拟双曲动量梯度的对抗深度强化学习研究
2021-12-21马志豪朱响斌
马志豪,朱响斌
浙江师范大学 数学与计算机科学学院,浙江 金华321004
在过去的几年中,深度强化学习领域获得了广泛关注,其应用领域也得到迅速增长。深度强化学习领域的一个重要吸引力是将深层神经网络特征学习功能与经典强化学习结合使用,因而可以通过将原始观察结果直接映射到操作行为来实现端到端策略学习。凭借深层神经网络作为函数逼近器,深度强化学习在各种挑战性任务(例如,视频游戏、机器人技术和经典控制[1])上均取得了显著成果,但最近的研究表明,这些策略易受对抗性攻击,对手对输入的微小干扰,会导致模型预测的输出不正确[2-4]。
深度学习算法之所以如此强大,是因为其利用了深层神经网络的多层结构。这意味着当尝试对输入进行分类时,可以从输入的许多不同特征中找到判断结果的依据。接受过识别大熊猫训练的agent可能会发现诸如色块、纹理或形状之类的特征,这与人们眼中显而易见的事物(如黑白)一样可预测。但这也意味着利用输入的微小变化可以使agent观察到明显不同的状态。深度神经网络(Deep Neural Network,DNN)构建的模型在图像任务中已取得显著成果。但研究表明,DNN极易被对抗样本攻击。
强化学习(RL)任务与分类任务不同的地方在于强化学习是通过一系列动作来收集样本,同时这些动作也改变了环境状态,每次执行动作后,agent通过观察获得环境更新后当前状态,这个观察可能包含不确定性,该不确定性源于环境的改变、观察的不准确和黑客的有意攻击。由于强化学习的任务是一个MDP过程,因此需要通过一系列动作来完成目标任务,这样强化学习在测试时间就有更多机会受到攻击,这也是强化学习在对抗攻击中与分类任务不同地方。本文考虑了将agent的观察值从s扰动成.s′.,但agent程序所在的基础真实环境状态s不变,此设置与对状态观测值进行对抗性攻击的方式(例如Huang等人[5])保持一致。
在深度学习与强化学习结合后,当前主流对抗攻击方法是采用了针对DNN一些攻击方法,主要的是采用基于梯度的攻击方法,基本上是采用梯度下降算法来产生扰动。在现有DRL对抗攻击文献中,采用梯度方法多数是传统随机梯度下降方法(SGD)。但SGD算法存在一些不足之处:第一,SGD每次只选取一个样本虽然很容易实现,但正因由此可能会导致迭代之间梯度方向变化很大,导致产生剧烈的震荡,不能快速地收敛到局部最优解;第二,SGD对解决身陷鞍点问题存在无能为力的情况。
针对上述情况,本文采了拟双曲动量算法来产生对抗样本,其原因是:第一,拟双曲动量算法(QHM)利用指数加权平均量,在更新模型参数时,对于t时刻梯度方向与t+1时刻梯度方向相同时,参数进行加强,即此梯度方向上运动更快;对于t时刻梯度方向与t+1时刻梯度方向不同的参数,参数进行削弱,即此梯度方向上的运动减慢。第二,QHM利用动量不断累加动能的特点,可以利用动能克服势能,逃逸出鞍点。第三,梯度下降方法的计算需要有确定的目标函数,而由于强化学习的特点,其目标函数是动态的,导致虽然DRL更容易受到攻击,但攻击样本需要的扰动却是一个计算量大且计算困难的点。而QHM作为动量梯度算法的极其简单的变式,且具有效率和概念上的简洁性,计算方面也不涉及二次求导,计算量较小和计算简单。所以本文选择QHM作为产生对抗样本的梯度下降算法,第2章会详细说明选择QHM的原因和好处。
但在深度强化学习中,深度神经网络的权重是在不断更新当中,这样就造成目标函数也在不断变化,因此在对抗性训练阶段,需要固定一段时间的权重,用于进行QHM的更新。因而把目标网络复制一份出来作为攻击网络单独进行权重更新,并且这样可以单独控制攻击网络更新权重的频率。另一方面,因为QHM要涉及到动量,即指数加权平均的梯度,而根据强化学习特点,每次选择动作执行后,环境状态会发生变化,但是新状态的策略会发生变化,这也会影响到动量计算,因此本文使用KL散度来计算不同状态的策略分布距离,来方便动量参数计算,从而在对抗本本生成中能使用QHM。
