基于多元特征的立体图像质量评价方法
2021-12-20史玉华迟兆鑫
史玉华,张 闯,2,迟兆鑫
(1.南京信息工程大学 电子与信息工程学院,南京 210044;2.江苏省气象探测与信息处理重点实验室,南京 210044)
0 概述
立体图像质量越高,人们从中获得信息越丰富,视觉体验也越舒适。在立体图像成像及处理过程中,由于经过采集、编码、压缩、传输、存储、显示等步骤,图像失真或者质量下降都是难以避免的,因此必须使用立体图像质量评价(Stereoscopic Image Quality Assessment,SIQA)方法来衡量立体图像的质量。SIQA 结果也是图像采集、传输、还原的一个标尺。
SIQA 分为主观SIQA 和客观SIQA 两类。主观SIQA 是人们根据主观感受给图像打分,其过程复杂耗时。因此,主观SIQA 很难应用于实际工作中。客观SIQA 是根据图像统计信息来评价,其应用广泛,分为全参考(Full Reference,FR)、半参考(Reduced Reference,RR)和无参考(No Reference,NR)。FR-SIQA 以原始图像作为对照,评估失真图像质量;RR-SIQA 只需要原始图像的部分信息;NR-SIQA 不需要原始图像的信息,相比FR-SIQA 和RR-SIQA,其具有更广的应用前景。
SIQA 的研究重点是构建符合人类视觉系统的感知模型,实现图像质量的准确预测。由于2D 图像和3D 图像的成像机理不同,并且3D 图像的每个视图不仅会产生单目失真,还存在对称或非对称单目失真,包括双目混淆、深度感知误差、视觉不适等双目失真,因此SIQA 与图像质量评价(Image Quality Assessment,IQA)的本质差异是SIQA 不仅考虑立体图像左右视图的单目失真,还考虑其双目的立体感知特性,如深度、视差等。
文献[1]利用2D IQA 模型的方法研究SIQA。文献[2]提出基于2D IQA 的NR-SIQA,该方法分别计算左视图和右视图的质量,并将2 个质量得分相结合来预测3D 图像的质量得分。文献[3]通过研究多种不同的2D IQA,并将其分别应用于SIQA,再辅以视差信息评价图像质量。由于这些方法未考虑人们视觉特性,对于立体图像质量的预测达不到很好的效果,尤其是引入不对称失真时,评价效果更差。文献[4]提出采用叠加立体图像视差/深度特征算法,对立体图像质量实现了较准确的评价,表明深度是影响人眼立体感知的重要特征。
