基于深度学习的人群计数研究综述
2021-12-14朱慧琳苗夺谦
余 鹰 朱慧琳 钱 进 潘 诚 苗夺谦,2
1(华东交通大学软件学院 南昌 330013) 2(同济大学电子与信息工程学院 上海 201804)
人群计数是估计图像或视频中人群的数量、密度或分布[1],它是智能视频监控分析领域的关键问题和研究热点,也是后续行为分析[2-3]、拥塞分析[4]、异常检测[5-6]和事件检测[7]等高级视频处理任务的基础.随着城市化进程的快速推进,城市人口数量急剧增长,导致各种人员高度聚集的社会活动频繁发生,如果管控不当,极易发生拥挤踩踏事故.例如上海“12.31”外滩踩踏事故中,由于现场管理和应对措施不当,引发了人群拥挤和摔倒,最终造成了重大人员伤亡的严重后果[8-9].如果有精度良好的人群计数系统实时统计相关场所的人群数量、分布或密度等信息,及时发现人群拥挤和异常行为并进行预警,以便采取措施进行疏导,就可以避免悲剧的发生[10-11].性能良好的人群计数算法也可以迁移到其他目标计数领域,如显微图片中的细菌与细胞计数[12]、拥挤道路上的汽车计数[13]等,拓展人群计数算法的应用范围.因此,人群计数方法的研究有着重要的现实意义和应用价值.
随着人工智能、计算机视觉等技术的不断发展,人群计数受到了国内外众多学者的广泛关注和研究.早期人群计数主要使用传统的计算机视觉方法提取行人特征[14],然后通过目标检测[15-19]或回归[20-21]的方式获取图像[22-25]或视频[26-28]中人群的数量.传统方法具有一定局限性,无法从图像中提取更抽象的有助于完成人群计数任务的语义特征,使得面对背景复杂、人群密集、遮挡严重的场景时,计数精度无法满足实际需求.近年来,深度学习技术发展迅猛,在许多计算机视觉任务中得到成功应用[29],促使研究人员开始探索基于卷积神经网络(convolutional neural network, CNN)[30]的人群计数办法.相比于传统方法,基于CNN的人群计数方法在处理场景适应性、尺度多样性等问题时表现更优.而且由于特征是自学习的,不需要人工选取,可以显著提升计数效果,因此已经成为当前人群计数领域的研究热点.使用CNN的人群计数方法主要分为直接回归计数法和密度图估计法2类.直接回归法只需向CNN送入人群图片,就可以直接输出人群数量,适用于人群稀疏场景.在密度图法中,CNN输出的是人群密度图,再以数学积分求和的方式计算出人数.这类方法性能的好坏一定程度上依赖于密度图的质量.为了提升密度图质量,会引入新的损失函数[31]来提高密度图的清晰度和准确度.无论采用哪种方法,都需要先进行特征提取.为了提升特征的鲁棒性,常使用多尺度预测、上下文感知、空洞卷积、可形变卷积等方法改进特征提取过程,以增强特征的判别能力.
得益于深度学习模型强大的特征提取能力,基于深度学习的人群计数方法的研究已经取得了很多优秀的成果.根据计数对象,可以将这些方法归纳为基于图像和基于视频的2类;根据网络模型结构,可将它们划分为单分支结构、多分支结构和特殊结构3类;根据度量规则,可将它们划分为基于欧氏距离损失、基于SSIM损失和基于对抗损失等多类.
本文重点讨论基于深度学习的静态图像人群计数方法,主要贡献可以归纳为3个方面:
1)从不同层面,对人群计数领域的研究现状进行系统全面的总结和深入的探讨,包括计数网络结构、损失函数、性能评价指标等.这种全面梳理可以帮助研究人员快速了解基于深度学习的人群计数算法的研究现状和关键技术.
2)基于数据比较了不同模型的计数效果,分析了计数模型性能优劣的原因,为未来研究人员设计更加优化的计数模型提供借鉴.
3)归纳总结了在模型设计、损失函数定义、ground-truth生成等方面存在的问题,为未来该领域的研究指明了方向.
1 人群计数网络
1.1 单分支结构计数网络
早期使用CNN的人群计数网络均为只包含一条数据通路的单分支网络结构.Wang等人[32]最先将CNN引入人群计数领域,提出了一种适用于密集人群场景的端到端CNN回归模型.该模型对AlexNet网络[33]进行改进,将最后的全连接层替换为单神经元层,直接预测人群数量.由于没有预测人群密度图,所以无法统计场景中的人员分布情况.此外,虽然该模型通过CNN自动学习了有效的计数特征,但是由于AlexNet的宽度较窄,深度也较浅,导致特征鲁棒性不够强,在人群密集场景下的计数效果较差,并且在跨场景计数时,效果不甚理想,缺乏足够的泛化性.
为了解决跨场景问题,Zhang等人[24]提出了一种基于AlexNet的跨场景计数模型Crowd CNN,首次尝试输出人群密度图,其总体结构如图1[24]所示:
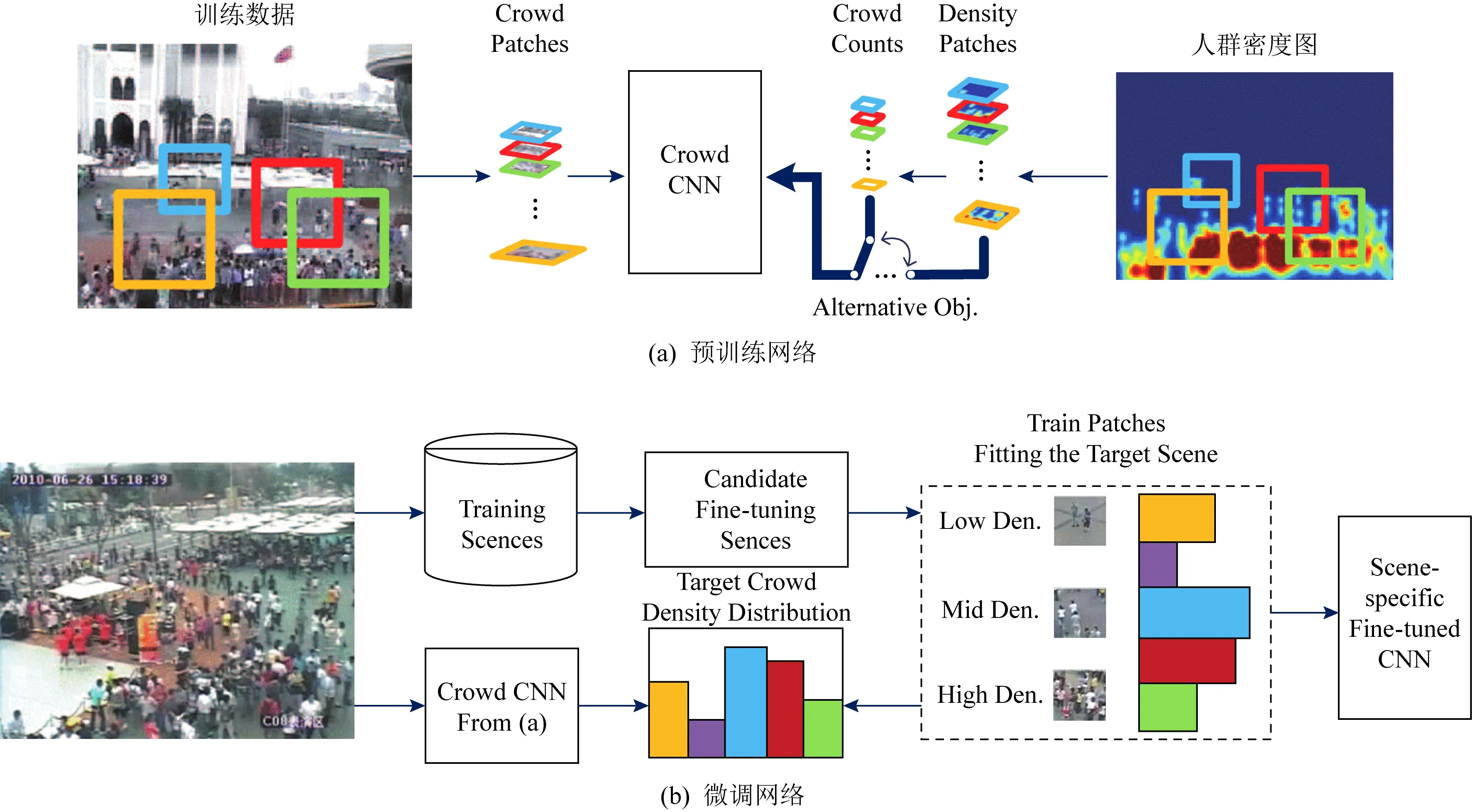
Fig.1 The cross-scene crowd counting model proposed by Reference[24]
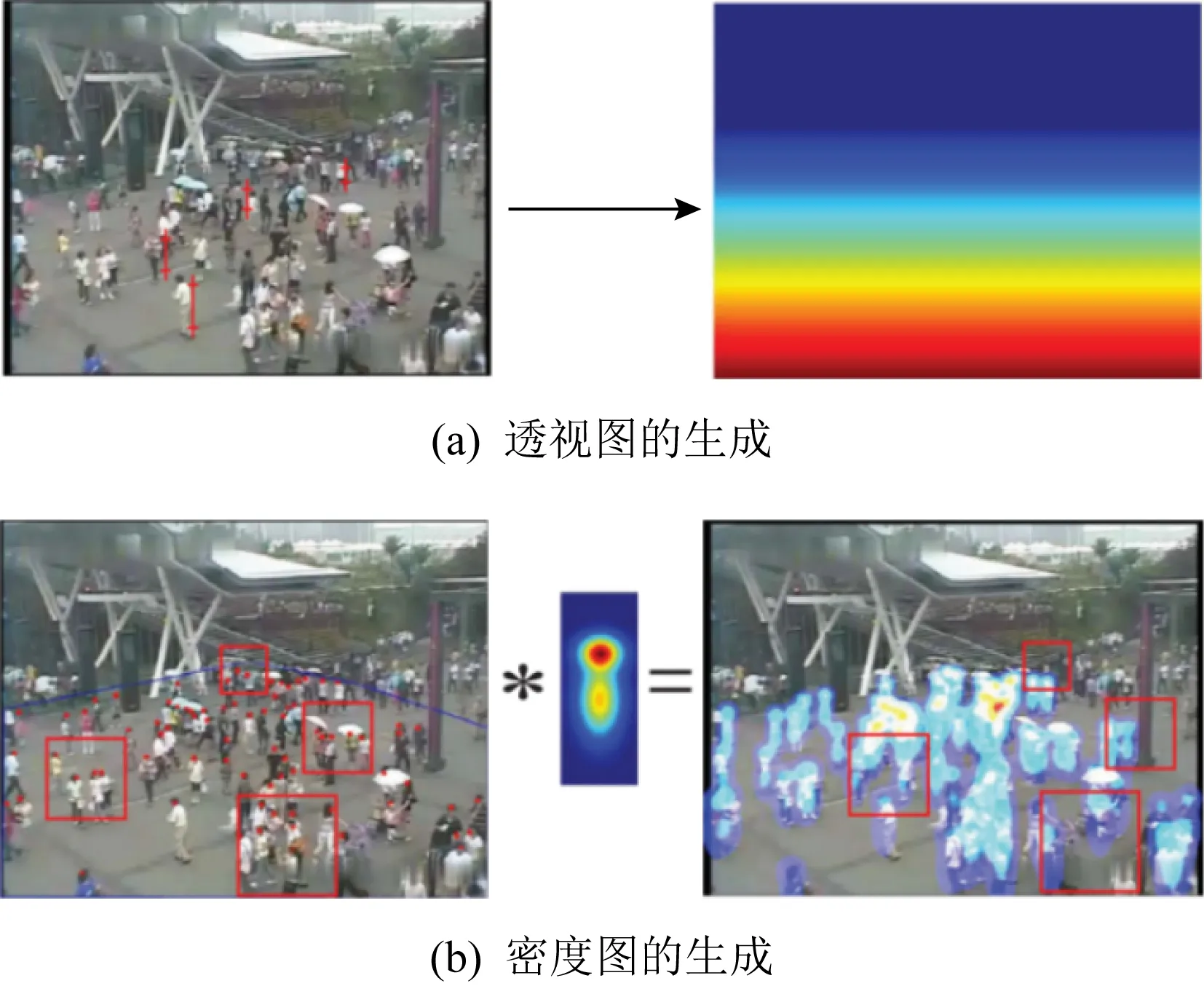
Fig.2 Normalized crowd density map for training[24]
其中,图1(a)描绘了计数网络的预训练(pre-trained)过程,通过人群密度图(crowd density map)和人群计数(crowd counts)这2个目标任务的交替训练来优化模型.然后,算法会根据目标场景特点,选择相似场景对计数模型进行微调(fine-tuning),如图1(b)所示,以达到跨场景计数的目的.为了提升计数准确性,作者还提出了透视图(perspective map)的概念,如图2(a)所示,颜色越浅代表目标尺度越大.然后,通过密度图和透视图的融合,如图2(b)所示,降低透视形变(perspective distortion)的不良影响,提升密度图质量.但是透视图较难获得,限制了该模型的推广.该工作的另一个贡献是建立了经典的人群计数数据集WorldExpo’10,为交叉场景人群计数模型的测评提供数据.
