基于OCR的中文债券图表数据检测和文本识别
2021-12-10张宁静袁书培吴海龙
张宁静,袁书培,吴海龙
(南华大学计算机学院,衡阳 421000)
0 引言
关于光学字符识别(optical character recogni⁃tion,OCR),是指将图像上的文字转化为计算机可编辑的文字内容。近年来,OCR检测与识别因其在诸多领域存在着较大的实际引用,使其逐渐成为计算机视觉领域的重要任务。尤其是在金融领域的应用则更加广泛,对于上市公司发布的公告、财报、研报等不可编辑的PDF金融文档,需要做结构化处理并抽取还原,提取关键信息供需要的用户参考。OCR检测识别技术主要有两个核心子任务——OCR文字检测和OCR文字识别。
在深度学习技术得到发展并大力推广之前,传统的文字检测方法通常主要依赖于从输入图像中提取手工设计的特征向量。连接组件分析标签[1-2]和滑动窗口[3]等方法被广泛用于该任务。目前,随着深度学习技术的发展,OCR检测识别技术都得到了显著的改善。不同于传统的OCR检测技术框架[4],现有的OCR检测模型主要有基于分割的检测模型和基于回归的检测模型的两大类模型。依赖于深度学习的OCR文字检测一般用到的模 型 算 法 主 要 有CTPN[5]、RRD[6]、DB[7]、EAST[8]、SegLink[9]、PixelLink[10],等。
传统的OCR识别过程主要分为两步:单字切割和分类。而目前基于深度学习的文字识别主要是端到端的文字识别,即不需要显式进行文字切割,而是将直接文字识别转化为序列学习问题。现今基于深度学习的端到端OCR技术有两大主流技术:CRNN OCR[11]和Attention OCR[12]。其主要区别在于翻译层的不同。这两大主流技术在其特征学习阶段都采用了CNN+RNN的网络结构,CRNN OCR在对齐时采取的方式是CTC算法,而Attention OCR采取的方式则是Attention机制。
