基于多头自注意力机制的深度缺陷分派模型
2021-12-09万发洋徐其江
万发洋,于 旭,徐其江
(1.青岛科技大学信息科学技术学院,山东 青岛 266061;2.山东信息职业技术学院,山东 潍坊 261061)
0 引 言
缺陷是破坏程序正常工作并使系统功能失效的软件错误。伴随着规模和复杂度的增加,大型开源软件通过缺陷跟踪系统(如Bugzilla和JIRA)管理缺陷,不断实现对缺陷报告的记录、管理以及状态更新。当前,大多数缺陷报告都是手动处理的,系统管理人员必须逐个检查缺陷报告,结合历史经验人工分配合适的修复者。这对于大型开源软件项目是一项劳动密集的任务。例如,在Eclipse中,每天都能收到大约100个新提交的缺陷报告,而系统内存在具有不同专业知识的1800名修复者。
为了合理利用缺陷跟踪系统的人力资源,Cubranic等人[1]提出了一种自动缺陷分派技术,通过学习历史数据将缺陷分配给一组最具专业技能的修复者。进而,学者们提出了一系列有关机器学习、信息检索和深度学习的缺陷分派方法。机器学习方法[2-4]将修复者视为类别,通过训练分类器为缺陷报告分派合适的修复者标签。Tamrawi等人[2]提出了一种基于模糊集的Bugzie方法,修复者对集合的隶属度通过术语相关性来表示,并使用它们来衡量修复者是否适合新的缺陷报告。Xuan等人[3]提出了一种半监督的缺陷分派方法,通过期望最大化算法增强朴素贝叶斯分类器对已分派和未分派缺陷的分类能力。信息检索方法[5-11]将缺陷报告作为查询,修复者作为返回结果,根据新提交的缺陷报告与历史缺陷报告之间的相似性对修复者排序。Tian等人[5]提出了一种基于排序模型Learning to rank的缺陷分派方法。结合缺陷报告的内容信息和源代码的定位信息识别合适的修复者处理特定的缺陷报告。Gay等人[6]提出了一种基于概念定位的IRRF缺陷分派方法,通过信息检索与相关性反馈机制的结合,计算缺陷报告与源文件在空间向量模型上的相似度。深度学习方法[12-17]通过神经网络的优异特征学习能力对数据有更本质的刻画,从而进行缺陷分派任务。Lee等人[12]首次将卷积神经网络应用于缺陷分派,将文本内容转换为高层特征,训练一个预测模型返回每位修复者被分派的概率。Mani等人[13]为了挖掘文本内容中存在的序列关系,应用循环神经网络并结合双向长短期记忆单元,提出了一种带有注意力机制的缺陷分派模型。除此以外,学者们还着手研究系统中关系模型对缺陷分派的影响[18-22]。
