古旧地图的信息化*
2021-12-09张光伟夏翠娟
潘 威,张光伟,夏翠娟,孙 涛
0 前言
古旧地图是人文社会科学研究的重要史料,在光学字符识别(OCR)、地理信息系统(GIS)、数据库技术等数据库信息化手段支持下,可以最大限度挖掘古旧地图中的地理信息,提升古旧地图的使用效率[1]。历史地理学界针对古旧地图的信息化处理已经进行多项实践,如张萍等基于多种古旧地图对西北“丝绸之路”交通路线和古代城市定位[2]、韩昭庆研究康熙《皇舆全览图》投影方式[3]、潘威等对近代灌渠体系的重建和分析[1],皆实践了GIS手段在古旧地图处理中的运用。不过,历史地理学界将古旧地图的信息化操作局限于GIS环境下的人工矢量化处理,限定了对古旧地图的进一步研究和更广泛使用[2]。解决以上问题的方法是让历史地理信息化与图情、计算机科学、信息管理等学科领域深度融合,在持续推动GIS在历史地理学中应用的同时,充分利用大数据环境下的数据库技术、图形计算技术、深度学习技术[1-4]。通过加强对古旧地图的管理、处理、使用和分析等多项技能,为历史地理学、地图学史和数字人文发展提供更多可能性。而要落实这一目标,首先应解决古旧地图文献的数字化管理和图幅内容的自动化提取。对古旧地图的管理既是对图幅作为文献的数字化和编目,也是对图幅内容的提取和数据化。
在历史地理学研究中,使用古旧地图需要信息化管理和图幅内容的信息化提取,两者实际为一有机整体。研究者首先需要建立古旧地图资料库,采用信息化手段管理大量古旧地图文档,在此基础上采用OCR等手段实现古旧地图信息提取的自动化,之后方才进入具体研究环节,即专题数据的使用层面。因此,古旧地图的信息化管理以及图幅内容的自动化提取是科研工作中的重要环节。实现这一目标,必须引入图情知识体系(本文所用“图情知识体系”一词为图书情报学的理论与技术体系总和,是笔者作为历史地理学工作者对图情学路径的一种概括),尤其是图情学界所采用的RDF编目、语义网和近年来大力提倡的OCR技术等,对推动历史地理信息化具有重要意义。本文以清代河工图的信息化处理方法为例,通过“数字历史黄河”(DHYR)中的图形资料库的设计与实现,展现OCR、语义网技术、深度学习技术在历史地理信息化建设中的重要作用,特别是对古旧地图管理和使用中的重要作用。

图1 DHYR·图形资料库中收录的部分古旧地图
1 “数字历史黄河”·图形资料库
1.1 资料介绍
