一种用于地震断层图像识别的SPD-UNet 模型
2021-12-20席英杰李克文徐延辉朱剑兵
席英杰,李克文,徐延辉,朱剑兵
(1.中国石油大学(华东)计算机科学与技术学院,山东 青岛 266580;2.中国石化胜利油田分公司物探研究院,山东东营 257022)
0 概述
断层是地下岩层沿一个破裂面或破裂带两侧发生相对位错的现象。地震往往是由断层活动引起的,是断层活动的一种表现,因此地震与断层的关系十分密切。在常规地震剖面上,断层可以通过反射波同相轴错动、分叉、合并、扭曲、形状和数目突变、相邻层位的错动等表象特征进行直接识别。在油气勘探领域,勘探阶段的区域断裂研究对于地质构造、沉积环境解释以及隐蔽性油气田开发具有重要作用。常规的断层解释方法是工作人员在三维地震数据的垂直剖面和水平切片上手动解释断层,通过视觉识别反射层的不连续性来实现断层解释,难度大、周期长、主观性强,在很大程度上依赖于解释人员的经验和相关区域的前期调研。长期以来,学者们围绕提高断层解释的精度和速度进行了大量研究,通过相干体属性[1]、方差体属性、断层切片、边缘增强属性等技术来提取三维地震数据精确描述断层,并为计算机自动识别断层打下了良好的基础。
近年来,随着计算机运算速度的不断提高,深度学习技术在多个领域均取得重大突破。深度学习的概念来源于人工神经网络,神经网络结构可以很好地抓取对象的特征属性,发现数据的隐藏特征,并具有良好的自我学习能力。因此,越来越多的学者开始尝试将深度学习技术应用到地震领域,与地震数据相结合解释地震断层。TINGDAHL 等[2]将深度学习与断层识别相结合用于地震目标检测。HUANG等[3-4]通过引入卷积神经网络(Convolutional Neural Networks,CNN)来识别地震属性检测断层。GUITTON 等[5-7]将CNN 与地震断层属性相结合来检测断层。WU 等[8]利用基于CNN 的像素级图像分割方法检测断层,并获得了显著效果。图像分割技术是计算机视觉领域的重要研究方向且已有许多CNN 模型被用于图像分割任务,例如LONG 等[9]提出的全卷积神经网络(Fully Convolutional Networks,FCN)模型、RONNEBERGER 等[10-12]提出的UNet、SegNet 网络以及残差网络模型,可利用图像分割技术实现地震断层的自动化识别。
本文基于Attention-UNet 神经网络模型和空洞卷积,提出一种用于地震断层图像识别的SPD-UNet模型。基于神经网络的Encoder-Decoder 结构,在Encoder 阶段输入地震断层图像,采用CNN 与SPD模块进行特征提取,在Decoder 阶段进行图像上采样恢复与Skip Connection 操作,完成对地震断层图像的训练与识别,同时引入Focal Loss 函数,解决地震图像的正负样本极度不平衡问题。
