一种保留社区结构信息的网络嵌入算法
2021-12-20吕少卿赵雪莉任新成
吕少卿,赵雪莉,张 潘,任新成
(1.西安邮电大学 通信与信息工程学院,西安 710121;2.陕西省信息通信网络及安全重点实验室,西安 710121;3.陕西省能源大数据智能处理省市共建重点实验室,陕西延安 716000)
0 概述
复杂网络[1-3]作为一种特殊的数据类型在现实世界中随处可见,例如由社交平台上用户好友关系抽象得到的社交网络、由论文之间引用关系抽象得到的引文网络、由蛋白质之间的相互作用关系抽象得到的蛋白质网络、由网页间链接关系抽象得到的Web 网络等。这些网络结构复杂,其中蕴含着一些值得深入探索和挖掘的信息及规律。
网络的表现形式很大程度上决定了能否对网络进行有效分析。早期,人们用邻接矩阵来进行网络的存储和表达,但邻接矩阵只能体现节点之间的链接关系,并不能体现网络的高阶关系[2]。此外,随着网络规模的增大,邻接矩阵还面临着存储成本高、计算效率低、数据稀疏等问题[4]。因此,研究人员转而研究将节点表示为低维、稠密的实值向量形式,即网络嵌入[5](又称为网络表示学习)。将网络节点表示为低维、稠密向量就能够进行后续的网络分析任务,如节点分类[6]、链接预测[7]、社区发现[8]、可视化[9]等,还可以作为边信息应用到推荐系统[10]等其他任务中。
从算法所使用的工具角度,可将现有的网络嵌入算法分为基于矩阵特征向量的方法、基于矩阵分解的方法、基于简单神经网络的方法和基于深度神经网络的方法4 类。基于矩阵特征向量的方法是早期的网络嵌入算法,包括局部线性嵌入[11](Locally Linear Embedding,LLE)、拉普拉斯特征映射[12](Laplacian Eigenmap,LE)等,该类算法通过提取网络的关系矩阵(如邻接矩阵或拉普拉斯矩阵),然后计算得到关系矩阵的特征向量,继而得到节点的表示向量。基于矩阵分解的方法包括GraRep[13]、HOPE[14]、NEU[15]等,该类算法通过对描述网络的关系矩阵进行矩阵分解,达到降维的目的,从而得到节点的低维表示向量。基于简单神经网络的方法包括DeepWalk[16]、Node2vec[17]和LINE[18]等,该类算法对网络进行概率建模,通过最大化概率来保留网络的拓扑结构信息,从而得到节点的表示向量。基于深度神经网络的方法包括SDNE[19]、DNGR[20]等,该类算法通过深度自编码捕获网络的非线性关系,进而得到节点的表示。
