基于布谷鸟算法的可逆数据库水印方案
2021-12-14沈泉江杨洪山
宋 岩 沈泉江 杨洪山
1(国网上海市电力公司电力科学研究院 上海 200433)2(星环信息科技(上海)有限公司 上海 200233)
0 引 言
随着大数据等IT技术的快速发展,越来越多的个人及企业将重要数据上传到云端进行存储、传输和发布。不过2016年Facebook发生的数据泄露事件表明,存放在云端的数据并没有用户所认为的安全。在这种关系型数据模式下,授权用户可以通过应用程序对数据进行访问和进一步使用,但这也面临一些安全威胁:授权用户可以随意对数据库信息进行复制或修改,甚至可以为牟利将数据非法泄露给未授权用户。可以看出,防止数据的非法共享是数据库安全应用面临的一大关键问题。因此数据库水印技术被提出。
近期,数据库加密和水印技术可以对数据库加密并将数字水印嵌入加密的数据库中,这使验证数据的来源与保护数据库的安全并免受篡改成为可能。数字水印技术在提出时主要是针对多媒体数据[1-3];而与一般多媒体数据相比,数据库具有低冗余度和低敏感性的特点,这使得在对数据库嵌入水印时,需要考虑减小因嵌入水印造成的失真以及如何保证水印鲁棒性的问题。
2000年,Khanna S等率先利用数据库水印解决数据库安全问题的思路。2002年文献[4]提出了首个用于关系数据库的数字水印方案。根据使用目的分类,数字水印可以分为鲁棒性数字水印和脆弱性数字水印。脆弱性水印是指对数据库进行的微小改动会破坏水印,这类水印主要用于保证数据未被攻击者篡改;而鲁棒性水印则保证在大幅度修改数据库信息时,依然可以通过水印提取方法从数据库中提取出原始水印,这类水印通常被用于证明数据来源及版权。
目前,传统数据库水印方法大多会随机选择嵌入水印的位置,这种方式虽操作直接且简便,但插入的水印可能会造成原始属性值的失真(超出原本值的范围)。将寻找嵌入水印的位置转化为一项优化求解问题,寻找插入水印的最佳位置成为一项广泛研究的问题,但大多数方法仍无法避免数据失真与计算速度较慢的问题。
差分水印拓展技术是一种将水印嵌入到数据差值中的方法,相比于其他嵌入水印的方法,这种技术最大的优点在于,在水印被提取出后仍可以无失真地恢复出原始数据库;即只要数据库传送到合法用户,用户在使用时无须考虑失真对于使用数据所造成的影响。但如果对数据不加选择地使用差分拓展技术,会使得插入水印后的值与原始值相差过大甚至超过本属性值所允许的范围。例如,电网频率通常保持在50 Hz±0.2 Hz,但如果对这一数值嵌入水印,可能会使得频率远超合法的波动范围,变为60 Hz甚至70 Hz,攻击者可以很容易判别出这一位置的数据插入了水印,进而摧毁或查看水印信息,甚至可以将水印替换成其他内容,通过这种方式嵌入的水印显然是不安全的。因此,在嵌入水印时应当选择合适的位置嵌入水印,使得嵌入水印后的值与原始值相差较小(失真较小);除减小失真外,也需要考虑水印的容量。差分拓展每次只能嵌入一个比特位的数值(0或1),这就需要尽可能多地寻找可以嵌入水印的位置,但同时还需考虑数据实时传输的要求,减少寻找嵌入水印位置所花费的时间。因此,需要能高效寻找适合嵌入水印位置的算法。
