一种基于协同训练半监督的分类算法
2021-12-17李延晖
王 宇,李延晖
(华中师范大学信息管理学院,武汉430079)
从PC时代到移动互联时代,从移动互联网到产业互联网,各行各业的数据正以前所未有的速度在累计,大数据受到越来越多的关注.在由数据驱动的情报创新研究中,如:情报分析与智能服务、信息行为与用户画像、信息可视化与社交媒体信息传播等,众多学者已经进行了全面深入的研究.其中大多数研究是以文本内容为主并且已经形成了成熟的框架体系[1].图像作为一类重要的信息载体,相比文本而言具有生动形象,直观清晰的特点,同时蕴含着更加丰富的信息,对这些海量的图像数据进行挖掘利用对于具有很重要的价值.已有学者在网络舆论监测、情感识别、推荐系统、隐私保护、信息检索等方向取得一些成果,如:詹必胜等针对数字图像文件设计出一种新的舆情信息安全体系[2].曾金等对网站新闻图像情感倾向进行了分析研究[3].陈芬等提出了一种视觉情感识别模型,并实现了通过图文结合的方式向用户推荐符合其情感需求的电影[4].王树义等构建出了社交网络图像隐私自动分类器,可以对社交媒体用户进行隐私暴露预警提示[5].包翔和刘桂锋提出一种基于特征包的图像检索系统框架,并通过数字图书馆的图像资源进行了实证检验[6].相比于较为成熟的文本数据分析,利用图像进行科学研究还有很大的空间.
随着互联网数据的大爆发,获得大量未标记样本变得越来越容易,相反地获得有标记样本却变得越来越困难.半监督学习(semi-supervised learning)[7]可以将少量有标记样本和大量未标记样本有机地利用起来,利用未标记样本数据中蕴含的有用结构信息辅助学习,不仅可以解决标记样本不足的现实问题,而且可以有效提高分类器的性能,提升分类的精度和效率.本研究提出一种基于半监督学习的分类算法,利用少量标记样本数据作为初始训练样本,使用大量未标记的样本辅助学习,提高分类器的泛化性能,实现分类精度的提升,希望能为情报信息领域的数据分析提供一定的借鉴意义.
1 相关研究综述
半监督分类主要使用大量的无标签数据来提高分类器的性能和泛化能力,在文本分类、图像处理、医学诊断和感兴趣信息推荐等领域中有广泛的应用,主要有四种主流类型[8],包括基于生成式模型的方法、半监督 SVM 方法、基于图的方法和基于分歧的方法.
一般认为,半监督学习的研究开始于Shahshahani和Landgrebe[9],首次提出了半监督学习的概念,并通过建立未标注数据和学习目标之间的联系,提升了学习的泛化性能.李宁宁[10]使用半监督协同训练方法进行文本感情分类,利用未标记的数据,选取电子商务和医疗社交媒体两个应用领域,证明半监督协同训练方法在不同数据分布情况下取得了较好的效果.李村合等[11]使用半监督支持向量机对E-MIMLSVM+算法进行改进,利用少量有标签样本和大量没有标签的样本进行学习,有助于发现样本内部隐藏的结构信息,证明改进后的算法有效提高分类器的泛化性能.高飞等[12]提出了基于样本类别确定度(CSS)的半监督分类算法,利用SAR图像测试,证实利用少量标记样本实现分类精度优于监督分类.赵建华[13]采用3个分类器作为基础分类器,使用无标记样本的信息辅助学习,增强分类器的差异性,同时保证较小的分类器分别分类误差.韩彦岭等[14]结合主动学习和半监督学习,筛选出最优代表性的半标签样本,应用于海冰图像分类,实现了较高的分类精度,有效的解决了遥感海冰分类样本少的问题.戴斌等[15]提出多类型文本的半监督性别分类方法,基于微博产生的不同类型的文本对用户的性别进行分类,使用协同训练的半监督学习方法,利用未标记样本数据辅助学习,实验结果表明其优于其他现有的半监督性别分类算法.刘欣媛[16]利用半监督学习自动标注语音数据,然后使用按需加权决策树分类优化模型,实现了在小样本的训练数据情况下,实现了较好的准确性.在图像分类领域,半监督结合深度学习的算法[17-18]也受到广泛的关注,由于其在少量标注的样本数据情况下借助大量无标记数据可以实现较好的分类精度.