本文以百度PaddlePaddle平台(以下简称飞桨)为对比对象,在飞桨提供的两款场景文字识别服务(Attention、CRNN-CTC)中均未包含有金融债券文本识别的情景分类,同时使用通用场景识别的模型经过我们实验,其结果也不让人满意。
本文的工作主要有重新搭配算法与模型并训练出适用于金融债券文本信息场景的模型,使其可以针对金融债券文本信息提供精准的结构化识别;考虑债券的非定性特征,如多印章、数字密集、标点符号的精准识别,以及环境因素,比如非扫描条件、有折痕、有污点等情况下系统的容错性及适配性。
1 数据集构建
1.1 数据准备
我们通过对于金融文档、金融图表的相关调研,经过对数据集的对比分析与筛选,我们将中文版的金融债券图表数据集的数据源确定为了中国债券信息网。
1.2 数据扩充
针对检测问题,从金融债券的实际业务场景出发,我们收集了四大种类的债券集(三线、无线、有框、长文本),同时从网上以及手工处理收集了1000余张图片。将其按照类别进行划分并进行手工标注,以此来扩充数据集。用以解决神经网络拟合是数据过少,预测精度不高的问题。

图1 文本检测数据扩容
而增对文本识别问题,我们首先使用了YCG09的chinese_ocr数据集,数据集包括100万的数据集,含汉字、英文字母、数字和标点共5990个字符,同时我们又手工扩充了2万张的数字标注,以期其在数字分隔符号上取得更好的效果,使用paddle提供的字典ppocr_keys_v1,共计6623个字符。

图2 文本识别数据扩容
1.3 数据增强
通过对业务场景和数据进行分析研究还发现,在债券文本多印章的场景下,被印章覆盖住的数据难以准确地识别出来,并且多印章出现的概率也不小。这可能会导致检测模型在实际业务场景下效果不佳,所以我们以手工合成以及网络搜索的方式增加了一些印章密集的情况,来对数据集进行增强,这可以很好地提高模型对被覆盖文本的的检测效果。
图3 数据增强-多印章示例
