确定型有限自动机生成最短正则表达式的启发式算法研究
2021-12-09蒙祖祈
蒙祖祈
(东北石油大学 计算机与信息技术学院, 黑龙江 大庆 163318)
0 引言
正则表达式与确定型有限自动机同属于正则语言模型,具有相同的表达能力,可以等价地相互转换。虽然自动机容易转化为高效的计算机内部程序,但状态间复杂的变迁关系难于理解,无法在工程实践中直接用于语法规则的设计和交流。根据自动机生成易于阅读的正则表达式有助于正则语言的理解和应用,也可以更广泛地应用自动机学习的研究成果,是形式语言领域研究的一个经典问题。
将确定型有限自动机转换为正则表达式的经典方法主要有3种:状态消减法、Brzozowski代数法和传递闭包法[1]。这3种方法生成的表达式质量均具有很大的不确定性,容易生成冗长的正则表达式,给表达式的阅读和理解带来困难。其实,无论采用哪种正则表达式生成方法,结果表达式的不确定性都源于状态排序的差异,状态排序的优化是提高正则表达式质量的关键。
目前,针对状态排序优化问题出现一批启发式状态排序算法,在一定程度上提高了结果表达式的质量。依据启发信息的类型,现有启发式排序算法可以分为结构特征算法和局部特征算法两类。结构特征算法由自动机拓扑结构决定状态顺序,包括桥状态法、回路计算法和嵌套回路法;局部特征算法根据状态自身及邻接状态决定状态顺序,包括流量法、静态度乘积法、动态度乘积法和权重法。具体算法介绍请参照文献[2]。
由于在各类实验中权重法[3]效果优异,已成功应用于XML数据模式挖掘[4]和日常行为规则挖掘[5]等应用领域中。因此,本研究分析权重法的计算原理,研究向前预测的改进权重法。相较于其他启发式算法,该算法能保证取得更优的结果表达式。
1 预备知识
有限自动机从识别语言的角度定义正则语言,包括确定型有限自动机和非确定型有限自动机,非确定型有限自动机可以转化为确定型有限自动机。其形式化定义如下。
定义1 确定型有限自动机。确定型有限自动机是一个五元组A=(Q,Σ,δ,s,f)。其中,Q为有限的状态集合;Σ为有限的输入符号集合;s为自动机的一个初始状态,简称初态,且s∈Q;f为自动机的一个终结状态或接受状态,简称终态,且f∈Q;δ为转移函数,输入一个状态和一个符号,输出一个状态,若转移函数的输入状态qi∈Q,符号是k∈Σ,输出状态qj∈Q,则qj=δ(qi,k)。
本研究针对精简的确定型有限自动机,定义如下。
定义2 精简性。若确定型有限自动机是精简的,则自动机中的每个状态都会出现在从初态到终态的某条路径上。
在状态消减过程中,精简的确定型有限自动机将失去每次转移只处理单个字符的性质,转化为等价的表达式自动机,其形式化定义如下。
定义3 表达式自动机[6]。表达式自动机EA的定义如式(1)。
EA=(Q,Σ,δ,s,f)
(1)
式中,Q、Σ、s、f的定义与确定型有限自动机相同。δ为表达式转移函数,有δ⊆Q×RΣ→Q。RΣ为一个正则表达式的集合,而且是Σ的超集。并规定:从任意状态p到q,只有一个正则表达式α且α∈RΣ,满足q=δ(p,α)。表达式自动机的字符规模|EA|是转移函数δ所能接受的所有正则表达式的长度和。
虽然正则表达式应用十分广泛,但其定义存在诸多差异。如UNIX正则表达式与POSIX正则表达式不同,PERL语言的正则表达式甚至可以容纳非正则语言。下面给出正则表达式的形式化定义。
定义4 正则表达式。字符集Σ上的正则表达式被递归地定义如下。
若Φ表示空集,ε表示空字符串,则Φ和ε是正则表达式;
每个α∈Σ为正则表达式;
若α和β为正则表达式,则二者选择运算(α|β)的结果为正则表达式;
若α和β为正则表达式,则二者连接运算(α·β)或(αβ)的结果为正则表达式;
若α为正则表达式,α*表示匹配α任意次,则α*也是正则表达式。
正则语言可以由无限多个等价的正则表达式描述,越简短的正则表达式越容易表现语言的共性特征,也越容易理解。本研究采用正则表达式的长度作为衡量正则表达式质量的依据。
定义5 正则表达式长度。正则表达式α长度定义为α所包含字符数量,不包括元操作符及ε,标记为|α|。例如,正则表达式(a|b)(a·b)*的长度为4。
本研究将状态消减法设定为自动机生成正则表达式的方法,这种方法的生成效果会受到状态消减序列的影响。下面给出状态消减序列的定义。
定义6 状态消减序列。定义状态消减序列s为〈q1,q2,…,qn-1,qn〉,序列长度|s|=n,如图1所示。
2 状态消减法
下面通过例子介绍状态消减法,并分析该方法对状态序列的敏感性。为保持自动机的语义不变性,每次状态消减需要给前驱状态和后继状态重建转移。若消减状态qk有m个前驱状态和n个后继状态,则需要重建m×n个转移,此外初态和终态不能是消减状态。重建转移的输入表达式为式(2)。
(2)