本文的贡献有两个方面:第一个贡献是运用拟双曲动量梯度算法结合特定目标函数来生成对抗样本进行攻击,使受攻击的DRLagent更容易受干扰,从而使agent的回报更小,说明深度强化学习脆弱性的一面。第二个贡献是采用拟双曲动量梯度算法进行对抗训练后的智能体对环境参数不确定性具有更好的鲁棒性,同时也提高了该智能体对其他梯度攻击的鲁棒性。使用拟定的对抗性攻击训练了DRL,实验结果表明了它对参数或模型不确定性的鲁棒性。
1 相关知识
1.1 对抗性攻击
DRL继承了有监督和无监督学习中的基本安全性问题,而其不断增加的复杂性又引发了RL和DRL独有的其他问题。关于对抗性攻击的开创性文章是Szegedy等人[6],其中提到了神经网络的两种现象。首先是高维神经网络的神经元不代表某个特征,但所有特征都混合在所有神经元中。第二种是在原始采样点上添加一些有针对性但不明显的干扰,这很容易导致神经网络分类错误。大多数现有方法会生成人眼无法感知的干扰图像的对抗示例[7-9],目的是欺骗训练有素的分类器。
后来,Goodfellow等人[4]提出,在一个线性模型中加入对抗干扰,只要线性模型的输入拥有足够的维度和足够的尺寸,线性模型也显示出对抗性样本的明显脆弱性,这也驳斥了对抗性样本是由于高度非线性模型引起的解释。相反,可以肯定的是,深度学习的对抗样本是由于模型的线性特征所致。他们在熊猫的照片上增加了人工噪音。人眼几乎看不到扰动前后的两个图像之间的差异,但人工智能模型会将其误认为是长臂猿,概率为99.3%[4]。一个对抗示例是构建复合图像的示例。通过向图像添加特定的扰动,对抗性示例可以帮助主体判断扰动图像属于深度学习模型中的错误分类。建立对抗性例子的过程就是对抗性攻击。
Pattanaik等人[10]提出了新颖的RL对抗性攻击,然后使用这些攻击训练DRL来提高对对抗性参数不确定性的鲁棒性。他们提出了对抗性攻击框架。该框架用于实施经过训练的DRL agent选取最差的可能动作,即该状态下最小Q值相对应的动作。
在基于值函数的深度强化学习算法中,对于观察通道环节,对抗性攻击是指对手干扰agent获得正常观察结果。让agent在错误的观察结果下,选择最佳动作的可能性增加。换句话说,让agent在正常状态下采取最差行为的可能性增加,从而使agent获得的奖励值下降。
着重于产生对抗性攻击,这将导致训练有素的DRL agent失败。这种攻击不仅是有效的对抗性攻击深度强化学习模型,而且在其他机器学习模型上也产生类似的攻击效果。
1.2 DRL基于观察状态的对抗性攻击
针对DRL的攻击可以分为四类:针对观察状态的对抗性攻击,针对环境状态的对抗性攻击,针对奖励的对抗性攻击和针对策略的对抗性攻击。本文主要考虑基于观察状态的对抗性攻击。
由于RL的每个要素(观察、动作、过渡动力和奖励)都可能具有不确定性,因此可以从环境、观察通道、奖励渠道、执行器、经验存储和选择等不同角度研究鲁棒的强化学习。agent从环境中观察原始的真实状态并采取相应的行动,但是攻击者会通过加入干扰更改观察结果,从而agent被欺骗并认为真实状态已更改,导致agent选择了错误的动作。
Lin等人[11]提出了战略定时攻击旨在扰乱每一轮中的最小观察子集,从而降低agent的性能。Behzadan等人[12]提出了一种对抗性DRL agent,该agent经过专门训练可以操纵自主导航DRL agent的操作环境,并通过利用目标的避碰策略来诱发碰撞或轨迹操纵。Han等人[13]研究了软件定义网络(SDN)中DRL智能体的情况,攻击者伪造部分奖励信号,以诱使智能体采取非最佳行动,从而导致关键服务器受到威胁或保留的节点数量明显减少。
