面向方志类古籍的多类型命名实体联合自动识别模型构建*
2021-12-15李娜
李 娜
0 引言
方志即地方志,是在一定体例范畴中,系统记载特定时空下自然、社会、政治、经济、文化等各个方面情况的专门文献,被誉为“一方之全史”[1],以起源早、类型全、数量多等特征而闻名[2]。我国保存至今的宋至民国的方志就有8,264种,11万余卷,成为重要的文化遗产宝库[3]。地方志承担着传承中华文明、延续历史智慧的使命,“要了解中国文化,必须先了解中国的地方志”[4];它也是一座强大的远期数据库,担负起决策信息支持任务[5-6],整理和利用地方志是我国的优秀传统。1950年代著名农史学家万国鼎组织力量,从40多个大中型城市、100多个文史单位的7,200余部地方志中手工整理摘抄物产专题资料,涉及宋至民国期间近900年全国范围内的物产品种、种植与饲养方法、利用技术等农业生产的各个方面,是农史学界著名的红本子,曾接待国内外众多学者前来查询[7]。
命名实体(Named Entities)是指文本中人名、地名、机构名、时间、数量等具有特定意义的实体,是正确理解文本的基础。方志类古籍中的命名实体类型多、数量大,蕴含着丰富的关联关系和隐性知识;通过命名实体识别技术对多类型命名实体及其之间的关联关系进行分析,能最大化挖掘和发挥方志类古籍的价值。数字人文为方志类古籍文本内容的深度知识组织提供了技术支持[8]。作为学科融合的代表领域,数字人文跨越计算机科学、语言学、历史学、文学等学科[9],拓展了人文学科研究的广度和深度[10]。本文以《方志物产》山西分卷为研究语料,探索条件随机场模型在方志类古籍命名实体识别中的性能和前景。《方志物产》山西分卷共13本,约43万字,记载了明成化21 年(1485)至民国29 年(1940)间山西境内的物产及相关信息,共收录51,545条物产信息,涉及植物、动物和货物3个类别。在人工标注语料基础上,引入命名实体识别技术中的条件随机场模型,通过自动识别模型和人机交互系统的构建,实现物产文本信息中别名、地名、人名、引用名、用途名等五类命名实体的一体化自动抽取,形成物产相关的命名实体专题数据库,建立关联数据集,为知识发现打下基础。
1 中文古籍命名实体识别研究综述
命名实体识别作为文本信息抽取任务中关键而实用的一项技术,主要从电子文本中识别出人们感兴趣的命名实体,在多种语言和领域有着广泛的应用,其中英语语料由于词汇含义的单一性和文本结构的规则性,取得了良好的识别效果。中文字词含义的多样性和行文结构的连续性成为中文命名实体识别的障碍,尤其是中文古籍使用繁体字以及无句读等特点,更是为中文古籍命名实体识别带来了更大困难。在中文古籍整理领域,命名实体识别的相关研究成果主要集中在国内,从早期基于规则的研究发展到基于条件随机场的研究,再到深度学习技术的应用,逐步积累了一系列学术成果。
