面向数字人文的辞书关联数据知识组织*
2021-12-15张志美钱智勇
张志美,陈 涛,钱智勇,何 书
0 引言
辞书古代又称 “字书”,是记录语言和语言文化的载体,用来解释字形、读音和释义,是馆藏重要文献资源和人文研究的重要工具。古代辞书知识涉及文字、音韵、语法、修辞、词汇、校勘、句读、句段、篇章等内容。先秦时代的《尔雅》是世界上第一部按同义和百科分类的义类综合性语文辞书,尔雅以古代中原地区规范通用的语言训释上古典籍中的难字和百科异名,反映了先秦时代的社会生活,是人类宝贵的文化遗产[1]。汉代以来的《尔雅》注疏文献是研究典籍文献及先秦语言和文化的知识宝库[2],也是大数据时代重要的知识组织工具。利用现代技术研究古代经典辞书,使非结构化的古代语言知识成为互联网的结构化的开放互联数据,通过网络传承中国优秀传统文化,是通过推动中华优秀传统文化创造性转化和创新性发展,让收藏在博物馆里的文物、陈列在广阔大地上遗产、书写在古籍里的文字都活起来的重要手段[3]。以元数据为基础的关联数据已经成为通用的语义互联的标准规范,利用关联数据对辞书知识组织,以三元组存储词汇知识库,是典籍数字人文的基础建设。网上已发布的词表中包括了大量现代语言同义词和语义概念关系,大量的词表本体研究与实践,为尔雅词表本体构建提供了可以复用的数据和结构。构建尔雅词表本体可以实现尔雅词汇知识的跨语言知识检索与共享复用,将对外国留学生及其他读者检索中文古籍词汇提供帮助;通过词表本体学习、本体进化等技术,尔雅词表本体也将成为自然语言处理、搜索引擎智能检索、典籍标注和数字人文研究的重要知识组织工具。
1 关联数据知识组织与数字人文的关系
1.1 关联数据简述
关联数据(Linked data) 最早是Berners-Lee[4]提出的概念,初衷是将WEB中没有进行关联的数据链接起来,构建可被机器理解的包含语义关系的数据网络。关联数据有4个基本原则[4]:用URI来为任何事物标识名称;通过HTTP协议便于用户可以查找到这些名称;以RDF 和SPARQL的形式提供原始数据;尽可能提供链接以发现更多信息资源。关联数据的核心是资源描述框架(RDF),RDF 采用基于RDF/XML 的语法进行数据存储与交换,使用三元组(主语—谓语—宾语)并通过URI标识网络中的资源和元数据,资源的概念对应于主语,资源的属性类型对应于谓语,资源的属性值对应于宾语,主语与谓语使用唯一标识HTTP URI,宾语可以是字符串,也可以是其它对象实体,谓语反映了资源之间的关系。RDF定义的元数据描述方法不仅为各种类型资源的描述提供统一的数据模型,允许不同领域的用户根据不同资源编制各自所需要的词汇表描述领域元数据的语义,同时还提供不同元数据之间相互兼容,相互操作的平台。关联数据已经在大众传媒、图书馆、文化遗产、数字人文、政府电子政务、商业企业等领域广泛应用。
1.2 关联数据在数字人文中的作用