状态消减法得到的正则表达式长度依赖于所选的状态消减序列。以图1(a)中自动机为例,若消减序列为s1=〈q1,q4,q2,q3〉,生成的正则表达式为ea*bhp*e|ea*dp*e|ea*ck*jhp*e,长度为19。若消减序列为s2=〈q3,q2,q1,q4〉,生成的正则表达式为ea*(d|(b|ck*j)h)p*e,长度为10。消减序列s2生成的表达式明显优于消减序列s1。
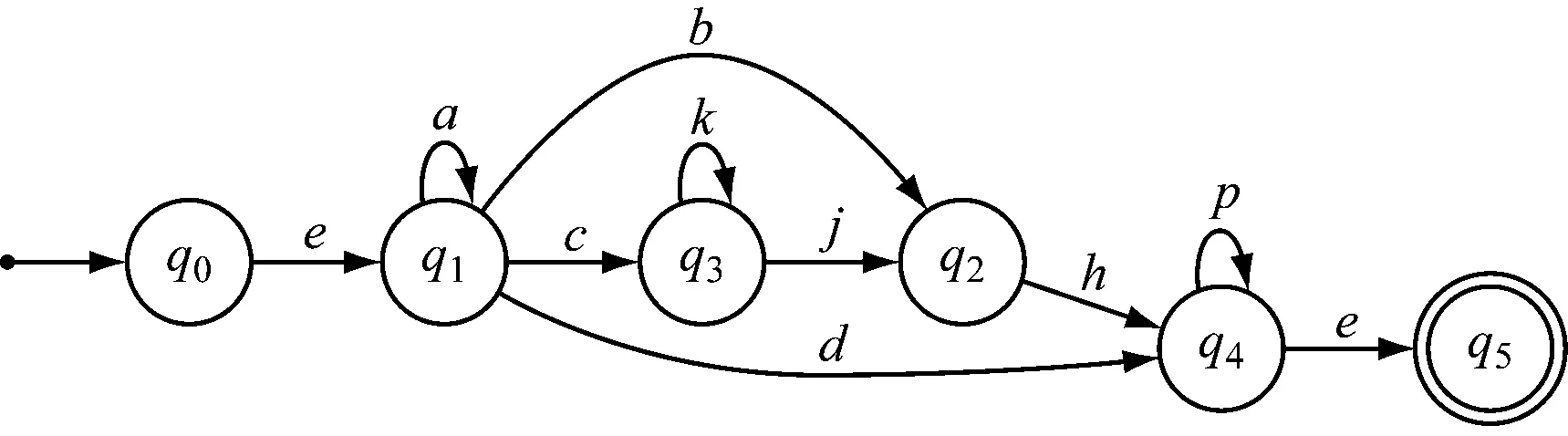
(a) 六阶自动机

(b) 消减q3后

(c) 消减q2后
3 向前预测的改进权重法
向前预测的动态权重法以权重函数为核心,以向前预测为主要的改进策略,改进算法还包含了并行消减策略,进一步提高计算结果质量。
3.1 权重法
权重法的核心思想是,在每次状态消减的迭代过程中,选择消除权重最低的状态。而权重函数的主要内容是给定一个状态,根据该状态的输入转移数,输出转移数,以及转移上的字符长度,计算消减该状态前后时自动机字符总量的变化。
定义7 权重函数。对于自动机A上的状态q,其权重函数w(q)如式(3)。
w(q)=(inq-1)×∑r∈outRE(q)|r|+
(outq-1)×∑r∈inRE(q)|r|+
(3)
(inq×outq-1)×|loopRE(q)|
其中,inRE(q)表示状态q输入转移上表达式集合;inq表示q不包含自身环的入度;outRE(q)表示q的输出转移上表达式集合;outq表示q不包含自身环的出度;loopRE(q)表示状态q自身环转移上的表达式;r表示确定型有限自动机中的字符或表达式自动机中的表达式;|r|表示字符或表达式的长度。
在每次迭代计算前,需要使用权重函数计算每个状态的权重,并通过排序得到一个权重最小的状态,而后才能使用状态消减法消减该状态。
3.2 并行消减状态策略
在某些表达式自动机中,即使是运用向前预测策略,也会出现在同一状态消减阶段中得出多个最小权值状态的情况。其状态表达式自动机如图2所示。
在第一个消减阶段中,最小权值的状态为q2、q3和q4,这两个状态的权值均为1,在常见的算法中多采用只消减其中一个状态的操作,而最优状态序列为〈q2,q3,q4,q1,q5〉。若此时消减的是状态q2,则有可能在最终得出最优消减序列;但是若消减状态q3或q4,则最后得出表达式的字符长度不会是最短的。因此在遇到多个最小权值状态时,逐个消减状态,可重构出多个自动机。将图2(a)的自动机同时消减q2、q3和q4,形成图2(b),图2(c)和图2(d)中的3个表达式自动机,运用权重函数分别对3个自动机中的状态计算权值后,可知在图2(a)的自动机,能够找到3个自动机中最小权值的状态q3,它的权值为0。此时便可以抛弃另外两个表达式自动机,沿着〈q2,q3〉这个状态序列继续消减状态。

