基于Adaboost 模型的并发程序数据竞争语句级检测
2021-12-20孙家泽舒新峰
孙家泽,易 刚,舒新峰
(1.西安邮电大学 计算机学院,西安 710121;2.西安邮电大学 陕西省网络数据分析与智能处理重点实验室,西安 710121)
0 概述
随着计算机硬件技术的更新迭代,多核处理器以及众核处理器[1]被广泛应用,越来越多的开发人员使用并发编程来提高程序的性能,提升了程序的运行速度、吞吐量和CPU 利用率。然而,并发程序内部存在并发性和不确定性,这会导致并发程序出现死锁[2]、数据竞争[3]、原子性违背[4]、顺序违背[5]等难以检测和修复的问题。数据竞争往往是引发其他并发问题的根本原因,在所有的并发缺陷问题中占较大比例,也是目前研究最多的一类问题[2]。如何有效地构建多线程数据竞争检测模型、设计或改进数据竞争定位算法以及准确识别多线程程序中的安全故障,是多线程并发程序安全性质量保障亟待解决的问题,其影响到多核处理器在各个领域的普及与应用。
针对数据竞争检测问题,国内外已有较多研究成果。在动态检测方面,Djit+[6]基于发生序关系方法,使用向量时钟对数据竞争进行分析,同时还包括FastTrack[7]、LOFT[8]和基于锁集的检测工具Eraser[9]。在静态检测方面,常用的检测工具有RacerX[5]、LOCKSMITH[10]和RELAY[11]。此外,蔡彦等提出一种基于采样的数据竞争检测方法来降低检测的开销,并开发了检测工具AtexRace[12],孙家泽等提出一种基于随机森林的数据竞争指令级检测方法,并实现了AIRaceTest 检测工具[13]。然而,这些检测方法中仍存在误报、漏报以及开销大等问题。
本文基于数据挖掘分类模型可高效处理大量数据的特点,提出一种以语句对特征作为样本集建立Adaboost[14]分类模型的方法,实现多线程程序数据竞争检测工具ADR。通过对被测程序进行动态插桩取样并对插桩[15]结果进行语句级转化提取语句对特征,以此构建数据竞争Adaboost 检测模型。由于数据竞争最终都可以归结到2 条线程交织[16],因此本文分析来自2 条不同线程的语句对,以简化检测过程。
1 数据竞争语句级检测算法
1.1 传统数据竞争检测
在对被测程序进行动态插桩取样时,需要取出指令的所在线程ID、指令的读写操作op 和指令所访问的内存地址memaddr。根据数据竞争的定义,如果同时满足以下3 个条件,则判定为数据竞争:1)2 条指令或多条指令所在线程ID 不一样;2)2 条指令或多条指令访问的内存地址一致;3)2 条指令或多条指令中至少有1 条指令的读写操作为写操作。但在实际情况下,该判断方法会带来大量的漏报和误报,因为不同线程存在确定先后关系,或者存在一个公共锁以保证针对共享内存空间的访问不会发生数据冲突,在这种情况下会带来大量的误报。
