基于视觉的手势识别算法及应用的研究
2021-12-17黄彦铭宁媛
黄彦铭,宁媛
(贵州大学 电气工程学院,贵阳 550025)
0 引言
人的手势自身就具有广泛的多义性、多样性、多元化以及空间和时间上的差异性等多种独特的特点,再加上人手形体的复杂性以及人体视觉的不确定性,所以基于视觉的手势识别成为了多学科、多领域交叉的研究难题。
手势识别主要是利用机器设备对人的手、胳膊等各关节的空间角度位置进行检测。这些机器设备大多是通过有线通信技术将计算机系统与人体互相结合连接,让使用者的手势信息准确地传送至识别系统内,其中典型设备以数据手套等机器设备为代表[1]。数据手套是由各种传感器组成的,使用者利用这些传感器将自身手的位置、角度以及手指的角度等信息录入到计算机系统内,达到手势识别的目的。尽管数据手套能够对人手识别达到良好的识别检测效果,但由于其价格昂贵,难以普遍应用。在此之后,光学标记方法的出现淘汰了数据手套,使用者的手上戴上光学标记,通过红外传感器将人手位置、形态等变化传送到系统内,达到良好的识别效果,但此方法约束了人手的活动范围,也避免不了复杂的设备使用[2]。
虽然引入外部设备能够提升手势识别的快速性、稳定性以及准确性,但却会掩盖手势的自然表达方式,于是基于视觉的手势识别方式应运而生[3]。
1 总体设计方案
本研究的设计流程如图1 所示。利用OpenCV调用电脑摄像头采集人体手势图像,建立手势库,以此为基础,对手势库中所采集到的手势图像进行预处理,将图像中的手势部分提取出来,分为测试集和训练集2 部分。其中,训练集用于导入所设计的CNN 卷积神经网络进行模型训练,测试集则是对所得到的训练模型进行准确率测试,当测试准确率达标,则输出保存训练模型,以此作为实时手势图像的手势判断模型。

图1 总体设计流程Fig.1 Overall design
2 图像预处理
2.1 图像预处理概述
图像预处理在数字图像中占有很重要的地位,图像质量的好坏,直接影响分析,例如分类、识别、分割等,图像预处理部分就是基础,也是重中之重。图像预处理即是将手中的原始图像进行加工,处理。在本研究中针对手势图像,采用了数据增广,肤色提取和形态学处理3 种方法做图像预处理。
2.2 数据增广
作为深度学习预处理中的常用技巧之一,数据增广的作用是增加数据集的量,增加数据集的多元性以及多样性,使所得到的训练模型具有更强的泛化能力。通过数据增广提升数据集中的相关数据,能防止网络学习到不相关的特征,更多的学到与数据有关的性能,显著的提升整体的性能,目前数据增广主要包括:水平/垂直翻转、旋转、缩放、裁剪、剪切、平移、对比度、色彩抖动、噪声等[4]。本研究中主要运用图像平移、翻转以及旋转3 种常用数据增广方法。
假设图像的原始坐标为(x0,y0),平移后的坐标为(x,y),则平移前和平移后的坐标关系如式(1)所示:
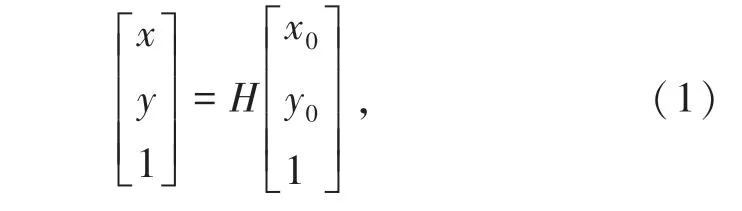
平移是指所有的像素在x和y方向各平移相应单位,平移变换对应的数学矩阵为式(2):
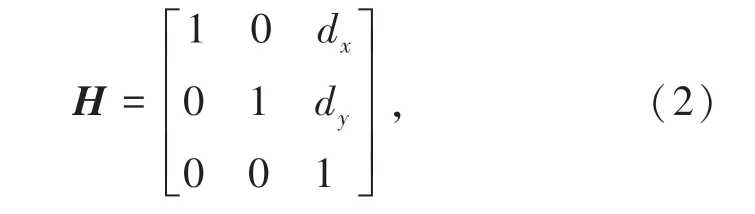
图像翻转包括水平翻转和垂直翻转,其中水平翻转对应的数学矩阵如式(3)所示,垂直翻转对应的数学矩阵如式(4)所示:

图像旋转则是需要确定旋转角,旋转对应的数学矩阵如(5)所示:

