基于改进SPPnet的YOLOv4目标检测
2021-12-17杨海舟李丹
杨海舟,李丹
(四川大学锦城学院,四川成都,611371)
0 引言
随着时代的快速发展,目标检测的应用在现代生活中占据了较大比重。如何快速而准确的实现目标检测也成为了一个现阶段的实际问题。现阶段,基于深度学习的目标检测算法可分为两类:Two-stage[1-3]和 One-stage。
第一类是,以R-CNN[1]系列为代表的Tow-stage检测算法,该类算法将检测过程分成两个阶段,先利用边界搜索生成预选框,再利用卷积神经网络实现分类和回归。该类算法虽然增强了精度,但其检测速度较低。第二类是,以YOLO为代表的One-stage检测算法,该类算法通过使用回归模型,将目标定位和分类一体化处理,可以直接获得结果,该类算法的最大特点是拥有较高的速度,而精度相对较低。在精度和速度之间获得更好的平衡,成为衡量目标检测模型综合性能重要的标准。YOLOv4(You Only Look Once)作为YOLO系列网络的最先进的工作,YOLOv4 网络的检测准确率 以及运行速度都远远高于 YOLOv3 网络。其结合了众多目测检测的tricks,完美实现了检测精度和速度的平衡。
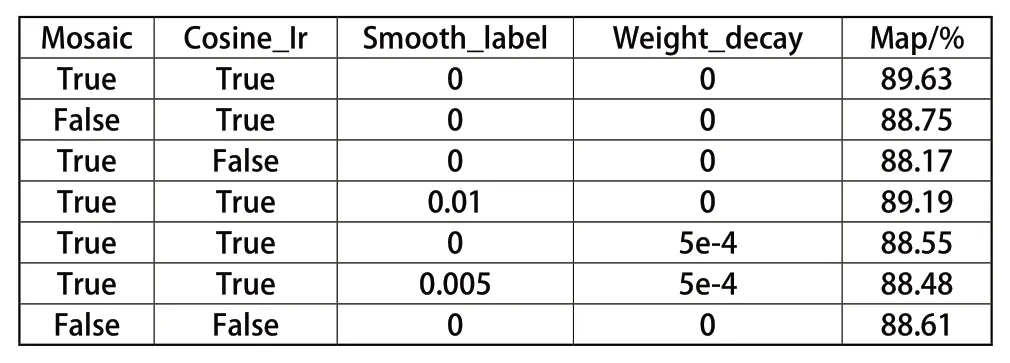
表 1 tricks使用及结果对比
YOLOv4的网络结构有四个重要部分组成,分别是:输入(Input)、主干(Backbone)、颈部(Neck)和头部(Head)。输入(Input):主要包括Mosaic数据增强、cmBN、自对抗训练(SAT)。Mosaic数据增强采用4张图片随机处理的方式进行拼接,这增强了对目标的检测,并且由于目标减少,所以也降低了训练成本。自对抗训练(STA)作为一种新型的数据增强方式可以改善学习的决策边界中的薄弱环节,提高模型的鲁棒性。主干(Backbone):采用的CSPDarkNet53作为主干网络,代替了之前的DarkNet53。增强了模型的学习能力的同时也解决了梯度消失问题。并且采用了Mish激活函数,使网络具有更强的准确性。颈部(Neck):目标检测网络在主干网络(Backbone)和最后的输出层之间插入的一层。颈部网络采用了空间金字塔池化(Space Pyramid Pool, SPP)模块和路径聚合网络(Path Aggregation Network, PANet)的结构。主要是用于对特征进行融合。