虽然上述方法保留了网络中的微观结构信息并取得了较好的表示结果,但却都忽略了网络结构中普遍存在的社区结构信息[1]。社区结构是网络所具有的宏观结构信息,同一社区内的节点通常具有密集的链接关系以及相似的特性,而不同社区节点间的链接则相对稀疏[21]。社区结构普遍存在于现实网络中,如社交网络、生物网络、Web 网络、引文网络等[21-22],其对刻画网络节点关系和完成后续网络分析任务具有重要作用。鉴于此,本文提出一种保留社区结构信息的网络嵌入算法PCNE。通过构造社区结构嵌入矩阵和社区隶属度矩阵得到原始网络中的宏观社区结构信息,并通过融合一阶相似性和二阶相似性得到网络中的微观结构信息。在此基础上,以迭代优化的方式对微观结构信息、宏观社区结构嵌入矩阵和社区隶属度矩阵进行联合优化,得到同时包含网络微观一阶、二阶结构信息和宏观社区结构信息的网络嵌入向量。
1 本文方法
表1 列出了本文PCNE 算法使用的符号及定义。

表1 符号定义Table 1 Definition of symbols
1.1 相关概念
本小节给出本文工作相关的一些基本概念及定义。
定义1(社区结构[23])社区结构是网络中存在的一些连接密集的群落(也称为簇)结构。同一社区内的节点彼此连接紧密,而各个不同社区中的节点间连接相对稀疏。
定义2(网络嵌入[5])网络嵌入又称网络表示学习或图嵌入。给定一个无向网络G=(V,E),网络嵌入的目标是学习一个映射函数f:v→rv∈Rd,将网络中每一个节点映射为一个d维稠密的实数向量,并且满足d<<|V|。
1.2 算法框架
给定网络G=(V,E)。设A∈Rn×n为网络的邻接矩阵。若节点i和节点j之间存在链接关系,则A中对应元素为1,否则为0。所得到的节点的表示矩阵为Y,Y中的第i行代表节点i的表示向量,其中,d表示嵌入空间中节点表示向量的维数。
PCNE 算法框架如图1 所示,其中主要包含两部分内容,即保留网络微观结构信息的模型和保留社区结构信息的模型。具体而言,首先通过节点间的链接关系得到包含一阶相似性和二阶相似性的微观结构相似性矩阵F,借助对称非负矩阵分解模型得到保留网络微观结构信息的损失函数;然后引入社区结构嵌入矩阵P,通过联合非负矩阵分解模型得到保留网络社区结构信息的损失函数;最后通过联合优化两部分损失函数,得到同时保留网络微观结构信息和网络社区结构信息的节点表示。
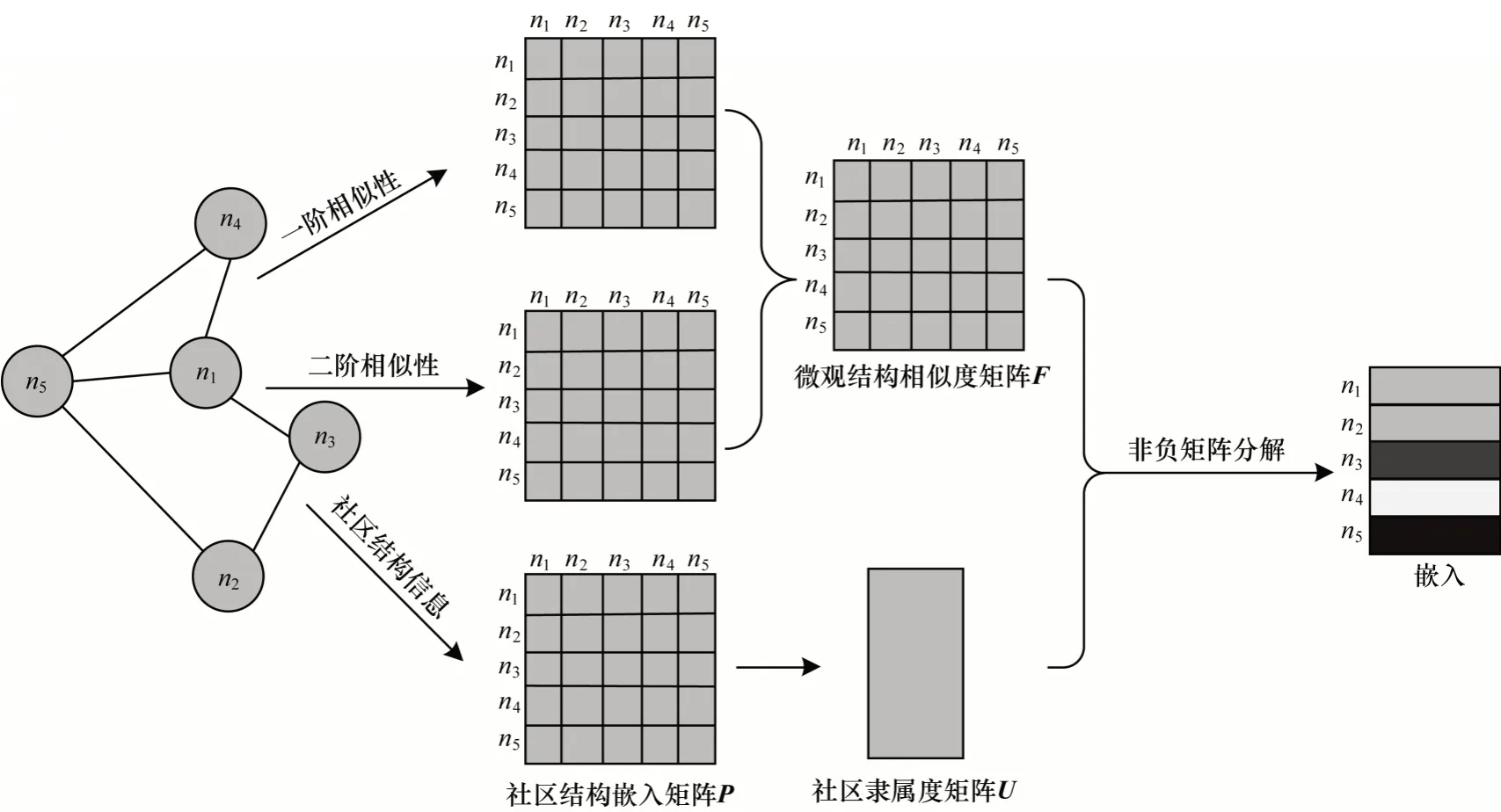
图1 PCNE 模型框架Fig.1 Framework of PCNE model
1.3 微观结构信息建模
本文通过保留网络中每对节点的一阶相似性和二阶相似性刻画网络的微观结构信息。具体地,如果在原始网络中一对节点之间存在边,那么它们就具有一阶相似性;如果一对节点在原始网络中没有边连接,那么它们之间的一阶相似性为0。在现实世界网络中,有边相连的两个节点之间通常具有相近的性质。以社交网络为例,如果一个节点和另一个节点相连(即有好友关系),那么这两个用户大概率具有相似的兴趣爱好或职业。这表明,在原始网络中直接相连的两个节点在嵌入空间中也应该彼此接近。本文将网络的邻接矩阵A作为节点间网络结构一阶相似性的描述。
