唇语识别的深度学习方法综述
2021-12-21马金林朱艳彬马自萍巩元文陈德光刘宇灏
马金林,朱艳彬,马自萍,巩元文,陈德光,刘宇灏
1.北方民族大学 计算机科学与工程学院,银川750021
2.图像图形智能信息处理国家民委重点实验室,银川750021
3.北方民族大学 数学与信息科学学院,银川750021
随着人工智能技术的发展和计算机算力的增强,唇语识别逐渐成为研究热点。唇语识别是一种通过视觉特征解释唇部、面部和舌头的运动来理解语音的技术,最初由Sumby等[1]在1954年提出,1984年,Illinois大学[2]建立了第一个唇语识别系统。与其他识别系统(包括人脸识别、指纹识别和手势识别)相比,唇语识别具有时效性、方便性和直接性的特点。唇语识别涉及模式识别[3-4]、计算机视觉[5]和图像处理等研究领域。由于其在信息安全[6-7]、语音识别[8-9]和辅助驾驶[10]方面具有应用价值而受到广泛关注。
根据识别模式的不同[11],将唇语识别分为视听语音识别(Audio-visual Speech Recognition,AVSR)和视觉语音识别(Visual Speech Recognition,VSR),AVSR是指利用唇部视觉信息辅助音频语音识别,VSR仅使用唇部的视觉信息。2016年之前,传统技术研究较为广泛,详见文献[12]。传统方法能够解决一定数据规模下识别精度不高的问题,但需要具备丰富唇读知识的研究者设计特征提取方法,此外,还存在泛化性不高的缺点。随着大规模数据集[13]的出现和识别任务复杂性的提高,基于深度学习挖掘人类视觉与认知规律的唇语识别技术成为发展必然。基于深度学习的唇语识别方法将一连串被裁剪的唇部图像送入前端以提取视觉特征,然后将其传递给后端以建立时间依赖的分类模型,并以端到端的形式进行训练。唇语识别的深度学习方法框架如图1所示。
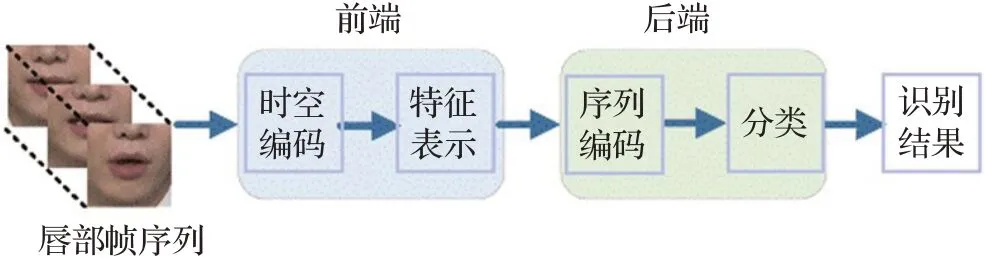
图1 唇语识别深度学习方法框架Fig.1 Deep learning methods for lip recognition
根据识别对象的不同[14-15],唇语识别的深度学习方法可以分为孤立唇语识别方法和连续唇语识别方法:孤立唇语识别方法的识别对象是数字、字母、单词或短语等视觉上可分的有限类别;连续唇语识别方法的识别对象是音素、视素[16](视觉信息的基本单位)、字符等视觉上不可区分的视觉单元。
1 孤立唇语识别的深度学习方法
孤立唇语识别的输入与输出呈多对一关系。由于数字字母等识别对象唇形的模糊性,不同识别对象可能产生相似的唇形运动,因此孤立唇语识别主要围绕如何更有效地描述唇动的底层特征、降低误判率展开。根据视觉时序特征提取方法的不同分为基于二维卷积神经网络(2D CNN)和基于三维卷积神经网络(3D CNN)两类识别方法。
1.1 基于2D CNN的识别方法