1.2 基于语句对特征的数据竞争检测方法
针对传统数据竞争检测方法误报率高、检测精度低的问题,本文提出一种基于语句对特征的数据竞争检测方法。首先对样本程序集进行插桩,提取出语句对的数据竞争相关属性,然后根据得到的数据集进行模型训练,最后根据得到的分类模型对被测并发程序进行数据竞争检测。本文采用的是集成分类模型。集成分类模型由若干单个分类器组成,相较于单一分类器而言,模型精度会更高。集成分类算法里最常用的是Adaboost 算法和随机森林算法,Adaboost 相较于随机森林而言,其各个弱分类器之间存在迭代关系,模型分类准确率更高。因此,本文先采用Adaboost 算法建立模型,再利用建立好的模型进行数据竞争检测。
本文方法的具体检测过程如下:
1)训练过程
(1)设样本并发程序P 的指令数为inscount,线程数为n,利用插桩工具Pin 对被测并发程序P 进行动态插桩,记录指令的线程为ID tid,指令访问的内存地址为addr,指令的读写操作为op,指令的锁集为lock。
(2)剔除掉无对应原码的指令以及来自同一条语句的指令,每一条语句仅保留一条指令,将指令级的插桩转换成为语句级插桩。
(3)遍历所有的语句对,提取出语句对中的Pm、Po、Pv、Pl、Pr这5 项数据竞争相关属性。
(4)提取特征Pm。语句对a-b的访问地址分别为memaddr_a 和memaddr_b。如 果memaddr_a=memaddr_b,则Pm为1,反之Pm为0。
(5)提取特征Po。取出语句a对内存读写模式op_a,取出语句b对内存的读写模式op_b。如果op_a=op_b,则Po为1,反之Po为0。
(6)提取特征Pv。假设线程总数一定,该值为常量MmaxThreads,每一个线程维护一个向量时钟,表示为stt[.],拥有MmaxThreads条记录。所有线程由[0,MmaxThreads-1]整数来表示。对于每一个索引u,stt[u]记录当线程u与线程t同步时线程u的本地时间。向量时钟的更新过程如下:先将每一个线程的向量时钟本地时间初始化为1:∀t:stt[t]←1,∀u:stu[u]←1。如果线程t释放了同步对象,则stt[t]←stt[ ]t+1,如果线程u获得一个由线程t释放的同步对象,则线程u更新其向量时钟,且每一个向量的值更新为此时线程t和线程u的向量的各个维度上的较大值:fori=0 toMmaxThreads-1:stu[i]←max(stu[i],stt[i])。最 后,根据得到向量时钟进行偏序判断,如果两者之间满足偏序关系,则Pv为1,反之Pv为0。