现实网络中存在的边通常是稀疏的[24],没有连边的节点对并不代表它们在低维空间的表示向量不相似。一种补充一阶相似性缺陷的解决方案是考虑他们的共同邻居,通过共同邻居来衡量两个节点之间的相似性,即二阶相似性。此外,现实中的网络经常会由于观测手段的不足导致丢失一些网络中本该存在的链接关系,因此保留节点间的二阶相似性就更有必要。本文定义矩阵S∈Rn×n为二阶相似度矩阵,并用邻接矩阵行向量的余弦相似作为其二阶相似度,如式(1)所示:

其中:ai为邻接矩阵A的第i行。
为同时保留网络结构的一阶相似性和二阶相似性,本文将两种相似性的加权和作为网络最终的微观结构相似性,用矩阵F来表示,并命名为微观结构相似度矩阵。F计算公式如式(2)所示:

其中:参数α>0,为二阶相似性的权重系数,α的大小体现二阶相似性对节点表示的重要性。在本文的后续实验中,选择α=3。
由于本文针对的是无向网络,因此微观结构相似度矩阵F是一个非负的对称矩阵。为使所得到的节点表示能够保留网络的微观结构信息,本文基于对称非负矩阵分解[23]提出式(3)所示的损失函数来最小化节点之间的嵌入差异:

1.4 社区结构信息建模
网络的邻接矩阵反映的是网络节点之间的链接关系,文献[23]通过非负矩阵分解的方式提取网络中的社区结构信息。假设网络由k个社区组成,则其目标函数如式(4)所示:

其中:矩阵A为网络的邻接矩阵;U∈Rn×k为社区隶属度矩阵,反映网络中各节点与各个社区之间的从属关系。无论节点i和节点j是否属于同一个社区,只要两节点之间存在链接,其对应元素就为1,因此,蕴含在网络中的社区结构不能通过直接分解邻接矩阵A来反映。本文通过分解文献[25]中所提出的更能反映网络中社区结构信息的社区结构嵌入矩阵P来提取网络的社区结构分布信息,其目标函数形式化表示为:

下面介绍社区结构嵌入矩阵P的具体构造方法。
由于社区内部的节点彼此之间连接紧密,因此每个具有链接关系的节点对都有落入同一社区内的可能性,定义这种可能性为社区成员相似性。对于网络中的节点i和节点j,它们之间社区成员相似度的计算公式如式(6)所示:
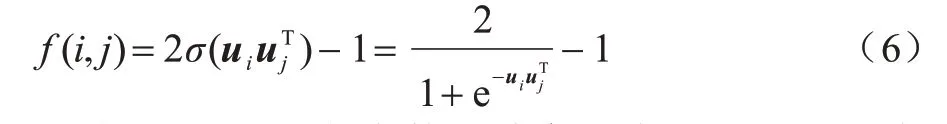
现实世界中的大多数网络都比较稀疏,在网络中任意选择两个节点,他们之间存在边的可能性几乎为零。为了最大化具有链接关系的节点对的社区成员相似性,同时最小化随机采样的节点对之间的社区成员相似性,本文采用负采样的方式,设计如式(7)所示的损失函数:
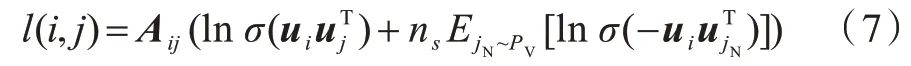
其中:ns为负采样样本数;jN为负采样的随机采样节点;,di表示节点i的度,D表示整个网络节点度数的总和。式(7)又可表示为:
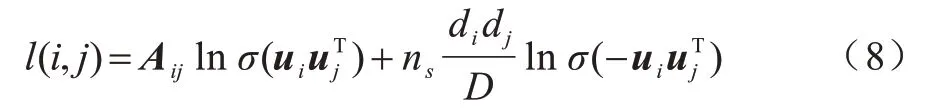
对式(8)求偏导,得到:
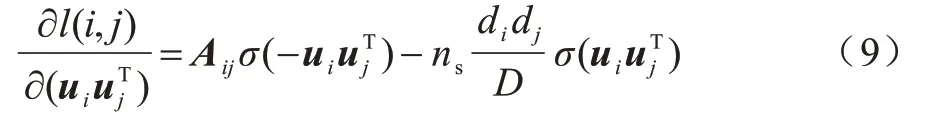

