基于HP-LSTM模型的股指价格预测方法
2021-12-21张朝阳
姚 远,张朝阳
河南大学 管理科学与工程研究所,河南 开封475004
股指价格预测一直是国内外学术的焦点,但是股票市场受到宏观经济政策、政治、投资心理和新闻舆论等大量因素的影响,具有高噪声、非平稳、非线性等特点,所以股票市场较难预测。国内外许多学者曾对时间序列预测模型进行研究,提出很多预测股票市场的模型。目前主要存在两大类模型,一类是传统计量模型,如ARMA、ARIMA和GARCH等模型[1-4],但是对一些高噪声、非平稳、非线性的时间序列预测精度较低。另一类是人工智能模型,近年来,由于人工智能技术快速发展,在金融界得到广泛应用。机器学习算法中的神经网络模型非常适合非平稳、非线性数据的建模[5-6],作为神经网络的一种,循环神经网络(Recurrent Neural Network,RNN)则非常适合时间序列预测,理论上也能够学习任意长度的时间序列,但由于存在梯度消失问题,实际中并不能学习较长的时间序列[7]。Hochreiter等人[8]提出了长短期人工神经网络(Long-Short-Term Memory,LSTM),相比普通RNN神经网络,LSTM神经网络模型引入了门控机制,解决了梯度消失问题,能学习较长的时间序列,在时间序列预测领域得到广泛应用[9-11]。由于大多金融时间序列具有高噪声等特点,在金融时间序列预测领域,LSTM神经网络结合其他模型可以得到精度更高的预测结果。景楠等人[12]将卷积神经网络(CNN)和LSTM神经网络模型结合在一起,利用CNN神经网络模型从时间序列中提取空间特征,将提取的特征输入LSTM,并在LSTM输出端引入注意力机制对沪铜期货高频价格进行预测,得到了预测精度更高的混合模型。Bao等人[13]将小波变换(WT)、堆叠自编码机(SAEs)和LSTM神经网络模型结合在一起,利用小波变换对股指价格时间序列进行去噪,然后利用堆叠自编码机学习股指价格时间序列的深度特征,最后将提取的特征输入LSTM神经网络模型进行预测,实验结果显示预测精度得到显著提升。Zhang等人[14]把股价时间序列看作不同交易频率的叠加,对LSTM神经网络模型内部结构进行修改,将DFT算法融入LSTM神经网络模型,预测精度得到较大提升,但此类模型网络深、参数多、复杂度高等特点,决策过程难以理解。Cho等人[15]在LSTM神经网络的基础上提出门控循环单元(Gated Recurrent Unit,GRU)。GRU神经网络相比LSTM神经网络仅包含“更新门”和“复位门”两个门控结构,并且融合了LSTM神经网络中的“细胞状态”和“隐藏状态”,因此GRU神经网络中训练参数更少,更不容易过拟合,并保持了LSTM神经网络的预测效果。