1.2 多分支结构计数网络
人群分布相对监控摄像头位置具有较大的不确定性,导致拍摄视角差异较大,所拍摄到的图像或视频中目标尺寸变化较大.对于人群计数任务来说,如何提高计数网络对目标尺度变化的适应性是亟待解决的问题.
为了解决多尺度问题,Boominathan等人[34]基于CNN提出了一种双分支结构计数网络CrowdNet,如图3所示.通过一个浅层网络(shallow network)和一个深层网络(deep network)分别提取不同尺度的特征信息进行融合来预测人群密度图.这种组合可以同时捕获高级和低级语义信息,以适应人群的非均匀缩放和视角的变化,因此有利于不同场景不同尺度的人群计数.
通过引入多路网络,使用大小不同的感受野提取不同尺度特征可以有效解决多尺度问题,由此衍生出了一系列多列卷积神经网络结构的人群计数算法.
Zhang等人[25]受多分支深度卷积神经网络[35]的启发,提出了一种多列卷积神经网络(multi-column CNN, MCNN)用于人群计数,其结构如图4所示.每一分支网络采用不同大小的卷积核来提取不同尺度目标的特征信息,减少因为视角变化形成的目标大小不一导致的计数误差.MCNN建立了图像与人群密度图之间的非线性关系,通过用全卷积层替换全连接层,使得模型可以处理任意大小的输入图片.为了进一步修正视角变化带来的影响,MCNN在生成密度图时,没有采用固定的高斯核,而是利用自适应高斯核计算密度图,提升了密度图质量.该工作的另一贡献是收集并标注了ShanghaiTech人群计数数据集,该数据集由1 198张带标注的图像组成,包含人群分布从稀疏到密集变化的各种场景,目前该数据集已成为人群计数领域的基准数据集之一.

Fig.3 The structure of two-column crowd crounting network[34]
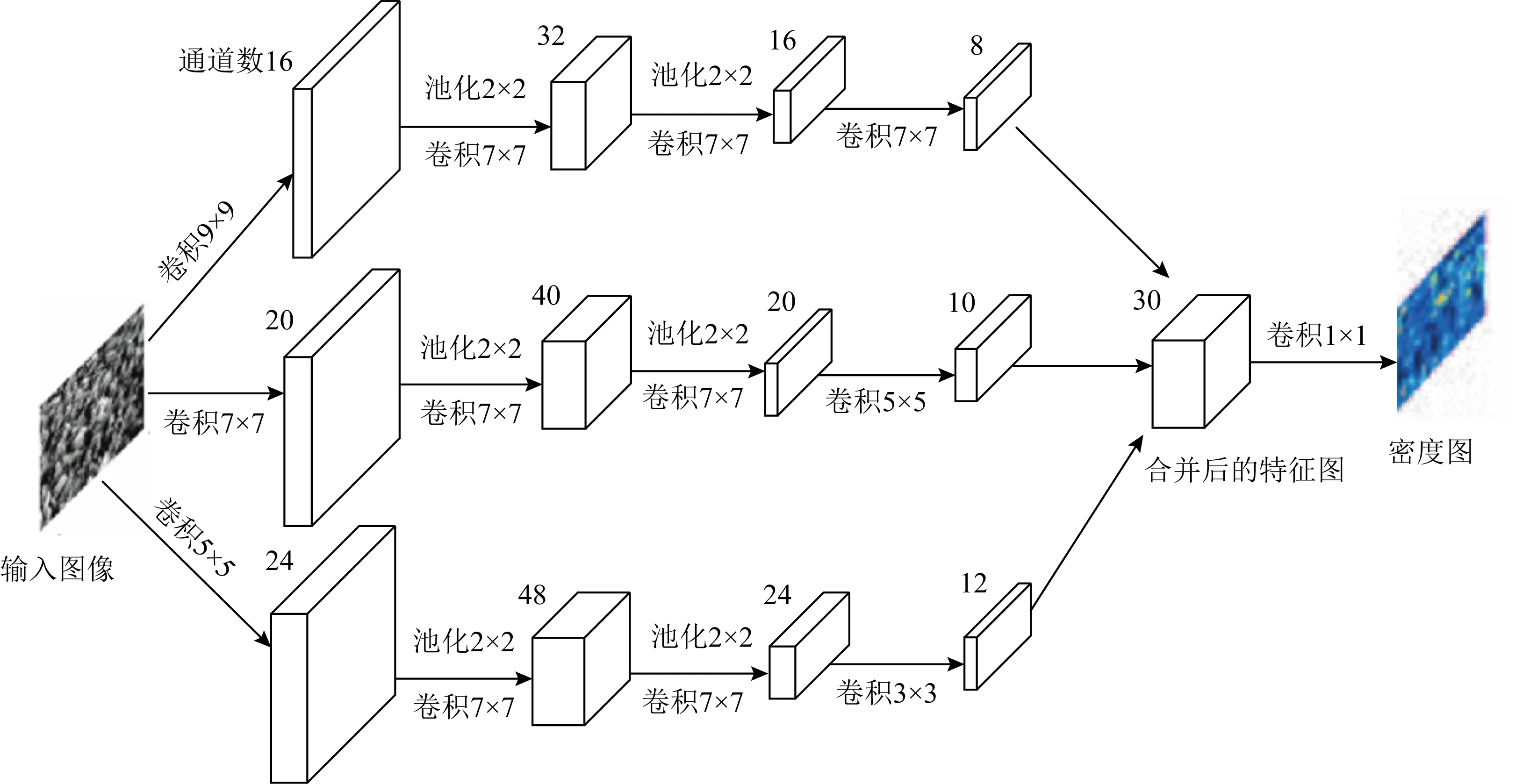
Fig.4 The structure of the multi-column crowd counting network[25]
计数性能的好坏主要依赖于密度图的质量.为了生成更高质量的密度图,Sindagi等人[36]提出了上下文金字塔卷积神经网络计数模型CP-CNN,其结构如图5所示,通过多个CNN获取不同尺度的场景上下文信息,并将这些上下文信息显式地嵌入到密度图生成网络,提升密度估计的精度.CP-CNN由4个部分组成,其中全局上下文估计器(global context estimator, GCE)和局部上下文估计器(local context estimator, LCE)分别提取图像的全局和局部上下文信息,即分别从全局和局部的角度预测图像的密度等级;密度估计器(density map estimator, DME)没有直接生成密度图,而是沿用了MCNN的多列网络结构生成高维特征图;融合卷积神经网络(fusion-CNN, F-CNN)则将前3个部分的输出进行融合,生成密度图.为了弥补DME中丢失的细节信息,F-CNN使用了一系列小数步长卷积层帮助重建密度图的细节.现有的CNN计数网络主要使用像素级欧氏距离损失函数来训练网络,这导致生成的密度图比较模糊.为此,CP-CNN引入对抗损失(adver-sarial loss),利用生成对抗网络(generative adver-sarial net, GAN)[37]来克服欧氏距离损失函数的不足.
2017年,Sam等人[38]提出了一种多列选择卷积神经网络(switch convolution neural network, Switch-CNN)用于人群计数,其结构如图6所示.与MCNN不同之处在于,Switch-CNN虽然采用多列网络结构,但是各列网络独立处理不同的区域.在送入网络之前,图像被切分成3×3的区域,然后对每个区域使用特定的SWITCH模块进行密度等级划分,并根据密度等级选择对应的分支进行计数.通过对于密度不同的人群有针对性地选用不同尺度的回归网络进行密度估计,使得最终的计数结果更为准确.Switch-CNN也存在不容忽视的弊端,如果分支选择错误将会大大影响计数准确度.
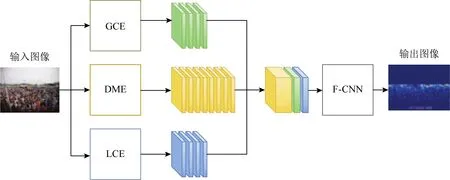
Fig.5 Architecture of CP-CNN[36]
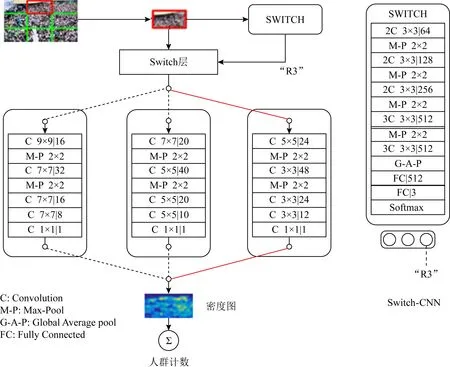
Fig.6 Architecture of Switch-CNN[38]
Switch-CNN根据图像块的内容选择合适的分支网络进行人群密度估计的做法,为设计多列计数网络提供了新思路.但是Swith-CNN将密度等级固定划分为3个层次,难以应对人群密度变化范围很大的场景.为此,Sam等人[39]对Switch-CNN进行改进,提出了逐步增长卷积神经网络(incrementally growing CNN, IG-CNN),其层次化训练过程如图7所示.从一个基础CNN模型(Base CNN)开始,通过不断地迭代,最后生成1棵CNN二叉树,叶子节点即为用于密度估计的回归器,其中每个回归器对应1种特定的密度等级.第1层通过聚类将训练集D0划分成D00和D01这2个部分,然后R00和R01是由复制R0而来,随后R00和R01分别在对应的训练集D00和D01上训练,其他层的构建情况相似.最终通过层次聚类,将原始训练集划分成多个子集,每个子集对应1个密度等级,由相应的密度估计器负责计数.测试阶段则会根据图片的密度等级选择对应的密度估计器.