基于规则的研究主要采用词表和注疏等方式开展。徐润华等以《左传》为研究对象,在文献和注疏自动对齐的基础上,提出利用古籍注疏分词的新方法,F值达89%[11];留金腾等采用自动分词与词性标注,并结合人工校正的方法,实现《淮南子》语料库的构建[12];王嘉灵以中古史传文献《汉书》为例,利用地名表、人名表、注疏词表来提高《汉书》的自动分词效果[13];朱锁玲以广东、福建、台湾三省《方志物产》为语料,通过整理文中地名出现的规则,构建规则库,与文本内容进行匹配,实现地名识别,准确率为63.38%,召回率为82.89%[14];衡中青以《方志物产》广东分卷为例,基于规则的方法分别识别文中的引书和别名,其中引书识别的召回率和正确率分别为84.95%和72.88%,别名的召回率为88.6%、正确率为71.6%[15]。
基于条件随机场的研究是命名实体识别领域比较成熟的方法,取得了较好的识别效果。肖磊[16]、汪青青[17]、李章超等[18]分别针对《左传》中的地名、人名、战争事件结构的特点,基于CRF模型,分别实现地名、人名和战争事件的自动识别;梁社会等对比条件随机场和注疏文献在先秦文献《孟子》自动分词实验中的效果,发现二者均达到较高的水平[19];朱晓等选择编年体题材的《明史》作为研究语料,用交叉验证法对比了条件随机场的无边图、完全图以及嵌套图等3种模型的性能[20];黄水清等基于先秦语料库,分别使用条件随机场和最大熵模型对地名进行了识别研究,结果表明条件随机场的识别效果优于最大熵模型[21];李秀英设计了综合算法,完成了对《史记》汉英对照的术语抽取,实现了汉英典籍平行语料库的构建[22];黄水清等基于《汉学引得丛刊》中的《春秋经传注疏引书引得》制定词汇表,通过条件随机场模型,结合统计和人工内省方法确定的特征模板,完成对先秦典籍进行自动分词的探究,最好的调和平均值达到97.47%[23];王铮将条件随机场模型应用到《三国演义》的地名识别中,准确率为99.16%[24]。叶辉等通过融合多特征的CRF模型提升中医古籍《金匮要略》中蕴含的症状药物实体的识别效果[25];王东波等构建基于先秦语料库的CRF模型,自动抽取其中蕴含的历史事件,构成实体信息[26];袁悦等对比不同词性标记集在《左转》《国语》两部典籍命名实体识别效果的差异性,为先秦古文献实体抽取与词性标注提供借鉴[27]。
近年深度学习技术得到快速发展,并在相关领域逐步开展实验研究,呈现出较好的应用前景。谢韬基于Apriori算法和LSTM神经网络对宋词和《史记》语料进行新词发现实验,取得较好效果[28];李成名运用深度学习中的LSTM-CRF模型对《左传》中的人名、地名进行了自动抽取实验,识别率达82%以上[29];李焕基于BERTBiLSTM-CRF模型对中医古籍文本中的中医术语进行识别,明显提升了识别效率[30];徐晨飞等对比Bi- RNN、 Bi- LSTM、 Bi- LSTM- CRF、BERT等深度学习模型在《方志物产》云南卷中对人名、别名、引书和地名等实体的识别效果,验证了深度学习方法在方志类古籍实体识别中的可行性[31];杜悦等运用7种深度学习模型从25本经过分词和人工标注的典籍语料中抽取历史事件相关实体,验证了深度学习模型对大规模中文古籍文本挖掘的可行性[32];刘忠宝等在BERT 和LSTM-CRF 模型的基础上,提出了面向《史记》历史事件及其组成元素的抽取方法,F1值分别达82.3%和76.0%[33];崔竞烽等利用深度学习模型对菊花古典诗词中的时间、地点、季节、花名、花色、人物、节日等命名实体进行标注和识别,得出BERT 模型识别效果较为显著的结伭[34]。