基于以上分析,社区结构嵌入矩阵P可由式(11)进行构造:

1.5 保留社区结构信息的网络嵌入
为了将网络的社区结构信息融入网络嵌入的过程中,利用得到的社区隶属度矩阵U对网络表示学习进行约束,使所得节点表示能够反映出网络的社区结构信息,从而在一定程度上提高网络表示学习的质量。本文引入一个非负矩阵H∈Rk×d,并命名为社区表示矩阵,其第i行的行向量hi即为第i个社区的向量表示。如果某节点的表示向量与某一社区的表示向量相似,则认为该节点属于该社区的可能性高。本文将节点i的表示向量yi与社区r的表示向量hr的内积作为两向量之间相似性的表达。因此,若节点i的表示向量与社区r的表示向量相互正交,即两者的表示完全不同,那么节点i属于社区r的可能性近乎为零。由于社区隶属度矩阵U体现了每个节点与各社区之间的从属信息,因此本文希望YHT的结果与社区隶属度U尽可能一致,从而设计如式(12)所示的目标函数:

基于上述分析,本文在网络的微观结构模型和社区发现模型之间建立了纽带,进而挖掘网络表示学习的过程中的社区结构信息。最终目标函数如式(13)所示:
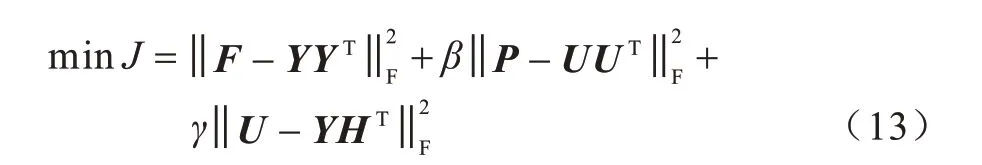
其中:参数β和γ均为非负值,β用于提取网络中蕴藏的社区结构,γ用于调节社区结构信息在网络表示学习过程中的贡献大小。通过调节这两个参数的值可以适应不同的网络和不同的应用场景。
1.6 模型优化
由于式(13)所示的目标函数是非凸的,因此几乎不可能找到全局最优解。为解决该最优化问题,本文基于文献[26]提出一个能够保证收敛到局部最优解的迭代更新过程。在保持其他参数不变的情况下,迭代更新每一个参数,具体过程如下:
更新H:保持Y、U不变,式(13)中只有最后一项与矩阵H有关。由文献[27]所提非负矩阵分解模型的乘法更新规则,得到式(14):

更新U:保持Y、H不变,为更新矩阵U,本文需要解决一个联合矩阵分解问题。由于式(13)中只有最后两项与矩阵U有关,因此只需要最小化式(15)所示的损失函数:
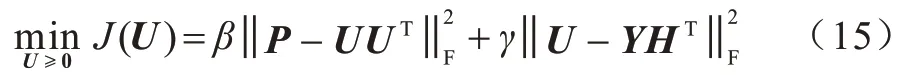
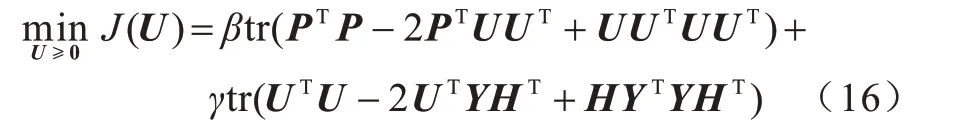
该约束优化问题可以通过引入矩阵U的拉格朗日乘数矩阵Θ构造拉格朗日函数来解决。拉格朗日函数如式(17)所示:
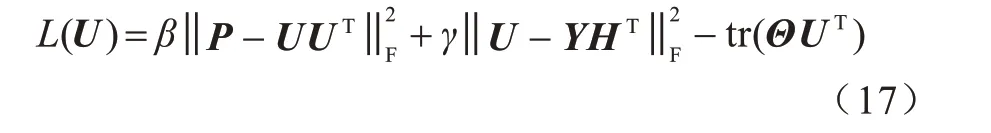
对矩阵U求偏导,得到:
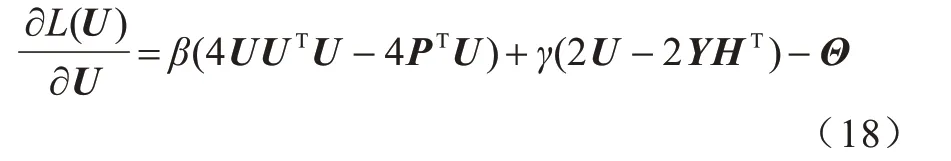
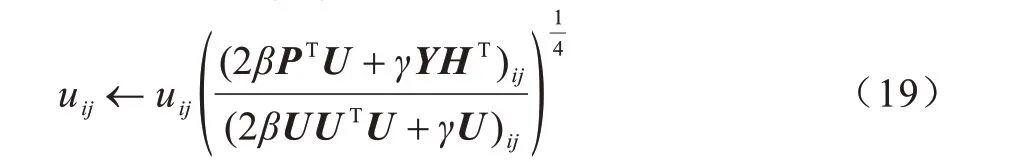
同理,固定矩阵U和H,可得到矩阵Y的更新规则,如式(20)所示:
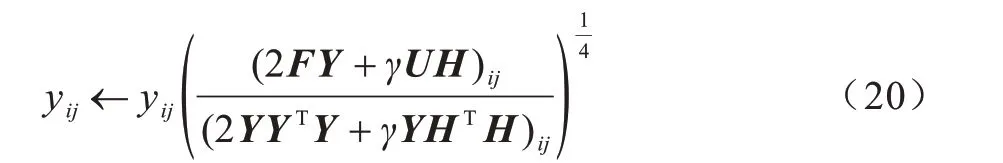
