计及频率偏移分布与惩罚代价的最大频率偏移预测方法
2021-12-12黄明增文云峰胥威汀
黄明增,文云峰,苟 竞,江 涵,胥威汀,李 婷
(1. 湖南大学电气与信息工程学院,湖南省长沙市 410082;2. 国网四川省电力公司经济技术研究院,四川省成都市 610041;3. 全球能源互联网集团有限公司,北京市 100031)
0 引言
频率衡量了有功出力和负荷平衡程度,是反映电能质量和系统安全稳定运行的重要指标[1-2]。若扰动事故后系统暂态频率偏移超出容许范围,将触发低频减载、高频切机等装置动作,使得系统面临切机、切负荷风险[3]。随着新能源和直流的大规模密集接入,部分电网常规电源“空心化”趋势逐渐凸显,惯性水平大幅降低,频率调节能力弱化[4],系统发生严重频率偏移的风险增加[5-6]。因此,有必要加强最大频率偏移实时感知能力,以辅助调度运行人员识别系统可能面临的频率失稳风险,提前做好应急预案,提升系统频率稳定性。
目前,电力系统最大频率偏移分析方法主要包括:时域仿真法[7]、解析模型法[8]和数据驱动法[9]。其中,时域仿真计及了电力系统详细的数学模型,可精确模拟有功扰动后频率响应过程,但建模难度大、计算耗时长;解析模型法将电力系统等值为单机(或多机)带集中负荷模型,计算复杂度有所降低,但由于进行了诸多简化,应用于实际大电网的适应性仍有待加强。
随着同步相量测量单元(synchrophasor measurement unit,PMU)的发展和广泛应用,调度中心积累了大量的监测信息[10],为基于数据驱动的最大频率偏移预测提供了强有力的数据支撑。基于系统潮流数据和扰动信息,文献[11]利用人工神经网络预测频率极值;文献[12]考虑发电机出力、旋转备用容量、原动机-调速器系统的影响,通过支持向量机回归估计暂态频率最低点。区别于浅层模型,文献[13]利用堆栈降噪自动编码器的深层构架挖掘极值频率、准稳态频率等频率指标信息。文献[14]计及低频减载控制策略的影响,并构建集成支持向量机以预测扰动事件下的最大频率偏移。
基于物理模型的电力系统频率响应分析复杂,上述数据驱动模型拓展了电力系统最大频率偏移预测手段,但研究工作中均没有考虑样本分布不均匀对最大频率偏移预测的影响。电力系统运行过程中,所发生的有功扰动呈现出故障类型少、功率波动范围窄的特点,尤其是有记录的大容量有功扰动历史事件的数目极少。因此,通过数据驱动建立的最大频率偏移预测模型往往更关注小扰动样本,而对严重扰动故障容易产生过于保守的预测,不利于调度员精准感知频率失稳风险。为此,文献[15]利用度量学习和模糊K均值聚类获取相近频率样本,再通过集成支持向量机预测最大频率偏移。尽管聚类后频率偏移差异有所缩小,但也加剧了样本的稀缺特性,不利于模型预测精度的提高。
针对上述问题,本文提出了一种计及频率偏移分布与惩罚代价的电力系统最大频率偏移预测方法。为更精确预测最大频率偏移,对轻梯度提升机(light gradient boosting machine,LightGBM)进行级联处理,并在其损失函数中加入惩罚敏感机制,辅助级 联 轻 梯 度 提 升 机(cascaded LightGBM,CasLightGBM)训练时自适应调整样本损失值。为避免维度爆炸问题,通过多源信息融合提取关键特征子集,并基于IEEE 118 节点标准系统验证所提出方法的有效性。
1 问题描述
1.1 频率安全
基于系统中正运行同步机组的总旋转动能和额定容量Ssys,可求得系统等效惯性时间常数如下:

式中:Hj、Sj分别为第j台机组的惯性时间常数和额定容量;N为同步机组总数。
仅考虑同步机组惯量响应和一次调频作用的情况下,系统遭受有功扰动后的频率动态变化过程可用等值转子运动方程描述为:

式中:Δf为系统频率偏移;ΔPm为机组机械功率增量;ΔPe为机组电磁功率增量;D为阻尼因子。
通过惯性中心频率fCOI描述系统的整体频率响应性能:

式中:fj为发电机节点j的频率。
参考文献[15],本文选择暂态过程中系统惯性中心的最大频率偏移Δfmax作为频率安全评估指标。对高维度强非线性的电力系统而言,其系统运行特征和Δfmax之间的映射关系是极其复杂的,难以通过解析模型精确求解。数据驱动模型具有强大的复杂函数表征能力,通过对频率数据进行挖掘学习,可建立系统运行特征x和Δfmax之间的非线性映射关系。

1.2 系统运行特征集
数据驱动模型所选取的输入特征应包含系统运行信息,且能较为全面地刻画有功扰动后电力系统频率响应特性。参考文献[12-16],构建如附录A 表A1 所示的系统运行特征集,其可通过PMU 装置直接或间接获取,且采集速度在毫秒级内,可以满足在线预测对数据获取快速性的要求[17-18]。
1.3 多源信息融合的关键特征选择
原始运行特征集提供了丰富的频率响应信息,但特征间存在一定的冗余性。此外,直接将原始运行特征作为输入,数据驱动模型容易遭遇维度灾难。为此,构建了一种多源信息融合的关键特征选择方法,可综合考虑系统运行特征间的关联信息与其在数据驱动模型建立中贡献信息的影响。
设运行特征集为Z={z1,z2,…,zn},zi∈Z,n为运行特征维度。引入联合互信息最大化(joint mutual information maximization,JMIM)[19]量 化 系统运行特征间的关联信息,对于任意运行特征序列zi,计算其与最大频率偏移Y之间的互信息I(zi;Y)。然后,不断选择能最大 化I(zi;Y)的运行特征,直至得到g个特征。当选择第i个特征时,特征选择标准α(zi)应满足:式 中:I(zi,zg;Y)为zi、zg和Y的 联 合 互 信 息;G为被选择特征构成的集合。

JMIM 从信息物理的角度出发筛选关键特征,其结果具有参考价值。然而,特征选择过程忽略了运行特征在数据驱动模型中的训练情况,不利于模型预测性能的提升。为此,还应考虑运行特征在数据驱动模型建立中的贡献度。LightGBM 在训练过程中记录了每个运行特征在回归树建立过程中的分割信息,对特征zi在所有回归树的分割信息进行求和即可得到其用于建立LightGBM 的贡献度fi,L。

式中:K为回归树的数量;Q为回归树中非叶子节点的数量;z″q为与节点q相关的特征;lk,q为第k棵树中节点q分裂后损失的减少值;P(⋅)为条件函数。
结合基于JMIM 的关联信息和基于LightGBM的贡献信息,进行归一化处理,可获得运行特征的综合重要度为:
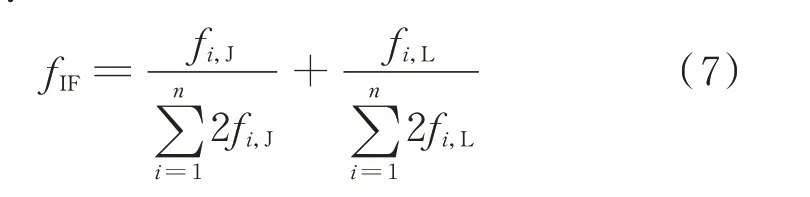
式中:fi,J为JMIM 所选取特征的互信息。为有效提取关键特征集,需要预先设定阈值,仅当运行特征的综合重要度大于预设阈值,才将其选为关键特征。
2 基于CasLightGBM 的最大频率偏移预测模型
2.1 CasLightGBM
LightGBM 是集成学习领域中的一种高效算法[20],基于梯度提升树(gradient boosting decision tree,GBDT)框架进行改进,有效提升了模型处理大数据的能力和预测精度。它的基本思想为将K个弱回归树fk(x)进行集成以构建强学习器:

LightGBM 通过多弱学习器集成增加输出多样性,避免了低精度弱学习器的负面影响,进而在一定程度上降低了样本依赖性。同时,借助于基于梯度的单面采样(gradient-based one-side sampling,GOSS)和互补特征压缩(exclusive feature bundling,EFB)等改进措施,其内存消耗得到有效控制[20]。
为进一步提升LightGBM 表征高维度强非线性复杂电力系统函数的能力,实现对关键运行特征的逐层表达学习,本文参考深度森林构架,构建了CasLightGBM。深度学习通过逐层训练网络参数向上表达,可有效挖掘输入特征数据的深层抽象信息,实现对复杂函数的映射表达。然而,其存在计算量大、耗时长和样本数量依赖性高等缺陷。深度森林通过逐级串联随机森林实现了深度学习构架的多层表达效果,且运算效率高,给进一步提升模型预测精度提供了新的思路[21]。LightGBM 内存消耗低,且与随机森林相比具有更优异的泛化能力,故本文采用CasLightGBM 替代级联森林结构,其结构如图1所示。

图1 CasLightGBM 结构Fig.1 Structure of CasLightGBM
构建4 个互异的LightGBM 学习器作为CasLightGBM 的 一 个 级 联 层,在CasLightGBM 建立过程中,采用均方误差(mean squared error,MSE)作为是否需要继续增加级联层的判断指标,具体计算方法如下:

式中:M为测试样本数量;ym、ŷm分别为第m个样本的真实值、预测值。
当CasLightGBM 扩展到新的级联层T时,判断当前层所计算的MSE 值是否大于T−1 层,若满足,则继续扩展级联层。
2.2 计及惩罚敏感机制的损失函数
CasLightGBM 的损失函数可由式(10)表示。

式中:l(⋅)是误差函数,衡量了模型的预测误差大小。损失函数L可基于MSE 函数进行构建。
将CasLightGBM 应用于电力系统最大频率偏移预测时,尽管训练后模型对数据的整体拟合程度较优,但得到的模型也可能不具备适应性,原因在于损失函数中忽略了频率偏移样本的分布差异。在电力系统运行过程中,大容量有功扰动事件的数量通常远小于小扰动事件的数量,这使得最大频率偏移的分布往往呈现边缘陡峻,左边高于右边的带状分布。此时,利用频率数据训练CasLightGBM,海量频率稳定样本的总损失值远大于严重扰动故障样本,使得模型在训练过程更关注频率稳定样本,而忽略了对控制装置动作具有重要参考意义的严重扰动故障样本。为此,参考交叉熵损失函数[22],在损失函数中引入敏感因子ω,以平衡频率偏移样本分布差异的影响。

式中:y为样本的频率偏移值;p为严重扰动故障样本对应的概率;ε为补偿因子,用于防止频率稳定样本概率过高导致梯度消失问题;R为频率安全的判断阈值,结合实际电网第三道防线判断标准,将R设置为0.8 Hz。当扰动事故后频率偏移大于0.8 Hz时,将触发第三道防线中低频减载或高周切机装置自动动作,大范围切除电网中的机组或负荷。因此,将扰动事故后最大频率偏移大于0.8 Hz 的样本划分为严重扰动故障样本,否则划分为频率稳定样本。
由式(11)可知,(1−p)值越接近1,ω值越小,避免了非严重扰动故障样本总损失值过大,进而在一定程度上平衡了最大频率偏移的分布差异的影响。
除了频率偏移大小的分布有所不同,严重扰动故障样本的预测值是否能准确反映频率失稳风险对应的代价也存在显著差异。对于超过第三道防线动作阈值的样本,CasLightGBM 预测值略大于控制措施动作阈值并不会造成严重的后果,但若预测值小于控制措施动作阈值,由于无法及时采取合适的紧急控制措施,容易诱发级联故障导致频率失稳或频率崩溃。因此,本文在损失函数中给严重扰动故障样本加入惩罚系数λ,最后得到的计及惩罚敏感机制的损失函数如下:

通过计及惩罚敏感机制的损失函数,CasLightGBM 在训练过程中不仅平衡了频率偏移分布差异的影响,还考虑了严重扰动事件预测保守所带来的惩罚代价,在电网最大频率偏移预测场景中更具实用性。
3 最大频率偏移预测方法及流程
为了构建更适应电网最大频率偏移预测场景的数据驱动模型,提出了一种计及频率偏移分布与惩罚代价的电力系统最大频率偏移预测方法。以系统运行信息作为输入,并通过多源信息融合提取关键特征集,避免维度爆炸问题。构建CasLightGBM 构架,并在其损失函数中加入惩罚敏感机制,可使CasLightGBM 训练时自适应调整样本损失值,进而提升最大频率偏移预测精度。在线应用前,CasLightGBM 需利用预先准备的数据集进行迭代训练,训练好的CasLightGBM 可在扰动事故后快速预测电力系统最大频率偏移值,给后续控制措施的制定提供参考,分为5 个步骤。
1)构建数据集。在不同运行方式下,利用时域仿真法模拟所研究系统在预想故障后的频率响应过程,进而获取最大频率偏移数据集。此外,若已具备丰富扰动事件下的频率监测数据,可直接运用历史数据构建数据集。同时,也可兼顾仿真数据和历史数据构建数据集。
2)选择关键特征。通过多源信息融合方法计算每个系统运行特征的综合重要度,结合预设阈值,从原始高维度的运行特征中筛选g维关键特征子集,以矩阵形式表示为:
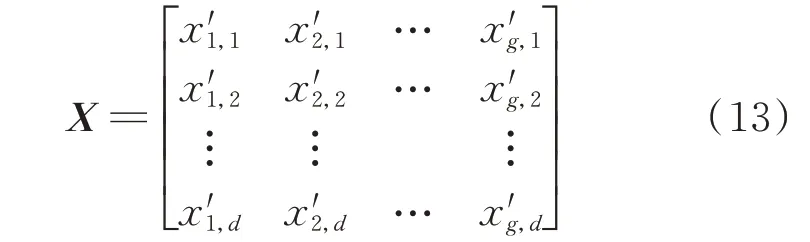
式中:d为所构建数据集的样本数量;x′g,d为第d个样本中第g个关键特征的数值。
3)训练CasLightGBM。确定当前数据集中频率偏移样本的概率分布和严重扰动故障样本对应的惩罚系数。利用关键特征数据及最大频率偏移数据对CasLightGBM 进行迭代训练,当级联层所获的MSE 值不再提升时,停止级联层扩展,并删除当前级联层,进而获得具备复杂函数强表征能力的CasLightGBM。
4)衡量CasLightGBM 预测性能。采用最大绝对误差值(maximum absolute error,MAE)、MSE 和均方根误差(root mean square error,RMSE)作为衡量CasLightGBM 整体预测性能的指标,其中,MAE和RMSE 表达式分别为:

5)将CasLightGBM 用于在线预测。在PMU 持续监测的过程中,若某一时刻量测的频率突变量大于预定的门槛值,即认为频率发生扰动[18]。扰动事故后,获取电网PMU 在线监测数据作为CasLightGBM 的输入数据,进而快速预测电力系统最大频率偏移。若所预测的系统最大频率偏移值超过电网第三道防线控制装置的触发值,及时发出预警,以便后续采取紧急控制措施维持频率稳定。
以上步骤具体流程如图2 所示。