除了使用以上的方式,针对识别模型,我们还使用了PaddleOCR提供的数据增强方式,还使用了颜色空间转换(cvtColor)、模糊(blur)、抖动(jitter)、噪声(gasuss noise)、随机切割(random crop)、透视(perspective)、颜色反转(reverse)等数据增强手段。在训练过程中每种扰动方式以50%的概率被选择。
1.4 数据处理
整体债券图表数据集我们将其分为4部分,其中第一数据集为预训练练数据集(约占10%,100张),用于同时初步训练多个算法模型,然后对比选择出最适合的算法模型;第二数据集为模型优化训练数据集(约占60%,600张),用于进行集中训练并优化模型,最后的成果模型;第三数据集为定量测试数据集(约占25%,250张),用于对模型进行定量测试,检测模型的训练效果;第四数据集(约占5%,50张),则用于进行定性多场景测试实验。测试模型在不同条件下的极端情况。各部分数据集我们又根据债券图标的类型对其进行了二次划分,其中包括有框表、三线表、无框表(分别占比4∶3∶3)
除了以上的债券图表数据集,为了训练识别模型,我们又引入了100000种文字数据集用于模型对于文字的识别训练以保证5000种文字的训练效果。
对于训练集,我们在进行分类后又借助PPOCRLabel进行了半自动人工标注[13]。
图4 PPOCRLabel界面
2 算法实现
2.1 算法选取
考虑到我们的系统检测识别目标是中文债券图标,是针对以简体中文、数字为主,及少量英文的文字进行检测识别,且部署在移动端。经过分析,我们初步选取了DB,EAST网络框架作为预训练的OCR检测模型框架和CRNN+CTC模型框架作为预训练的OCR识别模型框架。借助模型预筛选数据集,我们分别就检测和识别中同类型的模型进行统一的预训练,结果表1—表2所示。
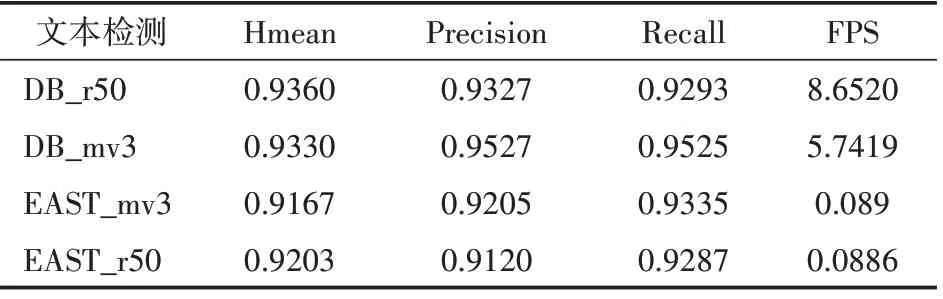
表1 OCR检测模型

表2 OCR识别模型
