基于多源数据的车流量时空预测方法*
2021-12-11龚永胜蔡世杰黄腾飞
胡 杰,龚永胜,蔡世杰,黄腾飞
(1.武汉理工大学,现代汽车零部件技术湖北省重点实验室,武汉430070;2.武汉理工大学,汽车零部件技术湖北省协同创新中心,武汉430070;3.新能源与智能网联车湖北工程技术研究中心,武汉430070)
前言
在智慧城市[1]建设过程中,随着车载传感器增加,车辆行驶过程中将产生大量的交通数据,如何充分挖掘隐含在数据中的普遍规律从而进一步推动智慧交通系统的发展,已经引起了大量学者[2]的关注。准确的车流量预测不仅有利于城市道路的规划建设,还有助于提高车辆的通行效率,缓解城市交通拥堵,减少资源浪费和环境污染。
为了提高交通流量的预测精度,研究人员做了大量探索。在基于状态估计的交通流量预测中,卡尔曼滤波的预测模型得到了广泛的应用[3-7]。由于不同路段的交通流量之间存在一定的线性关系,因此可使用卡尔曼滤波对线性函数的参数进行估计,从而实现交通流量的预测。该方法的缺点是模型容易产生滞后现象,难以适应日益复杂的城市路网结构。
在机器学习模型中,车流量被视为单一时间序列问题,使用机器学习模型拟合历史交通流的变化趋势从而实现对未来的预测。Marco等[8]提出了一种基于支持向量回归(support vector regression,SVR)的交通流量预测模型,考虑到交通流量的季节变化,该模型采用季节核来度量两个时间序列样本之间的相似性,实验证明该模型与传统的自回归滑动平均模型和卡尔曼滤波组合模型相比,在预测精度相同的情况下,大幅降低了模型的时间复杂度。Hu等[9]提出了一种基于混合PSO-SVR的短期交通流量预测模型,该模型采用快速粒子群优化算法(particle swarm optimization,PSO)对SVR的参数进行优化。Ge等[10-11]对复杂的交通流量序列采用小波变换转变为不同尺度下的单一特征,然后使用SVR模型分别对不同尺度下的子序列进行预测,该方法较大限度地挖掘了时间序列中的隐含信息和特征的变化,实现了较好的预测效果。在其他机器学习算法的研究中,樊汉勤[12]采用随机森林算法来实现交通流量的预测,可实现与SVR相似的效果。随着神经网络的发展,其优秀的非线性拟合能力使得神经网络在交通流量预测领域得到了广泛的青睐[13-16]。文献[17]和文献[18]中利用多层感知机(multilayer perception,MLP)和长短时记忆神经网络(long short-term memory networks,LSTM)对交通流量进行预测,并引入早停机制[19-20]来防止模型过拟合。基于时间序列的预测方法虽然改进了传统方法的预测精度,但该方法忽略了城市交通的空间连通性,不适于复杂交通系统的交通流量预测。
为了在时间序列预测的基础上进一步探索城市交通中的空间关系,基于图神经网络的图节点信息提取得到了广泛的应用[21]。文献[22]~文献[25]中提出了不同的图表示学习方法,实现了图节点的向量表示。图表示方法与传统时间序列模型相结合可实现交通流量的时空预测,改善交通流量的预测效果。刘道广[26]提出了一种基于图卷积网络(graph convolutional network,GCN)和LSTM相结合的时空预测模型,取得了较好的预测效果。Zhao等[27]提出了一种基于图卷积神经网络(GCN)和门控循环单元(gated recurrent unit,GRU)组合的时间图卷积网络(temporal graph convolutional network,T-GCN)模型来实现交通流量预测,充分考虑了城市交通中的空间特性。Zhang等[28]提出了一种基于残差网络的时空特征提取方法,并考虑了天气和节假日的影响,为车流量预测研究提供了新的思路。
为了充分考虑天气、时间、兴趣点(point of interest,POI)等外部因素对车流量的影响,本文中提出了一种基于多源数据与时空预测模型相结合的车流量预测方法。同时,提出了一种基于图表示学习和时间卷积的时空预测模型,并融合了基于历史出租车轨迹的空间邻接权值提取模型,进而提高模型的空间特征提取能力。
1 多源数据的预处理和分析
1.1 数据介绍
1.1.1 道路交通卡口数据集
道路交通卡口数据来源于DataCastle竞赛平台,采用的是青岛市107个道路交通卡口在2019年8月至9月7:00-19:00的车辆通行数据,时间跨度为35天,共计94 180 760条。数据的特征维数和空间分布如表1所示。