基于2D CNN的孤立唇语识别方法经历了两个研究阶段:第一阶段,通过构建基于光流和灰度图像的双流二维卷积神经网络展开研究。第二阶段,为避免光流输入,在单流2D CNN基础上,构建时间特征提取模块来捕获上下文信息。
第一阶段,针对单流2D CNN无法建模时间上下文信息的问题,Weng等[17]提出基于光流和灰度视频的双流网络,利用光流图像序列中像素的时域变化和相邻帧间的相关性,寻找前一帧与当前帧之间的对应关系来直接编码唇部运动。双流网络通过将光流与灰度视频流融合的方式,捕获相邻帧间的像素运动。具体地,使用PWC-Net[18]计算光流后,使用与灰度视频流相同的前端结构(不共享权重)提取光流特征,并与灰度视频流提取的特征相融合。该方法在清洁音频和低噪声条件下取得了一定效果,但无法获得长时依赖。为此,采用长短时记忆网络(Long Short Term Memory Network,LSTM)聚合2D CNN输出的视频帧的底层特征,产生了音视频同步网络SyncNet[19]。该网络包括五个2D CNN层和两个全连接层,将在卷积层提取自灰度输入图像的单帧特征向量输入到单层LSTM,LSTM在时间序列中对输入特征建模,返回预测类,在OuluVS数据集[20]上取得了94.1%的识别准确率。文献[21-22]也采用了类似结构。但由于LSTM对帧间底层的时间信息建模不足,导致时序信息丢失,同时,光流法的预计算具有计算量大、对光照和说话人姿态变化敏感的缺点。因此,设计时间特征提取模块,通过有效捕获唇部运动的上下文信息避免使用光流输入是该领域的研究热点。
第二阶段,避免光流输入,有两种设计思路。一种思路是从光流计算的原理出发,通过相邻帧的连续性和不同人发音时运动模式的一致性,设计变形流网络(DFN)[23]。变形流网络通过学习相邻帧之间的变形流来直接捕捉唇部区域的运动信息,它将唇部运动建模为说话过程中唇部区域的一系列明显变形,然后将学习到的变形流与原始灰度帧结合起来进行识别。为了使两个流在学习过程中利用信息的互补性进行相互学习,引入双向知识蒸馏损失来共同训练这两个分支。但由姿势、光照条件、说话人的外表、说话速度等的变化所带来的噪音使模型无法有效捕捉唇部运动信息。为提高模型对外部环境的鲁棒性,在局部特征和全局序列的层面上引入相互信息约束[24],以加强它们与语音内容的关系。一方面,通过施加局部相互信息最大化约束,提高模型发现细微的唇部运动和发音相似的单词之间细微差异的能力。另一方面,在全局序列水平上引入了互信息最大化约束,使模型能够更多关注与语音内容相关的关键帧辨别,而较少关注说话过程中出现的各种噪音。通过将这两者结合在一起,提高孤立唇语识别的辨别力和鲁棒性。