Huang等人[5]提出了一种统一的攻击策略,在这种方法中,攻击者会通过扰动agent观察到的每个图像,在每个时间步长攻击DRL agent。通过使用快速梯度符号算法(Goodfellow等人[4])进行图像的扰动。通过对具有离散动作的Atari游戏进行基于FGSM的攻击来评估深度强化学习策略的鲁棒性。Kos等人[14]提出使用值函数来指导对抗性扰动搜索。Behzadan等人[12]通过对抗性示例的可传递性研究了具有离散动作空间的DQN的黑盒攻击。Pattanaik等人[10]通过多步梯度下降和更好的损失函数,进一步增强了对DRL的对抗性攻击。通常这些方法作用于agent训练期间学到的策略。Gao等人[15]提出了一种针对DRL解释的具有普遍性的对抗攻击框架(UADRLI),其目的是制作一个单一的普遍性扰动,并能在每个时间步上被统一的应用。基于提出的方法,攻击者可以通过扰动观察状态,有效地欺骗后续状态的DRL agent。
1.3 DRL对抗训练
对于离散动作的RL任务,Kos等人[14]首先介绍了对Atari环境——Pong游戏环境的对抗训练的初步结果,该训练使用了对像素空间的弱FGSM攻击。Behzadan等人[16]对具有DQN的Atari游戏进行了对抗训练,发现agent在训练期间要适应攻击是具有挑战性的,即使只攻击一部分帧,agent的能力仍然会受到影响。测试时间攻击,对于乒乓球游戏(Pong game)而言,对抗训练可以将受到攻击时的奖励从-21(最低)提高到-5,但距离最佳奖励(+21)仍然很远。对于连续动作RL任务(例如MuJoCo环境),Mandlekar等人[17]使用带有策略梯度的基于FGSM的弱攻击来对抗性地训练一些简单的RL任务。Pattanaik等人[10]使用了通过优化方法产生的攻击。但是,他们的评估重点是针对环境变化的鲁棒性,而不是状态扰动。
2 基于梯度的对抗样本生成
2.1 DRL基于观察状态的对抗性攻击
DRL主要解决序列决策问题。当agent通过动作与环境进行交互时,环境会为agent返回当前的奖励。agent根据当前奖励评估采取行动。经过多次迭代的学习,agent可以通过反复试验最终在不断学习中达到最佳动作。
DRL问题通常由马尔可夫决策过程(Markov Decision Process,MDP)建模。MDP通常用元组( )S,A,P,R,γ描述,其中:(1)S为所有环境状态的集合s∈S。(2)A为一组有限的动作a∈A。(3)P为状态转移分布,如果在状态s中采取行动a,则系统将转换到新状态,并且状态转换分布描述了到其他状态的概率分布。(4)R为奖励回报,描述了行动可以产生的回报。(5)γ为折扣因子,0<γ<1。
令st和at为在时间t采取的状态和采取的行动。在每个迭代(episode)的开始时,s0~ρ0()·。在策略π下,将状态序列映射到动作,在π(at|st,…,s0)和st+1~ρ(st+1|at)处给出轨迹{st,at,r(st,at)},其中t=0,1,…。环境接收到动作后会给出一个奖励。DRL agent的目标是通过连续学习以最大化累积奖励Rt并获得最佳策略π*。
在RL中,在时间步t中生成的对手由δt表示,对抗性攻击的目的是找到使累积奖励δt最小的最佳对手。设T表示情节的长度,r(π,st)表示返回给定状态st以及策略π的奖励函数。因此,在RL中产生对抗性攻击的问题可以表示为:
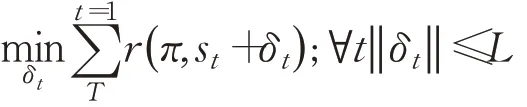