基于目前的缺陷分派研究,发现依然存在一些不足。首先,以往的模型过于依赖缺陷报告的文本质量,质量的高低直接影响缺陷分派的结果。图1表示缺陷报告ID为485038的部分文本描述。据统计,报告共83行、5307个字符。冗余的描述并不利于缺陷的准确定位,极大地增加了缺陷修复的工作量。其次,缺陷跟踪系统作为一个群智化的修复平台,包含多个不同的修复者社区,社区由具有相似的专业技能和开发活动的修复者组成。然而,缺陷报告中的元字段(如产品、构件等)作为筛选修复者社区的重要分类标签大多被以往的模型所忽视,并未考虑社区因素对缺陷分派的影响。图2表示修复者joakim.erdfelt和jesse.mcconnell在同一时间段的修复历史,可以发现2名修复者经常参与产品Jetty的缺陷,属于共同的修复者社区,具有相似的专业技能和开发活动。
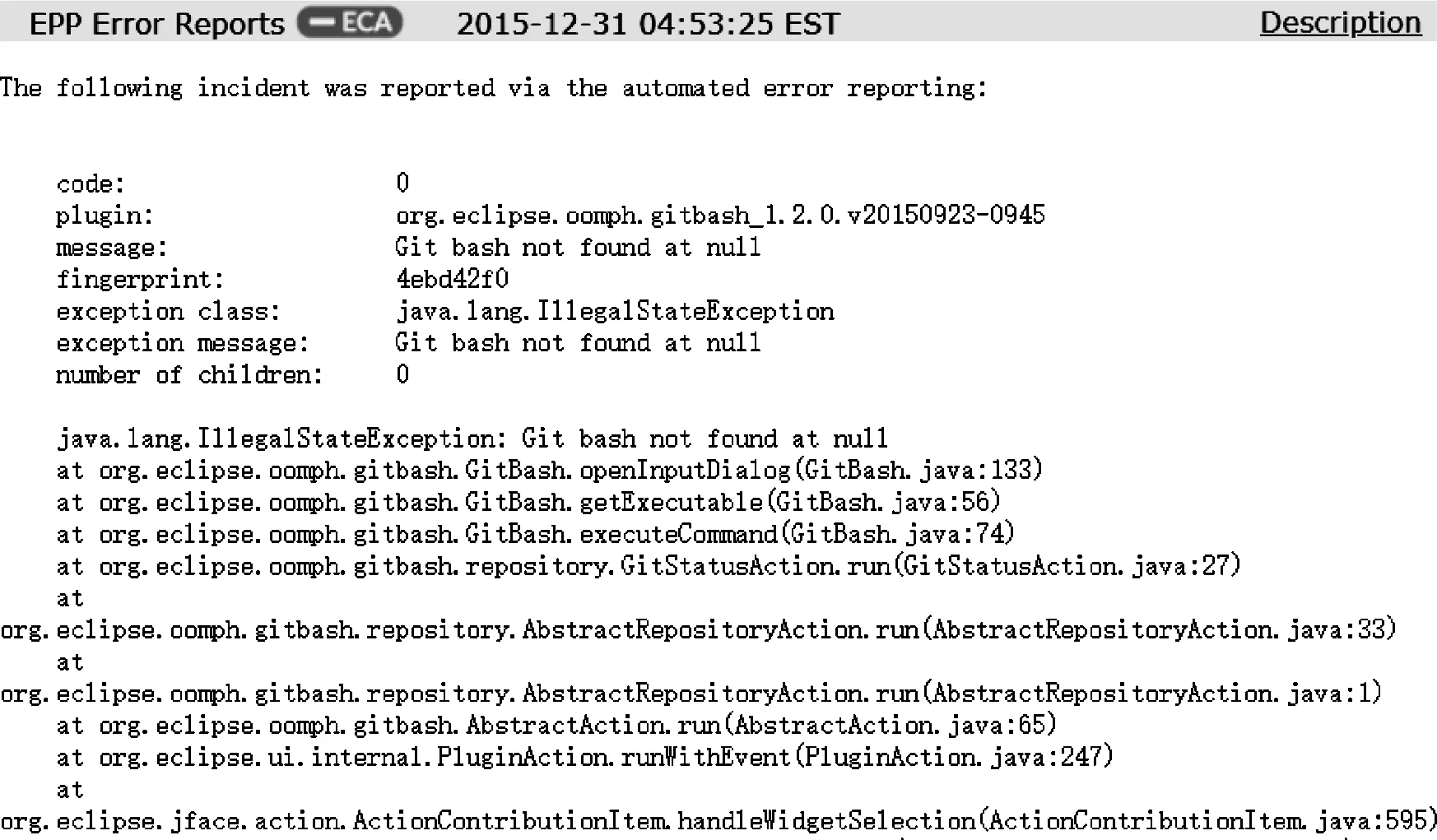
图1 缺陷报告ID为485038的部分文本描述

图2 joakim.erdfelt和jesse.mcconnell的修复历史
基于以上问题,本文提出一种基于多头自注意力机制的深度缺陷分派方法MSDBT,不仅考虑缺陷报告的文本内容,还根据产品、构件生成相同元字段的修复者序列,探究具有相似的专业技能和开发活动的修复者社区对缺陷分派结果的影响;采用双向循环神经网络抽取输入文本和修复者序列中的高层特征;最后,采用多头自注意力机制在内部的输入元素之间进行并行注意力计算。本文弱化缺陷报告文本中的冗余信息,并通过修复者序列进一步量化社区因素对缺陷分派的影响。
1 相关工作
1.1 缺陷报告
缺陷报告作为缺陷跟踪系统管理缺陷的基本单元,由元字段和文本内容组成。其中元字段是预先定义的属性标签,便于开发人员对缺陷报告的分类和查找;文本内容是开发人员对缺陷的自然语言表述,是以往工作的主要信息来源。元字段和文本内容的组成和含义如表1所示。
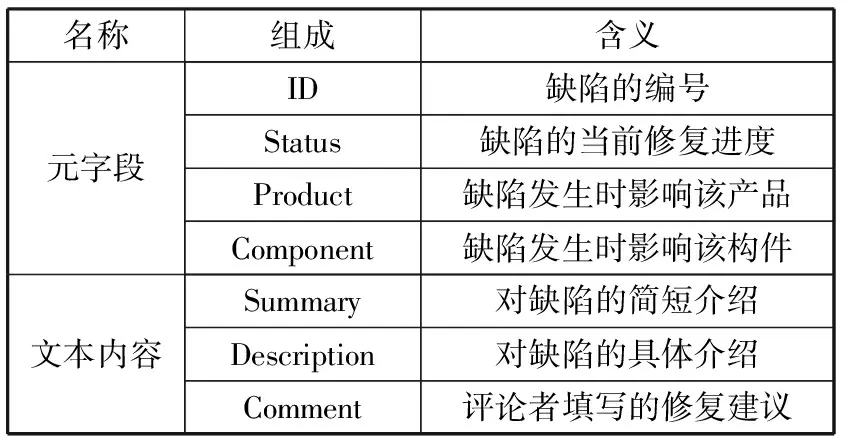
表1 元字段和文本内容的组成和含义
1.2 词嵌入模型
Word2Vec作为一种基于神经网络的词嵌入模型,将自由格式的文本作为输入转换为词向量,捕获文本中单词间的关联关系,对词汇以分布式向量的方式来表示。这不仅避免了矩阵稀疏的问题,还量化上下文之间的类比关系,挖掘出语义层面上的关联信息。模型训练的目标是最大化当前词wt在语料库的术语集合T上生成邻居词wt+j的条件概率p(wt+j|wt):
