基于深度残差生成对抗网络的运动图像去模糊
2021-12-16魏丙财张立晔孟晓亮王康涛
魏丙财, 张立晔, 孟晓亮, 王康涛
(山东理工大学 计算机科学与技术学院,山东 淄博 255000)
1 引 言
由于相对运动、镜头抖动、相机内部传感器噪声、天气因素(雾霾等)、相机散焦等原因,导致图像在拍摄、传输和储存时会产生一定的退化,造成图像质量下降,产生模糊[1]。其中运动模糊图像主要是由于相机与物体在短曝光时间内发生相对运动造成的。为了从运动模糊图像中提取有用的信息,图像复原已成为图像处理的一个重要研究方向,也是数字图像处理的一个重要应用。图像复原技术可以消除或减少图像退化的问题,获得更清晰的图像。
早期的图像去模糊研究,一般是在去模糊过程中假设模糊特征,利用图像的先验知识估计模糊核。因此,图像去模糊的重点之一是确定模糊核。根据模糊核的已知与否,去模糊方法可以分为两大类:一类模糊核已知,称为非盲复原;另一类模糊核未知,称为盲复原。
非盲复原又称为传统图像复原算法,此种方法会根据已知的模糊核,进行解卷积操作,如逆滤波、L-R算法、维纳滤波等算法。由于在实际应用中很难获得精确的模糊核,因此非盲复原表现较差,无法得到清晰的复原图像。
现实场景中盲复原的应用场景更广泛。早期的研究大多使用图像先验,包括全变差、重尾梯度先验或超拉普拉斯先验,它们通常以由粗到细的方式应用于图像,如Pan等人提出了基于图像暗通道先验的模糊核估计方法[2],Levin等利用一种超拉普拉斯先验建模图像的梯度来估计模糊核[3]。
近年来,随着深度学习算法的发展,以卷积神经网络(Convolutional Neural Network, CNN)为代表的深度学习算法被大量应用到图像盲去模糊领域。相比于早期根据图像先验信息的盲去模糊算法,深度学习算法可以做到比图像先验更好的效果。Xu等人引入了一种新颖的、可分离结构的卷积结构来进行反卷积,取得了不错的去模糊效果[4]。Su等人利用CNN进行端到端训练,利用视频中帧与帧之间信息,实现了视频去模糊[5]。
在真实数据集上,由于图像模糊核未知,文献[6]和文献[7]中提出利用CNN预测图像模糊核,实现模糊数据集的合成,最终实现了图像去模糊。然而,核估计涉及到几个问题。首先,假设简单的核卷积不能模拟一些具有挑战性的情况,如闭塞区域或深度变化。其次,核估计过程是微妙的,对噪声和饱和度敏感,所以模糊模型必须花费大量精力进行精心设计。第三,为动态场景中的每个像素寻找空间变化的模糊核需要大量的内存和算力。当模糊核参数无法进行准确估计时,上述方法都无法获得理想的效果[8]。因此,文献[8]和文献[9]摒弃了模糊核的估计过程,直接使用CNN实现了端到端的动态去模糊。
2014年,Goodfellow等人[10]提出了生成对抗网络(Generative Adversarial Networks, GAN)。GAN由两个相互竞争的网络构成,一个称为生成器,一个称为判别器。生成器负责接收随机噪声输入,然后合成数据样本,它的目标是令其尽量像正式数据样本,以“欺骗”判别器。判别器负责判断输入数据是生成器合成的“伪造”样本还是真实样本,它的目标是尽量将二者区分开。一个好的生成对抗网络目标就是让判别器判断真伪的概率接近0.5,即无法判断是否是生成器产生的样本。
由于性能强大,GAN很快被用于图像去模糊领域。生成对抗网络中的生成器负责接受模糊图片,将其复原,目标是生成类似清晰图像的去模糊图像,以骗过判别器;而判别器负责分别接收原始清晰图片以及生成器去模糊后的图片,尽量将二者区分。
Mao等人针对的是标准GAN生成的图片质量不高以及训练过程不稳定这两个缺陷进行改进,在判别器中使用最小二乘损失,提出了LSGAN,能够生成较高质量的图像[11]。Johnson等人提出用于风格迁移任务的网络,提出了感知损失函数,可以较好地衡量模型的质量[12]。Kupyn等人提出DeblurGAN[13],运用条件生成式对抗网络和内容损失函数(Content Loss Function)实现了运动图像模糊的去除。由于单个神经网络同时用于模糊与清晰数据的训练得到的合成模糊图像不能精确模拟真实场景的模糊过程,Zhang等人提出利用两个GAN,将其中一个负责图像的模糊,另一个负责图像的去模糊,实现了真实模糊去模糊[14]。
受到上述研究的启发,本文对GAN进行了改进。首先,改进了PatchGAN的结构,在网络参数只增加2.38%的前提下,将其最底层感受野提升至原先的两倍以上。其次,改进了残差块的结构,增加了卷积层数量,用以提升复原图像的质量。最后,基于GOPRO数据集和Lai数据集的仿真结果验证了本文提出的算法的有效性。
2 图像模糊与去模糊
2.1 图像的模糊
图像模糊模型可以表示为:
IB=K*IS+N,
(1)
其中:IB为模糊后的图像,IS为原图像,K为卷积核,N为加性噪声,*为卷积操作。
另外,模糊图像也可以通过逐帧模糊产生。对于模糊空间变化的图像,没有相机响应函数(Camera Response Function, CRF)的估计技术[15],CRF可以近似为已知的CRF的平均值[14],如公式(2)所示:
g(IS(i))=IS′(i)γ,
(2)
其中γ是一个参数,一般认为其等于2.2。潜在的清晰图像IS(i)可通过观察到的清晰图像IS′(i)得到。仿真的模糊图像IB可以通过式(3)得到:
(3)
其中:M代表清晰帧的个数,t代表某个时间,IS(t)代表时间t对应的清晰帧。
而真实的模糊图像实际上是多帧清晰图像的集成[16],可表示为式(4):
(4)
其中T为曝光时间周期。
现实世界的真实模糊图像如图1所示。