上述研究成果表明,在中文古籍整理方面,命名实体识别得到广泛应用,取得了良好的识别效果。随着技术进步,基于规则的方法逐步被基于CRF的方法和深度学习的方法替代。其中,条件随机场模型由于突破了隐马尔科夫模型的严格独立性假设限制,优化了最大熵模型的归一化处理,解决了标注偏差的问题,可以灵活融合上下文的多种特征,基于条件概率处理序列标注问题,且具有成熟的开源工具,在中文古籍分词领域有着良好的性能和广泛的应用;而深度学习模型正处于快速发展的阶段,稳定性和适用性都在逐步增强,拥有良好的应用前景。本研究选择将相对稳定成熟的CRF技术应用于方志类古籍的实体识别,综合对别名、地名、引用名、用途名、人名等五类命名实体进行一体化识别,并与其他基于规则和深度学习的实验结果形成对比。
2 识别模型构建
本研究过程主要分为3个部分:一是语料筛选和标注,即从《方志物产》山西分卷中选出备注信息不为空的物产信息,指定语料的标注原则,人工对物产的备注信息进行标注;二是机器学习和模型构建,将人工标注的语料打乱顺序后,平均分为10份,每次取其中9份作为训练语料,让计算机进行学习,分析并提取标注对象的内外部特征,形成特征模板,根据特征模板完成基于条件随机场的识别模型构建;三是模型测试,将训练语料以外的另一份语料作为测试语料,对基于条件随机场的识别模型进行测试,用召回率R、正确率P和加权平均值F作为测评指标,分析测评结果,评估模型性能。具体的技术路线如图1所示。本节主要探讨语料预处理、特征分析和模型构建的内容。
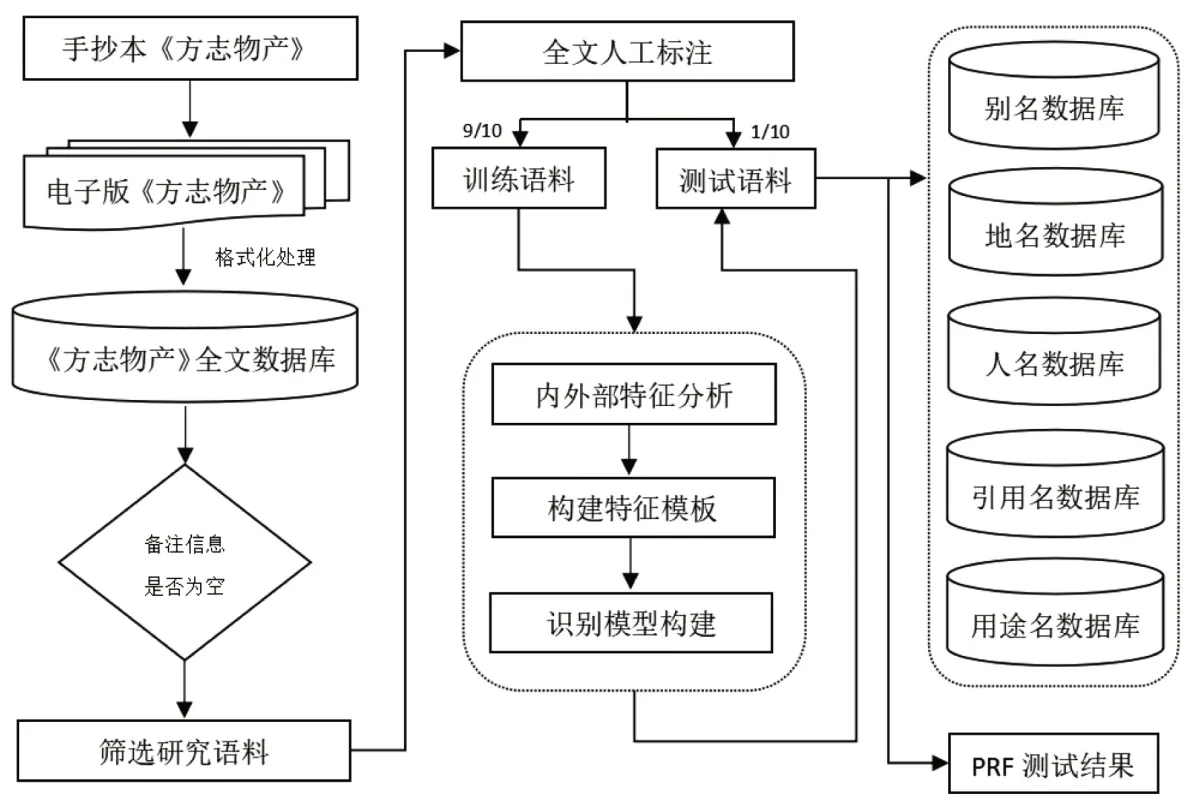
图1 研究的技术路线
2.1 语料筛选和标注
(1)语料筛选。首先,根据物产名称进行语料筛选。在流传过程中,由于文字变迁、抄写错误、字迹不清等,《方志物产》记载的物产名称不尽完备。《方志物产》山西分卷中共记载51,545条物产信息,部分物产的名称中除可识别的汉字外,还包括特殊符号,如 “+、□、(、?)”“鸂□、鷰(鳥衣)、(艹+旹)蘿、??”,代表该处为“缺字” 或“造字” 等情况。物产名称不完整的数据共273条,约占总语料规模0.53%。为保证数据的原始性和完整性,况且物产名称不完整并不影响命名实体识别,所以仍保留相关语料,尝试通过数据对比和关联等方式完善这部分物产名称的数据。其次,就文本结构而言,方志类文献中物产记载方式不一,物产备注信息存在缺失现象。图2所示是从《方志物产》山西分卷全文数据库中随机选取的10条物产信息,可见备注信息空缺的现象。本研究的目的是从物产的解释信息中抽取别名、地名、人名、引用名和用途名等5类实体信息,因此,语料库中没有解释信息的物产记录不是本研究的有效语料。《方志物产》 山西分卷记载的51,545条物产信息中,含解释信息的共9,085条,约占总物产量17.63%。