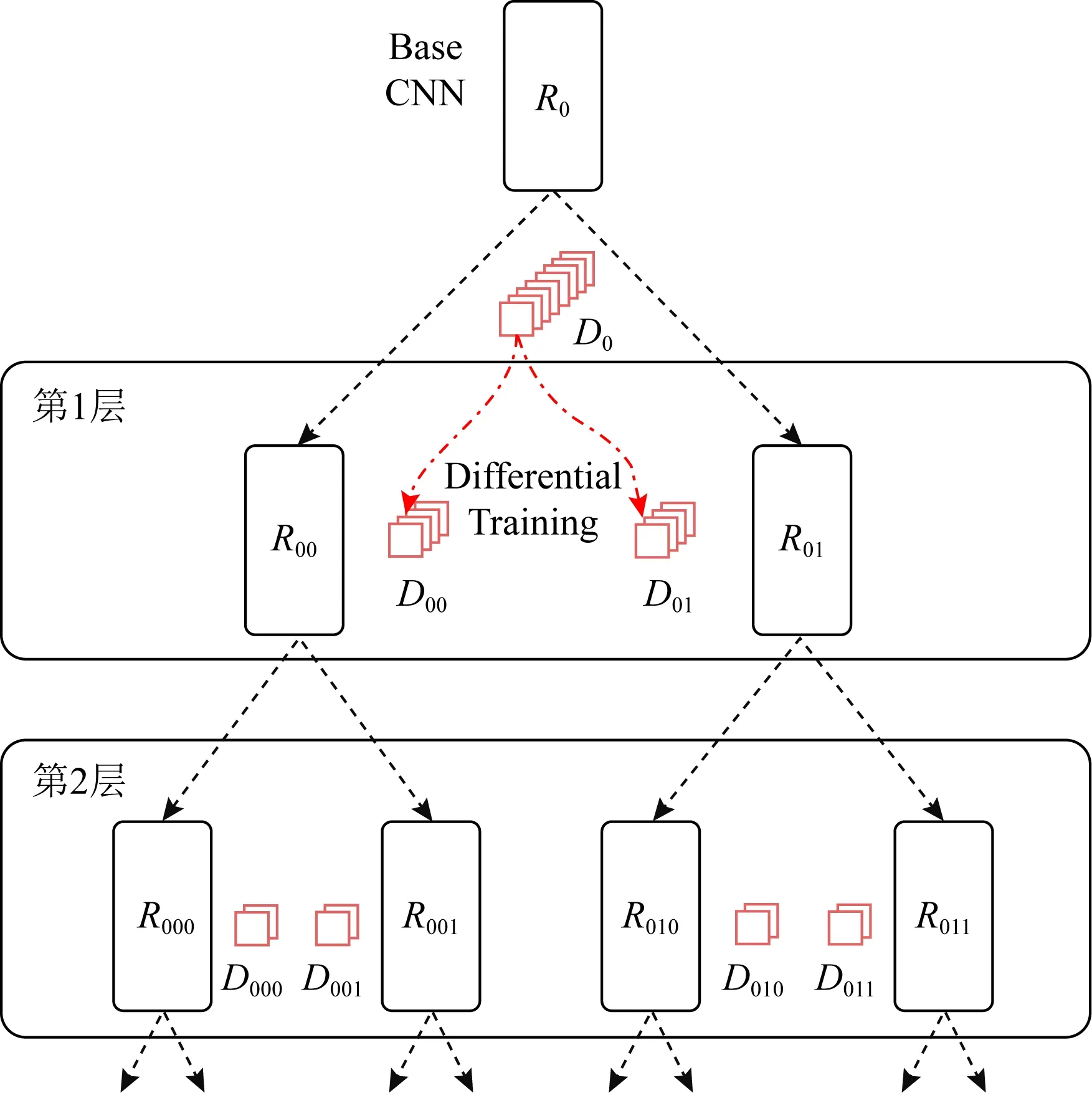
Fig.7 Training process of IG-CNN[39]
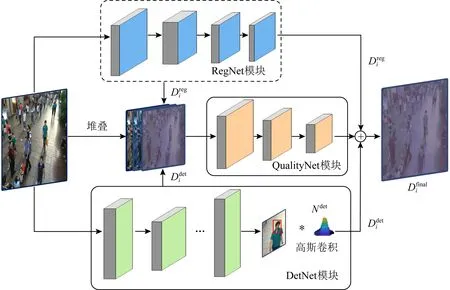
Fig.8 Architecture of DecideNet[41]
在已有的人群计数模型中,通常单纯地假设场景中的人群分布是稀疏或密集的.针对稀疏场景,采用检测方法进行计数[40];而针对密集场景,则采用回归方法进行人群密度估计.这样的模型往往难以应对密度变化范围很广的人群场景的计数.为了解决这个问题,Liu等人[41]提出了一种检测和回归相结合的人群计数模型DecideNet,其结构如图8所示.该模型也是一种多列结构的计数网络,其中RegNet模块采用回归方法直接从图像中估计人群密度,DetNet模块则在Faster-RCNN的后面添加了一个高斯卷积层(Gaussian convolution),直接将检测结果转化为人群密度图,然后QualityNet引入注意力模块,自动判别人群密集程度,并根据判别结果自适应地调整检测和回归这2种方法的权重,再根据这个权重将这2种密度图进行融合,以此获取更好的最优解.但是由于RegNet和DetNet这2个子网络均使用了较大的感受野,模型参数过多,导致该模型的训练复杂度较高.
多列计数网络使用不同大小的卷积核提取图像的多尺度特征,其良好的效果说明多尺度表达的重要性.但是多列计数网络也引入了新的问题,首先多尺度表达的性能通常依赖于网络分支的数量,即尺度的多样性受限于分支数目,其次已有工作大多采用欧氏距离作为损失函数,假设像素之间互相独立,导致生成的密度图比较模糊.
为了解决上述问题,Cao等人[42]提出了一种尺度聚合网络(scale aggregation network, SANet),其结构如图9所示.该模型没有采用MCNN的多列网络结构,而是借鉴了Inception[43]的架构思想,在每个卷积层同时使用不同大小的卷积核提取不同尺度的特征,最后通过反卷积生成高分辨率的密度图.整个模型由FME(feature map encoder)和DME(density map estimator)这2个部分组成,FME聚合提取出多尺度特征,DME融合特征生成高分辨率的密度图.度量预测的密度图与ground-truth的相似度时,采用SSIM计算局部一致性损失,然后对欧氏损失和局部一致性损失进行加权得到总损失.
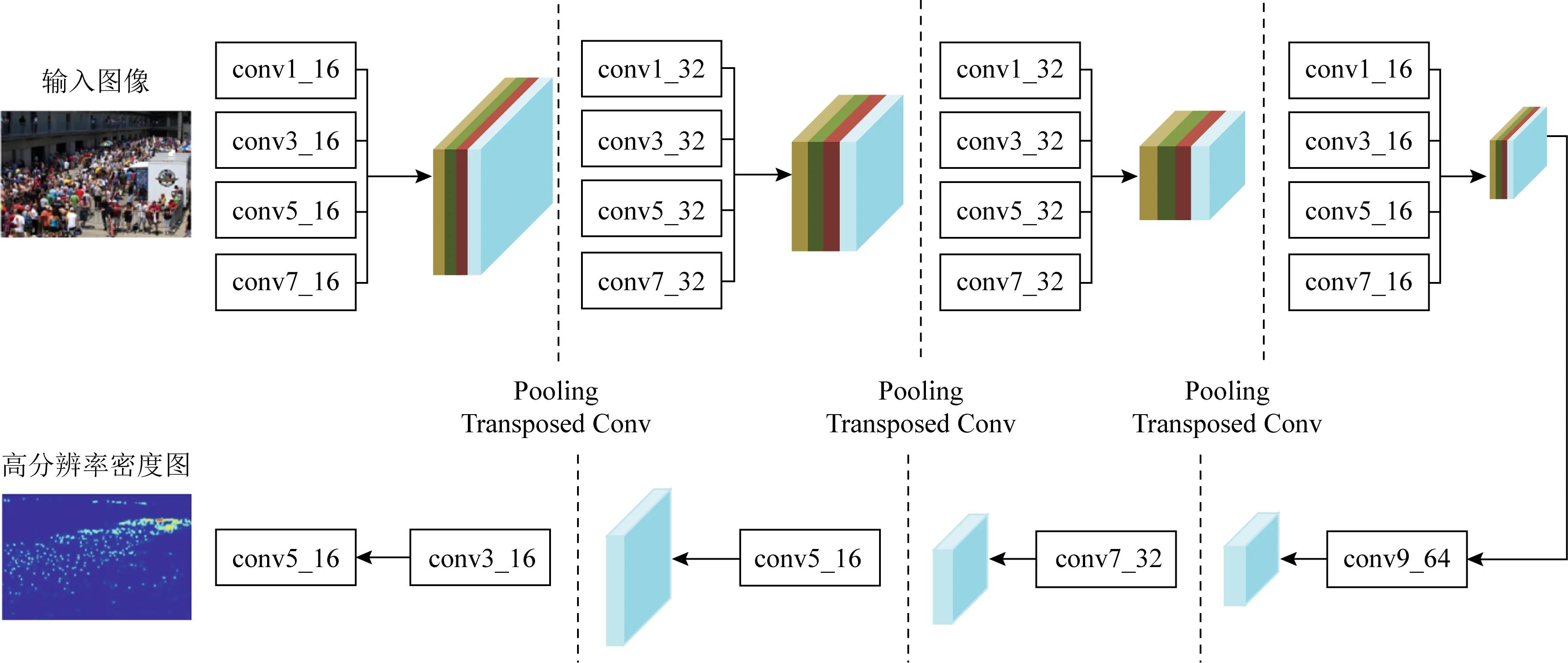
Fig.9 Architecture of SANet[42]
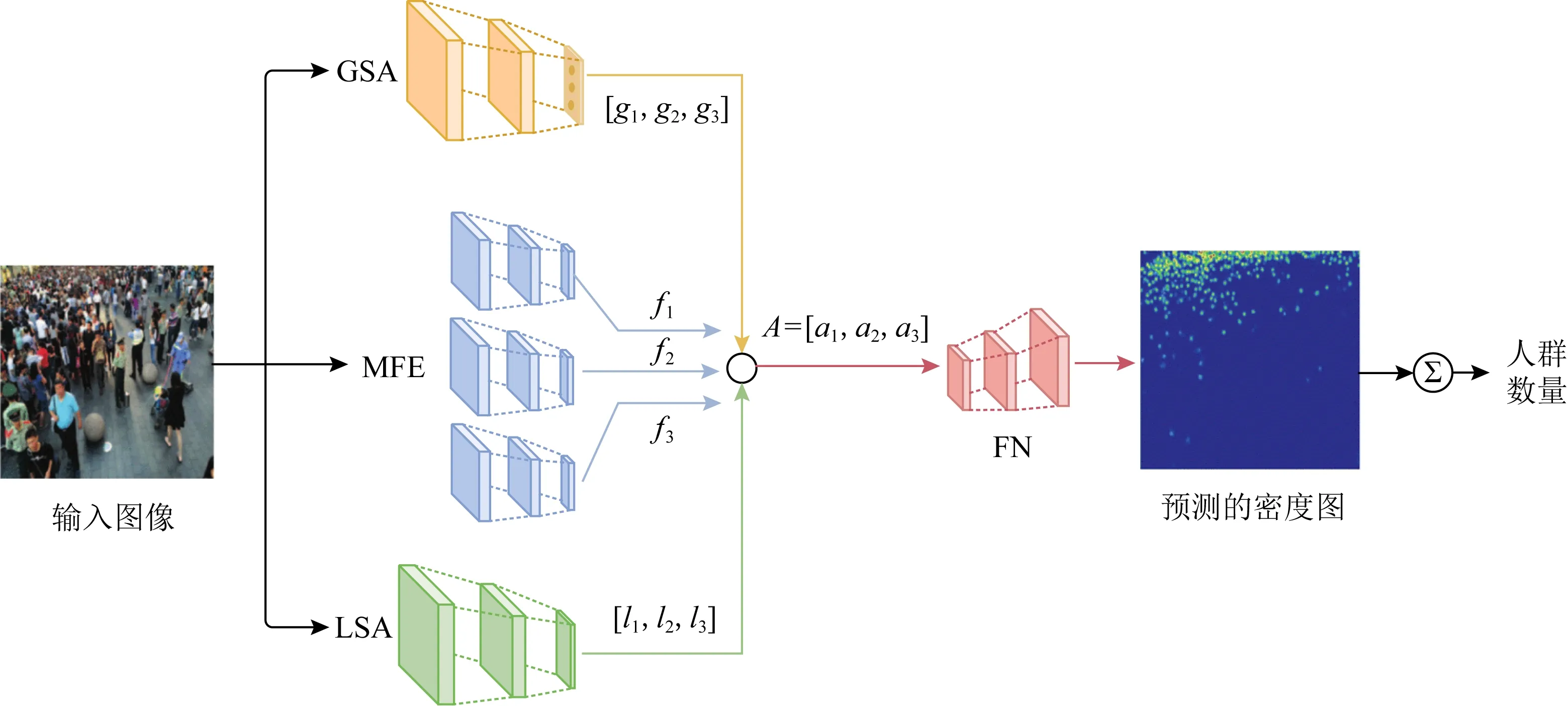
Fig.10 Architectureof SAAN[44]
由于“透视畸变”问题,位于不同景深的目标尺寸差异较大,对人群计数模型的建模能力提出了很高的要求.为了解决这个问题,Hossain等人[44]首次将注意力机制引入人群计数领域,提出了多分支的尺度感知注意力网络(scale-aware attention network, SAAN),其结构如图10[44]所示.该网络由4个模块组成,其中多尺度特征提取器(multi-scale feature extractor, MFE)负责从输入图像中提取多尺度特征图.受到MCNN[25]启发,MFE被设计成包含3个分支的多列网络,每个分支的感受野大小不同,可以捕获不同尺度的特征;为了获得图像的全局密度信息,与MFE中3个不同尺度的分支相对应,定义了3个全局密度等级,然后利用全局尺度注意力(global scale attentions, GSA)模块负责提取输入图像的全局上下文信息,计算3个全局密度等级对应的评分,并对这3个分值进行归一化.GSA只能提取图像的全局尺度信息,但在实际的人群计数图像中,不同位置往往存在密度差异,为此增加了局部尺度注意力(local scale attention, LSA)负责提取图像不同位置的细粒度局部上下文信息,并生成3张像素级的注意力图,用于描述局部尺度信息;最后,根据全局和局部的尺度信息对MFE提取的特征图进行加权,然后将加权后的特征图输入融合网络(fusion network, FN)生成最终的密度图.
与DecideNet[41]相比,SAAN通过注意力机制进行尺度选择的方式更加灵活.但是,由于SAAN包含4个子网络,且MFE包含多个分支,网络模型复杂、参数多、训练难度很大.
1.3 特殊结构计数网络