随着数字媒介和网络技术的快速发展,对不同载体文本进行保存、计算分析、编辑和内容建模等数字人文研究渐成趋势。在数字人文过程中关联数据的作用见图1,数字人文研究过程包括对数字资源组织与保存、文本计算分析、图像文本编辑和内容建模等方面。首先在数字资源的组织与保存方面,利用关联数据我们把网上各种结构化、半结构化和非结构化数据资源,通过URI链接,以RDF/XML三元组语法描述,并以专门用来存取RDF数据的三元组数据库保存各种数据。其次,在对文本的计算分析过程中,利用关联数据、本体、描述逻辑语言对文献进行字词句关联查询、校勘分析、注释内容比对分析、版本分析、概念关系抽取、作品作者时空分析等处理。第三,在数字人文的文本编辑阶段,利用关联数据技术与国际图像互操作框架结合,对文本中的图文声像等开放数据进行基于不同时期作品的编辑,例如对一部典籍作品在历史形成过程中出现的各种不同版本、修订情况进行整合编辑,利用国际图像互操作协议(IIIF)对各种版本的图像文本进行图像编辑并基于RDF的知识图谱展示串联成文献版本发现证据链,这种时空维度下的图像编辑将超越人文研究传统文本记录的界限。第四,在数字人文的内容建模阶段,可以根据不同文本内容结构,利用关联数据和已有本体模型结构对文本内容进行建模,在万维网的数字环境中,遵循已有的关联数据规范和推荐协议,完全可以为典籍文献、文化遗产、历史遗迹、考古等多维空间虚拟世界建立基于文本内容的仿真模型和研究场景。这些数字人文基础建设与应用过程是以数字资源描述框架为基础的关联数据理伭和技术为支撑的。反过来数字人文中的文本数字化保存、计算分析、图文编辑以及内容建模等过程也推进了以关联数据为核心的语义技术架构的改进和发展。
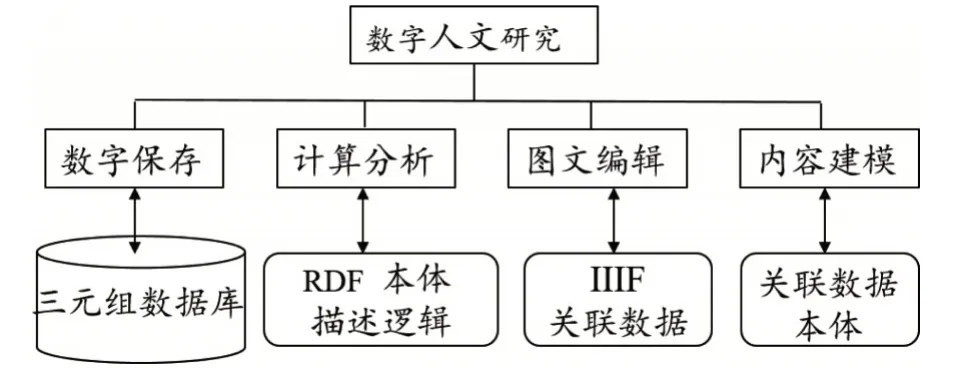
图1 关联数据在数字人文中的作用
1.3 图书馆关联数据与辞书知识组织相关研究
图书馆关联数据应用是以元数据和书目数据的转换为基础开始的。美国国会图书馆2017年将全部馆藏和规范目录从传统的MARC书目转换到BIBFRAME(书目描述框架)并推广使用。已经建成可供参考的重要本体词表包括元数据集(DCMI)、关联数据集词表、古籍书目本体等。国内采用关联数据技术研究构建特定领域叙词表应用成为趋势,近年国内馆藏文献资源关联数据知识组织相关研究有:夏翠娟等[5]基于关联数据四原则和语义技术框架设计和发布上海图书馆的家谱本体词表;白林林等[6]利用Drupal平台研究中文古籍书目关联数据发布过程;陈涛等[7]提出书目数据在BIBFRAME中的知识关联框架;侯西龙等[8]基于关联数据技术研究非遗知识组织与关联数据集构建的过程;王晓光等[9]研究敦煌壁画叙词表关联数据;徐晨飞等[10]研究方志物产史料关联数据构建与知识库应用。
在辞书语义知识组织研究方面有:《同义词词林》[11]及其编码系统将汉语词汇按语义分为大类、中类和小类,类下再以同义主题归集;知网概念关系词表(HowNet)揭示汉、英词语概念以及属性之间的关系;中英双语知识本体词网(ECTEC)是结合词网、知识本体与领域标记的词汇知识库;WordNet以同义词集合表示语义概念;FrameNet使用“框架元素” 进行词汇含义描述。已有的研究在关联数据标准规范、中文名称规范语义描述、本体构建、词汇语义相似度计算和词汇语义分类等方面的研究与实践成果为本文的研究提供了理伭指导和方法借鉴。辞书是人文研究的重要工具,利用关联数据对中国古代辞书中词汇语义进行知识组织是数字人文基础建设的重要内容。本文以《尔雅》词表构建、本体模型设计与关联数据发布为例,探索辞书关联数据知识组织理伭方法与实现过程,以期推进古代辞书典籍的知识组织与数字人文研究。