随着深度学习的发展,文献[5]提出一种传统算法与深度学习算法结合的方法——基于双目自相似性(Binocular Self-similarity,BS)和深层神经网 络(Deep Neural Network,DNN)的NR-SIQA 方法。文献[6]将卷积神经网络(Convolutional Neural Network,CNN)应用于SIQA,利用2 个卷积层、2 个池化层进行特征提取,并在网络最后层引入多层感知机(Multilayer Perceptron,MLP),将学习到的特征进行全连接得到质量分数。文献[7]采用多任务CNN 同时学习图像质量预测和失真类型识别。
基于深度学习的SIQA 方法没有考虑立体图像的深度性和显著性,无法准确反映立体图像的感知质量。本文提出一种基于多元特征的SIQA 方法。通过提取失真图像对的深度显著性特征、对比度特征和亮度系数归一化特征作为CNN 的输入特征进行训练,评价立体图像的质量。
1 基于多元特征的SIQA
1.1 图像特征提取
在IQA 中,人眼注意不到的图像信息属于冗余信息。IQA 方法在对图像进行系统训练过程中剔除一些质量不高的数据以提高方法的有效性[8]。立体图像的颜色、深度、边缘等特征在人眼对图像的理解中具有重要作用,也是IQA 的重要因素。因此,本文模拟人眼视觉特性,提取立体图像的深度显著特征和对比度特征作为网络的输入。
1.2 立体图像深度显著性特征
视觉显著性体现了人眼的关注度,图像中优先被人眼感知的区域称为图像显著性区域。研究表明图像的失真会导致显著图发生变化[9]。图像显著性特点使得图像显著性本身和图像质量息息相关。从心理和物理角度来看,视觉显著性受低层次特征(如颜色、边缘、深度信息)影响[10],低层次特征对显著性信息提取具有一定作用,而传统深度学习方法通常无法很好地学习图像的低层语义特征。因此,本文构建一种基于图像融合的立体图像显著性特征提取模型。深度显著性特征提取流程如图1所示。首先,通过左右视图相减求得视差图,并对视差图进行高斯差分滤波器(Difference of Gaussian,DoG)[11]得到立体图像的深度特征;其次,改进SDSP[12]模型以提取立体图像的颜色、边缘显著;最后,将深度特征图和显著图融合得到最终的立体深度显著图。
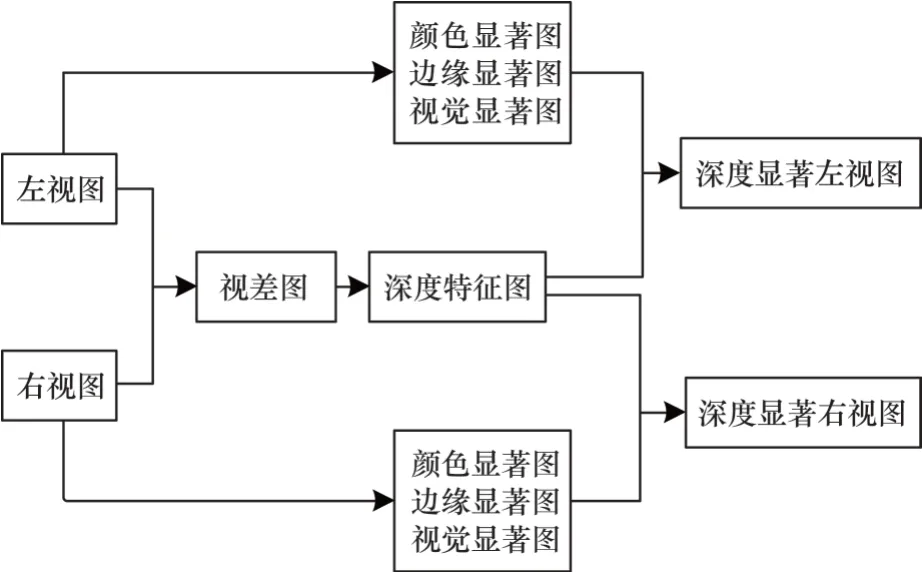
图1 深度显著性特征提取流程Fig.1 Extraction procedure of depth saliency feature
1.2.1 立体图像深度特征
深度信息能有效反映物体的深度变化程度,是立体图像深度感知特征的重要衡量指标[13],深度信息一般通过计算左右视图的视差图来获取[11]。由于DoG[11]滤波器与神经元的接收区相似,并且能够模拟人眼视觉系统(Human Visual System,HVS)的中心环绕机制[14]。DoG 滤波过程如图2 所示。
