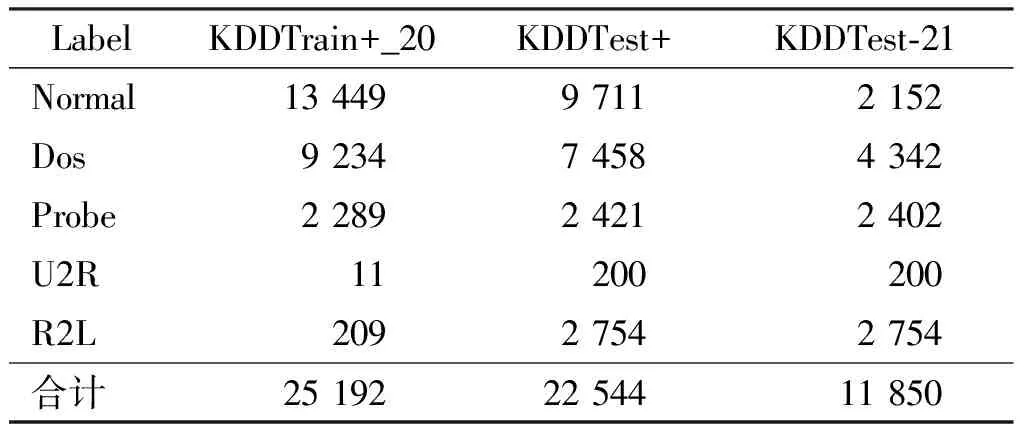
表2 NSL-KDD数据集样本类型的分布
从表1中可以看出,训练集KDDTrain+_20存在严重的类别不平衡现象,U2R和R2L攻击样本的数量严重偏少。
3.2 评价指标
为了定量评价CWGAN-DNN的性能,本文采用准确率(accuracy)、精确率(precision)、召回率(recall)和F1分数(F1 score)作为主要指标来衡量本模型的多分类性能:
(6)
(7)
(8)
(9)
式中:TP、TN、FP和FN分别表示真阳性、真阴性、假阳性和假阴性。
此外,文中采用AUC(area under the ROC curve,AUC)来反映综合能力。ROC (receiver operating characteristic curve,ROC)是研究学习器泛化性能的有效工具[20]。AUC是ROC曲线下的面积,可以更进一步的比较分类器的性能。
3.3 实验设置
3.3.1 实验设置
为了测试基于CWGAN-DNN的网络入侵检测方法的性能,本文设计了以下实验:
实验1:CWGAN-DNN模型的训练实验。
实验2:CWGAN-DNN与传统入侵检测方法的性能对比实验。
选择一些常见的机器学习方法进行比较。朴素贝叶斯和决策树是经典的机器学习方法,它们能以较低的开销提供较好的性能。随机森林[21]是一种由多个决策树构成的集成学习方法,但比决策树具有更强的泛化能力。支持向量机是一种经典而高效的分类方法,但不适用于大数据[22-23]。多层感知器(MLP)[24]是一种最简单的深度学习模型,具有稳定的分类能力。
实验3:CWGAN-DNN与不同数据类均衡方法的性能对比实验。
在类平衡方法方面,选用了随机过采样(ROS)、SMOTE和自适应综合过采样(adaptive synthetic,ADASYN)[25]技术进行对比,并将其与第2.3节中叙述的DNN结合。利用类平衡方法生成样本,然后将平衡后的样本输入DNN进行入侵检测,将这些方法分别记做ROS+DNN、SMOTE+DNN和ADASYN+DNN。这些方法中的DNN参数都保持一致,参考表2进行设置。

表2 DNN的网络结构
实验4:CWGAN-DNN与现有的入侵检测模型的性能对比实验。
将CWGAN-DNN与几种较为先进的入侵检测方法进行比较。基于模糊的神经网络(fuzziness-based neural network, NN)是一种半监督学习方法,它可以提高通过模糊分类进行入侵检测的泛化能力;文献[26]在最小二乘支持向量机(LSSVM)之前引入了一种基于互信息的特征选择(MIFS),它对特征进行贪婪选择,提升入侵检测的效果; 基于LSSVM+MIFS,文献[27]进一步提出了一种灵活的MIFS(FMIFS)方法,是一种无需经验参数的自适应特征选择方法;文献[28]将一维的入侵检测数据集转化为二维灰度图,并利用一个2层的卷积神经网络(CNN)进行入侵检测。这4种方法,均是在标准的KDDTrain+20%数据集上进行训练,并在KDDTest+数据集上进行了测试,这一点上与本文方法相同。本文采用参考文献中给出的性能数据进行对比,与CWGAN-DNN进行比较。