通过对筛选出了性能较优的模型DB_mv3及CRNN_mv3分别作为检测和识别模型算法,随后对他们进行了完整及系统的优化。
2.2 OCR检测算法
本文的债券图表检测模型主要以DBNet模型为大体框架,本系统以基于轻量级主干网络Mo⁃bileNetV3 Large[14]作为backbone,同时添加目标检测中常用的特征增强方案FPN[15]结构作为neck,类似于U-Net结构,最后添加了三层卷积作为head。
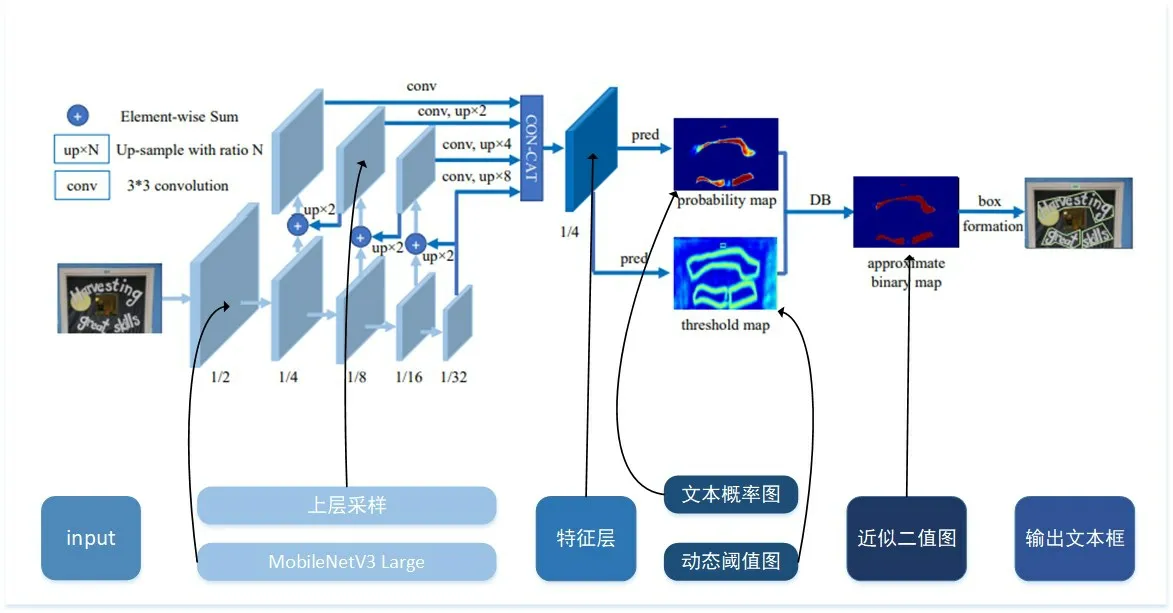
图5 DBNet模型结构
2.2.1 使用MobileNetV3 Large作为FPN网络体系中的卷积神经网络
我们在backbone部分主要搭建MobileNetV3 Large主体结构代码,其中需要注意的是,因为后边需要采用FPN结构,所以相比于原始的网络结构,这里搭建过程中获得了四个分支的输出,用于后续FPN结构。
if model_name=="large":
cfg=[
#k,exp,c,se,nl,s,
[3,16,16,False,′relu′,1],
[3,64,24,False,′relu′,2],
[3,72,24,False,′relu′,1],
#获得这一层的输出:c2
[5,72,40,True,′relu′,2],
[5,120,40,True,′relu′,1],
[5,120,40,True,′relu′,1],
#获得这一层的输出:c3
[3,240,80,False,′hardswish′,2],
[3,200,80,False,′hardswish′,1],
[3,184,80,False,′hardswish′,1],
[3,184,80,False,′hardswish′,1],
[3,480,112,True,′hardswish′,1],
[3,672,112,True,′hardswish′,1],
#获得这一层的输出:c4