另一种思路是对时间通道上的信息进行有效处理来设计时间特征提取模块。例如,Chung等[25]将建模的最小单元由单张图片变成连续若干帧所组成的片段,在通道维度上拼接后,作为分类网络的输入来构建时间特征提取模块。最具有代表性的工作是早期融合(Early Fusion,EF)[26]和多塔(Multi-Tower,MT)[27],它们在VGG-M[28]架构之上添加额外的卷积层,分别用于捕捉输入数据的空间和时空信息,提高网络动态特征建模能力。其中,基于2D CNN的多塔结构表现最好,在LRW数据集[29]的500个单词训练下,准确率达到61.1%。然而该方法仍无法处理整个唇部图像序列的时空信息,因此提出一种新的序列图像表示方法——帧级联图像(Concatenated Frame Image,CFI)[30]。CFI将视频的所有帧连接成一幅图像作为输入,分别在嵌套网络(Network in Network,NIN)[31]、AlexNet和GoogLeNet中提取视觉特征,基于CFI的GoogLeNet表现最好,但会大量学习到与任务无关的冗余信息(如姿态、光照、肤色等)。为解决这一问题,研究人员在CFI的基础上提出一种基于Hahn矩的2D CNN[32](HCNN),它结合Hahn矩有效地提取和保留图像中最有用的信息以减少冗余。实验表明,浅层HCNN模型能有效地降低视频图像的维度,分类精度优于GoogLeNet和SyncNet,极大降低了模型复杂度。
基于2D CNN的识别方法虽能很好地解决唇部特征的自动提取问题,但需要指出的是,在处理顺序输入时,即使使用动态帧,该方法在每次卷积运算后均会丢失输入数据的时间信息,该架构仍会在空间特征方面有所妥协,需要借助光流或设计专门的时间特征提取模块来捕获连续帧图像在时间维度上的信息。基于此,3D CNN被引入孤立唇语识别中。
1.2 基于3D CNN的识别方法
基于三维卷积神经网络的识别方法采用三维卷积(3D CNN)对连续帧唇部图像的时空信号进行建模,能很好地获取时间信息和空间信息。Stafylakis等[33]首次采用3D CNN来提取唇语视频的时空特征,强调对唇部区域进行短期动态建模的必要性。采用3D CNN建模虽然能够得到比2D CNN更紧凑的特征表示,但仅仅在具有丰富视听内容的数据集上表现良好,泛化能力弱。为解决这一问题,耦合的3D CNN[34]架构利用从视觉模态提取的信息,通过寻找视听流之间的对应关系补充缺失的信息来提高模型的泛化能力。首先,对视觉模块,将固定大小的60×100灰度图像输入到4层3D CNN提取唇部运动的时空信息,并利用时间上的相关性加以对齐;在音频模块,用3D卷积层提取MFCC(Mel-Fequency Cepstral Coefficients,MFCC)[35]特征,然后,将视频和音频模块提取的特征映射到一个特征空间,通过多模态特征判断视听流之间的对应关系。上述方法通过重复堆叠三维卷积块来获取较大的时间感受野,但存在参数量大、网络时空复杂度大、容易过拟合等问题。同时因时空特征信息存在差异而无法提取细粒度空间特征。
针对过拟合问题,主要通过构建3D+2D卷积神经网络结构的方法解决。首先通过一个大感受野的3D卷积抽取短时依赖,然后利用2D卷积独立地对图像特征建模,相当于用3D的形式代替了2D中多个连续帧的拼接。