本文基于布谷鸟搜索算法和差分拓展技术提出一种新的嵌入可逆水印的方案:首先通过哈希算法将数据依据元组的主键和属性的名称重新排序;然后通过布谷鸟算法寻找最适合插入水印的位置;最后,通过差分拓展技术在寻找到的最佳位置上打入水印。
基于此,本文的数据库水印方案可有效抵抗针对数据属性或数据元组的排序攻击,并且在位置寻优过程中具有较快的收敛速度。为了验证本文方案的效率,在一个森林覆盖类型数据集对这一方法进行了实验,并比较不同规模的数据库嵌入水印时,花费时间和造成数据失真的变化。
1 相关研究
Khanna S等率先提出利用数据库水印完成安全控制的思路并开启本领域研究。在此基础上,文献[4]提出了首个可用于关系数据的数字水印方案。
在此之后,研究者们针对关系数据无序、数据冗余小等特点,提出了一系列适合关系数据的数字水印方案,主要分为针对水印嵌入技术的研究、针对水印嵌入算法的研究,以及针对嵌入水印信息的研究。
针对水印嵌入算法的研究主要包括:Kiernan等[5]提出了针对关系数据库,通过MAC码来选择待嵌入水印元组和属性位置,通过LSB技术嵌入水印的方法。Sion等[6]在此基础上提出了一种按照标准化值的最高位排序元组,然后在MAC能够整除m的元组中,通过修改接近标准偏差边界的元组值来嵌入水印的方法。Shehab等[7]基于基因算法,首次将嵌入数字水印位置转化为优化问题,他们的方案减小了嵌入水印后造成的数据失真。Iftikhar等[8]基于信息概念提出了新的选择水印嵌入位置依据的方案。Imamoglu等[9]使用萤火虫算法在关系数据中选择嵌入水印的最佳位置,基于差分拓展技术实现水印嵌入和数据恢复。
针对水印嵌入算法的研究包括:Zhang等[10]首次提出了基于属性差值构建直方图的可逆数据库水印方案。同年,针对关系数据库,张勇等[11]提出了基于异或运算的可逆水印方案,但该方法并未给出水印检测算法;Gupta等[12]提出基于差分扩展的可逆水印方案,该方法将数字水印嵌入到不同属性的插值中完成水印的嵌入和提取;Farfoura等针对关系数据库提出的BRM方案可插入能够盲检测的可逆水印;Chang等[13]提出的BRRW技术基于直方图变换实现了针对关系数据库插入可逆水印。
针对水印信息的研究包括:Zhang等[14]将图像转化为二进制流作为水印插入到数值属性,该方案基于差分拓展技术实现水印的可逆提取。文献[15]将音频信号混合成水印信息后嵌入到关系数据库中,完成了水印的嵌入和提取。
2 相关背景和知识
布谷鸟搜索算法是一种启发式的算法,主要用于解决优化问题寻找问题的最优解;差分拓展水印嵌入技术是一种可逆的水印嵌入技术。
2.1 布谷鸟搜索算法
布谷鸟搜索算法是Yang等[16]观察自然界中布谷鸟借巢产卵的行为提出的,在该算法中,布谷鸟会按照特定的飞行方式寻找适合产卵的鸟巢位置,在本文中即寻找适合嵌入水印的位置。其中,布谷鸟搜索算法在应用时需满足以下三个假设:
(1) 每只布谷鸟作为一个寻找全局最优解的过程,一次只能选择一个鸟巢作为一组解,即目标位置点。
