基于注意力机制的区域小学入学规模预测
2021-12-17雷建军
陈 宇,邢 锐,雷建军
(1.湖北第二师范学院计算机学院,武汉 430205;2.湖北省教育云服务工程技术研究中心,武汉 430205;3.湖北省教育信息化发展中心(湖北省电化教育馆),武汉 430071)
义务教育均衡是我国基础教育的基本政策,合理的配置教育资源是政府教育管理部门的重要目标.学龄人口是各级教育管理部门对教育资源进行配置的主要依据,而每年小学入学规模的变化是区域内学龄人口波动的重要原因.当前,随着我国经济的迅猛发展,城镇化的进程加速,大量的人口从农村向城镇和发达城市迁移,也因此在区域间造成了教育资源需求的变化波动.由于,教育资源比如校舍的建设、教师的培养及配置都需要较长的周期.因此,如何适应人口的机械增长变化,科学预测未来区域内小学入学规模的变化趋势,准确把握区域内教育资源的配置需求,及时对教育资源进行合理配置对提高我国各级教育管理部门的治理能力,促进教育公平,创办让人民满意的教育具有重要意义.
1 入学规模预测方法
目前针对区域内入学规模预测的研究尚少,而入学规模的预测问题是人口预测的一种.因此,对入学规模的预测可参考人口预测的相关研究工作.当前对于人口预测的研究可以分为基于统计的方法和基于机器学习的预测模型.
1.1 基于统计的人口预测模型
现有的人口预测模型大多采用传统的统计模型,国外最早对人口问题进行定量研究的是英国人口学家 Malthus建立了人口指数增长模型Malthus模型[1],随后,荷兰科学家Verhulst对人口指数增长模型进行了修正,把影响人口增长的社会环境、自然环境等相关因素考虑进去提出了logistic 人口阻滞增长模型[2].Leslie提出了一个能够综合考虑多个影响因素的预测模型,即著名的 Leslie 矩阵模型[3],在人口预测领域得到了广泛的应用.
近年来,我国有不少学者借鉴了人口预测的研究开展了学龄人口的预测研究工作.李玲等利用CPPS软件基于人口普查第六次数据,对我国2016—2035年义务教育阶段学生规模进行预测[4];薛耀锋等采用LESLIE人口模型,以全国第六次人口普查数据模拟预测了2016—2025年的我国学龄人口变化趋势[5];周志等针对天津义务教育情况,采用灰色预测模型和线性回归原理对天津市户籍学龄人口的规模进行了预测[6].以上学者针对学龄人口预测普遍采用数理统计方法,如灰色预测、CPPS人口预测、Logistic回归预测以及队列要素法等.但从已有研究表明,采用灰色模型对人口发展趋势做预测,通常只能反映出人口的逻辑增长,无法解释生育率变化及迁移引发的人口规模变动,CPPS人口预测系统中设定的生育率为全国人口普查的全国维度,不适用于省级预测,Logistic模型只适合在短时期内的、较小区域的预测.虽然Leslie矩阵模型,有效解决了上述存在的问题,但Leslie矩阵模型的基本假定是所分年龄组内的人数稳定,但通常情况下分年龄人口数的数据很难获取,使其很难得到大规模应用.
1.2 基于机器学习的预测模型
随着人工智能技术的发展,神经网络模型在求解时间序列预测问题上得到了广泛的关注.在人口预测的问题上,Folorunso等在其论文中使用了具有反向传播的前馈人工神经网络对人口进行了预测[7],Tang在其论文中证明了采用神经网络的方法在预测人口方面比Logistic回归预测模型更有效[8].我国的谭永宏采用神经网络理论来建立了基于 BP 神经网络的人口预测模型,较好地表现了人口增长的非线性动力学的特点,其预测结果具有较高的精度[9].Zhan在其论文中使用了LSTM-RNN模型较好的解决了人口时间序列通常较短的问题[10].近年来,在旅游人数预测和交通流量人口预测等特殊场景下,Shi采用了神经网络预测了某地每年的旅游人数变化,取得了较好的效果[11],上述模型虽然为预测入学规模提供了思路,但都是基于一个特征的建模预测,没考虑入学规模在实际中和各地经济、人口等相关特征的关联关系,得到的预测结果会存在一些片面性.Berry的研究表明在影响人口变化的因素方面,许多社会和自然因素与人口趋势相互作用,如人口总量和经济增长具有较强的相关性[12],Goldstein的研究得出了区域内生育率与经济的关系[13].
随着我国统计数据的逐步完善,各年度学龄人口数、经济、人口数据逐渐开始累积,本文通过构建包含经济、人口等相关参量的多元时间序列来避免单一变量预测的局限性,挖掘学龄人口与各地经济、人口等相关特征和时序关系.与此同时,为了充分利用特征间的关联和时序间的依赖关系,本文在时间序列模型长短时记忆网络 (long short-term memory,LSTM)的基础上引入注意力(ATTENTION)机制.提出了基于ATTENTION-LSTM的小学入学规模预测模型,利用注意力机制对多元时间序列不同特征不同时刻的特征值描述其对待预测指标的权重,提取特征在历史时间点与待预测指标之间的关系,提高小学入学规模 预测模型的精度.
2 问题定义