(7)提取特征Pl。对于共享变量v和读写锁m,每次写访问变量v并持有锁m时,将锁m加入到write_locks_held(t)集合中,每次读访问变量v并持有锁m时,将锁m加入到locks_held(t)集合中。令locks_held(t)为线程t所持有的锁,包括写模式和读模式。令locks_held(u)为线程u所持有的锁,包括写模式和读模式。C(v)=locks_held(t)∩locks_held(u),如果C(v)为空集,则Pl为1,反之Pl为0。
(8)提取特征Pr。根据样本集已知的结果,如果该语句对发生数据竞争则Pr为1,否则为0。
(9)模型训练。以Pm、Po、Pv、Pl为特征属性,以Pr为标签属性,训练Adaboost 模型。
训练过程的算法描述如下:

2)检测过程
(1)提取被测并发线程Pm、Po、Pv、Pl特征属性。
(2)利用训练好的Adaboost 模型对提取得到的属性进行分析,得到检测检测结果Pr。
(3)如果Pr为0,则发生数据竞争,反之,则没发生数据竞争。
检测过程的算法描述如下:

2 Adaboost 模型
本文通过Intel Pin 工具提取出语句对的特征样本数据,并根据该样本数据建立数据竞争Adaboost 检测模型。本节具体描述Adaboost 模型的建立过程。
2.1 数据采集
数据采集过程如下:
1)输入多线程程序,使用Pin 工具进行动态插桩取样。
2)记录程序中该语句所在的线程ID tid。
3)记录程序中该语句所访问的内存地址memaddr。
4)记录程序中该语句所对应的读写操作op。
5)记录程序中该语句的锁集lock。
6)程序中该语句所在线程的向量时钟vectorclock。
7)记录程序中该语句所在的行号。
8)输出多线程程序语句的内存信息。
表1 列出了从多线程程序中随机抽取的5 条案例语句信息,其中:num 表示当前语句的编号;op 表示当前语句对内存进行的操作,‘R’表示读操作,‘W’表示写操作;memaddr 表示当前语句访问的内存地址;line 表示当前语句在被测程序中的所在行号;tid表示当前语句所在的线程ID,其中主线程的tid 为0,子线程thrd1 的tid 为1,thrd2 的tid 为2,thrd3 的tid为3;locks 表示当前指令收到的锁保护情况,其中0表示无任何锁保护;vectorclock 表示当前语句的向量时钟。