图1 现实生活中的运动模糊图片Fig.1 Motion blurred images in real life
2.2 图像的去模糊
图像去模糊就是对给定的模糊图像进行复原,得出相应的原始图像[17]。
非盲去模糊是指通过给定的已知模糊核进行图像的去模糊,而盲去模糊问题是指从给定噪声图像Y中估计出原图像X和模糊核Z。
盲去模糊过程可以表示为:
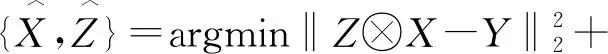
(5)
其中:φ(X)和θ(Z)分别是预期的清晰图像的正则化项和可能的模糊核。
3 相关工作
3.1 生成对抗网络
生成对抗网络(GAN)中包含两个相互竞争、相互对抗的网络——生成器和判别器(图2)。GAN中的对抗思想可以追溯到博弈论的纳什均衡,对抗的双方分别是生成器和判别器。二者对抗的目标函数可以描述为:
(6)
其中:x表示来自Pdata(x)真实样本,Ex~Pdata(x)为输入清晰图像的期望,D(·)表示判别器D的输出,G(·)表示生成器G的输出。

图2 GAN的结构Fig.2 Structure of GAN
GAN自发明以来,一直是深度学习领域研究的重点,又有多种变体,如DCGAN,将生成对抗网络与卷积神经网络结合,几乎完全使用卷积神经网络代替全连接层;条件生成对抗网络CGAN,在原始GAN的输入上进行改进,将额外条件信息如标签在输入阶段即传递给生成器与判别器;WGAN,在损失函数方面对GAN进行改进,提出wassertein距离损失函数与权重截断(Weight Clipping)措施,进一步提升了GAN的性能[18];WGAN-GP[19],在WGAN基础上进行改进,提出权重惩罚措施,有效防止WGAN可能发生的梯度消失、梯度爆炸以及权重限制困难等问题。
3.2 残差块及其改进
残差块[20]包括:两个权重层,中间包含一个ReLU激活函数,然后是一个跳跃连接块,之后是一个ReLU激活函数。跳跃连接块可实现梯度的跨层传播,有助于克服梯度衰减现象。通过添加残差块,可以在加深网络结构的情况下,较好地解决梯度消失和梯度爆炸的问题。残差块结构如图3所示。