“数字历史黄河”(DHYR)是由河南大学、云南大学共建共享共有的黄河历史变迁古旧地图资料库,目的是实现黄河历史变迁的数据管理、多维展示和辅助分析[5-6]。黄河流域古旧地图数量众多,中国国家图书馆等单位建有古旧地图管理平台,对其已经收藏图形,DHYR原则上不重复收录,专门针对尚未得到系统收集、整理和电子化处理的古旧地图,力求与其他单位藏图互为补充。该系统的资料管理库有专门的“图形资料库”(本文记为“DHYR·图形资料库”),其中收录有清代河工图、民国地形图、黄河流域规划图、晚清西方黄河调查图、近代工程蓝图、手绘草图等多种图像。图1列举了被DHYR·图形资料库收录的图形史料,其中,图1-1为1753年徐城北岸黄河支岔图(局部);图1-2为1932年渭北引泾灌溉图(局部);图1-3为1946年陕西省水利厅黄河规划图·洛河(局部)。DHYR覆盖范围为黄河流域的青、宁、甘、陕、豫、鲁、苏7省,内容涉及黄河防洪工程、灌溉体系、交通布局、土地利用等,包括中、英、日等多种语言文字,已达2,100余幅,原图收藏单位包括中国水利水电研究院、黄河水利委员会等重要机构,以及地方水利、档案、博物馆等系统。需要说明的是,沿黄地区的地形图除水利部门绘制外,还有大量为军事部门绘制,这类非水利机构暂时不收录于DHYR内。
1.2 设计思路
DHYR·图形资料库的界面设计风格简洁(见图2)。DHYR·图形资料库建设的主要思路包括:持续收集有关黄河的各类图形史料;修复破损史料;对图形进行扫描,形成高精度电子文本;建设信息化管理方案,进行高效管理;与平台其他资料库和数据库实现链接;充分挖掘史料价值,推动黄河变迁研究。之所以形成以上目的,主要在于这一工作面临多种困难,包括:经费限制,本工作只能将经费用于收集与整理图幅,突出内容建设,降低平台建设难度;管理能力不足,作为高校小型科研团队,缺乏公共图书馆那样成熟的信息平台管理能力,只能牺牲平台功能,将其维持在团队能够运营的水平上。实际上,这是许多高校中小型科研团队面临的问题,这一问题造成大量的历史地理专题数据库无法持续运营。

图2 DHYR·图形资料库前台界面
DHYR·图形资料库在设计上采取较保守的策略,优先保证资料库的稳定运行,在这一前提下逐步尝试新技术运用。DHYR·图形资料库有四大功能模块:(1)图幅信息模块:对图形史料的基本信息进行输入、编辑;(2)查询检索模块:按照图名、编码、绘制者、管理者、时代等多种要素进行图幅检索;(3)用户管理模块:登记、管理DHYR使用者信息;(4)数据维护模块:对数据进行存储、备份、还原操作。图形资料库是DHYR的组成部分,库结构采用HTML+CSS设计,后台结构采用SQL-Server。
1.3 编目方案
1.3.1 元数据方案和语义网技术