(2) 每次只有最好(目标函数值最优)的鸟巢作为本次迭代的最优解会被保留到下一代。
(3) 可以使用的鸟巢数量是开始就被确定的,一旦卵被发现(以0~1间的固定概率p)则重新寻找并建立新窝,即寻找新的目标位置点。
因此,基于莱维飞行布谷鸟算法可以给出每次更新鸟巢位置和路径的更新方式:
式中:⊗代表点乘运算。

2.2 差分扩展水印嵌入技术
差分拓展技术[17-18]是一种可以在提取出水印后无损恢复原始数据库的可逆水印技术。在获得某一元组的两个属性数值后,可以通过差分拓展技术修改它们的差值进而嵌入水印。假设某一行需要嵌入水印的数据是A1、A2,它们的平均值和插值为:

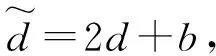
当接收方收到嵌入水印的数据后,可以通过如下步骤计算最终提取水印以及得到原始数据:

只要每次插入的水印信息b∈{0,1}便可以在取出水印后无失真地恢复出原始数据库。
例如,假设在数据库中需要嵌入的水印的两个属性值分别为A1=54、A2=21,需要插入的水印位为1,则嵌入水印的过程如下:

avg=⎣」=37
通过水印提取算法,可以提取出嵌入的水印并恢复出原始值,过程如下:
d=54-21=33


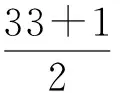
从上面的例子可以看出,差分拓展技术可以将水印以水印位(0或1的值)的形式嵌入到两个数值中,但这种方法会改变原始数据的值并带来一定的数据失真;通过这一方法,将嵌入水印后的数据库传输到可信的第三方后,通过嵌入水印的逆方法可以提取出水印并恢复出原始数据库。
3 本文方案
本文提出一种新的可逆数据库水印算法,该算法采用基于布谷鸟产卵的启发式搜索算法寻找水印的最佳嵌入位置;之后采用差分拓展算法在原始数据库中加入水印,该算法可以保证水印被提取出之后可以无损地恢复原数据库。
首先,对于下文所使用的主要变量的符号及其描述进行汇总和介绍,具体如表1所示。

表1 变量名及其含义
3.1 水印及数据库预处理
对数据库插入水印进行预处理,保证算法对重新排列属性/元组攻击的鲁棒性,预处理主要包括针对水印的预处理、针对元组的预处理,以及针对属性的预处理三个部分。
(1) 数据水印的预处理。针对水印的预处理是因为差分拓展技术在嵌入水印时,每次只能嵌入1或0,首先对需要嵌入的水印进行处理,将其转化为二进制的形式。
(2) 数据元组的预处理。对数据元组进行重新排序,以此来防范攻击者针对元组的增加、删除与重组攻击。主要方法是对输入数据库的元组r根据其主键PK分类到Ng个不同的子集,重新排序后x作为元组的索引:
x=H(key|H(key|r.PK))modNg
式中:|代表连接操作;key表示用户指定的密钥;H表示一个安全哈希算法(本文采用512比特的SHA-1哈希算法);r代表输入数据库的元组,PK代表当前元组的主键;mod代表取余操作;Ng代表子集总个数,本文以二进制长度描述水印的长度。由此,输入数据库便被分成与数据库水印长度相同数量的子集,每个组中将被嵌入水印的一位。例如,对于一个有100个元组的数据库与长度为10的水印,数据库将通过此方法为10个不同的组,每个组包含10个元组,后续对每个子集使用寻优算法并在其中嵌入相应的水印位的值。