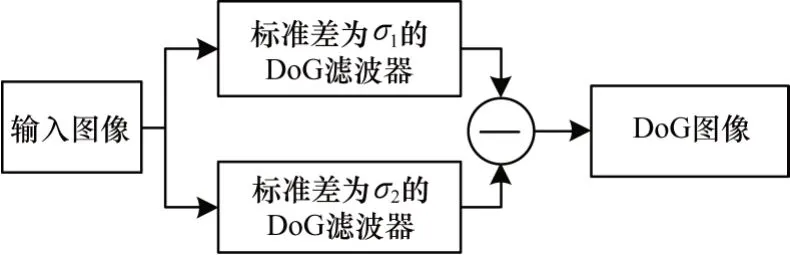
图2 DoG 滤波过程Fig.2 Filtering process of DoG
本文采用DoG 滤波器对视差图进行处理以提取立体图像的轮廓特征和深度边缘特征,具体过程如式(1)所示:
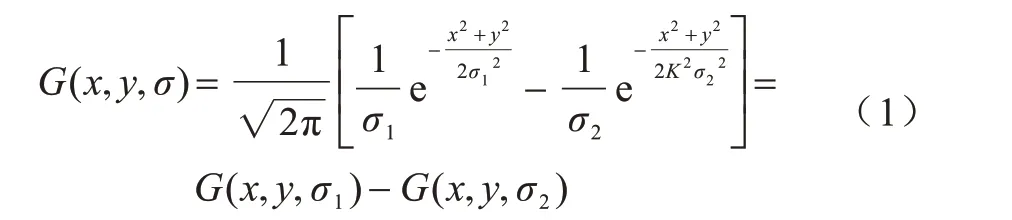
其中:(x,y)为该点像素的坐标;σ为控制滤波器尺度。本文σ1设置为1,σ2设置1.6。
失真图与深度特征图如图3 所示,图像库包含高斯模糊(Gussian Blur,BLUR)、快衰落(Fast Fading,FF)、JP2K(JP2000)、JPEG压缩、白噪声(White Noise,WN)。失真图如图3(a)~图3(e)所示,对应生成的深度特征图如图3(f)~图3(j)所示。从图3 可以看出,利用DoG 滤波器能够更准确地提取出目标的轮廓和边缘纹理特征。

图3 失真图与深度特征图Fig.3 Distortion images and depth feature images
1.2.2 颜色与边缘特征提取
SDSP 模型[12]提取的特征图像只关注图像的中心位置,造成信息损失,但人眼更容易感知边缘位置的变化。本文通过边缘显著取代中心位置显著,改进SDSP 模型。首先,暖色比冷色对人更具吸引力;其次,带通滤波能准确地模拟人类视觉系统在视觉场景中检测到显著物体的特征[12];最后,人眼对于图像边缘的变化敏感。
本文通过提取这3 种图像形成独眼图,作为图像的显著特征图,最终显著图的计算方法如式(2)所示:
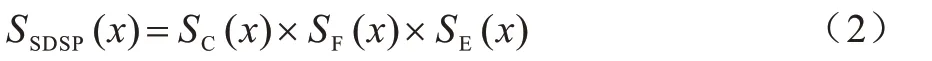
其中:SC为点x处的颜色显著;SF为点x处的显著性;SE为边缘显著。
失真图与颜色、边缘显著图如图4 所示,5 种失真类型下的失真左视图如图4(a)~图4(e)所示,对相应失真图像提取的颜色、边缘显著图如图4(f)~图4(j)所示。从图4 可以看出,该方法能够准确地提取图像的边缘、颜色等视觉显著特征并减少信息损失。

图4 失真图与颜色、边缘显著图Fig.4 Distortion images and color,edge saliency images
1.2.3 图像融合
图像融合具有图像增强、相互补充信息、去除噪声和冗余的优点。图像融合的方法包括基于加权平均的融合方法、基于主成分分析的融合方法、多尺度变换的融合方法和基于小波变换的图像融合方法。
小波变换有水平、垂直和对角三种高频子带,是一种正交变换[15],具有完善的重构能力。小波变换能够将立体图像的深度特征和显著特征融合从而得到立体图像深度显著图。深度显著图如图5 所示,从图5 可以看出,通过融合实现了图像边缘,深度等特征的互补作用。