图2 最大频率偏移预测流程Fig.2 Flow chart of maximum frequency deviation prediction
4 算例分析
以IEEE 118 节点标准系统作为测试系统,其包含118 个节点、179 条输电线路、54 个常规电源节点和64 个负荷节点。采用PSD-BPA 进行时域仿真,模拟扰动事故后的电力系统动态频率响应过程。采用拉丁超立方采样在[0.7,1.1]范围内生成50 种负荷水平,并相应调整系统发电机出力以保证潮流收敛。对所有机组进行N−1 及N−2 机组跳闸故障模拟,故障设置在0.01 s 发生,总仿真时长为120 s。最后,一共得到6 835 个最大频率偏移样本,以8∶2的比例将其随机划分为训练数据和测试数据。
4.1 最大频率偏移分布
图3 展示了所得最大频率偏移样本的拟合分布情况。从图3 可以看出,最大频率偏移样本的分布是极其不均匀的,频率偏移小的样本占了绝大多数,而大频率偏移样本则较为稀缺,例如,最大频率偏移大于0.8 Hz 的样本仅占9.39%。因而,通过数据驱动模型挖掘数据所隐藏的频率偏移信息时,严重扰动故障样本容易被忽视,导致训练后的模型倾向于对其做出过于保守的预测,这不利于调度员在扰动事故后精准感知频率失稳风险。

图3 最大频率偏移分布拟合曲线Fig.3 Fitting curve of the maximum frequency deviation distribution
4.2 关键特征选择
基于多源信息融合方法对系统运行特征的综合重要度进行计算,并降序处理,具体见附录B 图B1。为在降低运行特征维度的同时使所筛选的关键特征尽可能保留充足的频率偏移信息,将关键特征选择阈值设定为0.01,得到215 维的关键特征集。结合系统运行特征间的关联信息与其在数据驱动模型建立中的贡献信息,通过多源信息融合来筛选关键特征子集,所得关键特征维度为原始特征的31.30%(原始特征维度为697),有效降低模型复杂度并避免维度爆炸问题。
4.3 惩罚系数的影响
不同惩罚系数对CasLightGBM 预测最大频率偏移精度的影响如附录B 图B2 所示。可以看出,模型预测所得MAE 和MSE 的变化趋势较为相近,但并不完全相同。这是因为预测所得MAE 往往来自严重扰动故障样本,而MSE 反映的是所有样本的整体预测误差。当惩罚系数处于[1,3.5]时,MAE 和MSE 随着惩罚系数的变化在一个较优区间波动,而惩罚系数大于3.5 时,MAE 和MSE 会急剧增大。借助于惩罚系数,CasLightGBM 可将更多的注意力分配给严重扰动故障,从而降低严重扰动故障的预测误差,但惩罚系数设置过大也会破坏CasLightGBM对频率偏移样本信息提取的平衡,反而会降低其预测性能。综合考虑,将惩罚系数设置为2,此时模型预测所得MAE 和MSE 均达到最优。
4.4 计及惩罚敏感机制损失函数的有效性分析
为分析所构建计及惩罚敏感机制损失函数的有效性,与采用未改进损失函数的CasLightGBM 比较严重扰动故障样本的预测精度,如图4 所示。