(3) 数据属性的预处理。为防范攻击者针对属性的删除攻击,需要对数据属性进行重新排序,其方式是根据属性名称的哈希值对数据库的属性计算后进行重新排序,属性名A.name在重新排序后作为插入水印时确定属性位置的索引y:
y=H(key|H(key|A.name))
后文中使用的输入数据库与水印均经过预处理,相关的x、y均为经过预处理后的值。
3.2 改进的布谷鸟搜索算法
该模块使用布谷鸟搜索算法为所选子集DS中的元组选择嵌入水印信息的最佳属性对。从预处理模块获取子集作为输入,并最终输出所选择的布谷鸟及其给出的最优解即指定嵌入水印的位置(所选元组行的属性索引)。
3.2.1创建初始种群
该算法使用P只布谷鸟创建初始种群,计算不同布谷鸟给出解决方案的目标函数值后进行排序,算法的主要输入如下:
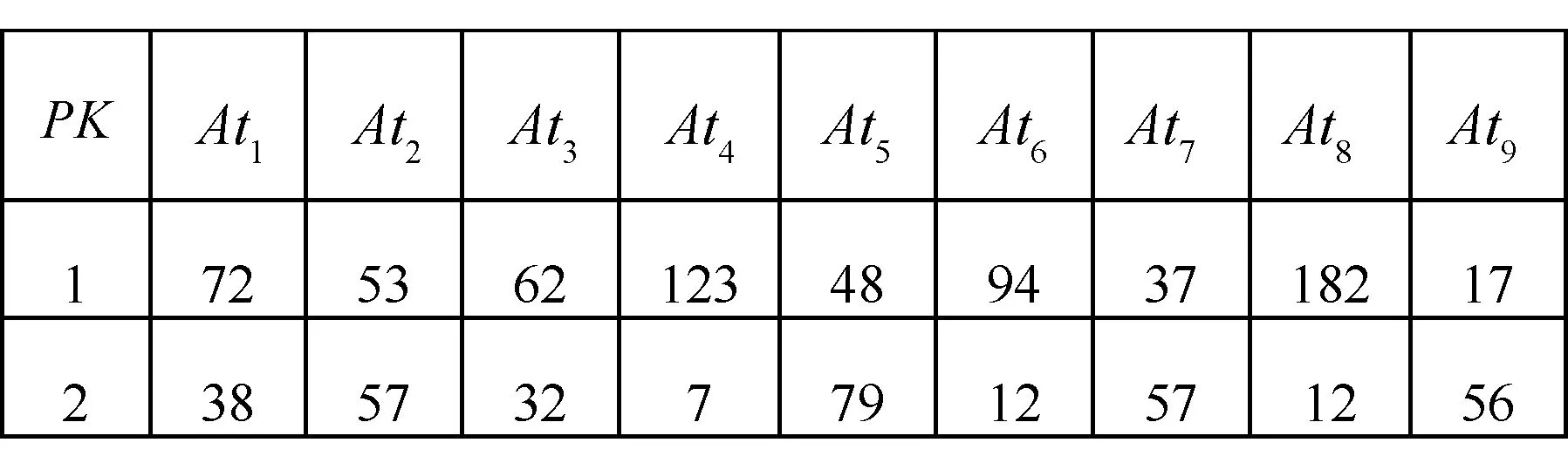
1) 待嵌入水印的关系数据库DS∈(p,A1,A2,…,An),其中:p为DS各元组的主键;A1,A2,…,An为DS的n个属性。DS由m个元组r1,r2,…,rm组成;每个元组都有且仅有一个各不相同的主键r.p和n个属性列r.A1,r.A2,…,r.An。
2) 初始种群数量表示用于寻找最优解的布谷鸟的数量,此数值越大,在寻优过程中便更容易找到全局最优解(或找到更好的局部最优解),但同时需要的算力也越大。
3) 待嵌入水印u=(u1,u2,…,uk),ui∈{0,1},k≤m。
4) 对于插入水印造成失真的偏好wa与对于水印容量的偏好wc,代表了对于嵌入水印造成失真与水印容量的偏好选择,wa+wc=1,wa越大则越偏好于选择对数据库造成失真小的方案,wc越大则代表了偏好于选择水印容量较大的方案。
在经过初始种群算法后的输出主要如下:
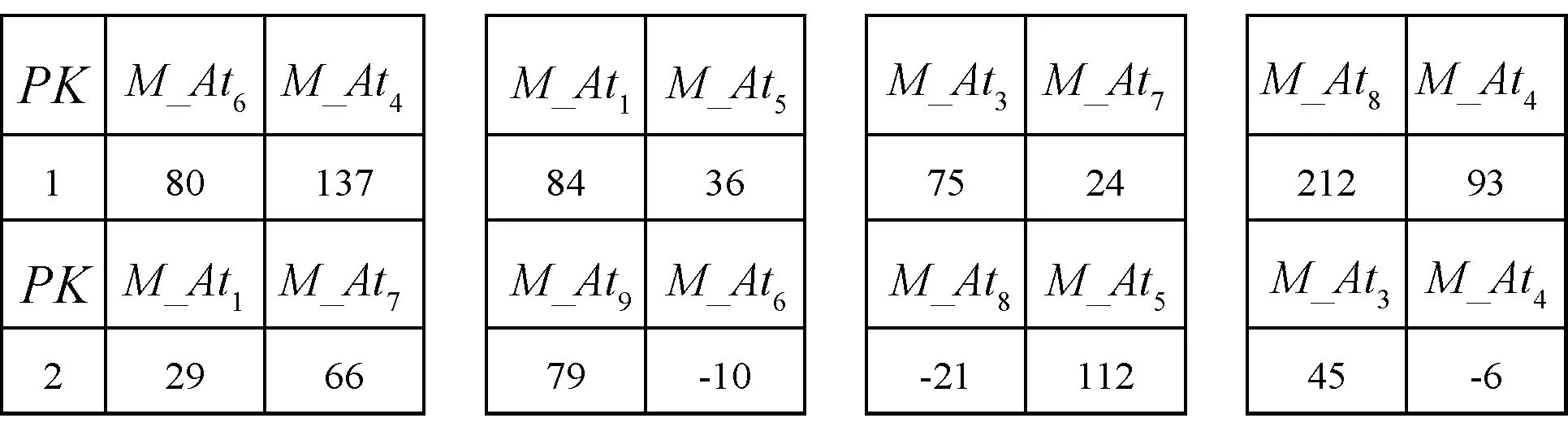
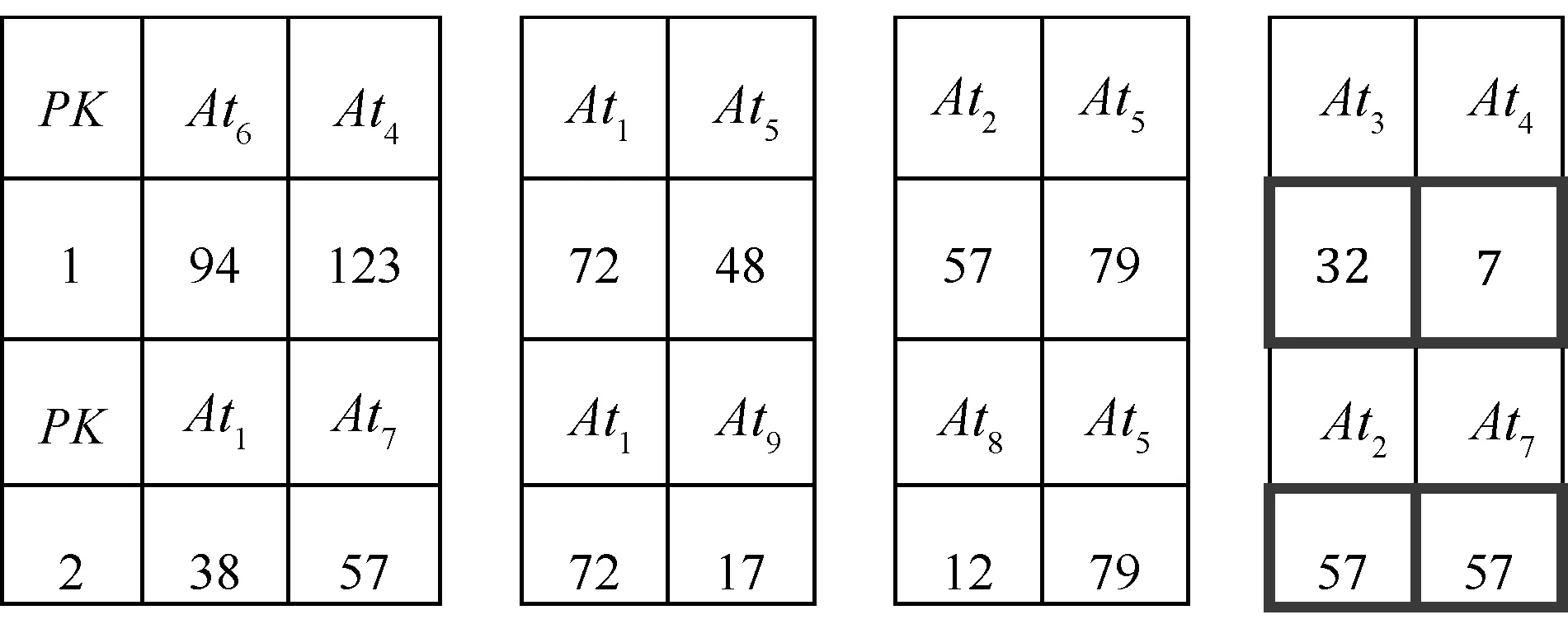
1) 初始种群:F1,F2,…,FP为P只布谷鸟给出的解决方案的合集,其中每个解决方案为一个三维的向量,向量的前两维代表对于不同元组为嵌入水印信息所选择的两个属性的索引值,第三维代表次元组其嵌入水印后造成的数据失真:例如,F1={[2,7,11],[1,5,4]},[1,5,4]}代表对于第一个元组,选择第2和第7个属性嵌入水印,造成的失真为11,对于第二个元组,选择第1和第5个属性嵌入水印,造成的失真为4。
2) 最佳方案Fbest:记录所有布谷鸟种,目标函数(fitness值)最小解决方案的水印插入位置信息。
初始种群算法如算法1所示。
算法1初始种群算法
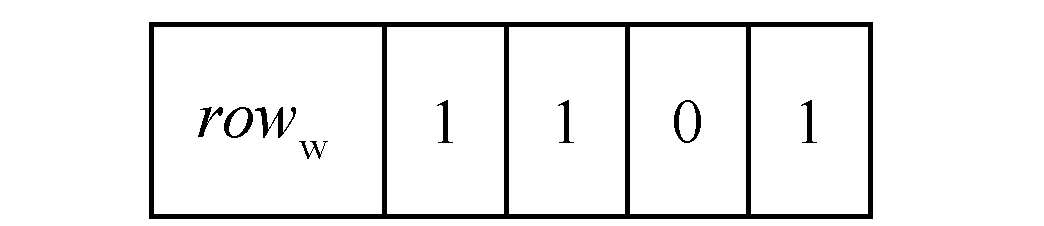
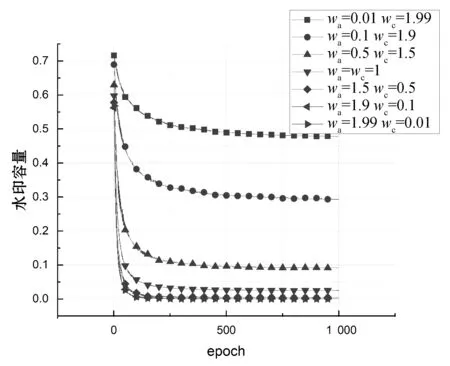