1 卷积神经网络模型
1.1 UNet 神经网络模型
UNet 网络是U 对称结构,由一个收缩路径(左边,也称特征提取)和一个扩张路径(右边,也称上采样)组成。收缩路径遵循典型的卷积网络结构,包含4 个Convolutional layer,每层layer 包含2 个3×3 卷积层以及1 个最大池化层。扩张路径包括4 个Upsampling layer,每个layer 与对应的feature map 通过Skip Connection 在通道维度进行拼接,形成更全面的特征信息,再进行下一步处理。
利用收缩路径部分对原始图像进行特征提取,之后采用扩张路径将feature map 恢复到输入图片大小,并恢复每一个像素对应的空间位置。由于经过上采样存在部分信息丢失的问题,通过Skip Connection 将对应的输出层(具有更好的全局信息)与浅层(具有更丰富的局部细节)相结合,从而进行更有效的预测。UNet 模型结构如图1 所示。
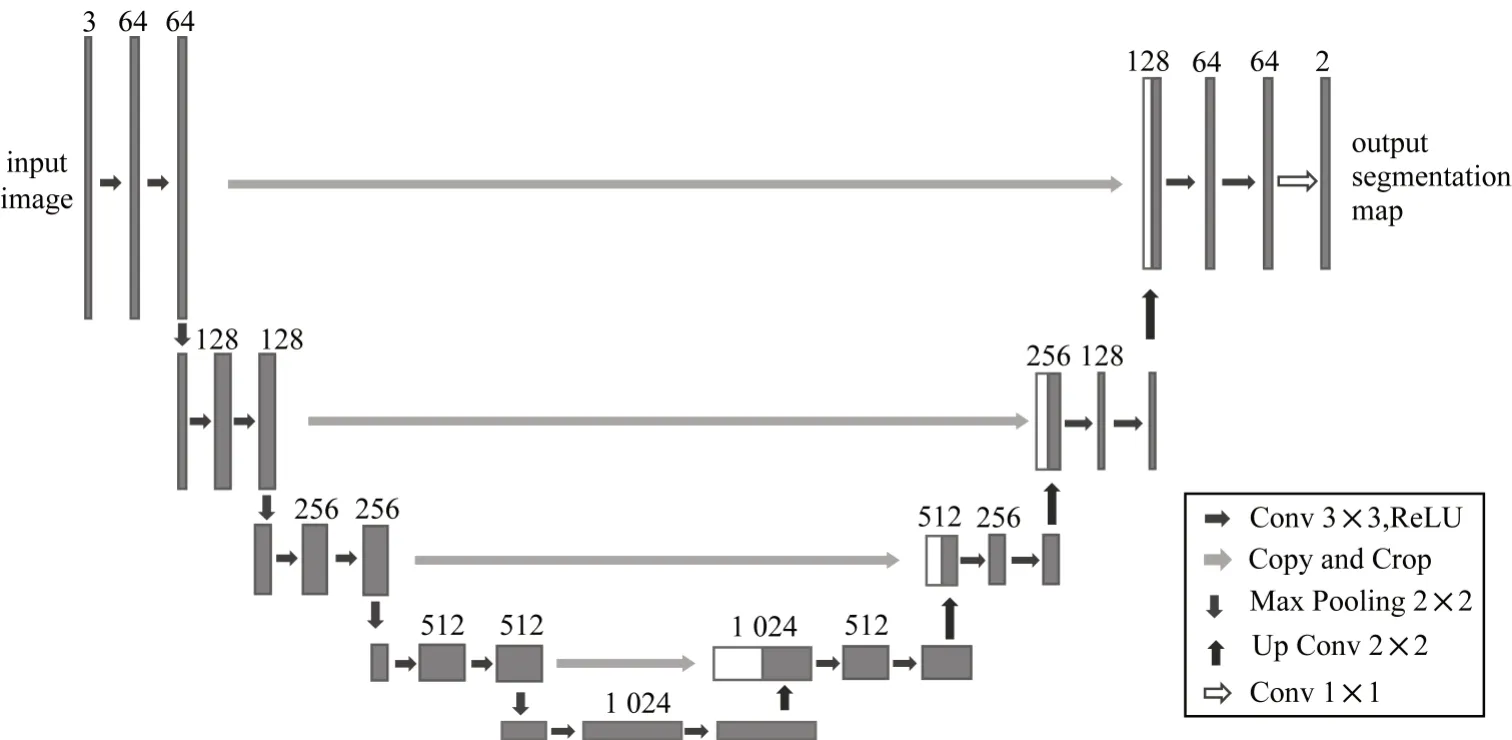
图1 UNet 模型结构Fig.1 Structure of UNet model
1.2 Attention-UNet 神经网络模型
在UNet 的基础上,在每个跳跃链接的末端使用Attention Gate[13]结构(以下简称AG),对需要提取的feature map 实现Attention 机制。Attention 机制是模仿人类注意力提出的一种解决方案,可以从大量信息中筛选出高价值信息,主流Attention 机制有通道注意力[14]、空间注意力[15]以及上下文注意力[16],应用于图像领域时可以抑制不相关背景区域的特征响应,使模型关注更有价值的特征。Attention-UNet 模型结构与UNet 一致,如图2 所示,网络接收输入图像,通过与UNet 类似的卷积和下采样操作进行特征提取,不同之处在于,在Skip Connection 阶段添加了AG 注意力模块,用于提升对断层区域的关注度。在图2 中,Hi、Wi、Di分别代表不同阶段输入输出的高、宽以及通道数,F表示每批次输入的数量。
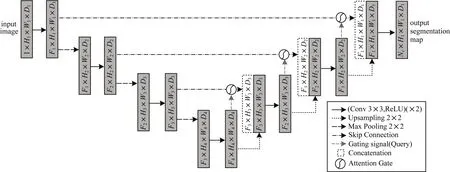
图2 Attention-UNet 模型结构Fig.2 Structure of Attention-UNet model
增加的AG 模块结构如图3 所示。AG 模块接收左侧上一层feature map 和右侧下一层特征,然后拼接右侧上一层得到最后输出。其中,g信号来自右侧下一层的输入,xl信号来自左侧上一层的输入。左侧输入分为两部分:一部分与g信号相加,然后共同进行ReLU 和Sigmoid 激活,得到的结果进行重采样,获得最终输出为xl的注意力系数;另一部分与xl进行相乘,以突出通过Skip Connection 传递的显著特征。