相较于一般的协同训练,本文方法主要在样本正确性判别和多样性增强方面进行了如下改进:1)利用了两个分类器的预测标签一致作为高置信度的判断条件;2)同时引入确定度阈值作为约束条件,在确保样本高置信度的前提下,筛选出更具有代表性和多样性的样本,提高分类器的泛化性能.以手写数字数据和Landsat土壤数据作为数据集的实验表明,本文提出的基于多分类器协同的半监督样本选择方法可有效提高分类器的泛化能力,提升分类的精度.
2 研究方法和过程
2.1 半监督学习
半监督学习(semi-supervised learning,SSL)的主要思想是在少量标记样本情况下,通过引入大量的未标记样本数据辅助模型学习,以避免模型在训练集上出现过拟合等情况,解决监督学习模型泛化能力弱的问题.
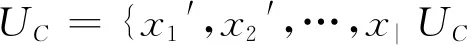
因此,半监督分类就是利用U和UC构造一个尽可能反映样本特征和标签真实关系的分类器,由贝叶斯公式可得:

(1)
后验概率P(yi│x)代表在输入样本特征x的条件下,其标记为yi的概率,其值越大,表明该样本真实标签是yi的可能性越大.先验概率P(yi)和P(x|yi)可以从标记样本集U中统计得到.当我们有大量未标记样本的时候,可以使得计算得到P(x)更加精确,使得最后求得的后验概率P(yi│x)更为精确,相应的分类器的泛化性能也得到提高.
Miller等[19]在1996年从理论上证明了未标记样本可以在分类过程中影响分类器的性能.虽然无标记样本没有包含样本的标签信息,但其有与标记样本相似的特征信息分布,可以有效辅助模型识别类别.图1显示了无标记样本辅助模型提升泛化能力的直观示例.类别A和B是两个类别,有标记样本和未标记样本,当仅使用有标记样本建立分类器时,分类器决策边界为红色虚线,而加入未标记样本后,分类模型的决策边界根据样本的分类密度重新调整(黑色实线),决策边界向右移动,使得分类器的泛化能力提高.
2.2 分类算法
2.2.1 支持向量机(support vector machines,SVM) SVM是由Vapnik[20]领导的AT&T Bell实验室研究小组在20世纪60年代提出的一种新的监督分类技术.SVM是一种基于统计学习理论的新型机器学习方法,以结构风险最小化为理论基础,其本质的思想是核函数方法,其被广泛应用于解决小样本、高维度、非线性和局部极小值等领域[21].
SVM通常用来分析线性问题,对于线性不可分问题可在高维空间内转化为线性可分问题,构造最优分类面.其目标就是要根据结构风险最小化原理构造目标函数,将样本尽可能地区分开来,通常分为两类情况来讨论:
1)线性可分.在线性可分的情况下,存在一个超平面使得训练样本完全分开.分割超平面可描述为:
ωTx+b=0,
(2)
其中,ω是n维法向量,可以决定超平面的方向,b为偏移量,决定超平面与原点之间的距离.由于超平面是由法向量ω和位移b共同决定的,可将超平面记为(ω,b).
样本集中的样本x与分割超平面的距离r可表示为:
r=|ωTx+b|/‖ω‖.
(3)
最优超平面是使得支持向量与超平面之间的距离和最大.
2)线性不可分.对于线性不可分的情况,SVM引入核函数,其可以将输入特征空间中的线性不可分问题转化为高维空间中的线性可分问题,极大的提高分类器对非线性问题的处理能力.其次,高维空间中的内积运算均是通过原空间中的核函数来完成的,所以转换为高维空间后只是改变了内积运算,并没有增加算法的复杂度[22].
2.2.2 随机森林(Random Forest,RF) RF算法主要是通过集成学习的思想将多个决策树分类器集成到一起,对于每一个输入的训练样本,随机森林都会产生N个分类预测结果,通过众数投票得到最后的识别结果.随机森林和Bagging算法类似,但是RF算法采用随机选择属性方法,先从特征集中选择特征子集,再根据每个决策树选择最优属性.RF算法结合多颗决策树,然后采用投票策略,相比于单一决策树,其泛化能力得到很大的提升.