(1)
其中,c是当前词wt周围邻居词的集合大小。
2 MSDBT模型
MSDBT的框架由输入层、特征抽取层、多头自注意力层、输出层组成。模型不仅弱化文本中的冗余信息,还通过社区因素进一步量化具有相似活动的修复者对缺陷分派的影响。输入层实现对数据的特征嵌入;特征抽取层实现文本内容和修复者社区的特征计算;多头自注意力层综合内部特征计算特征对结果的贡献程度;输出层计算为修复者分派缺陷报告的概率。
2.1 输入层
针对缺陷报告的文本内容和修复者社区,本文利用Word2Vec和one-hot编码将其转变为实数向量。
对于缺陷报告的文本内容,本文利用Word2Vec生成k维术语向量,术语在语义上的相似度通过向量的相似度来表征。其表达式为:
E=[e1,e2,e3,e4,…,el]
(2)
其中,设置文本序列的最大长度为l,ei为文本中第i个术语的特征表示,每个缺陷报告的文本内容生成大小为l×k的词向量矩阵E。
对于修复者社区,根据元字段中的产品和构件生成保留社区因素的修复者序列,并通过one-hot对修复者进行编码。例如Ed Merks、Dirk Fauth、Nathan Ridge参与产品JDT的修复者社区,假设Ed Merks、Dirk Fauth、Nathan Ridge、Grant Gayed是整个系统的修复者,则产品JDT的修复者社区编码F为:
F=[[1,0,0,0],[0,1,0,0],[0,0,1,0]]
(3)
2.2 特征抽取层
针对输入层提交的词向量矩阵和社区编码,特征抽取层连接两者生成输入矩阵X,通过双向长短期记忆网络挖掘前后2个方向的特征,更加全面地对输入内容进行特征抽取。双向长短期记忆网络是由LSTM单元组成双层神经网络,通过遗忘门、输入门、输出门决定细胞状态的保存程度和当前输入的记忆程度。
LSTM的第1步是通过遗忘门决定之前细胞状态Ct-1的丢弃程度。计算之前隐藏状态ht-1和当前输入xt的Sigmoid函数。其中,Wf表示遗忘门对应的权重矩阵,bf表示常数向量。
ft=σ(Wf·[ht-1,xt]+bf)
(4)
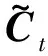
it=σ(Wi·[ht-1,xt]+bi)
(5)
(6)