表1 道路交通卡口数据样本
1.1.2出租车数据集
出租车数据集采用的是DataCastle网站提供的青岛市2019年8月1日至19日中7:00-19:00之间的出租车行驶轨迹数据。数据采集的时间间隔为20 s,共计100 740 505条。数据维度如表2所示。

表2 出租车数据样本
1.1.3 天气数据
天气数据来自WunderGround网站,数据包括时间(小时)、温度、湿度、风速、气压和天气状况6个维度,如表3所示。

表3 天气数据样本
1.1.4 POI数据
POI数据来自Openstreetmap平台,数据包含POI名称、POI类别、行政区、经度和纬度,如表4所示。

表4 POI数据样本
1.2 流量转换
1.2.1 道路交通卡口数据集的流量转换
道路交通卡口数据集包含道路车辆通行记录,以5 min为时间间隔,对各卡口的车辆通行记录进行流量统计转换。转换后的数据点代表5 min内的车流量。转换后的部分卡口(100051、100117、100335)车流量数据如图1所示。

图1 交通卡口车流量变化趋势
1.2.2 出租车数据集的流量转换
对于出租车数据集的处理,首先对出租车的轨迹进行坐标转换,将车载传感器采集的WGS84坐标系转换为GCJ02坐标系。其次,计算相邻两轨迹点之间的平均速度,剔除平均速度大于120 km/h的异常轨迹点,并使用线性插值法补全缺失。最后,基于Geohash6[29]对城市进行网格划分,以5 min为间隔统计每个网格的出租车流量,从而实现出租车数据集的流量转换。转换后的部分流量如图2所示。

图2 出租车流量变化趋势
1.3 Kalman数据平滑
受限于数据采集设备的精度,原始数据中不可避免地存在少量噪声。为了减少噪声,采用了基于Kalman滤波的数据平滑方法[30]。
1.4 特征相关性分析
1.4.1 时间相关性分析
充分挖掘车流量时间序列的时间特征有助于提高模型的预测精度。
(1)以天为单位的周期性分析
两个数据集前3天的变化趋势图如图3和图4所示。由图可见,车流量的变化趋势基本相同,说明车流量具有明显的周期性特征。

图3 车流量的周期性分析(天)-交通卡口流量的周期性对比

图4 车流量的周期性分析(天)-出租车流量的周期性对比
(2)以星期为单位的周期性分析
以星期为单位的周期性分析如图5所示。由图可见,工作日平均车流量较高,呈现明显的早晚高峰特性,且与周末的车流趋势有较大差异。

图5 车流量的周期性分析(星期)
1.4.2 天气相关性分析
天气状况会影响城市交通流。两个数据集在不同天气下的平均流量图如图6所示。由图可见,晴天的车流量都明显高于雨天,说明市民更倾向晴天出行。