RF算法的流程如下:
① 利用Bootstrap从样本集中随机选择T个训练集,S1,S2,…,ST;
②使用以上的训练集生成决策树C1,C2,…,CT,从K个属性中随机选择的k个属性(k ③T颗决策树形成随机森林,通过投票表决形成最终的预测类别,具体投票的时候,得票最多的类别为随机森林的最终结果: (4) 其中,H(x)表示最终的输出结果,hi(x)表示单个决策树,I表示示性函数,Y表示输出变量. 2.3.1 算法输入 1)使用两个分类算法作为监督算法,分别是SVM(支持向量机)和RF(随机森林),用于协同训练; 2.3.2 算法步骤 协同训练得到增强样本集的算法过程如下(流程如图2所示): 图2 样本增强算法流程 Fig.2 Sample enhancement algorithm flow ①样本在两个分类器中的预测标签一致: (5) ②样本si在两个分类器中的确定度满足: (6) 其中,Cersik代表样本si的基于分类器k的确定度,其值等于分类器预测某个样本属于各类别后验概率中的最大值与次大值之差,表示某个样本属于这一类别的可能性,值越大,表明分类器对该样本的预测越准确;当采用确定度和后验概率分别从候选无标签样本中选择高置信度样本时,确定度作为置信度判别标准,可以剔除分类器类别交界处低置信度的样本,筛选出可信度高的样本;ρ为设定的确定度阈值,需要人为调整. (7) (8) 5)剔除候选样本集中的增强样本: (9) (10) (11) 7)最后的增强样本集: (12) 其中,T为最后的迭代次数,D为最终半监督方法的增强样本集. 本算法采用了SVM和RF算法协同训练,采用了预测标签一致性和高确定度作为样本正确性的判别标准,加入了确定度最小值约束筛选出更加多样性的增强样本. 为了证明算法的有效性,采用Mnist数据集[23]和Landsat土壤数据集作为训练测试的样本集.Mnist手写数字示例如图3所示,总共有70 000个样本,每一个样本是28×28像素大小的图像,数值(整数)范围在0~255之间,标签为0~9,各个数字比例如表1所示,数据下载网址:http://yann.lecun.com/exdb/mnist/.Landsat. 表1 Mnist数据集说明Tab.1 Description of Mnist data set 图3 Mnist字符库部分样本Fig.3 Some samples of Mnist character library 土壤数据集共有6 435个标记样本,每个样本有一个土壤标签和与之对应的36个属性.数据集中采用3×3邻域中9个像素的多光谱值作为属性值,每个邻域中的中心像素的类别标记为场景的类别.数据集共含有6个类别,各类别比例及含义如表2所示,数据下载及详细介绍的网址:http://archive.ics.uci.edu/ml/datasets.php. 表2 Landsat土壤数据集说明Tab.2 Description of Landsat soil data set 本实验中,Mnist数据集和Landsat土壤数据集的每一类别训练样本分别为60个和200个,测试样本分别为1 000个和200个,其余样本剔除标签作为候选样本集.为了保证本算法的科学性[24],使训练样本和测试样本的概率分布一致,训练样本和测试样本均采用随机选择的方法得到. 对于半监督样本增强效果的评价,主要是考量增强样本集是否使得分类器泛化性能提高,因此,一般采用监督分类对测试样本集预测结果,并进行精度评价.监督学习采用两个分类器(SVM和RF)投票得到最后的预测标签,具体投票规则如下: (13) 该投票思路是分类器预测样本得到确定度大的预测标签即为最终的投票预测标签. 本文基于准确率(accuracy)评价训练样本对分类器泛化性能的影响,精度越大,表明构建分类器模型泛化性能越好.对于给定的测试集,准确率等于分类器正确预测样本数与测试集总样本数之比: (14) 其中,TPi是指被分类器正确分类的测试类别i的样本数目,n是总类别数,P是测试样本总数. 3.3.1 半监督学习结果 根据提出的算法,本实验设置如下参数:确定度变化阈值ε=0.01,确定度最大阈值ρmax=0.7,最小阈值ρmin=0.3.候选样本集的平均确定度随着迭代次数变化结果如图4所示.图4(a)和(b)分别表示了Mnist数据集和Landsat土壤数据集的确定度变化情况,可以看到随着迭代次数的增加,两个数据集的平均确定度在逐渐增加,且初始迭代时的增量较大(最大值分别为0.037和0.047),后续迭代过程中逐渐趋于稳定,当确定度增量(分别为0.005和0.006 3)小于预设值0.01,停止迭代.