上述更新规则均具有收敛性,通过迭代交替更新矩阵U、H、Y,可以得到网络的节点表示矩阵Y。
PCNE 算法的伪代码如下所示:
算法1 PCNE 算法

1.7 复杂度分析
PCNE算法的时间复杂度主要取决于式(14)、式(19)和式(20)的矩阵乘法运算,它们的时间复杂度分别为O(ndk)、O(n2k+ndk)和O(n2d+ndk),其中:n为节点数量;d为节点表示维数;k为网络中的社区数。由于实际应用中满足k≪n,因此PCNE的算法复杂度为O(dn2)。DeepWalk 的算法复杂度为O(dnloga n)[16],Node2vec 的算法复杂度为O(dn)[17],算法LINE 的复杂度为O(dm)[18],其中m为网络中边的数量。虽然这些算法的复杂度比PCNE 算法低,但是DeepWalk 和Node2vec 都是基于随机游走的算法,只考虑了节点的局部链接关系,LINE只考虑了一阶、二阶信息,这些算法都没有考虑宏观的社区结构信息,而社区结构信息对现实网络分析非常重要。PCNE 通过非负矩阵分解的方式将社区结构信息融入到网络表示学习过程中,在后续网络分析任务中能够取得比DeepWalk、Node2vec、LINE 更好的效果。
2 实验与结果分析
2.1 实验数据集
本文实验选取公开的真实网络Karate[28]和WebKB 网 络[29]的4个子网络(Cornell、Texas、Washington、Wisconsin)作为数据集进行实验,如表2所示。Karate[30]数据集是描述美国一所大学空手道俱乐部中34 个成员之间社会关系的网络,由34 个节点和78 条边组成,包含2 个类别标签;Cornell、Texas、Washington、Wisconsin 是WebKB[31]数据集的4 个子网络,均包含5 个类别标签,分别是由美国4 所大学的网页之间的链接关系构建的,Cornell 数据集由195 个节点和283 条边组成,Texas 数据集由187 个节点和289 条边组成,Washington 数据集由230 个节点和366 条边组成,Wisconsin 数据集由265 个节点和469 条边组成。
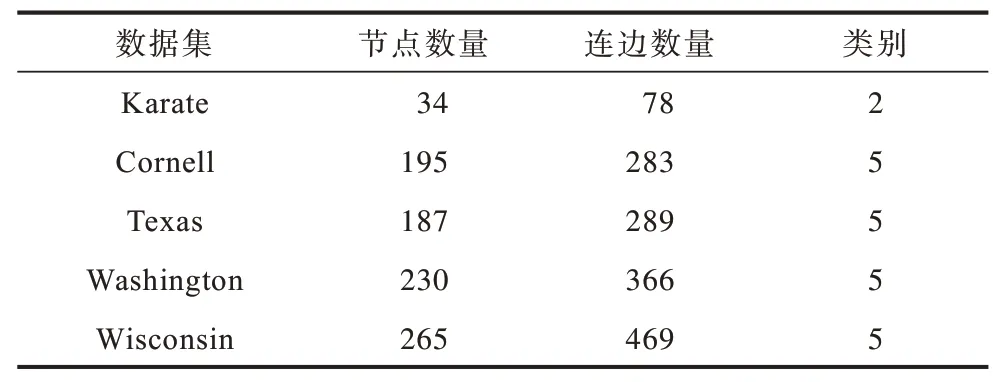
表2 实验数据集信息Table 2 Information of datasets for experiment
2.2 对比算法与参数设置
为验证本文PCNE 算法的有效性,将其与以下5 个具有代表性的网络表示学习算法进行对比。
1)DeepWalk[16]算法。该算法通过随机游走模型将获取的节点序列看作文本中的单词,作为Word2vec算法的输入,通过Skip-Gram 模型训练得到各节点的表示。实验中参数设置:每个节点采样的序列数量为40,节点序列长度为40,窗口大小为10。
