基于空间大数据及机器学习的红壤数字制图研究*
2021-12-09杨阳叶江霞王艳霞蔡志勇周汝良
杨阳,叶江霞,王艳霞,蔡志勇,周汝良
(1.西南林业大学 地理与生态旅游学院,云南 昆明 650224;2.西南林业大学 林学院,云南 昆明 650224;3.中航通飞研究院有限公司/中国特种飞行器研究所,广东 珠海 519000)
土壤多样性与生物多样性联系紧密[1]。无机环境所代表的生境多样性是形成生物群落多样性的基本条件[2],土壤多样性的精确研究取决于土壤类型与属性的数字化精确调查,土壤类型是土壤数字化调查的重要内容,前人研究表明,土壤类型是影响土壤生态系统和土壤生物活动的主要因素[2]。明确土壤类型的精确分布,是土壤生态系统多样性研究的前提和基础[1],也是生态修复工作的前提[3]。数字土壤地图将为生态保护、精准农业的研究和应用等提供新的科技手段。当前,我国的土壤类型图仍然是以第二次土壤普查数据为主,土壤类型图为手工绘制,误差相对较大[4-6]。随着大数据时代的来临,各种生态环境因子的数字化工作都需要更精确的数字化土壤类型图。数字土壤制图作为土壤制图的新方法,具有省时省力、精度较高的优点[4-5,7]。决策树与随机森林模型是数字土壤制图中的常用方法,可以很好的捕捉土壤与环境的非线性关系,如:张振华等[8]利用包括决策树与随机森林在内的3种机器学习方法,对新疆渭干河三角洲土壤pH等3种属性进行建模;周紫燕等[9]利用随机森林模型对小流域土壤图进行了更新;陈芳[10]利用随机森林模型建立了湖北省枣阳市的土壤类型图,并认为土壤类型图与实际结果中等吻合(Kappa=0.59)。当前,树形模型在数字土壤领域应用依旧较少,且局限于土壤元素或有机质建模中[9],尤其少见于土壤类型制图。仅有的土壤类型制图研究中,多是以行政区域为边界的小尺度尝试,缺乏以自然地理区域为研究对象的较大尺度研究,树形模型在大尺度区域应用的效果还有待深入研究。
红壤是我国亚热带和热带地区土壤受到中度富铁铝化作用的产物[11],是滇中高原的基带土壤,广泛分布于曲靖、昆明的大部分地区,文山、红河、玉溪的北部等地区。红壤土体深厚、质地黏重、胶而不板,盐基不饱和,土壤pH<7,养分含量低[12]。红壤的主要植被类型是亚热带常绿阔叶林,以云南松(Pinusyunnanensis)为主要次生植被。前人研究[13-15]通过典型剖面研究了红壤的理化性质、发生过程和农业活动状况。张芸萍等[13]使用决策树和多元回归计算了土壤pH与主要养分之间的关系;赵文军等[14]对抚仙湖流域四种土壤的理化性质进行了研究,认为红壤最适合烟草种植;罗亚芬等[15]测量了陆良县典型山原红壤的剖面养分状况。当前的研究主要通过挖掘剖面对滇中红壤的理化性质进行研究,对红壤空间分布的研究相对缺乏。明确红壤的空间分布,对于掌握云南省土壤多样性和土壤生物多样性具有重要的价值。云南省自然地理条件复杂多样,依据元江河谷将云南省分为滇东高原区和滇西横断山纵谷区[16],土壤类型和环境变量之间的关系受到多种环境因素的共同影响,这些环境因素相互耦合,表现出复杂的非线性关系[17]。滇东高原是云南红壤分布最集中的地区,利用树形模型模拟滇东高原红壤分布,对于推广树形模型在大尺度地形复杂区的应用价值具有重要意义,也是将数字化方法引入土壤多样性研究的一次尝试。
1 材料和方法
1.1 研究区概况
云南是典型的亚热带气候区,干湿季分明。植被分布以云南松和常绿阔叶林为主[18-21]。红壤是云南省的代表性土壤,主要分布于24°N~27°N之间的滇中高原及海拔2 500 m以下的中低山和丘陵地区[22]。云南16个州(市)中,红壤分布区包括昆明、曲靖、玉溪、楚雄、大理、保山及丽江南部地区。其中,滇中和滇南是云南省红壤分布最集中的地区。本研究以哀牢山—元江河谷为界,将昆明、文山、曲靖全境,玉溪、红河位于元江河谷以东的区域作为研究区域,依据1∶250万云南省地图划分了研究区,见图1,