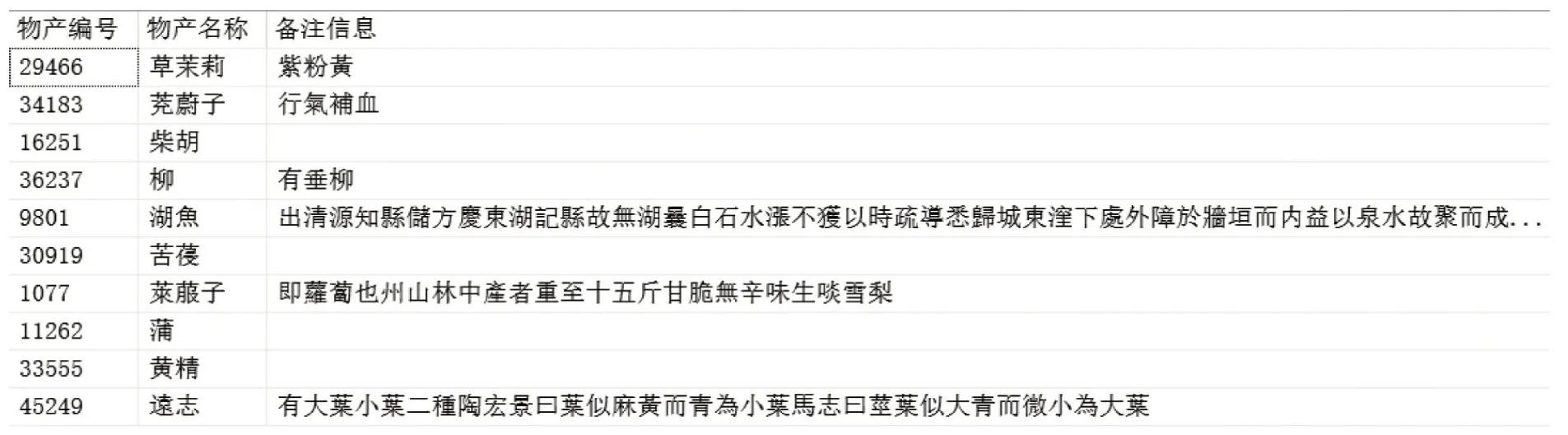
图2 随机选取的10条物产名称及其备注信息样例
(2)语料标注。为提升机器学习效果,对部分语料进行人工标注。在对物产的备注信息进行标注时,用英文单词表示对应的命名实体类别,标注时选用大写首字母表示,以“【”“】” 表示命名实体的左右边界,具体见表1。标注完成后,9,085条备注信息不为空的物产信息中含别名的有2,522条,含地名的1,308条,含人名的624条,含引用名的1,307条,含用途名的823条,共计6,584条,这是本文进行命名实体识别研究的最终语料。

表1 命名实体标注说明
2.2 标注集生成
在人工标注语料的基础上,对训练语料进行一定的标记,用于抽取语料特征。通过计算标注实体的加权长度,明确标注集的长度,生成标注集运用式,如下:

其中,Li表示i≤k当时,命名实体平均加权词长,Ni表示语料库中词长为i的命名实体出现次数,k和i为语料库中命名实体的最大词长和最小词长,N为语料库中命名实体出现次数总和。例如,L2就表示在k=2时,整个语料库的中命名实体的平均加权词长。通过反复计算和实验测试,本研究确定在《方志物产》的命名实体自动抽取中,使用4 词位的标注集,即P={B,M,E,S}。其中,B表示命名实体的起始词,M表示命名实体的中间词,E表示命名实体的结束词,S表示非命名实体词的标记。经过手工标记的语句,如 “旨鹝草 州境出草如綬亦名【A 文章草】”“蝙蝠 其矢名夜明砂【F治目翳障症】”“蟾酥 出【L 代州】【L 太原】【L 定襄】【L 五臺】【L崞縣】”“太谷蒲桃 見【P高青邱】 詩集今不可得”“虎【C 格物論】 云虎山獸之長”等,标注集的生成结果(样例)如表2所示。通过生成标注集,将训练语料处理成一串具有特定标识符的单字,为精确定位命名实体的左右边界词及分析边界词特征提供便利。命名实体的左右边界词是特征模板的重要内容,其分布特征影响实体抽取模型的功能优化和识别效果。
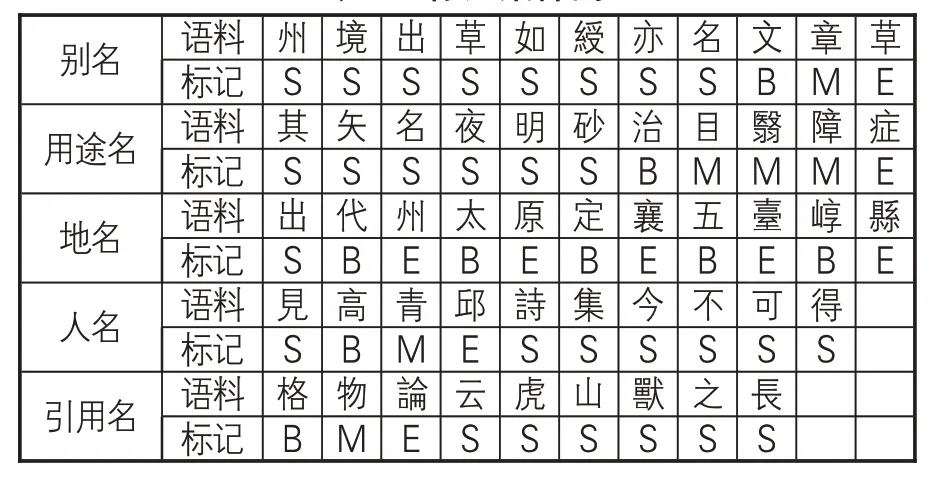
表2 标注集样例
2.3 内外部特征分析
基于人工标注语料和实体标注集,统计总结命名实体的内外部结构特征,作为核心要素应用到模型构建中。其中,内部特征是指命名实体的词长及其频次分布规律,外部特征是指命名实体的左右一元边界词及其频次分布规律。
(1)内部特征分析。命名实体的词长是指构成命名实体的字数。根据词长的统计分析结果,可以协助确定及识别序列的跨度。标注语料中共提取出人工标注的别名3,458个、地名2,287个、人名846 个、引用名1,944 个、用途名1,191个。从长度和频次统计结果看,5种类型命名实体的长度特征如表3所示。从表3可见,除了引用名稍长以外,别名、地名、人名、用途名的长度均集中在1、2、3上,高频长度能够涵盖绝大多数命名实体。词长的统计分析结果有助于提高模型对实体长度判断的准确性。