本团队在资料管理方式上,尝试中国历史地理学界内尚未被关注和使用的一些新方法,最重要的尝试是借鉴图情领域的元数据方案方法和语义网技术,对图形史料进行编目和元数据记录编码。图幅管理的重点在于编目方案设计,而历史地理学界尚未重视标准化规范化的资源编目的重要性,导致严重的数据孤岛现象。DHYR·图形资料采用图情领域的元数据方案设计方法和语义网领域的RDF(Resource Description Framework)模型和编码格式。RDF是W3C提出的用于描述知识单元及其相互关系的数据模型和数据编码标准[7],是特色历史文献资源编目中的主流方法。RDF将元数据记录抽象为主体(subject)、谓词(predict)与客体(object)3个组成部分,利用标准化的数据编码方案描述资料库中数据记录的每一个知识节点[8-9]。统一采用这种标准化规范化的方法,不仅能够实现工作团队内部和跨团队的数据共享,更易与图书馆系统中的编目数据进行互操作和整合,将个人研究融入文化基础设施体系,令历史地理学专题数据具有更为广阔的用户群体,共同建设知识谱系。这是促进历史地理信息管理规范化、数据共享便捷化、丰富数据维度的重要举措。DHYR在历史地理学界率先针对图形史料采用此方法,将单幅图形本身作为主体(subject)、描述图形元数据规范词表中的元素作为谓语(predict)、元素值作为客体(object)。比如,《道光黄河六省河工埽坝全图》的“题名(dc:title)”这一元素的编码结果为:《道光河工埽坝全图》实体dc:title“道光河工埽坝全图”。
1.3.2 元素集(词表)设计
在确定编目基本原则的基础上,具体编目方案设计需要充分考虑古旧图形记录的独特性,不能简单地将图情管理系统中对现代正规出版物、档案和一般古籍的编目方案套用至本工作。因此,需要制订有针对性的元数据方案,设计专用于古旧地图的元数据元素集(描述字段)。通过分析DHYR工作中已经收集的古旧地图,发现一些描述字段对描述图形具有重要作用,见表1中的“描述字段”列,包括描述性元数据和管理性元数据,是设计元数据元素集的基础。在此基础上,借鉴国际通用的都柏林核心(DC)元数据标准规范,复用其中的部分元素,并自定义一部分元素,还复用少量上海图书馆本体词表中的部分属性。随着今后工作的进展,这一方案将进行更新、扩展和修正。
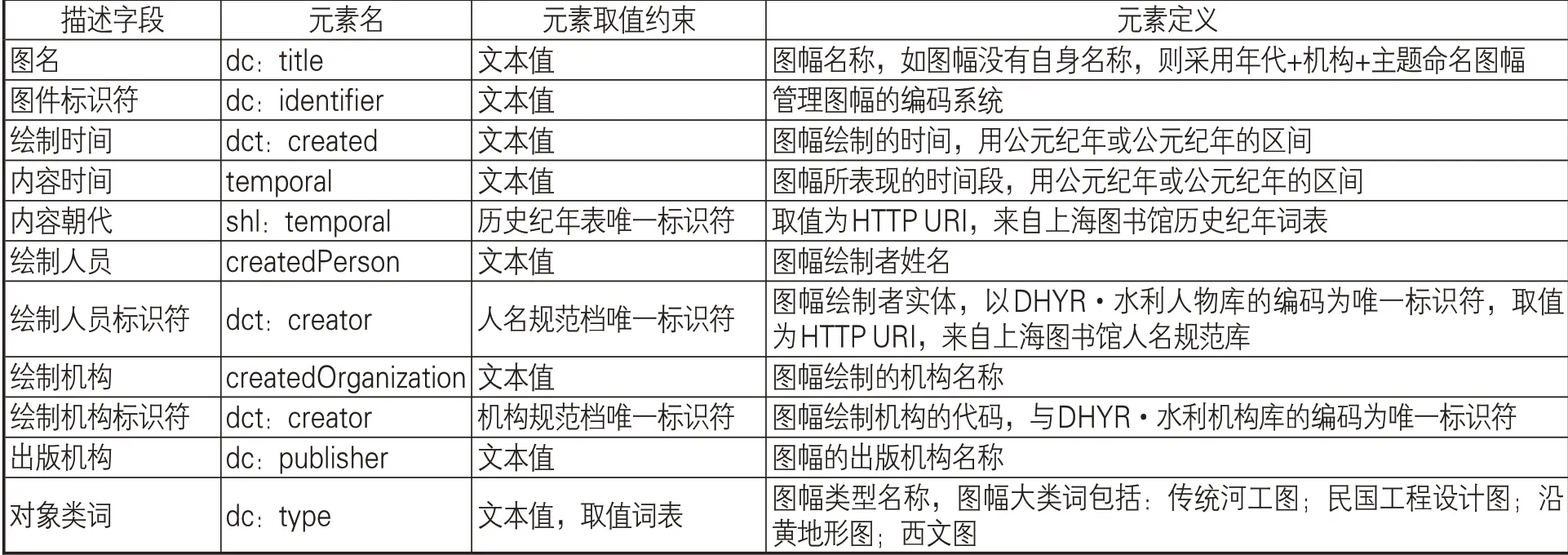
表1 描述词表构成及意义
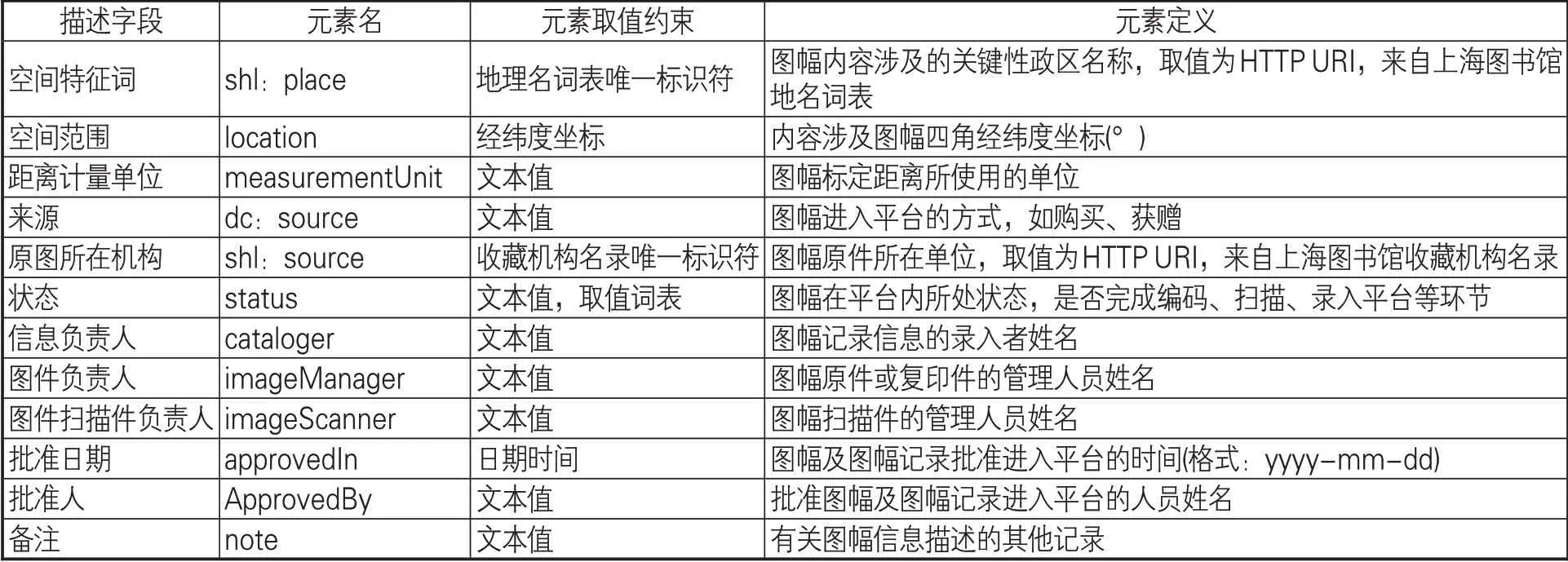
(续表1)
表1是对DHYR中古旧图形进行描述的字段构成及其定义。通过这些字段,能清晰描述古旧图形的时空信息、绘制信息和平台管理信息。
(1)“空间范围”字段采用经纬度坐标体现,这一做法可以在GIS环境中形成图幅覆盖范围的空间可视化成果,更直观地表现DHYR所收录图形史料的空间格局。