图1 研究区的位置
1.2 数据获取
(1)土壤样本数据采集 本研究以云南省1995年土壤分布图为基础选取训练样本,并利用第二次土壤普查[23]和《云南土种志》[24]中所核定的31个土壤剖面信息作为检验数据,训练与检测样点见图2。

图2 研究区DEM及其样点分布
采样原则为:①以1995年云南土壤类型分布图为采样基础,采样样点遍历研究区,采样类型为红壤样本与非红壤样本;②为保证红壤样本采样的典型性,尽量在红壤区中心采样,红壤区与非红壤区交界处1个栅格范围内不作为采样区域;③对于地形复杂区,尽可能多设立采样点。采样点标签为红壤和非红壤,利用采样点数据作为机器学习算法的训练和检验数据。最终得到训练样本1 145个,其中红壤样本916个,非红壤样本229个。
(2)环境因子数据获取 Mcbratney等[25]提出的clorpt方程建议使用土壤发生学理论中的地形、植被因子进行建模预测;朱阿兴等[5]提出较大空间范围内气候因子如年均温度、年均降水等因子可作为气候因子的衡量变量、数字高程模型(digital elevation model, DEM)及其衍生因子可以作为地形因子的主要变量、生物因子主要通过植被影响土壤发育,归一化植被指数(normalized difference vegetation Index,NDVI)是最常采用的因子。通过综合过往文献的变量选择和不同成土因子最有代表性的变量,最终选择了以下变量,归一化后参与建模。
地形数据 全国数字地形模型SRTM DEM 90 m分辨率数据(m)(来源于地理空间数据云http://www.gscloud.cn/),通过ArcGIS利用DEM计算出的全国坡向、坡度(°)、曲率数据、全国地貌隆起切割数据(计算方法来源自专利:CN111127646A)。
气候数据 中国235°西南风场数据来源于文献[26],全国多年平均降水量(mm)和平均温度(℃)数据来源于https://www.worldclim.org/。
植被数据 全国NDVI数据来源于http://www.gscloud.cn/。
1.3 研究方法
1.3.1 决策树模型
决策树模型(decision tree classifier)是一种树形的分类与回归模型,由一个根节点、一系列中间节点和一系列叶子节点构成。决策树通过对指定任务的多级递归分割方法,使用信息熵(information entropy)或者基尼系数(gini)作为分类依据,将一组训练数据划分为同质的数据集。决策树建模简单易懂且可以展示决策过程,具有良好的模型可视化能力,常被用于分类问题中。本研究通过调用sklearn库中的Decision Tree Classifier函数在Python中实现了决策树的建模,调用格式为Sklearn.DecisionTreeClassifier(criterion,random_state,max_depth,min_samples_split,min_samples_leaf)。
其中:criterion是分类标准;random_state是控制随机性的参数;max_depth是树的最大深度,是决策树泛化能力的关键参数;min_samples_split和min_samples_leaf分别决定了树分叉的最小个数和叶子节点的最小分类个数。