图6 天气相关性分析
1.4.3 POI相关性分析
不同POI下的平均流量的统计分析如图7所示,可知不同POI对应的流量存在较大差异,说明POI能间接反映市民的出行意图对城市交通存在影响。
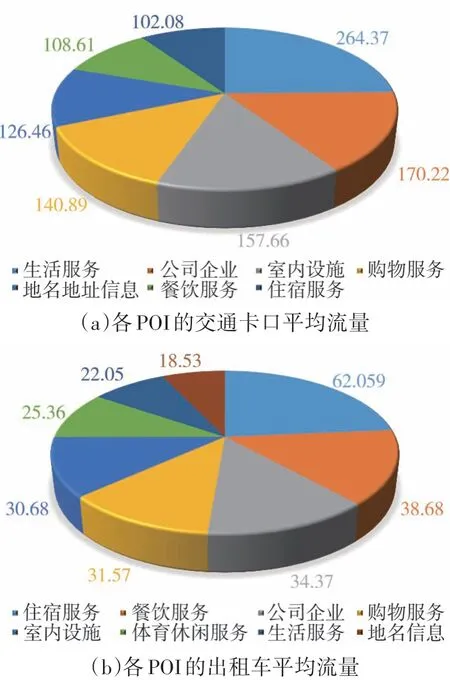
图7 POI相关性分析
2 多源特征表示
2.1 时间特征表征
为了加强模型的时间特征学习能力,提出了一种基于Time2vec[31]的时间周期特征提取模型。Time2vec模型通过嵌入神经网络层可以实现从输入时间序列中自动提取隐含的时间周期特征。Time2vec的周期特征表达式为

式中:ω和φ分别为正弦三角函数中的频率和初始相位;t为输入的时间特征(时间标量);i为第i个特征表示输出。
2.2 天气特征表征
为了更精确地描述天气舒适度对车流量的影响,提出了一种基于K-means聚类的出行舒适性分类方法。
K-means的输入包括天气特征中的温度、湿度、风速和气压4个维度,k值根据轮廓系数确定。聚类结果和轮廓图分别如图8(a)和图8(b)所示,当k取3时对应轮廓系数最大,说明聚类标签为3时最为合适。类别标签将经过One-Hot编码后输入模型。

图8 POI相关性分析
2.3 POI特征表征
2.3.1 道路交通卡口数据集的POI匹配
POI点和交通卡口点的匹配,采用了基于最近邻算法(K-nearest neighbor,KNN)的匹配方法。通过进行对照实验得知,当近邻参数k=50时,匹配效果最佳。匹配结果如图9所示,匹配后卡口的POI标签将通过One-Hot编码实现特征表征。

图9 道路卡口的POI匹配
2.3.2 出租车数据集的POI匹配
出租车数据集的流量为GeoHash6网格区域流量,首先计算每个网格内各类型的POI数量,其次将数量最大的类别作为网格的POI类别从而完成网格的POI匹配。所有的POI类别都将通过One-Hot编码实现特征表征。
3 基于多特征融合的车流量时空预测模型
为了充分考虑多源特征对车流量的影响,本文中从外部特征、空间特征和时间特征3个角度进行了综合建模,即采用外部特征、空间特征和时间特征提取模型经过张量拼接输入至MLP单元中进行多模型的融合,从而实现基于多特征融合的车流量时空预测方法。预测模型的总体结构如图10所示。
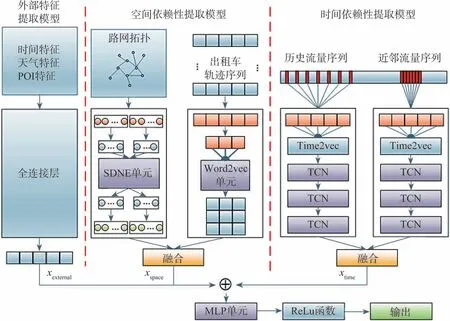
图10 预测模型整体结构
3.1 外部特征提取模型
外部特征包括多源特征表征中的时间、天气和POI属性。对此类特征进行相应的张量拼接后将连接到全连接网络实现外部特征的建模。外部特征提取模型的输出将与其他模型的输出融合后输入多层感知机网络中。
3.2 空间特征提取模型
3.2.1 基于图表示学习的空间邻接特征提取模型
在城市路网中,相邻道路交叉口之间的上下游关系会对整体的车流量产生重要影响。考虑到道路的空间分布对城市交通的交叉影响,采用了一种基于结构深层网络嵌入(structural deep network embedding,SDNE)的空间分布特征提取方法[25],其中1阶相似性用来捕获路网空间局部结构相关性,2阶相似性用来捕获路网空间全局结构相关性。图表示学习SDNE算法的总体结构如图11所示。