(a) 七阶表达式自动机

(b) 消减q2后重构的表达式自动机

(c) 消减q3后重构的表达式自动机

(d) 消减q4后重构的表达式自动机
3.3 向前预测策略
向前预测策略的核心思想在于,首先连续消减k个状态,然后运用权重函数,计算重构后自动机中各个状态的权值,以各状态中的最小权值作为自动机重构前的消减状态权值,从而达到“向前预测”的目的。具体操作如算法1所示。

算法1,第2步中k的自减用于跳出递归,第5步的向前预测策略是利用权重函数计算重构后的表达式自动机中各状态权值,步骤如算法2所示。

下面通过举例说明向前预测策略的计算过程,以自动机为例,如图3所示。
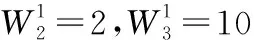
(4)

(a) 六状态自动机

(b) 消减q1后重构的表达式自动机

(c) 消减q2后重构的表达式自动机

(d) 消减q3后重构的表达式自动机

(e) 消减q4后重构的表达式自动机
分别消减图3(a)中的状态q2,q3和q4,重构后的表达式自动机分别如图3(c),图3(d),图3(e)所示。按照计算q1的权值的方法,同理计算其他状态的权值则可得式(5)—式(7)。
(5)
(6)
(7)
比较W1,W2,W3和W4可知,此时W2和W4为最小值,因此应该先消减q2和q4。消减状态后继续运用向前预测策略消减状态,可知最终状态序列为〈q2,q4,q1,q3〉或〈q4,q2,q1,q3〉,与该自动机的最优状态消减序列一致。
为保证预测步数k大于消减操作数n,在结合动态计算策略消减自动机的状态时,应使k随消减操作数n的减少而减少。当自动机的状态数较少时,向前预测步数取1—3步左右,便可以获得较短的表达式。而当自动机的状态数较多时,向前预测步数可以取状态数的开方,便可以获取比其他启发式算法短的表达式。
3.4 算法复杂度分析
改进算法的复杂度受到自动机状态数和预测步数的影响。给定n阶自动机A,权重法需要计算每个状态的权值,故时间复杂度为O(n);权重法只取权值最小的状态,故空间复杂度为O(1)。消减一个状态时,结合并行消减状态后,向前预测k步的改进权重法的时间复杂度则约为式(8)。
(8)
在低阶自动机中,当k取1到3便可以获得较优序列,此时时间复杂度平均为O(n2);而当状态数较大,k取状态数的开方时,此时时间复杂度平均为O(kn2)。
在递归计算过程需要存储自动机,以矩阵形式进行存储时,算法的空间复杂度约为O(kn2)。
4 实验及结果分析
对比实验在Pentium E6800的双核CPU机器上运行,主频为3.33 GHz,配置内存为4.00 GB,操作系统为Windows 10。实验中使用C#作为编程语言,并以Visual Studio 2017作为实验平台。
在下述实验中,自动机的随机生成方案设计如下:给定自动机的状态数量,状态间转移的建造概率服从0—1均匀分布,若概率大于0.5则建造转移,反之则不建造。生成的自动机还需满足2个条件:一是至少有一条从始态到终态的路径;二必须是精简的自动机。
该实验是向前预测的改进权重法(实验中简称为改进权重法)与其他启发式算法的实验进行正确率对比,实验方案如下:生成6到10阶自动机各1 000个,分别对各类启发式算法进行测试,算法中包含随机序列算法和自然序列算法,随机序列算法指序列中的状态随机排列,自然序列算法指序列中的状态按照状态编号由小到大排列。记录不同算法生成正则表达式的长度,然后与穷举状态序列算法所生成的最短正则表达式进行对比,得出算法的正确率μ,计算式如式(9)。

(9)
式中,C表示实验时自动机的个数;lh表示根据启发式算法生成序列,某个自动机转化成正则表达式的长度;le则表示根据穷举算法生成的正则表达式长度,即一个自动机能够转化的最优正则表达式。若上述二者相同,则令计数值k置1;否则记为0。通过计算计数值的统计数与自动机个数的比值获取正确率。
实验结果如图4所示。

图4 各类算法生成表达式的正确率对比图
改进权重法的正确率明显优于其他各类启发式算法。在10阶自动机的实验中,其他算法的正确率不到10%,而改进权重法的正确率仍能保持50%以上。
5 总结
本研究分析了状态消减法对消减序列的敏感性,在此基础上,提出了向前预测的改进权重法。实验结果显示,在转化低阶自动机时,向前预测的改进权重法可以显著提高生成最优表达式的正确率,但在转化高阶自动机时仍然存在正确率下降的问题。在下一步研究中,若是考虑利用智能优化或神经网络等机器学习算法,有望进一步提高生成表达式质量。
目前,向前预测的改进权重法主要应用在吉林油田的录井数据质量管理项目中,用于将样本构造的自动机转化成用正则表达式描述的数据质量校验规则。在转化少状态的自动机时,该算法可以生成较多简短的校验规则。
