基于EMD-ICA与遗传算法的轴承故障诊断方法
2021-12-15谢中敏沈宝国
谢中敏,沈宝国,胡 超
(江苏航空职业技术学院航空工程学院,江苏镇江 212134)
0 引言
轴承作为旋转机械的核心部件,其故障信息经常被反映在振动信号中。但受制备材料、工作环境等影响,致使轴承寿命离散度较大,且其振动信号常受到其他部件的影响,导致对轴承故障状态识别的难度较大[1]。
轴承故障振动信号是典型的非平稳信号,部分振动信号处理方法难以描述非平稳信号的局部信号特征,但经验模态分解法(Empirical Mode Decomposi‐tion,EMD)能够将振动信号分解为若干个本征模态(Intrinsic Mode Function,IMF)分量[2-3],从而凸显出信号的局部特征。且针对单通道混叠信号的另一种处理方式是利用独立分量(Independent Component Analysis,ICA)有效地分离振动信号中的故障特征信息,剔除噪声信号的干扰,从而进行频谱分析[4]。王志等[3]对轴承振动信号进行EMD 分解,将IMF 作为故障特征样本,采用融合和算法对滚动轴承故障样本进行诊断并取得较好的诊断结果;张健等[5]同样采用EMD 对滚动轴承振动信号进行分解并采用变量预测模型对轴承故障进行诊断。但EMD 分解会产生欠包络、端点效应等问题[6],而使用ICA需要构建有效的信号输入矩阵。
由于振动信号分析带来的诸多因素,许多学者对振动信号进行处理后,基于部分神经网络具备的模糊诊断性能实现轴承故障特征识别。