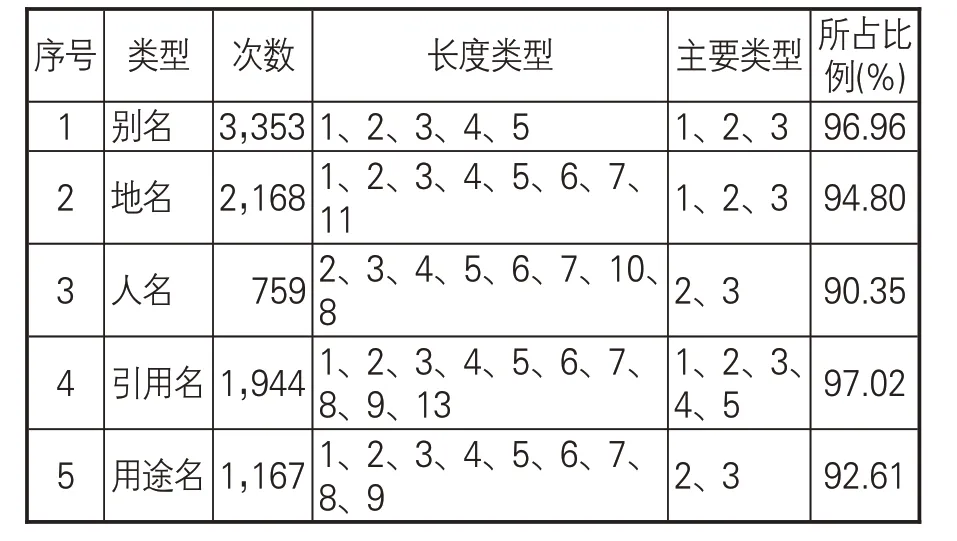
表3 命名实体长度特征统计表
(2)外部特征分析。根据已有标注集,对命名实体的左右一元边界词进行统计分析。假设把一条语料表示成 “SLn,…,SLi,…SL1,【R,R1,…,Rn】,SR1,…,SRj,…,SRn”,其中,【R,R1,…,Rn】 代表标注集,SLi代表标注集的左边界词,SLj代表标注集的右边界词,即可以判定标注集的左右一元边界词,即SL1和SR1,其分布状况运用式如下:

其中,pc(ω)为ω在语料中作为一元边界词的频率,fβ(ω)为ω作为一元边界词出现的次数,∑ωfβ(ω)为在语料中出现的总次数。表4所示为各类命名实体的高频左右一元边界词,括号中为该边界词出现的频率。可见,别名、用途名的左一元边界词聚集程度较高,最高频次均达到70%以上;地名的左右一元边界词都相对集中,最高频次均超过70%;人名和引用名的右一元边界词较左一元边界词更为集中,最高频次为100%。
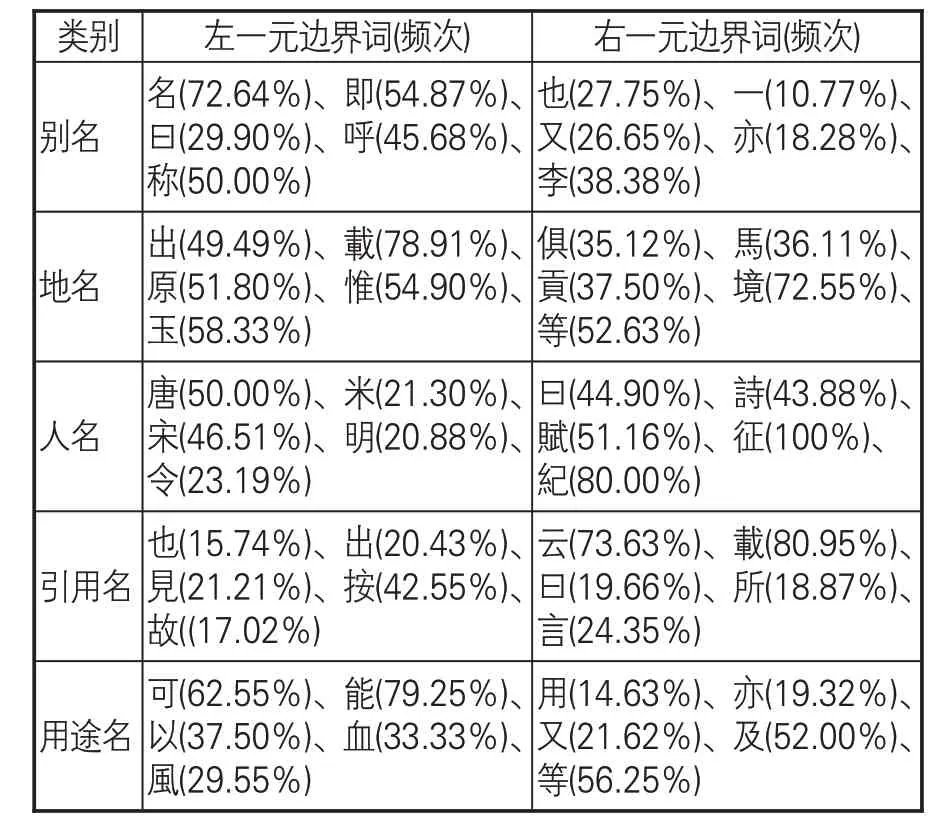
表4 高频左、右一元边界词
2.4 特征模板构建
条件随机场[35](Conditional Random Fields,CRF)是判别式概率模型,常用于标注或分析序列资料,自然语言是其分析对象之一。设图G=(V,E)是一个无向图,Y为已标注序列,Y={Yv|v∈V},X为待标注序列,令X={x1,x2,…,xn},Y={y1,y2,…,yn},如果Yv服从马尔科夫属性,则(X,Y)构成一个条件随机场,满足p(Yv|X,Yu,u≠v,v,{u,v}∈V)=p(Yv|X,Yu,u~v,{u,v}∈E),u~v表示u是v相邻的节点。为最大限度地提升模型的识别性能,在基于CRF构建识别模型时,应充分考虑标注语料中上下文结构特征。本模型构建中综合融入了训练语料命名实体的内部和外部特征,即上文所分析的实体长度、出现频次、左右边界词等。
(1)实体长度。《方志物产》语料中,最常见的别名长度为2,如 “虞美人 俗稱【A 芙蓉】 ”;最常见的地名长度为2,如 “萆麻子【L平魯】【L朔州】【L馬邑】 有”;最常见的人名长度为3,如“玉簪【P漢武帝】 寵【P李夫人】取玉簪搔頭後宮人皆效之玉簪花之名始此明【P徐文長】 詩曰小院秋深墜碧茵花間猶見李夫人搔頭可綴誰能綴一夜西風夢裏神”;最常见的引用名长度为2,如“艾【C爾雅】 曰水臺王安石【C字說】 曰艾可乂疾久而彌善故字從乂師曠曰歲欲病病草先生艾也”;最常见的用途名长度为2,如“蜂密 一名石蜜以白如膏者良【F潤燥】【F滑腸】【F補中】【F清熱】”。实体长度用阿拉伯数字表示,是识别模型的一个重要特征。
(2)一元边界词。命名实体抽取过程中,左右一元边界词是识别模型的重要参数。一旦确定了实体的左右一元边界词,就锁定了实体的具体位置,从而抽取出目标实体。在利用训练语料进行模型构建时,根据人工标注实体的位置标出左右一元边界词,用L代表左一元边界词,用R代表右一元边界词,用N代表非一元边界词。语料训练结果样例见表5。