虽然多分支结构计数网络取得了较好的计数效果,但是多分支结构网络模型的复杂性较高,由此也带来了一些新的问题[45].首先,网络模型参数繁多、训练困难,导致计数实时性较差;其次,多分支网络的结构冗余度较高.多分支计数网络原本是想通过不同的分支采用大小不等的感受野来提取不同尺度的特征,增强特征的适用性和鲁棒性.但研究表明,不同分支学习到的特征相似度很高,并没有因为场景密集程度不同而出现明显差异.为了克服这些问题,研究人员开始尝试将一些新型CNN结构,例如空洞卷积网络(dilated convolutional networks)[46]、可形变卷积网络(deformable convolutional network)[47]、GAN[37]等,引入人群计数领域,以降低计数模型复杂度,提升计数精度和人群密度图的还原度.
2018年,Li等人[45]提出了一种适用于密集人群计数的空洞卷积神经网络模型CSRNet,其网络结构如图11所示.CSRNet没有采用以往广泛使用的多分支网络结构,而是将舍弃了全连接层的VGG-16作为该网络的前端部分,后端则采用6层空洞卷积神经网络,构成一个单通道计数网络,大幅削减了网络参数量,降低了训练难度.同时,借助空洞卷积可以在保持分辨率的同时扩大感受野的优势,保留了更多的图像细节信息,使得生成的人群分布密度图质量更高.CSRNet后端有A,B,C,D这4组不同的配置,其中B组方案在ShanghaiTech PartA数据集上的表现最优.
CSRNet的成功为密集人群计数提供了新的思路,随后许多学者开始效仿采用空洞卷积进行人群计数研究[48].
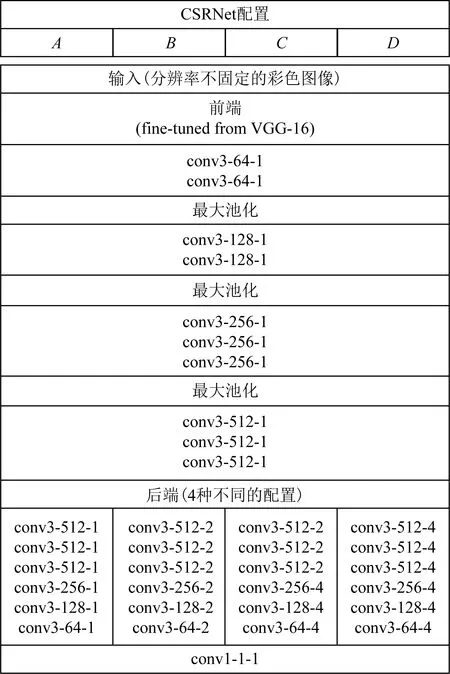
Fig.11 Configuration of CSRNet[45]
多分支计数网络的不同分支之间缺少相互协作,每个分支只是试图通过最小化欧氏损失优化自己的估计.由于每个分支只在特定尺度上表现良好,导致平均各分支结果后生成的密度图较模糊,同时由于在网络中使用池化层,大大降低了密度图的分辨率,使得最终的计数结果产生误差.此外,存在跨尺度统计不一致问题,一个图像分割成多份分别输入网络得到的总人数和将输入整张图像计算得出的人数存在差异.
为解决这些问题,受GAN在图像翻译方面[49]成功应用的启发,文献[50]提出了一种基于GAN的跨尺度人群计数网络(adversarial cross-scale consis-tency pursuit network, ACSCP),其结构如图12[50]所示.对抗损失的引入使得生成的密度图更加尖锐,U-Net 结构[51]的生成器保证了密度图的高分辨率,同时跨尺度一致性正则化约束了图像间的跨尺度误差.因此,该模型最终能生成质量好、分辨率高的人群分布密度图,从而获得更高的人群计数精度.
利用GAN来提高人群计数精度的方法,开启了一种新的思路.在SFCN[52]计数网络中,使用了改进的Cycle GAN[53]产生数据集风格相似的图片,并贡献了GCC数据集.DACC[54]中也使用Cycle GAN进行风格迁移.
基于深度神经网络的人群计数解决方案虽然取得了显著成果,但在高度拥挤嘈杂场景中,计数效果仍然会受到背景噪音、遮挡和不一致的人群分布的严重影响.为了解决这个问题,Liu等人[55]提出了一种融合了注意力机制的可形变卷积网络ADCrowdNet用于人群计数.如图13[55]所示,该网络模型主要由2个部分串联而成,其中注意力图生成器(attention map generator, AMG)用于检测人群候选区域,并估计这些区域的拥挤程度,为后续人群密度图的生成提供精细化的先验知识.通过注意力机制,可以过滤掉复杂背景等无关信息,使得后续工作只关注人群区域,降低各种噪声的干扰.密度图估计器(density map estimator, DME)是一个多尺度可形变卷积网络,用于生成高质量的密度图.由于注入了注意力,可形变卷积添加了方向参数,卷积核在注意力指导下在特征图上延伸,可以对不同形状的人群分布进行建模,很好地适应了真实场景中摄像机视角失真和人群分布多样性导致的畸变,保证了拥挤场景中人群密度图的准确性.

Fig.12 Architecture of ACSCP[50]

Fig.13 Architecture of ADCrowdNet[55]
注意力图生成器AMG的网络结构如图14所示,采用了VGG-16网络前10个卷积层作为前端(front end),用来提取图像的底层特征,后端(back end)架构类似Inception结构[43],采用多个空洞率不同的空洞卷积层[56]扩大感受野,应对不同尺度的人群分布.后端输出2通道的特征图Fc和Fb,分别代表前景(人群)和背景.然后,通过对特征图取全局平均池化GAP获得相应的权重Wc和Wb,再对其结果用softmax进行分类获取概率Pc和Pb.最后,对特征图和概率进行点乘获得注意力图.
密度图估计器DME的网络结构如图15所示,前端依然使用VGG-16,后端架构依然类似inception结构,但是采用了更适合拥挤嘈杂场景的多尺度可形变卷积,以适应人群分布的几何形变.
同年,DADNet[57]也同样使用可形变卷积进行人群计数,取得了较好的计数效果.