(2)“图件标识符”“绘制人员标识符”“绘制机构标识符”等的编订方式尚无行业标准,在历史地理学界也无前期成果可供参考,因此参考地理学界内普遍使用的“邮政编码方法”[10]。“图件标识符”采用7位整数进行编码,首2位表示图幅的历史阶段,如清代用“12”代表;第3位代表图幅类型,如传统时代的河工图用“1”代表;后4位代表此类型序号,由“0000”开始。“绘制人员标识符”“绘制机构标识符”采用4位整数进行编码,首2位表示人员、机构所处的历史阶段,后2位序号由“00”开始。“绘制人员标识符”“绘制机构标识符”分别是“水利人物数据库”中的人物标识码与“水利机构数据库”的机构标识码,通过标识码可以实现跨库链接。
2 基于深度学习的古旧地图地名识别
在完成古旧地图管理信息化的基础上,需要重视古旧地图图幅内容的自动提取。OCR(Optical Character Recognition)是图形识别的一种,主流的OCR系统使用深度神经网络,能够实现高精度的文档内容识别。
2.1 研制的必要性
在OCR系统支持下,历史文献识别的精度不断提升,数字化进程大大加快,但通用OCR系统中的文档分析与图形识别方法难以直接应用到古旧地图的处理之中,是因为古旧地图清晰度、幅面整洁度等要素差异巨大。比如,手绘古旧地图中,道路、边界线、文本等不同的地理要素互相叠加,而手写手绘也导致样式存在随机性误差,因而古旧地图中地名的识别难度更大[11-13]。古旧地图中地理要素的定位和提取非常重要,传统上由人工进行,近年借助机器学习等手段训练计算机实现自动提取图幅内容的需求日益增多,一些研究涉及从多种地图中提取地理信息和文本信息的方法[14-17]。地理信息系统中的地名解析(Geoparsing或Toponym Resolution)[18-20]是找出非结构化文本中提到的地名并将转换为对应的经纬度坐标的过程。非结构话文本中自动检测识别地名是自然语言处理(Natural Language Processing,NLP)中的命名实体识别(Named Entity Recognition,NER)[21]。本研究与文本中地名解析目标一致,都是从文本中提取地名:笔者的处理对象是图片,即扫描地图,使用OCR方法提取文本;后者的处理对象是已经数字化的文本,使用训练机器从中识别出表示地名的短语。笔者的工作与文本中地名解析的任务部分重叠:笔者从古旧地图中识别出的文本默认都是地名,但识别文本中的地名是文本中地名解析的核心工作,其方法能为本研究提供思路;相同的部分是都需要将识别的地名(通过OCR或NER得到)进行歧义消除(Disambiguation),确保提取的文本单元是合法的地名,OCR提取的文本内容如何组合为正确的地名是本研究需要解决的关键问题。