本文研究的问题可以表示为给定包含n个外部时间序列在t—1时刻的值预测某个目标序列在t时刻的值,通过学习得到它们之间的非线性关系.即:
(1)
式中,y=(y1,y2,…,yT-1)是目标序列,F函数就是准备利用深度学习的函数.
3 基于注意力机制的循环网络学龄人口预测模型设计
利用多元时间序列对学龄人口进行预测问题,一个重要的挑战是如何捕捉多变量之间的不同时间步的依赖关系.但是循环神经网络由于本身结构问题很难捕捉到这种依赖关系,因此,我们引入了注意力机制,同时,由于LSTM在时间序列预测上的良好表现,选择了LSTM模型作为循环神经网络单元构建了ATTENTION-LSTM模型对学龄人口进行预测.
3.1 长短时记忆网络
长短时记忆网络 (LSTM)是一种特殊的RNN结构,由Schmidhuber教授于1997年提出,在许多时序预测的研究中,LSTM模型都取得了很大的成功,得到了广泛的应用[14].传统的循环神经网络RNN在修正权重的过程中,面临梯度爆炸或梯度消失的问题.而LSTM对有意义的信息通过引入细胞状态进行保存,并通过“遗忘门”“更新门”“输出门”增加或者去除权重到细胞状态中,从而能够有效解决梯度爆炸或梯度消失问题.
3.2 注意力机制
注意力机制是利用了人们视觉在处理图像时,对关注的信息能够自我增强同时抑制其他无效信息,从而派生出一种从大量信息中自主选择最关键信息的一种信息处理方式,其已在深度学习里的语音识别、自然语言处理和图像描述等多个领域里取得了良好的效果[15].近年来,随着其应用的发展也逐渐应用于时间序列处理上.
注意力机制在时间序列上的应用主要由编码器和解码器两部分组成,编码器负责计算时间序列在某时刻上各特征的注意力权重,权重代表了各特征在某时刻对当前预测指标的重要程度,输入时间序列的所有特征值权重和为1,以注意力权重对初始输入的时间序列进行加权产生新的时间序列向量;解码器利用循环神经网络等时序分析模型对新的时间序列向量以及预测目标历史信息进行综合处理,得到当前的近似输出,注意力机制模型公式如下:
αt=fattetion(x),
(2)
ct=αtx,
(3)
(4)
其中,fattetion为权重函数.
3.3 基于注意力机制的输入序列编码器
基于上述原理,本文通过采用注意力机制分别学习人口、经济等相关指标的时间序列中各时间点的特征值对待入学规模的重要程度,以进一步提升待预测入学规模的预测质量.ATTENTION-LSTM模型结构图如图1所示.

图1 ATTENTION-LSTM结构图Fig.1 Architecture of ATTENTION-LSTM Model

(5)
(6)

(7)
(8)
(9)
(10)
LSTM的细胞状态和隐藏状态由下面两个公式进行更新:
(11)
(12)
其隐藏状态由下面公式更新:
(13)
编码器输出t个时间步的隐藏单元的状态值.上述式中,Wf、bf、Wi、bi、Wc、bc、Wo、bo分别为遗忘门、输入门、输出门和门控单元的权重和偏置.
3.4 基于注意力机制的解码器
模型同样使用了LSTM单元进行解码,为了克服LSTM随着时间步数的增长而带来的权重下降的问题,在解码阶段同样也引入了注意力机制,对于编码器输出的单元含有t个时间步的编码器隐藏状态进行相应的解码工作.
(14)
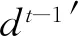
(15)

(16)
以环境变量和目标序列t时刻的值为解码器的输入:
(17)
解码器的三个门的更新公式为:
(18)
(19)
(20)
其细胞状态由以下公式更新:
(21)
(22)
隐藏细胞的更新公式为:
(23)
预测结果:

(24)
式中,Wy、bw、bv为权重系数和偏置参数.
4 实验结果与分析
4.1 实验平台及数据集说明(预处理)
本文全部数据来源于国家统计局网站(http://data.stats.gov),选取了31个省(区、市)的1978—2017年的年度数据构建多元时间序列数据集.其中选取指标普通小学招生数为预测指标,人口出生率、年末常驻人口数、居民消费水平指数为相关序列,反映预测指标小学入学人数与人口、经济等指标的相关性.
对于多元时间序列数据集通过设置滑动时间窗口大小进行重新划分,对于缺失数据,取相邻的两个数据的平均值填充,所有时间序列的值采用最大-最小归一化的方法进行预处理,经过预处理所有数据取值范围在[0,1]之间.
训练集和测试集的划分采用截断法,选取31个省市自治州的1978—2011年的数据作为训练数据构造训练数据集,2012—2017年的数据作为验证数据集.
4.2 评价指标
为了对预测模型进行评价,采用平均绝对误差(mean absolute errors,MAE),均方误差(root mean square error,RMSE),平均绝对百分比误差(mean average percentage error,MAPE)三个评价指标来评定预测模型的准确性.
(25)
(26)
(27)

4.3 入学规模预测模型训练和性能分析
根据前述入学规模预测模型的训练原理,本文的模型使用python 3.6、tensorflow 2.0、keras实现.tensorflow是谷歌公司开发的一个开源机器学习库,用于辅助构建和部署机器学习模型.Keras是一个神经网络API,具有界面友好、模块化、可扩充的特点,并支持Tensorflow,本文以Tensorflow作为后端.
模型参数由两部分组成,一部分为普通参数,包括注意力的权重系数、LSTM各隐藏单元的权重系数及全连接层内的连接参数和权重,这部分参数通常用模型通过梯度算法求得最优解,另一部分为超参数,主要包括:
1)训练迭代次数epoch:模型训练完整的数据集次数.通常根据经验所得;
2)训练块大小batch_size:一次输入模型训练的样本个数;
3)训练学习率learning_rate:通过调整学习率可调整各权重的超参数,学习率越低,收敛速度越慢,但精度较高,学习率越高,收敛速度越快,但易陷入局部最优解;
4)隐藏层数和神经元个数cells:这两个参数直接确定整个神经网络的基本结构,层数越多,神经元越多,参数就越多,模型训练所花时间就越长.
5)时间窗口宽度windows:通过设置 时间窗口宽度限定时间序列的长度.
为了能够取得较好的超参数,我们采用网格搜索方法对训练块大小batchsize、学习率learningrate、时间窗口宽度、隐藏层数和神经元数进行优选.首先,固定训练迭代次数 epoch=300随机种子数 seed=1;训练块大小batchsize=32等非关键参数值,然后,设定三个参数的取值范围:历史数据时间窗宽度 windows={4,6,8,10,12},LSTM 细胞数cells={64,128,192,256},学习速率learningrate={0.001,0.003,0.005,0.01,0.03,0.05};以均方根误差(RMSE)值最小为测试集上预测精度最高,以此进行相关参数优选.实验记录入学规模预测模型在不同参数组合下的仿真结果,由于篇幅所限,以下列出学习率learing_rate为0.001,0.01,0.05的仿真结果.
图中,颜色较浅代表RMSE越大,图2中,颜色普遍较浅,说明当学习率为0.01时,RMSE较大.根据图3和图4可知,当神经元个数cells较大及时间窗口windows长度偏小时,RMSE值较好,模型精度较高.参数寻优结果中5组最优的参数组合及对应的RMSE如表1所示.

图2 参数寻优(learning_rate=0.01)Fig.2 Parameter optimization (learning rate=0.01)

图3 参数寻优(learning_rate=0.001)Fig.3 Parameter optimization (learning rate=0.001)