使用网格搜索(grid search)确定参数最优值。网格搜索的原理是使用穷举法将可能的取值进行排列组合,并使用交叉验证对各组合的效果进行评估,选择最优解。利用sklearn中的train_test_split函数划分训练集和测试集,通过分类得分(score)对结果进行精度评价。应用栅格空间转换数据库(geospatial data abstraction library,GDAL)进行模型可视化。在ArcGIS 10.7中制图输出。
1.3.2 随机森林模型
随机森林模型(random forest classifier,RF)是一种由多颗决策树组成的集成算法,2001年由美国统计学家Breiman提出。该模型通过对多颗决策树构成的“森林”取平均值或少数服从多数的原则,达到最终效果大于单颗训练优异的决策树的目的[17]。随机森林采用了重复随机抽样(bootstrap)的建模方法,即对数据进行有放回的抽样作为决策树的训练集。本研究在python中使用Sklearn.RandomForestClassifier进行了随机森林建模,调用格式为,Sklearn.Random ForestClassifier(n_estimators,random_state,max_depth,min_samples_split,min_samples_leaf)。
其中:n_estimators是决策树的关键参数,决定了随机森林中树的数量,树的数量直接决定了模型拟合能力的强弱。使用学习曲线确定最佳的n_estimators取值。学习范围设定为1~200。其他参数设定方法都与决策树相同。使用GDAL库进行模型可视化,在ArcGis 10.7中制图输出。
1.3.3 精度评价
收集第二次土壤普查和《云南土种志》收录的研究区内31个红壤剖面作为检验样地,使用分类得分来衡量测试集分类精度;使用混淆矩阵来验证空间制图分类的准确性,使用总精度代表混淆矩阵的结果,总精度计算公式如下。

式中:Pii为混淆矩阵中第i行第i列的像元数,表示分类正确的个数;N表示总样本个数;K表示总分类正确的总个数。
2 结果与分析
2.1 决策树与随机森林的参数最优取值
2.1.1 决策树参数最优取值
使用0.8∶0.2的比例划分训练集和测试集,将Random_state参数待调值设定为1~200。根据过往研究[27],最大深度超过20后会出现严重的过拟合现象,max_depth设定为1~20。min_samples_leaf和min_samples_split均设定为1~10(样本量的0.1%),使用网格搜索对决策树参数进行调优。得到决策树random_state最优解为163,max_depth最优解为5,min_samples_leaf和min_samples_split最优解均为3,criterion最优参数为gini,决策树训练集精度为0.812 3,验证集精度为0.82。
2.1.2 随机森林参数最优取值
随机森林模型的精度很大程度上取决于构成森林的决策树数量。随机森林需要调试的参数包括森林中树的棵数n_estimators,树的最大深度max_depth,最小样本数min_samples_leaf和最小分裂个数min_samples_split,随机模式random_state。除了树的棵数之外,其他参数与决策树相同。根据过往文献[10,17,24,28],树的棵数对于随机森林精度的影响最高,因此,将n_estimators先设为默认值100,在其他参数得到最优解后通过学习曲线对给定范围内的值求最优解。随机森林使用bootstrap进行有放回的重复抽样,不需要划分训练集和测试集,一个抽样样本大约包含了63%的原始训练数据,而剩余数据则作为测试集使用。