图11 SDNE模型总体结构
在SDNE模型中,每个输入数据(节点邻接信息)需要经历相应的编码和解码过程,该过程对应为SDNE的2阶相似性学习。在节点编码时,通过多层非线性单元将节点信息从低维映射到高维从而得到节点信息的表示空间。在解码时,通过多层非线性元素进一步映射表示空间得到重构的节点邻接矩阵。
SDNE模型的输入为交通邻接图数据。该模型包含两个网络层,每层包含64个和128个隐藏神经元,用于学习交通卡口之间的隐含空间关联。
3.2.2基于历史轨迹的空间权重特征提取模型
针对空间权重问题,提出了一种基于出租车历史轨迹的邻接权重特征提取方法。首先,将出租车轨迹数据通过Geohash6网格编码;然后将轨迹编码去重后视为文本语言输入词嵌入Word2vec模型学习网格间的权重关系,从而实现网格间的实际车辆流动关系的探索;最后在网格的基础上实现交通卡口数据集和出租车数据集中各流量统计点的空间权重匹配。
词嵌入Word2vec模型为图12中所示的CBOW(continuous bag-of-words model)模型,模型包括输入层、隐含层和输出层。该模型的词窗口大小为5,图中ωi-1、ωi-2、ωi+1和ωi+2分别为CBOW模型中经过One-Hot编码后的输入,ωi为输出,也即CBOW模型根据当前单词的前后4个单词来预测当前词。

图12 CBOW模型结构
Word2vec模型训练后,其隐含层中的嵌入向量将被保存至模型的词典中,词向量可通过查询字典的方式获取。每个单词的嵌入维度由隐含层的神经元个数决定,嵌入后的词向量将包含单词间的相似度信息,也即空间权重信息。在词嵌入模型中,词窗口大小设置为4,嵌入维数为60,空间权重特征提取模型的结构如图13所示。

图13 邻接特征提取过程
在空间相关提取模型由SDNE模型和词嵌入的CBOW模型融合而成,其中SDNE负责空间邻接特征提取,CBOW负责邻接权重特征提取,空间相关提取模型的最终输出xspace是SDNE的输出xSDNE和Word2vec的输出xWord2vec的张量拼接。

3.3 时间特征提取模型
车流量作为时间序列数据,具有强烈的时间相关性。时间卷积网络(temporal convolutional net⁃works,TCN)中加入的因果卷积,加强了模型对序列数据的学习能力,同时通过膨胀卷积极大的扩展了模型的感受野。TCN还引入残差单元用于缓解梯度爆炸和梯度消失,从而使深TCN网络的实现成为可能。为了提高模型的效率,采用了基于TCN的时间相关性建模方法[32]。
为了提高模型的时间特征提取能力,建立了基于近邻预测和日周期预测的双基线时间特征提取模型。如图14所示,近邻基线上的TCN模型根据前12条(1 h)流量预测后续流量;在日周期基线上,模型根据前一天同一时间的流量预测当前值。

图14 双基线数据采样方法
3.4 多头自注意力机制
多头自注意力机制[33]能增强模型对长序列的“记忆能力”,增强模型对长期依赖的学习。在深度学习中,注意力机制被广泛用于增强模型对重要信息的关注度。自注意力模型的输出向量可根据式(3)计算得出,其中dk为调节参数,Q、K、V分别为查询向量序列、键向量序列和值向量序列,3种序列可由输入信息经过线性变换获得。

多头自注意力模型的输出计算方法如式(4)和式(5)所示,其中WQ、WK、WV和WO为隐藏参数矩阵,headi为第i个放缩点积注意层的输出。为了避免模型训练过程中出现过拟合现象,同时加入早停算法。