皮骏等[7-8]基于轴承振动信号时域特征参数,结合遗传算法[7]、量子遗传算法[8]、极限学习机[7-8]等对轴承故障进行诊断并取得较好的结果;陈超宇等[9]利用全矢深度学习网络对轴承故障样本进行诊断;殷锴等[10]将BP 神经网络用于故障诊断;马圣[11]基于试验室轴承故障信号,利用经验模态分解法对轴承故障振动信号进行处理,并结合优化算法优化的极限学习机实现轴承故障诊断;郑蒙福等[12]基于滚动轴承信号的集总经验模态分解的能量特征,结合单纯进化算法优化的支持向量机实现轴承故障诊断。但不少学者直接对采集的振动信号进行时域特征处理[6],导致得到的特征信息中也存在干扰信息。为了避免由于振动信息掺杂带来的干扰,本文采用EMD 对振动信号进行分解,利用能量贡献度筛选IMF 分量进行信号重构,通过ICA 实现振动信号的分离;对处理后的信号进行特征参量提取,考虑到提取特征参量之间的耦合性、高维性,采用遗传算法进行最优特征选择,并用遗传算法优化的极限学习机实现轴承故障诊断。
1 振动信号降噪方法
轴承通常被包裹在旋转机械的内部,通过振动加速度采集到的振动信号较弱,且包含各种复杂的机械噪声信号与部分由试验设备等造成的干扰信号。对此,采用最小二乘法拟合法消除由于采集系统或者振动信号本身原因所导致的信号漂移现象。
采集到的振动信号中通常包含着多种微弱振动信号,极有可能淹没由轴承故障引起的高频冲击信号。EMD 是一种非常适用于处理非平稳信号的时频处理方法[2],其主要思想是将振动信号x(t)进行分解,直到不满足前提假设条件时为止,分解得到的一系列独立分量从不同角度反映着振动信号。
振动信号x(t)极有可能由不同振动源组合叠加而成,因此在处理振动信号时如果能够准确识别振源,对于故障识别颇受裨益。快速ICA 能够从复杂混叠信号中提取相互独立的信号源[2]。
基于上述分析,本文在对振动信号进行后续处理时,采用“最小二乘法+EMD+ICA”的模式对采集到的振动信号进行降噪处理,剔除信号x(t)中的干扰项,其降噪流程如图1所示。
降噪方法的基本步骤如下:
(1)对轴承振动信号x(t)进行最小二乘法趋势消除分析,并对振动信号数据进行指数平滑法处理;
(2)对步骤(1)处理得到的振动信号进行EMD 分解,得到1组不同尺度的IMF分量;
(3)计算IMF分量的信息熵增益比,计算方法如下:
a.对IMF分量进行归一化处理

式中:λi'为处理后的IMF 分量;λi为IMF 分量降序排列后的第i个分量;d为IMF分量的数量。
b.计算第i个分量的熵值pi
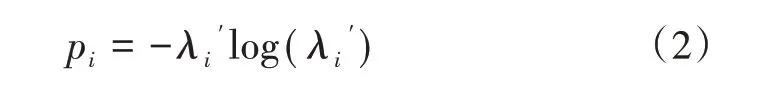
c.计算第i个分量熵值pi的增益比gi
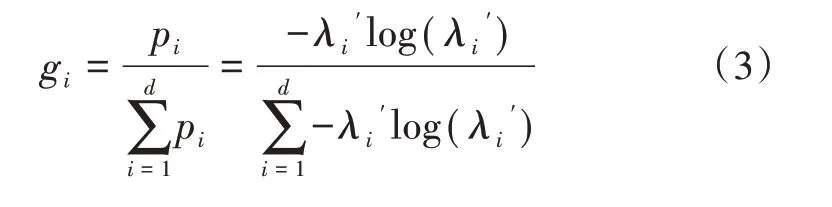
(4)对筛选信息增益比大于0.1 的前几个分量进行重构得到信号x(t)';
(5)将x(t)与x(t)’作为ICA 的输入矩阵,令其均值0 进行去中心化和白化处理,随机选择初始权值wp;
(6)通过一系列迭代计算,当wp收敛时可得到分离矩阵和分离信号。
2 滚动轴承振动数据来源与处理
2.1 滚动轴承数据来源
文中所采用的滚动轴承故障振动数据源自美国西储大学的轴承数据中心[13]。轴承故障模拟试验台如图2 所示。试验台主要包括:1500 W 的电机、扭矩频编码器、功率计、加速度传感器、控制电子装置等(图中未给出);轴承类型为6205-2RS-JEM-SKF,其基本尺寸参数见表1。在试验中,电机转动频率为1730 r/min,采用频率为48 kHz。采用整周期采样,获取到内环故障、外环故障以及滚动体故障的振动信号,其中某个整周期的时域振动信号如图3所示。

图2 轴承振动分析试验台和采集装置

表1 6205-2RS-JEM-SKF型轴承参数
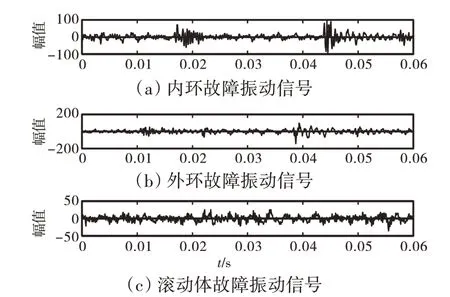