除n_estimators外,其余参数设定均与决策树相同,利用网格搜索进行穷举得到参数最优解:random_state最优解为14,max_depth最优解为3,min_samples_leaf和min_samples_split最优解均为3。在确定了其他参数的最优组合后,使用学习曲线对n_estimators参数进行调试,预设范围为1~200(默认值±100%),学习曲线见图3。可见,随着决策树棵数的提高,随机森林的精度在0.798~0.803之间波动,n_estimators最优解为9,测试集精度为0.803 18。不同方法在训练集和测试集的精度见表1,在给定最优参数条件下,决策树在训练集和测试集上的精度略高于随机森林(+1.34%,+1.97%),但二者没有显著差异。

图3 随机森林参数调优结果
为判定决策树和随机森林在不同随机场景下在测试集上的精度差异,使用交叉验证对两种方法进行50次交叉验证,结果见图4。可以看出,绝大多数情况下,两者变化的趋势较为相似,随机森林的精度略高于决策树。仅在少数情况下,决策树精度高于随机森林。总体而言,决策树和随机森林在测试集上的精度差异不显著。
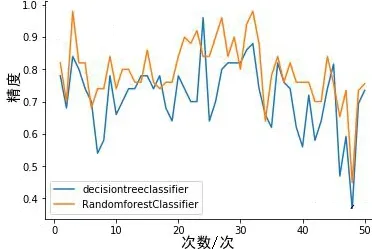
图4 决策树与随机森林交叉验证结果
2.2 模型精度影响因子的重要性排序
采用随机森林方法对影响模型精度的10种因子进行变量重要性排序,得到图5结果。随机森林预测变量重要性的方法为平均降低精度,即将一个变量替换为随机数后模型精度降低的程度,降低程度越大表示该变量越重要。由图5可知,影响随机森林结果的参数重要性前5的变量为DEM(0.328 0),Tem.(0.281 9),t_cut(0.216 4),habt(0.062 9)和slope(0.055 7),其余变量对红壤分布的影响相对较低。其中,DEM可以识别分布区海拔高度,云南省是山地主导的省份,海拔的变化直接影响了土壤种类的分布;Tem.是分布区温度,热量条件是影响土壤种类分布的重要因素;t_cut、habt是地形切割和地形起伏度的指标,slope是坡度指标,这3个指标可以衡量地形的起伏变化程度。在重要性前5的指标中,4个是DEM及衍生指标,这比较适合云南省山地主导的自然地理格局,与任必武等[29]的研究结论相似。可以认为,RF对变量重要性的排序比较合理。

图5 RF环境变量重要性排序

表1 不同机器学习方法精度对比
2.3 空间制图与精度检验
2.3.1 决策树的空间制图与精度检验
决策树空间制图结果见图6。整个研究区除北部轿子雪山部分地区(图6黑框部分)之外,大部分都被划分为红壤区。红壤区连续分布且不随地形地貌的变化而变化。决策树空间制图显示出与测试集精度极不匹配的空间分布。滇东地区除红壤(面积占比55.26%)外,还包括石灰土(8.85%)、紫色土(8.33%)、棕壤(6.93%)等地带性土壤分布,除此以外,还有水稻土、新积土等面积占比小于5%的土壤。决策树模型不能准确的判断红壤与其他土壤的区别,很容易将其他类型的土壤全部划分为红壤。与郭鹏涛等[17]在小尺度橡胶园的结果(r=0.69)相比,决策树模型在大尺度的制图工作中缺乏土壤空间细节和空间变化,表明了决策树算法没有捕捉到整体数据中标签与样本的准确关系。因此可以认为,决策树算法在大尺度的数字土壤类型制图中是过拟合的,不适合在大范围、大尺度的数字土壤制图中使用。

图6 决策树模型的红壤空间分布
2.3.2 随机森林的空间制图与精度检验