2)LINE[18]算法。实验中用LINE1 和LINE2 分别表示基于一阶结构相似性的模型和基于二阶结构相似性的模型,用LINE 表示基于一阶和二阶结构相似性的模型。这3 个算法的参数设置为:负采样的样本数设为5,学习率的初值设为0.025。
3)Node2vec[17]算法。该算法在DeepWalk 算法的基础上引入2 个超参数p、q以平衡基于深度的随机游走策略和基于广度的随机游走策略。Node2vec算法的参数设置为p=0.25,q=0.25,其余参数与DeepWalk 的参数一致。
为保证实验的公平性,节点的表示向量维度都设置为20 维。本文PCNE 算法的参数设置为:β=0.1,γ=0.5。
2.3 实验结果及其分析
本文利用节点分类任务评估PCNE 算法的性能。为了执行该任务,将所得到的节点嵌入向量视为网络中每个节点的特征作为分类器的输入,以预测节点的标签。在实验中,本文采用scikit-learn 包中的一对多SVM 分类器,在分类器的训练过程中,训练集百分比即训练率A设置为{10%,15%,20%,25%,30%},其余部分作为测试集。为确保实验结果的稳定性和可靠性,对每个数据集分别进行10 次独立重复实验,最终实验结果取10次实验的Micro-F1值和Macro-F1值的均值。表3~表7 列出了PCNE 和其他5 个算法在5 个数据集不同训练比例下的实验结果,其中加粗数据表示最优。可以看出,在Karate、Texas和Washington数据集上,PCNE算法明显优于其他算法,无论是以Micro-F1 还是以Macro-F1 为评价标准,其在各训练比例下均取得了最高的评价得分:节点分类性能在Micro-F1 上分别比第2名提高了0.96%~9.36%(Karate)、0.77%~3.51%(Texas)和9.95%~13.01%(Washington),在Macro-F1 上分别比第2 名提高了3.02%~11.44%(Karate)、0.4%~5.66%(Texas)和3.82%~5.93%(Washington)。在Cornell和Wisconsin 数据集上,PCNE 虽然没有在所有数据上体现出优势,但在大部分情况下的表现依然具有一定竞争力。例如:在Cornell 数据集上,PCNE 在节点分类任务上得到了最高的Micro-F1,虽在Macro-F1 分数表现略差,但比最高得分仅低了1%左右;而在Wisconsin数据集上,其节点分类性能指标Micro-F1 也在各训练率下均取得了最高评价得分。因此,从综合性能上看,PCNE 算法在节点分类任务中的表现仍具有较强的竞争力。
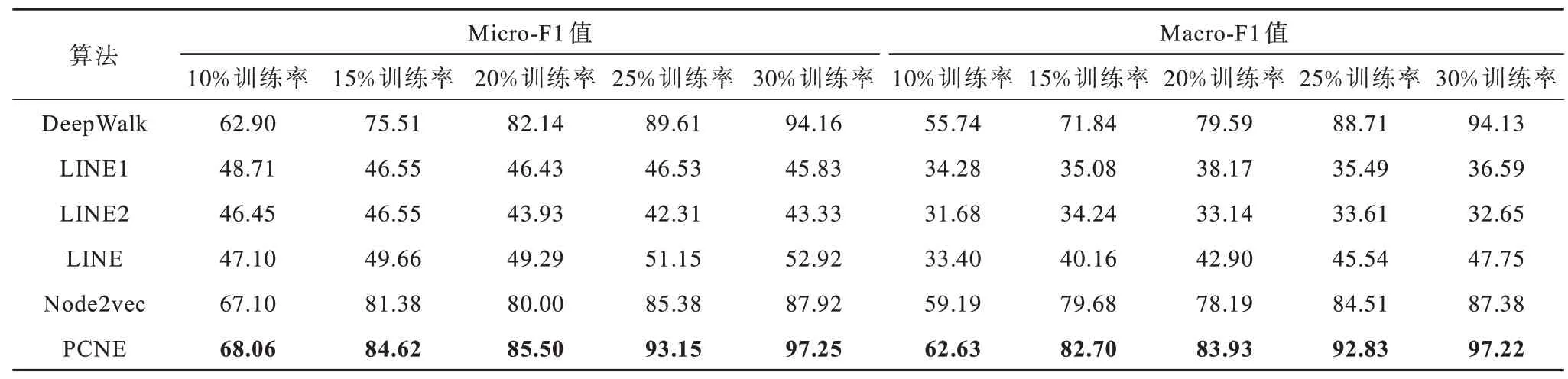
表3 Karate 数据集上的节点分类性能Table 3 Node classification performance on Karate dataset %