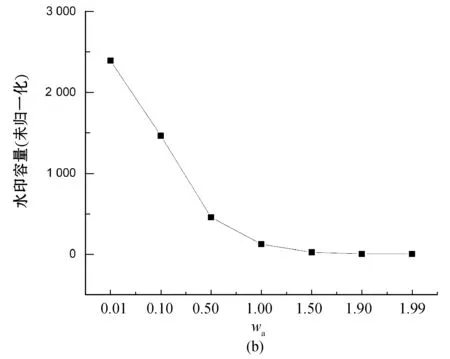
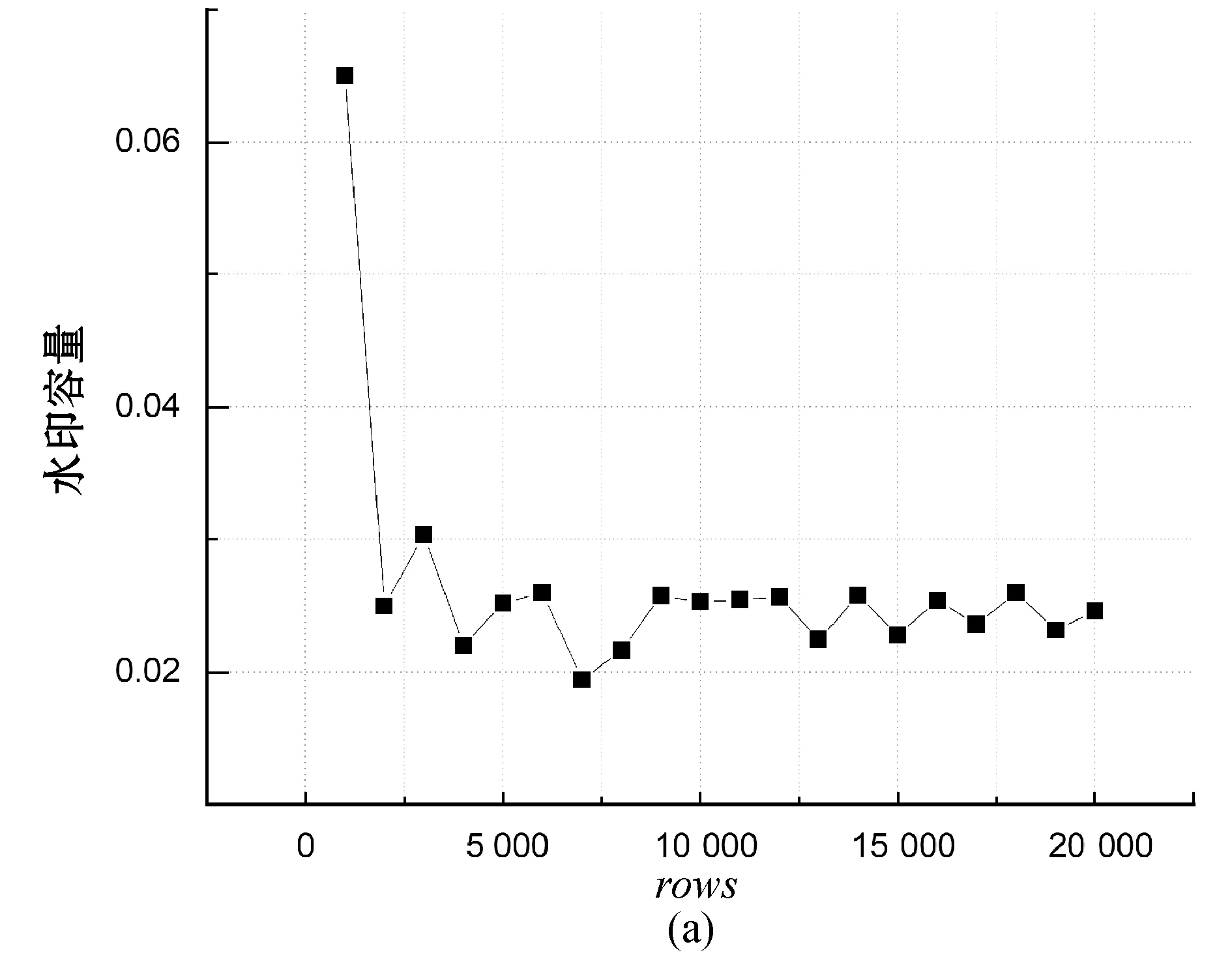
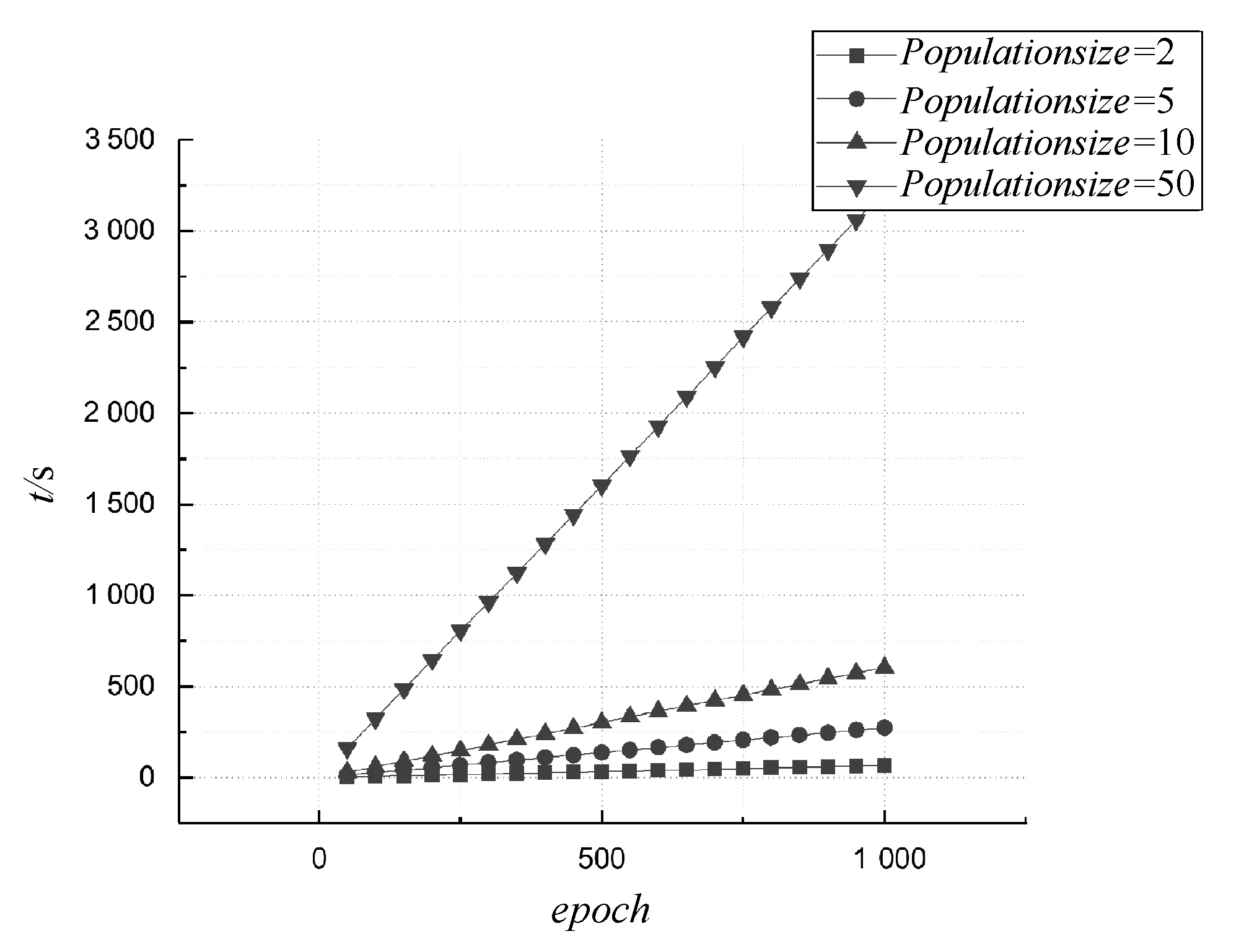
1. forp=1,p 2.mdfp=0,rowp=0 3. fori=1,i 4. [x[p][i],y[p][i]]=random chosed (x,y∈(0,n)) 7.rowp=rowp+1 10.fitness(xp,yp)min(fitness) 11.Fbest=[xp,yp,fitness(xp,yp)] 12.F=[x,y,fitness] 变量row用于保存有关水印容量的信息。步骤9中每个布谷鸟计算第p个布谷鸟的fitnessp。fitness受两个因素的影响:属性的总失真和可以加水印容量。第一个因素是通过计算属性mdfp来表示的;第二个因素主要由rowp衡量。这两个因素的比重由wa和wc确定。步骤10中在生成初始种群中找到fitness最小的方案并记录其信息为为Fbest。 布谷鸟算法的fitness函数旨在将嵌入水印之后的失真降到最小值,布谷鸟算法为每个元组选择嵌入水印的最佳位置,保证在通过差分拓展技术嵌入水印后对数据库造成的失真影响最小。适应度函数旨在考虑两个方面:插入水印引起所选属性的失真和水印的容量。图1给出了对于一个由9个属性及2个元组组成的数据库,使用布谷鸟算法基于4只布谷鸟的初始种群过程。 (a) 假设将要插入水印的数据库 (b) 使用5只布谷鸟给定初始种群 (c) 计算初始种群解决方案中的属性值插入水印后的值 (d) 每只布谷鸟解决方案的fitness图1 初始种群例子 3.2.2确定最佳布谷鸟 在此步骤中,布谷鸟算法计算在前一阶段创建的初始种群的基础上,对除了给出最优(即fitness最小)解决方案布谷鸟外,其他布谷鸟会通过莱维飞行更新获取新的随机位置并重复这一过程并保留较优的过程,并在算法超过最大迭代次数或目标函数值满足阈值要求后,返回最优的解决方案作为结果。该算法的输入包括: 1) 原始关系数据库DS。 2) 初始种群F。 3) 最佳方案Fbest。 4) 迭代次数epoch:算法迭代次数的上限,当迭代次数达到这一值后,返回本轮迭代的最优方案,epoch值越大,fitness值则更优,但相应地也需要更多的算力与时间,如何合理地设置epoch是平衡算法时间与fitness的关键。 5) 结束阈值threshold:用于判断是否已取得满足问题要求的方案,当最优方案的fitness小于阈值时,便停止继续迭代,返回满足要求的水印嵌入方案。最终输出为最佳解决方案Fbest。 种群更新算法如算法2所示。 