[5,672,160,True,′hardswish′,2],
[5,960,160,True,′hardswish′,1],
[5,960,160,True,′hardswish′,1],
#获得这一层的输出:c5
]
cls_ch_squeeze=960
具体连接结构如图6所示。
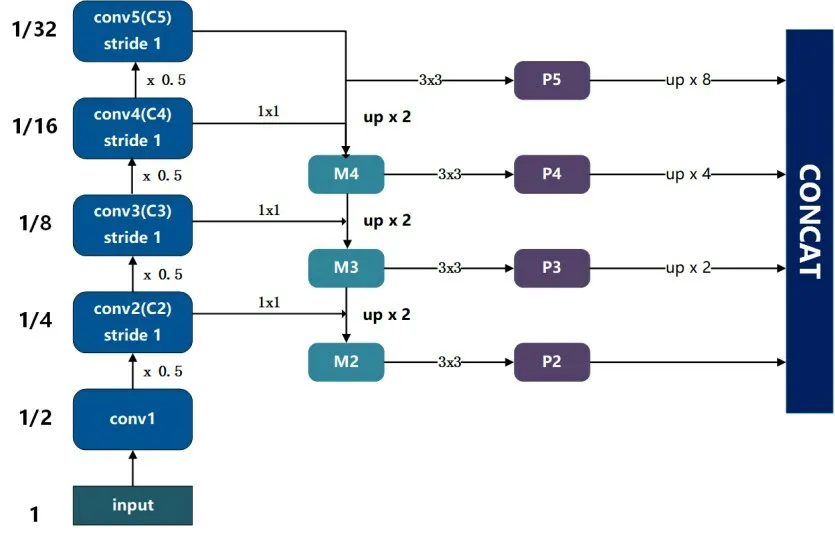
图6 MobileNetV3 Large在FPN网络体系中的应用
2.2.2 用普通卷积替代了可变形卷积(deformable convolution)
在DBNet中的backbone里一般会默认将3×3 conv替换成可变形卷积,以此可以使得卷积操作的位置会在监督信息的指导下进行选择,可以较好地适应目标的各种尺寸,提供更加丰富的感受野,这对于极端比例的文本检测效果有益,但是同时也带来大量复杂的计算量的弊端。而针对我们的检测目标是文本框,文本框的比例通常较为正常,因此,此处我们选择保留普通卷积,以减少不必要的计算量。
2.2.3 DBNet算法的特点:可微分二值化处理(differentiable Binarization)
标准二值化处理:
一般使用分割网络(segmentation network)产生的概率图(probability map P),将P转化为一个二值图P,当像素为1的时候,认定其为有效的文本区域,同时二值处理过程:

但是标准的二值处理是不可微的,这样分割网络不可以在训练过程中优化,故在DBNet算法中采用了可微分二值化:
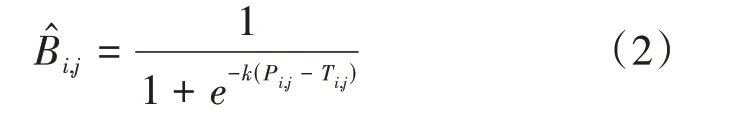
其中:̂是近似二值图,T是自适应阈值图,k是膨胀因子。
一般习惯性设置k=50,带有自适应阈值的可微分二值化不仅有助于把文字区域与背景区分开,而且还能把相近的实例分离开来。
2.2.4 Loss损失函数
损失函数是通过概率图损失L s-二值图损失L b-阈值图L t构成的带有权重的损失。