2 尔雅词表构建与本体设计
2.1 尔雅词表构建概述
《尔雅》是中国第一部按词义和分类编排的综合性语文辞书。《尔雅》原有20篇,现存19篇按内容分为普通语词和百科名词两个部分[1]。普通语词即生活中常用的一般词语,包括“释诂”“释言”“释训” 三篇。《尔雅》百科名词共分16个大类,其中有解释古代亲属关系的 “释亲”,有解释和反映上古人类日常生活的“释宫”“释器”“释乐”,有解释古代天象称谓的 “释天”,还有解释古代动物称谓的 “释虫”“释鱼”“释鸟”“释兽”“释畜” 等,每个类篇目下细分小的分类。这些分类反映了战国至秦汉时代人们的衣食住行等社会生活和文化知识结构,尔雅训诂资料也成为后人通释经书和典籍文献的参考工具。课题以实现辞书典籍语义知识检索与辅助数字人文研究为目标,研究尔雅多语词表构建。选取上海古籍出版社2004 年出版的简体本《尔雅译注》(胡奇光,方环海著),该书是上海古籍出版社邀请名家历经10年完成的简体中文《十三经译注》之一,可帮助读者最大程度读通和理解原著;尔雅注释还参照南开大学出版社1987年出版的《尔雅今注》(徐朝华著),该书是当代第一次使用语体文为尔雅作注的著作[2]。上述书中的注释原句引用参考郭璞《尔雅注》、邢昺《尔雅疏》、郝懿行《尔雅义疏》、邵晋涵《尔雅正义》、孙炎《尔雅音义》、黄侃《尔雅音训》、阮元《尔雅注疏校勘记》,释义例句参考许慎《说文解字》、刘熙《释名》、杨雄《方言》、顾野王《玉篇》、司马光《类篇》、陈彭年等《广韵》、陆德明《经典释文》等典籍。尔雅词表中的词汇结构由训释词语、被训释词语、例证三部分组成。
尔雅中的训释词语包括类义编码和释义两个部分。对每个被训释词语给出唯一的类义编码,词语编码参考《同义词词林》的分类编码规则,以英文字母大写的A-S表示《尔雅》中的十九个大类,以英文字母小写的a-y表示大类之下的2级小类,小写字母z表示0,以001-999位数字代表概念同义词集。训释词语或百科名词称谓包括中文、英文、日文、韩文,分别以语种标签cn、en、ja、ko区分语种标记。
被训释词语内容包括汉语拼音、注音、古今字、异体字、通假字,释义(中文、英文、日文、韩文)、典籍中注释原句(加双引号)、注释者(注者名、字、朝代、籍贯),注释句典籍出处、典籍中注疏原句和注疏者(名、字、朝代、籍贯)。
例证包括典籍中的例句、例句出处、例句作者(名、字、朝代、籍贯)、例句注释语句、例句注释者(名、字、朝代、籍贯)、例句注释出处、例句注疏语句、例句注疏者(名、字、朝代、籍贯)、例句注疏语句、例句注疏出处、例句注笺句、例句注笺者(名、字、朝代、籍贯)和例句注笺出处。
尔雅词表全面反映了被训释语词的读音、字形变化、多语种释义、分类、例证及其注、疏、笺等内容。比如“释器” 中的被训释词语“罍”的完整标注如下:
罍/léi/ㄌㄟ'/壶形青铜酒器/Ff003/(cn)古代壶形酒器,与壶相似,用来盛酒或水,多用青铜铸造,亦有陶制的/(en)Ancient pot shaped wine vessels/(ja)古代の壷形酒器/(ko)고대주전자형술그릇/“罍,酒尊也。”/陆德明(名元朗,字德明)/唐/苏州吴县(今江苏省苏州市)人/《经典释文》/“罍者,尊之大者也。”/邢昺(字叔明)/北宋/曹州济阴郡(今山东省菏泽市曹县北) 人/《尔雅疏》/“我姑酌彼金罍,维以不永怀。”/《诗经·周南·卷耳》/“罍,酒器,刻为云雷之象,以黄金饰之。”/朱熹(字元晦,又字仲晦,号晦庵)/南宋/南剑州尤溪(今属福建三明市尤溪县)人/《诗经集传》
这段标注中被训释词 “罍” 的类义编码Ff003中,F表示大类“释器”,f表示小类“酒器”,003表示小类“酒器” 中的壶形青铜酒器,通过Ff003就将不同语种的“罍” 的解释映射出来,从而实现语义关联和跨语言检索。由语言学老师与多名古汉语、英语、日语、韩语研究生,根据《尔雅译注》中词语的简体中文释义,借助翻译词典进行词语释义的手工翻译、标注和校对工作,我们完成了尔雅简体字版本共3584个被训释词语和百科名词称谓,以及2219个训释词语和百科名称的多语种释义。尔雅词表的标注为尔雅本体设计完成了数据准备。
2.2 尔雅词表本体设计
2.2.1 尔雅词表本体的定义与设计原则
本体在牛津词典中解释为:本体是关于某个主题领域中的概念和类别并显示它们之间的关系的列表。在知识工程领域,Neches最早给本体的定义为[12]:特定主题领域词表基本术语及关系,再结合这些术语及关系定义词表的外延规则。汤姆·格鲁伯给本体定义为[13]:一个共享的概念化模型的明确规范说明。张晓林认为[14]:本体就是概念集,是特定领域内公认的关于该领域的对象及其关系的概念化表示,包括对象类等级体系、类属性及取值约束、对象类之间逻辑关系、对象类及关系的推理规则。根据上述本体概念的解释,结合尔雅词表的内容结构,给尔雅词表本体定义为:尔雅词表本体是利用本体语言和规范描述尔雅词表中的被训释词语及百科名词释义并给出词间关系的可视化的语义词表。用ERYA表示尔雅词表本体,公式表示为:ERYA={C,P,I,O},公式右边括号中的C为概念,在尔雅词表中包括全部训释词语和类义编码;P为属性,包括对象属性和数据属性;I为实例;O为公理,表示概念的永真断言,用于被训释词语之间隐含关系推理。与关系型数据词表相比,尔雅词表本体的最大作用是实现基于尔雅训释词语概念的分类检索和词表的关联数据开放服务,便于与其他词表互操作,实现尔雅知识共享和复用;可用于字人文中典籍文本的语义标注,使隐含在文本中的隐性知识显式化。
尔雅词表本体设计遵循三个基本原则:首先尽量利用现有的本体数据模型,找到相似本体的类、属性和关系,在它们的基础上添加、修改、创建本体;其次最大限度的重用已经发布使用的词汇表和术语以便于以后的关联,在此基础上创建新的术语类及其属性,尽量给新建词汇添加注释信息,如使用rdfs:label属性定义词汇标签;最后要为词表给出命名空间声明并赋予一个稳定、永久的URI,为本体本身添加注释,说明本体的版本及版本兼容信息,以利于尔雅词表的共享和重用。
2.2.2 尔雅词表本体设计步骤
尔雅词表本体模型设计采用自上向下与自下向上相结合的方法,尔雅词表总体设计采用自上而下的元数据分析方法,参考国家图书馆的《基于元数据的本体构建规范与应用指南》[15],本体模型设计采用自下而上的方法,通过对词表进行内容分析,制定本体设计流程和步骤。将尔雅词表本体的设计流程概括为三个步骤。