因为GRU神经网络的优良特性,因此在越来越多的领域得到应用。如Umut等人[16]将GRU神经网络应用于电力价格预测,实验结果表明GRU神经网络的预测精度优于所有基准模型。赵兵等人[17]结合卷积神经网络(CNN)和GRU神经网络,并将注意力机制融入网络中,提出基于注意力机制的CNN-GRU模型,最后将提出的模型应用于短期电力负荷预测中,实验结果表明CNN-GRU模型具有更高的预测精度。但是金融领域需要的不仅仅是高精度模型,同时更关注模型的可解释性,因此提高神经网络模型的可解释性也成为当前人工智能领域的新课题。
在混合模型中,有一类是利用信号分解算法将时间序列分解为不同频率的序列,然后分别预测分解出的各个序列使预测精度得到提升。如郭金录[18]利用变分模态分解(VMD)和集合经验模态分解(EEMD)技术将沪深300指数价格时间序列分解为不同频率的时间序列,然后利用LSTM神经网络模型分别进行预测,最后将预测结果相加得出股指的预测值。实验结果表明,与其他基准模型比较,精度得到显著提升。但是在此类模型当中,较难分析分解出的各个序列的实际意义,可解释性仍然较差。另一类模型则将传统计量模型和神经网络模型结合,既提高了模型预测精度,同时也提高了模型的可解释性。如Kim等人[19]将LSTM神经网络模型和GARCH模型整合在一起,提出LSTM-GARCH混合模型,并将模型用于股指价格波动率预测,实验结果显示,相比单一GARCH模型,预测精度得到显著提升。Bukhari等人[20]将ARFIMA模型和LSTM神经网络模型结合在一起,提出ARFIMA-LSTM模型,并将其用于金融时间序列预测,与单一ARIMA和LSTM神经网络模型相比,预测精度得到提升。此类模型在提高了预测精度的同时,融合传统计量模型,相比将不同的机器学习模型或者信号处理算法融合起来的混合模型,降低了模型的复杂性,提高了模型的可解释性。
由于股指价格会受到不同因素的影响,有研究将股指价格时间序列分解为不同频率的子序列,并分别对其进行预测以提高预测精度。HP滤波(Hodrick-Prescott Filter)是由Hodrick和Prescott提出的一种研究经济运行的一种滤波方法,它将经济运行看作长期趋势和短期波动的叠加,被广泛用于经济学研究中[21-24]。HP滤波除了可以用于宏观经济分析,一些研究也将HP滤波用于微观经济变量预测当中。