图5 深度显著图Fig.5 Depth saliency images
1.3 立体图像对比度特征
对比度特征是立体图像的底层特征之一,能够充分表达立体图像的内容,对基于人眼视觉感知的SIQA方法具有积极的作用。立体图像对比度的提取方法是通过自适应找到分割阈值向量以增强立体图像对比度。图像库5 种失真类型中失真图与对比度特征图如图6 所示,在图像失真严重的情况下,对比度特征图能准确反映图像的结构。

图6 失真图与对比度特征图Fig.6 Distortion images and contrast feature images
1.4 亮度系数归一化
如果将左视图或右视图直接作为CNN 输入,导致算法耗时过长,这对处理图片数量较多的情况是不利的。如何在提高算法求解速度和精度的同时保留立体图像结构特征是亟待解决的问题。
文献[16]发现失真程度不同的自然图像经过亮度系数归一化后,其概率密度更符合高斯分布。这种亮度系数归一化后的图像所保留的结构,被证明能够提高IQA 的性能[17]。
MSCN 概率密度分布大致左右对称,符合高斯分布的特点。失真图和提取的亮度系数归一化特征如图7 所示。本文通过亮度系数归一化处理左右视图,相应概率密度分布如图8 所示。MSCN系数由于失真的存在从而改变特征统计特性,量化这些变化可以预测影响图像失真类型及其感知质量。

图7 失真图和亮度系数归一化图Fig.7 Distortion images and brightness coefficient normalization images
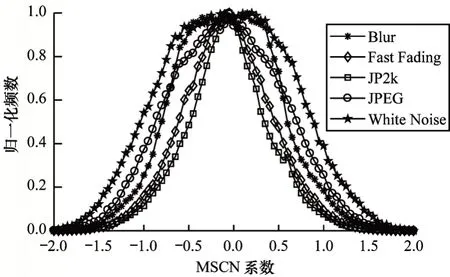
图8 概率密度分布Fig.8 Probability density distribution
2 SIQA 网络结构
CNN 中VGG Net 结构简单且具有较高的有效性,将其应用到SIQA 模型中。VGG-16 有5 段卷积,每段内有2、3 个卷积层,卷积核的大小均为3×3,每段的卷积核数量相同。5 段卷积中的卷积核数量逐次递增:64、128、256、512、512。在第1~4 段内每段卷积后连接1 个池化层,主要是减小图片尺寸,网络最后层有3 个全连接层。
网络中全连接层过多存在参数冗余、深度信息损失多、空间结构性表达不足等问题。针对以上问题,CNN 结构如图9 所示。
本文在已有的VGG-16 网络基础上做了改进:在第5 段卷积结束后,将得到的6 个特征层级联再进行1 次卷积和池化,最后连接1 个全连接层。改进后的网络能够最大程度保留立体图像的深度特征,同时减小内存,提高算法的速度和精度。在网络最后的全连接层中加入dropout 层以防止过拟合现象,丢失率设置为0.5。
