基于深度学习的连续帧车道线检测网络
2021-12-17孔健李烨尹婷
孔健,李烨,尹婷
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引言
传统的车道线检测方法依赖于手工特征提取来检测车道线。手工特征一般是基于颜色、边缘等,这些特征可与霍夫变换或卡尔曼滤波器结合在一起预测车道线。这些方法很简单,实时性好,对平台的要求也比较低。但是,其性能取决于测试环境,例如照明条件和是否遮挡,面对复杂路况时检测鲁棒性很差,甚至检测不出车道线,对于安全行驶决策是致命的。
近期车道线检测采用深度学习网络来提取特征,在复杂的场景中具有出色的性能,其中卷积神经网络(Convolutional Neural Network,CNN)方法在计算机视觉领域的表现尤为突出。车道线检测通常基于语义检测任务,对图像每一个像素分配一个二进制标签,以指示其是否属于车道线。尽管这些方法取得了出色的性能,但由于其采用多分类方法来区分每个车道,因此只能应用于固定车道数量的场景。SCNN 网络按照一定方向(上、下、左、右),按照顺序进行卷积,适用于车道线这种持续延伸的目标[1];LaneNet 将问题归结为实例分割,使用用于特征提取的共享编码器和2 个解码器,其中一个解码器执行二进制车道线分割,另一个解码器进行实例分割,使得该网络可以检测任意数量的车道线[2];PointLaneNet 结合关键点检测与点云实例分割进行车道线检测,也可适用于检测任意场景和任意数量的车道线[3]。
由于驾驶场景是连续的,在相邻帧之间存在大量重叠画面,因此相邻帧中车道线的位置具有高度的相关性。更准确地说,即使车道线可能会受到阴影、污渍和遮挡带来的损坏或退化,当前帧中的车道线仍可以通过前面多个帧进行预测。使用多帧进行车道线检测,涉及到时域信息的提取,RNN 具有连续信号处理、序列特征提取和综合等优点,但是单纯使用RNN 进行图像处理会产生大量参数,造成沉重的计算负担。同时车道线大小长宽不固定,采用单一尺度特征图进行检测,效果不是很好。
为了改善这些问题,提出了一种基于连续帧的车道线检测网络。
(1)提出了一种新的融合策略,将CNN 与长短期记忆网络LSTM(Long Short-Term Memory,LSTM)融合;
(2)LSTM 被实现为双向ConvLSTM,捕获来自正反方向的时空信息;
(3)编码器CNN 生成多尺度特征映射,输入相应的双层LSTM 网络捕获连续帧的时空信息,最后在解码器CNN 中进行特征融合。
1 网络结构设计