(1)定义尔雅词表概念类。通过对尔雅词表标注字段及内容的分析,定义尔雅本体的实体具名类。类是具有共同属性特征的个体或对象的集合,所谓具名类就是由设计者在创建本体时直接定义并赋予明确名称标识的类。
在定义具名类时,共定义5个类(见表1)。从尔雅词表的元数据中看出,一条完整的被训释词主要涉及到对尔雅被训释词的解释(erya:Concept)、被训释词所属分类(erya:Category)、被训释词所在原始例句(erya:Sentence)以及例句的典籍出处(bibo:Book)几大信息块,其他的具体信息都可以归纳到这几大信息块中,为后续可以和更多的人物知识库关联,在典籍出处中又单独抽出人物类。考虑可以复用现有本体包括国会图书馆bibo 书目本体和foaf 本体的人物类(foaf:Person),首先定义一个表示尔雅概念的类,我们定义一个“Concept” 类表示词表实体对象的概念集合。尔雅词表中的词语释义和例证来自典籍文献,把典籍实体抽取出来定义一个表示所有注释和例证出处的类,这里复用bibo本体中“bibo:Book” 类。尔雅词表中的训释词语都有唯一的类义编码,根据尔雅的分类编码定义一个“Category”(分类)类。尔雅词表中的词语释义包括中英日韩多语释义句子,还包括例句及其注、疏、笺句,为集中表示句子概念实体,定义了一个“Sentence”(句子)类。尔雅词表中的人包括作者、注者、注疏者、注笺者等,关于人的实体,有成熟的本体类,复用foaf 本体中的“foaf:Person” 类。这样就完成尔雅词表本体5个实体类的构建。尔雅词表本体类构建代码如下:
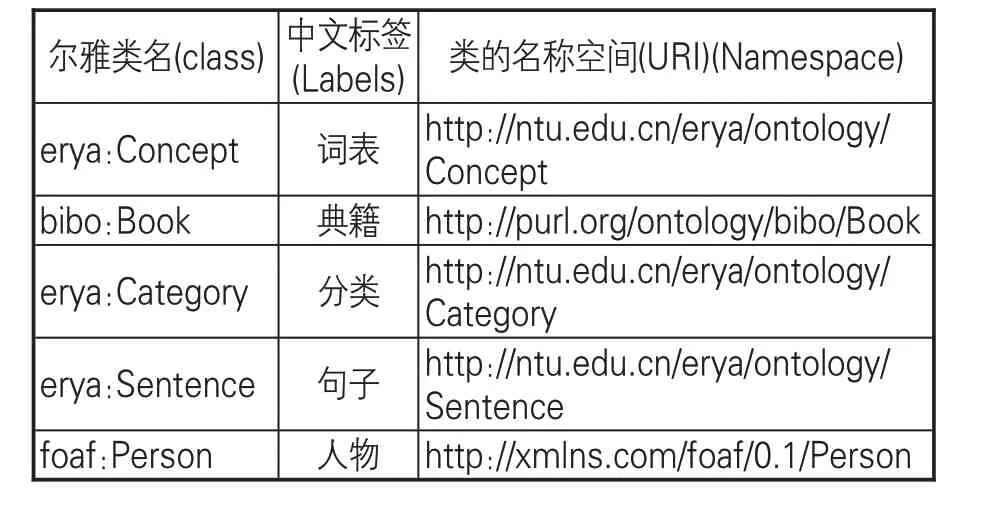
表1 尔雅词表本体类


(2)定义词表本体类的属性及其属性约束,完成尔雅词表本体模型(见图2)构建。词表本体中属性的作用是描述类的主要特征以及类和类、类和实例之间的关系。属性主要有两种,一种是对象属性,描述的对象是实体类,另一种是数据类型属性,描述的对象是字符串、数字、日期等数值型数据。每个属性都有定义域(领域)和值域,定义域是指属性的应用范围(领域中的哪些类),值域是指属性的取值范围,对于对象属性,其值域是某个类,对于数值属性,其值域就是不同数据类型。尔雅词表本体类的对象属性见表2,词表本体的数据属性见表3。
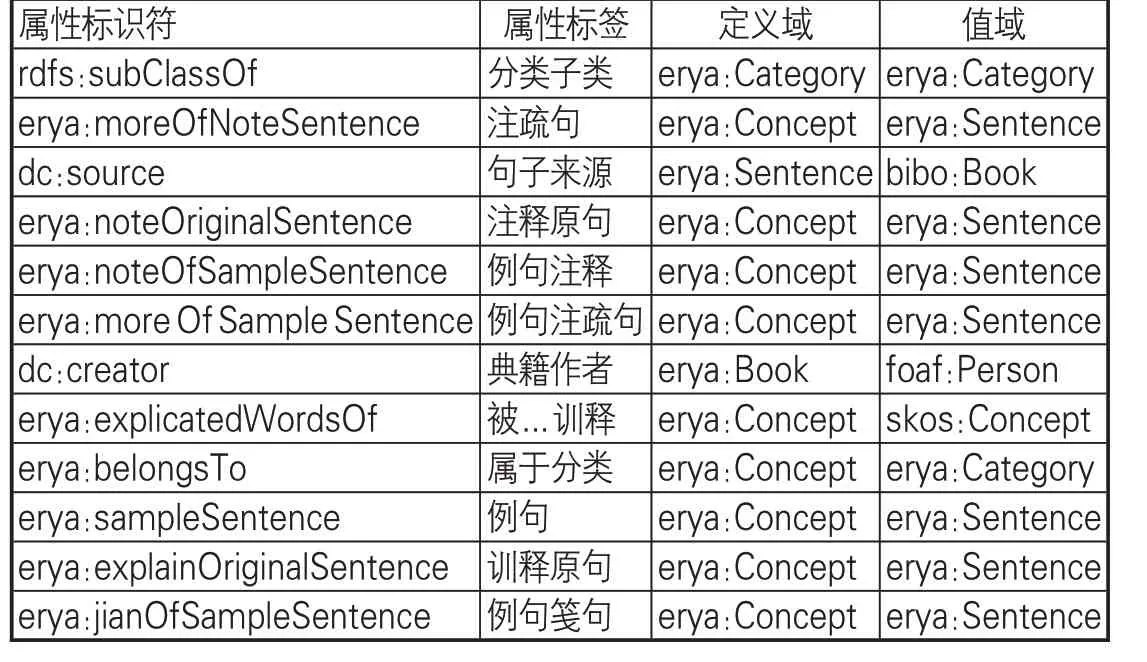
表2 尔雅词表本体的对象属性
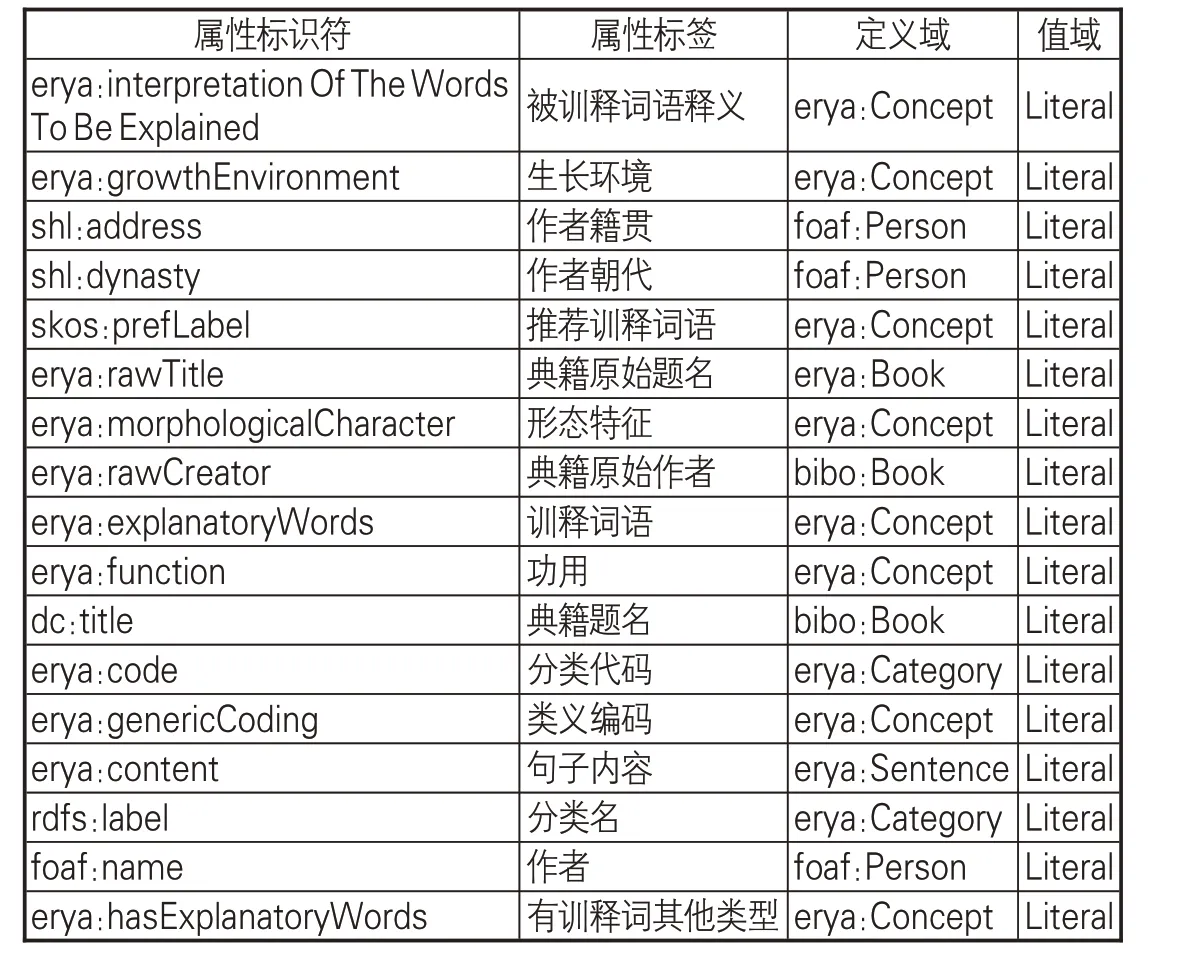
表3 尔雅词表本体的数据属性
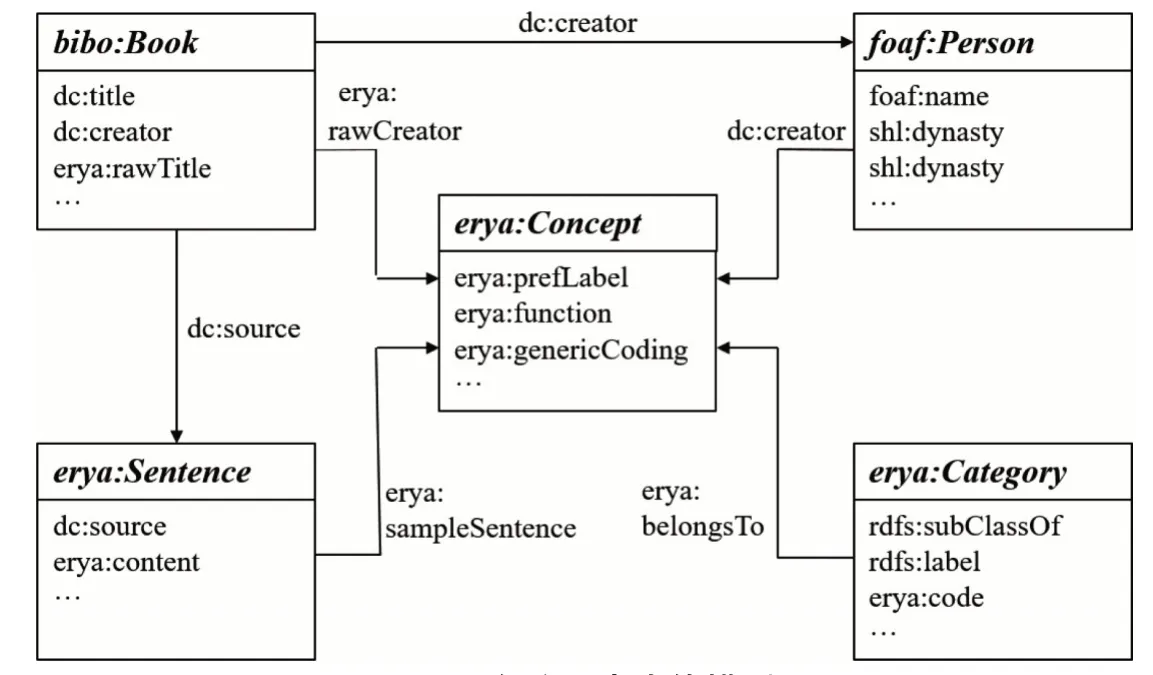
图2 尔雅词表本体模型
通过概念抽取程序完成尔雅词表本体2,219个训释词语概念,3,584个被训释词语和百科名词异名的术语实例,其中释诂被训释词语1,029个,释言词语653个,释训词语249个,百科词语1,650个。通过12个对象属性和17个数据属性及其约束实现了基于训释词语概念的多维度语义关联。图3可视化展示了尔雅词表本体的概念类及属性关系。
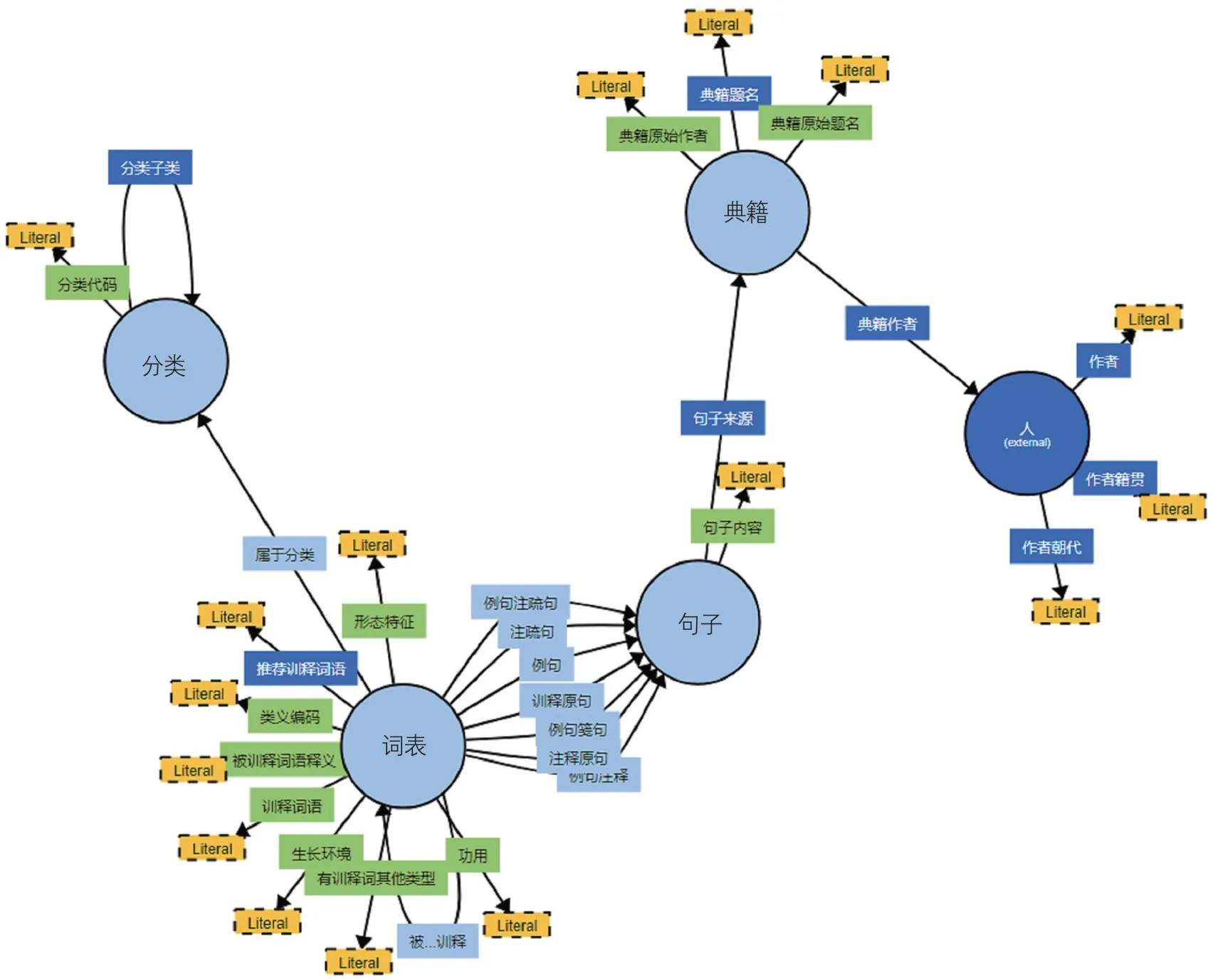