实验5:不同数据生成率对CWGAN-DNN性能影响对比实验。
为了验证生成样本的效果,本文还对数据的生成率对于CWGAN-DNN入侵检测性能的影响,通过一系列不同生成率的实验来评估CWGAN-DNN。
3.3.2 实验环境及参数设置
本文实验基于Windows10操作系统下Pytorch和sklearn框架进行实现。CWGAN模块中,鉴别器D和生成器G的体系结构相对灵活,可以根据具体情况进行设置。本文根据文献[16]确定了CWGAN的结构,并在验证集上通过网格搜索调整CWGAN的参数。生成器和鉴别器的各层的网络大小分别设置为100-256-256-63和63-256-256-5。
CWGAN的学习率(在算法1中表示为αD和αG)都设置为0.001。批大小(用m表示)为500,在每次迭代时优化D和G一次。生成样本个数的数量设置为原始样本的数量的1.5倍,即数据的生成比(生成样本数量:原始样本数量)为1.5∶1。对CWGAN模块进行训练,直到所有类的D收敛到0.5,此时鉴别器已经无法分辨生成样本和真实样本,即生成器具备了生成高质量样本的能力,这意味着CWGAN已经完成优化。
DNN使用具有100个神经元的全连接层作为输入层。之后采用2个大小分别为100和40的全连接层作为隐藏层。输出层的大小等于类数5。学习率设置为0.000 1。最后使用Softmax函数,将输出向量转换为概率分布p(y|r)。表2描述了DNN模块的详细结构。
作为对比试验,传统入侵检测方法和类均衡方法均使用sklearn框架进行实现,参数选择上使用网格搜索法进行优化;在与其它的先进入侵检测方法进行对比时,参考对应文献中的数据。
3.4 实验结果及分析
3.4.1 实验1:CWGAN和DNN的训练
利用CWGAN为Probe、R2L和U2R等3个少数类生成样本,训练过程中鉴别器D的损失曲线见图2。
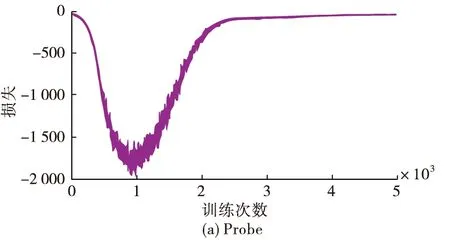


图2 NSL-KDD上少数类样本训练鉴别器的损失曲线
图2(a)、(b)和(c)分别对应Probe、U2R和R2L类,可以看到CWGAN在Probe、U2R和R2L类上分别在3 000、5 000和3 500次训练后鉴别器损失收敛。
3个类的损失函数曲线在收敛之后均存在不同程度的震荡,其中U2R类的震荡最为明显,R2L次之,Probe的震荡幅度最小。这是因为KDD Train+数据集当中U2R类的仅有11个样本,较难收敛。