本文提出网络的总体架构如图1 所示,由3 个主要部分组成:编码器、双向ConvLSTM 和解码器。编码器和解码器是2 个对称的卷积网络,训练时选取5 幅连续图片和最后一帧的地面真实情况作为输入训练所提出的网络,并在最后一帧识别车道;编码器生成多尺度特征映射;输入双向ConvLSTM 捕获连续帧的时空信息;多尺度特征映射的时空信息被输入解码器进行特征融合。

图1 总体网络结构图Fig.1 Overall network structure diagram
1.1 多尺度编码器网络
在编码器部分进行特征提取,并生成多尺度特征映射。受SegNet 和U-Net 在语义分割方面的成功启发,参考SegNet 和U-Net 设计了编码器,并通过改变卷积核数和Conv 层对其进行了优化如图2所示,可以在准确率和效率之间取得平衡。在UNet 中,编码网络的一个块包括2 个卷积层,卷积核数是最后一个块的2 倍,池化层用于特征映射的下采样。经过此操作后,特征映射的大小将缩小到一半,而通道数量将加倍,表示高级语义特征。在优化的U-Net 编码器中,最后一个块没有使卷积层的核数加倍,如图2(a)所示。因为车道通常可以用颜色和边缘等来表示,即使使用较少的通道,原始图像中的信息也能得到很好的表达。SegNet 采用VGGNet的16 层卷积结构作为编码器,如图2(b)所示。

图2 编码器架构Fig.2 Encoder architecture
编码器生成多尺度特征映射,然后将不同大小的特征块用作ConvLSTM 模块的输入。假设(St,St-1,St-2,St-3,St-4)是在时间(t,t-1,t-2,t-3,t-4)的输入,这里使用(其中k=1,2,3,4,5)来表示(St,St-1,St-2,St-3,St-4)的第k层的特征映射。换句话说,当使用St作为输入时,将是编码器网络的第一个块的特征映射,如式(1)。
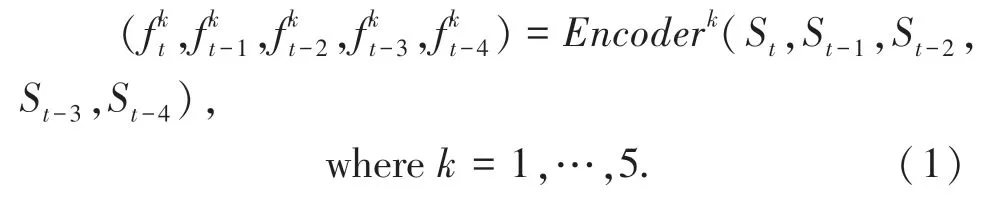
1.2 双向LSTM
为了提取连续帧的时空信息,LSTM 块将编码器提取的特征映射作为输入。采用LSTM 是因为其遗忘不重要信息和保留重要特征的能力优于传统的RNN 网络,而全连接LSTM 耗时且计算量大,本文网络中使用卷积LSTM(ConvLSTM)。ConvLSTM 用卷积运算代替LSTM 中每个门的矩阵乘法运算,广泛应用于时间序列数据的端到端训练和特征提取[4]。
下面将详细描述这些组件,一般的ConvLSTM在t时刻的激活可以表述为式(2)~式(6):
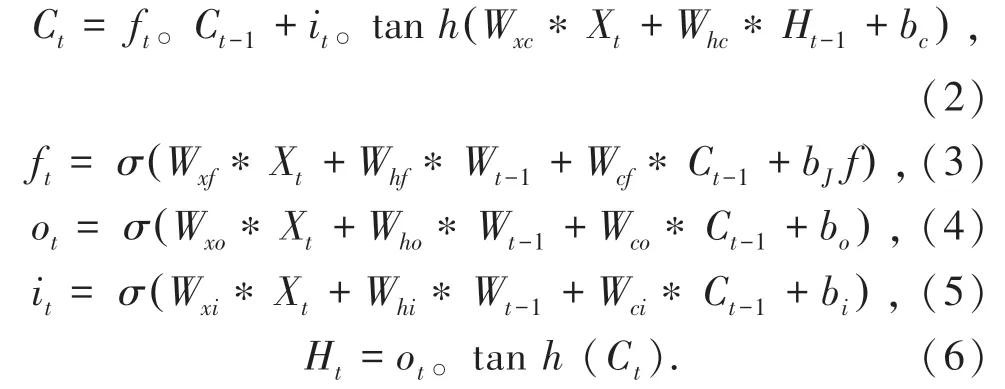
其中,Xt表示编码器在时间t提取的输入特征映射;Ct、Ht和Ct-1、Ht-1分别表示在时间t和t-1的存储器和输出激活;Ct、it、ft和ot分别表示单元、输入门、遗忘门和输出门;Wxi是输入Xt对输入门的权重矩阵;bi是输入门的偏差;其它W和b的含义可以从上述规则中推断出来;σ(.)表示sigmoid 运算;tanh(.)表示双曲正切非线性;“*”和“。”分别表示卷积运算和阿达玛积。