下一步,根据前2步的输出计算信息的丢弃和更新,确定当前的细胞状态Ct。
(7)
最后,基于细胞状态确定输出信息,首先,通过输出门计算之前隐藏状态ht-1和当前输入xt的Sigmoid函数,决定哪些信息需要输出。其次,利用tanh函数规范细胞状态Ct并将其乘以输出门的值,确定当前单元的输出ht。其中,Wo表示输入门对应的权重矩阵,bo表示常数向量。
ot=σ(Wo·[ht-1,xt]+bo)
(8)
ht=ot·tanh(Ct)
(9)
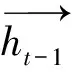
(10)
最终,综合输入矩阵X获得特征抽取层的输出序列S。
S=[s1,s2,s3,s4,…,st]
(11)
2.3 多头自注意力层
考虑到文本内容的冗余信息和修复者社区对缺陷分派的影响,本文通过多头自注意力机制[23]强化特征抽取层在不同时刻的输出序列S的关键特征,每个时刻的注意力表示对分类结果的贡献程度,如图3所示。多头自注意力利用多次并行查询从输入信息中提取到多组不同子空间进行相关信息的获取,从多方面捕获序列的关键信息。其计算方式如下:
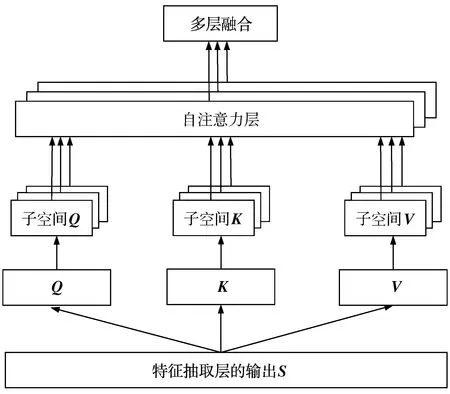
图3 多头自注意力层结构
首先,将特征抽取层的输出S线性变换生成查询向量矩阵Q、键向量矩阵K、值向量矩阵V。其中,WQ、WK、WV为转换矩阵。
(12)
将Q、K、V投影到h个不同子空间。其中,WQi、WKi、WVi分别为Q、K、V的第i个转换矩阵。
(13)
通过缩放点积对Qi和Ki进行内积运算,并使用softmax函数归一化后与Vi相乘得到单头的注意力值headi,并行地在h个子空间上计算注意力。其中,d是缩放因子,将Q、K的内积变为标准的正态分布。
(14)
最后,融合所有子空间的注意力值。其中,WO为转换矩阵。
A(Q,K,V)=Concat(head1,…,headh)WO
(15)
2.4 输出层
输出层采用softmax分类器计算每名修复者的概率。其中Wd为转换矩阵,bd为实数向量。
(16)
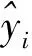
(17)
3 实 验
3.1 数据集