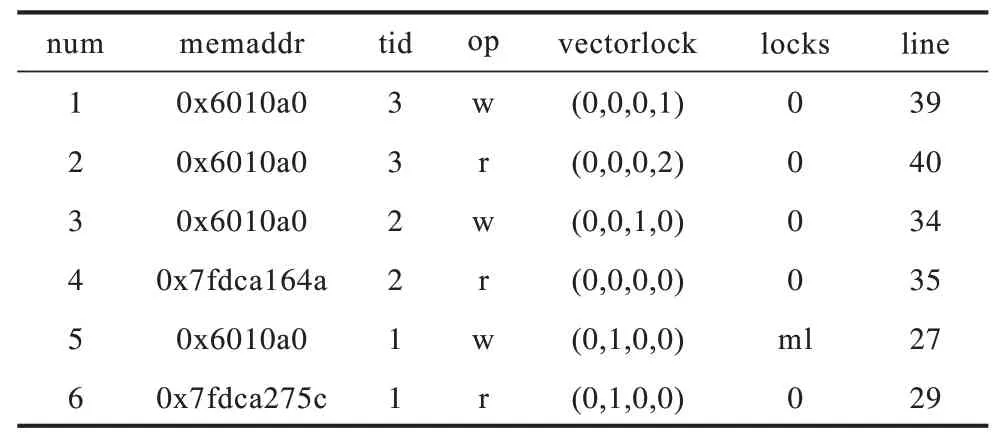
表1 多线程程序语句的内存信息Table 1 Memory information of multithreading statement
对表1 中的数据进行处理,提取出语句对的Pm、Po、Pv、Pl、Pr这5 项特征,如表2 所示。
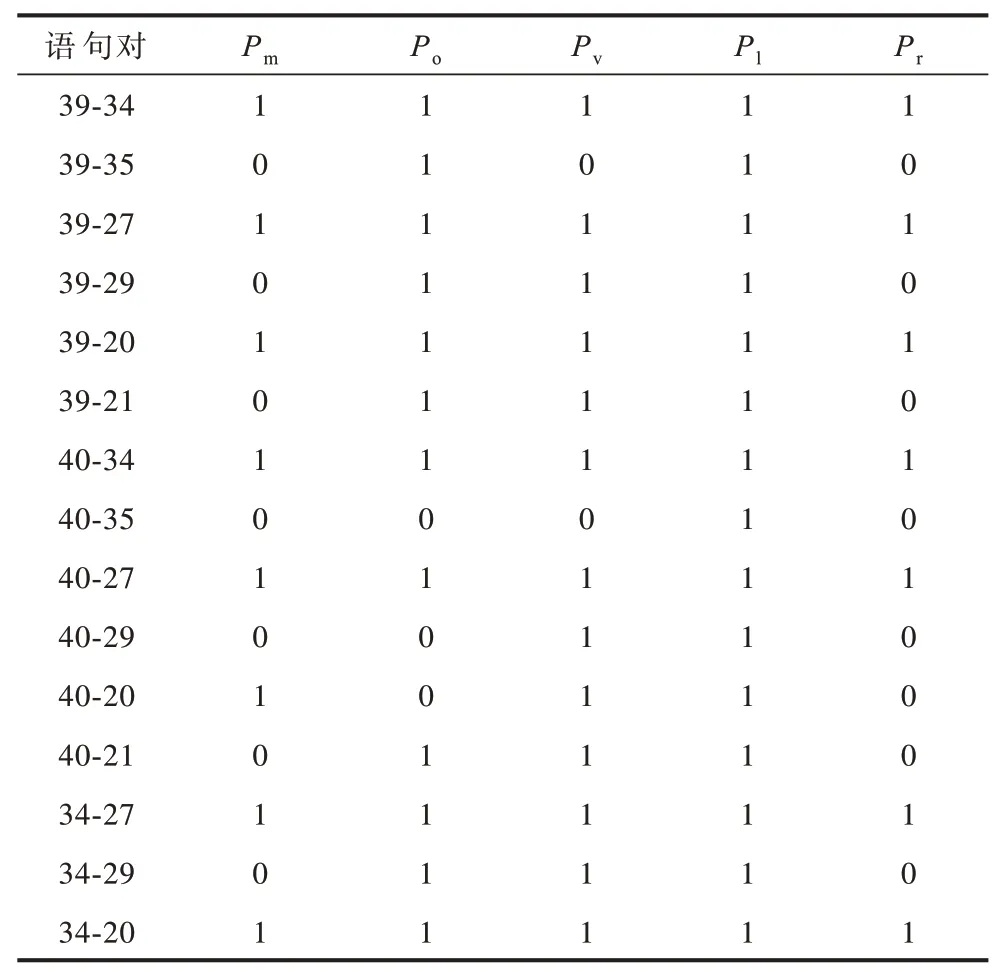
表2 语句对数据数值化特征表Table 2 Eigenvalue table of statement pair
2.2 Adaboost 模型训练
Adaboost[14]算法的设计思想主要是针对同一训练集将其训练成不同的分类器并构建在一起,最终形成一个更强的分类器。Adaboost 算法流程如图1所示。首先,每轮迭代中会在新训练集上产生一个新的学习器。然后,使用该学习器对所有样本进行预测,以评估每个样本的重要性。在每一次迭代时,会给每一个样本赋予一个权重,根据每一次预测的准确性进行动态调整,权重越高的样本会在下一次训练过程中占越大的比重,即准确性低的样本会被着重关注。
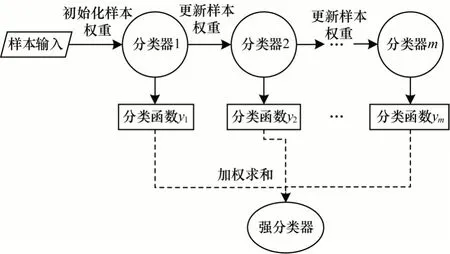
图1 Adaboost 算法流程Fig.1 Procedure of Adaboost algorithm
本文从Github[17]上选取5组多线程程序来训练Adaboost模型,取出的语句对经整合后总数为60 8631。对整理得到的数据进行预处理得到特征数据集TestUnity。在特征数据集TestUnity 上进行Adaboost模型训练时,如果迭代次数n_estimators 设定得较低,必然导致模型精确度降低,但如果n_estimators 设定得较高,也会导致训练模型的开销增大。因此,需要对其设定一个合适的值,使模型的精确度达到要求并且开销最低。同时,如果决策树最大深度max_depth 过大也会出现过拟合现象,影响模型精确度。