网络中第k个(k=1,2,3,4,5)ConvLSTM 模块将公式(1)中提到的特征映射作为其输入,这个ConvLSTM 模块产生一个输出特征映射(表示为gk),捕获这些个帧的时空信息。操作总结如式(7):
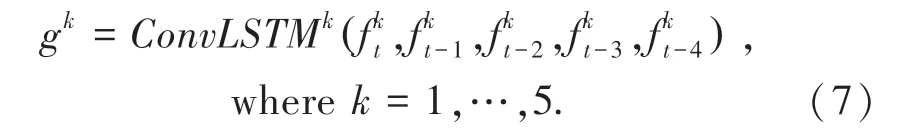
得益于语音识别方面的进步,在这里进一步将ConvLSTM 模块扩展到双向ConvLSTM,以使用前向和后向2 种方向对时空信息进行建模。



图3 双向ConvLSTM 模块体系结构Fig.3 Bidirectional ConvLSTM module architecture
1.3 解码器网络
在解码器中,接收的特征映射的大小和数量与编码器特征映射相同,但方向相反,以便更好地恢复。在各个网络模型中,ResNet等采用的elementwise add(简称add)来融合特征[5],而DenseNet等则采用concat 来融合特征[6]。add 是特征映射的相加,concat 是通道的合并,add 的计算量要比concat的计算量小得多,因此选用add 进行特征融合。
解码器每个子块中的上采样和卷积匹配编码器的子块中的相应操作。解码器获取5 个双向ConvLSTM 模块的输出(g1,g2,g3,g4,g5),并为时间t+1 生成未来的语义分段掩码St+1(假设提前一步预测)。解码器结构如图4 所示。
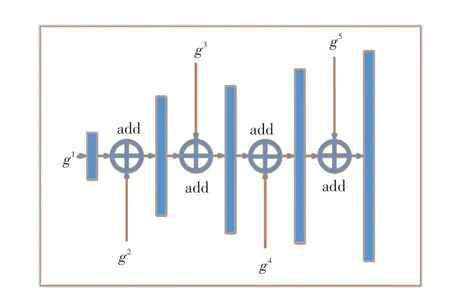
图4 解码器结构Fig.4 Decoder structure
采用1×1 卷积,在g1上进行上采样,以匹配g2的尺寸;然后通过add 与g2结合起来。g2,g3,g4和g5操作类似,最后1×1 卷积和上采样来获得St+1,式(11)~式(13)。
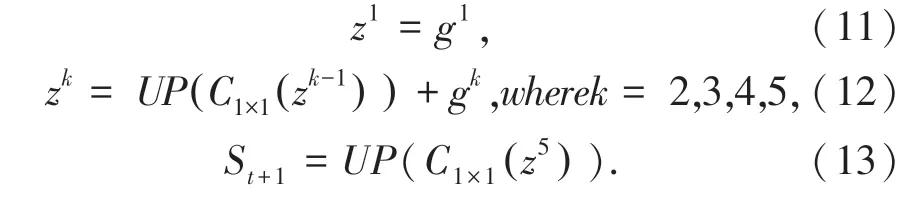
C1×1(.) 和UP(.) 分别表示1×1 卷积和上采样操作。
2 实验设置
2.1 数据集设置
Robust Lane Detection 中自行构建了一个连续帧车道线数据集[7],使用TuSimple 数据集和Robust Lane Detection 的一个数据集组成的综合数据集。TuSimple 车道数据集包括3 626个图像序列。这些图片是高速公路上的前额驾驶场景,每个序列包含一秒钟内收集的20 个连续帧,最后一帧即第20 张图像车道线被标记。这里为了增加数据集,在每个序列中额外标记了第13 幅图像的车道线。Robust Lane Detection 车道线数据集包括1 148个乡村道路图像序列,使用这2 个数据集结合,大大扩展了车道线数据集的多样性,详细信息见表1 和图5。

