基于图注意力网络的案件罪名预测方法:CP-GAT
2021-12-20赵琪珲李大鹏高天寒闻英友
赵琪珲, 李大鹏, 高天寒, 闻英友
(1. 东北大学 软件学院, 辽宁 沈阳 110169; 2. 东北大学 计算机科学与工程学院, 辽宁 沈阳 110169; 3. 东北大学 计算机科学与工程学院/东软研究院, 辽宁 沈阳 110169)
近年来,人工智能技术的稳健发展使得自然语言处理、计算机视觉、语音识别等领域都取得了显著的进步.在法律智能[1]这个新兴的研究领域中,自然语言作为法律的载体,有着形式丰富的文本数据,所以面向自然语言处理的法律智能各项任务都得到了长足的发展,如智能案例检索、法律判决预测、法律风险提示、法律智能问答等.这些任务可以极大简化法律工作者的工作,并且可以给与非法律工作人员专业的法律建议.其中法律判决预测作为重要的一项子任务,以其自身的实用性以及对于法律从业人员的参考性,得到了学术界的极大关注.法律判决预测(legal judgment prediction, LJP)包含三个子任务:罪名预测、刑期预测和法条预测.罪名预测任务的目的是通过给定的一段司法文本(一般为案情描述)来自动判定所属罪名.这一任务是法律人工智能中重要的一项子任务,它能够给与法官等法律从业人员辅助参考意见,极大简化了他们的工作量,有着重要的实用价值.
过去几年,学术界一直把案件罪名预测这一任务等同于文本分类任务去处理.文本分类是自然语言处理领域的经典且重要的任务[2].文本分类任务通常可以分为3类.第一类是基于数学和定量分析方法[3-4],都是基于少量数据和少量标签的数据集.第二类是基于人工构建特征工程的方式,再通过传统机器学习算法去做预测. Liu等[5]在K最近邻算法(K-nearest neighbors,KNN)中使用了词和段落级别的特征去预测罪名.Liu等[6]的方法是首先使用支持向量机(SVM)去做第一次分类,然后再利用文本数据的词级别特征和词共现频率做重新排序,得到罪名分类结果.Katz等[7]利用了案例配置信息如:地点、时间等,作为罪名预测的特征信息.但是这类方法是通过人工提取浅层特征,不仅需要法律专业人员提供帮助,而且还不足以完全提取法律文书的不同层次的语义特征.第三类是利用深度神经网络模型来预测罪名.近期随着基于深度学习的语言模型的发展,越来越多的法律相关工作应用了神经网络模型作为法律文本数据的特征提取器.Luo等[8]在使用注意力的神经网络中融入了法条信息.Jiang等[9]提出了一种基于神经网络与强化学习相结合的方法解决了罪名预测任务以及其中的可解释性问题.Long等[10]开创性地把罪名预测任务从普遍的文本分类任务转化成了文本阅读理解任务,取得了良好的效果.Zhong等[11]基于有向无环图(directed acyclic graph,DAG)定义子任务之间的拓扑性的依赖关系这个理论,创建了罪名预测系统.Duan等[12]融合了外部知识从而对罪名预测模型进行了加强.
案件罪名预测任务目前有两个待解决的问题:一是如何应对具有长尾效应的数据集,也就是如何保证模型能够尽可能从只有少量样本的数据中学习到更多的信息;二是罪名混淆问题,其根本原因就是不同罪名所依赖的法条可能在语义上存在很大的相似性,例如在危险驾驶罪和交通肇事罪中,就包含大量重叠的词汇描述.
为了解决上述问题,本文受文献[13-14]工作的启发,提出了一种基于图注意力网络(graph attention network, GAT)的罪名预测模型,名为CP-GAT(charge prediction based on graph attention network).本文使用CAIL2018[15]数据集中的法律文书即裁判文书作为构建图数据集的基础.所构建的图结构包含两种节点:文书节点、词节点及两种边:词节点之间的边、词节点与文书节点之间的边.本文提出的方法首先将数据集中关于案情描述部分的文本数据和案例对应的法条文本数据做分词,然后把去重后的词与每个文书作为图的节点.词节点间的边权值是通过计算词共现矩阵从而得到的,文书词节点间的边权值是通过计算TF-IDF(term frequency-inverse document frequency)[16]得到的.通过上述流程得到可以用于输入到图注意力网络的数据,最后通过GAT模型提取到图节点的特征信息,进而把基于司法文书的罪名预测问题转化为图节点的分类问题.本文提出的方法在CAIL2018这个数据集上进行罪名预测任务的表现好于对比实验所用的模型,并且在选取数据集中长尾数据作为训练数据的情况下,依然取得了远高于实验对比模型的预测效果,进一步证明了本文方法行之有效.
1 构建基于GAT的罪名预测方法
本文提出的罪名预测方法(CP-GAT)的整体结构如图1所示,共包含三层结构,第一层是图结构构建层,这一层的主要工作是通过数据预处理手段把案例文书(包括案例对应的事实描述,法条信息)数据转换成对应的图数据,其中把法条也加入到图数据的构建中,这也是融合法条知识的一种手段,可以提高模型本身的性能;第二层是基于图注意力网络的特征提取层,在这一层中使用了图注意力网络对节点进行特征提取;第三层是罪名预测层,本文使用了softmax分类器对罪名做出预测.