SPP网络作为Neck的附加模块,采用四种不同尺度的最大化操作:1×1,5×5,9×9,13×13,对上层输出的feature map进行处理,再将不同尺度的特征图进行Concat操作。该模块显著的增加了主干特征的接收范围,并且将上下文特征信息分离出来。FPN+PAN结构,FPN是自顶向下,将高层的特征通过上采用的方式进行传递融合,得到进行预测的特征图。而Neck这部分,除了FPN外,还在此基础上添加了一个自底向上的特征金字塔,其中包含两个PAN结构。避免了在传递的过程中出现信息丢失的问题,提高了网络预测的准确性。头部(Head):沿用了YOLO-v3的多尺度预测方式。对图像特征进行预测,生成边界框和并预测类别。在损失函数方面,其损失函数由三部分组成,分别为:预测框回归误差、置信度误差、分类误差。其中预测框回归误差不再使用YOLO-v3的均方误差,而是采用的CIoU损失。
1 基于改进的SPPnet的YOLOv4
■1.1 模型结构
在YOLOv4的主干网络后使用了SPPnet,但漏检等情况并未得到有效的改善,为此本文在YOLO head2前增加了使用不同大小池化核的SPPnet(命名为SPP-1),同时为了保证SPPnet的网络的通道数在引入前后保持数量一致,故在SPP-1后使用了cocat和卷积层。改进后的模型结构如图1所示。
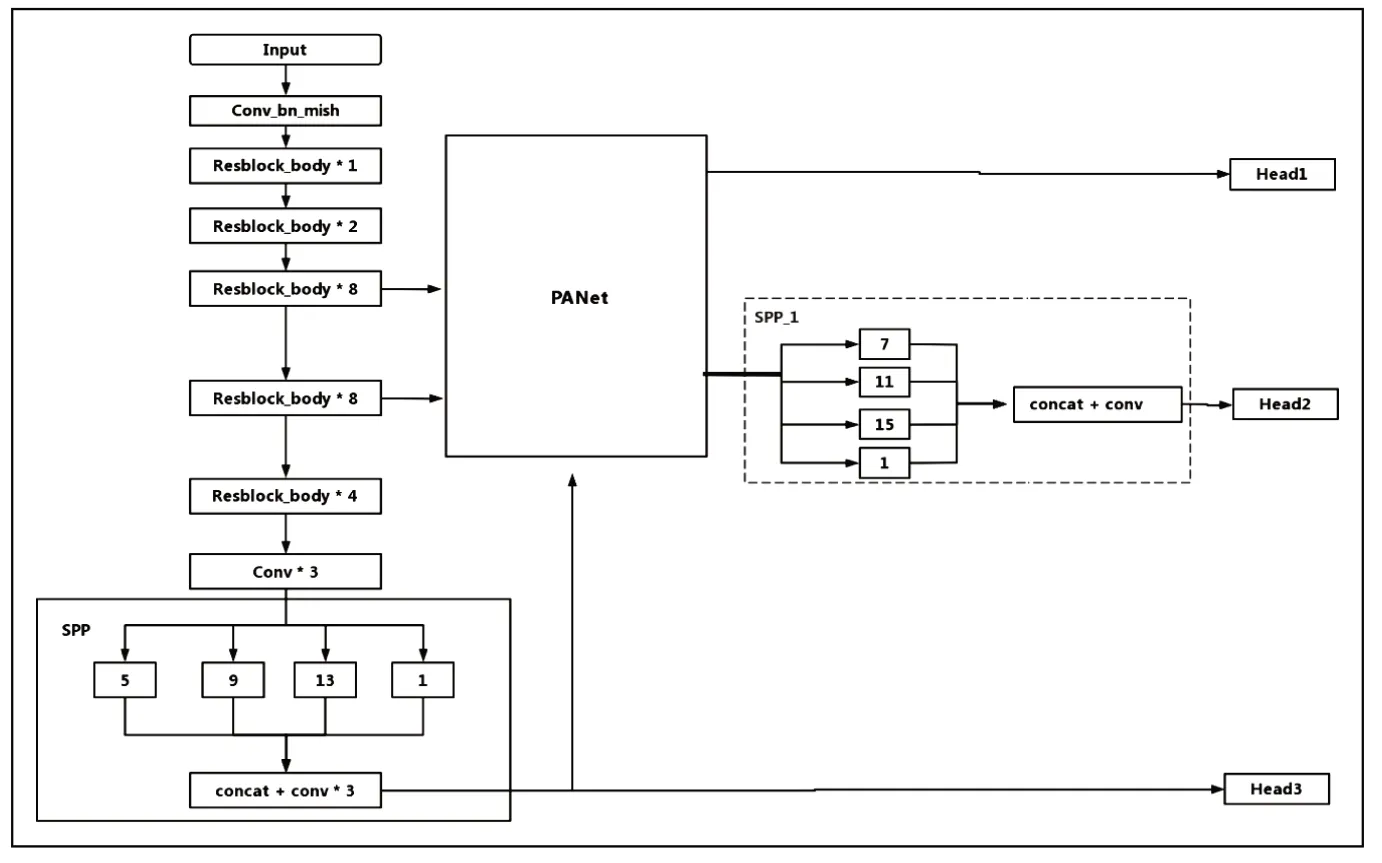
图1 改进后的模型结构
■1.2 SPPnet
卷积神经网络(CNN)通常由卷积层和全连接层组成。卷积层不需要输入数据的大小。然而,第一个完全连接的层要求输入大小必须是固定的。以VGG网络16为例,其输入大小固定为224×224,这在一定程度上限制了模型的泛化性能和应用场景。
SPP结构是在CSPDarknet53最后一个特征层之后,在对最后一个特征层进行三次卷积后,用四个不同尺寸的最大池化进行处理,四个不同尺寸的池化核大小分别为13x13、9x9、5x5、1x1。YOLOv4中通过添加SPP结构,增大感受野,分离出最重要的上下文特征,并且不会降低检测速度。通过对SPPnet结构的分析得出,原YOLOv4结构中使用的SPPnet并不能很好的实现对不同尺度目标特征信息的有效提取。为此,本位针对性的提出在以CSPdarknet53为主干网络结构基础上融合多个SPPnet结构。分别命名为SPP、SPP_1,其中SPP结构参数保持不变,SPP_1的卷积核大小调整为15x15、11x11、7x7、1x1以此满足浅层神经网络中的多尺度特征融合,SPP、SPP_1的网络结构图如图2所示。