受ResNet[36]启发,Stafylakis等[33]提出基于3D CNN+ResNet的网络架构,网络输入是灰度归一化且持续时间为1 s的视频序列,残差网络由34层(包括卷积层、池化层和全连接层)组成,这些层逐渐减少具有最大池化层的空间维数,直到每个时间步输出一维矢量为止。然后,这些一维矢量用作两个双向LSTM(Bi-LSTM)[37](每个方向两个)的输入特征,在每个时间步将它们串联起来进行分类。此后,Petridis等[38]在类似的前端结构上,使用Bi-GRU替代Bi-LSTM,并添加音频流构建出第一个视听融合模型,该模型能同时学习从图像像素和音频波形中提取到的特征。与逐层堆叠的3D CNN相比,将2D CNN和3D CNN聚集在一起,不仅可以增强模型学习视觉特征的能力,而且大大降低了时空融合的复杂性。此外,为进一步减少模型参数量,提出改进的3DDensNet模型[39],使用1×1×1卷积的稠密块和变形块起特征压缩的作用。
针对视频信号的时空特征存在差异的问题,Wiriyathammabhum等[40]提出SpotFast网 络。SpotFast是动作识别网络SlowFast的变种,它利用一个时间窗口作为定点路径使用词的边界信息,将所有帧作为快速路径隐含着其他语境的建模。这两条路径都与双时空卷积融合,在减小时空特征差异的同时加快训练速度,再结合记忆增强的横向转化器学习用于分类的顺序特征。
3D CNN采用三维卷积同时捕获时空信息,且能同时处理多个输入帧,提升了算法的运行速度。目前,基于3D CNN方法的识别精度已远超2D CNN方法。但3D CNN的一个缺点是需要算力强大的硬件,因而需要较高的计算和存储开销。目前常利用由2D和3D卷积层混合而成的3D+2D卷积神经网络的方法进行解决。表1列出了孤立唇语识别主要的深度学习方法。
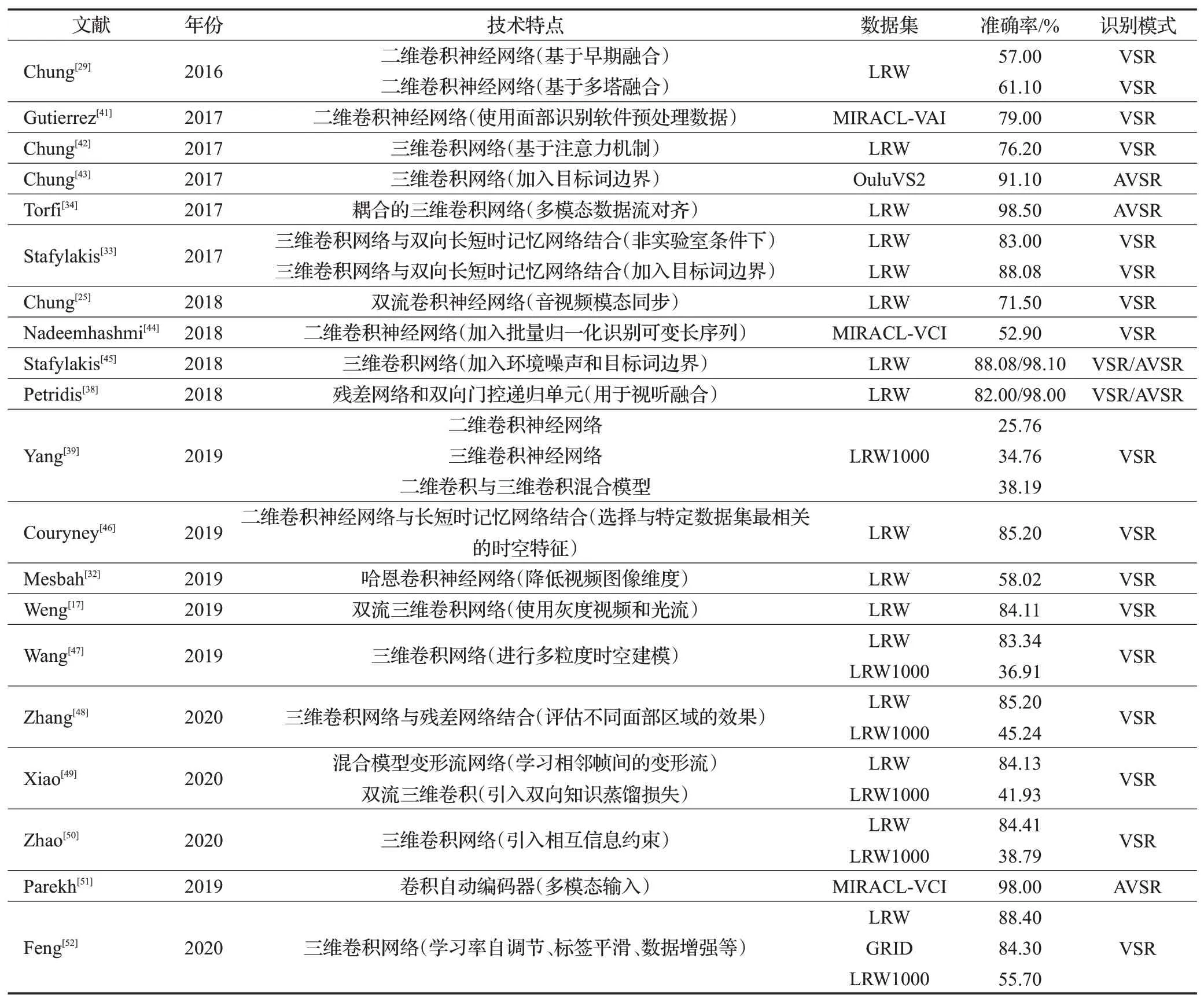
表1 孤立唇语识别的深度学习方法Table 1 Isolated lip recognition techniques based on deep learning and representative work
2 连续唇语识别的深度学习方法
连续唇语识别的输入输出之间是多对多关系,相较于孤立唇语识别,需要建立更为可靠的长期时序依赖。根据主干网络的特点将连续唇语识别方法分为基于联结时序主义分类模型和基于注意力机制的编解码模型。
2.1 基于联结时序主义分类模型
相较于孤立唇语识别,连续唇语识别更为复杂,对时序性要求更强。采用联结时序主义分类(Connectionist Temporal Classification,CTC)[53]能更好地对唇语长时序序列进行文本标签对齐。Assael等[54]基于CTC损失提出第一个连续唇语识别网络LipNet,在GRID数据集上对LipNet进行评测,在重叠和未观察到的说话人条件下,单词错误率[55]分别达到4.8%和11.4%。类似地,汉语句子识别的LipCH-Net[56]架构也被提出。