4 实验结果与分析
4.1 实验设置
4.1.1 评价指标
本文中以均方根误差(root mean squared error,RMSE)和平均绝对误差(mean absolute error,MAE)为评价指标实现预测模型的对比评估。两个评价指标越小,则表示预测效果越佳。
4.1.2 相关参数设置
通过多个对照实验分析预测效果,模型最佳效果的相关参数设置如下:训练集、验证集和测试集的比例分别为60%、20%、20%。在外部特征模块中,Time2vec的神经元数为32,K-means聚类标签为3,KNN近邻参数为50,Geohash编码长度为6。在空间特征提取模块中,SDNE模型的批量大小和迭代次数分别为128和50;邻接权值模型的单词窗口大小和嵌入尺寸分别为4和60。在时间特征提取模型中,批量大小为256,早停容忍度为5,早停阈值为0.001,模型的优化算法为Adam。
4.2 结果分析
4.2.1 多源特征对比及结果分析
该部分设置了以TCN为基模型的多源特征验证方案。车流量的输入步长为12(1 h),预测长度为6(30 min),对照实验如下所示:
TCN,交通流序列作为输入;
Time-TCN,在TCN的基础上添加时间特征;
Wea-TCN,在TCN的基础上添加天气特征;
POI-TCN,在TCN的基础上添加POI类别特征;
GTCN,在TCN的基础上组合空间特征提取模型SDNE与邻接权重提取模型Word2vec。
两个真实数据集的对照模型预测结果(3次重复实验后的平均值)如图15所示。

图15 多源特征预测结果对比
由对比结果可知,多源特征的引入改善了模型的预测效果。空间相关性特征的引入最大程度提升了模型的预测效果,验证了空间相关性建模的有效性;时间、天气和POI特征的引入均不同程度地提升了模型的预测精度,验证了基于多源数据方法的合理性。
4.2.2 预测模型对比及结果分析
为了验证MF-AGTCN模型的预测效果,该部分以RNN、LSTM、GRU、CNN、TCN和Zhao等提出的基于图卷积网络(GCN)与GRU的组合模型TGCN[27]为对照模型设计了对照实验。所有的对照模型均调至最佳状态,并设置随机失活率为0.5以防止过拟合。同样,模型的输入步长为12(1 h),预测长度为6(30 min)。实验结果如图16所示。

图16 不同模型的预测结果对比
实验结果表明,MF-AGTCN模型在两个数据集的多个预测步长上都呈现出更好的预测效果。相比于5个模型的平均提升对比,MF-AGTCN相比RNN的提升最大,相比TCN模型提升相对较小,说明TCN模型在两个交通数据集上优于传统递归神经网络,也验证了MF-AGTCN模型中的基于TCN模型的时间相关性建模的合理性。在MF-AGTCN与T-GCN模型的对比中,由于时间特征提取模型Time2vec和多头注意力机制的引入使MF-AGTCN模型改善了未来25~30 min的车流量预测精度,说明MF-AGTCN模型具备更优异的中长时预测性能。
MF-AGTCN模型在两个真实交通数据中的部分预测效果如图17和图18所示。由图可见,MFAGTCN模型较好地拟合了真实的交通流波动趋势,且在预测步长为30 min时依然表现稳定,进而验证了其良好泛化能力。
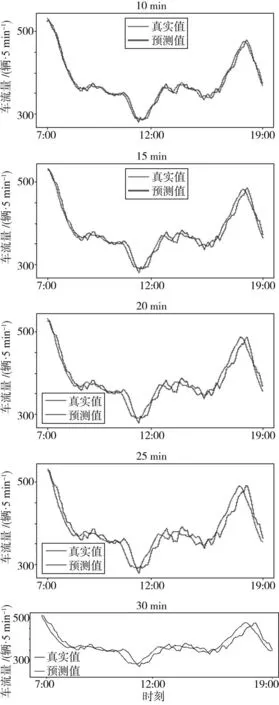
图17 道路交通卡口流量数据集MF-AGTCN预测结果

图18 出租车流量数据集MF-AGTCN预测结果
5 结论
本文中提出了基于多源数据的特征工程和时空预测模型相结合的车流量预测方法,该方法从外部特征、空间特征和时间特征的角度建立车流量预测模型,其中基于图表示学习SDNE模型的空间特征提取模型与基于出租车历史轨迹的空间权重模型的引入,改善了空间依赖性特征的提取能力,有利于提高模型对复杂交通系统的适用性。多组对照实验结果表明,MF-AGTCN预测模型实现了预测精度的提升,并具有良好的泛化能力,同时还改善了对长序列数据的学习能力,使模型具备更优异的中长时预测性能。