2.2 深度学习与古旧地图地名识别
利用机器学习方法从古旧地图中识别地名需要大量的训练数据,因此数据标注工作很关键。本研究采用逐步迭代的数据标注方法,起初使用通用的OCR检测和识别古旧地图中的文本,然后人工对检测出的文本区域以及识别的文本内容进行校对,在新数据集上训练新的地名文本检测和识别模型,这样每迭代一次模型的性能增强一次,经过若干次迭代,系统就具备较高的地名检测和识别准确率。
古旧地图中地名文本的检测属于对象检测的一种,深度学习在该领域取得了成功。对象检测主要分为“两步法”(Two-Stage)和“一步法”(One-Stage)。“两步法”对图片进行特征提取后,得到候选框,再进行分类及回归,代表算法是RCNN系列[14]的目标检测算法。“一步法”是在提取的图片的特征图上进行密集抽样,产生大量的先验框,然后进行分类和回归,代表方法包括YOLO[22]、SSD[23]、RetinaNet[24]。本研究使用一步法检测中国古旧地图中所有的单个汉字,训练针对不同大小汉字的检测模型。U-Net[25]在智能语义分割任务中表现突出,最初是在医疗影像处理中得到成功应用,然后广泛应用于对象检测和语义分割任务,本研究采用这种结构的网络进行字符级文本检测。
由于文本检测是字符级的,因此文本识别模型采用字符级识别模型。在文本识别领域,主流的OCR系统采用行(列)级别的识别模型,主要采用CTC(Connectionist Temporal Classification)算法搭配卷积神经网络叠加循环卷积神经网络(RNN)对图片中包含的文本序列进行建模[26-29],一般而言文档中的行和列相较于单个字符更易检测。但是,地图中的地名文本排列往往不像普通文献那样规则,而且有的地名字符间的距离较远,所以行列级别的识别在地图文本识别中并不像在一般文献识别那么有效,因此使用卷积神经网络进行字符级别的检测和识别。
2.3 工作流程
检测到的文字形成正确的地名需要将这些字符合并组成地名词语,使用Min-Cost Flow算法[25-26],将检测到的文字进行适当合并得到地名。图片中的文本转录到计算机,主要包含两个步骤:文本区域的检测和文本的识别。前者从图片中将包含文本的部分与图片其余区域进行分割;后者将切割出的文本图片进行识别,并将对应的文本存储到计算机。
本研究的古旧地图文本自动提取方法包括2项关键步骤:一是古旧地图中地名文本的检测与识别;二是合并检测到的文本形成正确的地名。第一步实际上是OCR系统功能:检测和识别图片中文本。有些中文地图中文字数量密集,使用主流的OCR框架往往很难正确检测出所有包含的文字,也很难一步到位地将所有文字根据视觉特点(如排列、距离)直接生成正确的地名(见图3)。