如姚远等人[25]使用HP滤波将已实现波动率分解为长期分量和短期分量,然后使用自回归神经网络(ARXNN)预测长期分量,使用自回归模型预测短期分量,实证结果显示预测精度得到显著提升;周亮[26]利用HP滤波将人民币汇率序列分解为趋势项和周期项,分别利用ARIMA模型和机器学习模型对其进行预测,实验结果显示预测结果比单一模型更加精确;杨建辉等人[27]利用HP滤波将股价时间序列分解为长期趋势序列和短期波动序列,然后通过高阶自回归和GARCH模型对分解出的序列进行预测,得到了精度较高的预测结果。由于大多数基于HP滤波的预测模型都使用了传统计量模型对分解出的序列进行预测,预测结果虽具有较高的可解释性和实际含义,但预测精度相对不高,实际利用价值不高。
股指价格时间序列具有高噪声、非线性、非平稳等特点,而LSTM神经网络模型对此类时间序列预测精度较高,因此本文引入HP滤波器,将股指价格时间序列分解为长期趋势序列和短期波动序列,使用LSTM神经网络模型分别对长期分量和短期分量进行预测,最后将两个预测值相加得到股指价格预测值,实验结果表明本文提出的模型相比单一神经网络模型预测精度有较大提升。因为长期趋势序列和短期波动序列分别代表原时间序列的长期特征和短期特征,具有一定的实际经济含义,因此模型的可解释性也得到了提升。
1 模型设计
1.1 Hodrick-Prescott滤波基本原理
Hodrick-Prescott滤波(HP滤波)是由Hodrick和Prescott于1980年提出,随后被广泛应用于经济分析中。HP滤波假设经济运行是长期变动和短期波动的结合,将时间序列Y={y1,y2,…,yT}分解为两个子序列,即长期趋势序列G={g1,g2,…,gT}和短期波动序列S={s1,s2,…,sT}。其中长期趋势序列gt,t=1,2,…,T,通过最小化下式得出:
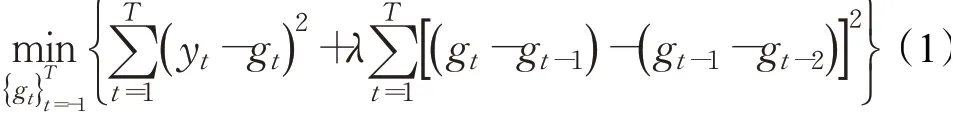
其中,T表示时间序列yt的样本个数,λ大于0,称为平滑参数。表示两项的权重。当λ=0时,满足最小化问题的长期趋势序列G等于原序列Y。λ的值越大,长期趋势序列中的变化总数相对于原序列中的变化减小,即λ越大,分离出的长期趋势序列越平滑。当λ趋于无穷大时,长期趋势序列将接近线性函数。短期波动序列可以通过原时间序列减去长期趋势序列得出,即S=Y-G。
1.2 长短期人工神经网络(LSTM)
循环神经网络(RNN)是神经网络的一种,可以根据时间序列中的前一个观测值来预测下一个时刻的值。RNN一次处理一个时间序列中的观测值,在隐藏层中通过不断调整一个“状态向量”来储存时间序列中的历史信息。虽然RNN的目标是学习时间序列中的历史信息,但是因为RNN使用反向传播算法,会遇到梯度消失问题,所以RNN不适合处理较长的时间序列。长短期人工神经网络(LSTM)是RNN的一种变体,解决了训练过场中遇到的梯度消失问题,因此可以处理较长的时间序列。LSTM相比标准RNN增加了输入门(input gate)、忘记门(forget gate)和输出门(output gate)三个门控单元,LSTM体系结构如图1所示。