上述架构在最小识别单元为字符的小规模连续唇语识别中取得了不错性能。针对数据集中可识别词汇量小的问题,Shillingford等[57]建立了现有规模最大的视觉语音数据集LSVSR,并首次提出最小识别单元为音素的V2P模型。其结构如图2所示。V2P使用CTC损失进行训练,其前端由3D卷积模块组成,用于从视频片段提取时空特征。后端通过时间模块聚合这些特征,输出目标音素序列。在测试阶段,使用基于有限状态转换器(FSTs)的译码器产生给定音素分布序列对应的单词序列。V2P和LipNet在LSVSR数据集上分别实现了59.1%和27.3%的单词识别率。
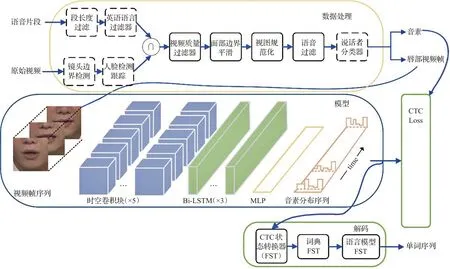
图2 V2P框架Fig.2 V2P framework diagram
基于CTC损失的连续唇语识别方法,通过长时序列的文本标签对齐,解决说话速度不同导致的输入序列和输出序列的长度上不相等问题。由于网络输出有条件相互独立的假设,CTC损失更多地关注邻近帧的局部信息[58],而不是所有帧的全局信息,因此需要外部语言模型才能获得良好性能(如V2P中需采用N-gram有限状态转换器转换成单词序列)。同时,CTC损失需要满足输入序列必须比输出序列长的约束,因此它不适合进行可变长的连续唇语标签预测。
2.2 基于注意力机制的编解码模型
与基于CTC的模型不同,编解码模型允许外部语言模型作为解码器的一部分被隐性学习,这将连续唇语识别中可训练的数据从对齐数据扩展到纯文本数据,有利于提升模型的泛化能力。在此基础上引入注意力机制[59]计算解码器的隐藏状态来从给定的帧序列中提取鉴别性特征,同时忽略多余的背景信息。有助于解码器在不同时间步长下对编码器的输出引起注意,从而更好地处理可变长的连续唇语识别任务。
其中最具代表性的工作是Chung等[42]提出的由Watch、Listen、Attend和Spell模块组成的WLAS网络,其中Watch、Listen模块为视频和语音模块编码。Spell模块为解码模块,Attend模块根据作用于视频和语音的注意力机制计算每个时间步的上下文向量。为进一步提升模型的泛化能力,将这项工作扩展到多视图数据并提出改进的MV-WAS网络[60],分别在侧面视图和正面视图实现了62.8%和56.4%的单词错误率。此后,研究者们通过使用基于注意力机制的方法消除条件独立性假设,获得了比CTC更好的性能。本文总结不同类型注意力机制在唇语识别中的应用,如表2所示。

表2 唇语识别中不同类型注意力机制对比表Table 2 Comparison of different types of attention mechanisms in lip recognition