以图2(b)中Probe类的损失曲线为例进行分析。在0~1 000次迭代时,G无法生成有效的数据,D可以很轻易的区分出生成样本,损失值较大;在1 000~3 000次迭代过程中,G的生成能力不断提高,D给出生成样本的得分越来越接近原始样本的得分,损失值不断降低,并在4 000次后达到动态稳定。
在DNN模块训练过程中,将平衡后的数据集作为输入。DNN模块在训练后,在测试数据集上进行入侵检测。以交叉熵函数为损失,采用Adam算法进行优化,将学习率设置为0.000 1。DNN的损失曲线如图3所示,分类器已经收敛。
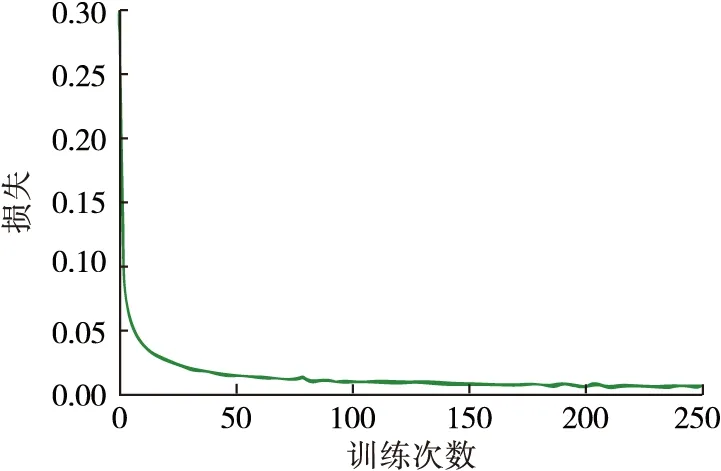
图3 DNN分类器训练过程中的损失曲线
3.4.2 实验2:CWGAN-DNN与传统入侵检测方法的性能对比实验
如表3所示,与传统的机器学习方法相比,CWGAN-DNN的准确度、和F1分数分别提升了最少3%,而AUC比MLP有2%的下降。在传统的方法中,MLP的准确率较好,在准确度和F1分数相比其他机器学习方法有1%~2%下降的情况下,AUC提升至少9%。MLP作为一种深度学习模型,具有良好的分类能力,但在处理类不平衡数据方面仍然存在一定的困难。朴素贝叶斯在NSL-KDD上取得了所有机器学习算法中最高的AUC(83%),因为它是一个生成模型,受数据类不均衡的影响较小,但它表达能力的不足导致它的分类性能较差。随机森林在2个数据集上取得了不错的成绩,显示了其作为集成模型的优秀泛化能力。然而,上述结果均反映出传统方法对数据的表达能力不足和对类不平衡数据的处理能力较弱的缺陷。
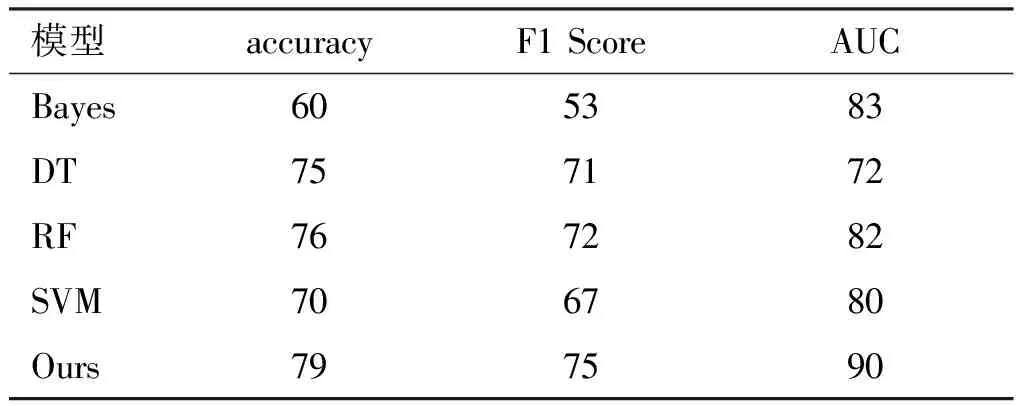
表3 CWGAN与传统机器学习方法比较单位:%
3.4.3 实验3:CWGAN-DNN与不同数据类均衡方法的性能对比实验
如表4所示,对类均衡方法,CWGAN-DNN与常见的类均衡方法相比,CWGAN-DNN的准确度、F1分数和AUC分别提升了最少3%、1%和1%。采用均衡样本训练的DNN的表现都比仅使用原始训练集更好,因为类均衡方法有助于解决类不平衡问题。SMOTE和ADASYN方法可以较好地从生成的样本中学习少数类,其准确度与RF等机器学习算法相同,F1分数和AUC均有一定的提升。然而相比于仅使用原始数据集进行训练的DNN,类均衡方法在提升准确度和F1分数的同时,AUC有至少2%的下降,体现了分类能力和泛化能力的取舍。
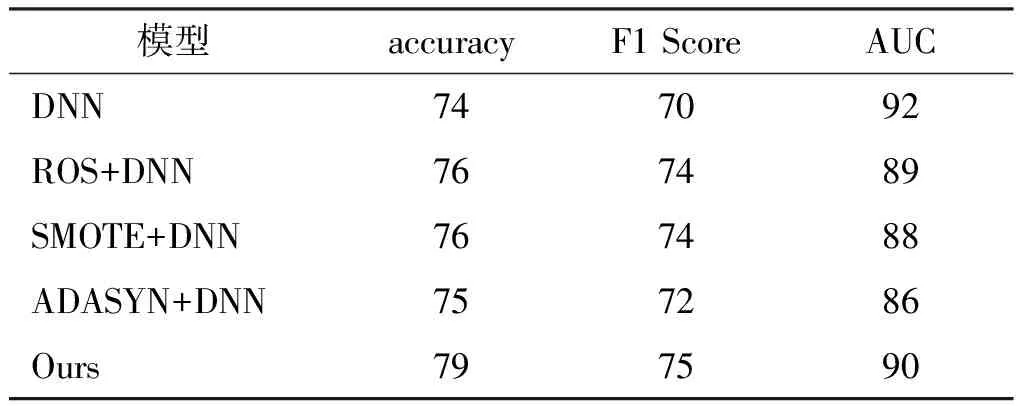
表4 CWGAN与其他类均衡方法的比较 单位:%
如图4所示,所有的类均衡方法对少数类的检测能力均有一定的提升。