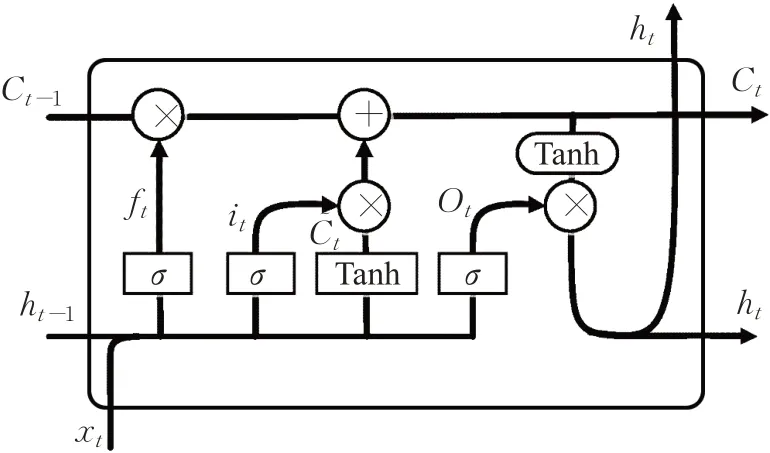
图1 长短期人工神经网络体系结构Fig.1 Structure of Long-Short-Term Memory

其中,xt表示在t时刻的输入向量,W和U表示输入权重向量,b为偏置向量,⊙表示哈达马积(Hadamard product)。函数σ和tanh都为非线性激活函数。激活函数σ通常为Sigmoid函数,所以输出ft在[]0,1之间,表示遗忘前一时刻的Ct-1的概率。Ct由两部分组成,第一部分是,即输入门,第二部分为ft⊙Ct-1,两部分相加来得到Ct。ht由两部分组成,第一部分为ot,它由前一时刻的ht-1和现在的输入向量xt以及Sigmoid函数组成,第二部分由Ct-1和tanh激活函数组成,即
1.3 HP-LSTM模型
股指价格时间序列受到长期经济政策和短期交易行为的影响,并具有高噪声、非平稳、非线性等特点。短期预测更多地依赖短期波动数据,而长期预测应更多地运用长期趋势数据。而且为了在提高模型精度的同时不过度增加模型的复杂度,使模型具有较高的性能和可解释性,本文提出HP-LSTM模型,首先运用HP滤波将股指的开盘价、最高价、最低价、收盘价和交易量等5个指标的时间序列分解为长期趋势子序列和短期波动子序列,然后运用LSTM神经网络模型分别对两个子序列进行预测建模。本文中将用于预测长期趋势序列的LSTM神经网络模型称为LSTM-L,将用于预测短期波动序列的LSTM神经网络模型成为LSTM-S,详细建模步骤如下:
(1)将原始股指数据通过HP滤波进行分解,得到长期趋势序列和短期波动序列。
(2)为了加快神经网络的训练速度,消除不同指标的不同量纲对结果的影响,将上步分解得到的时间序列进行归一化处理。
(3)利用滑动窗口法对数据处理,生成适合输入LSTM神经网络模型的数据集,并将生成的数据集划分为训练集、验证集和测试集,在训练集中训练模型,验证集中调整参数。
(4)将测试集中的长期趋势序列和短期波动序列分别输入训练好的LSTM-L和LSTM-S中进行预测,得到两个序列的预测结果。
(5)将步骤(4)中得到的两个序列的预测结果进行反归一化处理,然后叠加得到最终预测结果。模型结构如图2所示。
2 实验分析
2.1 实验环境