随机森林模型的空间制图(图7)精度为67.74%(21/31),比1995年版云南土壤图58.06%(18/31)的精度提高了9.68%,与陈芳[10]以枣阳市为研究区的中尺度土壤制图精度相似。与测试集相比,空间制图精度减少了近13%,这与小尺度复杂的微环境导致的模型辨别能力下降和变量的尺度变化影响有关。由图6可知,随机森林模型展现出了与地形地貌较为吻合的红壤分布区。由此可见,虽然随机森林在训练集和验证集上的精度略低于决策树,但是由于集成算法的优势,随机森林具有较强的泛化能力,对空间数据的处理不易出现过度拟合,更适合大范围的数字土壤制图。

图7 随机森林模型的红壤空间分布
总体分布上,以南盘江河谷和文山盘龙江河谷为界,将整个区域分为3个部分,南盘江河谷以北为滇中高原,南盘江河谷以南,盘龙江以西为元江河谷区,以东为滇东南喀斯特地貌区。滇中高原山系多呈南北走向,由西到东包括了三台山、拱王山、梁王山、轿子雪山南部和乌蒙山系。在上述山系,红壤基本沿山系呈南北走向(图8),尤其是滇中昆明一带,红壤呈现非常清晰的南北带状分布趋势,红壤在本区域分布于山谷区和山南坡尤其是山西南坡,山北坡根据海拔的高低分布棕壤、黄棕壤、暗棕壤等半淋溶土;山体不同坡向土壤类型的不同与山体不同坡向水热条件有关[30-32];元江河谷区红壤同样受到地形走势的影响,基本沿西北—东南山系走向分布(图9),相比于滇中高原区,元江河谷区位于热带与亚热带气候过渡区,水热条件好于滇中高原区,如个旧(年均温18.1 ℃,年降水1 101 mm[11])比昆明(年均温14.25 ℃,年均降水924 mm[33-35])年均温高近4 ℃,年均降水量高近200 mm。在河谷地区分布赤红壤、紫色土等亚热带土壤,随着海拔的升高,分布有黄壤、黄棕壤等土类;文山盘龙江以东为滇东南喀斯特地貌区,海拔范围为618~3 000 m,喀斯特地貌强烈发育导致了地表隆起切割强烈,缺乏高大山系。滇东南喀斯特地形区位于热带地区,水热条件优越,红壤与砖红壤、赤红壤,石灰土、黑色石灰土等土壤混杂分布,缺乏明显的地带性规律(图10)。
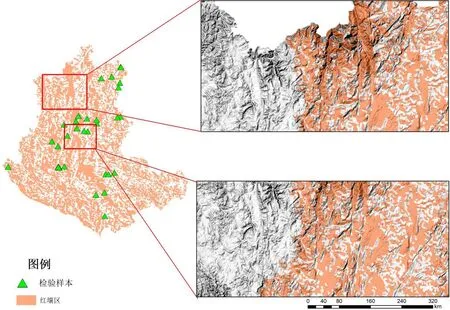
图8 滇中高原红壤分布区

图9 元江河谷红壤分布区

图10 滇东南喀斯特区红壤分布区
2.4 地形地貌要素对红壤分布的影响分析
地形地貌对红壤分布的影响主要体现在影响成土的水热条件上。研究区地形起伏较大,山南坡为阳坡和迎风坡,王艳霞等[36]通过计算滇中地区阴阳坡气温直减率认为阳坡(0.52 ℃)气温直减率小于阴坡(0.55 ℃)和平均值(0.53 ℃),表明阳坡在同等光照条件下可以获得更多热量;徐八林等[37]记录了2018年文山麻栗坡县9月2日降水数据,山南侧的猛硐乡站4 h降水量为196.0 mm,而山北侧的杨万站同时段降水仅为45.3 mm,相差达100 mm以上。可见,地形地貌影响土壤分布的主要机制是通过水热条件的再分配间接地影响成土过程和土壤发生学特性[12]。对于红壤,水热条件的改变直接影响淋溶作用的强度,进而影响红壤的分布区域。
3 讨论与结论
3.1 讨论
在大数据时代,手工绘制的土壤类型图无论在精度和成本上都难以满足数字农业和精细化林业管理的需要。利用空间大数据,通过机器学习方法进行数字土壤图更新,对于提高土壤类型分布图的精度和制图效率具有重要的意义。本研究以滇东地区红壤为研究对象,通过机器学习对滇东地区红壤进行了空间分布模拟,对比1995年版土壤类型图,本文有以下新的突破:通过机器学习方法,将滇东红壤分布图精度提高了9.68%,新的红壤分布图展现了更符合滇东地区自然地理条件的空间分布,更能表现出山地对土壤形成的间接主导作用;将机器学习方法引入云南数字土壤制图工作中,得出了以随机森林为代表的集成算法更适用于大尺度数字土壤制图的结论。