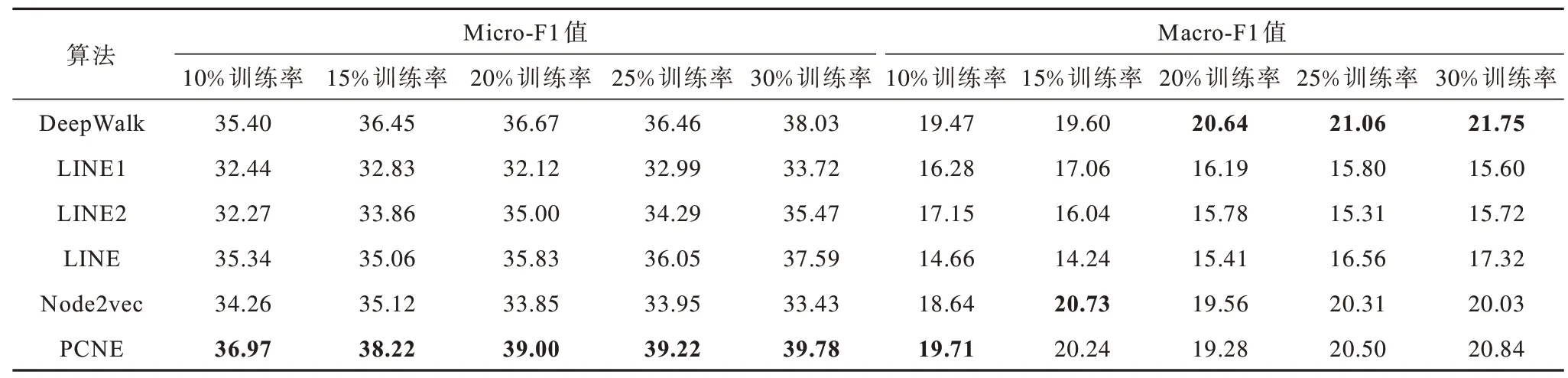
表4 Cornell 数据集上的节点分类性能Table 4 Node classification performance on Cornell dataset %

表5 Texas 数据集上的节点分类性能Table 5 Node classification performance on Texas dataset %
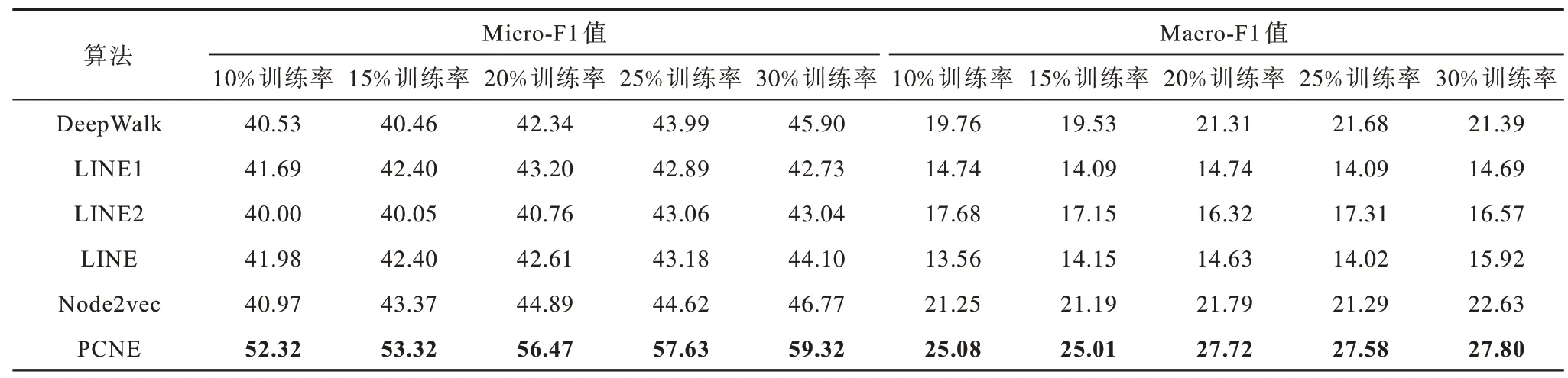
表6 Washington 数据集上的节点分类性能Table 6 Node classification performance on Washington dataset %
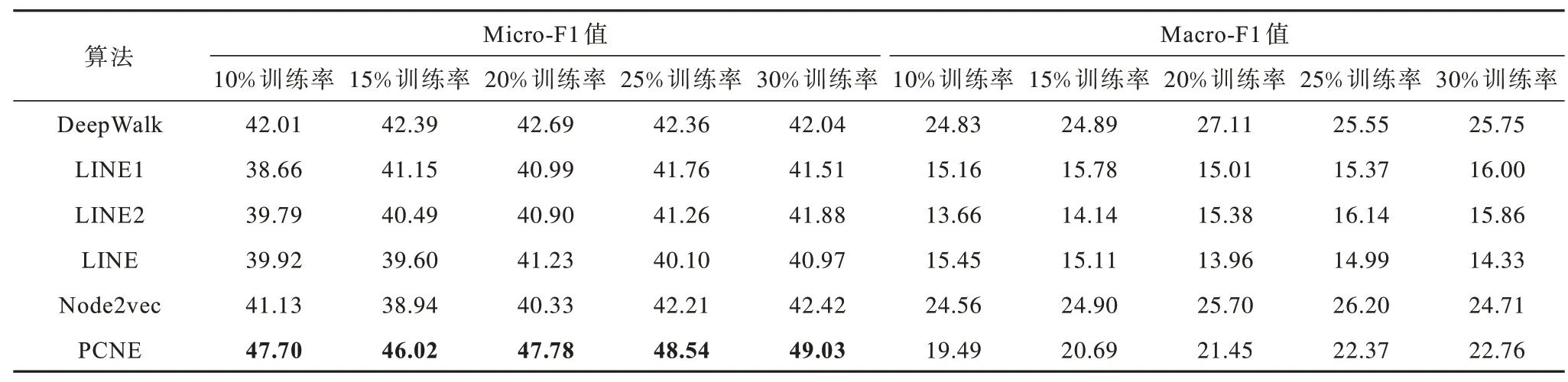
表7 Wisconsin 数据集上的节点分类性能Table 7 Node classification performance on Wisconsin dataset %
2.4 参数敏感性分析
本文PCNE 算法主要包含β、γ、d这3 个参数,分别用以调节各目标对网络表示学习的贡献大小,其中:参数β控制网络中社区结构划分的质量对网络表示学习的影响;参数γ控制社区结构信息对网络表示学习的影响;参数d为所学节点向量表示维数。为研究这3 个参数对PCNE 算法的影响,分别在Cornell、Texas、Washington 和Wisconsin数据集上进行实验分析。
1)在固定向量表示维数d=100 的情况下,对其余2 个参数的敏感性进行实验分析。实验中将训练比例固定为30%,并设置参数β,γ∈{0.1,0.5,1,5,10}。图2~图5 分别记录并反映了不同数据集上2 个参数对节点分类任务评价指标Micro-F1 值的影响,可以看出:在4 个数据集上,随着参数β和γ的调整,PCNE 算法表现都较为稳定,性能指标Micro-F1 在4 个数据集上的波动范围均在可控范围内,分别为2.89%(Cornell)、4.65%(Texas)、3.17%(Washington)和3.36%(Wisconsin);而从整体看,随着2 个参数的变化,指标Micro-F1 变化范围较小,变化趋势较为平缓。
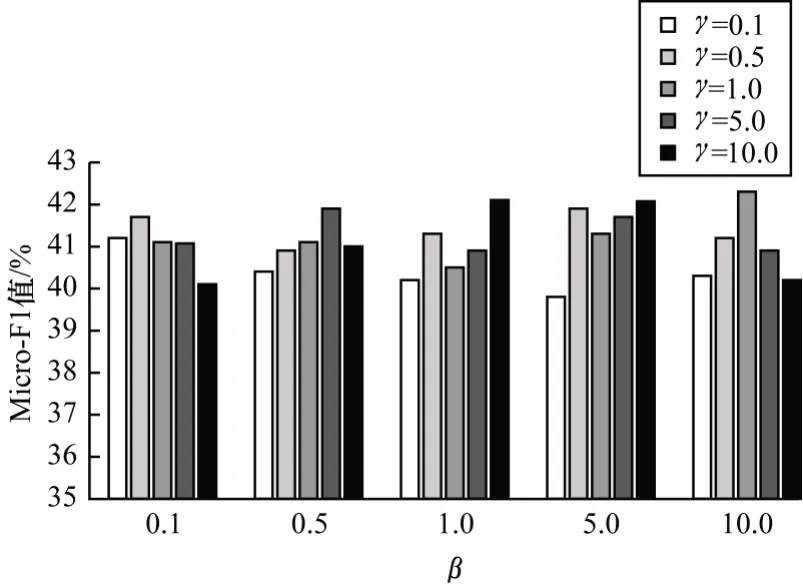
图2 Cornell 数据集上参数β 和γ 的敏感性Fig.2 Susceptibility of parameters β and γ on Cornell dataset

图3 Texas 数据集上参数β 和γ 的敏感性Fig.3 Susceptibility of parameters β and γ on Texas dataset