本次研究在Windows10x64操作系统下进行,使用的Python版本为3.7,模型搭建在支持GPU的Tensor-Flow框架下完成,TensorFlow版本为2.3.1。CPU为Intel®CoreTMi5-7300HQ,GPU为NVIDIA GeForce GTX 1050,内存为8 GB。
2.2 数据来源
本文使用的数据来自CSMAR数据库,采用上证综指、深证成指和沪深300三个股指数据,时间跨度为2009年1月1日至2019年12月31日,选取每日开盘价、最高价、最低价、收盘价和交易量5个特征,每种股指共拥有2 675条有效数据。
2.3 HP滤波分解及数据归一化处理
运用HP滤波之前必须选取一个合适的平滑参数λ,不同的平滑参数决定了不同的长期趋势和短期波动,根据此前相关研究[26-28],本文中将λ值设定为100。为了加快神经网络的训练速度,消除不同指标的不同量纲对结果造成的影响,本文采用线性归一化函数对数据进行归一化:

其中,Pn表示时间序列中第n个,maxPn和minPn分别是时间序列Pn中的最大值和最小值,为了使预测数据仍然具有实际意义,需要对预测数据进行反归一化:
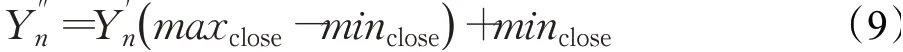
其中,maxclose和minclose分别为收盘价中的最大值和最小值为第n个预测值为第n个反归一化后的预测值。图3为对选取的深证成指每个指标归一化后进行HP滤波分解的结果。
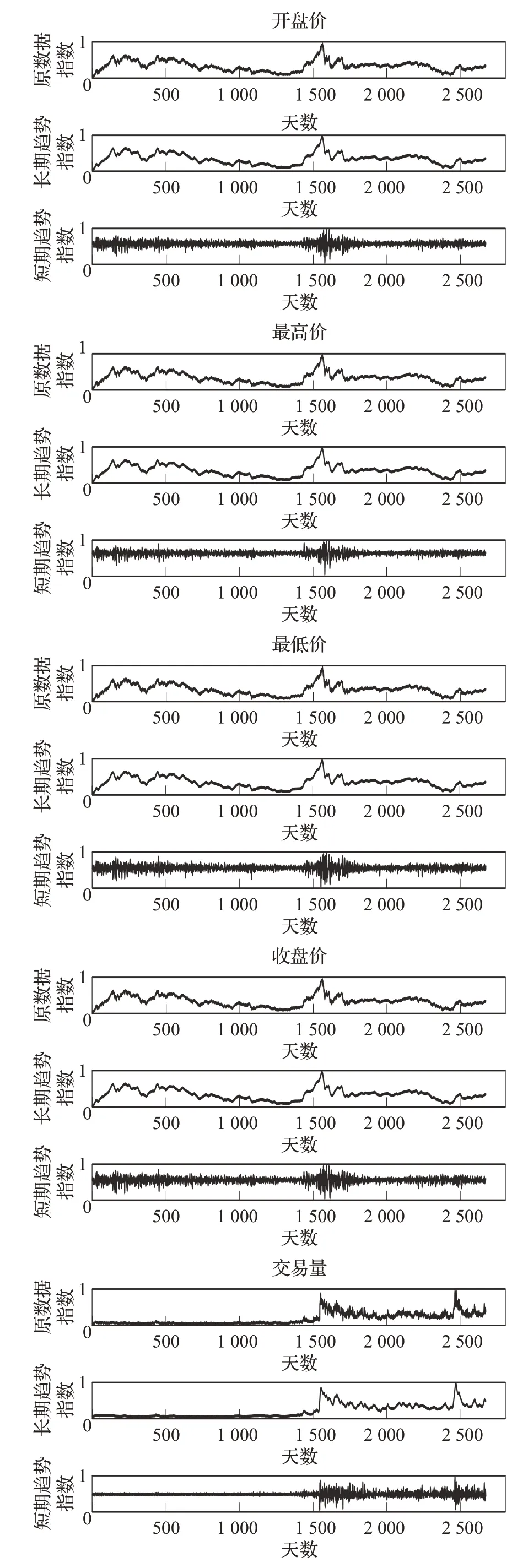
图3 HP滤波分解结果Fig.3 Decomposition result of HP filter
2.4 衡量指标
为了评价模型预测效果,本文选取均方根误差(Root Mean Square Error,RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)和R2score(R2决定系数)作为评价指标。RMSE、MAPE和R2score的计算公式如下所示:
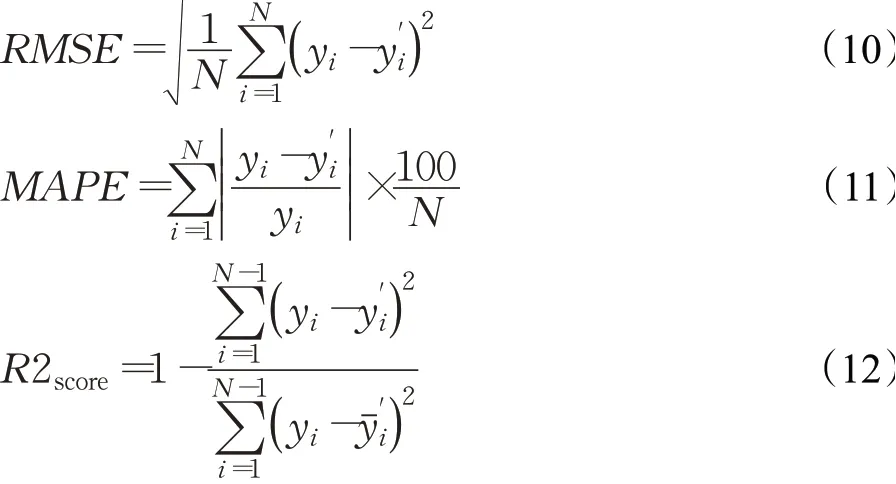
其中,N为预测样本个数,yi和分别表示真实值和预测值为预测值的平均值。其中RMSE和MAPE越小说明模型的预测效果越好,R2score的取值在0到1之间,越接近1说明模型的拟合效果越好。
2.5 模型参数选择