图3 尔雅词表本体可视化
(3)为本体本身添加注释属性并完成本体的测试、修改和完善。为本体自身添加注释属性包括版本信息及名称空间声明,版本信息包括版本号、URI、发布机构以及版本兼容信息等,以利于本体的共享和重用。本体的测试采用上海图书馆本体服务中心校验系统对尔雅词表数据的正确性和一致性进行数据检验,并根据检测结果对尔雅词表本体文档进行纠错和优化,保证了尔雅词表本体数据的正确。
3 尔雅词表本体关联数据发布与检索
3.1 关联数据发布规范与步骤
关联数据发布是依据关联数据基本原则对结构化、半结构化和非结构化数据作了规范和限定之后,通过一定技术步骤发布出来以供检索与数据开放共享的过程。国外图书馆书目数据、叙词表、元数据相关标准等较早发布为关联数据本体[16-17]。随着关联数据发布实践的逐渐增多,近年来国内图书馆领域对关联数据构建的研究水平有很大提高。王忠义等[18]研究将分布式人类计算(DHC)应用于数字图书馆的深层关联数据发布架构;牛永骎等[19]通过开源软件D2R发布图书情报领域学者的关联数据集,探索实体URI定义、作者重名、专著与网络学术记录难以采全等问题;陈涛等[20]以关联数据七星模型为基础,结合国外和国内诸多关联数据发布平台实施的实例,深入分析关联数据创建与发布过程中存在的问题和对策思考,提出了关联数据发布的十个常用规范和建议。这些研究与实践为尔雅词表关联数据的发布提供了指导和借鉴。根据尔雅词表本体的内容性质与特点,我们提出尔雅词表关联数据发布的六个基本步骤(见图4)和遵循的规范。

图4 本体词表关联数据发布流程
(1)词表数据准备。设计尔雅词表URI时,考虑尔雅URI 除作为尔雅词表本体的标识名称之外,还考虑到在尔雅词表发布后,方便领域人员通过HTTP访问尔雅词表资源,设置URI采用了机构域名http://ww.ntu.edu.cn/erya/ontology/,这样便于今后永久访问尔雅词表资源同时利于复用和与其他词表的关联。
(2)词表本体设计。抽取尔雅词表的数据结构,按照知识组织的标准规范设计尔雅词表本体,尽量复用已有本体,复用和扩展本体属性时,区分对象属性与数据属性,尔雅本体设计过程中复用了dc、bibo、foaf等词表规范。
(3)词表关联数据转换。依据本体将尔雅词表中的数据转换为RDF格式,从尔雅文本的结构化表格转换为关联数据。除了提供SPARQL端口形式以访问尔雅词表数据之外,还提供尔雅词表资源的内容协商获取方式,支持机器可读和复用。
(4)词表的数据存储。将转换好的关联数据存储到数据库,采用三元组数据库存储尔雅词表的RDF数据,选用适合尔雅词表的图模式进行词表的数据存储并与尔雅词表的关系型数据库及词表索引库共存。
(5)词表的发布。按照关联数据四个基本原则与开放数据的七星标准,发布尔雅词表本体和词语训释实例数据。描述尔雅资源时严格区分尔雅本体的类与属性,在发布尔雅词表数据集的同时,以高可读性形式发布尔雅词表数据集对应的尔雅词表本体,并加注本体的元数据信息。
(6)词表本体可视化检索与应用。提供的数据服务包括尔雅词表的检索,提供尔雅数据集的数据状态,词表检索结果的可视化,通过本体对齐,尔雅词表与外部词表的链接,支持典籍语义标注研究。尔雅词表按照这样标准化的步骤和规范发布出来,所有的词汇都是实体,可以元数据注释自解释,尔雅词表不仅被机器可读,而且被任意链接复用,尔雅词表中的词语概念、关系都可以被重用,实现更大范围的词表资源互操作。