本文使用的数据集是开源项目Eclipse、Mozilla、Netbeans、GCC中的缺陷报告集合。由缺陷的生命周期可知,新修复的缺陷是不稳定的,易出现再分派的情况,所以选取状态较为稳定的历史缺陷来分析(即解决方案为“已修复”,报告状态为“关闭”、“已解决”、“已验证”),提交时间至少是4年前。为减少噪声,删除参与次数少于10次的修复者。经过筛选后,数据集包含38152个缺陷报告、1609名修复者。
3.2 度量指标
为了评价实验结果推荐精度,本文使用召回率Recall@K进行度量,这类度量指标已在先前的相关工作中广泛使用[1,3-4],计算公式为:
(18)
假设共存在q个待推荐的缺陷报告,对于每个缺陷报告,Di表示缺陷报告中真实参与的修复者集合,Pi表示本文模型推荐的修复者集合。K表示推荐修复者的集合大小,在这里K=5。
3.3 对比方法与实验设置
本文设置3种方法作为对比方法:
1)SVM[4]使用支持向量机来完成缺陷报告文本分类的经典方法。
2)MTM[8]根据缺陷报告的元字段,以监督的方式更新修复者在各个主题的比例。
3)DT[14]结合文本与修复者活动序列,循环神经网络使用文本特征与活跃度进行修复者的类别分配。
对于本文模型的参数设置,文本长度设置为300,并通过补零或截断进行文本内容调整,Word2vec生成的向量维度设置为256。Bi-LSTM神经网络的隐藏层神经元个数为300。多头注意力机制独生成12个线性子空间,每次的输出维度都是128维。
3.4 实验结果
实验为了比较本文提出的MSDBT模型与已有模型在缺陷分派上的准确性,如图4所示,MSDBT在4个数据集上Recall@5的平均值为0.6375,相较于SVM,提升了8.97%。相较于MTM,提升了7.64%。相较于DT,提升了3.76%。结果表明,本文模型的召回率指标优于对照的方法。
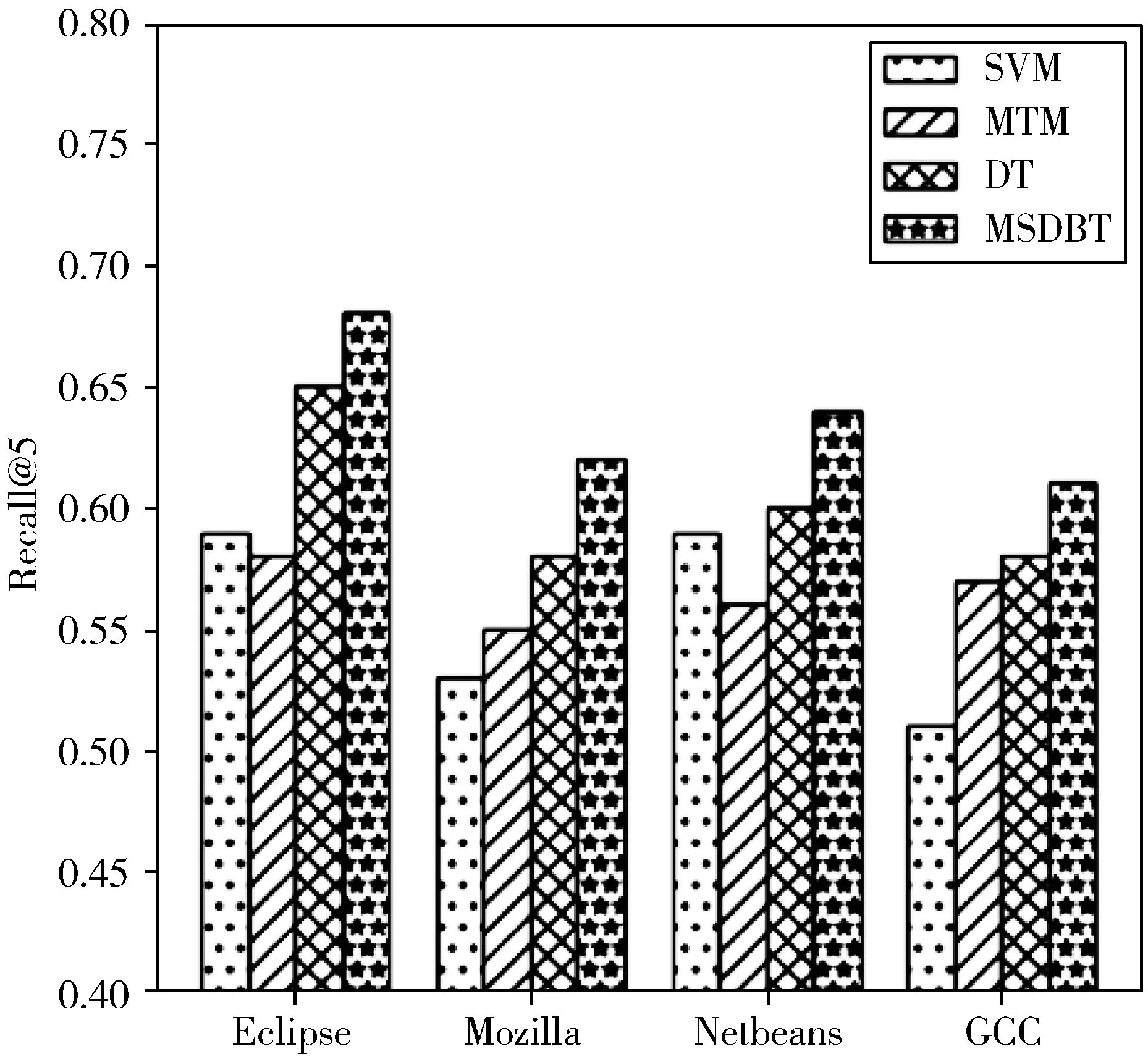
图4 MSBDT及对比方法的实验结果
4 结束语
本文针对缺陷的修复者推荐问题,提出了一种基于多头自注意力机制的缺陷分派模型MSDBT。从文本描述和元字段这2个角度出发,采用双向长短期记忆网络提取文本和修复者序列的特征,并使用多头自注意力机制进一步在内部元素之间计算并行注意力。弱化文本内容中的冗余信息的同时增加修复者社区对缺陷分派的影响。本文在4个大型开源项目的数据集上进行验证,实验结果表明,本文模型较经典的缺陷分派方法具有明显优势。在未来的工作中将考虑不同数据类型的影响、系统的动态变化以及不同数据集之间的跨域分析,进一步提升缺陷分派模型的性能。