图3 滚动轴承振动信号的时域波形
2.2 滚动轴承振动信号的降噪处理
采用第1 章中提到的方法对滚动轴承振动信号进行降噪处理,内环故障的振动信号经过最小二乘法和指数平滑法处理后的效果如图4 所示。从图中可见,轴承振动信号的采集确实存在一定的微弱漂移现象;并且经过平滑处理后,振动信号的趋势变化更为直观可见。
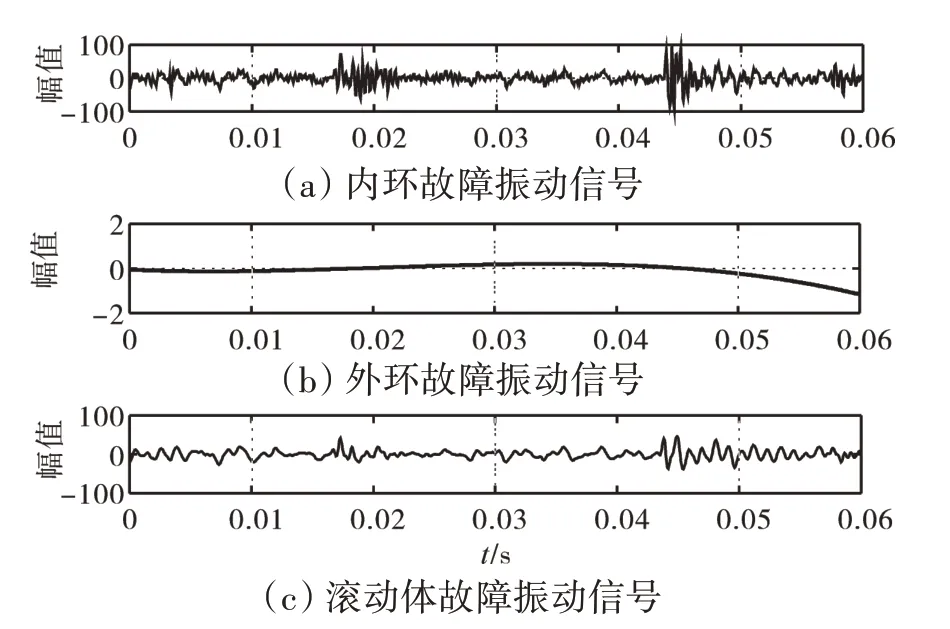
图4 最小二乘法消除趋势项
对振动信号进行EMD 分解,外环故障振动信号的EMD 分解如图5 所示;计算内、外环故障以及滚动体故障振动信号的IMF 分量的信息熵增益比,如图6所示。从图中可见,不同故障类型的振动信号被分解成的IMF 分量数量不一,且其所包含的信息量不同,选择信息增益比大于0.1 的IMF 分量实现信号重构,得到x(t)'。将x(t)与x(t)'作为ICA 的输入矩阵,对振动信号进行分解,轴承内环故障信号分解如图7所示。
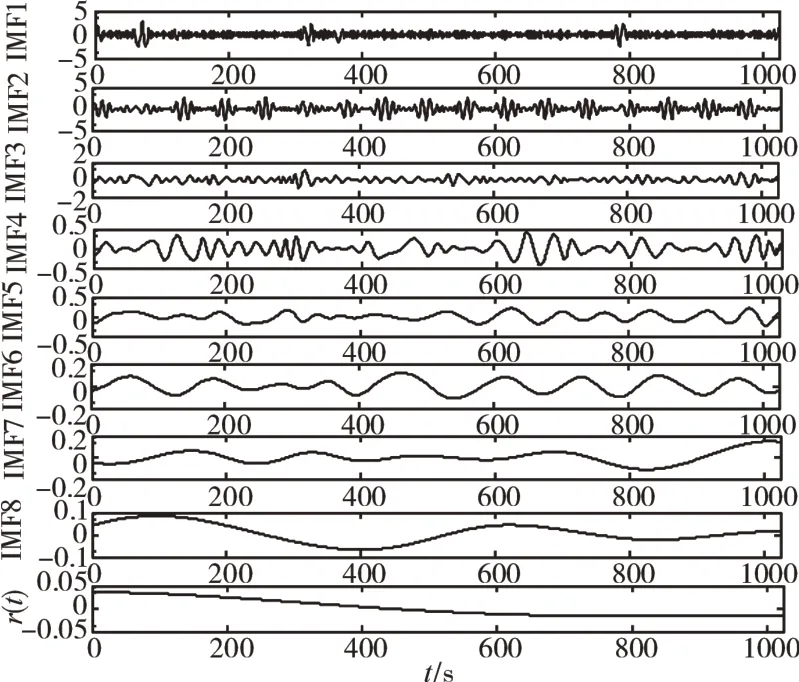
图5 外环故障信号的EMD分解
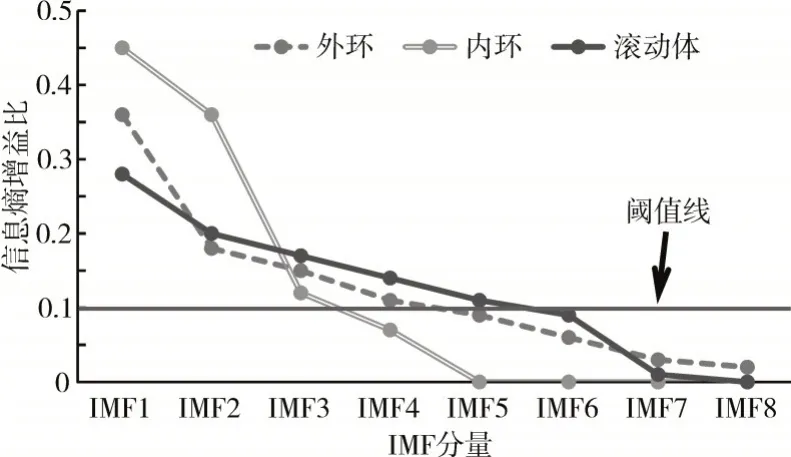
图6 IMF分量的信息熵增益比
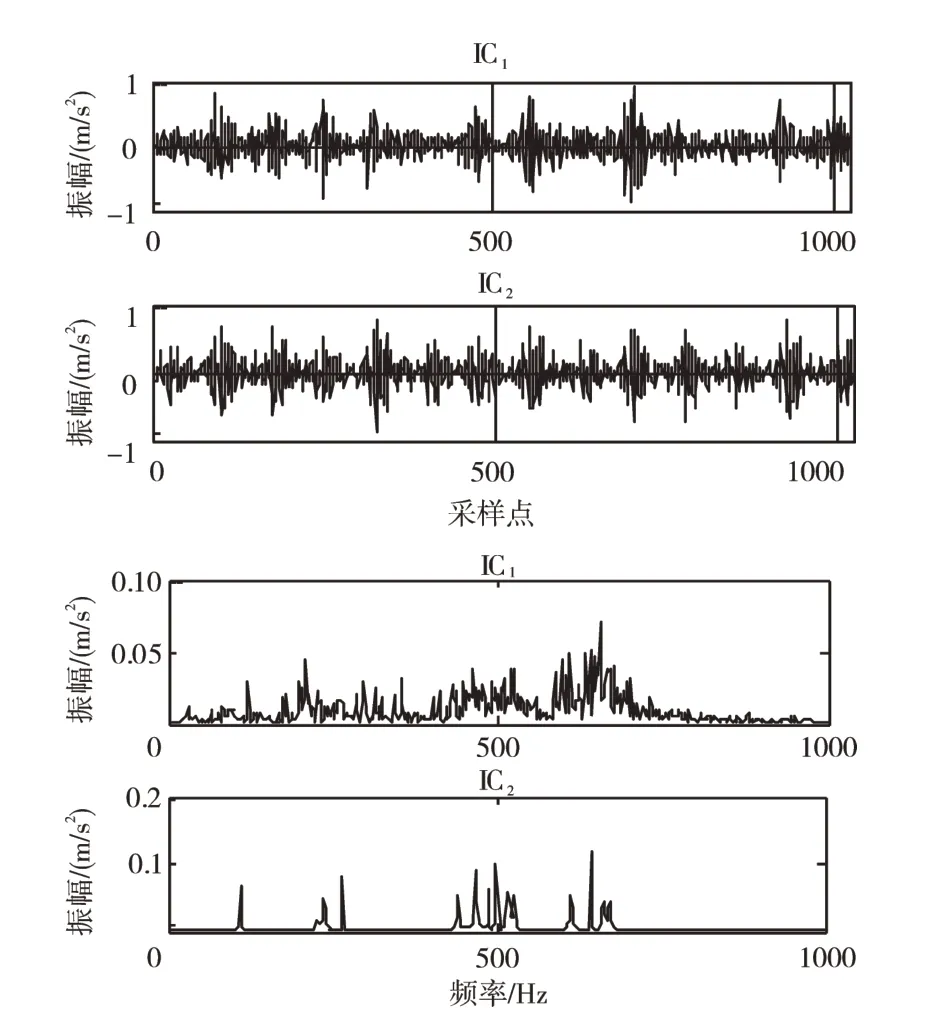
图7 轴承内环故障
从图中可见,IC2分量相比于IC1分量冲击特性更加明显,且其频域变换后IC2的特征频谱相比更易突出。因此,后续特征参量提取基于ICA 分离后得到的IC2分量。
但通过频谱对故障特征进行识别,尤其是针对轴承而言,需要先根据待检测物体尺寸计算故障特征频率,随后从频谱中寻找是否存在相关故障特征频率的倍频存在,从而判断故障。在识别过程中为降低人工干预,采用遗传算法优化的极限学习机对轴承健康状态进行诊断。