图1 CP-GAT的整体架构图
1.1 面向司法文书的图结构数据构建
本文所使用异质图结构的数据是基于CAIL2018数据集中的案例以及案例中包含的事实描述(fact)与对应法条(relevant law article)所构建成.异质图包含多种类型的节点或者关系,每个节点属于一个特定的对象类型,每条关系属于一个特定的关系类型,这样的图被称作异质图,真实世界中的图大部分都可以被自然地建模为异质图,所以目前基于异质图的研究如火如荼.本文所构建的图数据中包含两种节点:词节点、案例节点,两种边:词-词、词-案例.图数据的可视化样例如图2所示,包含两种节点,例如:王某是词节点,A185是案例节点,代表第185篇案例文书.

图2 基于裁判文书构建的图样例
本文构建后的图数据的节点数量为案例个数与文本数据(案例中的事实描述与法条)中不重复词个数的总和.图中的边计算方式分为两种,如下所示:
(1)
其中:Sij代表节点i与节点j间的边权值.词-案例类型的边权值是通过计算TF-IDF(term frequency-inverse document frequency)词频-逆文档频率值得到的.其中:TF是词频,其含义是单词出现在文档中的次数;IDF是逆文档频率,其含义是衡量词语在文档中的普遍重要性.某一特定词语的逆文档频率是由总文档数目除以包含该词语的文档数目,再将得到的商取以10为底的对数得到的.为了得到更好的实验效果,本文方法使用固定大小的滑动窗口来计算TF-IDF值.第二种类型的边是词-词类型的边,通常这种类型的边权值都是计算词之间的相似度,本文采用计算词语与词语的PMI(point-wise mutual information)点分互信息的值来给词-词边赋权值:
(2)
其中:NW(i)是在语料集上包含词语i的滑动窗口个数;NW(i,j) 是包含词语i和词语j的滑动窗口个数;NW 是整体滑动窗口的个数.PMI是一种计算词关联度的方式,其值的大小代表两个词之间的关系是否紧密.PMI的基本思想是统计两个词语在文本中同时出现的概率,概率越大,其相关性就越紧密,关联度越高.
本文方法所构建的图结构数据,便于在全局的层面上对共现信息进行建模,也可以更好地应用图注意力网络对图中节点进行特征提取.
1.2 基于GAT的特征提取层
本文在图节点的特征提取部分,使用了图注意力网络(GAT)对整个图结构进行建模,从而获取网络中的案例节点对应的特征表达.
卷积神经网络(CNN)、循环神经网络(RNN)无法将非欧氏空间上的数据作为网络的输入,因为非欧氏空间上的数据是无法保证平移不变性的.图神经网络(graph neural networks,GNN)的出现解决了非欧式空间数据的处理问题.Kipf等[17]提出一种图卷积网络(graph convolutional network,GCN),该网络是直接作用在图数据上的,并且可以通过节点的邻居信息来得到自身节点的特征向量,图卷积网络属于频域方法,该网络的思想是利用图的拉普拉斯矩阵的特征值和特征向量来研究图的性质.门控图神经网络(gated graph neural network,GGNN)[18]主要是解决过深层的图神经网络导致过度平滑的问题,使用门控循环单元(gated recurrent unit, GRU)更新节点状态.
本文采用图注意力网络对整个图进行建模,GAT模型在GCN的基础上进行了改进,结合了 Attention 机制,Attention机制可以为不同节点分配不同权重,在训练时依赖于成对的相邻节点,而不依赖具体的网络结构.CAT假设图中包含N个节点,则输入网络的节点向量记作:h={h1,h2,…,hN},hi∈F,图注意力网络的输出向量记作:F.本文方法所使用的模型在计算节点间的信息聚合时引入了自注意力机制(self-attention),对应的计算公式为
eij=a(Whi,Whj) .
(3)
其中eij表示节点j对于节点i的重要性,并且节点i必须是节点j的一阶邻居,在计算节点间的注意力得分时则使用了masked attention来实现上述对于邻居节点必须为一阶邻居的假设要求.计算节点间注意力分值的过程如图3所示.
图3中hi是需要计算注意力分值的节点特征向量,此处假设节点i有4个一阶邻居节点,即:hj1,hj2,hj3,hj4,为4个一阶邻居节点对应的特征向量.aij1,aij2,aij3,aij4为经过注意力机制计算后对应的分值.
计算注意力分值的公式如下:
αij=softmaxj(eij) .
(4)
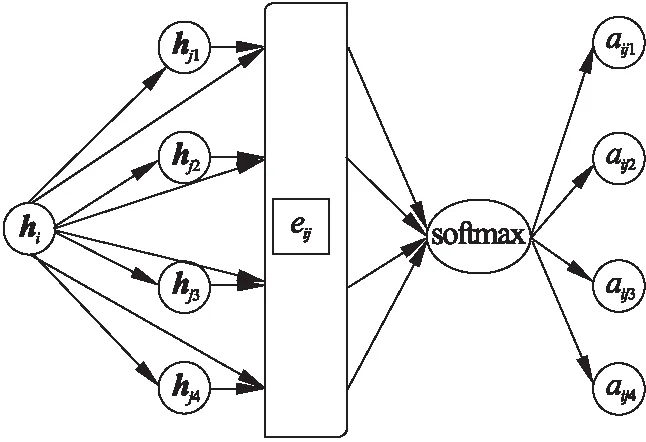
图3 计算节点间注意力分值的过程图
本文中用到的注意力机制是通过单层前馈神经网络来实现的,其中激活函数使用LeakyReLU函数,进而计算注意力分值的公式可以扩展为
(5)
其中:βT是前馈神经网络的可训练参数;W是可训练的参数.GAT中还加入了多头注意力机制,经过K头注意力机制计算后的特征向量进行拼接后,对应的输出特征向量表达如下:
(6)
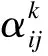
(7)