通过状态观察进行强化学习。agent观察到扰动状态而不是真实的环境状态,而是包含噪声因素δt,表示为对手加入扰动攻击DDQN的流程如图1所示。
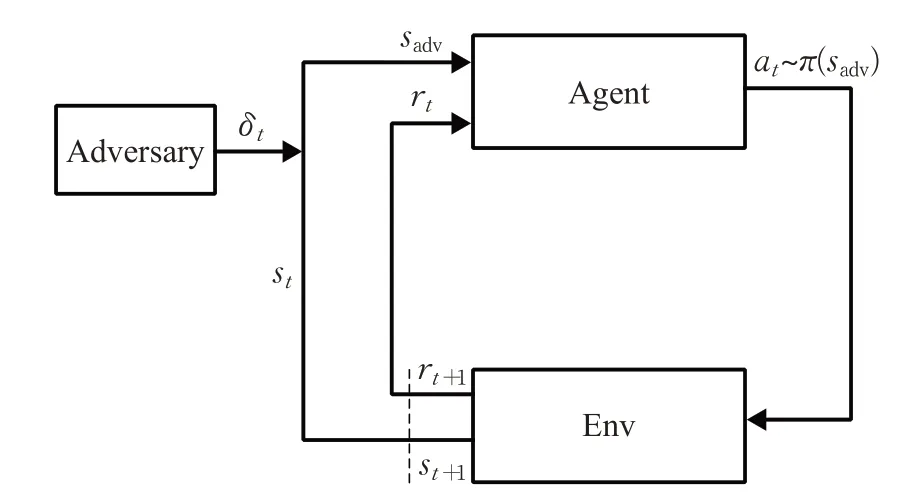
图1 基于状态的攻击流程图Fig.1 Flow chart of opponent’s state-based attack
研究许多攻击方面的工作(Goodfellow等人[4]、Huang等人[5]、Behzadan等人[12])。这些攻击的方法本质上是基于梯度下降的,因为它们都是通过在策略网络中进行反向传播,以计算成本函数相对于输入状态的梯度来生成对抗性样本。
2.2 梯度下降
Pattanaik等人[10]使用的是随机梯度下降(Stochastic Gradient Descent,SGD),随机梯度下降(SGD)源自Robbins和Monro在1951年提出的随机近似[18],最初应用于模式识别和神经网络。此方法在迭代过程中随机选择一个或几个示例的梯度来替换整个梯度,从而大大降低了计算复杂度。随机梯度下降每次迭代使用一个样本来更新参数。并非所有训练数据都具有随机梯度下降功能。随机梯度下降是随机优化一条训练数据,损失函数在每次迭代中。这样,大大加快了每个参数的更新速度。原始的SGD公式是:
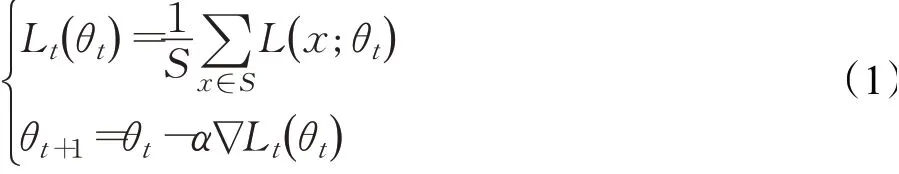
定义1最优策略π为条件概率质量函数具有最大条件概率质量函数值的动作记为a*,而具有最小条件概率质量函数值的动作,也称为最坏的动作记为aω。
假设1在t时刻,RL agent产生n个不同的动作,记动作集合为
定义2[10]满足假设1,aω=min{ }a1,a2,…,an,定义对抗概率分布
定义3[10]最佳对抗性攻击的目标函数,定义为对抗概率分布和最优策略之间的交叉熵损失,记为:

根据Pattanaik等人[10],最小化RL agent目标函数,定义为最大化最差动作的最优策略,形式上为这样,保证了利用最小化RL agent目标函数来进行攻击agent。另外其中样本的集合为S(SGD中的样本个数为1),损失度量为代表单个样本。θt+1表示的是t+1时刻和θt表示的是t时刻的优化参数表示在t时刻的损失函数,α表示学习率。Pattanaik等人[10]的SGD表示为:
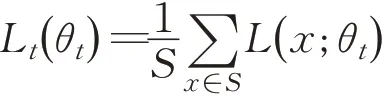
由假设1、定义2、定义3:
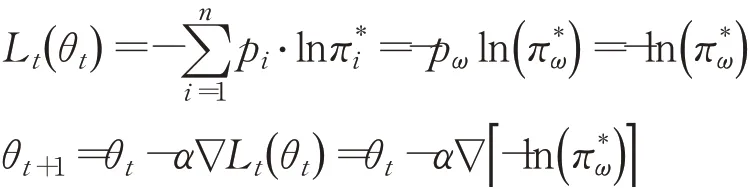
但是SGD存在着明显的缺点:准确度下降。由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛。算法可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势。不易于并行实现。可以想象到,如果学习率太大,将无法获得理想的结果,如果学习率太小,则训练可能会非常耗时。对于复杂的问题,用户通常希望使用很高的学习率来快速学习感兴趣的参数,以获得初步的判断结果。不幸的是,当学习率很大时,SGD会产生剧烈波动,这可能会导致训练不稳定。
于是引入动量(Momentum)方法[19]。一方面是为了解决“峡谷”和“鞍点”问题;一方面也可以用于SGD加速,特别是针对高曲率、小幅但是方向一致的梯度。动量方法不容易因为某次的干扰而产生巨大波动,可以使轨迹更加稳定;同时因为在鞍点处因为惯性的作用,更有可能离开鞍点。其中β为经验折扣因子,叠加了Momentum(MOM)的SGD公式为:
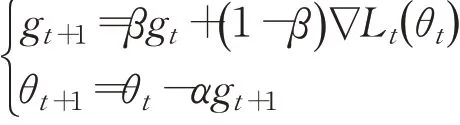