(1)决策树与随机森林模型泛化能力的对比 决策树模型在训练集和测试集上的精度分别高于随机森林1.34%和1.97%,但在最终的空间模拟中缺乏可信性。这表明相比于随机森林,决策树存在较严重的过拟合现象。可能的原因是:①关键参数max_depth数值的差异导致了模型复杂度的不同。决策树的最大深度为5,随机森林为3,这使得决策树的模型更为复杂,也更能捕捉到训练集中标签与数据的特定模式,而不能准确地捕捉到整体数据与标签之间的关系。②决策树使用与标签强相关的指标—如海拔和温度—进行预测,而放弃相对弱相关的指标。而随机森林使用随机选择方法选择变量,高相关度和低相关度的变量都会被选择,从而促进了树的多样性。随机森林生成的决策树是去相关性的,这使得随机森林对过拟合具有更好的鲁棒性。③模型过拟合还跟训练集规模有关系,由于训练集划分的关系,决策树(80%)比随机森林(63%)训练集规模大17%,这也导致了决策树更能挖掘训练集中标签与样本的关系。综上所述,更复杂的模型和强相关变量为主的构建方法使决策树有更好的统计精度,而随机森林相对简单的模型和去相关化的构建方法牺牲了相对较小的统计预测精度换得了更好的鲁棒性。对于大尺度的土壤制图来说,在相似的统计精度水平下,拥有更好泛化能力的随机森林模型是比决策树更优的选择。
(2)影响红壤分布的主要环境变量 决策树模型和随机森林模型都表明海拔是主导红壤分布的关键因子(0.328),这与Zeraatpisheh等[38]、杨煜岑等[39]、任丽等[40]、张厚喜等[41]研究结论类似。其他影响红壤分布的因子包括地表切割、地表隆起、温度。海拔是对红壤分布影响最大的地理因子,这是因为云南垂直气候差异明显,不同的海拔高度有完全不同的水热环境,海拔与地表隆起和地表切割度相互耦合,造就了滇东地区多样的水热因子组合。水热是土壤发育的主导因子,温度是影响红壤分布的第二大因子(0.281 9),温度影响土壤形成过程中物质的积累、分解和转化过程,进而影响土壤类型与土壤性质[12]。这与任必武等[29]在福建亚热带复杂地貌区的结论类似。滇东地区海拔和地表切割隆起强烈,地形地貌的巨大差异使得温度变化差异巨大。Van’t Hoff温度定律表明,温度每上升10 ℃,化学风化的速率增加一倍;根据Ramann风化因数定律,化学风化作用的强弱受到土壤绝对温度和一年中可以发生风化的时间两个因素的控制[11],温度差异直接导致了风化强度和风化时间的差异,进而影响了风化和淋溶作用发生的程度,导致了土壤类型的差异。
一般情况下,降水也应当是影响土壤类型分布的重要因素,但在本研究中,降水的影响却比较微弱,这可能是由于滇东地区降水差异相对较小且训练样点集中于滇中高原造成的。后期的工作将会增加对滇南区域的训练。用于空间精度检验的现有剖面数据过少且分布不均匀是本研究另一个不足之处,现有检验剖面集中于滇中高原地区,对于北侧、南侧的地形复杂区剖面数量不足,增加检验剖面数量也是未来需要进行的工作。
3.2 结论
本研究以第二次土壤普查数据和《云南土种志》数据为基础,利用决策树和随机森林模型,预测了滇东地区红壤的空间分布格局,并利用现有的31个剖面进行了检验,得到了如下结论:
(1)随机森林比决策树更适合进行大尺度的红壤制图,利用随机森林模型得到的红壤分布图精度为67.74%,比现行的土壤类型图精度提高9.68%,展示了更精细的红壤空间分布格局。海拔是影响红壤分布最重要的因素,温度、地形切割度、地形隆起度是影响红壤分布的次要因素。
(2)随机森林模型虽然能较好地捕获土壤类型与环境变量之间的非线性关系,但随机森林在验证集上和利用剖面获得的精度仍有近13%的差异,可能原因是训练样点仍然不足或者影响土壤类型的变量未被列入到模型中。在未来的研究中,如何弥补精度的差异以及如何引入更多相关变量是值得进一步研究的问题。