算法2种群更新算法 1. fort=1,t 2. [newx, newy]=Cuckoo Search(x,y) 3. forp=1,p 4. fori=1,i 5. ifmdf(newx[p][i], newy[p][i]) 6.x[p][i]=newx[p][i],y[p][i]=newy[p][i] 7.fitness[p]=fitness(x[p],y[p]) 8. iffitness[p] 9.Fbest=[x[p],y[p],fitness(x[p],y[p])] 10. iffitness[p] 11. returnFbest 12. returnFbest 其中:步骤3中,对P只布谷鸟依次计算并通过Levy飞行更新其值;步骤4-步骤9对比Levy飞行后各位置值的并保留较优值;步骤10-步骤11用于判断当前迭代的最优fitness是否已满足阈值要求。图2以初始种群中的例子进行说明。 (a) 假设将要插入水印的数据库 (b) 对除了最优的其他布谷鸟通过莱维飞行进行更新 (c) 计算更新后的位置插入水印后的值 (d) 计算每只初始布谷鸟解决方案的fitness图2 更新种群实例 在水印嵌入阶段所使用的差分拓展嵌入技术是一种可以在提取水印后恢复原始数据库的方法,但其嵌入水印的效率较低(一次只能嵌入一位0或1),不加选择的嵌入水印会给原始数据库带来较大失真,在3.2节中使用布谷鸟搜索算法寻找适合的嵌入位置可以避免因嵌入水印造成过大的数据失真。 水印嵌入阶段需要在原始数据库中,按照在3.2节中获得的最佳嵌入位置Fbest分组地嵌入水印。水印嵌入算法原理已经在2.2节进行了说明,本节主要以本问题的情况说明水印具体的嵌入过程:在3.2节中获得的Fbest是一个m(原数据库元组数)行、2列的矩阵,其中第i行的2个数据表示原始数据库第i个元组中用于嵌入水印属性列的索引,两个待嵌入水印的原始数据按序与需要被嵌入的一位水印(0或1)一同传入水印嵌入算法,在嵌入水印后,按序分别替换用于嵌入水印的两原始数据。算法的主要输入如下: 1) 原始关系数据库DS。 2) 最佳方案Fbest。 水印嵌入算法的输出为已经嵌入水印的数据库,它会与加密密钥key以及通过3.1节属性名加密后的水印嵌入位置一起传输并最后用于提取水印以及恢复原始数据库。水印嵌入算法如算法3所示。 算法3水印嵌入算法 1. fork=0,k 3. [i,j]=Fbest[k] 其中步骤2将原始数据库进行了拷贝,并在拷贝后的数据库中通过改动数值的方式嵌入水印。 为方便理解,对于嵌入水印算法以及目标函数和数据失真的计算举例进行说明:假设要在一个具有4个元组、9个属性的数据库中嵌入两位水印u:(0,1)。通过3.1节的预处理,将4个元组分到了2个子集分别嵌入水印的两位(第1、第3元组被分到子集1用于嵌入水印的第一位,第2、第4元组被分到子集2用于嵌入水印的第二位)。嵌入水印的过程如图3所示。 (a) 原始数据库、需要迁入的水印及在3.2节中选择的嵌入水印的位置 (b) 嵌入水印后的数据库 (c) 未嵌入水印数据库各属性的阈值 (d) 各元组能否嵌入水印及水印容量的计算 图3 水印嵌入过程实例 本节对本文方案进行实验仿真并对结果进行详细分析。实验环境为一台配备Intel core i7-9750H处理器、16 GB DDR4内存的计算机主机,操作系统为Windows 10,数据库为Mysql。