表1 数据集的结构和内容Tab.1 The structure and content of the data set

图5 数据集图像Fig.5 Pictures of date set
训练时,选取5 幅连续图片和最后一帧的车道线标注作为输入,训练所提出的网络,并在最后一帧检测车道线。为使所提出的网络能够在不同的行驶速度下进行车道检测,对输入图像进行了3 种不同的采样,即1 帧、2 帧和3 帧的步长,见表2。
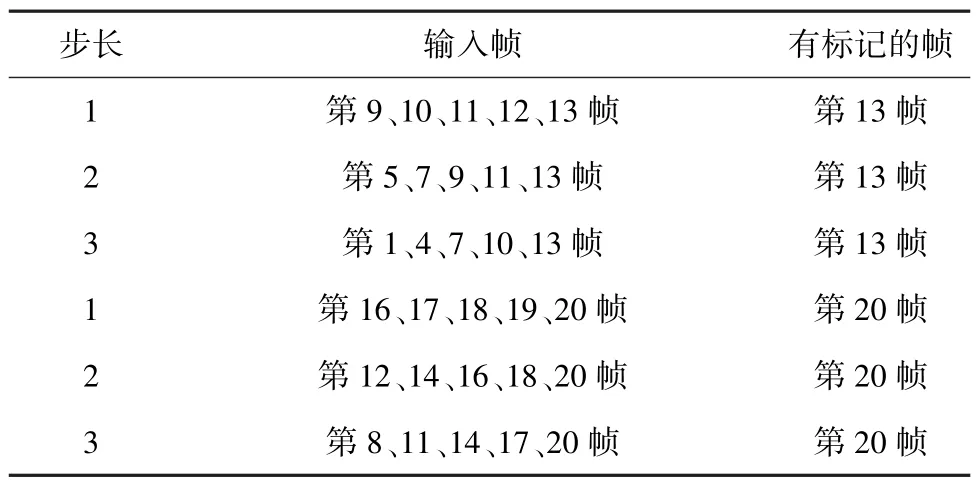
表2 连续输入图像的采样方法Tab.2 Sampling method of continuous input image
在数据扩充中,采用了旋转、翻转和裁剪等操作,生成了38 192个用于训练的标记图像组。输入将随机改变为不同的光照情况,这有助于训练的模型更加健壮。
为了测试,抽取5 幅连续图像来识别最后一帧的车道,将其与最后一帧的地面真实值进行比较。构建了2 个测试集,测试集1 是在正常的TuSimple测试集上构建的,测试集2 由在不同情况下路面图片组成,针对模型稳健性进行评估。
Robust Lane Detection 数据集中用细线来标注车道,然而在语义分割任务中,网络必须学习像素级标签。所以对图像进行低分辨率采样,因为当图像变小时,车道线宽度接近一个像素,如图6 所示。

图6 低分辨率图像Fig.6 Low resolution image
2.2 超参数设置和损失函数
(1)ImageNet 是一个用于分类的大型基准数据集[8],提出的网络在ImageNet 上进行预先训练。利用预先训练好的权值进行初始化,不仅可以节省训练时间,而且可以将适当权值传递给所提出网络[9];
(2)以N幅连续的驾驶场景图像为输入,进行车道线识别。因此在反向传播中,ConvLSTM 的每个权重更新系数应该除以N。在实验中,设置N=5,还研究了N对影响车道线检测性能的影响;
(3)基于加权交叉熵构造了一个损失函数来求解区分性分割任务,式(14):
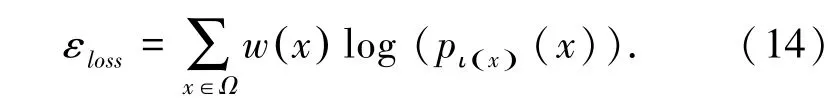
其中,ι:Ω→{1,…,K} 是每个像素的真实标签,w:Ω→ℝ 是每个类的权重,目的是平衡车道线类。其被设置为整个训练集中2 个类的像素数的比率。pι(x)定义为式(15):

其中,ak(x) 表示特征通道k在像素位置x∈Ω,Ω∈Z2处的激活,k是类的数目;