表5 五类命名实体的左右一元边界词标注样例
3 模型测试与结果分析
3.1 模型测试
本研究采用正确率P、召回率R和调和平均数F[36]对基于CRF的命名实体识别模型的识别效果进行综合评价,用以衡量其在方志类古籍文献整理中的适用性和应用前景。

其中,correct是模型识别结果中正确的命名实体数量,incorrect是模型识别结果中错误的命名实体数量,unrecognized是人工标注出来但模型没能识别的命名实体数量。
为合理优化和提升模型识别效果,本研究使用十次交叉法验证不同训练语料和测试语料下的模型性能。首先,将所有语料随机乱序排列,并平均分成10等份;其次,每次验证选取10份中的任意9份作为训练语料,用于构建命名实体自动抽取模型,将剩余的1份语料作为测试语料,评估模型的性能,共进行10次评估实验,从而获得最优模型。五类命名实体测试的最优结果如图3所示。从最优模型识别结果看,面向《方志物产》 命名实体自动抽取模型的识别效果中,效率最高的是正确率,其次是调和平均数,而召回率相对较低。即,模型识别出的实体中正确的比例较高,但是占全部应识别出的实体比例稍低。五类命名实体中,别名、地名、引用名的效果较好, 最高正确率均达到了95.48%,人名和用途名的识别效果稍差,正确率为70%~80%。

图3 最优模型的测试结果
3.2 对比分析
近期有学者运用Bi-RNN、Bi-LSTM、Bi-LSTM-CRF、BERT等深度学习模型对《方志物产》云南分卷语料中的别名、人名、地名、引用名进行了一体化识别[31]。其中,Bi-RNN是一种双向循环神经网络模型,加入了时间序列的变化,分别从起点和末尾两端对文本序列进行学习,获取句子中词之间的语义关系;Bi-LSTM为双向长短时记忆模型,引入遗忘门、输入门和输出门,更加全面地捕获文本序列信息,解决语料长距离依赖问题;Bi-LSTM-CRF 模型将双向长短时记忆模型与CRF模型相结合,既考虑到文本前后序列的关联性,又解决标记偏置的问题,是较为主流的方法;BERT模型摒弃了RNN循环式神经网络结构,通过自注意力机制进行建模,采用双向语言模型提取上下文语义关系,有效解决长期依赖问题,在自然语言处理领域具有突破性表现。本文将基于条件随机场模型与基于Bi- RNN、 Bi- LSTM、 Bi-LSTM-CRF、BERT 等深度学习模型识别效果中的F1 值进行比较,结果见表6。基于条件随机场的模型对别名和地名两类实体的识别效果较显著,而深度学习在人名识别方面的效果优于条件随机场模型,二者在引用名的识别效果上基本持平。另外,本研究将命名实体技术首先应用于《方志物产》 中用途名的实体识别,尚未有其他模型的对比数据。

表6 CRF与深度学习模型识别效果F1值比较(单位:%)
3.3 结果分析
分析基于CRF的命名实体识别模型正确率分布,以及对比人工标注与机器识别结果可发现:
(1)识别效果最好的实体类型依次是地名、别名、引用名。这是因为在《方志物产》的编纂过程中,地名、别名和引用名的表述较为规范,且聚集程度高,无伭是在时间线上还是在空间域上,这三类实体重复出现的几率大,词长和边界词等文本特征相对明显,在一定程度上提升了模型的识别性能。这三类实体识别错误的情况主要集中在以下几个方面。就地名而言,一种情况是实体不是一个具体的地名,而是一个范围或者指代性的名词,导致机器无法根据特征进行精确判别,如语料 “訓峪後溝等十數村” 不是一个确切的常规地名,导致机器识别的结果表现为实体字段识别不全;另一种情况是实体并列出现,如语料 “太原平陽潞安三府及汾澤二州俱出” 中 “汾澤” 二州就因为并列出现而被漏识别。就别名而言,主要存在实体类型判断错误情况,即模型实体抽取是正确的,但是由于多类型命名实体的混合以及语言表达规则的相似性,导致在实体类型划分时出现了错误,如 “赭石” 的语料 “生河東山中別錄曰出代郡者名代赭李時珍曰赭赤色也代即雁門也俗呼土朱鐵”,识别结果为“代赭、雁門、土朱鐵”,显而易见,“雁門” 并非物产“赭石” 的别名,而是地点“代” 表示的地名,只是因为二者的语言规则相似而被误判。就引用名而言,主要原因是实体嵌套导致的实体名称过长,如语料“細莖叢生花豓藍色既開如墜花落結子他邑所無附宋司馬光晉陽三月未有春色詩天心均煦嫗物態異芬芳上國花應爛邊城柳未黄清明空改火元已漫浮觞仍説秋寒早年年八月霜” 中“宋司馬光晉陽三月未有春色詩”,就存在时间、人名、地名、引用名的连续嵌套,导致机器判别出错。
(2)人名和用途名的识别效果存在着较大的提升空间。其中,人名识别方面,古人除了本名以外,还有字、号、官职、尊称、谥号等多种别名,实体的长短、出现的频率等缺乏规律性,机器判别难度大;此外,不同类型的实体嵌套或者混淆的情况较为常见,如“河南王孝瑜” 为地名与人名的嵌套、“白香山” 为地名与人名的混淆、“魏武衛將軍奚康生” 为官职名与人名混淆,“唐段成式” 为朝代名与人名混淆等。而用途名的识别方面,主要立足传统中草药的功效角度进行描述,表达方式多样,不同时代、不同地区或不同志书对同一物产同一功效的描述也不尽相同,且数种功效经常并列出现,如物产 “青蒿” 的语料“處處生之春夏採莖葉同童便煎退骨蒸劳熱生搗絞汁却心疼熱秋黃冬採根實實須炒治風疹疥瘙虗煩盜汗開胃明目辟邪殺虫” 中就有“風疹、疥瘙、虗煩、盜汗、開胃、明目、辟邪、殺虫” 等多种用途名称的并列使用,成为机器识别精度提升的阻碍。
本文总结的问题与经验,可以为方志类古籍大规模语料标注和实体识别研究提供借鉴。其中,增强领域专家的介入程度和提高标注人员的语言素养,有助于提升训练语料人工标注的精度;适当扩大训练语料的规模,有利于更全面地收集异质性较强的实体类型的特征信息;积极借助现有的数据集和标注标准,有益于排除标注过程中出现的分歧问题,从而提升实体识别模型的总体效果。
3.4 基于实体识别结果的应用