目标变量和预测值之间的平方距离之和如式(3)所示:

其中:yi为目标变量的真实值为预测结果。
3 实验与分析
3.1 数据准备
本文采用图像库是德州大学奥斯汀分校和视频工程实验室制作的LIVE 3D Image Quality Database—Phase I[18]/Phase Ⅱ[19]图像库以及由Mobile3DTV和MPEG 提供的NBU-3D 图像库[20]。LIVE 3D 图像库包含5 种失真类型的图像,分别为JP2K、JPEG 压缩、Blur、White Noise、Fast Fading。其中Blur 失真共含45 组图像共90 张,另外4 种失真类型每种含80 组图像,各160 张图像,共730 张图像。NBU-3D立体图像测试库包含12 对原始立体图像和312 对失真立体图像,包含Blur、White Noise、JPEG、JP2K 以 及H.264 编码5 种失真类型,左右图像均为失真程度相同的对称失真,并给出每组失真立体图像的DMOS值。DMOS 值越低代表图像质量越好,反之代表图像质量越差。
LIVE 3D IQA Phase I 图像库JP2K 失真的左视图和右视图如图10 所示,失真程度从左到右递减。

图10 LIVE 3D IQA Phase I 图像库不同DMOS 对应的JP2K 失真图像对Fig.10 JP2K distortion image pairs corresponding to different DMOS on LIVE 3D IQA Phase I image library
3.2 实验过程
本文提出NR-SIQA 方法总体结构如图11 所示。首先设计图像特征提取函数制作数据集,提取了3 种立体图像特征组合成特征图像数据集。由于存在全连接层,因此输入图像的维度必须是固定的,将图像切块为128 像素×128 像素作为输入,图像库提供DMOS 制作为标签。图像库中图片失真为均匀失真,所以每个输入块的质量分数与原图像相同。对CNN进行训练以预测图像的质量分数。最后预测DMOS为一幅图像中所有图像块DMOS 的平均值。为防止过拟合,本文方法将数据集随机分配得到训练集和测试集,数量比例为4∶1。
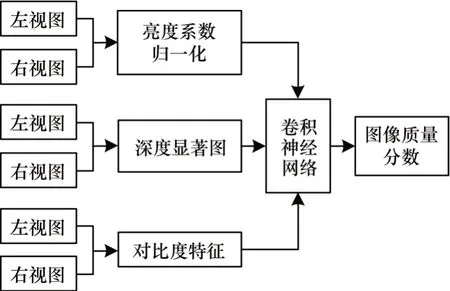
图11 NR-SIQA 方法总体结构Fig.11 Overall structure of NR-SIQA method