本系统工作流程见图4。第一步,采取字符级别的文本检测,即检测地图中所有的字符,并使用字符识别模型识别出这些字符。第二步,首先根据检测到的字符的视觉特点,如相对位置、大小,构建一个K-NN的网络。在网路中,每个检测到的字符是一个节点,每个汉字代表的节点周围距离它最近的K个其他汉字所对应的节点之间,添加一条有向边边的权重是它们在图片中检测到的限界框(Bounding Boxes)中心之间的欧式距离,这里的权重在后面的算法中也称为耗费,在构建的这个网络上使用Min-Cost Flow Algorithm将符合条件的字符连缀起来形成地名候选。后续研究将尝试使用与该古旧地图同时代的地名词典(Gazetteer)对候选地名进行筛选和校对,从而获得更准确的历史地名。
2.4 系统关键部件
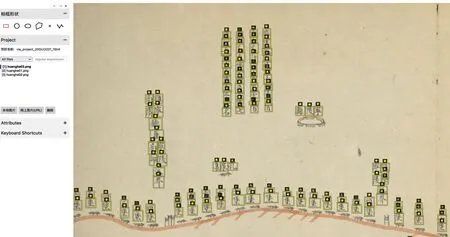
图3 古旧地图地名识别的操作界面
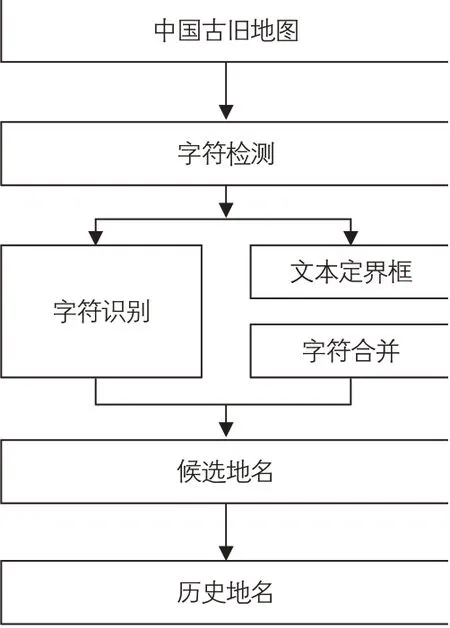
图4 系统组成与工作流程
(1)文本检测部件。在古旧地图的字符检测任务中,采用U-Net[25]架构的深度神经网络模型。该模型能够进行图片的语义分割(Semantic Segmentation),在历史文献自动处理领域得到广泛应用[29-32],其中包括古旧地图中的文本识别[26]。因为目标是进行字符级的识别,所以字符检测模型的数据标注采用单个字符的标注,标注的信息主要是字符的定界框(bounding boxes)。检测出的单个字符输入中文手写体OCR系统进行识别,该系统能够对简体、繁体中文进行识别。
(2)文本识别部件。实施文本检测的模块需要记录每个字符的坐标和尺寸,一方面为后续查询定位提供服务,另一方面为第二步的字符合成地名提供辅助信息。地图中的文本标注信息具有如下特点:一个地名用的字符大小一致,大小不一致的往往不属于同一个地名;一个地名包含的字符往往聚在一起成为方向不定的一行(排列方向可能为多种倾斜角度)。本研究的方法是:首先根据第一步中获得的每个字符的定界框(Bounding Box),将检测到的字符进行分层(位置与原图中一样),大小近似的在同一层次,以解决大小字符之间的干扰。将同一层的文本视为同一级别,利用地名文本的视觉特点组合成地名候选。
(3)中文地名合成部件。第二步类似于解析文本中包含的地名(Geoparsing)[9],采用基于Mincost Flow Algorithm的地名合成算法,从无结构文本中识别出地名(自动化的实现需要自然语言理解相关技术),处理的是提取到的词条,默认是地名。但OCR识别准确率难以在各种情况下都能达到100%准确率,古旧地图中有些地名文本排列密度高、与背景叠加等原因使得提取到的词条可能是错误的。因此,提取到的地名需要一个去模糊化(Toponym Disambiguation)过程[33],即确定提取的地名所属历史时期和所属高层政区[26-27]。