图3 AG 模块结构Fig.3 Structure of AG module
1.3 空洞卷积
在图像分割领域,增大卷积核的感受野十分重要,有利于捕获更大区域的特征信息,在传统神经网络中,一般采用池化操作降低图像尺寸以增大感受野,同时减少计算参数量,但池化存在一定的缺陷,由于降低了输入图像的尺寸,会造成信息的丢失,尤其在地震断层识别中,地震断层属于小目标,在池化操作下极易造成识别不连续,甚至无法重建目标断层。
空洞卷积[17]最初来源于DeepLab 系列v1[18]和v2[19]网络,经过PSPNet[20]、DeepLab v3+[21]等网络的不断完善,具有更大感受野的同时保持原有的权重个数不变,并且可通过空洞卷积的不同空洞率更好地捕获多尺度[22]的上下文信息。空洞卷积示意图如图4 所示。

图4 空洞卷积示意图Fig.4 Schematic diagram of dilated convolution
空洞卷积的实际卷积核计算公式如下:

其中:k为原始卷积核大小;r为空洞卷积的空洞率;K为空洞卷积大小。
2 SPD-UNet 模型
对于地震断层识别,可以将地震剖面切片视为原始输入图片,将断层识别问题视为在断层图片上通过标记断层位置进而识别图像的二分割问题。利用UNet网络并引入Attention机制和空洞卷积来实现图像分割,使得神经网络能进行相应的学习与识别。
SPD-UNet 模型相比UNet 模型在特征提取部分的前3 层结构保持不变,输入图像大小为256 像素×256像素,每层包含2个3×3的卷积层,然后加入Batch Normalization 对数据进行归一化处理,使得数据在进行ReLU 之前不会因为过大而导致网络性能不稳定,ReLU 激活之后接一个2×2 的Max Pooling池化操作,用来增大感受野并且降低参数量。由于断层识别属于小目标识别,为避免图像信息损失过多,在特征提取的后两层,取消池化操作,采用空洞卷积来增大感受野,提高特征提取精度。此外,由于空洞卷积是稀疏的,存在空洞率越大获得的长距离信息关联性越低的问题,会导致输出的结果连续性较差,空间关联性较低,并影响识别精度。为此,在本文模型中将金字塔结构[23]的空洞卷积进行组合,整合成SPD 模块,如图5 所示。