数据集为加利福尼亚大学的森林覆盖类型(Forest CoverType dataset,FCT)数据集,其中数据集包含581 012个元组,由54个属性组成。因为数据库第9个之后的属性含有大量属性值为0的元素,对此使用差分水印拓展技术会将两个属性值为0的属性选作插入水印的最佳位置,从而导致算法有多个全局最优解,这对于评估实验结果是十分不利的,因此,在实验过程中仅选取前9个属性以及前20 000个元组进行实验。本实验主要分为两个部分,第一部分主要测试算法中种群数量、迭代次数、权重系数(wa和wc)对于目标函数中数据失真和水印容量大小的影响,并对参数选择进行优化;在第一部分的基础上,第二部分主要测试算法中种群数量、迭代次数、原始数据库元组数量对于目标函数以及算法运行时间的影响,并评价本算法的优劣。 数据失真与水印容量是衡量数据库水印算法优劣的重要标准。因而在本节中主要研究迭代次数、种群数量、权重系数(wa和wc)对于数据库失真与水印容量造成的影响。需要特别说明的是,在目标函数中水印容量使用的是不能嵌入水印的元组数,为避免歧义,在后文中对于水印容量使用好和差进行形容。 首先,为了验证算法对于目标函数中数据失真度和水印容量的寻优情况,设定数据库元组数(rows)为5 000,研究不同权重系数情况(两者之和恒为2)下,数据库失真与水印容量随迭代次数变化的情况,结果如图4所示。 (a) (b)图4 水印容量与数据失真随权重系数与迭代次数的变化情况 可以看出,随着迭代次数的增大,数据失真与水印容量都逐渐收敛,在所测试的几种情况中,当迭代次数超过800次之后,结果都已经趋于稳定。因此,在后续的实验中,设定最大迭代次数为1 000,并认为此时的结果已经收敛。同时,我们发现权重系数会影响最终收敛的结果,但图4中曲线较为集中,难以观察不同权重系数情况下,水印容量及数据失真收敛时的情况。因此,在图4的基础上,仅记录最后一次迭代输出的最终结果中数据失真及水印容量的大小,并记录这一值随权重系数的变化情况,且为在途中更直观地反映有多少元组不能嵌入水印以及对于数据库造成的总失真情况,在此实验中,使用的数据失真值为整个数据库水印容量之和(未取平均值),而水印容量为实际不能嵌入水印的元组数(未归一化),结果如图5所示。 图5 收敛时数据失真与水印容量随权重系数的变化情况 可以看出,在实验的几组数据中,wa=1可以使数据失真在实验最后获得最低的数据失真,而对于水印容量,wa=1.90及wa=1.99都可以使水印容量达到最优情况,但在wa>1后,水印容量的变化便已经很小了,因此在后续的实验中,选择wa=wc=1进行实验。 其次,为了研究问题矩阵的维数对于问题结果造成的影响,设定wa=wc=1,最大迭代次数为1 000,种群数量为2,数据库失真与水印容量随问题矩阵变化的情况如图6所示。 图6 收敛时水印容量与数据失真随问题矩阵维数的变化情况 可以看出,对于水印容量,几乎很难找到使得收敛时水印容量最佳的数据库维度。但可以发现,当数据库的维度过小时(在本实验中为1 000时),数据库水印容量相对较差,这主要是由于允许嵌入水印的范围较小。对于数据失真,虽然在本实验结果中,当水印容量为6 000时,数据失真较小。