本文对原始手势图像所做的数据增广示例,如图2 所示。
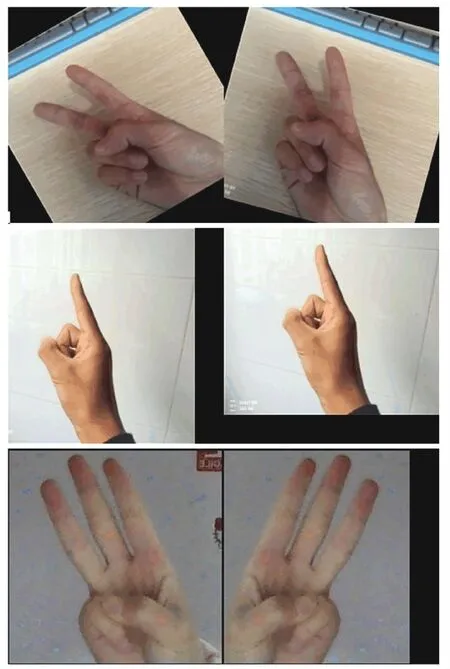
图2 数据增广示例图Fig.2 Data augmentation example diagram
2.3 肤色提取
常规下原始手势图像都是基于RGB(三原色)空间下的图像,这样的图像更便于在硬件中理解与处理。而在机器视觉中,为了提取RGB 原始手势图像中的手势部分,通常是将RGB 转换为HSV 颜色空间,其中H代表色度 hue,S代表饱和度saturation,V代表亮度value,各个参数的范围见表1[5]。因此,在HSV 颜色空间中能通过对3 个参数的范围进行一个设定,在此范围内的即为肤色区域,也就是手势区域。而肤色区域的H、S、V3 个参数范围如式(6)所示。

表1 HSV 参数范围Tab.1 HSV parameter range
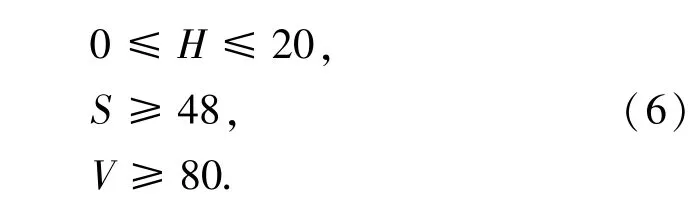
基于HSV 颜色空间的肤色提取预处理图像示例如图3 所示。