确定度随着迭代次数由快到慢的逐渐增加,表明随着分类器不断的学习,由增强样本构建的分类器模型对未标记样本预测置信度逐渐增加.为了验证半监督学习对分类器泛化性能的提升,用每一次迭代得到的增强样本构建分类器,预测测试集标签并计算精度,得到图5所示结果.从图5中可以看出,随着迭代次数的增加,分类器预测准确率在两个数据集上均呈现逐渐增加趋势,而且开始时增加速度较快,反映了分类器的泛化能力随着半监督学习过程逐渐提升. 图4 候选集样本平均确定度变化((a)数据集,(b)数据集)Fig.4 Changes in the average certainty of the candidate set samples ((a)Mnist data set,(b)Landsat data set) 图6显示了两个数据集中增强样本数目的变化,经过初次迭代后,Mnist数据集样本总数由600增长到12 398,而Landsat土壤数据集样本总数由1 200增长到1 703,随着迭代次数增加,增长速度逐渐变慢.由图5和图6的对比分析可以发现,增强样本数目和模型准确率变化趋势一致,主要是由于增强样本开始时的快速增长,导致样本多样性增加,进一步使得构建分类性能提升,后面增强样本的数量趋于稳定,其所构建模型的准确率也平稳变化,趋于稳定.为了更直观地验证半监督学习的效果,图7对比了两个数据集中原始训练样本和增强样本构建分类器分别预测测试集样本的准确率,发现全部类别的准确率都得到提升.两个数据集的总体准确率分别提升5.97%和7.02%,Mnist数据集中数字5这类准确率提升最高(提升11.9%,从79.3%到91.2%),Landsat土壤数据集中土壤3这一类准确率提升最明显(提升15.8%,从73.5%到89.3%),说明本文提出的协同半监督方法可以有效利用未标记样本,在多个数据集上实现分类器泛化能力的提升. 图5 增强样本构建模型的精度变化((a)数据集,(b)数据集)Fig.5 Accuracy changes of the model built by enhanced samples ((a)Mnist data set,(b)Landsat data set) 图6 增强样本总数变化((a)数据集,(b)数据集)Fig.6 Changes in the total number of enhanced samples ((a)Mnist data set,(b)Landsat data set) 注:OA为所有类别总的准确率.图7 半监督学习对分类器预测精度提升((a)数据集,(b)数据集)Fig.7 Semi-supervised learning to improve the prediction accuracy of the classifier ((a)Mnist data set,(b)Landsat data set) 3.3.2 最大确定度和分类类别数目对准确率的影响 为了探究最大概率和分类类别数对本方法的影响,做了如下研究:1)以0.1的间隔调整最大确定度值,探究确定度对最终分类器准确率变化的影响;2)将Mnist数据集分类类别减少为5类(原始类别的一半),探究对最终分类器准确率变化的影响. 表3显示了两个数据集中随着最大确定度ρmax的变化,由增强样本构建分类器的准确率和增强样本数变化.由图可知当ρmax分别为0.5和0.6时,两个数据集的分类器准确率均有最大值,ρmax为0.9时,分类器准确率最小,增强样本数最少.最大确定度阈值越大,表明筛选条件越严格,增强样本数也就越少,这样对未标记样本的利用就少,因此对最终分类器的准确率提升有限;但是随着最大确定度阈值的降低,更多的样本会被纳入到增强样本中,同时也有一些错误样本筛选进来,导致分类器的准确率降低.因此,选择合适的筛选准则对分类器泛化性能提升有一定的影响. 表3 最大确定度对分类准确率的影响Tab.3 The influence of maximum certainty on classification accuracy 图8显示了基于Mnist手写数据集中5个类别的半监督学习结果,利用增强前后的样本分别构建SVM和RF分类器,然后采用确定度投票得到预测结果计算精度.图8显示所有的类别准确率都得到提升,同样数字5这一类变化最大,准确率提升了13.6%,总体的准确率提升6%,与10个类别的效果相差不大.由于类别较少,分类任务简单化,故原始样本和增强样本得到准确率都比10个类别的高.