神经网络模型由输入层、LSTM层、一层全连接层和输出层组成。本文由前10天的数据预测第11天的收盘价,所以设置LSTM层的时间步长为10,LSTM层使用的激活函数为tanh函数,全连接层使用的激活函数为线性激活函数,批尺寸(batchsize)设置为32,使用的目标优化函数为均方误差(Mean Square Error,MSE),使用的优化器为亚当优化器(Adam)。通过网格搜索法,神经网络层数从1层到4层间隔为1依次递增,每层神经元个数从1到200,间隔为5依此递增,每种结构运行50次得到验证误差平均数,最终确认的LSTM-L和LSTM-S的详细超参数如表1所示。因为HP滤波分解得到的长期趋势序列和短期波动序列具有不同的特征,而LSTM-S预测的是短期波动序列,相比长期趋势序列波动频率更大,结构更加复杂,神经网络层数或者每层的神经元个数过多都将会导致过拟合,导致在验证集中的误差增大,因此LSTM-S的层数和每层神经元个数均少于LSTM-L。其中LSTM-L和LSTM-S的训练误差和验证误差如图4所示,临近训练结束时模型LSTM-L和LSTM-S的训练误差和验证误差都非常接近,说明模型没有过拟合或欠拟合。
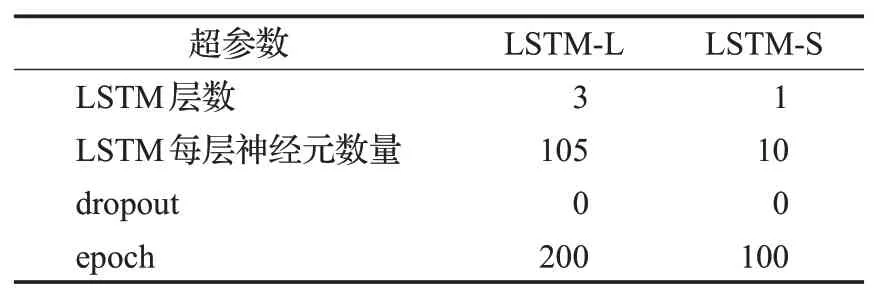
表1 模型参数Table 1 Model parameter
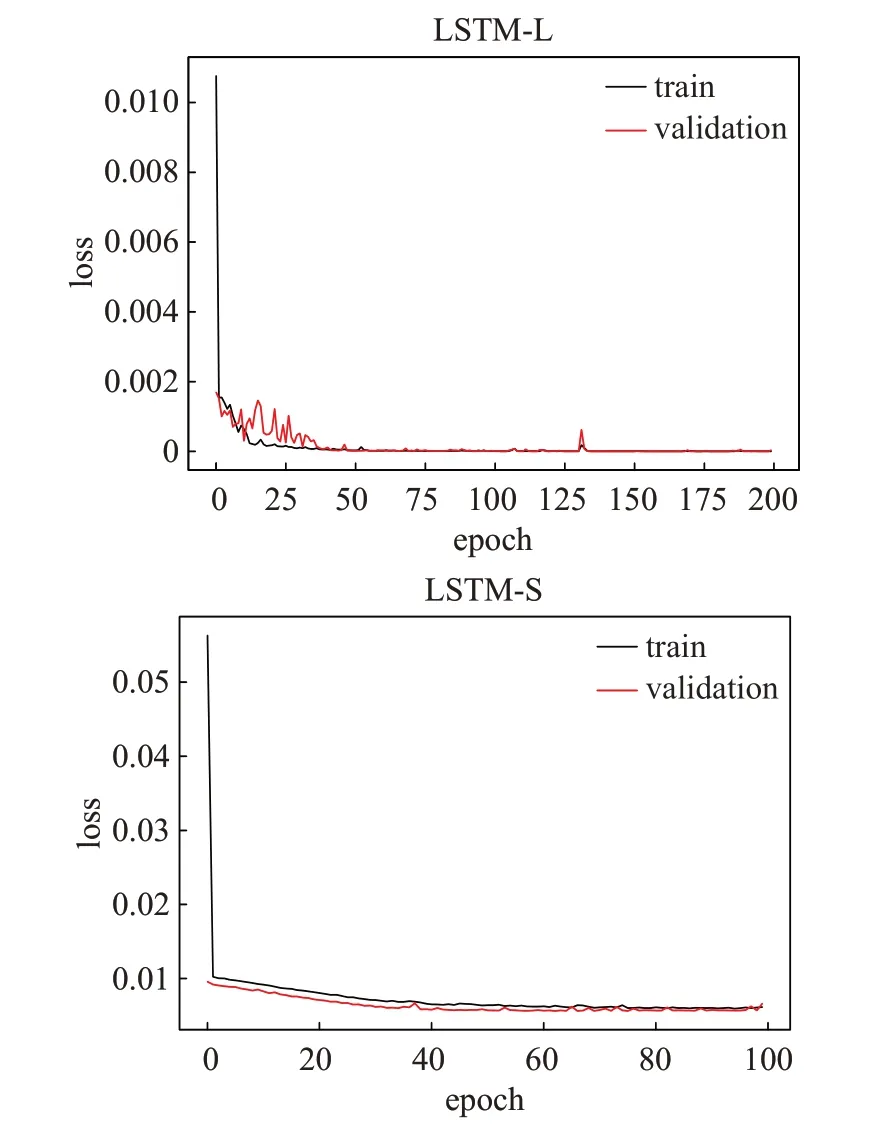
图4 模型的训练误差和验证误差Fig.4 Training error and validation error of model
2.6 实证结果
2.6.1 单一模型预测效果分析
本文将HP滤波分解和归一化后的数据按照3∶1∶1的比例划分为训练集、验证集和测试集,使用2.4节提出的指标衡量模型的预测精度,并与LSTM、RNN、GRU等基准模型进行对比。同时为便于之后与只适合输入一种特征的混合模型比较,在本小节中也测试了仅将收盘价作为输入特征情况下的模型精度。
在深证成指数据的实验中,从表2中得出,输入开盘价、最高价、最低价、收盘价、交易量等5个特征的情况下,模型的预测效果从差到好依次为RNN、LSTM、GRU、HP-LSTM。HP-LSTM模型在测试集得到的三个指 标 的RMSE、MAPE和R2score分 别 为101.214 8、0.836 3%、0.992 6,均优于单一的LSTM、GRU和RNN。相比次优的GRU模型,LSTM模型结合了HP滤波后,RMSE减少了28.31%,MAPE减少了26.31%,R2score从0.986 2提高至0.992 6。在仅将收盘价作为输入特征的情况下,HP-LSTM模型预测精度相比基准模型也有显著提升。因为在两种不同的输入特征的情况下,各个模型的预测精度大致相同,因此图5中只显示了输入特征为开盘价、最高价、最低价、收盘价、交易量的预测结果,可以观察到,单一的LSTM、GRU和RNN模型相比HP-LSTM模型存在明显的滞后。