图4 严重故障样本的预测精度比较Fig.4 Comparison of prediction accuracy for serious fault samples
从图4 可以看出,当CasLightGBM 的预测结果低于真实值时,未改进损失函数使得CasLightGBM预测结果偏于保守,而计及惩罚敏感机制损失函数有助于提高模型的最大频率偏移预测值,进而更接近于真实值。同时,由于未改进损失函数中没有考虑频率偏移分布差异的影响,CasLightGBM 也容易做出过于偏激的预测。当CasLightGBM 预测结果高于真实值时,采用未改进损失函数训练的CasLightGBM 的预测值甚至会偏离真实值更多。图4 中,采用未改进损失函数训练的CasLightGBM的预测值大于真实值的概率为37.01%,而采用计及惩罚敏感机制损失函数后预测值大于真实值的概率上升到46.45%。由于预测保守导致错判频率安全的概率由5.5%降低到0.7%,因此,采用计及惩罚敏感机制的损失函数更有助于调度运行人员精确感知频率失稳风险。
为进一步分析计及惩罚敏感机制损失函数的优越性,对模型预测误差的绝对值分布进行展示,见附录B 图B3。其中,预测误差绝对值大于0.03 Hz 的比例下降了2.93%,预测误差绝对值小于0.01 Hz 的比例上升了17.35%。在CasLightGBM 损失函数中加入惩罚敏感机制,也有助于提升模型的综合性能。
4.5 不同算法比较
为了验证所提出CasLightGBM 的泛化能力,选取常用的机器学习方法,如LightGBM、长短期记忆(long short term memory,LSTM)网络、支持向量机(support vector machine,SVM)、决策树(decision tree,DT)进行对比分析。将多源信息融合方法选取的关键特征作为各机器学习模型的输入数据,采用相同的数据集进行训练和测试,结果如表1所示。
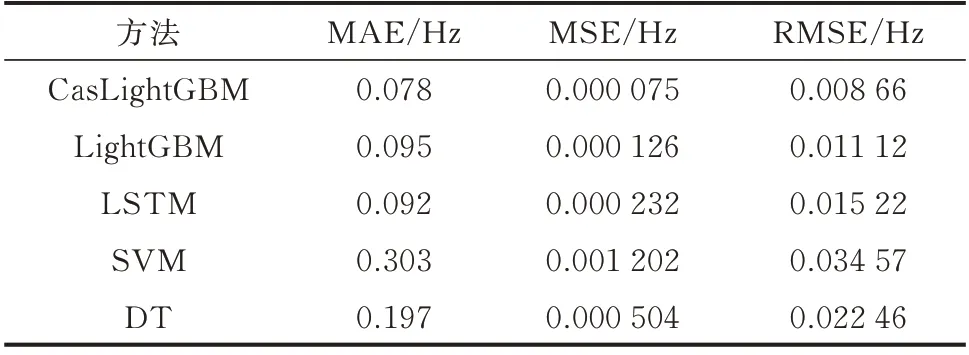
表1 不同方法的预测精度对比Table 1 Comparison of prediction accuracy of different methods
由表1 可以看出,相比于其他方法,本文所提方法在MAE、MSE、RMSE 上均具有最佳的性能表现。LightGBM 和LSTM 分别为集成学习、深度学习领域中的优秀方法,具有较强的数据挖掘能力,但预测所得MAE 分别比CasLightGBM 高了21.79%、17.95%,RMSE 分 别 比 CasLightGBM 高 了28.41%、75.75%。SVM 和DT 的预测效果并不理想,这是浅层神经网络本身的局限造成的。浅层神经网络无法对关键特征进行深层学习,大量频率信息无法被挖掘,因而对最大频率偏移的拟合受限。相比之下,CasLightGBM 利用级联结构高效挖掘隐藏在关键特征中的丰富频率偏移信息,可精确表征复杂电力系统函数,具有优异的泛化能力。
4.6 不同训练样本数量时的预测精度分析
通过改变用于训练CasLightGBM 的样本数量来分析其预测精度的变化规律。固定测试样本数量为1 366 个,分别加入1 000、2 000、…、5 000 个训练样本,CasLightGBM 的预测精度如表2 所示。可见,随着训练样本数目增加,预测所得MAE、MSE 和RMSE 均有所降低,原因在于训练样本数目越多,能提供的频率偏移信息越丰富。当训练样本为3 000 时,预测所得MAE 已低于0.1 Hz,表明CasLightGBM 在稀疏样本场景中也具有一定的适应性。继续增加样本数量,各评价指标的降幅有所递减,直至训练样本为5 000 时,CasLightGBM 达到一个较优水平,预测所得MAE 和MSE 分别为0.08 Hz 和1.05×10-4Hz。

表2 不同样本数量的预测精度对比Table 2 Comparison of prediction accuracy with different sample numbers
4.7 抗噪声能力分析
获取电网运行信息时,可能会受到来自处理设备以及传输通道所引入噪声的影响,为此,本文在数据集中添加信噪比在20~40 dB 范围变化的高斯白噪声,以验证所提模型的抗噪声性能,结果如表3所示。