通过以上分析,可以得出分类任务中类别数目的变化对分类器泛化能力提升的影响较小. 图8 分类器预测准确率变化Fig.8 The change of classifier's prediction accuracy 3.3.3 对比实验分析 为了验证本研究提出算法的有效性,本研究将提出的算法与常用的监督算法和半监督协同学习算法进行对比实验.监督算法采用K最邻近分类(K nearest neighbor,KNN),半监督学习算法采用Co-training和Co-forest作为对比算法.K最邻近分类算法是较为成熟的监督学习算法[25],其基本运算思想是首先确定分类的最终类别数目,并确定特征空间,然后以待分类对象和训练集样本之间的距离作为判别标准,确定该待分类对象的k个最近“邻居”,最后通过各个邻居的类别判断待分类对象的类别. 半监督学习中,Co-training和Co-forest是比较常见的半监督协同学习算法.Co-training的基本思想[26]是利用两个分类算法根据数据集的不同视图分别构建有分歧的分类器,实验中采用SVM和RF作为基分类器,然后从未标记样本中选择一定数目置信度高的样本增加到对方分类器的训练样本中,不断迭代更新分类器,直到分类器不再变化.Co-Forest采用了集成学习的方式[27],以随机树作为基分类器的集成分类器,可以使未标记数据的置信度以更简单有效的方式计算.对于单个基分类器hi(i∈{1,2,…,N}),它的协同分类器集合是Hi(除hi之外的所有子分类器).在迭代协同学习过程中,Hi可以将高置信度的未标记样本不断加入到基分类器hi训练样本中,从而提高基分类器hi的整体性能. 图9显示了不同分类方法在两个数据集上的精度表现,KNN算法没有进行样本增强,仅利用了原始样本进行了分类;而Co-training、Co-forest和本研究提出的算法均对原始样本进行了增强,图中所示的准确度是基于增强样本的构建分类器得到的.如图9所示,不同方法在两个数据集中具有相似的表现,其中KNN仅利用了原始样本集,因此,构建的分类器的泛化性较差,精度为各个方法中最低;而三种半监督方法由于利用了候选集中的未标记样本信息,经过样本增强后,分类精度都有较大的提升.本研究提出的算法具有最高的精度表现,在Landsat土壤数据集和Mnist手写数据集上较Co-training分别提升4.97%和3.24%,较Co-forest分别提升3.64%和2.81%,进一步说明本研究提出算法的优越性.通过分析两个数据集在不同方法的表现,可以发现各方法在Mnist数据集的精度高于Landsat土壤数据集,主要的原因是Landsat数据集类别均为土壤,区分难度较大,导致各分类算法的精度相对较低. 图9 不同方法的分类方法精度对比Fig.9 Comparison of accuracy of classification methods of different methods 对图像数据的分类算法研究对经济社会和科学研究都具有重要意义,本文研究了一种半监督学习的样本增强分类算法.利用两个分类器协同训练,以手写数字和Landsat土壤数据作为测试数据集,通过多分类器预测标签一致性和确定度约束两个筛选规则,从未标记样本集中筛选出最有代表性的样本构成增强样本集,以准确率为评价标准,验证本算法对分类器泛化性能的影响.通过实验,可以得到如下结论. 1)本文利用多分类器协同训练,对未标记样本预测标签和类别确定度进行约束处理,可以保证筛选出样本的可靠性和多样性,并实现了对分类器泛化能力的提升. 2)对未标记样本确定度取不同阈值,会影响增强样本的正确性,进而影响构建分类器的准确率. 3)分类任务中类别的数目变化对半监督学习效果影响很小. 4)通过与KNN、Co-training和Co-forest算法的对比实验,可以发现本研究提出的算法获取的增强样本在分类精度上有较明显的优势. 在后期的工作中,可以进一步探究在少样本的情况下,利用半监督算法得到的增强样本在深度学习算法中的应用,因为深度学习需要大量的训练样本,同时也有一定的容错能力,故可以探究利用半监督学习和深度学习结合对分类准确率的提升效果.2.3 样本增强算法流程



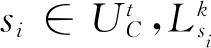

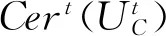

3 实验及结果分析
3.1 数据集



3.2 算法评价指标

3.3 结果及分析







4 结论