以“菠薐” 和“貫衆” 两条物产的解释信息“一名波斯菜詢芻錄云南人呼菠菜北人呼赤根菜劉禹錫嘉話錄本自頗陵國流入中國語訛耳能觧酒毒” 和“出遼州一名鳳尾草李時珍曰葉莖如鳳尾一本而眾枝貫之故草名鳳尾根名貫眾廣雅謂之貫節” 为例,CRF模型对别名、地名、人名、引用名、用途名的识别结果分别为 “‘波斯菜、菠菜、赤根菜’、‘劉禹錫’、‘詢芻錄、嘉話錄’、‘觧酒毒’” 和 “‘鳳尾草、貫節’、‘遼州’、‘李時珍’、‘廣雅’”。根据物产名与命名实体识别的人名、地名、别名、引用名、用途名五类命名实体之间的对应关系,以及物产名所属的记载时间和地区、物产分类信息等要素,建立起关联关系(如表7所示),并以此为基础,开展数据挖掘和知识发现研究。

表7 关联数据识别结果样例
通过物产与别名的关联关系,可以挖掘指定物产的别名信息,还可以发现哪些物产拥有相同的别名,为分析别名的来源提供了资料支撑;通过物产与人名的关联关系,可以挖掘物产在传播的过程中,受到哪些历史人物的影响,是在哪些方面产生了影响,如命名方面、文学方面、种植技术方面等;通过物产与时空的关联关系,不仅可以挖掘物产横向地域上的变迁,还可以挖掘物产在纵向时间上的消长,将物产与社会变迁、生态环境等紧密联系起来;通过物产与引用名之间的关系,可以了解具体物产在哪些古籍文献或诗词歌赋或民间谚语中记载或流传,为资料查找提供重要线索;通过物产与用途之间的关联关系,可以挖掘物产在生活、民俗、药用等方面的价值,为进一步深度利用打下了基础。例如,图4为依据物产与人名之间关联关系而生成的知识图谱,可以根据不同的需求开展不同纬度、不同角度的深度剖析;图5是来源志书在时空范围的分布图,呈现了不同朝代山西境内不同地区的志书修撰情况,这从侧面反应了物产记载的详略程度;图6是物产与时空之间关联关系的分布图,展示了棉花在山西引种和传播的进程。
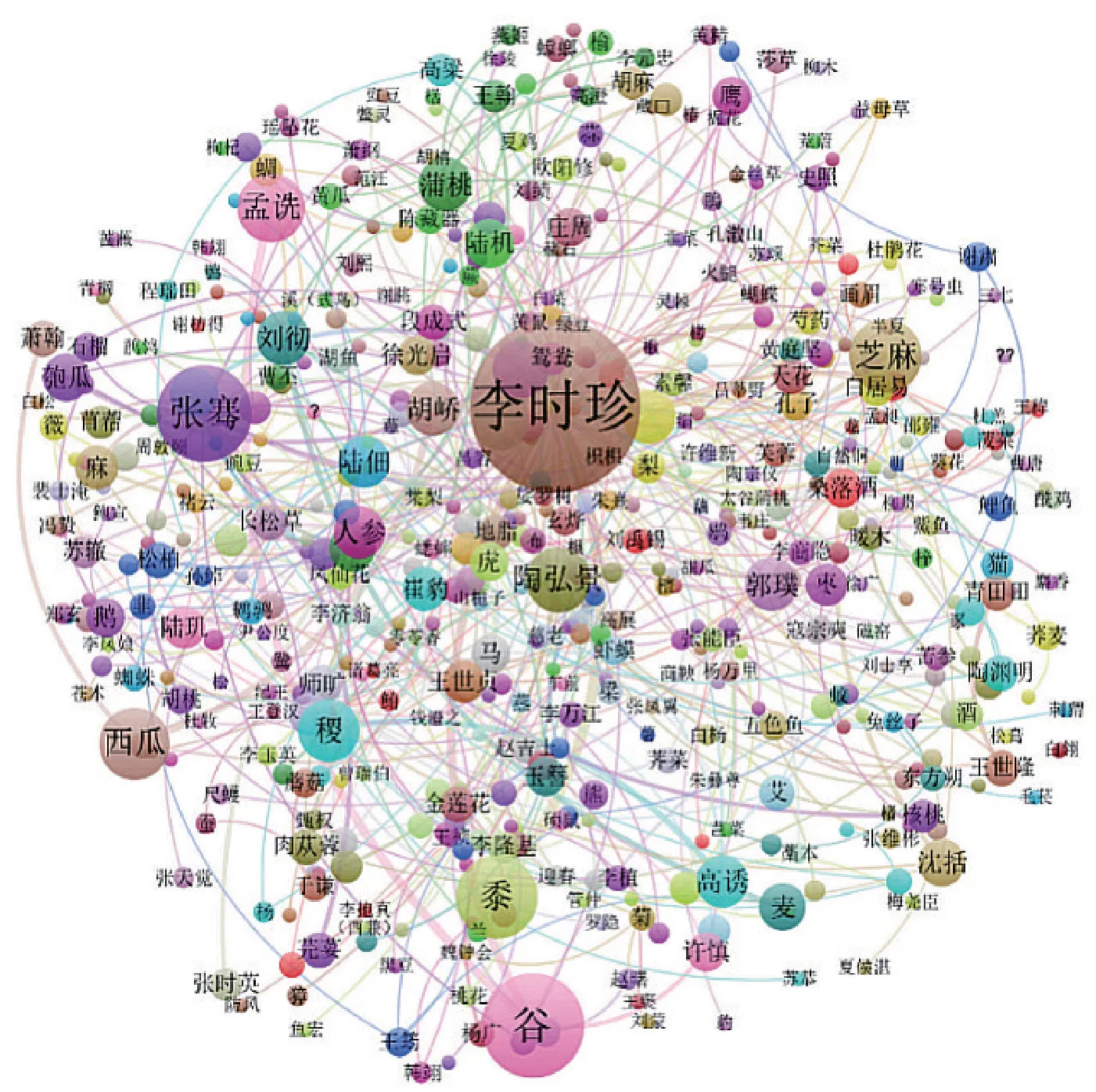
图4 物产与人名之间的关联关系可视化图
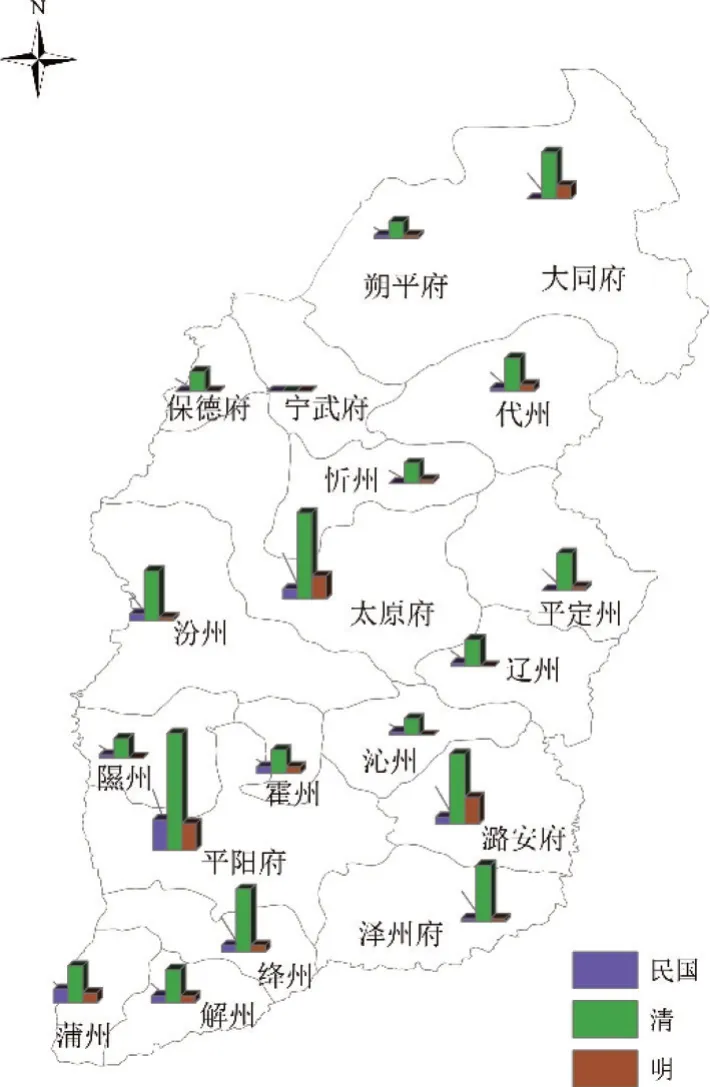
图5 志书的空间分布图

图6 物产“棉” 的时空传播分布图
4 结语
本文以《方志物产》山西分卷为研究语料,基于条件随机场构建多类型命名实体复杂识别模型,实现了文本中别名、地名、人名、引用名和用途名五类命名实体的自动抽取,并应用十次交叉法对模型识别性能进行测评,取得了较好的实验结果。本研究验证了在方志类古籍的知识挖掘中,条件随机场模型能发挥较好的效果,具有较高的可行性和较好的应用前景,为大规模方志古籍以及其他类古籍的挖掘利用研究提供借鉴。
但是,本研究仍然存在有待进一步提升的空间:语料规模小,仅以山西一省物产资料为研究对象,占全国语料1%左右,规模偏小;标注精度低,人工标注者的农史底蕴薄弱,导致人工标注不够完善;模型特征少,模型构建中仅采纳了长度、频率、左右一元边界词作为特征,没有全面覆盖所有特征信息。
在未来研究中,需要逐步扩大语料规模,从一个省份扩展到多个省份,直至全国;引入农史专业学者对语料进行深度标注、提升标注程度,构建标注标准体系,以便在更大范围内推广;获取更多语料特征,丰富特征模板,完善识别模型的功能,提升识别效果。