本文选取皮尔森线性相关系数(Pearson Linear Correlation Coefficient,PLCC)、斯皮尔曼秩相关系数(Spearman Rank Correlation Coefficient,SROCC)、均方根误差(Root Mean Square Error,RMSE)对模型进行评估[21],其中,PLCC 衡量模型预测的DMOS 和图像库提供的DMOS 之间的相关性;SROCC 衡量两个变量之间的单调相关性;RMSE 用于衡量预测DMOS 和DMOS之间的偏差。PLCC 和SROCC 的值越接近1,表明预测值和真值之间的相关性越高。RMSE 值越低表明预测值和真值差距越小,模型的预测效果越好。
3.3 实验结果与分析
本文图像库的数据以4∶1 分为训练集和测试集。模型训练的意义在于使预测的质量分数尽量向图像库提供的质量分数靠近。在显卡GTX 1050Ti、处理器i5 的电脑上进行实验,批次大小为10,迭代次数为5 000,模型训练时间和测试时间如表1 所示。3 个图像库制作的数据集中随机选取1/5 的图片作为测试集,模型测试图片数和每张图片测试时间如表2 所示。从表2 可以看出,模型测试时间可以达到实时。
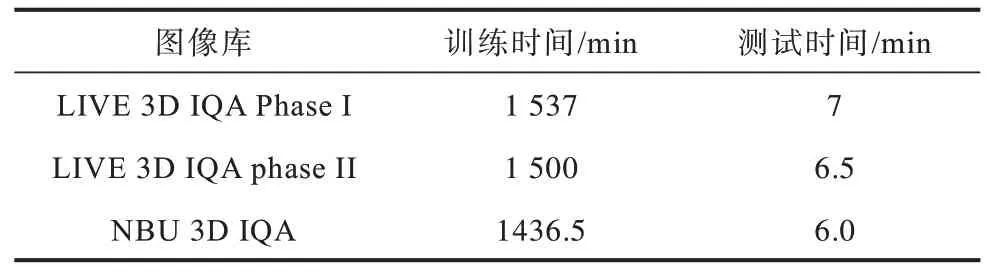
表1 不同图像库模型训练时间和预测时间对比Table 1 Training time and prediction time comparison of model on different images library
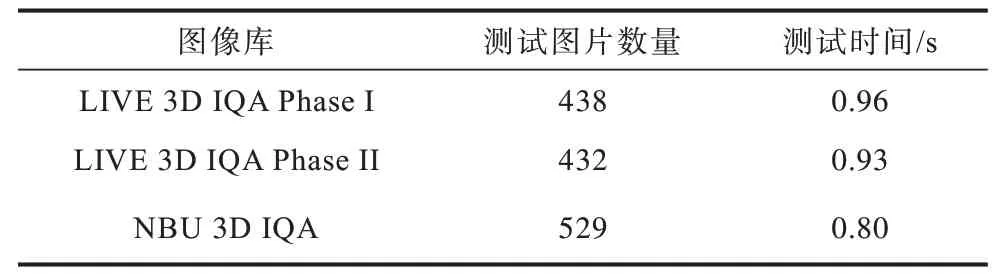
表2 不同图像库模型测试图片数量和每张图片测试时间Table 2 Number of test pictures and test time per picture of model on different images library
为了更全面地分析实验结果,LIVE 3D IQA Phase I 中5 种失真类型下预测DMOS 和图像库中DMOS 散点线性拟合如图12 所示。说明本文提出图像质量评价方法无论在总体还是在5 种失真类型下得到的结果都具有较好的主观一致性。
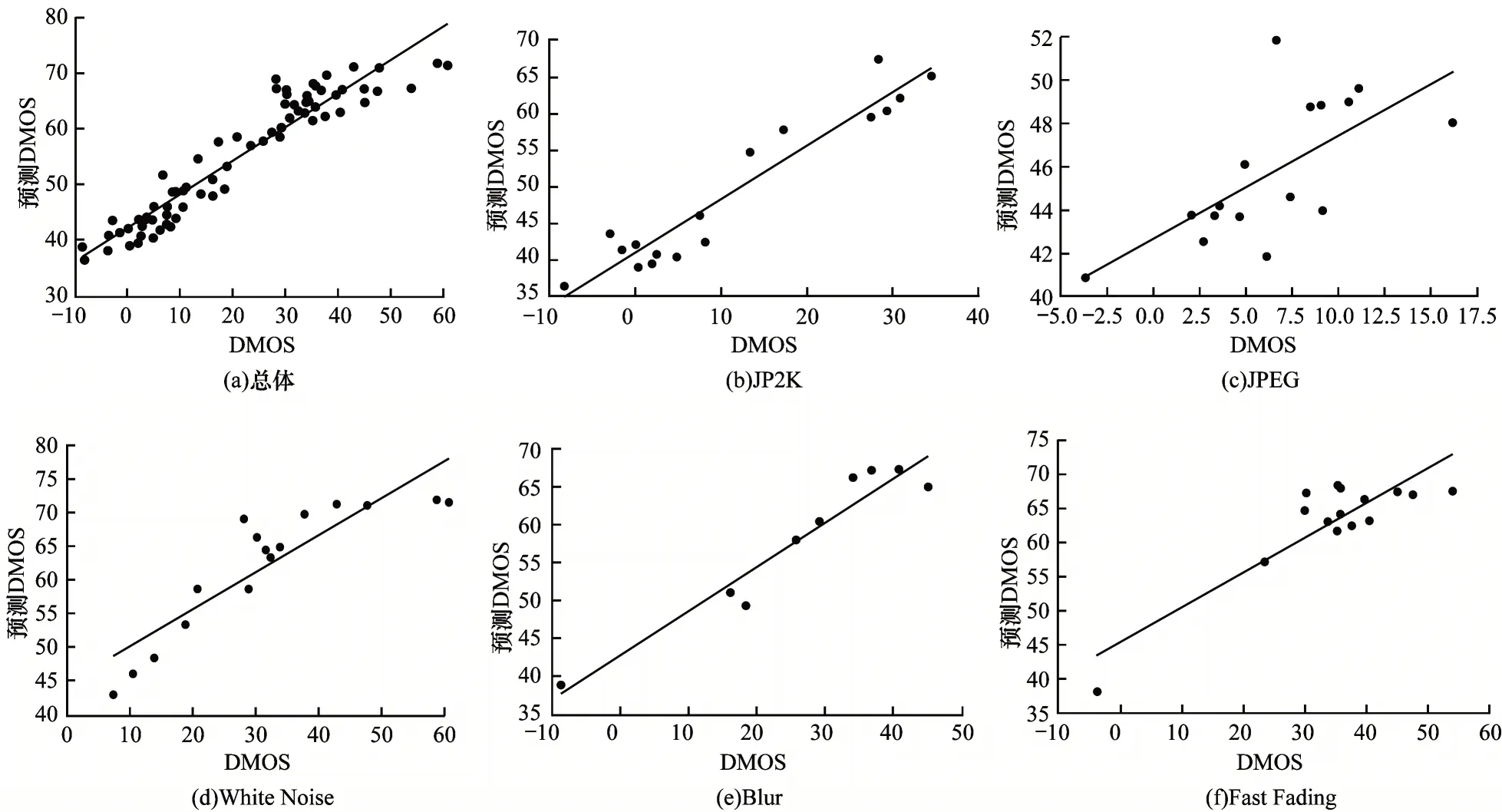
图12 LIVE 3D IQA Phase I 图像库不同失真类型的DMOS 散点线性拟合Fig.12 DMOS scatter linear fitting of different distortion types on LIVE 3D IQA Phase I image library
本文方法在LIVE 3D IQA Phase II 上预测的结果如图13 所示,与LIVE 3D IQA Phase I 相比,LIVE 3D IQA Phase II 包含240 对不对称失真图片。从图13 可以看出,本文方法在LIVE 3D IQA Phase II上取得了较好的预测效果,针对非对称失真图像也能较准确地预测出质量分数。