图3 残差块的结构Fig.3 Structure of res-block
本文改进的残差块包括:3个卷积层,每个卷积层都是3×3的卷积核。使用两个ReLU激活函数,这样可以达到较快的收敛速度,并且在第一个卷积层与第二个卷积层之间添加一个概率为0.5的Dropout层,这样有助于防止模型过拟合,同时加快模型训练速度。最后是一个跳跃连接模块,有助于解决梯度消失问题以及梯度爆炸问题。同时由于BN层已被证明会增加计算复杂性,并且降低性能[8],因此本文的判别器去除了批归一化(Batch Normalization, BN)层,同时,本研究领域内使用深度学习去模糊的研究,大都使用小批次进行训练,如Nah[8]等,训练批次为2;Kupyn[13]等提出的DeblurGAN,训练批次为1;Zhang[14]等提出的基于真实模糊去模糊,批次为4;使用小批次训练时不适合使用批归一化层。结构如图4所示。
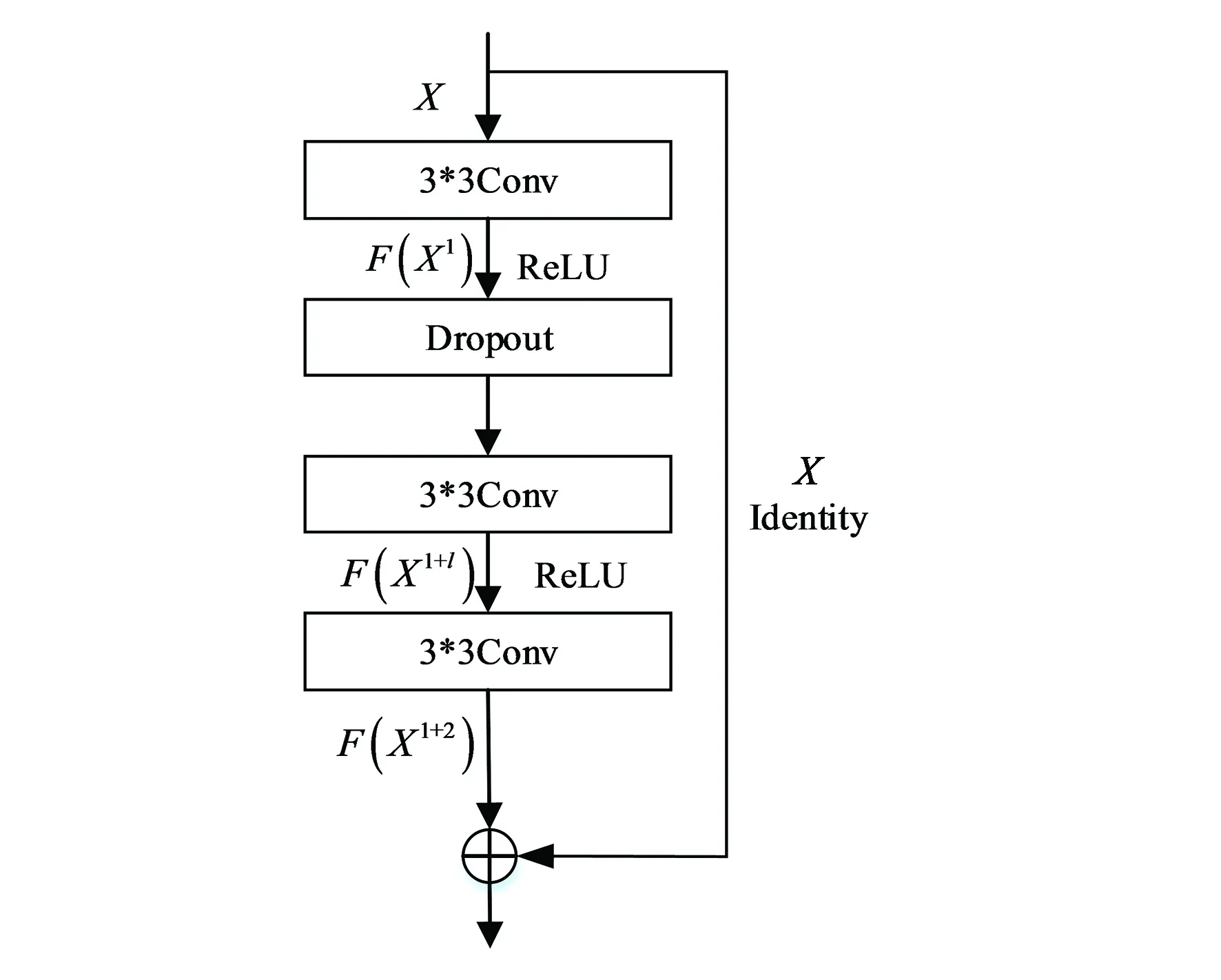
图4 改进残差块的结构Fig.4 Structure of improved Res-block
3.3 损失函数
本文使用WGAN[18]中的Wassertein距离为判别器的损失函数,其定义如下:

(7)
其中,x和y分别表示真实样本和生成样本,∏(Pdata,Pg)是Pdata和Pg的联合分布的集合,(x,y)~γ表示其中的采样,inf表示对采样出的真实样本和生成样本的距离期望,即E(x,y)~γ[‖x-y‖]取下限。
同时,本文使用内容损失[12](Content loss)作为生成器的损失函数。内容损失是一种基于生成图像和目标图像的CNN特征图差异的L2损失,不同于普通的L2损失,内容损失通过预训练的网络某一层的输出特征来定义:
(8)
其中:Φi,j代表通过预训练卷积神经网络提取的特征图,本文使用的预训练模型为VGG16。Wi,j和Hi,j为特征图的大小。
4 网络结构
4.1 生成器的网络结构
受到Johnson[12]等提出的用于风格迁移任务的网络的启发,本文生成器网络结构如图5所示。其中的编码器层(Encoder)和解码器层(Decoder)均包含3层卷积层,每个卷积层后面还包括一个ReLU激活函数层。生成器中所有卷积层的填充方式均为same。最后的激活函数使用tanh激活函数,除此层外,生成器的激活函数均为ReLU激活函数。在这些结构之上,生成器中还包含一个跳跃连接块,用于解决由网络深度过深带来的梯度消失、梯度爆炸等问题。