图2 显示了不同的决策树深度随着迭代次数的增加,其分类误差率的变化趋势,从中可以看出:当max_depth=10 时,随着迭代次数的增加,模型的分类误差率无明显变换,即泛化能力没有增强,模型处于过拟合状态;当max_depth=1 时,迭代次数逐渐增加时,分类的误差率也逐渐减少,同时其泛化能力也逐渐增强;但是当n_estimators ≥90 时,模型的分类误差率趋于平稳,而当max_depth=2时,其误差率走势与max_depth=1时相似,但其分类误差率相对更低。由于在Adaboost模型中选定的弱学习器的复杂度很低,其决策深度一般设定在1 到2 之间,因此设定最优的max_depth=2,而当n_estimators ≥90 时,由于模型的分类误差率趋于平稳,随着迭代次数继续增加必然导致模型训练的开销也会不断增加,因此,本文设定最优的n_estimators为90。
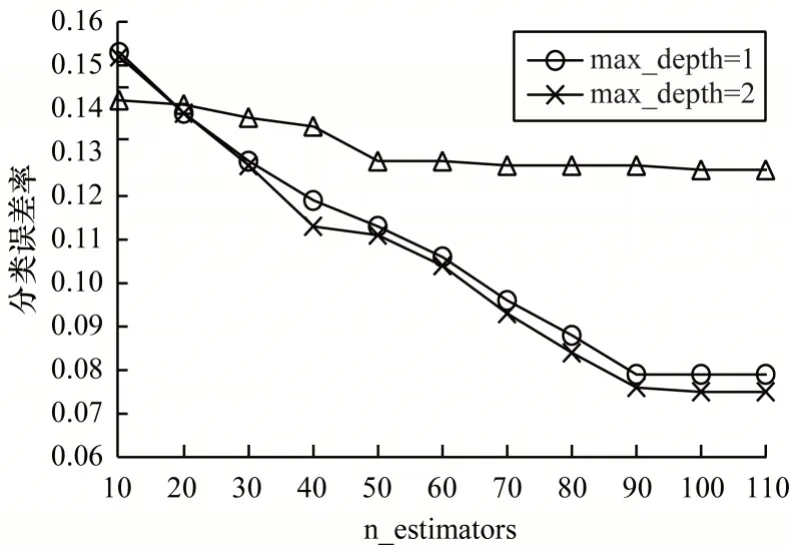
图2 分类误差率与迭代次数的关系Fig.2 Relationship between classification error rate and iteration times
3 实验与结果分析
本节通过一系列实验,验证所提方法的有效性。首先提出研究问题,然后介绍实验数据集,最后总结并分析实验结果。
3.1 研究问题
针对本文所提出的多线程程序数据竞争检测工具ADR,从以下2 个角度出发进行有效性验证。
1)与Eraser、Djit+等数据竞争检测工具相比,ADR 检测准确率是否提升以及提升幅度。
2)与Eraser、Djit+等数据竞争检测工具相比,ADR 的检测开销是否有所降低。
3.2 实验数据集
由于目前没有任何机构或者研究人员发布数据竞争检测的精确数据集,因此本文选择Github[17]上的1 组已知数据竞争结果的多线程并发程序进行插桩取样,将插桩结果作为建立Adaboost 模型的训练集。
实验环境为Ubuntu19.04,处理器核心数为4,运行内存4 GB。选择的验证测试程序来源如下:
1)为验证Adaboost 数据竞争检测模型的准确性,在Google Code的data-race-test[18]测试集中筛选出50组多线程并发程序组成一个测试程序TestCodes进行验证。
2)为验证Adaboost 数据竞争检测模型的时间开销和内存开销,选择SPLASH-2 基本套件[19]中的2 组程序和Parsec 基准程序3.1[20]中的3 组程序来进行验证。具体如表3 所示。
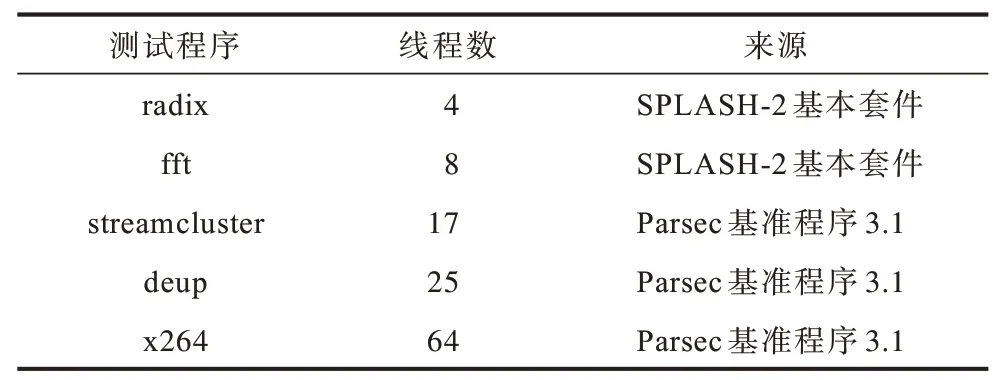
表3 测试程序信息Table 3 Information of test programs
3.3 实验过程