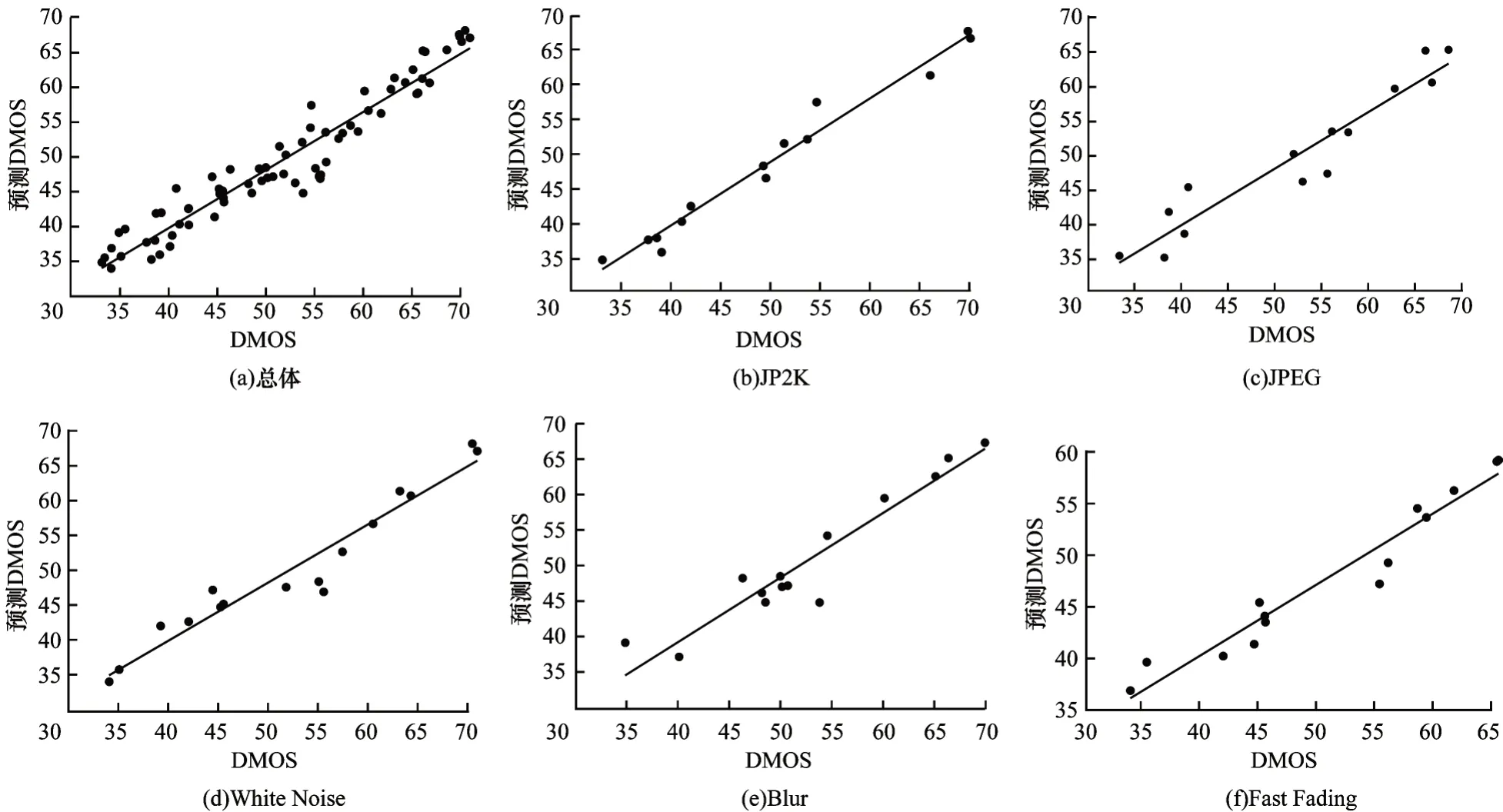
图13 LIVE 3D IQA Phase II 图像库不同失真类型的DMOS 散点线性拟合Fig.13 DMOS scatter linear fitting of different distortion types on LIVE 3D IQA Phase II image library
本文方法在NBU 3D IQA 图像库训练后预测结果如图14 所示。由图14 可以看出,本文方法在NBU 3D IQA 图像库上的预测结果与人类感知具有较高的一致性。
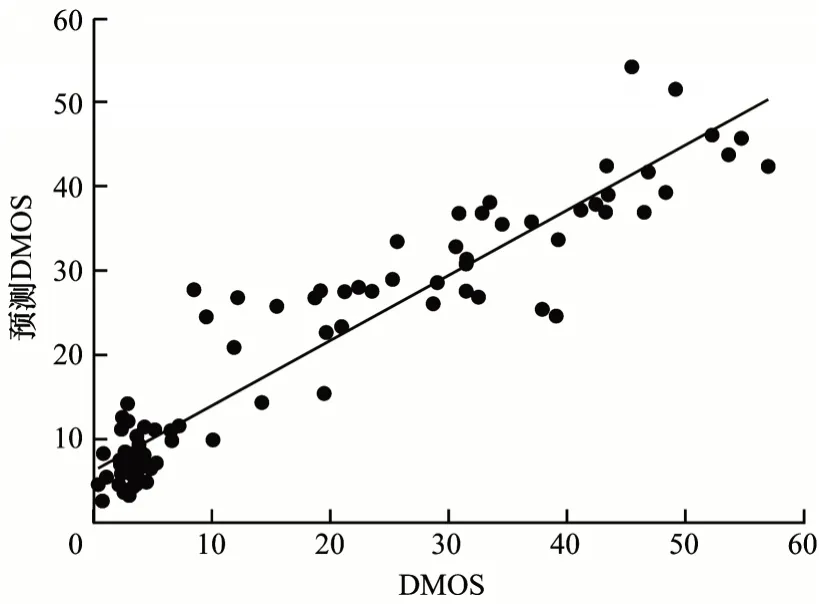
图14 NBU 3D IQA 图像库的测试结果Fig.14 Test results on NBU 3D IQA image library
本文选取13 种有代表性的方法与本文提出的方法进行比较。一类包括7 种FR-SIQA 方法[1,3,22-26];另一类是6 种NR-SIQA 方法[17,19,27-30]。在这6 个NR-SIQA方法[28-30]中,文献[19]是基于深度感知的3D NR-SIQA指标;文献[29]将一组手工制作的自然场景统计特征作为稀疏自编码器的输入,通过softmax回归汇总到其相应的质量得分。文献[30]提出的模型是基于孪生神经网络,以2 个图像块作为输入,对2 个输入图像块之间质量分数进行排序。与其他基于深度学习的SIQA不同,本文方法是从人眼视觉特性和立体图像的感知特征出发,结合深度学习,实现立体图像的多元特征到质量分数的映射。
在LIVE 3D IQA Phase I、LIVE 3D IQA Phase II 和NBU 3D IQA 图像库不同方法的评价指标对比如表3和表4 所示。表中-为原论文没有提供相应的实验结果,也没有找到相应的源代码来重现实验结果。

表3 LIVE 3D IQA Phase I和Phase II图像库不同方法的评价指标对比Table 3 Evaluation indexs comparison among different methods on LIVE 3D IQA Phase I and Phase II image library

表4 NBU 3D IQA 图像库不同方法的评价指标对比Table 4 Evaluation indexs comparison among different methods on NBU 3D IQA image library