Nesterov’s Accelerated Gradient(NAG)[20]是Momentum的变种。与动量方法在公式上的唯一区别是计算梯度时的不同。NAG中,先用当前的速度临时更新一遍参数,再用更新的临时参数计算梯度。因此,Nesterov动量可以解释为在Momentum动量方法中添加了一个校正因子。但是NAG方法因为用到了二阶信息,NAG方法收敛速度明显加快。波动也小了很多。叠加Nesterov动量的SGD公式为:
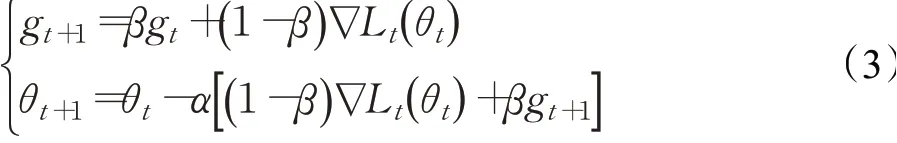
本文写的公式参考的Ma等人[21],与另一种动量公式的表示形式相反(Sutskever等人[22]),用( )1-β归一化抑制了动量缓冲参数g。这既可以消除更新步幅幅度对β的依赖性,又可以将g解释为过去梯度的加权平均值。当然,Ma等人[21]的公式书写方法与Sutskever等人[22]的方法相比,这也将更新缩小了1-β倍。这很容易逆转,相应增加常数因子α。
2.3 拟双曲动量梯度
为了克服SGD的缺点,引入动量方面的方法。本文选择Ma等人[21]提出的一种新颖的方法,即拟双曲动量梯度下降算法(QHM)。本文使用拟双曲动量梯度下降算法来提高框架的效率。Ma等人[21]提供的QHM理论在操作效率和理解概念方面简明扼要。拟双曲动量梯度下降算法的公式如下:
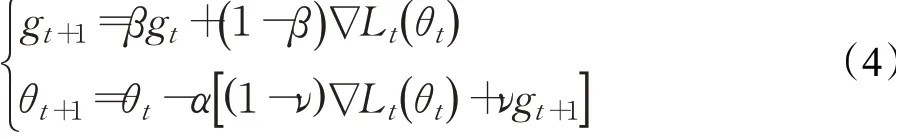
根据定义1~3,则QHM表示为:
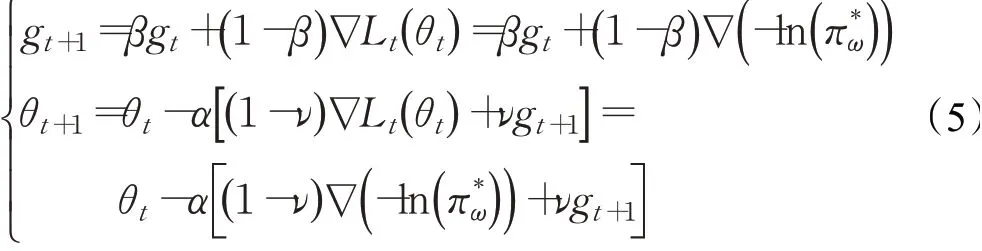
尽管准双曲动量与普通动量类似,但需要辅助存储缓冲区。每个更新步骤还需要1个就地标量向量乘法和3个标度向量加法。QHM计算量小,易于理解且易于实现。它们可以在各种情况下代替动量。特别是,它们可以通过使用即时折扣(即ν)来使用高指数折扣因数(即β)[21]。与NAG相比,QHM没有新增额外的计算开销。并且在一定的条件下,QHM与NAG是等同的。
由式(3)得θt+1(NAG)的展开式:
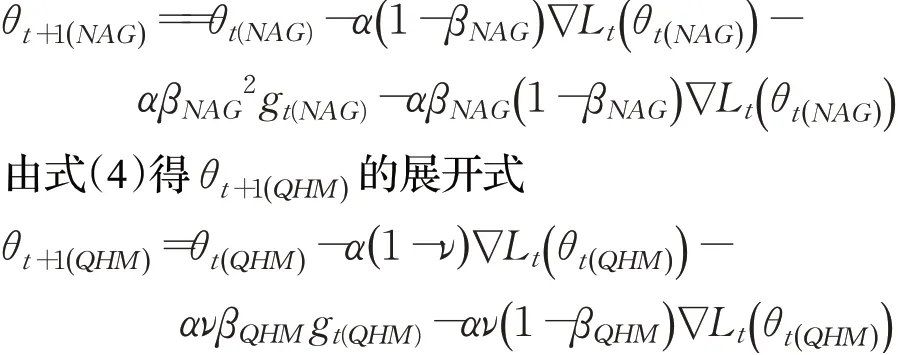
从上述两公式的格式可以看出两者很相近,并且当t时刻满足如下公式:
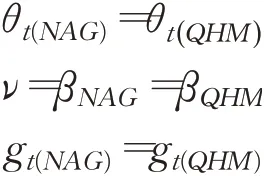
可以得到θt+1(NAG)=θt+1(QHM),即QHM与NAG的运算结果相同。
对于SGD和QHM,假设SGD和QHM的参数处于同一点,现在来考虑这一点处的参数更新,如图2所示。
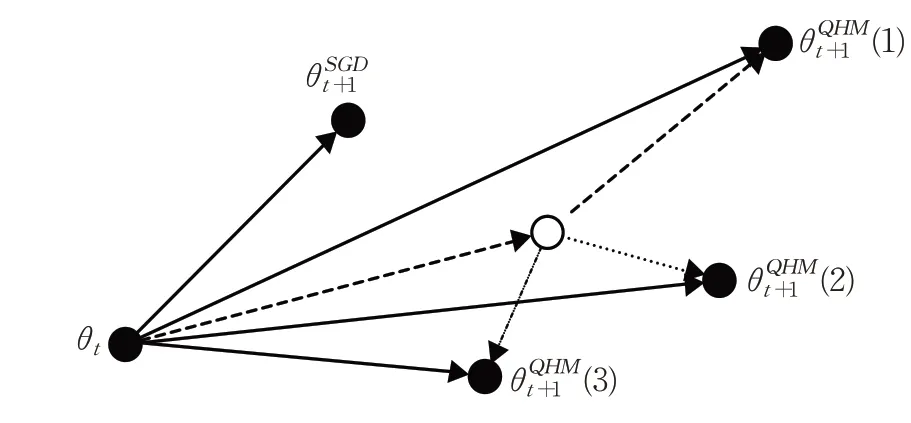
图2 SGD和QHM参数更新示意图Fig.2 Schematic diagram of parameters update of SGD and QHM
图2 展示了SGD和QHM的参数更新过程。基于公式SGD的参数更新过程,如实线所示。参数θt沿负梯度方向移动步长α,即可得到更新参数基于公式QHM可知,如虚线所示,θt先沿加权平均梯度gt+1,也就是动量的负方向移动步长αν;如虚线所示,再延负梯度方向移动步长α(1-ν);从而得到更新参数如虚线和点线的过程所示,若梯度的方向与加权平均梯度gt+1的方向夹角为锐角,亦可看作是向前一步后并未发现前方梯度出现逆转,于是项起到了加强更新的作用,得到更新参数如虚线和“短线-点-点”线的过程所示,若梯度的方向与加权平均梯度gt+1的方向夹角为钝角,可看作是向前一步后发现前方梯度出现大波动,于是项起到了减弱更新的效果,得到更新参数,这样不会因为某次的干扰而产生巨大波动的作用。
3 基于拟双曲动量梯度的对抗性攻击和对抗性训练
3.1 基于拟双曲动量梯度的对抗性训练时期的对抗性攻击