3 古旧地图信息化处理与清代黄河变迁研究
基于元数据方案、语义网技术和深度学习的古旧地图管理、处理方法能够实现古旧地图中地理信息的高效挖掘。这些方法是否能在历史地理学科研实践中发挥作用呢?下文以清代黄河变迁研究为例,介绍该方法在历史自然地理研究中的应用前景。
3.1 清代黄河下游的“汛”“堡”名称提取
清代黄河下游依靠“汛”“堡”等基层水利管理单元实现修防、赈灾、工程建设与管理、河银征收、防盗等事务,是清代河政运作的基础。“汛”依托于黄河一侧河岸的堤防进行划分,“堡”则是在“汛”之下由几个河兵或河夫驻守的据点。“汛”“堡”等基层水利单元的提取和定位,可以为清代黄河变迁研究提供定位河务运作的空间框架,能够将河银收支、物料贸易网络、河务官员流动路径、堤防修护与决口等多项河务环节置于具体的地理空间下重新认识。但是,“汛”“堡”的整体状况在文字性史料中并未得到全面记录,仅有少数举办大型工程或发生决堤事件的“汛”“堡”名称被记载。这一问题可以依靠清代河工图解决。
利用DHYR·图形资料库,在规模庞大的清代河工图中快速检索到覆盖下游全境、拥有“汛”-“堡”记录的图形史料。在史料搜寻方面,大致比传统方法节省70%~80%的时间成本。以《道光黄河六省埽坝全图》为例,利用本文提出的古旧地图地名提取方法,训练计算机对图幅中“汛”“堡”名称进行快速提取,形成格式化表格,能够快速完成“汛”“堡”名录的制作。如图5所示,限界框(Bounding Boxes)标定100%的“汛”“堡”名称,为后期实现定位提供基础。
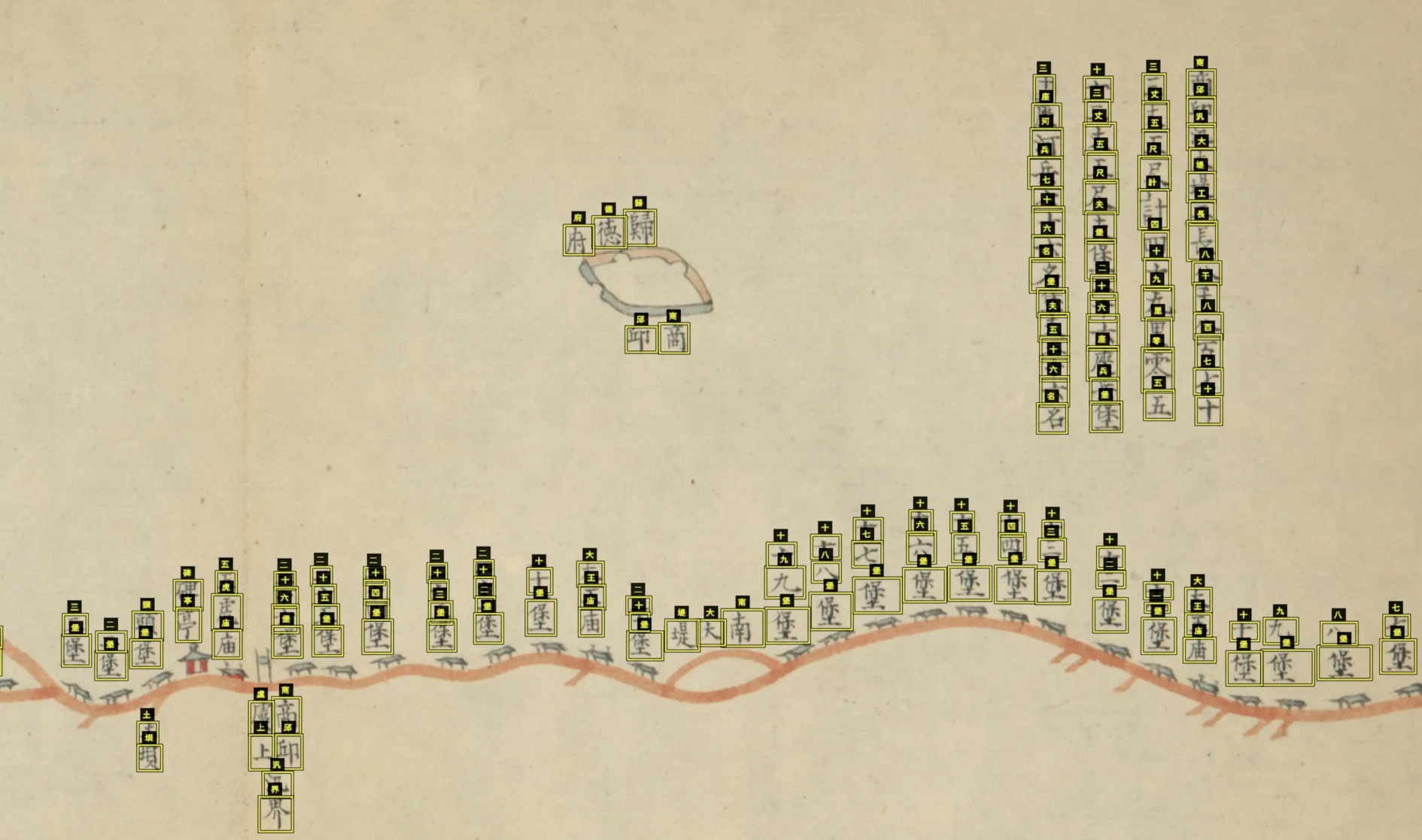
图5 黄河河工图地名的检测与识别
图5 是依据此方法重建的豫东河段“汛”“堡”空间格局。与孙涛提出的黄河兰考以下河段“汛”界数据共同构成完整的“汛”“堡”空间数据[34]。在此基础上,根据文字性史料,可以判断少数“堡”所在的经纬度位置,如中牟下汛的九堡即今中牟县九堡村,此河段一直是豫东河防重点,现代建有“九堡控导工程”。少数“堡”的经纬度确定后,基本上可以在现代地图上确定“汛”“堡”体系的基本格局,之后根据史料记录和清代黄河下游形态、堤防格局推断所有“堡”的位置,据此确定“汛”的范围。
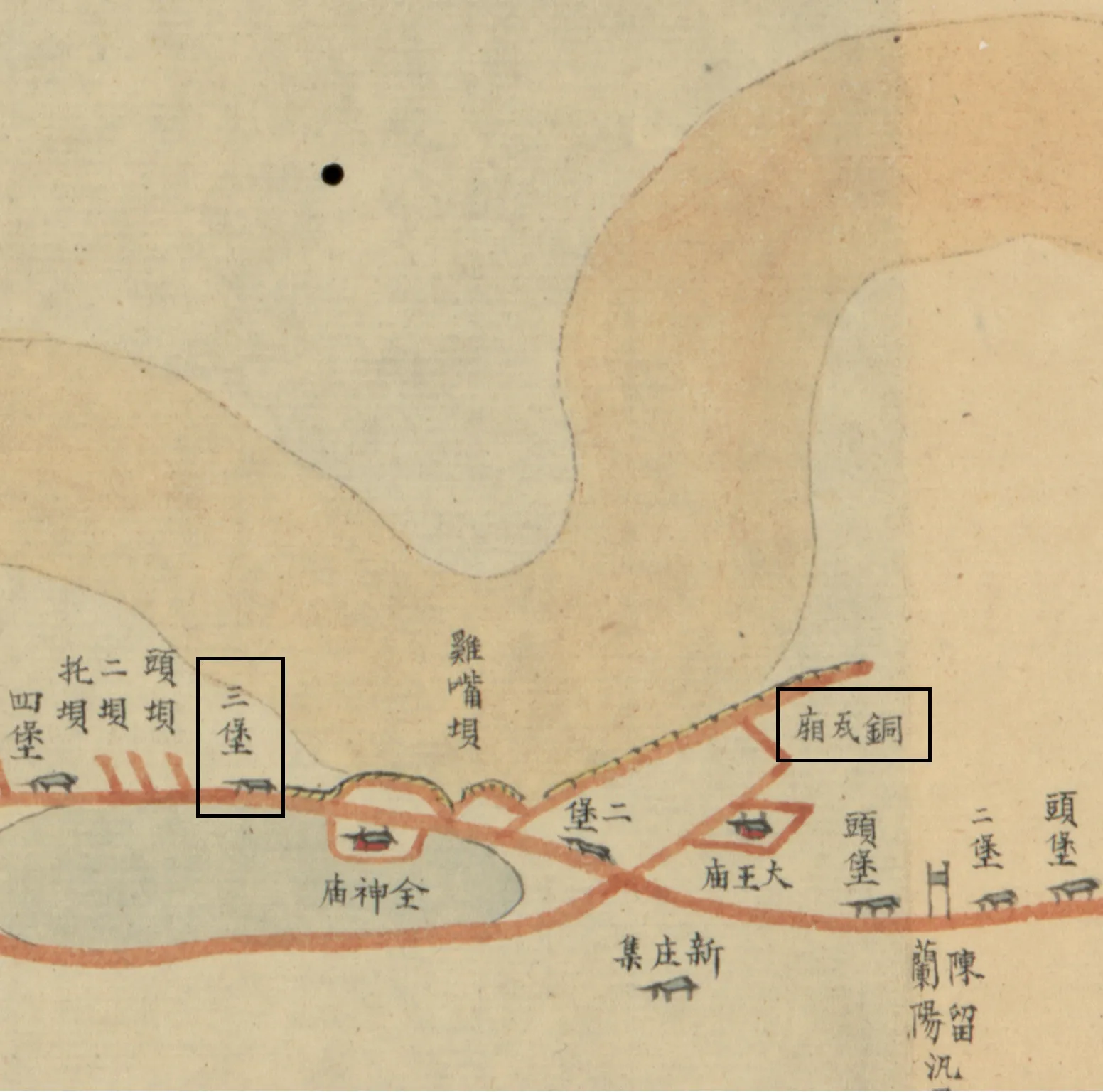
图6 道光《豫省河工图》
3.2 黄河重大变迁事件研究