从表3 和表4 可以看出,无论是NR-SIQA 还是FR-SIQA,本文方法在3 个图像库均取得了较好的性能,特别是在LIVE 3D IQA phase II 图像库上。本文方法所预测的DMOS 与原始DMOS 具有较好的相关性,进一步证明该方法在SIQA 方面的有效性。
10 种方法在LIVE 3D IQA phaseⅠ和phaseⅡ图像库不同失真类型的评价指标对比如表5 和表6 所示。本文方法在单个失真类型上具有稳定的性能。
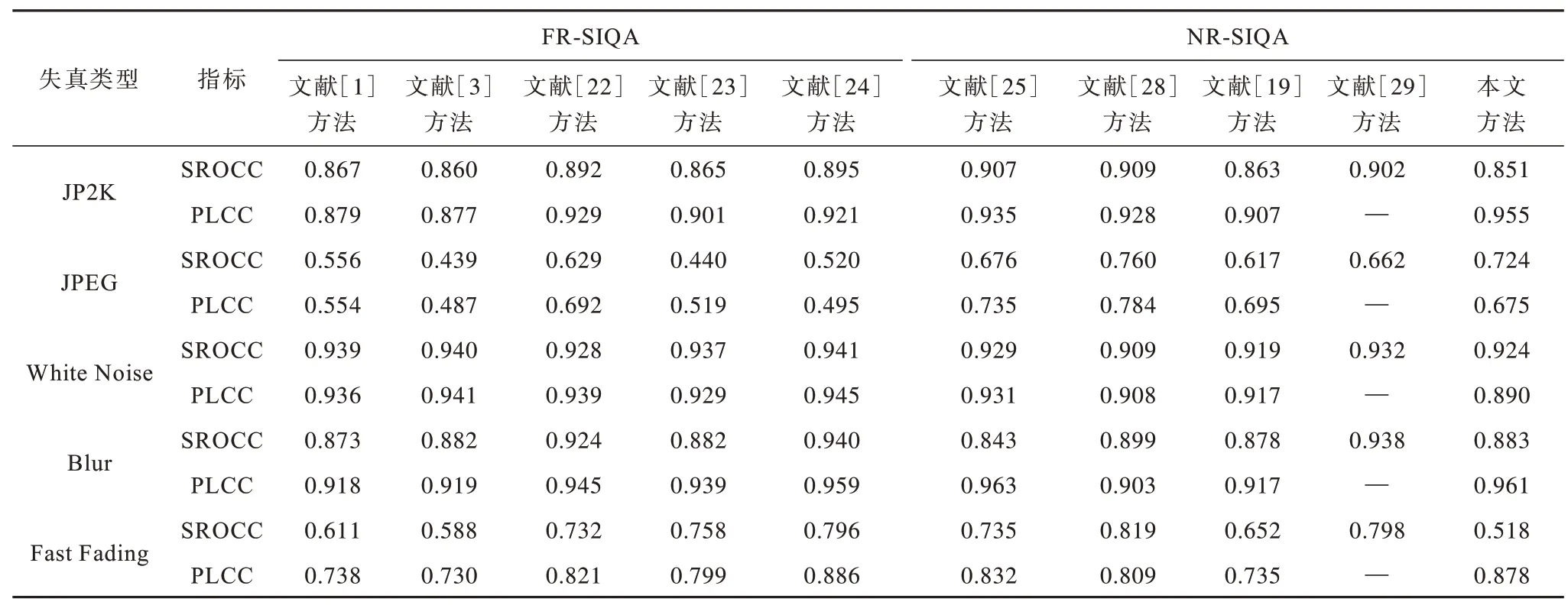
表5 LIVE 3D IQA phase I 图像库不同失真类型的评价指标对比Table 5 Evaluation indexs comparison among different distortion types on LIVE 3D IQA phase I image library
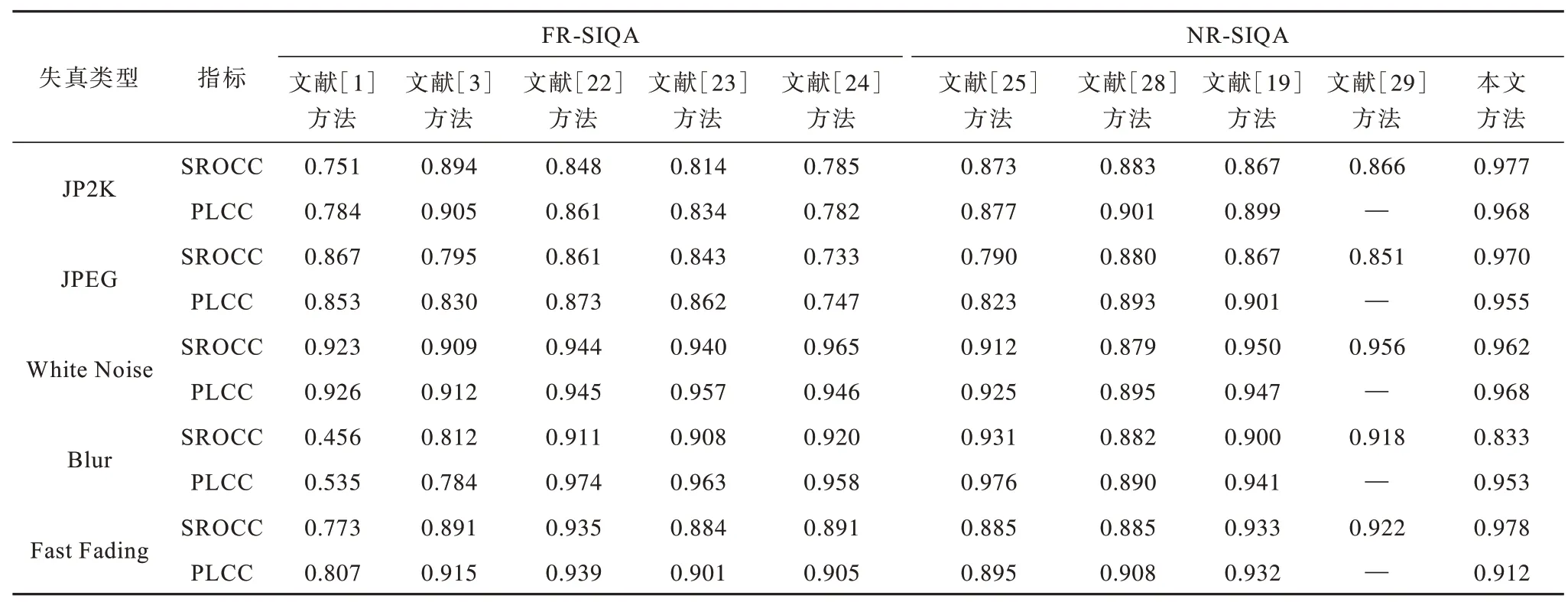
表6 LIVE 3D IQA Phase II 图像库不同失真类型的评价指标对比Table 6 Evaluation indexs comparison among different distortion types on LIVE 3D IQA phase II image library
利用跨数据库测试进一步分析本文方法的性能,LIVE 3D IQA PhaseⅠ作为训练集,LIVE 3D IQA PhaseⅡ和NBU 3D IQA 图像库作为测试集。将测试结果与文献[17]、文献[27]和文献[29]3种IQA指标进行对比。SROCC 的结果如 表7 所示,因NBU 3D IQA 图像库 包含的H.264 编码失真类型在LIVE 3D IQA PhaseⅠ中不存在,所以在NBU 3D IQA 图像库上测试结果不佳。实验结果表明,本文方法具有较好的泛化性和鲁棒性。

表7 跨数据库上不同方法的SROCC 对比Table 7 SROCC comparison among different methods on cross-database
4 结束语
本文根据人眼视觉特性和立体图像特点,提出一种多元立体图像特征与CNN 结合的SIQA 方法。通过提取失真图像对的深度显著性特征、对比度特征和亮度系数归一化后的左右视图作为CNN 输入训练模型,预测立体图像的质量分数。实验结果表明,本文方法能够准确评价对称和不对称失真立体图像,评价结果符合人类主观感知,且具有较好的适用性和鲁棒性。后续将考虑视觉多通道分解性和人眼误差等因素,进一步提高SIQA 的准确性。