本文考虑到对于Pattanaik等人的[10]算法是针对最差动作aω和对应状态s,因为最差动作aω和状态s会使损失函数发生改变。由于强化学习过程中,智能体会使用依据当前策略选择动作执行,从而会作于用于环境,造成环境状态的变化,这后续状态的aω与前面状态的最坏动作可能不是一同的,因此如果只是按照时间顺序使用QHM,会出现不同的最差动作aω和状态s穿插在一起的情况。然而gt是加权平均梯度,针对不同的最差动作aω和状态s进行加权平均梯度,这样计算动量意义不大,同时也很难在每一步采用SGD或QHM方法一直计算收到局部最优点去得到最优攻击样本。因而本文方法是首先要确保的是相同网络权重下,如果网络权重更新,则gt只能重新赋值为初始动量值。其次在选择最差动作aω相同条件下并且将状态s的改变限制在一定微小的范围内,此时使用之前记录的最差动作aω相应的gt来优化下降过程并对gt进行更新。这样的加权平均梯度gt才会对损失函数有意义。但是高维度状态s之间的计算会使得计算过大,于是本文提出在Q值分布相近情况下,并且在相同网络权重和最差动作aω情况下,采用之前相近Q值分布状态下的gt来近似计算新动量参数,实验结果表明这个方法有效的。对于相近Q值分布状态的判定,通过设置对称式KL散度来计算在相同网络权重和最差动作aω情况下策略分布的距离。此时刻的策略πp和之前记录的策略πq都经过了softmax函数的作用,映射成为(0,1)的值,而这些值的累和为1(满足概率的性质)。那么就可以将它理解成概率,进而使用KL散度。对于策略分布的KL散度公式:
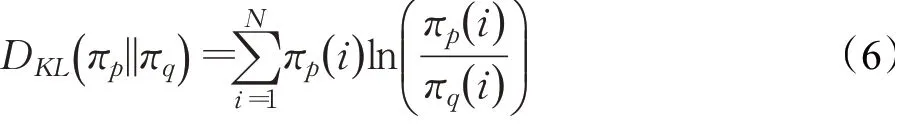
因为KL散度是不对称的,所以本文计算出策略πp对策略πq和策略πq对策略πp这两个方向的两个KL散度,然后将它们的均值称为对称式KL散度,作为两策略分布间的距离,具体公式如公式(7)所示:
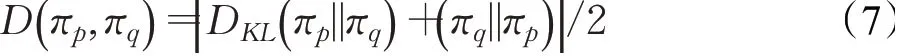
衡量对称式KL散度D(πp,πq)是否小于阈值τ时,即若D(πp,πq)<τ时,使用最差动作aω之前记录的gt-1来计算更新gt。
本文使用QHM来生成对抗性攻击干扰。本文将在Pattanaik等人[10]的框架上进行改进,使用QHM算法,并且复制一个Q网络称为Qadv进行权值更新。加上基于beta概率分布的随机采样噪声,进行n次示例以进行比较取出扰动最大的状态sadv。算法1概述了针对DDQN的梯度攻击。

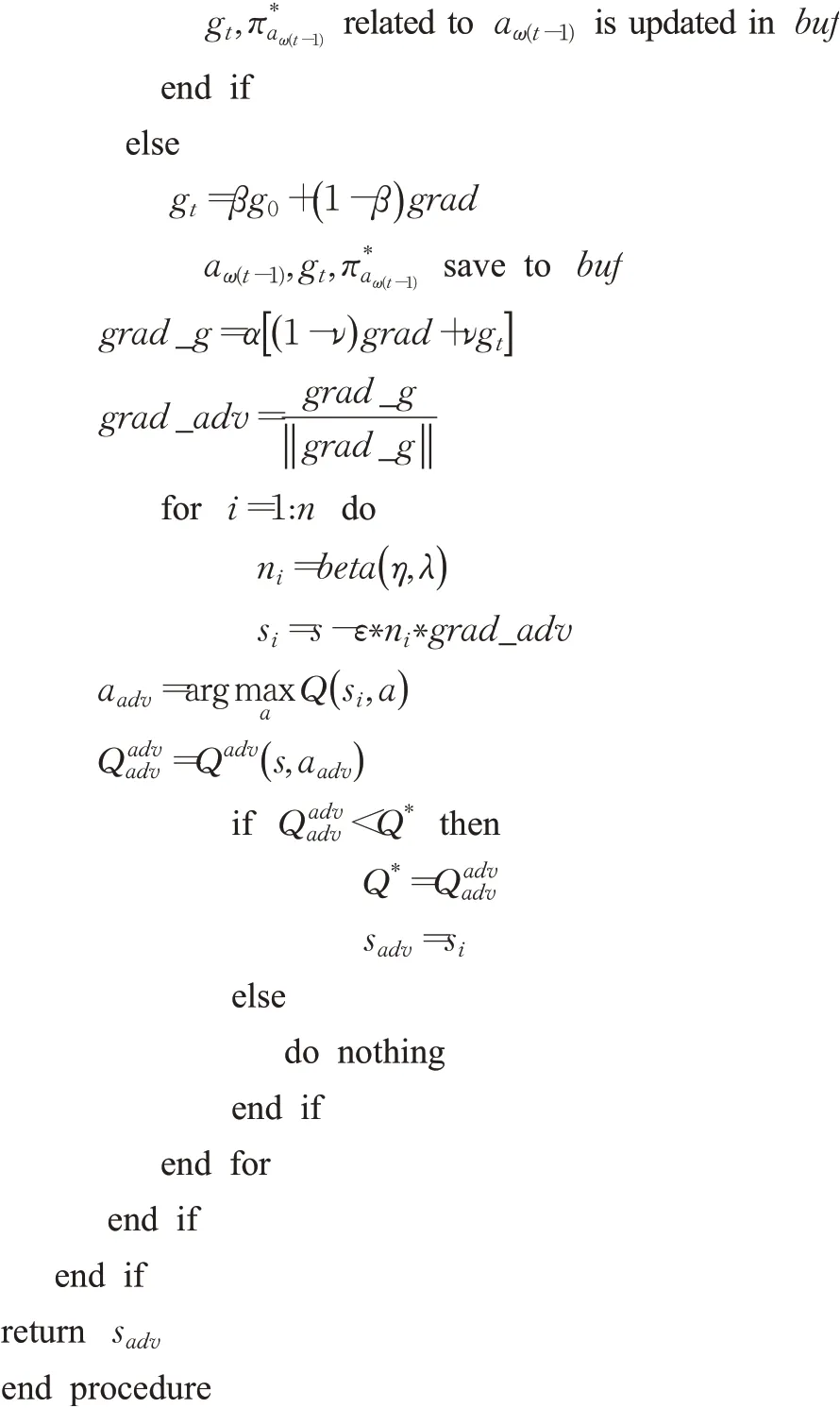
3.2 基于拟双曲动量梯度的对抗性训练算法
对抗训练是深度强化学习防御对抗攻击的主要方法。本文使用拟双曲动量梯度产生的干扰影响观测状态的方法,欺骗智能体在错误观察状态下选择最优动作,而实际上是当前环境状态的最差动作。本文首先使用原始DRL(DDQN)训练算法,然后通过对抗训练使训练后的agent变得更加鲁棒。参考在Pattanaik等人[10]的对抗训练算法,本文的对抗性训练算法如算法2所示。


3.3 基于拟双曲动量梯度的测试阶段对抗性攻击
测试阶段对抗性攻击是指训练好的模型在决策时或应用时受到攻击情况。由算法1与算法2生成的对抗样本时应用了训练过程中神经网络权重,因此基于拟双曲动量梯度的测试阶段攻击样本的生成算法需要作出调整。主要的变化在于测试阶段神经网络权重是不变的,因此需要对算法1与算法2进行调整。针对算法1,因为测试时间较短,所以不进行复制网络来进行单独的操作,而是直接使用Q网络。所以针对算法1QHMA(Qadv,Q,s,η,λ,α,β,ν,n,ε,g0,buf,τ)中,将Qadv用Q代替,即QHMA(Q,Q,s,η,λ,α,β,ν,n,ε,g0,buf,τ)。针对算法2的改动,基于拟双曲动量梯度的测试阶段算法如算法3所示。

4 实验及结果分析