SPD 模块共包括4 个卷积,1 个常规3×3 卷积核与3 个空洞卷积,空洞率r分别为2、3 和4。4 个卷积核接收来自上一层的同一个输出,分别与其进行卷积操作后输出同样尺寸的结果。将4 个输出进行sum 后的值作为该layer 最后的输出,SPD 模块使得模型可以同时兼顾小范围和大范围内的特征信息,在具有更大感受野的同时,利用不同空洞率的金字塔卷积组合,避免空洞卷积产生的网格效应。
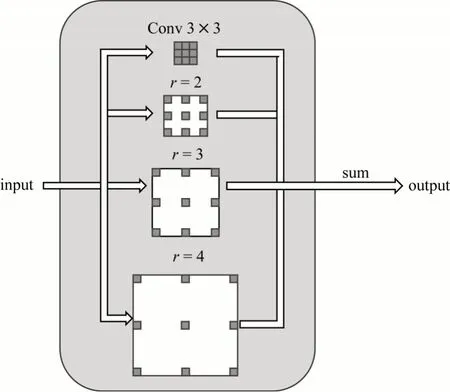
图5 SPD 模块结构Fig.5 Structure of SPD module
在上采样部分,输入部分改进了传统UNet 网络的Skip Connection 部分,加入一个Attention Gate 来添加注意力机制,AG 接收左侧上一层feature map 和右侧下一层特征,然后拼接右侧上一层得到最后输出。右侧包括3 层,每层采用Upsample 进行扩展,然后采用2×2 的卷积及Batch Normalization 层进行归一化,之后进行ReLU 激活,传递到右边上一层。模型采用Sigmoid 函数对最终输出进行处理,使得最终输出图像中每个像素点的值对应于0~1,保证网络模型的输出大小与输入大小一致。SPD-UNet 模型结构如图6 所示。
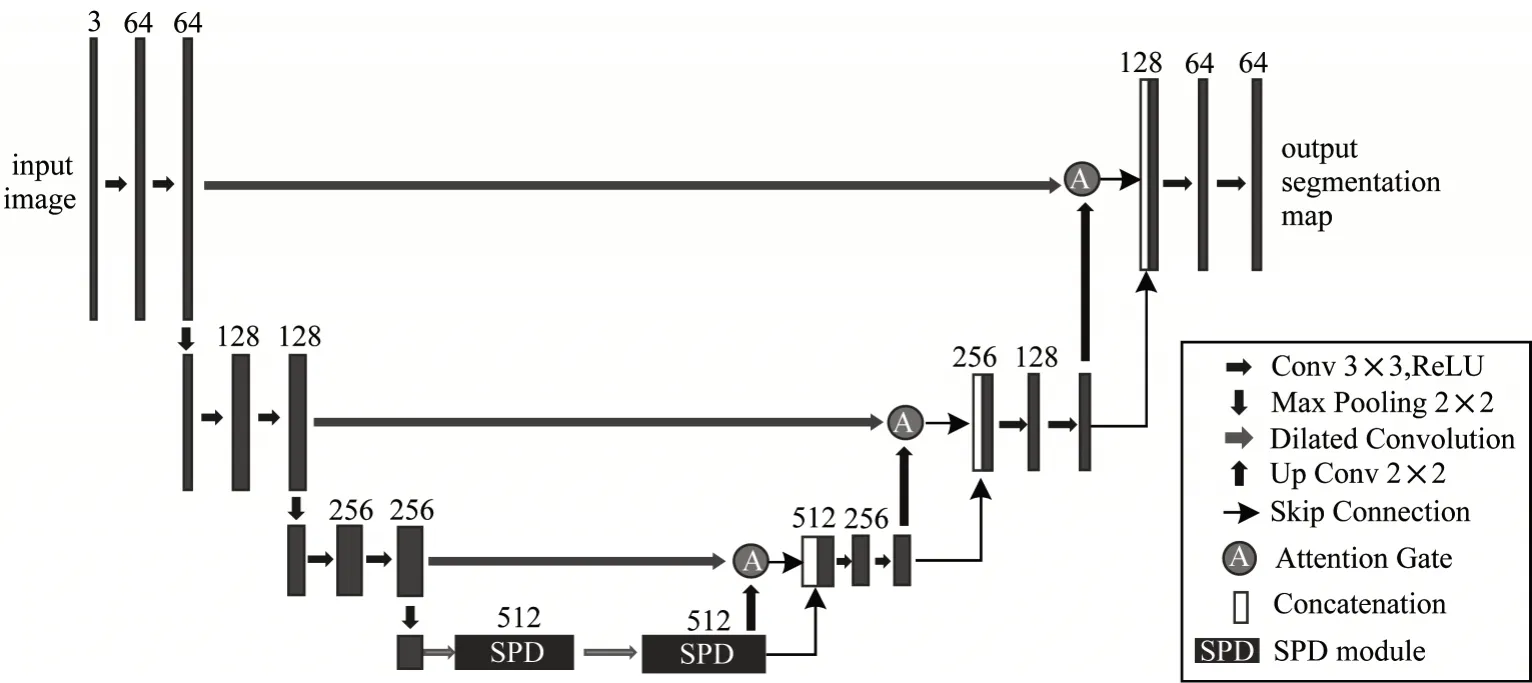
图6 SPD-UNet 模型结构Fig.6 Structure of SPD-UNet model
3 模型训练
模型训练实验选取胜利油田某区块地震断层数据,地震数据为高精度地震采集数据。提取SEGY地震数据体,将SEGY 数据体通过提取识别获得断层区块剖面图集,选取图片进行断层标注组建样本集、训练集与测试集。
在传统的图像分割领域,最常用的二分类损失函数为BCE Loss,但因为地震图像正负样本比例极度不平衡,负样本占比达到90%以上,在神经网络学习的过程中,过多的无用负样本会使得模型整体学习方向发生偏差,产生无效学习,导致预测效果差,识别效果不明显。因此,本文中所有网络模型均采用Focal Loss 作为损失函数。
Focal Loss[24]是在标准交叉熵基础上修改得到的。标准交叉熵是将各个训练样本交叉熵直接求和,即各个样本权重一致,计算公式如下:

为表示简便,用pt表示true class 概率,将式(2)改写为:

通过添加系数α来控制正负样本对总体Loss 的共享权重,α取值较小时可以降低负样本的权重,如式(4)所示:

此外,需要解决控制易分类和难分类样本的权重问题,如式(5)所示:

通过调制系数γ减少易分类样本的权重,使得模型更关注于难分类样本,因此Focal Loss 最终表达式如式(6)所示,既能调整正负样本的权重,又能控制难易分类样本的权重。
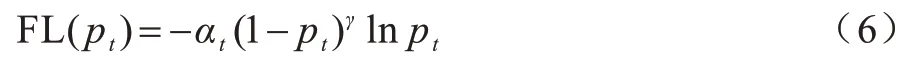
对于Focal Loss 函数,将系数α设置为0.25,参数对比结果如图7 所示,可以看出,当γ取2 时,模型损失函数最小,拟合精度最好,因此选取α=0.25、γ=2来共同调节损失函数。
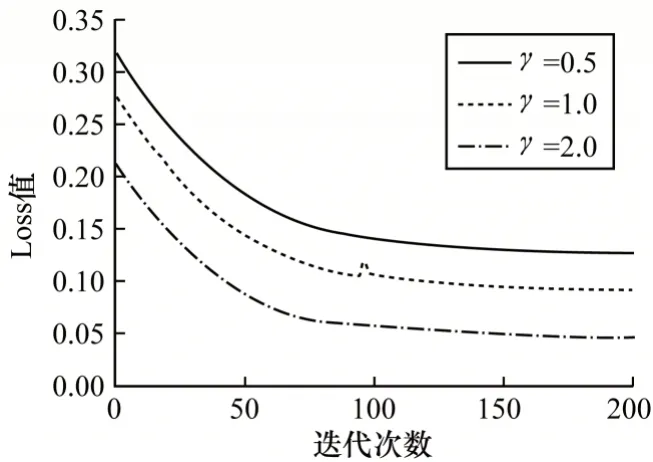
图7 Focal Loss 函数参数对比结果Fig.7 Comparison results of Focal Loss function parameters
深度学习网络有多种训练算法,常用的有随机梯度下降法(SGD)、自适应梯度下降法(Adgrad)、自适应学习率调整法(Adadelta)、自适应动量估计法(Adam)等。本文实验采用收敛速度较快的Adam算法。
4 实验验证
在图像分割领域,最常用的评价指标为交并比(Intersection over Union,IOU)和DICE 系数,本文实验选取这两种指标进行性能评测。
4.1 评价指标
DICE 系数和IOU 是衡量两个集合之间相似性的度量指标,在图像分割领域用来衡量网络分割结果与实际结果间的相似性,数值越大,图像的相似性越高。DICE 系数和IOU 虽然在表达方式上有所差别,但均是关于图像分割精度的指标,计算公式分别如式(7)和式(8)所示。为更好地应用于断层识别任务,将其转换为如式(9)和式(10)所示。
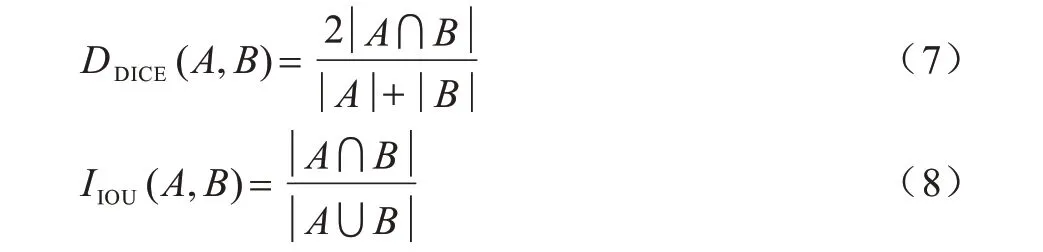
其中:A、B分别表示两个集合,即两张图片的像素集合。
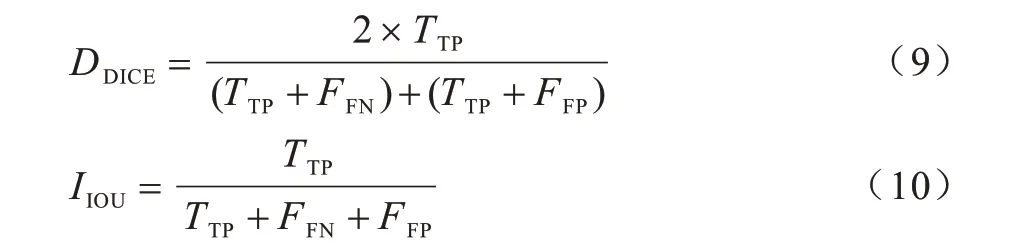
其中:TTP是样本目标和预测目标的交集部分;FFP是将背景误认为断层的部分;FFN是将断层误认为背景的部分。鉴于地震断层图像正负样本极不平衡,实验在进行IOU 及DICE 系数计算时选择去除背景元素的图像。
4.2 实验结果与分析
不同UNet 模型的识别结果如图8 所示,其中,图8(a)表示原始图像,图8(b)表示实际标注,图8(c)表示用UNet 模型进行断层识别的结果,图8(d)表示用Attention-UNet 模型进行断层识别的结果,图8(e)表示加入单层空洞卷积的Attention-UNet 模型进行断层识别的结果,图8(f)表示用本文SPD-UNet 模型进行断层识别的结果。不同UNet 模型在断层图像识别中识别性能比较如表1 所示。从实验结果可以看出:UNet 模型可以识别部分断层,但边缘较为模糊,且识别精度较低,缺失较严重,断层识别连续性较差,在测试集上的DICE 值为0.703 6,IOU 值为0.542 8;加入Attention 机制后,断层识别的连续性和精度均有了明显提升,但整体识别效果仍然不够好,在测试集上的DICE 值为0.769 2,IOU 值为0.625 0;加入单层空洞卷积后结果差别不大,并且单层空洞卷积存在长距离信息残缺问题,导致相比Attention-UNet 模型预测断层的连续性更差一些,在测试集上的DICE 值为0.670 3,IOU 值为0.504 1;本文SPD-UNet 模型较其他模型有较大改善,识别精度明显提升。