1.3 输出层
在输出层,本文采用softmax分类器,将经过GAT模型计算后的向量记作H,并输入到分类器中,对应的公式如下:
O=softmax(H) .
(8)
本文在模型训练阶段,采用交叉熵损失函数作为本方法的损失函数,公式如下:
(9)
其中:γD为带标签的文书索引集合;Y是输出特征的维度,为实验使用数据集中包含的罪名类别的总个数.
2 实验结果分析
2.1 数据集
为了验证本文提出方法的有效性,本文使用CAIL2018法律数据集中的CAIL-big数据集,该数据集中的每个案例都包含案例事实描述,对应法条,对应罪名以及刑期.在数据集的前期处理工作中,本文首先过滤出小于10个词的样本,然后筛选出单罪名的样本,最后把处理后的数据再分为两部分,分别是CAIL-N(训练集数量为1 001 185)和CAIL-S(训练集数量为80 000),其中CAIL-N数据集包含更多的案例、法条以及罪名数量,相较于CAIL-N,CAIL-S数据集规模较小.表1展示了所用数据集的详细信息.

表1 实验数据集统计信息
2.2 实验评价标准
本文使用准确率、精确率、召回率、宏平均F1值作为方法的实验评价标准.
2.3 实验对比模型
本文在实验中使用了以下对比模型:
TFIDF+SVM:该方法使用了TF-IDF为文本构建特征信息,然后使用SVM[19]作为分类器.
CNN[20]:该方法使用了多种过滤器的CNN来提取文本特征信息,最后使用softmax作为分类器.
RCNN[21]:方法灵活地结合RNN和CNN构造了新的模型,利用了两种模型的优点,提升了文本分类的性能.
HARNN[22]:该方法使用了层次化注意力机制的RNN作为文本特征提取器,也使用softmax作为分类器.
FLA[8]:该模型在文本特征提取器中利用注意力机制融入了案例对应的法条信息,进一步提升了罪名预测效果.
TOPJUDGE[23]:该方法框架是通过使用有向无环图结构来捕捉LPJ子任务之间的拓扑依赖关系的拓扑多任务框架.
GCN:该方法创新性提出了可用于节点分类等任务的图卷积网络,取得了良好的效果.
2.4 实验参数设置
本文使用THULAC[24]作为中文分词工具,THULAC是目前针对中文分词效果优秀并且运行速度很快的工具包.对于基于CNN的对比模型,设置了文本的最大长度为512个词,过滤器个数设置为256,针对多窗口CNN模型,分别设置了2,3,4,5的滑动窗口长度.对于基于RNN的对比模型,设置了单句最大长度为64,单个文本数据包含最大的句子个数为64.本文使用的词向量维度设置为200维,使用skipgram[25]方法训练词向量.
本文提出的CP-GAT方法所使用的实验参数,则是选取了实验中最优结果的参数,在图注意力网络中,首先是采用了3层图注意力网络,节点向量维度设置为200维,窗口大小设置为25.在计算注意力分值时,仅计算节点的一阶邻居,在每一层都采用了6头注意力机制来产生节点的输出.实验设置最大轮数为100轮,并且使用Adam(adaptive moment estimation)[25]作为模型训练的优化器,其学习率设置为0.02, Dropout为0.5,L2损失权重设置为0.001.
2.5 实验结果分析