(4)为了有效地训练所提出的网路,在不同的训练阶段使用不同的优化器。一开始使用自适应矩估计(Adam)优化器,其具有更高的梯度下降率,但很容易陷入局部极小。为了避免这种情况,当网络被训练到一个相对较高的精度时,转而使用随机梯度下降优化器(SGD),其在寻找全局最优解方面具有更高的性能。
在更换优化器时,需要进行学习速率匹配,否则学习过程会受到干扰,导致收敛的混乱或停滞。学习率匹配公式(16)~(18):

其中,wk表示第k次迭代中的权重;αk是学习率;f(.)是由损失函数f(.)计算的随机梯度。实验中,初始学习率设为0.01,当训练精度达到90%时,改变优化器。
3 实验
在实验中,车道检测图像的采样分辨率为256×128。实验配置为E5-2630@2.3GHz,64GB 内存和2 个GeForce GTX TITAN-X GPU。批量处理大小为16,epoches为100。
3.1 与原始网络以及修改版本比较
将本文提出的网络命名为UNet_2ConvLSTM 和SegNet_2ConvLSTM,与其原始基线以及一些修改版本进行了比较。包括以下方法:
(1)SegNet:一种经典的用于语义分割的编解码结构神经网络,编码器与VGGNet 相同;
(2)SegNet_Cat:在SegNet 基础上,在编码器和解码器之间添加多尺度编码特征融合;
(3)SegNet_ConvLSTM:在SegNet_Cat 中添加单向LSTM;
(4)SegNet 3D:通过将连续图像叠放,利用三维卷积核得到混合的空间和序列特征;
(5)UNet 相关网络:将SegNet 的编码器和解码器替换为修改后的UNet,生成相应网络。
在对上述网络进行训练后,对测试集的结果进行了比较。首先从视觉上检查不同方法得到的结果;然后对其进行定量比较;并证明所提出框架的先进性。
如图7 所示,所提网络识别出了输入图像中的每一条车道线,当车道线被遮挡或形状不规则时,也能够完整地识别出,避免将一条连续的车道线检测成多条断裂的车道,而其它方法很容易将其它边界识别为车道线或者识别不连续。

图7 车道线检测结果Fig.7 Lane line detection results
SegNet_Cat 表明了在编码器和解码器之间添加多尺度特征融合的有效性,见表3。SegNet _ConvLSTM 表明了在SegNet_Cat 中的编码器网络之后使用传统的单向ConvLSTM 的有效性。而本文所提网络即使用多尺度编特征融合,又将传统的单向ConvLSTM 拓展为双向ConvLSTM,性能进一步提升,同时也胜过SegNet_3D,相对于SegNet 的准确率分别提高了约1.5%,FN 和FP 也有一定降低。UNet_2ConvLSTM 表现同理。但是由于代表车道线的像素远远小于代表背景的像素。因此,准确度只能看作是一个参考指标。