表3 CasLightGBM 抗噪性能Table 3 Anti-noise performance of CasLightGBM
随着噪声干扰程度加强,CasLightGBM 的预测误差所有增加,但增加的幅度是非常小的。噪声强度为20 dB 时,所得MAE、RMSE 与40 dB 场景相比仅增加了0.010 3 Hz、0.002 9 Hz。此外,在信噪比为20 dB 的高噪声强度场景中,预测所得MAE 依旧低于0.1 Hz,体现了CasLightGBM 优异的抗噪性能。
4.8 时间优越性
除泛化能力外,模型预测的快速性对电力系统最大频率偏移在线应用而言也是至关重要的。利用时域仿真执行1 次和1 336 次针对预想故障的最大频率偏移计算分别需2.35 s、53.50 min。随着系统规模扩大,模型愈加复杂,时域仿真计算所需时间将更长。CasLightGBM 通过数据驱动方式建立关键特征-最大频率偏移之间的映射关系,训练所需时间为3.25 s,训练好的模型可在0.02 s 内给出单个样本或批量样本的最大频率偏移预测结果,更有助于调度员快速感知电力系统频率态势。应当指出,完全依靠离线时域仿真生成CasLightGBM 的训练集是非常耗时的。在具备一定的数据样本后,可将在线评估结果添加到离线数据库中,不断丰富和更新数据集,减少对离线仿真数据的需求。
4.9 模型适应性分析
为验证所提方法在不同故障类型场景的适应性,除机组跳闸故障外,还考虑各类短路故障中最为严重的三相短路故障[23]。新数据集的测试结果见附录B 表B1。在三相短路故障场景中,CasLightGBM的整体预测性能较优异,预测所得MSE 和RMSE分别为2.5×10-5Hz 和5.02×10-3Hz。在混合机组跳闸故障和三相短路故障的场景中,尽管预测难度增大,CasLightGBM 依旧显示出较好的泛化能力,预测所得MAE 和MSE 分别为0.088 Hz 和6.6×10-5Hz,与只含机组跳闸故障样本的测试结果相比,MAE 仅增加了0.01 Hz,而MSE 有所下降。因而,在多故障类型场景中,CasLightGBM 也具有较好的适应性。
此外,为验证所提方法在新运行方式下的适应性,新增两种运行场景,分别为大负荷方式(基准负荷的115%)和小负荷方式(基准负荷的65%),考虑机组跳闸故障和三相短路故障。利用测试场景外的数据训练CasLightGBM,基准负荷水平场景和大/小负荷方式场景的最大频率偏移预测结果如附录B表B2 所示。由表B2 可知,尽管大负荷方式下系统稳定性问题更加突出,模型精确预测难度大,利用历史数据训练的CasLightGBM 依然保持着较好的泛化能力,在机组跳闸故障和三相短路故障场景预测所得MAE 分别为0.099 Hz 和0.086 Hz。
5 结语
针对现有最大频率偏移预测方法对样本非均匀性处理不足的问题,提出了一种计及频率偏移分布与惩罚代价的最大频率偏移预测方法,主要结论如下。
1)运用多源信息融合方法筛选关键特征子集,所得关键特征维度与原始特征维度相比显著降低,有助于提升CasLightGBM 的运算效率,避免维度爆炸问题。
2)通过计及惩罚敏感机制的损失函数,CasLightGBM 可在训练过程中给予严重扰动故障样本更多关注,并考虑其预测保守的惩罚代价,预测效果更优。此外,计及惩罚敏感机制的损失函数也有利于提升CasLightGBM 的综合预测性能。
3)相较于LightGBM、LSTM、SVM、DT 等机器学习方法,所构建的CasLightGBM 具有更优异的预测精度、适应性,且抗噪声干扰能力强,可在扰动事故后快速预测电力系统最大频率偏移,为后续控制措施的制定奠定基础。
后续将进一步探索所提方法在实际电网中的应用,提升数据驱动模型在稀疏样本场景下的适应性。随着新能源渗透率逐渐提高,系统频率稳定特性变化显著,如何进一步提高模型的继承性和泛化能力,也需深入研究。基于迁移学习技术提升CasLightGBM 在稀缺样本及新能源渗透率提升场景的适应性,将是下一阶段的研究重点。
本文研究得到湖湘青年科技创新人才项目(2020RC3015)的资助,特此致谢!
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