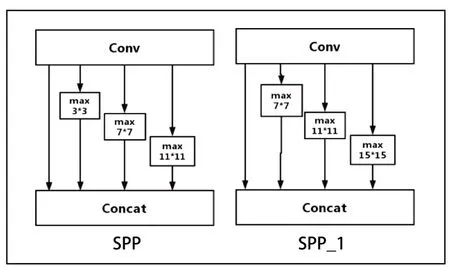
图2 SPPnet结构示意图
■1.3 CSPDarknet
CSPNet 易于实现,且具有很好的通用性,可以构造在 ResNet、ResNeXt和 DenseNet等 网 络体系中。CSPDar knet53是在 Darknet53基础上,参考了CSPNet,其主干主要包括五个CSP模块。CSP模块先是将特征图分成两部分,一个部分是Resblock的结构,分别迭代1,2,8,8,4次,另一个部分是经过少量操作的残差边,最后进行通道叠加操作,主要目的是能够实现更丰富的梯度组合,同时减少计算量,用于解决需要大量推理计算的问题。
■1.4 PANet
PANet的概念在Mask R-CNN中也存在。PANet是对特征金字塔网络(Feature Pyramid Network, FPN)的进一步改进。FPNet采用的是自顶向下的传输模式,将高层特征传入下层。因此底层的特征无法对高层特征产生影响。并且在FPNet的这种传输模式中,顶部的信息传入底部是逐层传输的,这也导致了计算量增大,所以提出了PANet来解决这一问题。
在PANet中引入了自底层向顶层向上传播信息的增强结构路径,避免了在传递过程中部分信息丢失的问题,并使得底层的信息更容易到达高层顶部。在加入了PANet后,在进行从顶层向下层的特征融合后,再进行自下层向顶层的特征融合,这样的特征传递方式穿越的特征图数量得到了大大的减少,因此减少了计算量。
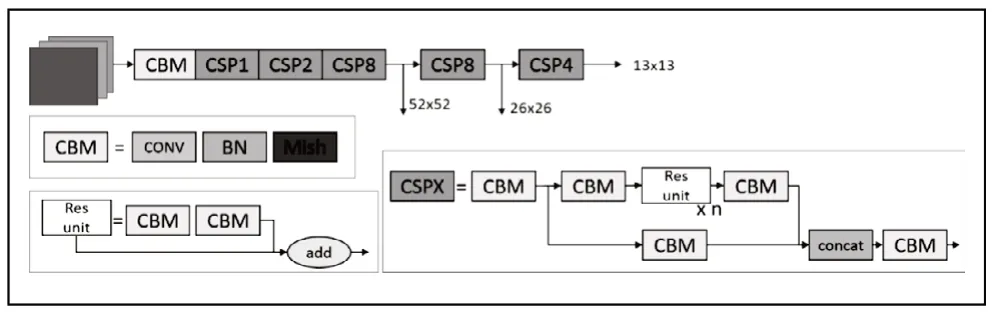
图 3 CSPDarketnet53结构
2 实验
为验证改进后的检测算法的综合性能,本文使用的数据是PASCAL VOC 07+12,其包含16000余张训练数据集,和5000张测试数据集,并与YOLOv4算法进行了对比实验。我们的方法是在2.2GHz Intel i7-8750 CPU和NVIDIA GeForce RTX 2070S GPU上执行的。相应的程序在Pytorch框架下使用Python实现。
在物体检测中,通常使用 mAP 指数来评估准确度。基于原始YOLOv4模型,输入图像的分辨率设置为416 × 416,Batch size为16,初始学习率为0.0001,经过50个Epoch得到最终的网络模型。原YOLOv4算法与改进后的算法的20类相比,实验结果如图4、图5所示。