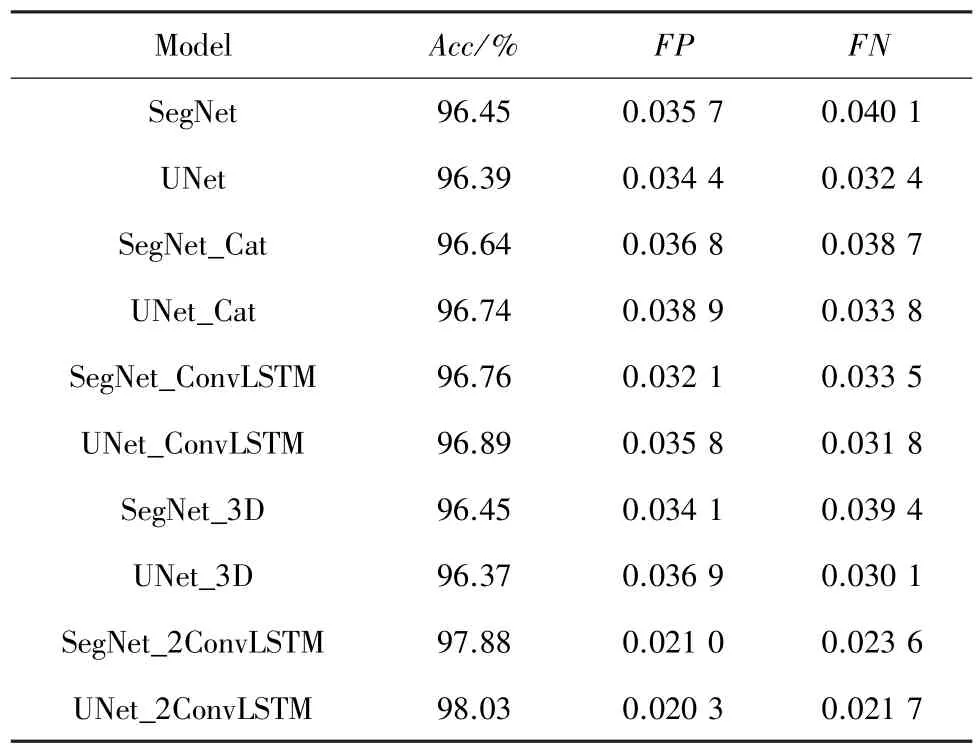
表3 各网络在测试集1 上准确度对比Tab.3 Comparison of each network on test set 1
在车道线检测任务中,将车道线设置为正类,背景设置为负类。根据公式(19)(20),其中TruePositive表示正确预测为车道线的像素数,FalsePositive表示错误预测为车道线的像素数,FalseNegative表示错误预测为背景的像素数,UNet_2ConvLSTM 的Precision比UNet 提高了8%,Recall仅下降了1.5%。对于SegNet,加入双向ConvLSTM后,Precision提高了6%,Recall也略有提高,见表4。
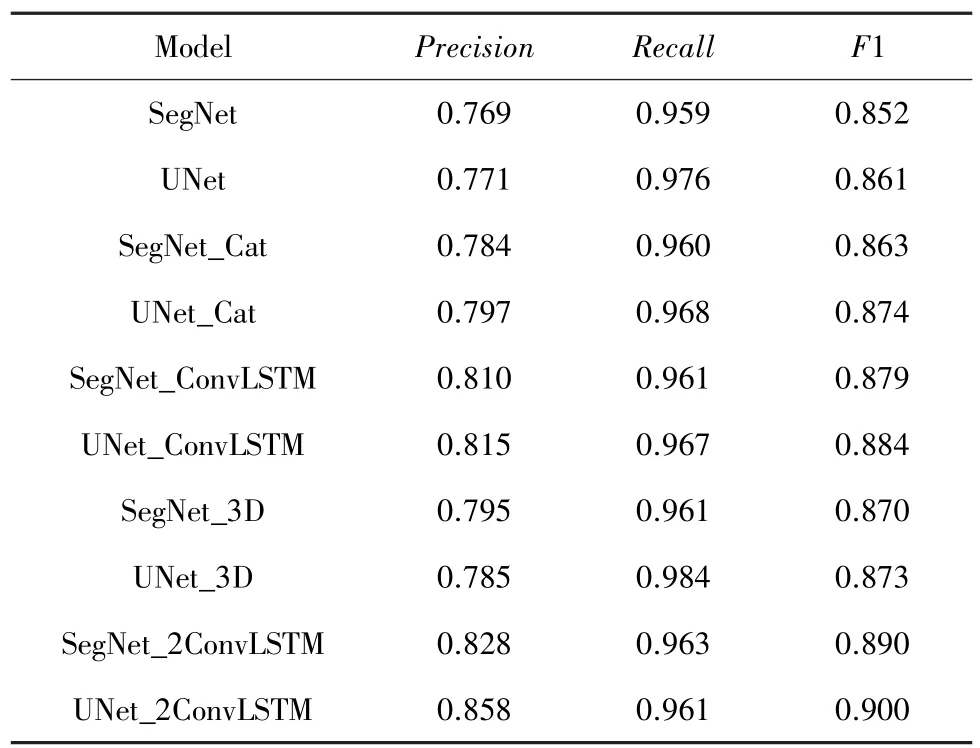
表4 各网络在测试集1 上的测试结果Tab.4 Test results of each network on test set 1

考虑到Precision或Recall只反映车道检测性能的一个方面,又引入F1 测度作为一个整体进行评价。F1 定义为式(21)。所提方法的F1 测量值比原始版本提高了约4%,见表4。这些显著的改进表明,多帧比单帧预测车道线更加准确和双向ConvLSTM 在语义分割框架中对序列数据的有效性。

从表4 可以更明显的看出,SegNet 基础上添加多尺度特征融合的有效性。由于ConvLSTM 能够接受高维张量作为输入,因此其可以在原始基线的基础上提高精度,而双向ConvLSTM 性能提升更加明显,相对于SegNet 的F1 提高了约3.8%。UNet_2ConvLSTM 表现同理,相比于UNet 网络的F1 提高了约4.1%。
三维卷积核在立体视觉问题中非常普遍,其也可以通过将图像堆积到三维体积来处理连续图像。也测试了SegNet_3D 和UNet_3D 的性能,见表4。然而由于三维卷积核对时间序列特征的描述能力不强,导致没有很好的性能表现。
本文提出网络以一系列图像为输入,可能会增加运行时间。如果处理全部5 帧,则所提出的网络比仅处理一个图像的网络要耗费更多时间。因为之前帧的特征已经被抽象出来,编码器可以重用前4帧的特征,只需要处理当前帧,而且性能与全部处理5 帧相差无几,由于ConvLSTM 块可以在gpu 并行执行,对于以单个图像作为输入的模型,其运行时间与原网络几乎相同,具体表现见表5。
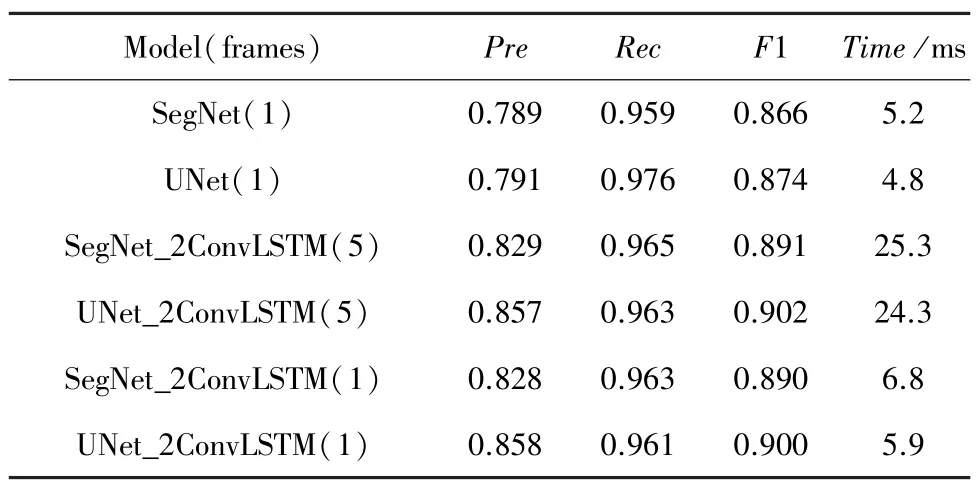