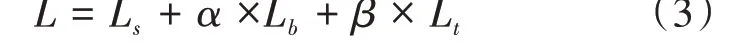
其中α和β我们分别设为5和10。
L s使用dire_loss函数和L b使用二值交叉熵损失函数:

其中S l代表正负样本比例为1∶3的样本集。
L t为平滑后的L1损失,为了避免样本不平衡的问题,只计算G d内部的值

2.2.5 在MobileNetV3中利用h-swish代替swish
使用swish当作为ReLU的替代时,它可以显著提高神经网络的精度,但是在嵌入式环境中,成本太大,而我们的模型是基于移动端设计的,所以选择了h-swish。但是由于大量采用h-swish会引入延迟,因此我们网络前半部分的激活函数仍采用ReLU,后半部分则采用h-swish。
2.3 OCR识别算法
我们系统基于CRNN模型,本系统以基于轻量级主干网络MobileNetV3 Small[14]作为backbone进行图像特征序列的提取,同时添加RNN结构作为neck预测每帧的标签分布,CTCHEAD作为head。

图7 CRNN+CTC模型结构
在Borisyuk等人[16]提出“Rosetta”新型人工智能系统中,该系统文字检测和识别的模型也是基于CRNN框架,但是采用了轻量级的backbone,在效率与性能上都有不错的表现。同时,我们对本系统的预设是建立在轻便简洁、操作友好的移动端,期望识别算法是精度相对高而相对轻量能在移动端运行。
基于之前检测模型设计,发现MobileNetV3是一种良好的轻量级主干网络,MobileNetV3 Small在众多数据集上虽然识别延迟高于Mobile⁃NetV3 Large,但是识别精确度要高于Mobile⁃NetV3 Large,由于对精确度比延迟的需求高,因此我们选择了MobileNetV3 Small作为backbone。
2.3.1 Map-to-Sequence的实现