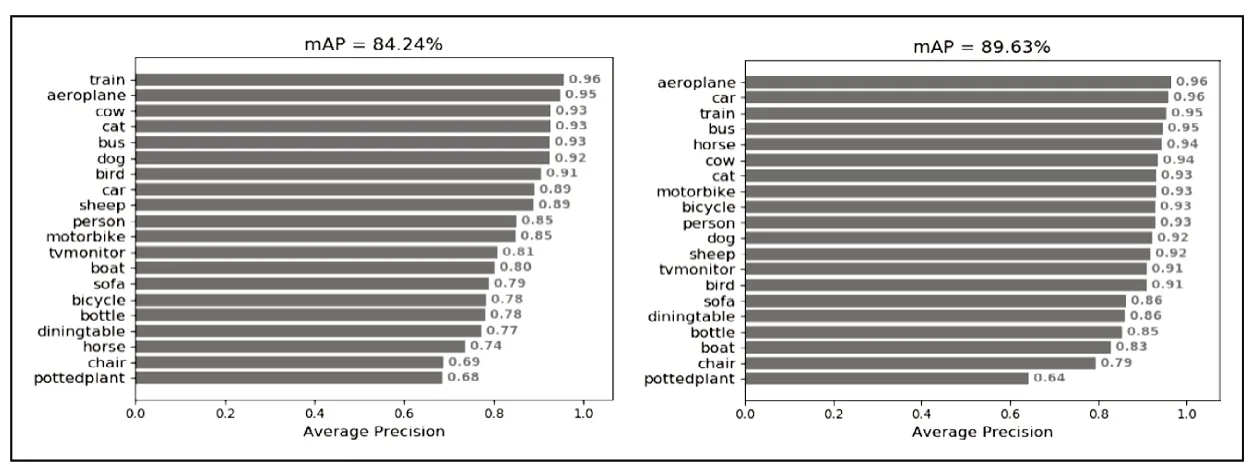
图4 左图为原YOLOv4实验结果,右图为改进后的YOLOv4
图4中,改进后的算法相比于原YOLOv4算法,在几乎所有类别上都有显著的提升。原YOLOv4对pottedplant的检测效果本身在二十个类别中就是最低的,主要是因为这个类别物体在图像属于通常尺寸比较小,而且在测试集中物体或多或少的受到其他物体的遮挡,对于YOLO算法来说,检测的难度比较大。图4中,原YOLOV4和改进后的模型,对图像检测的情况来看,第一幅图像中, 改进后的模型不仅能检测YOLOV4检测出的目标,还能检测出YOLOV4没有检测出的右边的男士。第二幅图像中,原YOLOV4漏检了diningtable目标,改进后的模型能准确检测。第三幅图像中,原YOLOV4漏检的比较严重,而且还将目标car类别检测成motorbike类别,而改进的算法能减少漏检的情况,并且能正确检测目标的类别。所以与原YOLOV4相比,改进后的模型检测效果更好。

图 5 改进后的模型与原YOLOV4检测图像的对比
YOLOv4中 常 用 的tricks有Mosaic,cosine learning rate,smooth label,以及weight decay。从上述表1中可以看出,只有通过对改进后的模型算法进行对比验证,才能知道当前的设计是最佳的,我们通过在实验中调整mosaic数据增强、余弦退火学习率、标签平滑和权重衰减这些训练方法,使得改进的算法有最好的结果。只有当Mosaic数据增 强、Cosine_Ir打 开,Smooth_label=0,Weight_decay关闭时,改进后的模型才达到最高89.63%的mAP。
3 总结
本文在YOLOv4的基础上,通过嵌入改进的SPPnet,提出了改进的YOLOv4检测模型。在相同的数据集下进行目标检测的实验,改进后的YOLOv4检测模型与YOLOv4等主流检测模型相比较,改进后的模型具有较好的效率和较高的准确性。此外,在普通非结构化场景下,该算法还能成功检测出部分被遮挡的物体,包括小尺度和大尺度物体。该改进方法是成功且有效果的。在未来的工作中,改进后的模型有望应用于室内场景的目标检测、戴口罩下的人脸检测、人流量移动下的目标检测……等任务。关于本文的研究内容,依然存在进一步的优化空间,在后续的工作中,还可以开阔思想,进一步提升检测的速度,将该功能广泛应用在更多的领域。