表5 在测试集1 上测试结果和运行时间Tab.5 Test results and running time on test set 1
SegNet_2ConvLSTM 如果将所有5 个帧作为新的输入进行处理,则运行时间大约为25 ms。如果存储并重用前4 帧的特征,则运行时间为6.8 ms,比原SegNet 的5.2 ms 稍长。同样,U-Net_2ConvLSTM运行的平均时间约为5.9 ms,比U-Net 的4.8 ms 稍长。
3.2 与TuSimple 车道线检测竞赛中方法比较
为了进一步验证所提出方法的性能,将所提出的方法与TuSimple 车道线检测竞赛中的方法进行了比较。这里训练集是基于原始图像大小的TuSimple 数据集。PointLaneNet 可以在单个网络中同时执行位置预测和车道线分类;ENet-SAD 与现有方法相比精度属于前列,且参数量更少[10];SCNN由于网络结构较深,并且采用行列卷积的形式,也取得了不错的精度;LaneNet 由于设计了一个带分支结构的多任务网络,取得了较好的结果;ERFNet 核心元素是一个新层,利用跳跃连接和1D 卷积核,也在检测精度上得到了提升[11]。从表6 可看出,所提网络的FN和FP都接近最佳结果,在所有方法中具有最高的精确度。

表6 与TuSimple 车道线检测竞赛先进算法比较Tab.6 Comparison of advanced algorithms with TuSimple lane line detection competition
3.3 鲁棒性测试
尽管在之前的测试集上取得了很高的性能,但是仍需要测试所提网络的鲁棒性。因为即使是细微的错误识别也会增加交通事故的风险[12]。一个好的车道检测模型应该能够处理各种不同的驾驶场景,如城市道路和高速公路等日常驾驶场景,以及具有挑战性的驾驶场景,如乡村道路、照明不良、人车遮挡等。
在鲁棒性测试中,使用具有不同的驾驶场景的测试集2 进行测试。测试集2 包含728 个图像,包括农村、城市和高速公路场景中的车道线图片,是一个综合性和挑战性的测试集,其中一些车道线人眼也很难检测到。
UNet_2ConvLSTM 在所有场景的Precision 上都优于其它方法,并且有很大的提高,见表7。表8 所示在大多数场景中也都达到了最高的F1值,这说明了所提网络具有很好的鲁棒性。大多数实验UNet_2ConvLSTM 的性能优于SegNet_2ConvLSTM。

表7 在12 种挑战性场景中的表现(Precision)Tab.7 Performance in 12 challenging scenarios(Precision)
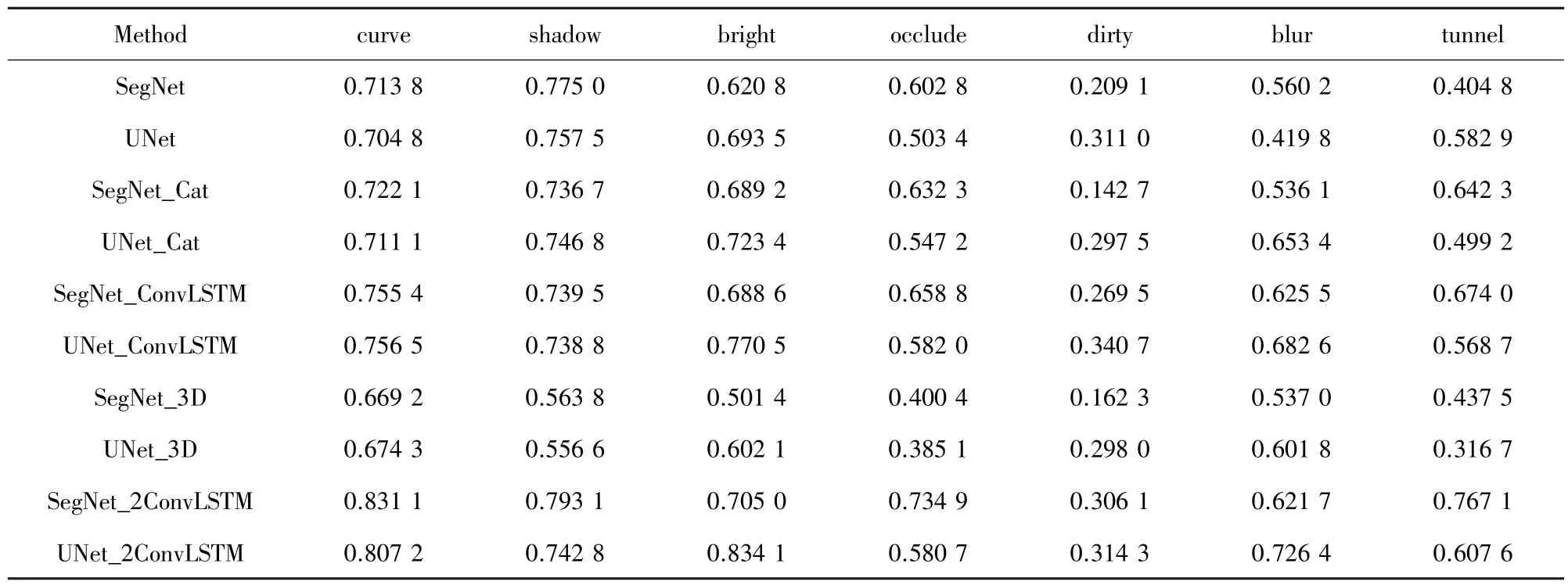