3.2 尔雅词表关联数据转换与发布
尔雅词表是基于Excel 的数据表,使用Excel2RDF数据映射转换完成三元组数据发布。Excel2RDF映射过程见图5。例如,尔雅原始词表中的被训释词“俶” 的内容结构见表4-5。
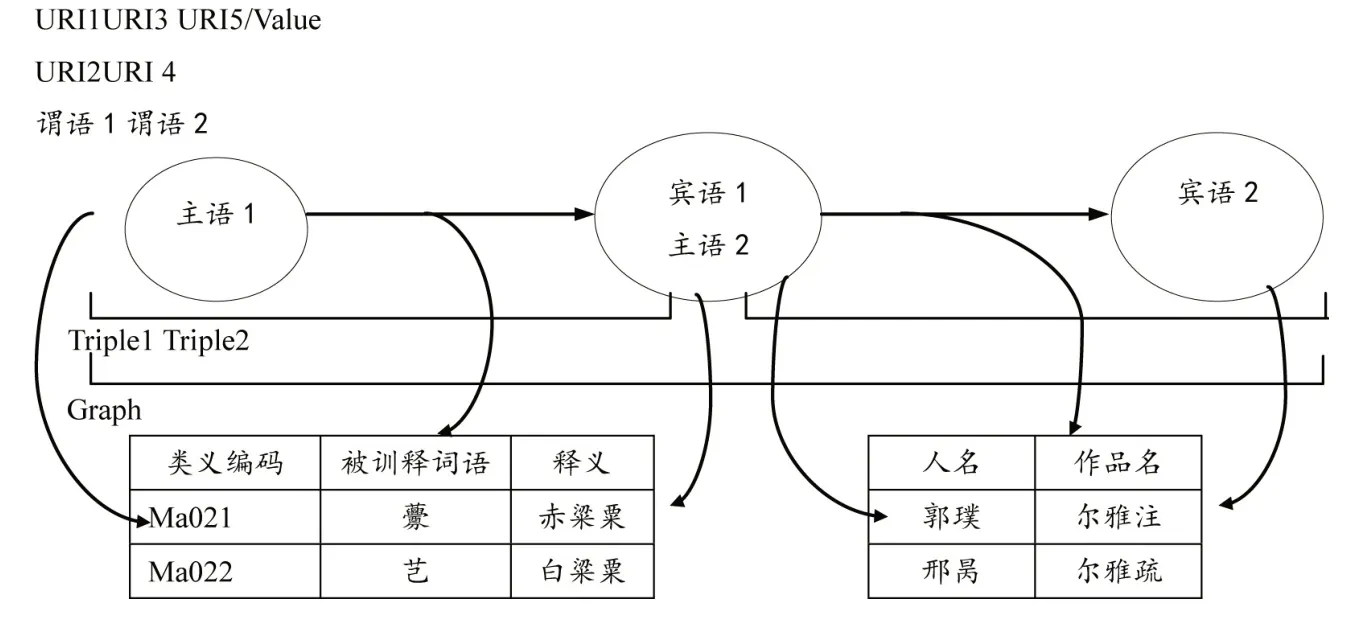
图5 尔雅词表Excel2RDF映射过程

表4 “俶” 的训释词语类义编码

表5 “俶” 的音、形、义标注
第一层是类义编码层,类义编码 “A”,表示“训诂” 类,给出“类义编码” 的随机码URI作主语,取值“A” 作宾语。第二层是训释词语层,训释词语“始也(开始)” 的“类义编码” 是“Az001”,“训释词语”(ch、en、ja、ko)分别作谓语,表中对应不同列(不同语种的“始也”)作宾语。第三层是有关被训释词语 “初” 的所有列(表中节选了部分),表中的列还包括“俶” 的读音、注音、古今字、异体字、通假字、释义、注释原句、注释出处、注者、注疏句、注疏出处、疏者、例句、例句出处、例句作者、例句注、疏、笺等,行的主键值 “俶” 作主语,表中的这些列都被作为谓语抽取,行的句子数据取值被作为宾语抽取。通过这样的三层代码转换,完成尔雅本体词表从Excel到RDF的映射。被训释词语 “俶” 的RDF映射转换代码如下:

词表本体简单的存储方法是以文件方式保存,适用于数据量小的静态文件,如已归档的本体文件。对动态的数据库和表格数据的存储以图数据库为主流。尔雅词表本体是动态表格数据,选择三元组数据库存储(Triplestore),优点包括:模式灵活,可对RDF存储进行相当于模式更改的实时操作,无需任何停机或重新设计;使用轻便,RDF存储通常通过HTTP进行查询,易放入服务架构;语言标准,使用RDF和SPARQL实现的标准化水平远高于SQL,在系统之间移动数据易,因为语言统一;表达方便,在RDF中对复杂数据建模要比在SQL 中容易,查询语言SPARQL的操作更容易;踪迹可寻,SPARQL允许用户跟踪每一条信息的来源,并存储关于它的元数据,轻松完成复杂的查询。尔雅词表本体选择使用OpenLink Virtuoso进行存储,OpenLink Virtuoso支持关系数据、对象-关系数据、RDF数据、XML数据和文本数据的统一管理,支持sparql1.1语法查询,支持W3C的关联数据系列协议,可以把三元组数据直接存储在数据库表中,定义了RDF_QUAD表,每个三元组存储为RDF_QUAD中的一行,表的列分别代表图、主语、谓语和宾语。RDF_DATATYPE表,保存宾语的类型名和2个字节值的映射。
3.3 尔雅词表本体的检索与利用
3.3.1 尔雅词表本体的SPARQL检索
尔雅词表本体存储到OpenLink Virtuoso后,可以通过SPARQL直接检索尔雅词表中的词语,SPARQL是W3C制定并推荐的在RDF数据库中查询和操纵RDF数据的语言和协议,可根据需要通过SPARQL语句描述尔雅词表中的变量及其关系,构成带有变量的图模式查询表达式,例如查询尔雅被训释词语“元” 的所有释义,构造SPARQL表达式查询见下,SPARQL查询结果如表6。通过SPARQL 的Restful API 接口,外部系统可以查询和关联到尔雅词表,并获取相关词在尔雅词表中的所有关联信息。