ADR 体系结构如图3 所示,主要由模型构建模块和模型预测模块这2 部分组成。本文首先利用样本程序的插桩结果训练得到Adaboost 分类模型,然后利用建立好的分类器对待测程序进行数据竞争检测。
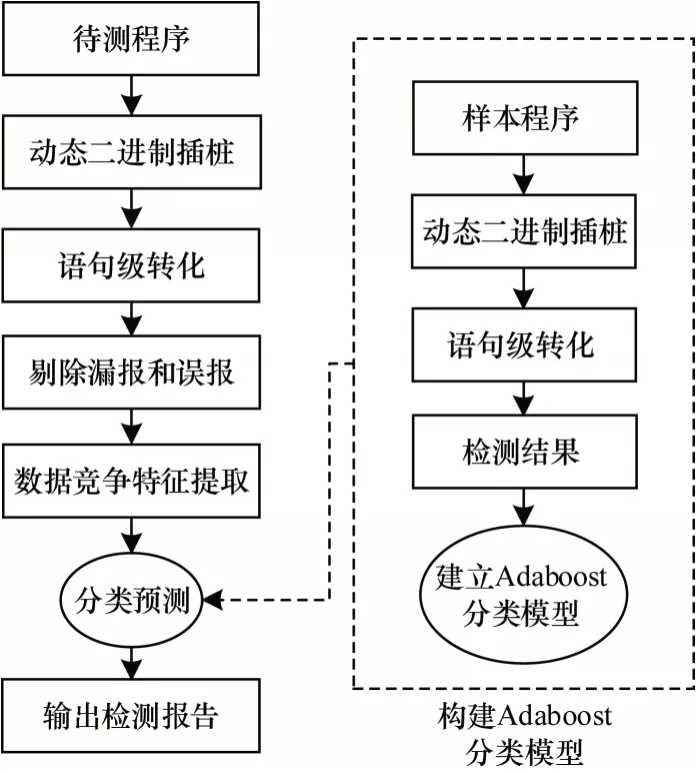
图3 ADR 体系结构Fig.3 Architecture of ADR
将ADR 与Eraser、Djit+和Thread Sanitizer 这3 种种动态数据竞争检测工具进行对比实验。Eraser、Djit+和Thread Sanitizer分别使用的检测算法是Happen-Before、Lockset 和Happen-Before+Lockset 混 合 算 法。
3.4 检测精度分析
由于TestCodes 程序由多个小程序示例组成,因此每个小程序示例可能存在零个或者多个数据竞争。本文定义以下3 个指标来衡量检测精度:数据竞争检测的误报数FP,数据竞争检测的正确数TP,数据竞争检测的漏报数FN。4 种检测工具对TestCodes 程序的数据竞争检测结果如图4 所示,已知TestCodes 中真实存在的数据竞争次数为80。
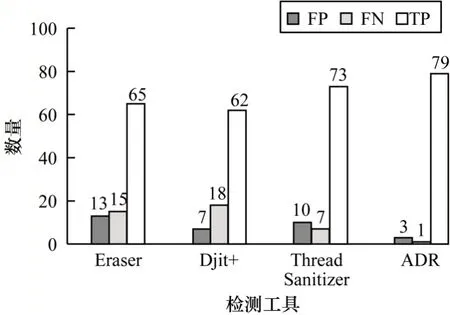
图4 不同数据竞争检测工具的检测精度Fig.4 Detection accuracy of different detection tools
从TP 值上来对比分析。ADR 检测出到79 次数据竞争,其检测准确度最高。Djit+容易受到线程调度的影响,所以漏报较多,Eraser 与Thread Sanitizer 由于是在原码级别进行的判断,会遗漏部分数据竞争。ADR采用的Adaboost分类模型是由若干个弱分类器组合而成,而且各个弱分类器之间存在迭代关系,使模型分类准确率更高。
从FP 值上来对比分析。因为Eraser 对很多确定性同步语句未进行处理,所以其误报数最多。Dijt+由于其使用的算法是Happen-Before,而ADR 是在语句级上进行的实验,剔除了重复以及无对应原码的指令信息,因此降低了检测的误报数。
3.5 检测开销分析
本文选取SPLASH-2 基本套件中的radix、fft 程序和Parsec 基准程序3.1 中的streamcluster、deup、x264 组成一个测试程序集,它们的线程数量呈递增模式,分别为5、11、17、25、64,对Eraser、Djit+、Thread Sanitizer 与ADR 检测工具进行时间开销与内存开销方面的对比,如图5 和图6 所示。