但多次实验发现这一结论与选择的元组的值的具体情况有关。为了测试算法对于不同大小数据库嵌入水印的情况,在后续的实验中分别选取5 000、10 000、15 000、20 000个元组嵌入水印。 最后,为了研究种群数量对于实验结果造成的影响,设定数据库元组数(rows)为5 000,最大迭代次数为1 000,研究数据库失真与水印容量随种群数量变化的情况,结果如图7所示。 图7 收敛时数据失真与水印容量随种群数量的变化情况 可以看出,种群数量为35时,最终的数据失真最小;种群数量为15时,水印容量情况最优。但种群数量通常会大幅度地影响算法的运行时间,过大的种群数量通常会造成算法耗时过长,故在后续的实验中,只验证种群数量为2、5、10、50时的情况。 在4.1节基础上,固定wa=wc=1、最大迭代次数为1 000,其他不能固定的参数会在每个实验中进行说明。为更好地对本文方案的运行时间和目标函数(为找到降低数据失真和提高水印容量平衡的目标函数)进行评测,本节主要关注种群数量、迭代次数及问题矩阵DS元组数量的变化对目标函数(fitness)以及算法运行时间造成的影响。 首先,保持种群数量为2,观察不同输入矩阵维数(rows)下目标函数(fitness)随epoch的变化情况,实验结果如图8所示。 图8 迭代次数与问题矩阵维数对于目标函数的影响 可以看出,随着迭代次数的增大,fitness呈指数级下降,且不同种群数量的下降曲线几乎一致,这就使得本文算法对于不同规模数据库都有着较好的泛化性能。 其次,设定输入矩阵维数(rows)为5 000,观察不同种群数量(PopulationSize)下,目标函数(fitness)随迭代次数(epoch)的变化情况,实验结果如图9所示。 图9 迭代次数与初始种群数量对于目标函数的影响 可以看出,随着种群数量的增大,目标函数的值下降速度变得更快;同时,对于测试的数据,目标函数最终收敛的值随种群数量的增大而减小,在实验中,当种群数量大于10时,本文算法可以将目标函数优化到7左右。 最后,设定输入矩阵维数(rows)为5 000,观察不同种群数量情况下,寻找最优位置花费的时间(t)随迭代次数变化的情况,实验结果如图10所示。 图10 初始种群数量与迭代次数对于程序运行时间的影响 可以看出,实验所用时间(t)与迭代次数(epoch)几乎呈正相关,且种群数量(PopulationSize)越大,其增长速度也越大,在实验中,对于种群数量小于10的情况,本文算法最终的运行时间都保持在10 min以内。 本文提出一种基于改进布谷鸟算法和差分拓展技术的可逆数据库水印方案。在接下来的工作中将会尝试突破单纯的差分拓展技术所受到的数据类型限制:实验中所使用的数据库为整型数据库,但在实际嵌入水印时,可能需要在非整型甚至文本型的数据库中嵌入水印,差分拓展技术因其本身的算法要求,难以在非整型数据中嵌入水印,在文本型数据库中也会面临诸多挑战。





3.3 水印嵌入






4 实 验
4.1 实验参数优化





4.2 目标函数及算法运行时间


5 结 语