Fig.14 Architecture of attention map generator
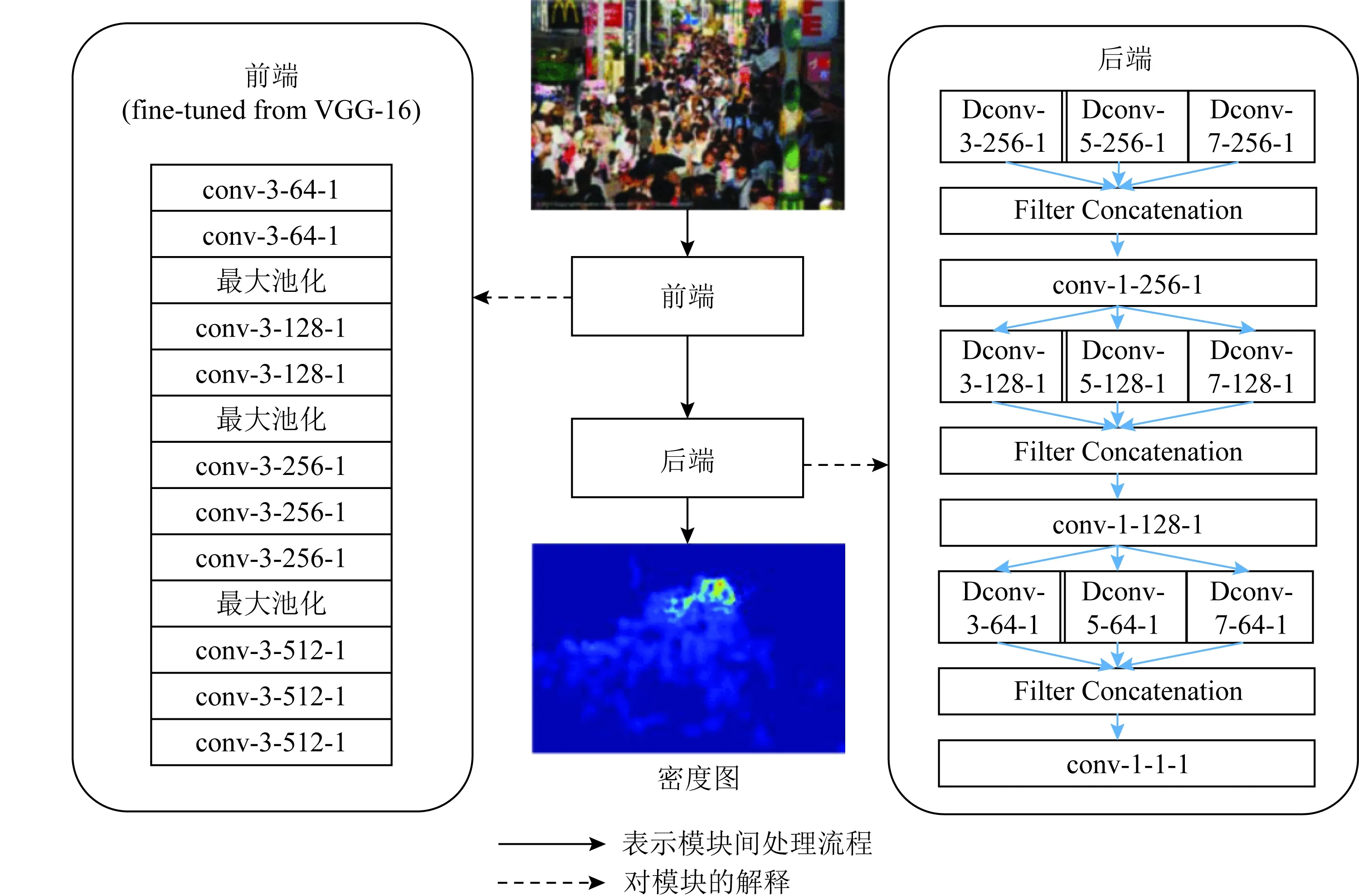
Fig.15 Architecture of density map estimator
背景噪声会对人群计数算法的性能带来重大影响.为了减少背景噪声干扰,许多学者进行了尝试,例如ADCrowdNet通过注意力机制,过滤掉背景,让模型只关注人群区域.此外,也有学者试图将图像分割技术MASK R-CNN[58]应用于人群计数领域,以去除背景噪声.
实现背景和人群分割的难点在于如何制作用于分割的ground truth.为此,研究者们进行了各种尝试,SFANet[59]采用了将原本的坐标点ground truth进行固定高斯核大小的高斯模糊,再选取一定阈值对其进行0和1的二值化,由此形成分割ground truth;MAN[60]采用了固定高斯核对原本坐标点ground truth进行处理,并将非0值全置为1,形成分割ground truth;W-Net[61]则采用SANet[42]中的归一化高斯核方法对坐标点图进行高斯模糊,再设置一定的阈值进行二分类;SGANet[62]采用每个人头使用25×25的方格表示,以此制作ground truth.
总之,如何降低背景噪声干扰仍然是人群计数领域未来需要重点关注的问题.除了以上结合分割算法的人群计数算法以外,CFF[63]将分割任务、分类任务、计数任务结合,为我们提供了多任务结合的思路.
由分析可知,随着研究的深入,计数模型的结构在不断发生变化.为了解决多尺度问题,计数网络从最初简单的单分支结构演变为复杂的多分支结构,使得计数准确性得到了提升.但是多分支结构会带来了网络参数量大、计算复杂度高等问题,导致计数模型的效率低下.为了克服这些问题,研究人员在设计时又试图重新回归简单的单分支网络结构,通过引入各种新型CNN技术来降低模型复杂度,同时提升计数精度.因此,减少分支数量,让计数模型既简单又有效,将是未来模型网络结构的设计方向.
此外,从分析中可知,注意力机制、空洞卷积、对抗生成网络、可形变卷积等CNN技术可以解决计数领域存在的多尺度、复杂背景干扰等问题,帮助提升密度图质量.因此,未来在设计网络时,可以考虑结合这些技术提升计数精度.
2 人群计数损失函数
损失函数的作用是评价模型的预测值与真实值ground-truth的一致程度,是模型训练中不可缺少的一部分.损失函数值越小,说明预测值越接近真实值,则模型的计数性能越好.在人群计数任务中,通过定义损失函数,可以将人群密度图的映射关系学习转化为一个最优化问题.常用的人群计数损失函数包括欧氏损失、结构相似性损失等.神经网络训练的目的就是是找到使损失函数值最小的网络参数值.
2.1 欧氏距离损失
早期绝大多数基于密度图进行人群计数的工作,例如跨场景计数模型[24]、MCNN[25]、CrowdNet[34]、Switch-CNN[38]、CSRNet[45]等方法,均采用像素级的欧氏距离作为模型损失函数,度量估计密度图与真实密度图之间的差距:
(1)
其中,F(Xi;θ)是参数为θ的映射函数,它将输入图像Xi映射到预测密度图,Fi是真实密度图,N为训练样本个数.
由于欧氏距离损失简单、训练速度快,且计数效果较好,早期得到了较为广泛的应用.但是欧氏距离损失的鲁棒性较差,很容易因为个别像素点的极端情况而影响整体的计数效果.此外,欧氏距离损失是取所有像素点的平均,并不关注图片的结构化信息.对于同一张图片,容易出现人群密集区域预测值偏小,而人群稀疏区域预测值偏大的问题,但是最终的平均结果却没有体现这些问题,从而导致生成的密度图模糊、细节不清晰.
2.2 结构相似性损失
由于欧氏距离损失不足以表达人的视觉系统对图片的直观感受,导致生成的密度图质量不高.为了克服欧氏距离损失的不足,SANet[42]提出了以结构相似性指标(structual similarity index)[31]为基础的结构相似性损失来度量密度图的质量.结构相似性指标是由Wang等人[31]提出的一种图像质量评价标准,记为SSIM.不同于基于像素的误差评价标准,SSIM从图像的亮度、对比度和结构这3个方面度量图像相似性,并通过均值、方差、协方差3个局部统计量计算2张图像之间的相似度.SSIM的取值范围在-1~1之间,SSIM值越大,说明相似度越高.结构相似性指标SSIM的计算方法为
(2)
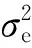
(3)
其中,N代表密度图的像素点数量,X是生成密度图与真实密度图相同像素点位置对应的图像块集合.
实验表明,结构相似性损失确实可以提高生成密度图质量,相比于关注像素间差异的欧氏距离损失,结构相似性损失能够更好地关注图像间对应局部块的差异,从而更好地生成密度图.在后续的研究中,计数模型SFCN[52]也采用了类似的做法.
为了进一步提高计数精度,许多学者对结构相似性损失进行改进.DSSINet[64]将空洞卷积融入结构相似性度量中,构建了一个空洞卷积网络DMS-SSIM用于计算结构相似性损失LSSIM.通过扩大SSIM指标的感受野,每个像素点可以融合多尺度信息,使得在不同尺度下,可以输出局部区域的高质量密度图.
思想道德修养与法律基础课程的设置主要是对大学生进行社会主义道德教育和法制教育。在不改变课程属性和课程内容前提下,从课程设计的主线、内容的排序、课程载体及考核等方面借鉴工作过程系统化设计课程。将原本课程章节组合设置为4大专题,如,“大学新生变形记”,“爱己、爱他(她)、爱家庭、爱工作岗位、爱自然、爱国家”系列专题,结合当前现实生活热点案例设置为“×××案例之我见”与“我的道德践行录”。因此,课程考核可从网络教学、课堂教学、实践教学3个方面进行。
2.3 生成对抗损失
基于密度图的人群计数方法通常以单张静态的人群图像作为输入,然后输出1张与输入图像对应的人群密度图,这一目标本质上可视作一个图像转换问题(image-to-image translation).GAN[37]为解决图像转换问题提供了一个可行的思路,即可以通过生成网络和判别网络的不断博弈,进而使生成网络学习人群密度分布,生成密度图的质量逐渐趋好;判别网络也通过不断训练,提高本身的判别能力.损失函数作为生成对抗网络的关键,对于生成对抗网络训练、求解最优值的过程尤为重要.在人群计数领域,可以使用对抗损失函数,通过对抗的方式对生成图片进行矫正,由此避免出现密度图模糊问题.
CP-CNN[36]网络在欧氏距离损失的基础上,增加了生成对抗损失,提高了预测密度图的质量,其损失函数为
LT=LE+λaLA,
(4)
(5)
LA=-log(φD(φ(X))),
(6)
其中,LT是总损耗,LE是生成密度图与对应的真实密度图之间的像素级欧氏损失,λa是权重因子,LA是对抗性损失,X是尺寸为W×H的输入图像,Y是ground truth密度图,φ是由DME和F-CNN组成的网络,φD是用于计算对抗损失的鉴别子网络.
在之后的人群计数算法研究中,对抗损失屡见不鲜.ACSCP[50]网络采用U-Net作为密度图生成器,并使用了对抗损失,可定义为
LA(G,D)=Ex,y~Pdata(x,y)[logD(x,y)]+
Ex~Pdata(x)[log(1-D(x,G(x)))],
(7)
其中,x表示训练块,y表示相应的ground truth.G是生成网络,D是判别网络,G试图最小化这个目标函数,而D试图将其最大化,通过判别网络与生成网络的一种联合训练得到最终的模型.RPNet[65]采用了一种对抗结构来提取拥挤区域的结构特征.