本章的实验是经典RL文献中的控制实验问题(例如Mountaincar,Cartpole),如图3所示。本文的DDQN实现是keras-rl[20]中模块的修改版本。本文的实验结果表明提出的对抗性攻击使原始的DDQN算法的性能显著下降,并通过对抗性训练算法,在面对基于环境因素的改变时,使DDQN鲁棒性得到了显著提高。
图3 经典控制问题Fig.3 Classic control problem
4.1 对抗性攻击
在图4中显示的是经典控制问题的对抗性攻击情况,图4(a)显示了使用DDQN的对Cartpole环境的对抗性攻击。图4(b)显示了对Mountaincar环境的对抗性攻击。实验中展示了对抗性攻击的有效性和强力性。首先在默认参数上使用原版本DRL(DDQN)训练了一名agent。然后,在不改变环境参数的前提下,测试了未经过对抗性训练的agent,在面对基于HFSGM的对抗性攻击,基于SGD的对抗性攻击以及基于QHM的对抗性攻击的情况。
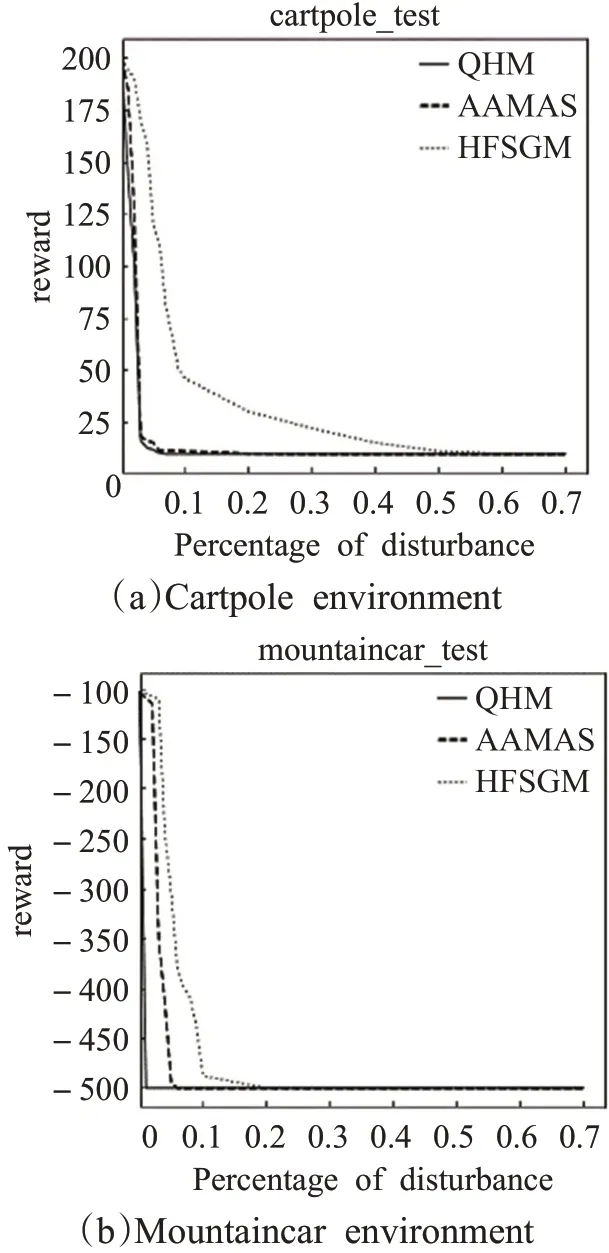
图4 经典控制问题的测试情况Fig.4 Test situation of classic control problem
Y轴最高值对应于没有受到对抗性攻击时收到的平均奖励,X轴对应于扰动的百分比。显而易见,对抗性攻击降低了基于深度学习的算法的性能。对比三者,虽然图4(a)中基于SGD的对抗性攻击以及基于QHM的对抗性攻击都使奖励快速下降,,但综合图4(b)可以看出,针对经典控制问题,攻击在三者中更有威胁性。
4.2 鲁棒性训练
首先来观察下对于经典控制问题,使用原始DRL(DDQN)训练的过程后,基于QHM的对抗训练的DDQN再训练的过程和基于SGD的对抗训练的DDQN再训练的过程。
图5 中显示的是经典控制问题的训练过程情况,图5(a)是在Cartpole环境中,首先训练一个原始的DDQN,让agent针对Cartpole环境训练完毕。然后分别加入基于SGD的对抗训练和基于QHM的对抗训练。图5(a)显示的是基于SGD的对抗训练的DDQN和基于QHM的对抗训练的DDQN的训练过程,观察这个过程记录的数据可以发现,基于SGD的对抗训练的DDQN先到达奖励为10 000的稳定状态。基于QHM的对抗训练的DDQN的训练过程因为对抗样本更好,而到达奖励为10 000的稳定状态的步数相对滞后。在图(b)关于Mountaincar的环境中,训练一个原始的DDQN,让agent针对Mountaincar环境训练完毕。然后分别加入基于SGD的对抗训练和基于QHM的对抗训练。基于QHM的对抗训练过程相比于基于SGD的对抗训练过程处于低奖励值的次数更多。从而由训练过程实验证明了基于QHM的对抗攻击会对agent造成更大的扰动,达到更强力的破坏。
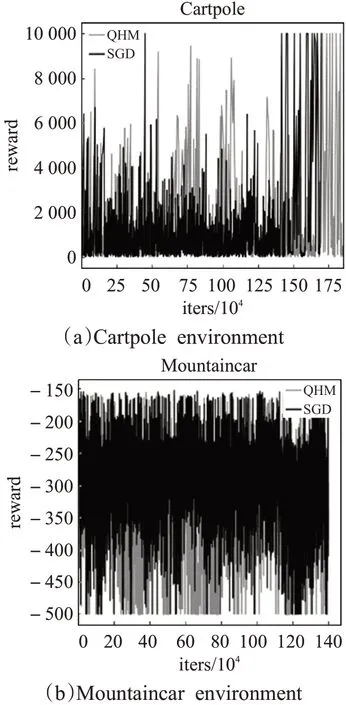
图5 经典控制问题的训练过程情况Fig.5 Training process of classic control problem
为了进行评估,测试了经过对抗性训练的agent面对环境中各种参数的改变而获得的奖励值,并将其与原始agent进行了比较。