在图4(a)中可以看到,ADASYN方法对Probe和R2L两类的精确度提升明显,在U2R类上表现一般。而CWGAN可以大幅度提升U2R和R2L两个少数类的检测精确度,和本文选择的方法相比均有不同程度的提升。在U2R和R2L类上,CWGAN-DNN对比DNN分别提升了55%和61%,对比其他类均衡方法,分别了15%~40%和1%~58%的提升。
图4(b)中,CWGAN在Probe和R2L两个少数类上的召回率提升幅度与其他性能较好的类均衡方法相近。但在U2R类上,CWGAN-DNN的召回率仅为6%。根据式(16)的描述,recall较低,说明FP的值较大,有大量的其他类的样本被检测为U2R类。这是因为训练集当中U2R类仅有11个样本,导致CWGAN在U2R样本上的进行训练时无法学习到U2R类样本的特征,生成的样本质量较低。


图4 类均衡方法在各类别上的性能比较
3.4.4 实验4:CWGAN-DNN与现有的入侵检测模型的性能对比实验
如表5所示,在与其他的先进的入侵检测算法进行比较时,CWGAN-DNN在准确率、召回率和F1分数3项指标上都追平或超过其他的方法,而在精确度和AUC指标上,CWGAN-DNN仅落后CNN 4%和2%。CWGAN-DNN性能的提高得益于CWGAN对少数类的高代表性合成样本,缓解类不平衡问题,模拟了未知异常。
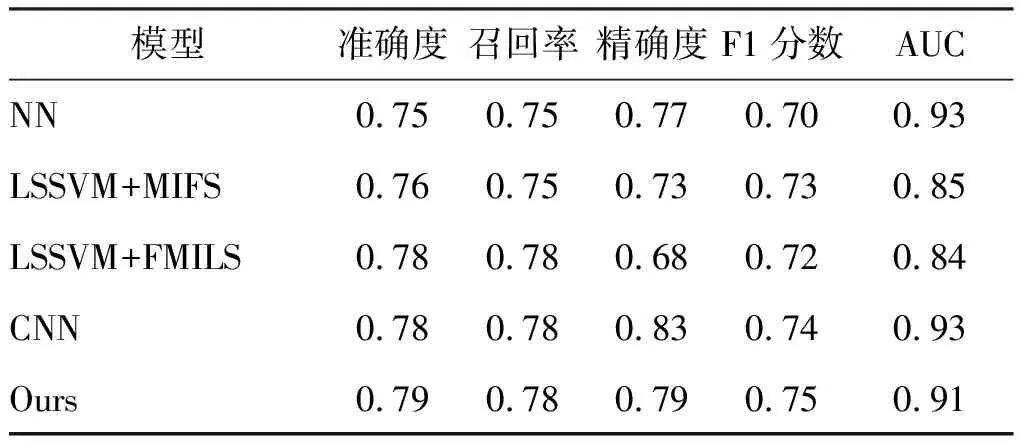
表5 CWGAN与其他先进方法的对比
3.4.5 实验5:不同数据生成率对CWGAN-DNN性能影响对比实验。
具有不同生成比率的IGAN-IDS的精度如表4所示。与没有合成样本的结果(r=0)相比,可以观察到CWGAN-DNN在训练过程中生成样本时表现出更高的性能(精确度提高4%),说明了CWGAN的积极作用。进一步比较了不同生成比率的IGAN-IDS的细节性能,如图5所示。从图5可以看出,CWGAN在生成率为1.5时获得最高的准确度、召回率和F1分数。而在生成率为0.5和1时,AUC的值最低。在实验中,建议生成率应控制在1.5。
综上所述,CWGAN-DNN确实可以通过生成样本来提高入侵检测的性能,而且生成的比率应该受到严格的控制。

图7 CWGAN-DNN在不同生成率下的表现
4 结语
为解决入侵检测系统中由训练样本类不均衡导致的检测识别率和泛化能力较差的问题,本文通过VGM和CWGAN技术生成少数类新的训练样本,改善训练集中的类不平衡问题,并在均衡训练集上训练一个全连接DNN网络进行入侵检测。将本文提出的CWGAN-DNN入侵检测技术进行性能评估,并与传统入侵检测方法、类均衡方法和主流入侵检测技术进行了比较。同时对于CWGAN在少数类的检测性能和CWGAN数据生成率对检测性能的影响。实验结果表明,CWGAN-DNN相比于传统的基于机器学习和类均衡技术的入侵检测方法,能够有效提升少数类的检测性能,从而提高总体分类能力和泛化能力。