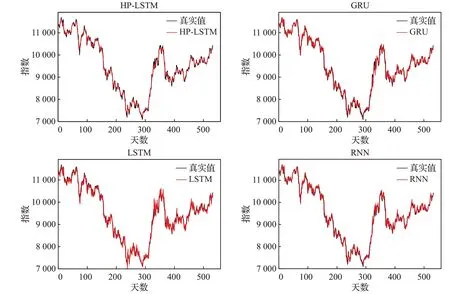
图5 预测结果Fig.5 Results of prediction

表2 HP-LSTM及基准模型测试误差Table 2 Test error of HP-LSTM and benchmark model
2.6.2 混合模型预测效果分析
因为大部分混合模型的预测性能相比单一模型均有一定提升,且本文提出的HP-LSTM模型为混合模型,为使实验结果更具可比性,因此将HP-LSTM模型与其他基于HP滤波的混合模型进行比较。经查阅文献可知[25-26],部分研究使用机器学习模型预测HP滤波分解出的其中一个子序列,使用计量模型预测另一子序列,且预测精度较高。因此将HP-LSTM-ARIMA、HP-ARIMA-GARCH-LSTM作为基准模型,输入特征为每日收盘价。
由表3可知,在混合模型对比实验中,混合模型预测精度由低到高分别为HP-LSTM-ARIMA-GARCH、HP-ARIMA-LSTM、HP-LSTM,并且所有混合模型的预测性能均比单一模型有显著提升。因此HP滤波将时间序列分解为长期趋势和短期波动,使LSTM神经网络模型捕捉到了股指价格时间序列的长期趋势特征和短期波动特征,有助于提高模型整体的预测能力。

表3 HP-LSTM及其他混合模型测试误差Table 3 Test error of HP-LSTM and other hybrid models
3 稳健性分析
为进一步验证本文提出的模型的准确性和稳定性,将使用HP-LSTM和基准模型预测上证综指和沪深300,然后通过每个模型的预测结果,得到测试误差,最后从实验得到的测试误差结果证明HP-LSTM优于基准模型。
数据集的时间跨度为2009年1月1日至2019年12月31日,剔除节假日后共有2 675条有效数据。由图6可知,三个股票走势相似,进行归一化后将消除量纲影响,所以在对上证综指和沪深300的预测当中继续使用表1中的超参数。因为在输入特征不同的情况下HPLSTM的预测效果大致相同,因此图7中只显示了输入特征为开盘价、最高价、最低价、收盘价、交易量时HPLSTM模型的预测结果。
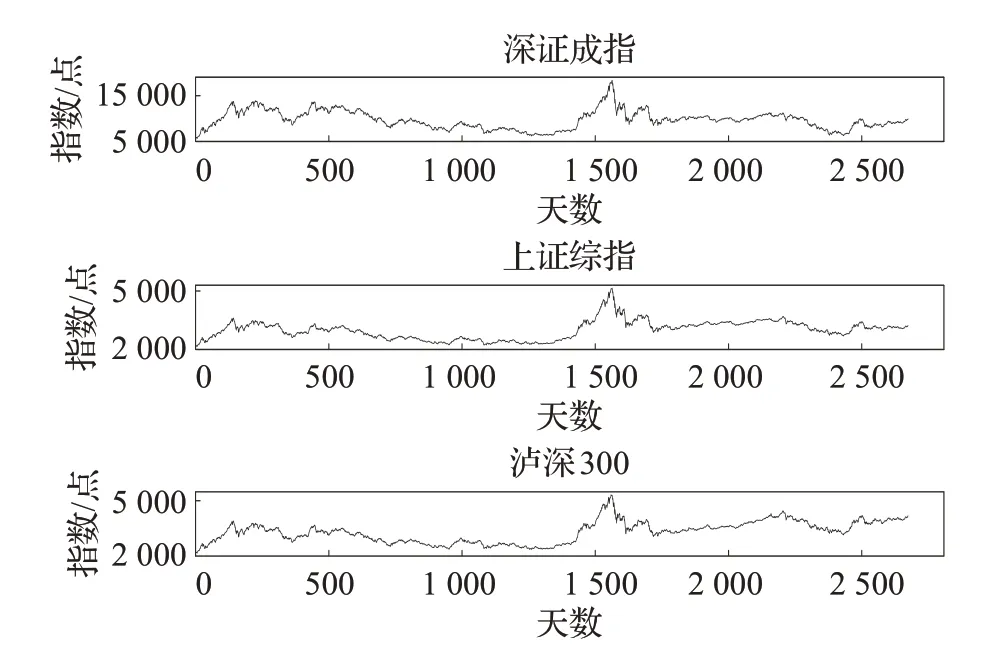
图6 股指价格时间序列Fig.6 Time series of stock index price

图7 上证综指和沪深300预测结果Fig.7 Forecast results of Shanghai Composite Index and CSI 300