对抗损失对于密度图质量的提升有着显著作用,但对抗损失也有着难以训练的缺点.除这3种损失外,人群计数任务使用的损失函数还有很多,例如人群统计损失,但是每个损失函数各有优缺点,因此实际应用中,常常会联合多种损失,共同构建一个综合性的损失函数.
对于人群计数任务来说,密度图质量的优劣将直接影响计数性能.现有的损失函数虽然可以生成密度图,但是仍有许多亟待改进的地方.未来如何定义新的损失函数,以生成高质量的密度图也是该领域的一个研究重点.
3 ground-truth密度图生成方法
为了训练计数网络,需要对人群图片中的目标进行标注.常见的做法是为图片中的每个人头标注中心坐标,然后再利用高斯核将坐标图转化为ground-truth人群密度图.ground-truth密度图质量的高低,直接影响网络的训练结果.优质的ground-truth能使网络更好地学习到人群图片特征,计数网络的鲁棒性和适应性也会更好.近年来对ground-truth生成方法的研究从未停止过,ground-truth密度图生成的关键在于如何选择高斯核,设置不同的高斯核对网络性能的影响很大,常用的3种高斯核设置方法为:
1)几何自适应法

Fig.16 Geometric adaptive method[25]
2)固定高斯核法
该方法忽略了人头尺寸差异,以及自身与邻居的相似性,无论图片中哪个位置的人头均采用方差大小固定的高斯核对每个人头进行高斯模糊,采用固定高斯核的算法有CP-CNN[36],其生成的ground-truth密度图如图17[36]所示.固定高斯核法解决了几何自适应法中的近处人头消失的问题,但是由于高斯核大小固定,对于远处人头来说,高斯核尺寸可能过大,使得远处人头出现重叠,降低了密度图质量.
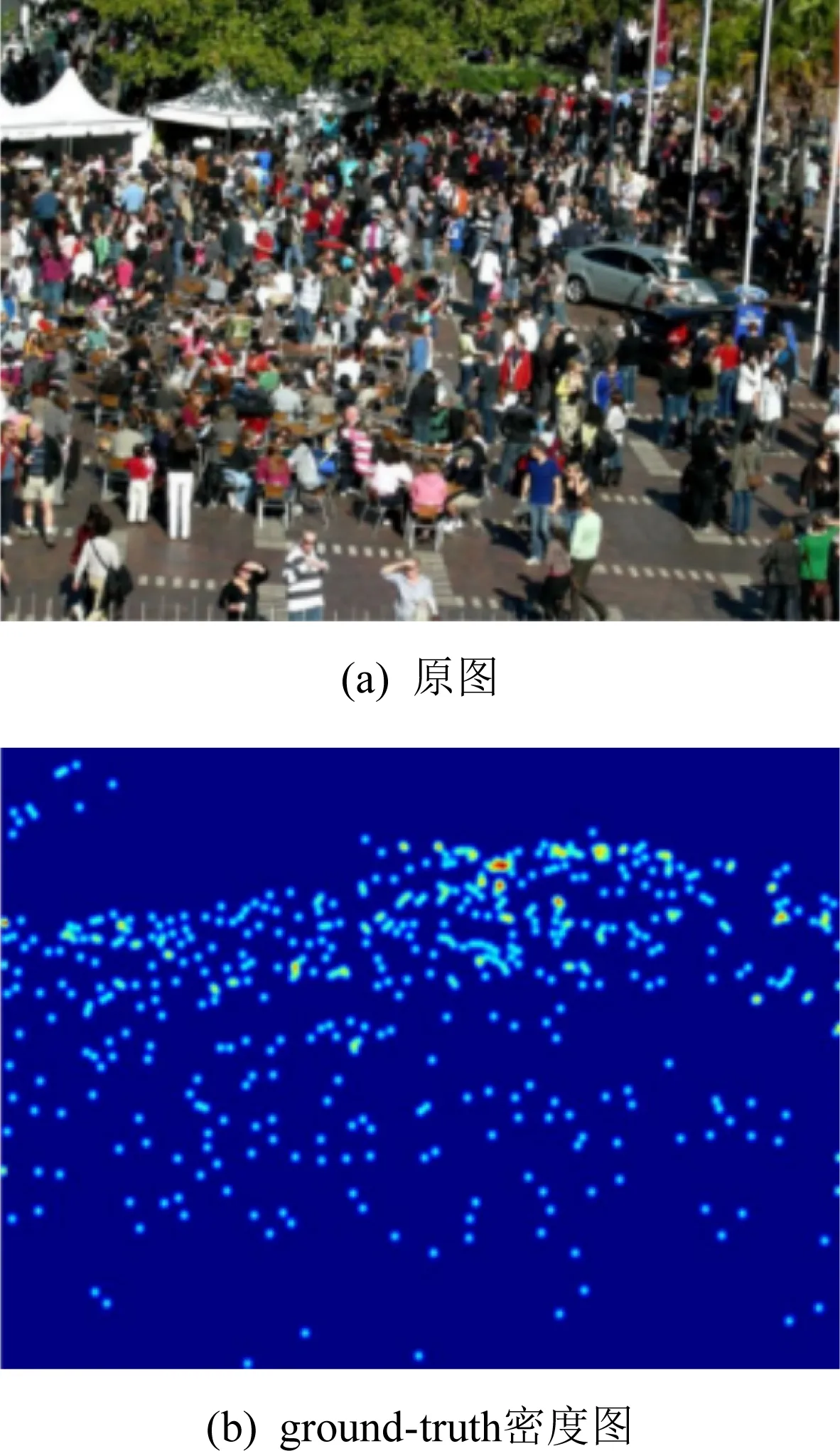
Fig.17 Fixed Gaussian kernel method[36]
3)内容感知标注法
为解决方法1)2)存在的问题,Oghaz等人[66]提出了一种通过内容感知标注技术生成密度图的方法.首先,用暴力最近邻(brute-force nearest neighbor)算法定位最近的头部,再用无监督分割算法Chan-Vese分割出头部区域,然后依据邻居头部的大小计算高斯核尺寸,其生成的密度图如图18[66]所示.该方法也是根据邻居情况灵活确定高斯核大小,但是与几何自适应法相比,它采用brute-force最近邻算法替代k-d树空间划分法(k-d tree space partitioning approach)来寻找最近邻,这样能确保寻找结果与实际相符.

Fig.18 Content-aware annotation method[66]
总之,高质量密度图是人群计数算法成功的基础和关键,因此ground-truth的生成方法将是人群计数领域未来的一个研究重点.
4 评价指标
为了对不同模型的准确率以及鲁棒性进行测评,需要有合适的评价指标.在人群计数领域,常用的评价指标有均方误差(mean squared error,MSE)、平均绝对误差(mean absolute error,MAE)和均方根误差(root mean squared error,RMSE),具体定义为

(8)
(9)
(10)
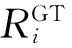
MSE和RMSE可以反映模型的鲁棒性,而MAE可以反映模型的准确性.通过对各个人群计数模型的评价指标MSE,MAE,RMSE的比较,可以评定各个计数模型的性能.
由于上述评价指标存在一定的局限性,很多研究人员进行了不同的改进,以适应不同的评价需求.例如,原始的MSE,MAE,RMSE只能度量全局鲁棒性和准确性,无法评价局部区域的计数性能,因此Tian等人[67]将MAE和RMSE扩展成块平均绝对误差(patch mean absolute error,PMAE),和块均方误差(patch mean squared error,PMSE),用于评价局部区域的计数效果.此外,对于基于密度图的人群计数算法来说,密度图质量高低对算法性能优劣具有决定性作用,因此也可以采用已有的图像质量评价指标来衡量计数模型的性能.
5 人群计数数据集
随着人群计数算法研究的不断推进,该领域数据集的丰富性和针对性在逐步提高,图片数量以及质量也在进一步提升.表1按照时间顺序列举了具有代表性的人群计数数据集,不仅包括早期创建的经典人群计数数据集,也包括近年来新出现的数据集.这些数据集在拍摄视角、场景类型、平均分辨率、图像数量、每张图像所标注的目标数量等方面各有不同,总体呈现多样化特点.分2个部分对数据集进行简要介绍.

Table 1 Crowd Counting Datasets
5.1 经典人群计数数据集
本节主要介绍早期的经典人群计数数据集,包括WorldExpo’10[24,70],ShanghaiTech[25],UCSD[68],Mall[69],UCF_CC_50[21],它们经常被看作是验证计数算法有效性的基准数据集,在近几年的人群计数算法研究中应用最为广泛[81].其中,UCSD,Mall,WorldExpo’10,ShanghaiTech PartB主要针对人群稀疏场景,UCF_CC_50和ShanghaiTech PartA则主要针对人群密集场景;在数据量方面,WorldExpo’10,UCSD,Mall的数据量较大;UCSD,Mall,World-Expo’10,ShanghaiTech PartB数据集图片的分辨率是固定的,其他2个数据集中的图像分辨率是随机变化的.
数据集UCSD和Mall中的图像均来自相同的视频序列,在图像之间不存在视角变化.而其他经典数据集的图像样本来自不同的视频序列,视角和人群尺度的变化较大.表2~7通过度量准确性的MAE和度量鲁棒性的MSE这2个评价指标,比较了不同计数算法在各种经典人群计数数据集上的表现,分析了算法表现优劣的原因.所有实验数据均来自算法相关的参考文献.
UCSD数据集[68]是最早创建的人群计数数据集之一.包含2 000帧从人行道视频监控中采集的图像,每帧的分辨率为238×158.每隔5帧人工标注1次,其余帧中的行人位置则使用线性插值方式创建,最终标注了49885个行人目标.该数据集的人群密度相对较低,平均1帧约15人,由于数据是从一个位置采集的,场景和透视角度单一.
表2列出了不同计数网络在UCSD数据集上的实验结果,由表可知,随着时间推移,算法性能在不断提升.评价指标MAE和MSE排名前3的算法分别是E3D[82],PACNN[83],PaDNet[67].其中,PaDNet提出了针对不同密度人群进行计数的泛密度计数方法;E3D中最主要的创新是结合了3D卷积核来编码局部时空特征,该网络主要针对视频中的人群计数,但在图像数据集上依然取得了良好的性能;PACNN将透视信息集成到密度回归中,以方便融合目标比例变化相关的特征.其次,考虑了局部注意力的网络ADCrowdNet以及考虑尺度多样性的计数网络MCNN,SANet,ACSCP等性能表现均较好.由此分析可知,对于较为稀疏的人群场景,场景的尺度多样性是最应该考虑的要素,而且将局部信息作为额外的辅助信息,将有助于提升计数性能.

Table 2 Comparison of Crowd Counting Networks on UCSD
Mall数据集[69]是由安装在购物中心的监控摄像头采集而来,共包含2 000帧分辨率为320×240的图像样本,标注了行人目标6 000个,前800帧用于训练,剩余1 200帧用于测试.该数据集场景复杂,人群密度以及光照条件差异较大,而且图像存在严重的透视畸变,目标的表观特征和尺度差异较大.与UCSD数据集相比,Mall数据集的人群密度相对较高,然而这2个数据集由于都在固定地点拍摄,所以均存在场景单一的问题,无法反应室内场景的实际状况.此外,该数据集还存在由场景对象,例如摊位、植物等,引起的严重遮挡,这一特性增加了人群计数的难度.