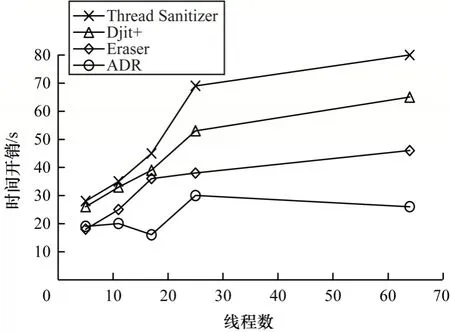
图5 不同数据竞争检测工具的检测时间开销Fig.5 Comparison of detection runtime overhead of different detection tools

图6 不同数据竞争检测工具的检测内存开销Fig.6 Comparison of detection memory overhead of different detection tools
由图5 可以看出,Thread Sanitizer的检测时间开销最大,Djit+的时间开销仅次于Thread Sanitizer。这是因为Thread Sanitizer和Djit+使用的都是Happen-Before算法,当线程数量很多时,在各个线程之间状态切换非常麻烦,增加了时间的开销,且Thread Sanitizer 还需要判断锁集的状态,所以时间开销最大。ADR 通过高效处理大量数据建立检测模型加快了检测的速度,使检测的时间开销更小。综合检测数据可知,ADR 检测的时间开销相比于其他检测方法降低约29.3%。
由图6 可以看出,Thread Sanitizer 相比于其他的检测方法,其检测的内存开销最大。这是因为Thread Sanitizer 保存了所有并发历史访问的锁集和向量时钟,而Djit+保留了所有的历史访问的向量时钟,因此,Thread Sanitizer产生的内存开销最大。ADR 为语句级检测,在对待测程序进行插桩取样时,每一条语句仅保留一条指令,只需要记录各个线程在内存中的状态信息,剔除掉了无对应原码的指令,降低了内存开销。综合检测数据可知,ADR 检测所产生的内存开销相比于其他检测方法降低约21.1%。
4 结束语
本文提出一种基于语句对特征的数据竞争方法。利用插桩工具Pin 对被测并发程序进行动态插桩,记录指令的相关内存信息。在此基础上,通过对指令信息进行过滤操作,将指令级插桩转换成语句级插桩,然后根据样本数据集建立数据竞争Adaboost 模型,对被测程序进行数据竞争检测,并基于此模型实现数据竞争检测工具ADR。实验结果表明,该方法能够有效降低漏报率与误报率,同时检测过程不受线程调度的影响,可减少检测的时间开销和内存开销,提高检测效率。后续将在数据采集过程中引入采样策略,减少样本的数据量,从而进一步减少数据竞争检测的内存消耗,优化数据竞争的检测效率。此外,在基于语句对特征的数据竞争方法中融入更优的采样策略,也将是下一步的研究方向。