图5 生成器的网络结构Fig.5 Network structure of generator
4.2 判别器的网络结构
PatchGAN是由Phillip Isola等[21]提出的一种马尔科夫判别器。马尔科夫判别器可以将图像有效地建模为马尔科夫随机场。PatchGAN判别器试图对图像中的每个N×N块进行分类,以确定其真假,在图像上卷积运行这个鉴别器,对所有响应进行平均,作为最终的判别器输出。Patch通过5层卷积层的叠加,将最底层卷积层的感受野扩展为70×70。
受到PatchGAN判别器的启发,本文对其进行改进,在参数数量只增加2.38%的前提下,将最底层感受野提升至142,而运行时间几乎没有增加。在PatchGAN中,最后对网络输出的特征图取均值作为判别器的最后输出。为了进一步降低算法复杂度,改进的网络在网络最后使用全局平均池化层代替均值操作,同样可以做到求取特征图均值的效果。PatchGAN结构以及本文改进的PatchGAN结构如表1和表2所示。

表1 PatchGAN结构图Tab.1 Structure of PatchGAN

表2 本文提出的改进PatchGAN结构图
5 实验结果与分析
本文的仿真实验在配置有Tesla-P100的服务器上进行,服务器系统为CentOS 7,使用TensorFlow2框架与Adam优化器,初始学习率设置为10-4。经过若干次迭代训练,最终学习率线性衰减到10-7。
由于本文网络结构的输入要求,需要将训练数据集中的图片剪裁成256×256大小的图片。而生成器中全部都是卷积层,不存在全连接层,属于全卷积(Fully Convolutional Networks, FCN)神经网络,可以应用于任意大小的图像。
5.1 数据集信息
本文采用GOPRO数据集和Lai数据集[24]对本文算法的复原效果进行测试。
GOPRO数据集是目前进行图像去模糊研究的最常用的数据集之一,其使用GOPRO4相机拍摄240帧/s的视频,然后生成模糊图片来模拟真实的运动模糊。该数据集由3 214对清晰和模糊的图像组成,每张图像的分辨率都是1 280×720。我们采用其中2 103张图片作为训练集,其余1 111张图片作为测试集,并将其剪裁为256×256大小的图片,作为神经网络的输入。
Lai数据集是一系列真实世界的模糊图像,是在真实场景中由不同的相机、不同的设置与不同的用户处捕捉的,没有清晰的对照物,无法进行定量分析。
5.2 图像质量客观评价
图像复原仿真实验的结果通常选用峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)和结构相似性(Structural Similarity, SSIM)两项指标进行衡量。
表1的实验结果表明,在GOPRO数据集上,本文提出的基于深度残差生成对抗网络的运动去模糊算法具有更好的复原能力,可达到更高的PSNR和较高的SSIM。部分实验效果如图6所示,其中左侧部分是模糊图像,中间部分是去模糊效果图,最右侧是清晰图像。

表3 GOPRO数据集上不同算法质量评估结果

图6 GOPRO数据集复原效果Fig.6 Restoration effects of GOPRO dataset
5.3 Lai数据集主观评价
图7是Lai数据集中测试图像face2去模糊效果比较图,第一行图片从左至右依次是模糊图像,Sun[26]等、Krishnan[27]等、Whyte[28]等的结果;第二行图像从左至右依次是Nah[8]等、Pan[2]等、Xu[29]等、本文算法的结果。从图中可以看出,本文提出的算法能够很好地获得复原效果,从图中可以清楚地获取图片人物的细节信息。

图7 Lai 数据集去模糊效果定性比较Fig.7 Qualitative comparison of deblurring effects of Lai datasets
6 结 论
本文对图像去模糊领域进行了研究,提出了一种基于深度残差生成对抗网络的运动去模糊算法,实现了精度更高的运动模糊图像盲复原。改进了残差块的结构,使之能更好的地适应图像去模糊领域的应用,改进了PatchGAN的结构,在网络参数只增加2.38%的前提下,将其最底层感受野提升至原先的两倍以上。实验结果表明,在GOPRO数据集中,本文提出算法复原的图像可达到较高的客观评价指标,峰值信噪比PSNR可达到28.31 dB,结构相似性SSIM可达到0.831 7,可以恢复出较高质量的清晰图像。在Lai数据集上,复原的图像可以达到较好的主观视觉效果。