表3列出不同计数网络在Mall数据集上的运行结果.其中按照MAE和MSE排名,表现最好的算法包括DecideNet[41],DRSAN[90],E3D[82],SAAN[44].其中,SAAN网络利用了多尺度注意力机制;E3D考虑了局部时空特征;DecideNet中有检测分支,更加关注局部信息;DRSAN主要是通过区域精细化过程自适应地解决了可学习的空间变换模块中的2个问题,来更好地适应摄像机的不同视角变化,这种方法很好地考虑到了图片中不同人群的尺度特征.
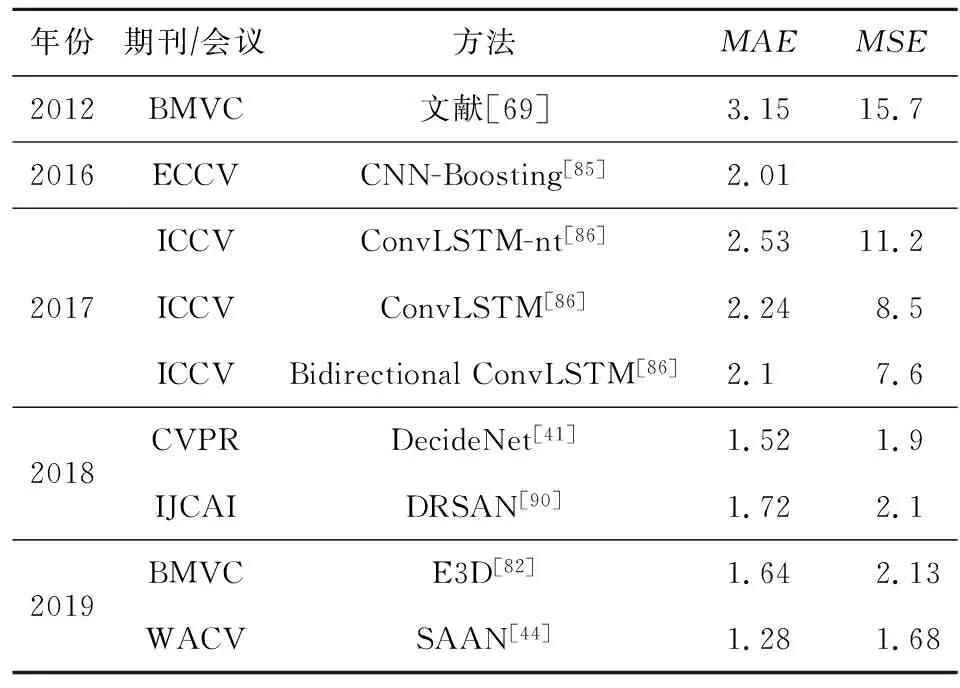
Table 3 Comparison of Crowd Counting Networks on Mall
相较于其他数据集,Mall与UCSD这2个数据集的人群密度均较小.由这2个数据集中各模型的实验结果可得,对于较为稀疏的场景,我们应该更关注人群局部特征和多尺度特征,而空洞卷积在稀疏场景的效果并没有特别突出.
MCNN网络在提出多阵列网络结构的同时,还创建了人群计数数据集ShanghaiTech.该数据集包含1 198张图片,分为partA和partB这2个部分,共标注了330 165个头部位置.人群分布较为密集的PartA包含300张训练图片,182张测试图片,图像分辨率是变化的;人群分布较为稀疏的PartB包含400张训练图片,316张测试图片,图像分辨率固定不变.总体上看,在ShanghaiTech数据集上进行精确计数是具有挑战性的,因为该数据集无论是场景类型,还是透视角度和人群密度都变化多样.
表4和表5为各计数网络在ShanghaiTech PartA和Part B上的运行结果.在PartA上,性能表现较好的网络包括SPANet+SANet,S-DCNet,PGCNet,ADSCNet.其中,SPANet将空间上下文融入人群计数,并与考虑尺度特征的SANet相结合,得到的模型拥有很好的鲁棒性;S-DCNet是一种空间分而治之的网络,通过获取局部特征来实现图片整体的计数;PGCNet克服了由于透视效应而产生的场景尺度变化,获得了较好的计数性能;ADSCNet提出了一种具有自我校正监督的自适应空洞网络计数算法,对空洞卷积进行改进,使其可以根据图片场景及尺度变换而自适应地选择不同的空洞卷积.PartB部分去除了PGCNet网络,增加了DSSINet网络的比较.该网络引入了基于空洞卷积的结构化损失,能更好地体现图片中的局部损失.

Table 4 Comparison of Crowd Counting Networks on ShanghaiTech Part A
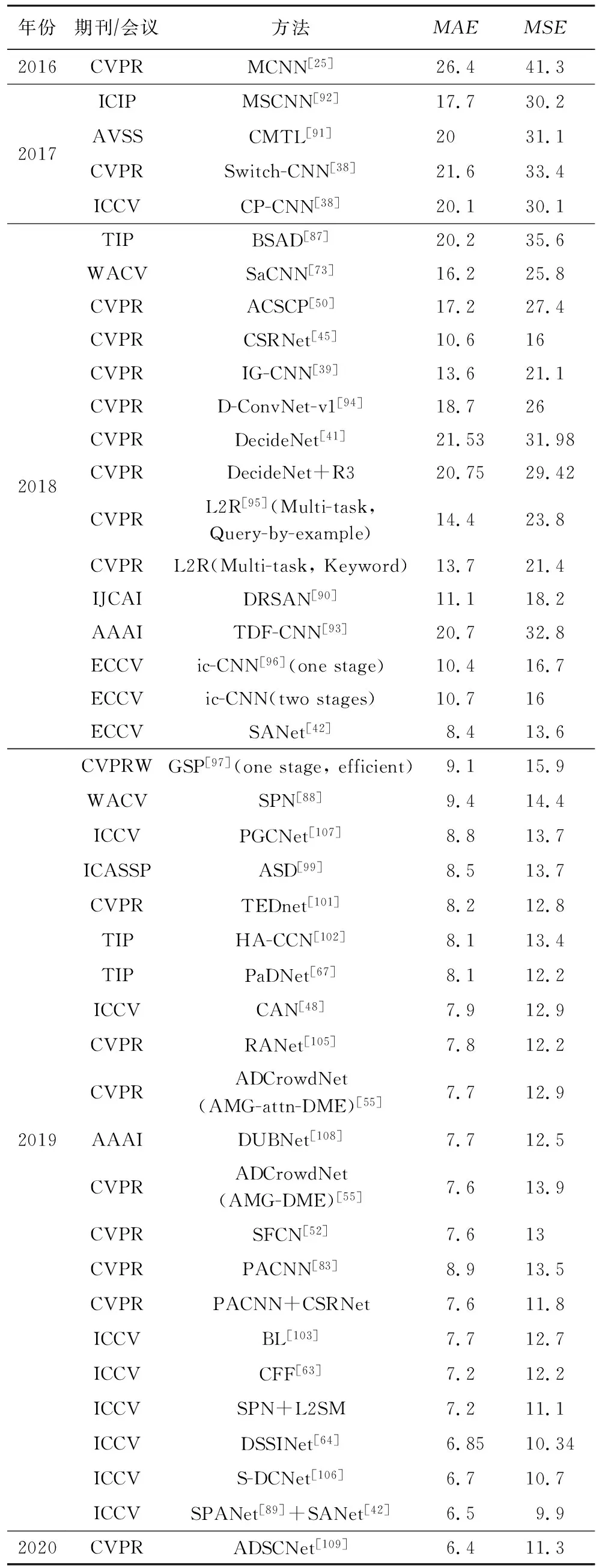
Table 5 Comparison of Crowd Counting Networks on ShanghaiTech Part B
由数据对比可知,稀疏场景的人群计数效果明显优于密集场景的人群计数效果.因此,在未来的研究中,密集场景人群计数将依然是该领域的研究重点.
UCF_CC_50数据集是第1个真正意义上具有挑战性的大规模人群计数数据集.包含了50张不同分辨率的图片,内容涵盖了音乐会、抗议活动、体育场和马拉松比赛等不同场景.整个数据集中共标注了63 075个头部位置,其中每张图片包含的人数从94到4 543不等,密度等级变化极大.
表6是不同计数网络在UCF_CC_50数据集上的运行结果.在性能指标MAE和MSE上排名前4的方法包括PaDNet,SPN+L2SM,ASD,CAN,其中PaDNet表现最好,其采用的融合图像不同密度的泛密度方法恰好适用于UCF_CC_50这种人群密度变化范围较广的数据集;SPN提出了一个比例金字塔网络(SPN),该网络采用共享的单个深列结构,并通过尺度金字塔模块提取高层的多种尺度信息,其与L2SM结合,更加关注于人群多尺度信息;ASD是一个场景自适应框架,能够更好地对可变人群场景进行计数;CAN采用了空间金字塔池化结构处理人群多尺度特征,在此数据集上获得了较好的鲁棒性.
由表6和分析可得,空洞卷积和多尺度网络在此数据集上的表现效果更好.相比UCSD,Mall,ShanghaiTech,UCF_CC_50这4个数据集的效果,Switch-CNN网络的性能提升明显,而UCF_CC_50数据集的场景更为复杂,由此可得,Switch结构增加了模型的鲁棒性,多阵列模型的效果明显好于单列计数网络模型.
早期的人群计数方法主要关注单一场景的计数问题,导致模型跨场景计数性能较差,为此Zhang等人构建了采集于上海世界博览会的人群计数数据集WorldExpro’10.该数据集由108个监控探头采集的1 132个视频序列组成,通过从不同位置的摄像头采集数据,确保了场景类型的多样性.其中,3 980帧图像进行了人工标注,每帧的分辨率为576×720,总共标注了199 923个目标位置.该数据集被划分为2个部分,来自103个场景的1 127个视频序列作为训练集,其余5个场景的数据作为测试集.每个测试场景由120个标记帧组成,观众数量从1~220不等.虽然尝试捕捉不同密度级别的场景,但在测试集中,多样性仅限于5个场景,人群数量最大被限制在220个.因此,该数据集不足以评估为极端密集场景设计的人群计数算法.