我们不能直接把CNN得到的特征图送入RNN进行训练的,而是需要进行一些调整,根据特征图提取RNN需要的特征向量序列。首先从CNN模型产生的特征图中提取特征向量序列,每一个特征向量在特征图上按列从左到右生成,每一列包含c维特征,这意味着第i个特征向量是所有的特征图第i列像素的连接,这些特征向量就构成一个序列,作为循环层的输入,每个特征向量作为RNN在一个时间步(time step)的输入。
2.3.2 BiLSTM的状态更新公式
本文采用的双层双向LSTM按时序展开如图8所示(图中省略了内部状态c t,⊕为向量拼接操作)。
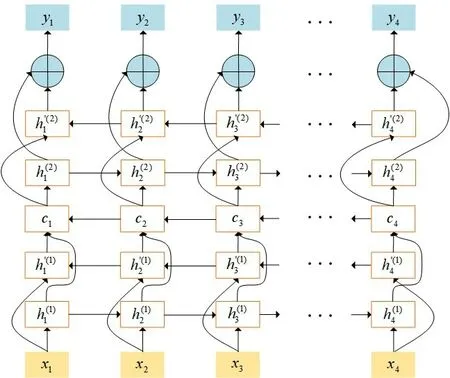
图8 双层BiLSTM时序展开
状态更新公式如下:
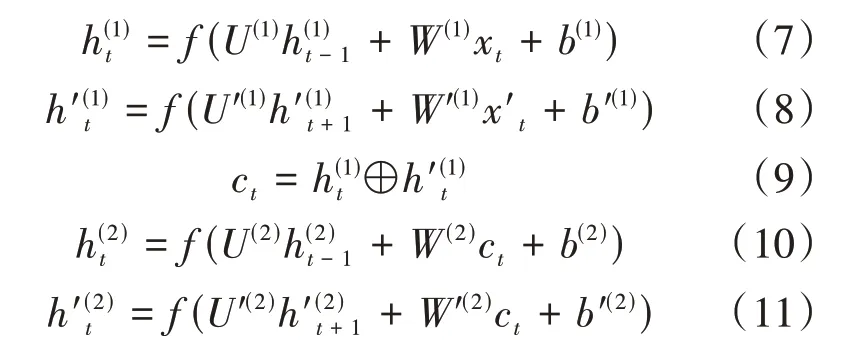
比较简单直观地可以看到t时刻第一层Bi L⁃STM的第一层(顺时间循环层)的隐状态h(1)t取决于前一时刻的隐状态h(1)t-1和输入值x t,但是需要特别注意的是第二层(逆时间循环层)的隐状态h′(1)t则取决于后一时刻的隐状态和输入值x t。
2.4 模型部署
本文模型部署在飞桨的AI Studio上,AI Stu⁃dio是基于百度深度学习平台飞桨的人工智能学习与实训社区,提供在线编程环境、免费GPU算力以及数据模型可视化VisualDL服务。我们还使用Baidu推出的PaddleOCR工具进行优化部署,PaddleOCR工具对该文本检测训练数据提供了如随机旋转角度(-10°,10°)、随机裁剪(做透视变换和旋转)、随机翻转的数据增强的方式,每种扰动方式以50%的概率被选择。
3 实验结果分析
3.1 定量统计结果
本项目根据收集的数据训练集,其中包括1000张检测图片及1000000张中文文档数据的识别图片,经过数据集划分后进行训练,训练结果如下图所示。
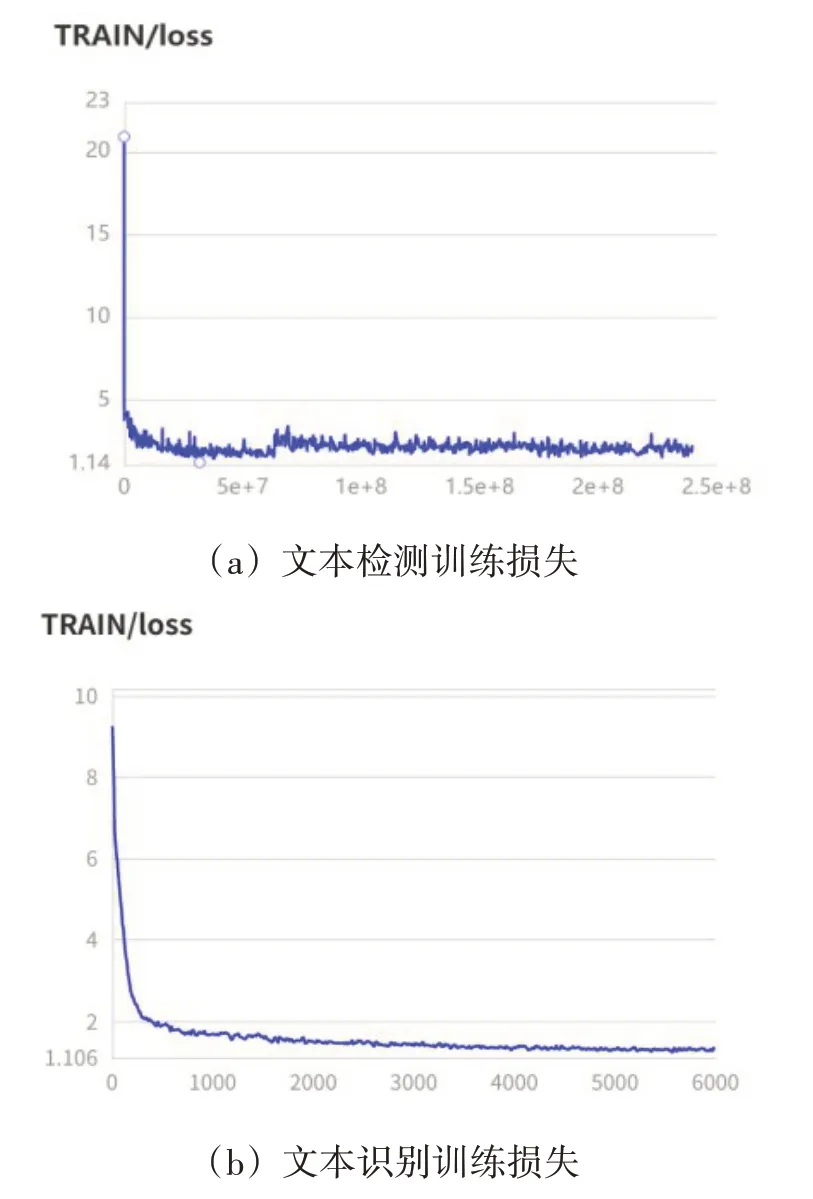
图9
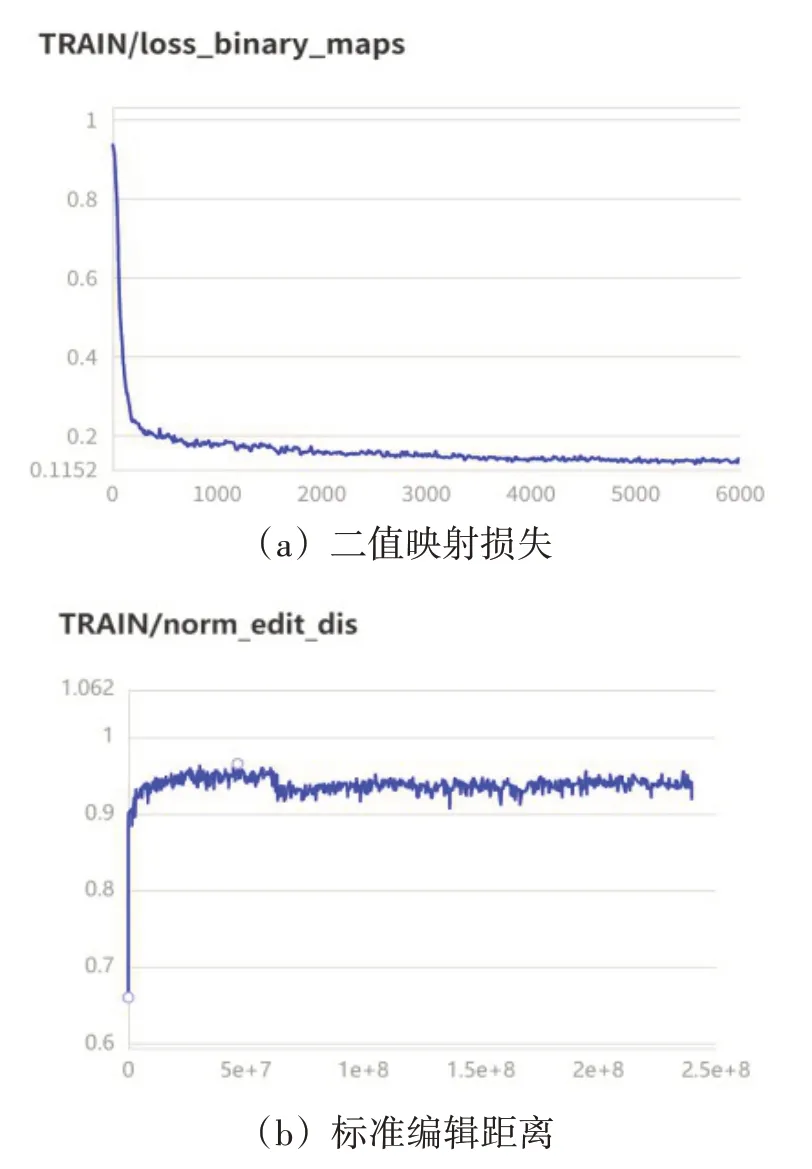