图6 中显示了Cartpole环境中由于强大的训练,agent在面对不同环境参数,而性能上得到的改善。图6(a)显示了Cartpole环境中原始DDQN算法在手推车质量和杆长之间变化的每步平均回报;图6(b)显示了通过SGD训练后,鲁棒DDQN算法的每步平均回报。图6(c)显示了通过QHM训练后,鲁棒DDQN算法的每步平均回报。当杆子倾斜的角度θ不能大于15°,手推车移动的位置保持在中间到两边各2.4个单位长度,每个小步的每个时间步长收到1的奖励。这一过程在pole倾斜角度超过15°,手推车超出需要保持的范围或者花费完10 000个时间步长时结束。在图6(a)~(c)中,展示了对Cartpole环境的总体奖励有了显着改善。从默认参数得到的原始DDQN的最佳reward分数是10 000。未经过对抗训练的原始DDQN的agent在面对Length of Pole和Mass of Cart的参数变化时,reward产生严重的下降。从图6(a)上可以发现未经过对抗训练的agent的reward下降率达97%以上(所以干扰环境下的reward情况均低于500)。但是经过对抗训练的agent在面对Length of Pole和Mass of Cart的参数变化时,reward依旧可以保持相应的平稳。在Length of Pole和Mass of Cart处于极端情况时(例如Length of Pole=2.5并且Mass of Cart=2.5),本文提出的基于QHM的对抗训练的DDQN比起基于SGD的对抗训练的DDQN能得到更好的reward。

图6 Cartpole环境下鲁棒性训练Fig.6 Robust training in Cartpole environment
图7 中显示了Mountaincar环境中由于强大的训练,agent在面对不同环境参数,而性能上得到的改善。图7(a)显示了Mountaincar环境中原始DDQN算法在小车质量和功率系数之间变化的每步平均回报;图7(b)显示了基于SGD的对抗性训练后,鲁棒DDQN算法的每步平均回报。图7(c)显示了基于QHM的对抗性训练后,鲁棒DDQN算法的每步平均回报。在Mountaincar环境中,agent在达到目标所需的每个时间步长都得到-1的负回报。当汽车达到目标或花费完500个时间步长时,episode就会结束。在右部三角形区域中,由于功率系数不足(例如power=0.33,mass=2.25)以推动山地车到达目标,因此无法得到有效的改进。在右上方区域,它功率过大。因此,它容易达到目标。即使如此,不同的对抗训练的效果也不同,奖励值显示出本文提出的基于QHM的对抗性训练使agent更具有鲁棒性。在右上方区域,提出的方法reward比基于SGD的对抗性训练要高出50%。另外在对角线区域周围,功率系数恰好足以推动山地车,因此也可以观察到显著的reward变化,在这个区域内也显示着本文提出的基于QHM的对抗性训练使agent更具有鲁棒性。
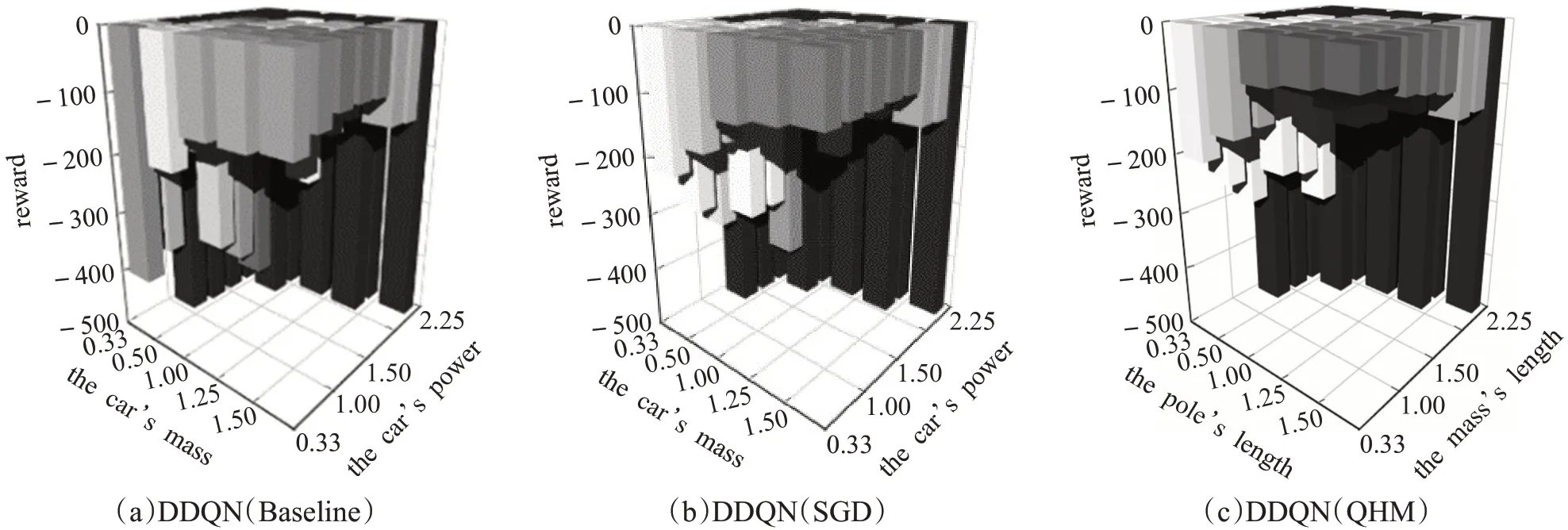
图7 Mountaincar环境下鲁棒性训练Fig.7 Robust training in Mountaincar environment
4.3 小结
通过对抗训练使agent具有鲁棒性。对经过基于SGD的对抗性训练的DDQN以及基于QHM的对抗性训练的DDQN,并将其与“原版本”DRL进行了各项评估和比较。在不同的控制理论问题中,都可以发现由于对抗训练的存在可以增强DDQN的鲁棒性,并且提出的基于QHM的算法,在两个实验中都优于Pattanaik等人[10]提出的算法。
5 结束语
本文通过研究状态观察的对抗性扰动下的强化学习问题,提出了针对深度强化学习算法基于拟双曲动量梯度方法产生对抗攻击样本。并针对神经网络权重的多变性,提出使用复制网络和对称型KL散度对算法施加约束条件,从而更好地实现强有力的对抗攻击样本的生成。在测试时间阶段,实验结果表明原始训练好的DDQN在面对基于QHM的对抗性攻击时的脆弱性。在对抗训练阶段,利用对抗性攻击来训练DRL agent,训练后的DDQN在各种环境参数变化中实现了强大的性能,展示了基于QHM的对抗性训练的DDQN具有更强的抗干扰性能和攻击性能。