2.3 特征参数的提取
在时域分析中,通常使用能够反映振动信号在时域上的幅值和能量的指标[2,7]:平均值、绝对平均值、峰峰值、均方根值;能够反映振动信号在时域上分布的指标:标准差、偏度、峭度、脉冲因子、波形因子、波峰因子、变异系数、方差。这些指标的部分值见表2。
工程项目质量,由于其影响因素多,波动大、变异大、隐蔽性以及终检局限大等特点,造成工程项目质量管理中往往会不可避免地出现一些问题,工程项目质量管理不是一个单一的短期的过程,而应该是一个长期的系统的过程。施工项目质量控制的系统过程主要分为事前质量控制,事中质量控制和事后质量控制。
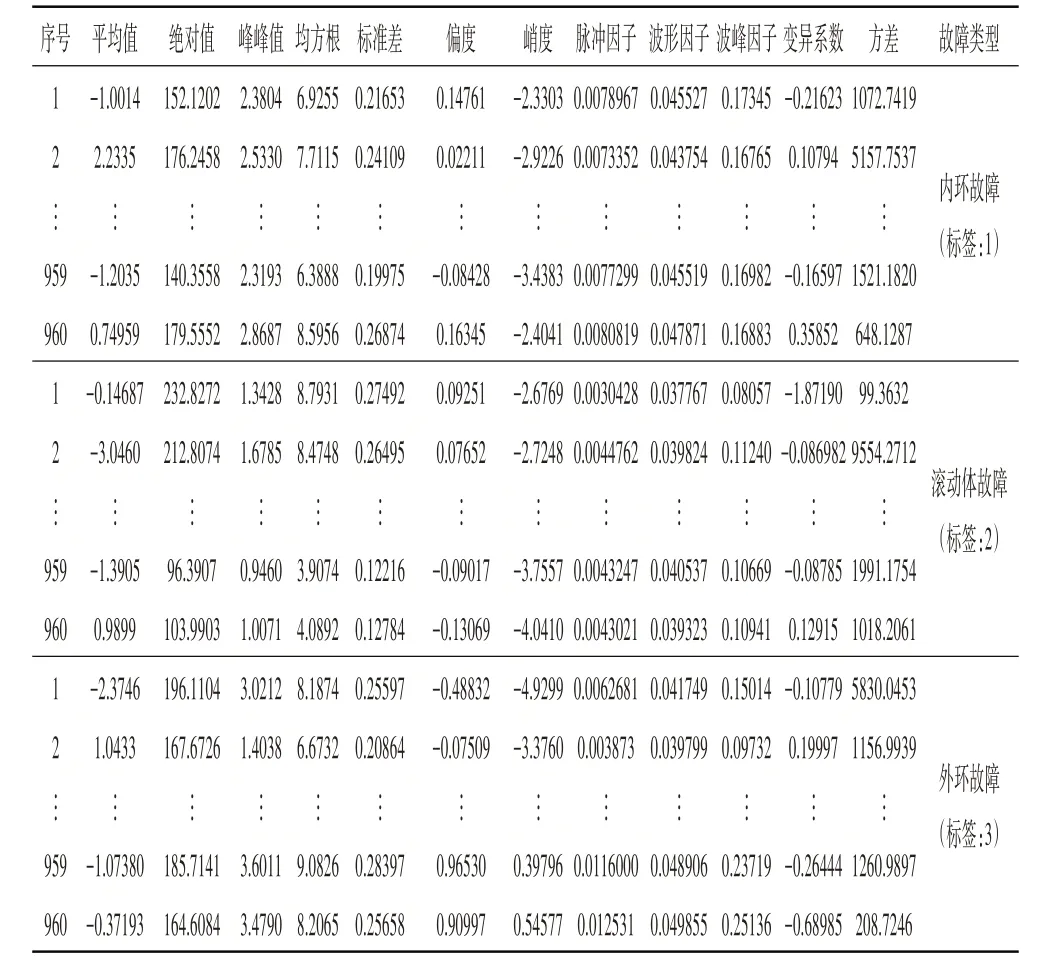
表2 时域特征参量
3 遗传算法优化的极限学习机诊断模型
3.1 最优特征参数的筛选
考虑到时域特征中部分特征之间的耦合性和特征指标数量的高维性,如果直接进行故障诊断不仅造成诊断时间延长,同时还会造成诊断效果较差。因此,利用遗传算法对输入变量进行降维操作。
利用遗传算法对自变量降维时,需要将解空间映射到编码空间中,而每个编码则表示一种解。在变量筛选过程中,变量要么被选中要么被舍弃,选中的变量对应的基因值赋值为“1”,否则赋值为“0”。采用遗传算法在降维过程中,通过计算检验集样本的误差值判断变量的舍弃,如果变量的加入使得误差值减小,则选择,否则舍弃。
由于每类故障有960 组样本集,3 类轴承故障共计2880 组数据,随机选择2000 组数据集作为训练样本集,另随机不重复选择300 组数据集作为校验集数据,剩下的580 组数据作为测试集样本数据。由于神经网络随机初始值导致的不可复现问题,筛选变量时需在相同条件下重复试验100 次,记录每次试验的校验集误差值,求得的平均误差变化如图8 所示;选择出现频率大于50次的特征参量作为最优特征,在100次试验下各特征被选中的次数如图9 所示。因此,最优特征参数为:平均值、绝对值、峰峰值、均方根值、偏度、峭度、脉冲因子、波峰因子,其部分数值结果呈现见表3。