基于注意力机制的编解码模型在可变长连续唇语识别任务中取得了不错的效果,但使用递归神经网络堆叠编解码器的过程中会产生两个问题:(1)RNN中的“teacher-forcing”策略[61]导致的暴露偏差。(2)判别性优化目标(通常是交叉熵损失)和单词错误率之间的不一致。为解决这两个问题,Luo等[62]提出基于伪卷积策略梯度(PCPG)模型:一方面引入单词错误率评价指标作为奖励形式,与原始判别目标一起优化模型;另一方面受卷积运算的局部感知特性启发,在奖励和损失维度上进行伪卷积运算,从而将每个时间步周围的更多背景考虑在内,为整个优化过程生成一个稳健的奖励和损失。该方法虽能一定程度上解决RNN堆叠带来的问题,但无法突破RNN自身结构限制导致的模型无法快速收敛和并行训练问题。基于此,研究者们彻底摒弃RNN,提出基于多头自注意力机制的编解码框架Transformer[60],它能在不同子空间表示中学习唇部运动相关信息,进一步提高全局上下文特征的提取能力。根据采用的损失函数不同,将其分为TM-seq2seq和TM-CTC。其中,TM-seq2seq采用隐马尔可夫模型[63]进行解码的第二阶段,单独的注意力头被用于关注嵌入的视频和音频。
在每个解码器层中,所产生的视频和音频上下文信息在信道维度上连接并传播到前馈块。而TM-CTC先采用CTC预测逐帧标签,然后在逐帧预测和输出序列之间寻找最佳对齐方式。TM-CTC模型将视频和音频编码连接起来,通过一组自注意/前馈模块传播结果,网络的输出是每个输入帧的CTC后验概率,并且整个堆栈都用CTC损失训练。其缺点是模型假定输入和输出序列之间是单向排序的。Afouras等[60]比较了这两种变体的性能,在VSR识别模式下,TM-Seq2Seq性能更优,TM-CTC模型对于环境噪声的鲁棒性更强。
CTC假设个体特征具有条件独立性,而基于注意力的模型可以提供非顺序对齐。为强制单调对齐,同时摆脱条件独立性假设。2018年,首次提出将CTC损失与基于注意力的模型相结合的混合架构[75]。该架构的编码器使用一组双向长短时记忆网络将输入流转换为按帧计算的隐藏特征表示。这些特征通过一个包含递归神经网络语言模型(RNN-LM)、注意力机制和CTC的联合解码器来输出标签序列,在LRS2数据集上实现7%的单词错误率。同年Xu等[58]提出LCANet,将编码的时空特征输入到级联注意力CTC解码器,从而捕获更长的上下文信息。引入注意力机制使CTC损失中的条件独立性假设的约束变弱,对视觉相似的视素单元做出更好预测,在提高连续唇语识别精度的同时,提升了收敛速度。该模型在GRID数据集上获得了97.1%的识别准确率。表3列出了主要连续唇语识别的深度学习方法。
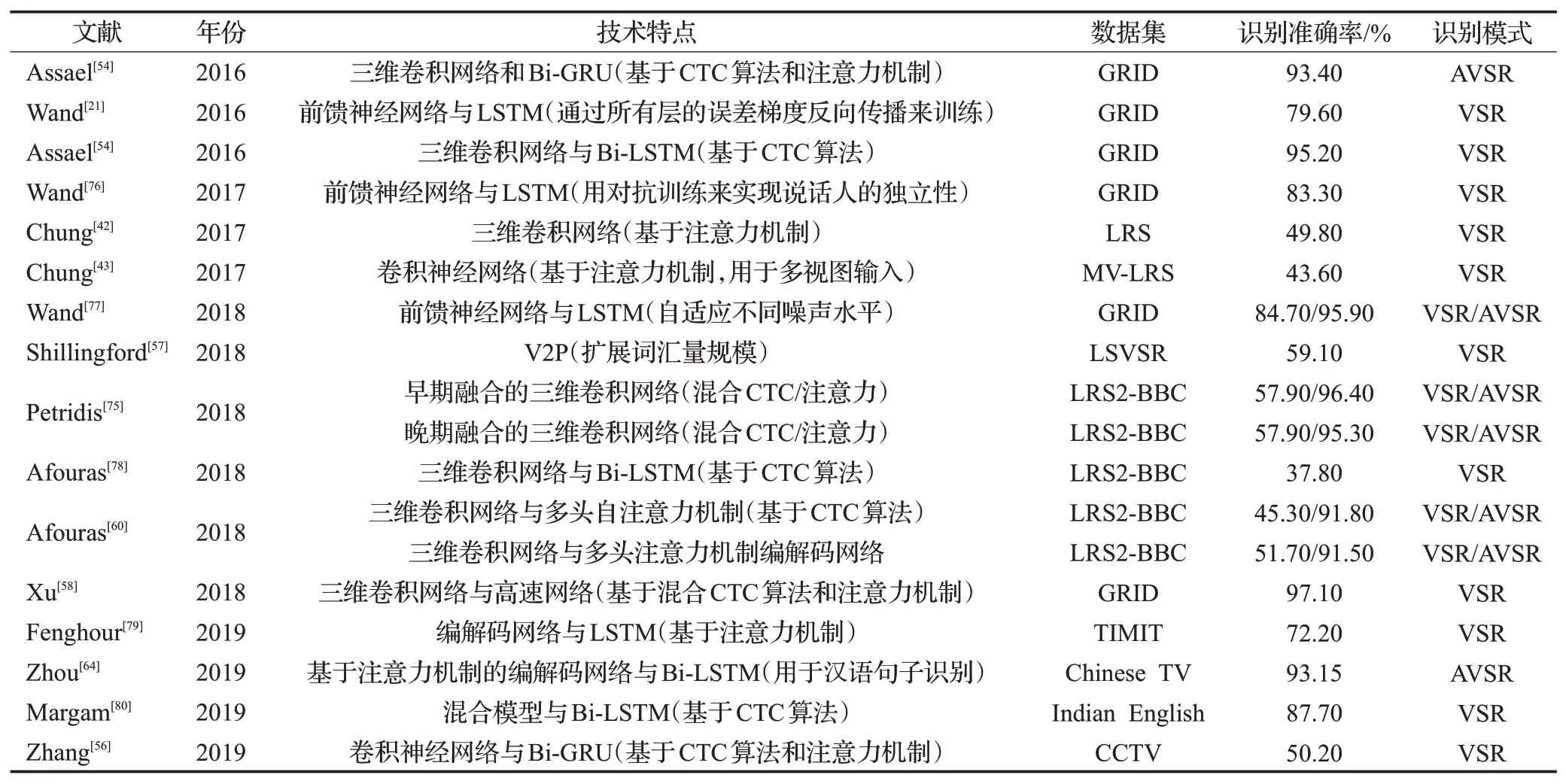
表3 连续唇语识别的深度学习方法Table 3 Continuous lip recognition techniques based on deep learning and representative work
3 唇语识别的深度学习方法的性能对比