图3 基于HSV 颜色空间的肤色提取示例图Fig.3 Skin color extraction based on HSV color space example diagram
2.4 形态学处理
数学形态学中有2 个基本运算,即腐蚀和膨胀。腐蚀和膨胀是针对图像高亮部分而言,其操作就是将图像或图像的一部分A,与卷积核B 进行卷积后的取值与赋值操作。
图像腐蚀操作就像“领域被蚕食”一样,将图像的高亮部分缩减化,其运行所得到的结果图与原图中的高亮区域相比面积更小,线条更细。其数学表达式(7)如下:
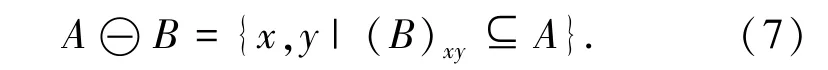
式(7)表示图像A 用卷积核B 来进行腐蚀处理,通过卷积核B 与图像A 进行卷积计算,得出B覆盖区域的像素最小值,并用这个最小值来替代参考点的像素值,即是求局部最小值操作,这样原图中的高亮区域就会逐渐减小。
图像膨胀操作是腐蚀操作的逆操作,就像“领域的扩张”一样,将图像中的高亮区域扩张,其运行所得到的结果图与原图的高亮区域相比面积更大,线条更粗。其数学表达式(8)如下:
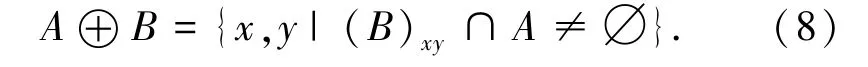
式(8)表示图像A 用卷积核B 来进行膨胀操作,即是求局部最大值,达到增大原图高亮区域的目的。
腐蚀与膨胀两者结合形成了开运算和闭运算。开运算是先腐蚀再膨胀,主要目的为去除孤立的小点;闭运算则是先膨胀再腐蚀,主要目的为填平小孔,弥合小裂缝。本研究中运用了两次开运算,用以加强对图像的处理效果,处理示例如图4 所示。
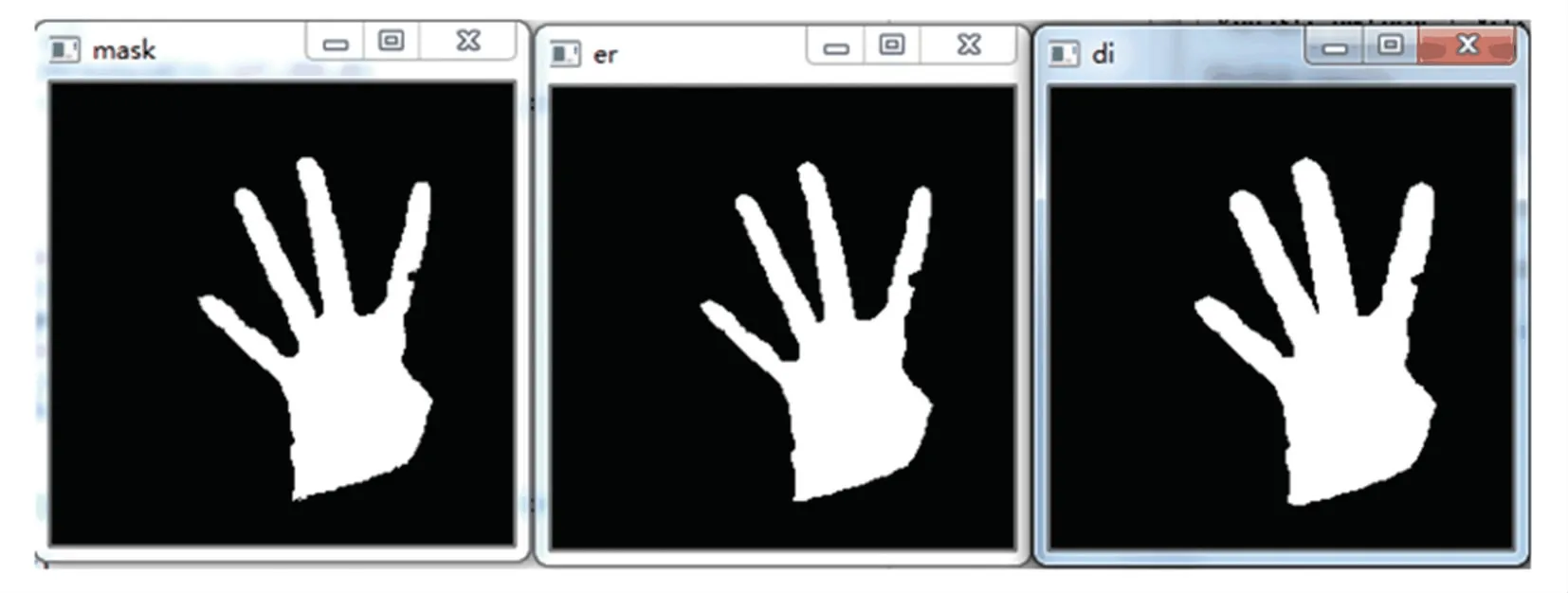
图4 腐蚀膨胀示例图Fig.4 Corrosion and expansion example diagram
3 CNN 卷积神经网络模型设计与实验结果
3.1 模型建立
本文采用深度学习中的CNN 卷积神经网络来对所得到的预处理手势图片进行模型训练,相较于简单的神经网络模型,CNN 卷积神经网络的优势在于不再单一地对每个图片像素做处理,而是对一小块区域的处理。这种做法加强了图像信息的连续性,使得神经网络看到的是一个图像,而非一个点,同时也加深了神经网络对图像的理解,卷积神经网络有一个批量过滤器,通过重复的收集图像的信息,每次收集的信息都是小块像素区域的信息,将信息整理,先得到边缘信息,再用边缘信息总结出更高层的信息结构,得到部分轮廓信息,然后得到完整的图像信息特征,最后将特征输入全连接层进行分类,得到分类结果。本文中卷积神经网络的设计流程如图5 所示。

图5 CNN 卷积神经网络模型设计流程Fig.5 CNN convolutional neural network model design process
3.2 模型训练
使用预处理数据集训练的模型的准确率和损失函数如图6 和图7 所示。可以看到,随着训练模型步骤的增多,其深度的加深,即采集到的训练集的特征的逐步增多,训练的准确率逐步增高,最后逐渐稳定在0.96~0.97 之间,而损失函数也逐步的降低到0.6 左右。
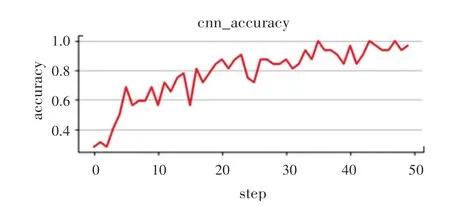
图6 训练集准确率Fig.6 Training set accuracy

图7 损失函数Fig.7 Loss function
3.3 实验结果
为了更好的实现人机交互,本文利用PyQt5 的designer 工具生成了人机交互界面,调用电脑摄像头对实时拍摄的手势图像进行识别,测试结果如图8所示。

图8 测试结果图Fig.8 Test result chart
4 结束语
本文选用的工具是Spyder,对一、二、三、四,4种手势图像进行图像增广、肤色提取和腐蚀膨胀等预处理操作,设计了CNN 卷积神经网络对预处理图像进行分类、验证以及识别,并用PyQt5 的designer工具实现了人机交互界面显示实验结果,得到了较为满意的实验结果,为图像预处理以及人机交互奠定了良好的基础。