图11
同时对于训练所得的模型,50张检测图片和2000张识别图片。将训练所得的模型用于测试集上进行验证,在IoU阈值为0.5的标准下,测试结果如表3—表4所示。

表3 DB_mv3测试结果

表4 CRNN_mv3测试结果
3.2 定性多场景实验结果
(1)多印章类型文档。指印章比较多的债券图标文档。
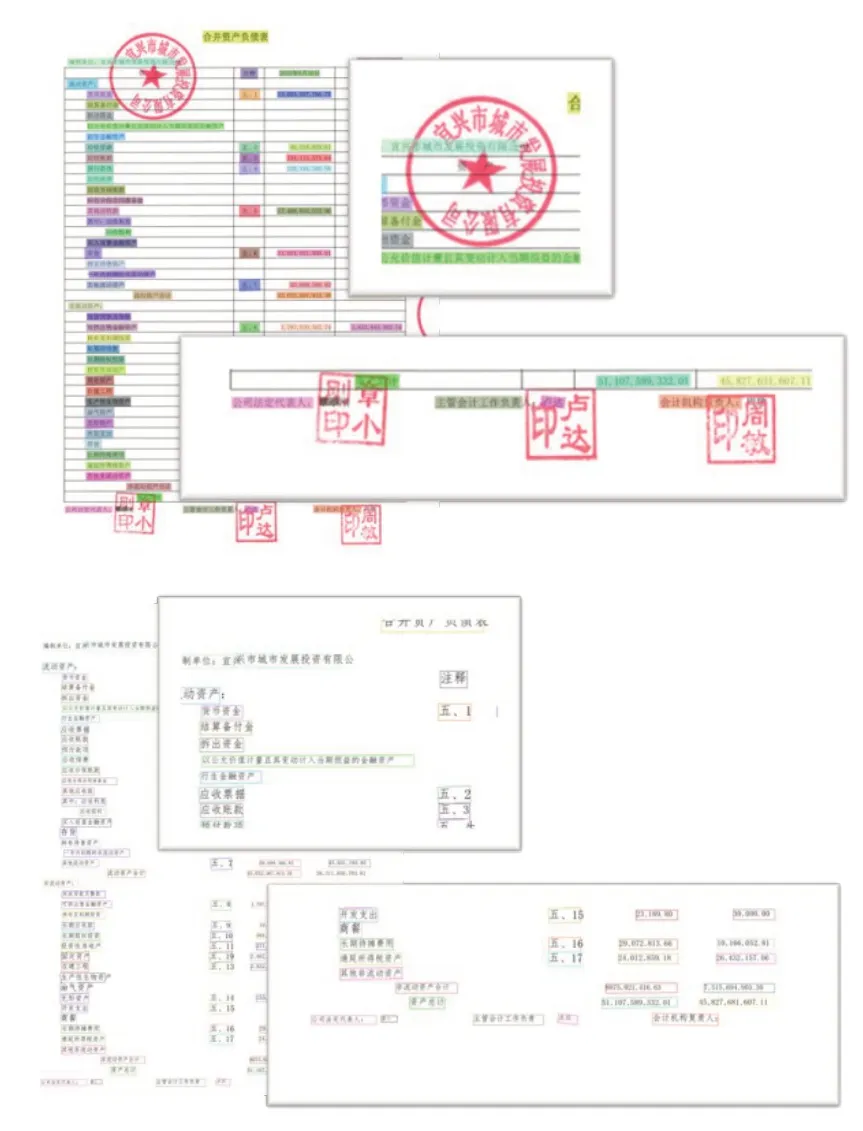
图12 多印章类型文档的检测识别结果
(2)过挤压类型文档。指存在表格线框挤压表格内文本文字情况的债券图标文档。

图13 过挤压类型文档的检测结果
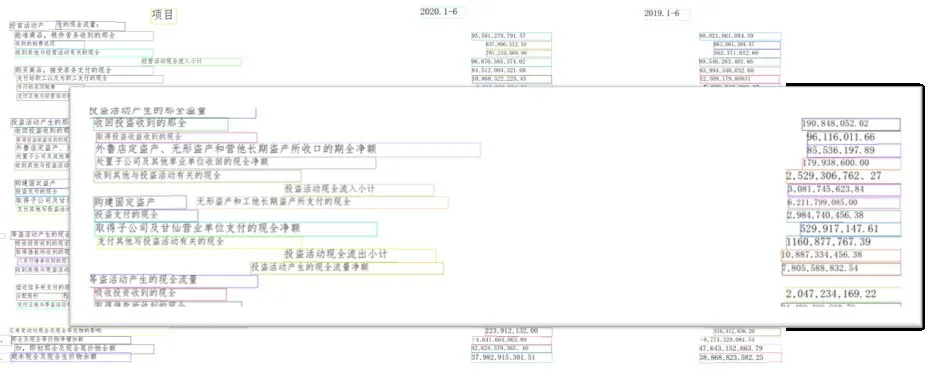
图14 过挤压类型文档的识别结果
(3)扭曲类型文档。指不平整的债券图标文档。
图15 扭曲类型文档的检测识别结果
(4)折痕类型文档。指有折痕印记的债券图标文档。

图16 折痕类型文档的检测识别结果
(5)污点类型文档。指存在污点污迹的债券图标文档。


图17 污点类型文档的检测识别结果
4 结语
本文采用海量的数据集并且进行了半人工化的标注,经过调查研究以及通过训练的低数据集下的通用模型后,选择了兼顾精度和效率的模型,文本检测模型DB_MV3以及CRNN_MV3,并对通用模型进行了优化和改良。在移动端离线部署的情况下,检测识别精度和效率经过实验证明也较为稳定。
普通CPU环境即移动端离线情况下,单个大图片的预测时间平均为2 s左右,而移动端联网条件下,为了使检测服务并发进行,我们使用了springcloud部署该项目,构建多个检测服务后台,将检测服务作为微服务集群,然后通过负载均衡使其满足需求。本项目能在基础环境下能够实时运行且能同时满足多个用户的检测服务。目前算法检测识别时间离线和联网主要取决于债券图表的文字密集程度和图片数据压缩上传速度,后续希望可以从这两个角度进行改进以降低检测识别所耗费的时间。