目前,由神经网络实现的端到端唇语识别架构已达到比传统方法更高的性能[81-82]。陆续发布的大规模唇语识别数据集为研究者们在通用大规模数据集上评估其方法创造了条件。大量训练样本和具有挑战性的测试集使唇语识别的深度学习方法的训练和可靠结论的得出成为可能。唇语识别系统的识别性能不仅取决于模型表现,而且受许多其他因素(如预处理方法)直接影响,即使对同样的数据集采用相同的方法,是否有外部语言模型、是否存在说话者依赖、是否有音频信号也会影响识别效果。唇语识别中常关注的实验条件有:
(1)外部语言模型[78],在解码过程中整合外部语言模型,实际是对文本输出的后处理优化过程。
(2)说话者依赖[83],是指测试集中的说话人同时也出现在训练集中,在这种条件下训练出的模型容易出现对于说话者的过拟合。
(3)音频信号,多数唇语识别深度学习方法在训练阶段不会使用音频信息,但部分方法会不同程度地利用音频信息训练音视频共享特征表示。
字母数字识别的全面评估见参考文献[84],本文评估单词、短语、句子三种不同识别任务中。本文选取常用的单词数据集LRW[29]与LRW-1000[39]、短语数据集GRID[85]和句子数据集LRS2-BBC[42]与LRS3-TED[86]对唇语识别的深度学习方法进行比较,结果如表4所示。
由表4可以看出:(1)孤立唇语识别主要在前端结构的初始层使用三维卷积来提高性能。算法性能与前端CNN的深度息息相关,ResNet-18平衡了模型深度与识别精度,显示出积极的影响。此外多数方法采用递归架构,如双向LSTM和双向GRU或近期使用较多的TCNs对后端序列进行编码。满足上述条件的基线模型识别准确率可达82%~83%,但要进一步提高性能需要采取不同的前端策略。例如,对训练图像进行数据增强以生成任意姿势的合成面部数据,使系统能够很好地泛化。通过设计专门的训练策略,在LRW和LRW-1000上,孤立唇语识别的最高识别准确率分别达到88.40%和55.70%。

表4 不同数据集下代表性方法对比Table 4 Comparison of representative methods under different datasets
(2)连续唇语识别在GRID数据集上的单词错误率已低至2.9%,表明深度学习方法在面向小规模受限实验环境下的连续唇读识别能力几乎饱和。这催生了非受限环境下大规模数据集的构建,相比之前在受限实验室环境下收集的数据集来说,其识别难度有很大的提升,如在LRS2-BBC数据集上连续唇语识别的单词错误率高达48.3%,表明基于深度学习的方法对于连续唇语识别任务的性能十分有限。表5从算法优点、局限性和适用范围3个方面对孤立唇语识别的深度学习方法和连续唇语识别的深度学习方法进行了总结和比较。
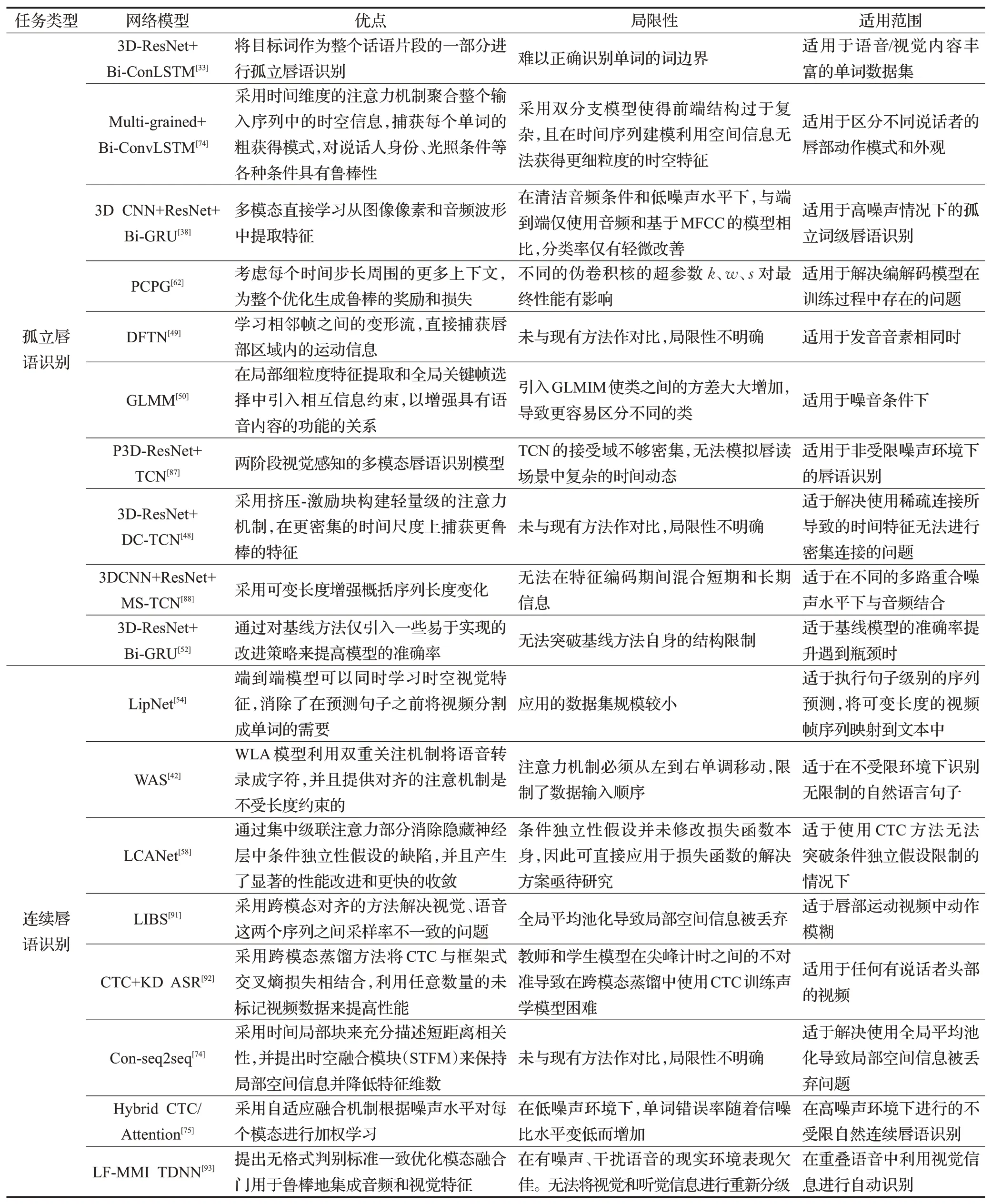
表5 唇语识别深度学习方法对比表Table 5 Comparison table of deep learning methods for lip recognition
4 困难与挑战
基于深度学习的唇语识别虽已取得重大进展,但在以下方面仍存在许多问题。