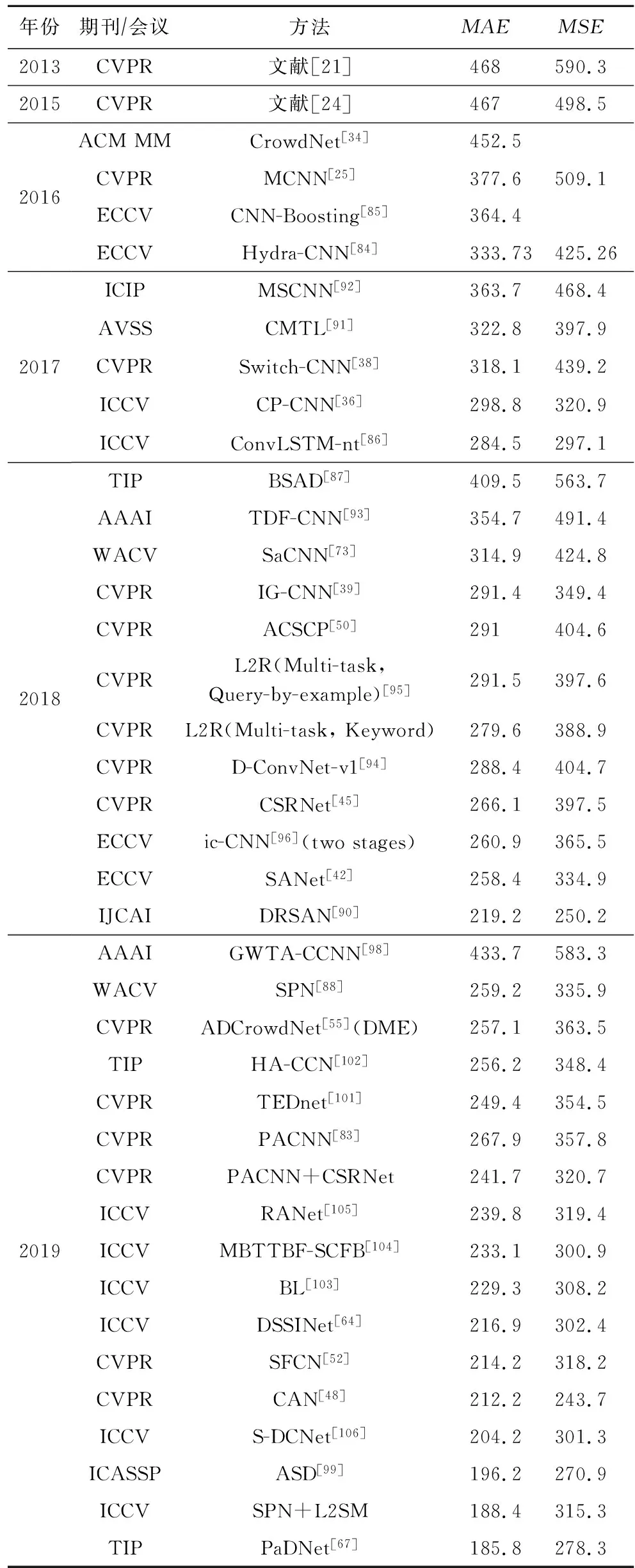
Table 6 Comparison of Crowd Counting Networks on UCF_CC_50
表7列出了不同计数网络在WorldExpo’10数据集上的MAE值.其中,采用融入空洞率的结构性损失的网络DSSINet的平均性能最好;融合了图像上下文信息的CP-CNN和CAN网络对于多角度、多尺度场景的效果较好;在S2,S3,S5场景中,空洞卷积的表现都是最好;此外,包含空洞卷积和可形变卷积的ADCrowdNet在S4场景下得到了很好的计数效果;加入透视引导卷积(PGC)的网络PGCNet在场景S3上获得很好的效果,可见尺度信息对于场景S3的重要性.由分析可知,在人群相对稀疏的场景下,空洞卷积可以在不同场景下取得很好的效果,结构性损失在多个场景的计数中都表现良好.

Table 7 Comparison of Crowd Counting Networks on WorldExpo’10
5.2 其他人群计数数据集
本节主要介绍近几年新出现的人群计数数据集,包括DISCO[80],NWPU-Crowd[78],UCF-QNRF[72],JHU-CROWD++[79]等.这些数据集的出现在一定程度上缓解了经典数据集存在的场景单一、图像质量不高、数据规模过小等问题.
CityUHK-X[71]是由香港城市大学VISAL实验室创建的人群计数数据集,包含来自55个场景的3 191张图片,其中训练集由来自43个场景的2 503张图片构成,共标注了78 592个实例;测试集则由来自12个场景的688张图片构成,共标注了28 191个实例.该数据集的特色在于将拍摄角度和高度作为场景上下文辅助信息,然后卷积核权重随之自适应变化,以提升计数准确性.
UCF-QNRF[72]数据集具有场景丰富,视角、密度以及光照条件均变化多样的特点,是一个非常具有挑战性的人群计数数据集.它共包含1 535张密集人群场景图片的数据集,其中训练集1 201张图像,测试集334张图像,共有1 251 642个目标被标注,由于标注数量众多,该数据集适合采用深度卷积神经网络进行训练.此外,该数据集图片的分辨率很高,因此在训练过程中可能出现内存不足.
SmartCity数据集[73]主要用于验证计数模型在人群稀疏场景中的有效性.现有的人群计数数据集主要采集自人群密集场景,基于密集场景数据集训练出来的网络难以保证对稀疏场景的泛化性.为此,腾讯优图从10种不同城市场景中,采集了50张图片.这些图像包括室内和室外2种场景,均采用了很高的视角拍摄,图像中行人稀少,平均数量只有7.4个.
Fudan-ShanghaiTech数据集[74]为进行基于视频的人群计数算法的研究提供了数据.已有的数据集主要面向基于图像的人群计数,为了更好地推动基于视频的人群计数算法的研究,研究人员从13个不同场景中捕获了100个视频,这些视频包含150 000帧图片,共标注了394 081个实体.其中训练集包含60个视频,共9 000帧图像;测试集包含剩余的40个视频,共6 000帧图像.
Beijing-BRT[75]是一个智能交通领域的人群计数数据集,包含1 280张从北京快速公交(bus rapid transit, BRT)采集的图片,其中720张用于训练,560张用于测试.每张图片像素大小为640×360,共标注了16 795个行人目标.该数据集与实际情况比较相符,涵盖了各种光照条件,而且时间跨度比较大,从白天到夜晚均有图像数据,因此基于该数据集训练出来的计数模型泛化能力较强.
DroneCrowd[76]数据集是由天津大学机器学习和数据挖掘实验室的AISKYEYE团队通过无人机拍摄创建,由288段视频剪辑和10 209张静态图像构成.数据集图像涵盖不同的地理位置、标注目标类型以及密集程度,变化范围广泛,很具有代表性.不仅可以用于视频或图像的目标检测和跟踪任务的研究,也可以用于人群计数任务的研究.
DLR-ACD[77]是一个包括33张航拍图像的人群计数数据集,数据集图片来自不同的城市场景,包括运动会、露天集会、庆典等存在大量人员聚集的场合,采用安装在直升机上的摄像头直接拍摄,所得到图片的空间分辨率在4.5cm/pixel~15cm/pixel之间变化.对图片中的每个人进行了手工标注,共标注了226 291个实例.
NWPU-Crowd[78]是目前人群计数领域最大的数据集,拥有5 109张图片和2 133 238个标注实体,而且单张图片的标注实体数量变化范围非常大,对计数任务来说虽然挑战极大,但也有助于提升训练模型的泛化性;该数据集的图片分辨率较高,有利于计数准确性的提升.此外,部分图片的目标标注数量为0,这些负样本的加入有助于提升训练模型的鲁棒性.该数据集还提供了一个平台,供研究人员进行计数模型的性能比较.
JHU-CROWD++[79]也是一个非常具有挑战性的大规模人群计数数据集,包含4 372张图像,共计151万个标注,所有图像采集于各种不同的场景和环境条件,甚至包括一些基于恶劣天气变化和光照变化的图像,覆盖面很广.此外,该数据集与NWPU-Crowd类似,引入负样本,增强训练模型的鲁棒性,同时对人头采用了多种标注方式,包括点、近似边界框、模糊级别等,为不同计数算法的训练提供支撑条件.
DISCO[80]是一个极具特色的大规模人群计数基准数据集,包含1 935张图片和170 270个带标注的实体,每张图片对应一段时长为1 s的音频剪辑.最终通过声音和图像的共同作用,实现视听人群计数.
5.3 讨 论
随着人群计数领域受关注程度的提高和研究的深入,人群计数数据集也逐渐增多,主要呈现5个特点:
1)在场景方面,由早期的单一化向多样化演变,部分数据集甚至包含极端条件下的场景图像,由此训练出来的模型跨场景迁移能力更强.
2)在图像分辨率方面,早期场景图像分辨率较低,图像质量较差,人群特征不明显,不利于模型训练.随着视频设备发展,图像分辨率不断增强,计数的准确率不断攀升.
3)在视角和尺度方面,变化范围更广,更贴近现实情况,有助于提升计数模型的泛化性和实用性.
4)数据规模不断增强,更加适合采用深度学习方法进行训练.此外,数据规模的增强降低了模型的过拟合风险.
5)样本类型更加丰富.早期人群计数数据集中每张图片均有人,标注数量至少为1,无人负样本的加入可以帮助模型过滤噪声,提升鲁棒性.
此外,分析实验数据可知,采用了注意力机制、空洞卷积以及额外辅助信息的网络往往性能较好.主要是由于注意力机制可以帮助计数网络专注于有效信息,排除噪声干扰;空洞卷积可以在不增加模型参数和计算量的前提下,扩大感受野,捕获多尺度信息,保留图像更多细节;而额外的辅助信息,例如视角,可以辅助处理多尺度问题.
目前,虽然已经构建了各种人群计数数据集,为验证计数算法的有效性提供了数据支撑,但是在场景多样性、标注准确性以及视图多样性等方面依然无法满足实验需求,这些也将是今后构建数据集时,需要重点考虑的问题.对于某些场景来说,采集图像非常困难且无法实现准确标注,此时可以考虑通过人工合成的方法生成图片,例如GCC[52]通过生成对抗网络人工合成了大量图片,为构建数据集提供了新思路.
6 总结与展望
近年来人群计数算法研究,尤其是基于深度学习的人群计数算法研究已经取得了明显进展,但是要在智能视频监控系统中真正应用并普及仍然面临许多挑战[110],例如相互遮挡、透视扭曲、照明变化以及天气变化等因素,都会影响计数的准确性.今后可以针对这些问题,从3个方面开展工作:
1)遮挡条件下的人群计数.随着人群密度增大,人与人之间会产生遮挡,下一步可以研究在遮挡条件下如何进行人群计数同时获取人群分布等细节信息.
2)特殊天气条件下的人群计数.现实中天气变化多样,不仅有风和日丽,亦有风雨交加.特殊天气下的数据采集和标注较困难[111],研究相对较少.下一步可以重点关注特殊天气条件下的人群计数问题,同时构建相应的数据集.
3)昏暗光照条件下的人群计数.在光照不足的环境中,摄像头拍摄的图片往往较模糊,人头无法清晰辨认,下一步可以研究昏暗光照条件下人群计数问题的处理方法.
本文针对近年来人群计数领域的相关论文进行调研, 在简单回顾传统人群计数算法之后, 对基于深度学习的人群计数方法进行了系统性的总结和介绍,并给出了这个方向未来的研究趋势,希望可以给相关研究人员提供一些参考.
作者贡献声明:余鹰负责综述选题确定、文章主体撰写和修订等工作,并指导和督促完成相关文献资料的收集整理以及论文初稿的写作;朱慧琳和钱进参与文献资料的分析、整理和论文初稿的写作;潘诚参与了文献资料的收集以及部分图表数据的绘制;苗夺谦负责提出论文修改意见,指导论文写作.