19世纪以来,黄河下游最重要的变化即1855年(清咸丰五年)的“铜瓦厢改道”,黄河在今兰考东坝头一带改道北流,夺大清河入渤海,结束了1128年以来形成的黄河“夺淮入黄海”局面,奠定了现代黄河下游基本格局。借助道光《豫省河工图》(见图6)及对其的信息化处理,可以重新认识“铜瓦厢改道”的过程、原因和影响。
重新讨论“铜瓦厢改道”,首先需要准确认识决口点位置,长期以来,学界认为此次大改道决口点为黄河兰考段的铜瓦厢,但通过阅读清代河工档案,结合实地调查,本研究发现1855年决口点为兰阳上汛三堡[35]。从道光《豫省河工图》中发现,道光年间铜瓦厢段黄河已经紧逼河堤,铜瓦厢段形成托坝、挑水坝、鸡嘴坝、格堤等复合工程构成的复杂体系,其中紧邻黄河北岸的挑坝和格堤体系才是铜瓦厢埽工所在,黄河北摆的现象在道光时期已经非常明显。因此,确定兰阳上汛三堡所在位置非常重要。按前述操作方法,基于道光《豫省河工图》,本研究确定兰阳上汛三堡所在地(今兰考东坝头镇东700米黄河河道内)。决口点位置的重新认识确定了决口点正是清代档案中记录的“兰阳无工河段”①,“铜瓦厢改道”的直接原因之一其实是清政府对“工”的布局出现问题,而非铜瓦厢本身工程出现问题。这一认识使得学界能够重新思考1949年以来得出的一些认识,比如用铜瓦厢工程腐败、太平天国战争导致清廷无暇顾及河务等解释此次大改道的成因[36],而是回到清代河务制度本身,从制度结构性不足角度重新认识大改道的原因。“铜瓦厢改道”的重新认识仅是一个例证,实际上,古旧地图在历史时期黄河变迁(改道、决口、摆动以及管理方式)研究中的作用仍需更多案例进行验证,进而总结为历史自然地理的系统性研究方法,革新历史地理学的研究方法。
4 结论与展望
(1)古旧地图的信息化包括管理信息化、内容自动化提取和专题数据利用3个环节。
(2)编目方案能提高古旧地图的管理效率。DHYR建设尝试采用RDF方案对平台图形资料库进行编目,这一方法实现了图形资料信息的标准化,在提高信息检索效率、实现跨库链接以及不同知识体系融合方面发挥巨大作用,能解决历史地理信息化中的数据孤岛现象。
(3)基于深度学习的古旧地图地名检测和提取技术能够快速、准确地整理古旧地图中的地名信息。本研究所采用的“U-Net架构深度神经网络模型”在处理古旧地图中提高了信息采集的准确率和完整性,效果良好。
(4)信息化手段能够支持中小型学术团队进行批量文献处理、数据重建与分析,克服人力、财力限制,完成较复杂的大型跨学科研究任务。历史地理学界有必要学习图情知识体系,增强与图情学界的交流。
注释
①咸丰五年七月初九日河南巡抚英桂行移具奏河水盛涨下北厅兰阳汛三堡漫溢夺溜. 黄河水利委员会,档案号:清1-4(6)-13- 015.