(1)视觉歧义:首先在发音的过程中,有一些不同的音素具有相同的口型。如,英语中的辅音音素/d/和/t/在视觉上是不可区分的。其次相同单词在不同语言环境下发音不同。目前在没有具体语境的情况下,很难区分视觉歧义。研究人员主要使用不同的音素映射[94-95]和相邻字符或词来解决视觉歧义问题。
(2)姿态变化:在现实中,人们在说话的过程中可能伴随着头部的转动。这种变化导致唇部角度的变化。由于不同说话人的姿态不同,有不同的角度样本。从这些样本中很难提取到与语音内容相联系的特征。在现实场景下,极难在说话过程中获取到多视角的唇部运动数据。目前对此仍少有针对性的解决方法。主要通过建立多视图的视觉语音数据集,获取更多视角来解决唇语识别中说话者姿态变化引起的面部角度问题。
(3)说话者依赖:在一些数据集中,说话者数目非常少,而在实际应用中往往需要识别未知说话者。不同人的说话习惯存在差异,唇语识别就是要从唇部图像中提取特征。这些特征往往含有说话者的信息,而与说话内容无关。因此,如何在唇部图片中提取与说话人无关的信息也是一个关键问题。
(4)多模态识别:单模态方法提取唇部视频帧的视觉特征信息是有限的,从多模态方向入手,采用音频、图像差分图、变形流等作为辅助输入处理唇语识别任务,提取不同维度的有效信息是该领域的一个重要研究方向。
(5)大规模唇语数据集:一些早期数据集在数量、样本和背景方面是单调的,这极大地限制了唇语识别的发展。近年来,越来越多的大规模视觉语音数据集出现,例如LRW、LRS和LSVSR。在说话者数量和说话内容方面更加丰富,但这些数据集仍然存在词汇量较小、采集场景与姿势受限等问题。唇语识别亟需构建包含多个说话者和不同姿势背景的大规模数据集,尤其针对中文的这对唇语识别技术的发展起着重要作用。
(6)多语种混合识别:多语种识别中存在的困难:嵌入语言受主体语言影响形成的非母语视素现象严重,不同语言视素构成之间的差异给混合视素建模带来巨大困难,带标注的混合视素训练数据极其稀缺。可以通过引入“混合词典构建”“混合视素模型自适应”算法,解决口型差异带来的协同视素和视素差异等问题。
5 未来研究趋势
结合唇语识别的现状和深度学习的发展方向,其深度学习方法的未来发展趋势主要为:小样本学习、轻量化模型。
(1)小样本学习:大多数基于深度学习的连续唇语识别方法需要大量的训练样本才能收敛。然而,现实的唇语识别任务往往应用于特定场景,无法提供足够的训练样本,训练样本的缺少会导致深度学习模型欠拟合。在未来的研究中,可以利用多模态信息来缓解小样本学习中标注数据少的问题,例如增加深度图信息。同时,可以在特征层面进行数据增强,来提升模型的鲁棒性。
(2)轻量化模型:设计轻量化唇语识别模型,使其可以部署到移动终端或便携式设备。由于现有的唇语识别模型具有参数多、时间复杂度高等特点,既不能满足实时性和高效性的要求,也不能部署于移动终端或便携式设备。可借助蒸馏、剪枝、自动模型压缩等方法,设计更加轻量化的识别网络,推动唇语识别应用于更多场景。