表8 在12 种挑战性场景中的表现(F1 度量)Tab.8 Performance in 12 challenging scenarios(F1 measurement)
3.4 超参数分析
网络中主要有2 个参数可能会影响本文所提出网络的性能,一个是输入的连续帧总帧数,另一个是采样步长。这2 个参数共同决定第一帧和最后一帧之间的范围。
当更多的帧作为网络输入时,网络可以生成包含更多附加信息的特征映射,这可能有助于最终的预测结果。但是如果使用太多的前面的帧,结果也可能不好,因为距离当前帧较远的前面帧中的车道线情况可能与当前帧显著不同。在这里首先分析了输入帧数对检测结果的影响,将输入帧数设置为1~5,同时也分析了在输入帧数相同情况下,采样步长对检测结果的影响。
这里以UNet_2ConvLSTM为例,在测试集1 上进行了测试。从表9 可以看出,在相同的采样步长下,当使用更多的连续图像作为输入时,精确度和F1 测量值都会增加,这说明了使用所提出的网络结构使用连续帧作为输入的有用性,采用多帧的方法比仅使用一幅图像作为输入的方法有显著的改进。随着步幅的增加,性能的增长趋于稳定。例如,从4帧到5 帧的性能改善要小于从2 帧到3 帧的性能改善,因为从较远的前一帧得到的信息对车道预测和检测的帮助要小。分析了另一个参数:2 幅连续输入图像之间的采样步长的影响。从表9 可以看出,当帧数固定时,所提出的模型在不同的采样步长下获得了非常接近的性能,这表明抽样步幅的影响较小。

表9 UNet_2ConvLSTM 在不同参数设置下在测试集1 的表现Tab.9 UNet_2ConvLSTM performance in test set 1 under different parameter settings
上述结果有助于理解双向ConvLSTM 的有效性。单帧输入时,编码器提取的特征地图不能包含车道的全部信息,在某种程度上,解码器必须想象来预测结果;当使用多帧作为输入时,双向ConvLSTM将从连续图像中提取的特征映射集成在一起,得到更全面、更丰富的车道线信息,有助于解码器做出更准确的预测。
4 结束语
本文提出了一种连续帧车道线检测网络。首先,在该网络中用编码器提取输入帧的多尺度特征信息;其次,用双向ConvLSTM 对多尺度的序列特征进行处理;最后,将双向ConvLSTM 的输出输入解码器进行特征融合和车道线预测。与其它网络相比,提出的网络具有较高的精确率、召回率和F1值。此外,该网络在一个具有挑战性驾驶场景的数据集上进行了测试,检验其鲁棒性。结果表明,本文所提出的网络能够在各种情况下稳定地检测出车道,并能很好地避免错误。在参数分析中,采用较长的输入序列来提高检测性能,进一步证明了多帧比单一图像更有利于车道检测的策略。