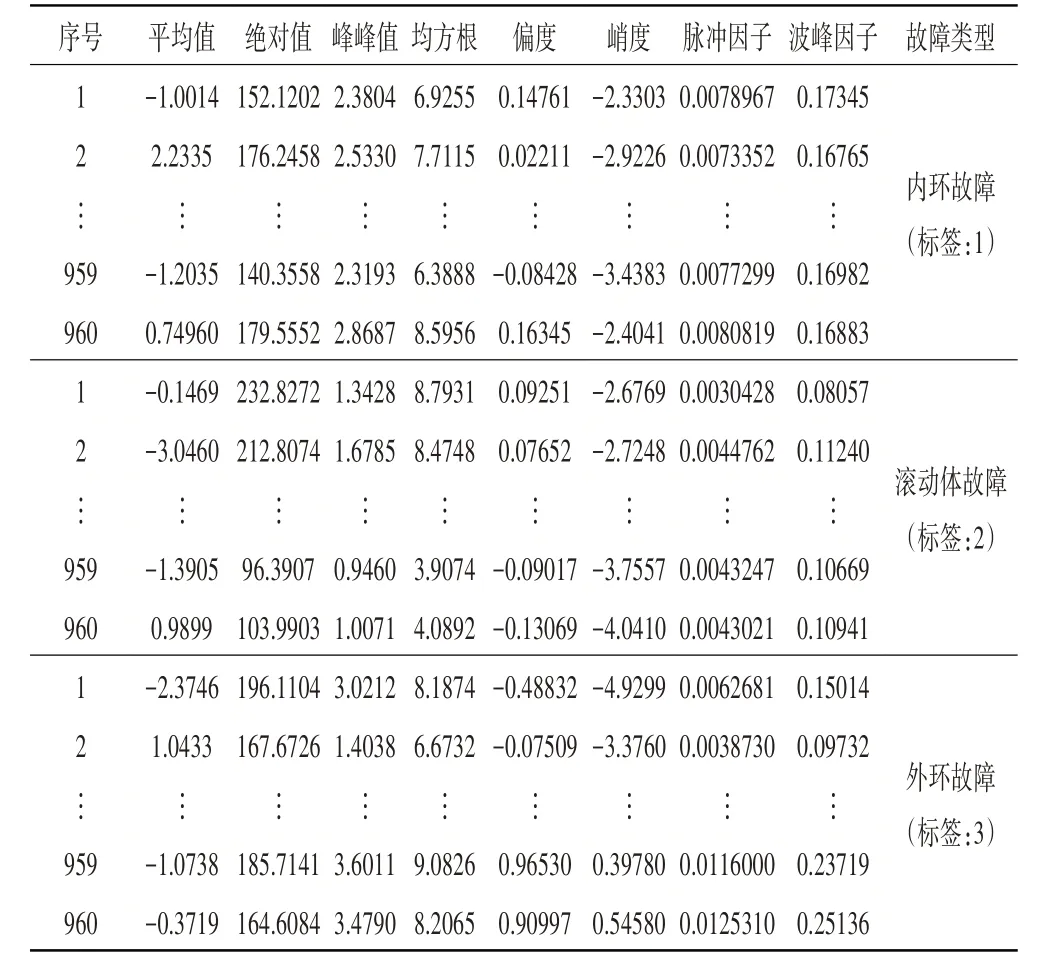
表3 最优的时域特征参量
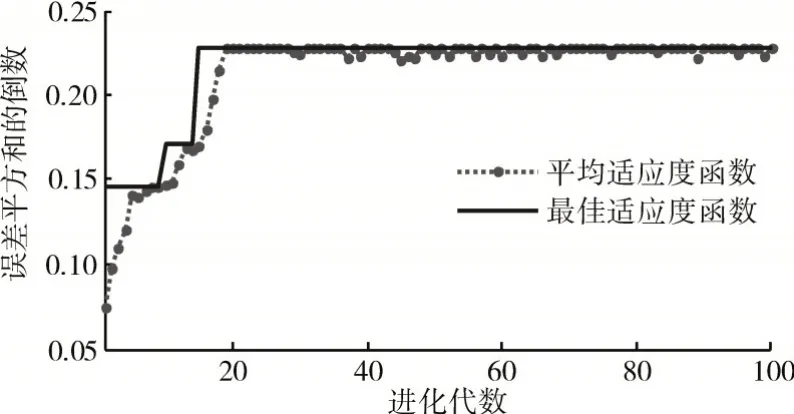
图8 自变量降维过程的适应度函数进化过程
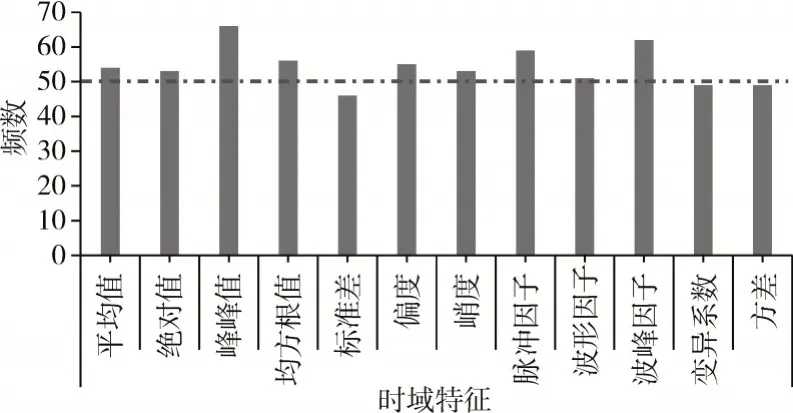
图9 100次试验下各变量被选中的频率
3.2 遗传算法优化的极限学习机
Huang 等[14]提出极限学习机(Extreme Learning Machine,ELM)算法,用于克服单隐层前馈神经网络训练速度慢、容易陷入局部极小点而难以达到全局最优等缺点。且ELM 算法随机产生输入层与隐含层连接权值和隐含层阈值,便能逼近任意非线性分段函数[15]。但极限学习机相比传统神经网络需要更多的隐含层神经元,且由于随机赋予输入权值和阈值,可能会导致病态问题出现[16]。针对这一问题,本文利用遗传算法优化ELM,并用于故障诊断中。
3.2.1 遗传算法
遗传算法是一种生物种群优化算法,其基本思想是通过对种群中的个体进行交叉、变异等操作实现最优种群的选择,其详细理论可参考文献[11]。遗传算法具有实用、高效、鲁棒性强的优点,但在求解非线性问题时容易出现早熟现象,从而使算法不能跳出局部极值。为避免这种情况的出现,文中采用自适应变异概率,即:对高于种群平均适应度的个体采用较低的变异概率,而对低于种群平均适应度的个体采用较高的变异概率。
3.2.2 遗传算法优化的极限学习机
诊断模型的基本步骤如下:
(1)根据提取的时域特征参数量,设置降维模型中遗传算法的参数并初始化种群;
(2)经过选择、交叉、变异操作,产生新的种群,并计算校验集样本的误差;
(3)根据误差选择特征变量,重复进化种群直至满足终止条件时输出最优特征变量;
(4)对最优特征参量数据集进行非重复划分,并设置优化模型中的遗传算法相关参数;
(5)经过选择、交叉、变异操作,产生新的种群,并计算种群适应度值;
(6)根据适应度值选择最优个体;
(7)重复步骤(5)并实时更新最优个体,直至满足终止条件为止;
(8)输出ELM 网络的最优参数值,并根据Moore-Penrose计算ELM输出矩阵。
文中涉及到遗传算法优化极限学习机诊断模型为一整体,是指诊断方法主要包括如下过程:信号的处理、特征提取、降维和诊断,其诊断过程如图10 所示,图中红色虚线表示误分类。
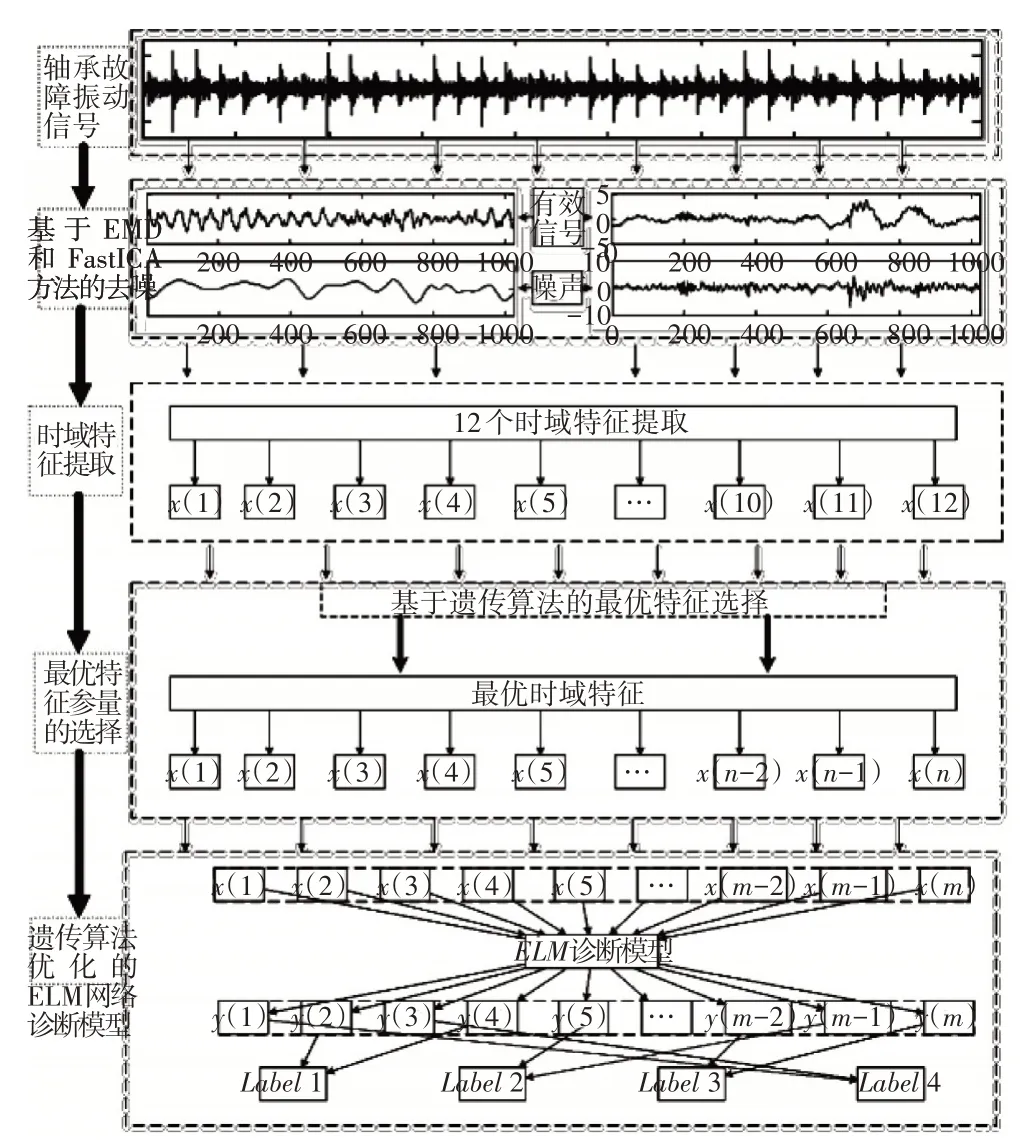
图10 EMD-FASTICA 与遗传算法降维的极限学习机诊断方法
4 故障诊断结果分析
为了验证文中提出的故障诊断方法,从是否去噪、是否降维并结合常见的BP神经网络、支持向量机出发,分析本文方法的可行性。
对算法中涉及的参数进行如下说明:遗传算法种群数量为30,最大进化代数为100,交叉概率为0.6,变异概率为0.05,初始基因值为[-0.5,0.5];极限学习机网络输入神经元数量等于输入变量维度,隐含层神经元数量为30,激活函数采用sigmoid(),输出神经元数量为3;BP 神经网络采用3-7-1 的网络结构;支持向量机随机初始化罚参数和核参数;在遗传算法优化的极限学习机中,从数据样本集中随机不重复地选择1660 组数据作为训练集数据、随机不重复地选择500组数据作为校验集数据,剩下的720 组数据作为测试集数据;在未优化的极限学习机中,随机不重复地选择2160组数据作为训练集数据、剩下720组数据作为测试集数据。