表1 4 种UNet 模型在断层图像识别中的识别性能比较Table 1 Comparison of identification performance of four UNet models in fault image identification

图8 4 种UNet 模型的识别结果比较Fig.8 Comparison of identification results of four UNet models
图9 给出了用常见的语义分割领域的神经网络模型进行断层识别,其中,图9(a)表示FCN 模型的识别结果,图9(b)表示基于34 层网络的ResUNet 模型识别结果,图9(c)表示SegNet 模型的识别结果,图9(d)表示本文SPD-UNet 模型的识别结果。不同语义分割模型在断层图像识别中的识别性能比较如表2 所示。从实验结果可以看出,本文SPD-UNet 模型识别效果优于SegNet 与ResUNet 模型,与FCN 模型接近,识别连续性更好,与实际标注的地震断层形状及位置更接近。

图9 4 种语义分割模型的识别结果比较Fig.9 Comparison of identification results of four semantic segmentation models

表2 4 种语义分割模型在断层图像识别中的识别性能比较Table 2 Comparison of identification performance of four semantic segmentation models in fault image identification
综上所述,SPD-UNet 模型在断层识别方面,相比UNet、Attention-UNet 以及单层空洞卷积模型,IOU 值、DICE 系数和参数量指标均获得较大性能提升,得到了更好的识别结果。相比其他语义分割模型,SPD-UNet 模型在测试集上,IOU 值相比SegNet与ResUNet 模型约有0.05 和0.02 的提升,与FCN 模型的IOU 值也较接近,DICE 系数达到0.837 8,IOU值达到0.720 9,说明了SPD-UNet 模型的有效性。SPD-UNet模型的参数量为39.5×106,大于SegNet、ResUNet 以及其他UNet 系列模型的参数量,但IOU也高于上述模型。与此同时,在识别精度略低于FCN 的情况下,参数量略大于FCN 模型的35.9×106,说明SPD-UNet 模型存在优化空间。
5 结束语
本文构建面向断层图像识别的改进SPD-UNet模型,利用神经网络强大的编码和解码能力,通过特征提取与上采样,并引入注意力机制、空洞卷积和Focal Loss 损失函数,增强SPD-UNet 模型的断层图像特征提取能力,在保证感受野大小且不损失分辨率的情况下,更全面地捕捉断层的整体分布信息。同时,利用SPD 模块解决空洞卷积的局部信息丢失问题,提高断层信息关联性及图像识别精度。实验结果表明,应用SPD-UNet 模型进行地震断层识别效果较好。后续将通过优化Encoder-Decoder 结构、Attention 机制以及门控模块进一步提升SPD-UNet模型的地震断层图像识别精度,并利用GAN 网络降低地震断层图像噪声对识别结果的影响。