从表2,表3中可得到,本文提出的方法在所有对比指标上都好于对比模型.基于卷积神经网络和基于循环神经网络的方法在对比指标上都要好于传统机器学习模型SVM.而在文本特征信息的提取效果上基于RNN的方法也要好于基于CNN的方法.而TOPJUDGE本质也是基于CNN的框架,只是将多个任务进行了一定程度的关联,从而达到了很好的效果.基于图神经网络的方法在对比指标上全面领先于深度学习和传统机器学习方法,尤其是在宏观F1值这个指标上表现要优秀很多,而宏观F1值在一定程度上也验证了对易混淆罪名的处理能力,本文提出的方法在这个指标上也达到了最优效果,进一步证明了本文模型处理易混淆罪名的有效性.

表2 基于CAIL-N数据集的罪名预测结果
本文也进行了有关模型结构的消融实验,实验结果如表4所示.实验中控制的模型结构变量包括:图卷积层的层数,使用的多头注意力机制的头数.在本文进行的消融实验中,选取了1,2,3,4层不同层数的图卷积结构,4,6,8头的多头注意力机制.从表4中可以看到,当模型采用的层数为3,注意力机制头数为6时,取得了最优效果.

表3 基于CAIL-S数据集的罪名预测结果

表4 消融实验——采用不同层数及注意力头数的 CP-GAT预测结果(CAIL-N)
而由于本文实验用到的数据集是不平衡的数据集,部分罪名样本数量很少,为了进一步验证基于图神经的方法在处理小样本数据方面的优势,将数据集中的罪名按照数量进行了分类统计,分别为数量小于10(罪名个数为49),数量在10到100之间(罪名个数为51),数量大于100(罪名个数为49).实验的对比模型使用了深度学习模型中表现较好的HARNN和基于图神经网络的两个方法,实验结果如表5所示.
由表5可以得到,基于图神经网络的方法处理小样本数据的能力要强于本文选用的基于RNN的对比模型,而本文提出的方法在F1值这个指标上是领先于所有对比模型的,尤其是在样本数量小于10的罪名样本的罪名预测上.以上实验表明,本文提出的方法在小样本罪名预测任务上同样具有很高的有效性.

表5 分类数据集的罪名预测的宏观F1值
本文提出的罪名预测方法CP-GAT效果能够领先于其他对比模型,主要原因在于图注意力网络对于图结构数据的强大建模能力,图注意力网络本身是基于GCN的基础上引入attention思想去计算每个节点的邻居节点对它的权重,从而实现从局部信息去获取到整个网络整体信息,同时通过堆叠隐藏的自注意层能够获取临近节点的有用特征,不仅避免大量矩阵运算,而且可以更加精确获得节点的特征信息.并且CP-GAT也融合了法条信息,法条信息中包含了大量模型可以用到的知识,进一步提升了罪名预测效果.
3 结 语
本文基于图注意力网络提出了一种新的罪名预测方法(CP-GAT),该方法首先通过文本数据构建异质图数据,然后在异质图上使用图注意力网络进行图节点特征学习,得到用于预测罪名的案例节点特征向量,最后通过分类层得到案例所属罪名.通过实验验证,CP-GAT在所有对比指标上都要好于其他对比方法,并且在处理小样本数据上也具有很高的有效性.
以后的研究工作:1)通过改进图神经网络结构更好地提高小样本数据的预测效果;2)更好地结合外部知识以提高罪名预测任务的效果,并使罪名预测任务具有可解释性.