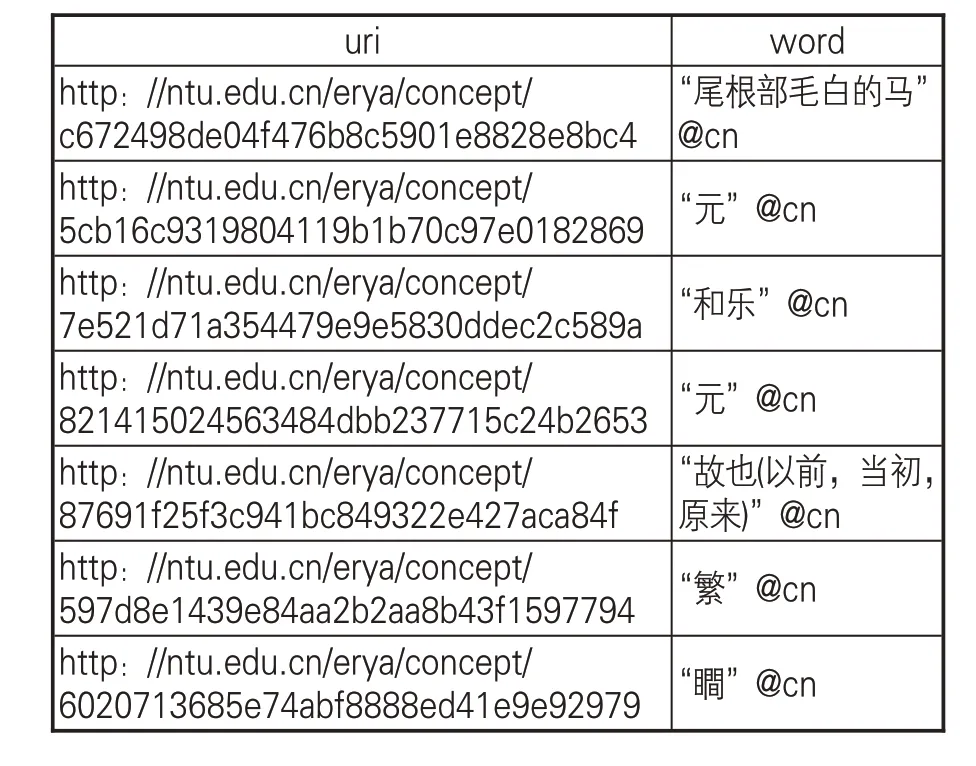
表6 尔雅词表SPARQL检索结果

3.3.2 尔雅词表本体可视化检索系统
尔雅本体词表检索通过可视化检索平台SOOOPA,可以检索尔雅词表中全部被训释词语及实体类、属性关联,并可视化显示每个实体类及其个体词语的三元组。比如,查询 “马”,如图6列表显示尔雅词表中“释畜” 类下马属子类的全部97 个马的训释词语以及被训释词语不同马的称谓及中、英、日、韩语释义,注释出处,例句等三元组数据。图7可视化显示 “释畜” 类 “马属”“骃” 字的关联数据知识图谱,图中展示古代一种被称作 “骃” 的马的中、英、日、韩文释义、属种、注释原句、注释出处、诗经中的例句及注释,也关联与“骃” 相关的其他马的称谓及其解释,这种图像化的词汇知识便于读者研究和学习古代语言,同时多语言释义也方便了外语读者和留学生学习中国古代汉语时作为检索工具。后续将尔雅词表本体与图书馆古籍书目本体关联,可以扩充检索尔雅注释馆藏出处和版本信息。
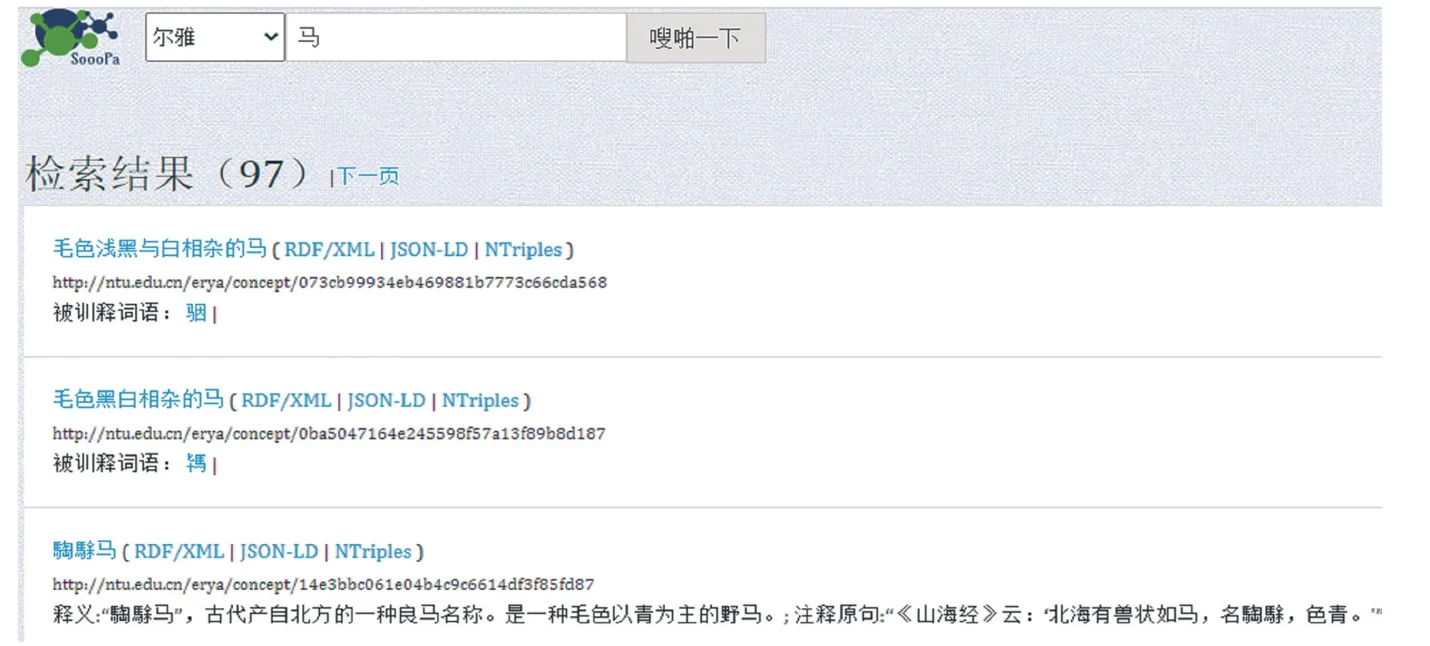
图6 尔雅词表本体概念检索“马”

图7 尔雅词表中“骃” 字关联数据知识图谱
4 结语
为实现古代经典辞书语义知识组织和数字人文研究,通过对辞书尔雅内容的分析,以简体本的《尔雅译注》为基础,构建含有中、英、日、韩文释义的尔雅词表,基于此探索以词表、典籍、句子、分类和人物为实体类的尔雅词表领域知识本体构建,并定义概念属性关系,完成尔雅词汇的实例抽取;再依据本体,对尔雅词表进行关联数据映射转换与存储发布,实现尔雅词表本体知识的跨语言关联检索与可视化呈现,为典籍数字人文提供了可以复用的辞书多语语义词典。不足之处在于尔雅词表本体构建基本以手工方式为主,词汇内容仅选取的简体中文版的尔雅注释,词汇英文、日文、韩文释义是参照《尔雅译注》 中的简体中文释义手工翻译,难免有对古文释义的深度翻译不到位的地方,此外还需要丰富不同版本馆藏古籍注释中的词汇释义。可以通过辞书典籍标注的众包平台,由更多的人文学者参与辞书标注与校对,并研究利用机器学习和自然语言处理的中文分词和语义标注技术,对典籍注释进行半自动标注,并在词表中添加尔雅图像的内容和注释,丰富词表的语言和知识。未来通过研究词表本体对齐和本体映射技术,可以将尔雅词表与wordnet 英、日、韩文等多语词表进行映射关联,实现词表词语更大范围的在线关联检索。此外,还可以利用尔雅词表构建《诗经》《国语》等典籍知识图谱,再与机器深度学习技术相结合,对中国典籍文献进行跨学科机器翻译、智慧学习等数字人文应用,通过预测典籍知识单元之间的各种关系,包括概念之间的生成关系、上下文关系、同义关系等,从关联的辞书和典籍资源中发现新概念和属性关系,并应用于在线学习平台,支持读者和外国留学生碎片化阅读和自助学习。通过对不同时间和地点不同作者的词汇释义聚合、比对、推理分析计算,辅助人文学者进行典籍文本挖掘与知识发现研究。