图4 参数寻优(learning_rate=0.05)Fig.4 Parameter optimization (learning rate=0.05)
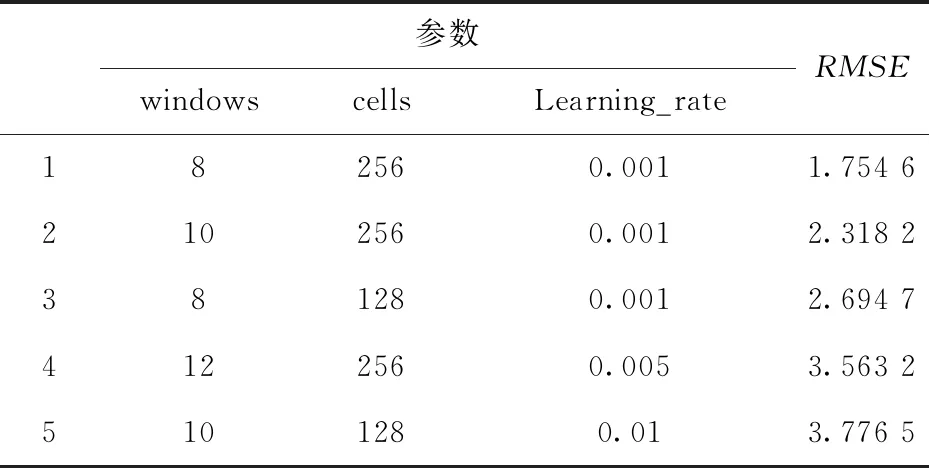
表1 最优参数组合及RMSE对应表Tab.1 Optimal parameter combination and RMSE correspondence table
通过参数优选最后选取的相关参数为windows=8,cell=256,batchsize=32,learning_rate=0.001.
4.4 对比方法
为了进一步验证本文的ATTENTION-LSTM模型在提升入学规模预测的有效性,将本文中的模型与传统基于统计的时序预测算法历史平均模型(HA)及整合移动平均自回归模型(ARIMA)及不带 ATTENTION机制的长短周期记忆网络LSTM模型进行比较.其中传统的LSTM模型包括两层LSTM层以及一个全连接层.HA模型使用三个历史时间段的入学规模平均值作预测.ARIMA模型通过序列的一阶差分进行预处理,根据AIC准则定阶P、Q的值分别为3和1.
图5 给出了四种模型分别对某省市2012—2017年入学规模的预测结果.

图5 入学规模预测模型比较Fig.5 Comparison of enrollment scale forecasting models
从图中可知,对于入学规模变化的规律,四种模型都能够对未来年份的入学规模进行一定的有效预测,但ARIMA模型和HA 模型与真实曲线存在较大偏差;LSTM 模型曲线除某阶段效果较差以外,其余预测效果较 HA模型 有大幅提升.ATTENTION—LSTM 模型与真实曲线形态最为接近.
四种模型分别在测试集上进行10次实验后的平均结果如表2所示.
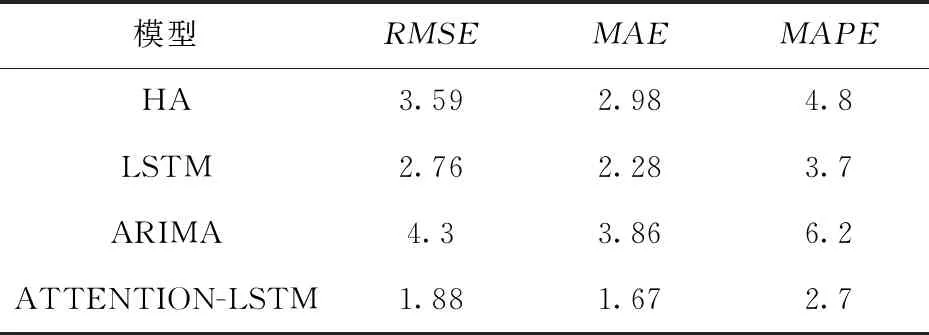
表2 模型测试集结果对比表Tab.2 Comparison of model test set results table
实验结果表明,ARIMA和HA 模型两种传统的统计时序预测模型由于没有考虑复杂的非线性序列变化规律,主要还是应用于时序平稳的场景,因此,实验精度相对最差.LSTM模型作为非线性时序预测模型可以通过细胞的状态来解决时间序列数据的长期依赖问题,保留预测变量变化的长短期变化规律,各项指标对比有所提升,但由于其只利用单个时间序列数据训练,无法挖掘其他因素如人口、经济等对区域内入学规模人数的影响.而ATTENTION—LSTM模型与其他模型比较更贴近实际结果,在所有测试集中MAE、MAPE、RMSE三个指标的值均优于其它模型.
5 结束语
小学入学规模预测对我国区域内义务教育工作具有重要意义,传统基于统计的时序预测方法由于无法描述学龄人口会随经济条件造成的人口迁移、生育政策影响等产生不规则的波动关系,难以取得较好的效果.本文利用机器学习,根据学龄人口时间序列的时序特征,结合人口因素、经济因素等相关时间序列,建立了一种基于Attention-Lstm网络的区域小学入学规模预测模型,利用Attention机制为不同的输入特征赋予权重,以突出对小学入学规模预测起到关键作用的特征,通过实验表明本文提出的模型能够充分挖掘人口、经济等因素于小学入学规模中规律的信息,具有较好的鲁棒性,比传统的时序预测方法具有更好的准确率,提高了中长期预测的精度,有助于教育管理部门更好的提前进行布局和规划.