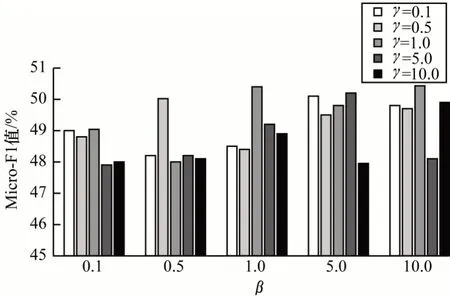
图4 Washington 数据集上参数β 和γ 的敏感性Fig.4 Susceptibility of parameters β and γ on Washington dataset
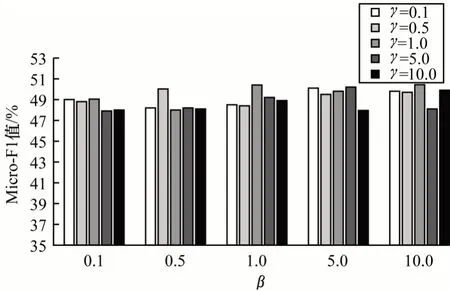
图5 Wisconsin 数据集上参数β 和γ 的敏感性Fig.5 Susceptibility of parameters β and γ on Wisconsin dataset
2)在固定参数β和γ的情况下,分析表示向量维数d的敏感性,即d对节点分类性能的影响。实验中训练比例仍固定为30%,并设置参数d∈{20,50,100,150,200}。由于在其他数据集上也会出现相似的结果,因此本文仅展示在数据集Texas 和Washington 上的结果。图6记录并反映了在这2个数据集上表示维数d对于分类性能评价指标Micro-F1 的影响,可以看出:无论是Texas 数据集还是Washington 数据集,随着表示维数d的增加,节点分类性能指标Micro-F1 也随之增大,当d增加到一定数值后,Micro-F1便趋于稳定,再随着d增大,Micro-F1 反而有所下降。这说明在表示维数较低的情况下,该算法捕获的网络信息较少,随着表示维数的增加,算法捕获网络信息的能力有所提高,而选择太高的维数又会因特征过多导致具有重要区分度的特征的权重过小从而影响节点间的差异。因此,对于Texas和Washington数据集而言,节点表示维数选取d=100或50 较为合适。
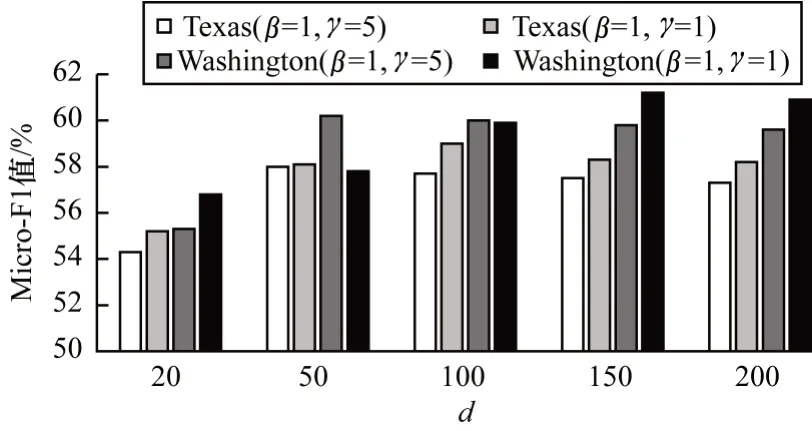
图6 表示向量维数d 的敏感性Fig.6 Susceptibility of dimension d for representation vector
3 结束语
本文提出一种保留社区结构信息的网络表示学习算法PCNE。定义网络结构的一阶相似性和二阶相似性,将其作为网络的微观结构信息进行建模。同时对网络中蕴含的社区结构信息进行建模,通过非负矩阵分解的方式得到社区隶属度矩阵,基于此提取网络中的社区结构信息。将两者放在一个统一的框架下进行联合优化,从而得到保留社区结构信息及微观结构信息的节点表示向量。在真实数据集上的节点分类对比实验结果验证了PCNE 算法的有效性。该算法与DeepWalk、Node2vec、LINE 等算法都是针对同质网络进行研究(即网络中的节点为同一类型),虽然同质网络在现实世界中更广泛和普遍,但现实世界中还存在大量的异质网络(即在同一个网络中存在多种类型的节点,如评价网络、购物网络等)。因此,如何合理高效地将网络结构信息融入异质网络的表示学习,将是后续深入研究的课题。