利用本文提出的方法及对比方法对轴承故障样本数据实施诊断,其诊断结果见表4。为了方便分析,对结果进行分类整理,如图11、12所示。
从表4 中可见,故障样本数据经过降噪、降维处理后的诊断效果与未降噪、未降维的效果存在差异,其规律很好地被展示在图11、12中。从图11中可见,振动信号经过降噪处理并对振动特征参数进行降维处理后,诊断效果均存在明显改善;从图12 中可见,振动信号经过降噪处理后相比未降噪,其诊断结果也存在明显差异;通过对表4 的诊断结果数据进行分析发现,经过降噪并降维处理后,诊断效果最好;且相比于ELM、SVM和BP,GA-ELM 的诊断效果最优,其对3种故障的平均诊断正确率达到90.67%,而其它3种分别为87.36%、81.35%和81.56%。
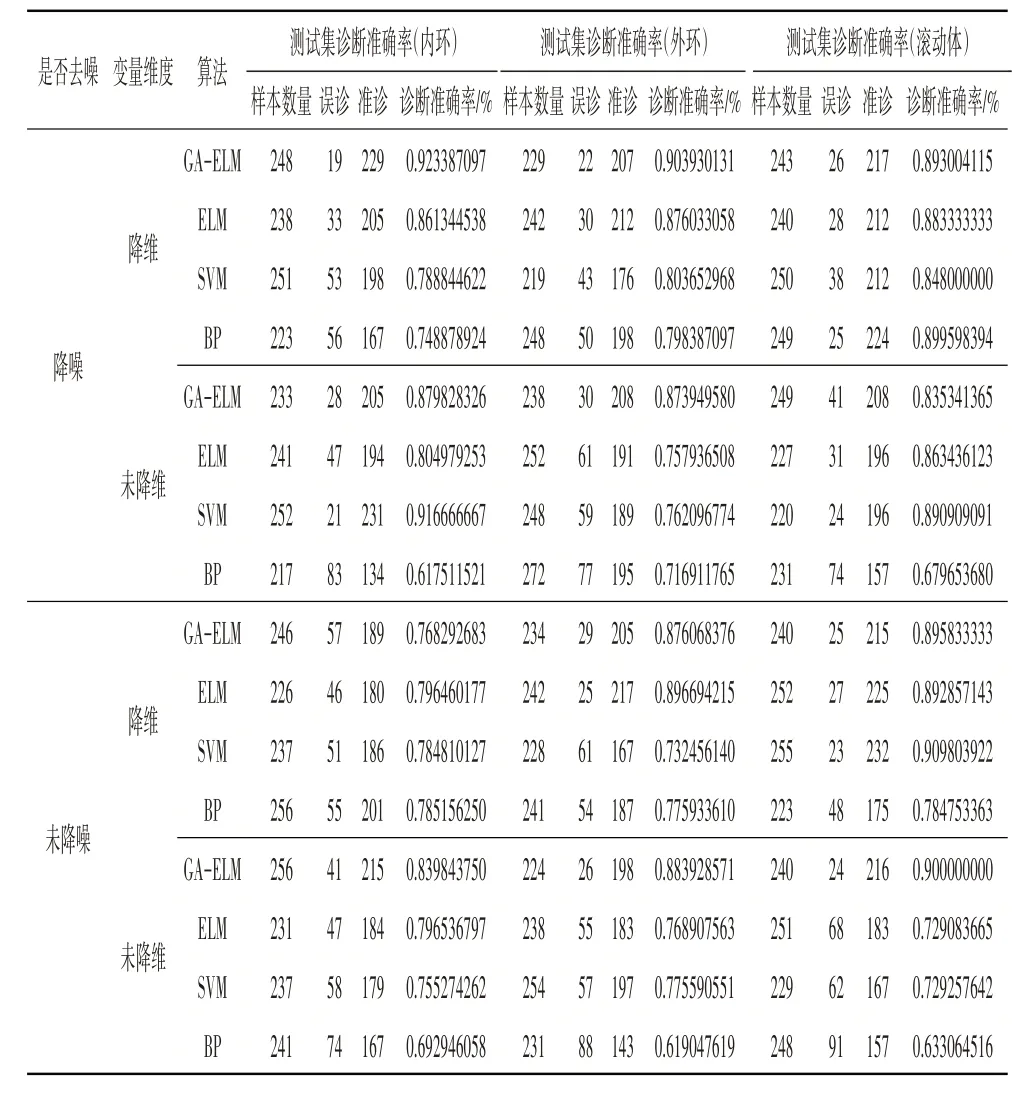
表4 故障诊断结果
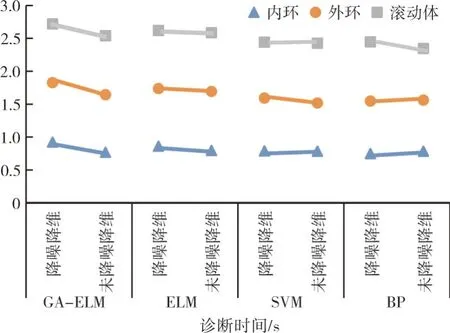
图11 轴承故障样本数据诊断结果(降维)
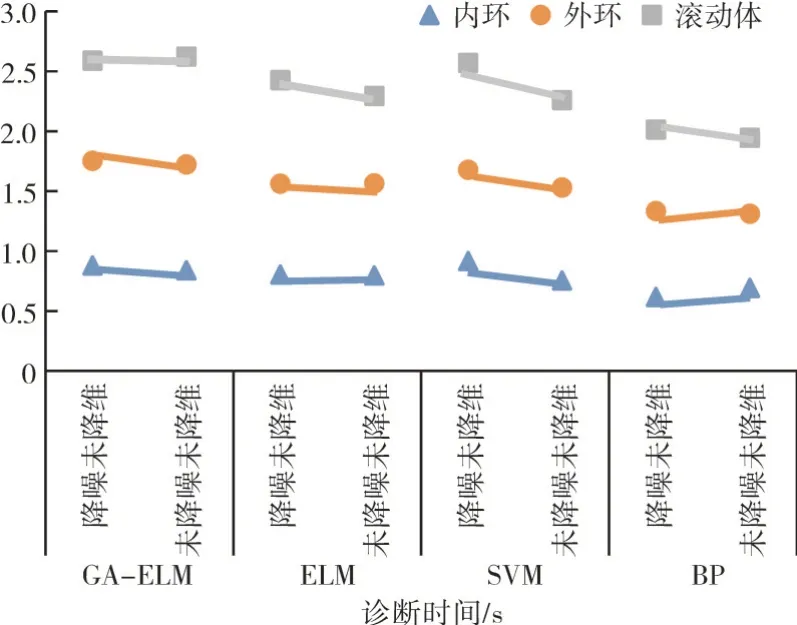
图12 轴承故障样本数据诊断结果(未降维)
5 结论
通过试验仿真发现:(1)ICA 能对混叠信号进行有效分离,实现更具故障特征信息的提取;(2)特征变量的降维不仅能够降低计算维度,同时也能提升诊断方法的准确率;(3)经过优化后的诊断网络,其故障识别率相对提升;(4)文中提出的轴承故障诊断方法能够有效地实现故障诊断,其准确率能超过90%,具有明显优势,而ELM、SVM 和BP 3 种诊断模型正确率分别为87.36%、81.35%和81.56%。