在表4中可以发现,在两种不同的输入特征情况下,HP-LSTM模型在使用上证综指和沪深300数据集上都优于基准模型,并且对上证综指的预测效果略好于沪深300。当输入特征为开盘价、最高价、最低价、收盘价、交易量时,在上证综指数据集中,HP-LSTM模型的测试误差最小值相比次优模型,RMSE降低了27.30%,MAPE降低了24.04%,R2score由0.982 0提升至0.990 5。在沪深300数据集中,测试误差相比次优模型,RMSE降低了26.84%,MAPE降低了23.33%,R2score从0.980 1提升至0.989 3,预测精度明显提升。当输入特征为收盘价时,在上证综指和沪深300数据集中所有混合模型的测试误差均低于单一模型,并且HP-LSTM模型的测试误差始终最低。因为均方根误差(RMSE)表示预测值和真实值之间的差异,量纲与原数据的量纲相同,在平均绝对百分误差(MAPE)和R2score相差不大的情况下,如果原数据量纲不同,均方误差将会相差较大,所以在对上证综指和沪深300的预测中的评价指标RMSE远低于深证成指。
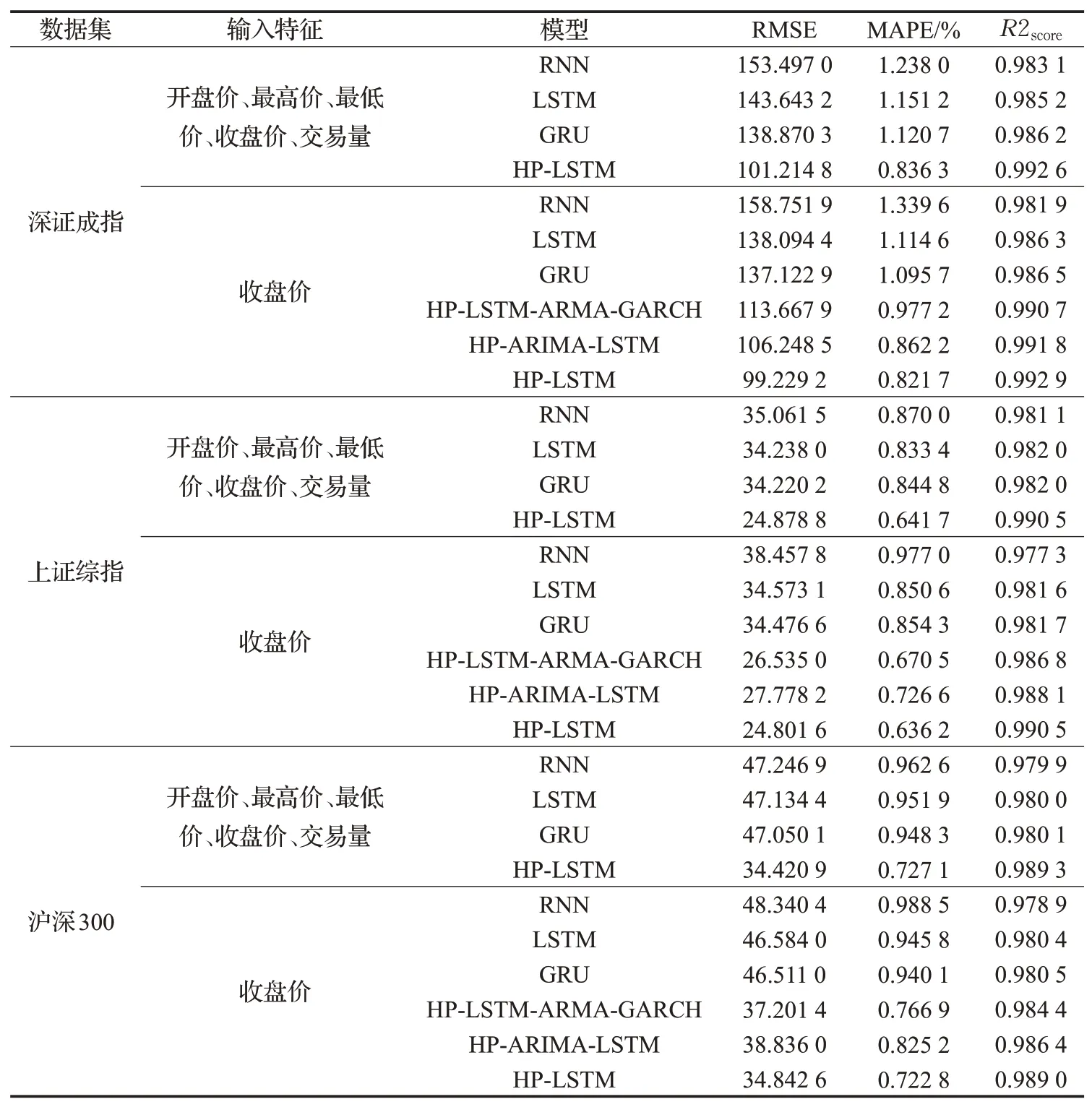
表4 HP-LSTM及基准模型测试误差Table 4 Test error of HP-LSTM benchmark model
4 结论
为了提高股指价格预测精度,本文提出一种基于HP滤波分解的LSTM神经网络模型预测股指价格走势。模型首先利用HP滤波将进行归一化处理后的股指数据分解为长期趋势和短期波动两个序列,然后使用LSTM神经网络模型分别对长期分量和短期分量进行预测,最后将两个序列相加并反归一化得到预测值,预测精度相比基准模型显著提高。经实验分析,得出HPLSTM模型具有以下特点:
(1)股指价格走势反应了不同频率的交易模型,HP滤波作为一种经济分析工具,将时间序列分解为不同频率成分的叠加,使HP-LSTM模型继承了HP滤波的分解功能。
(2)HP滤波是由Hodrick和Prescott提出的一种研究经济运行的一种滤波方法,它将经济运行看作长期趋势和短期波动的叠加,因此HP-LSTM模型的预测结果更加具有可解释性。
(3)融合了LSTM神经网络模型处理高噪声、非平稳和非线性的优良性能,对HP滤波分解出的长期趋势和短期波动序列进行预测均取得了较高的精度。
(4)在不同的数据集上,HP-LSTM的测试误差均优于基准模型,说明HP-LSTM模型的预测精度和稳定性均得到较大提升。
虽然本文提出的模型取得了不错的效果,因为本文没有考虑技术指标和投资心理等因素,所以在实际运用中可以考虑纳入这些指标,股指价格的预测精度可能进一步提高。本文的研究结果有助于有关部门进行风险预警,同时为股指价格预测研究提供了新的思路。
