去中心化的数据处理方案设计
2021-12-09李光程赵庆林
李光程,赵庆林,谢 侃
(1. 澳门科技大学 资讯科技学院,澳门 999078;2. 广东工业大学 自动化学院,广东 广州 510006)
当前,集中式框架已被大多数数据处理平台(例如,MapReduce[1],storm[2],flink[3])广泛采用,在该平台中,主节点集中控制和管理多个从节点。但是,这种集中式框架通常具有以下缺点:(1) 主节点中出现单点故障或瓶颈[4-5];(2) 扩展集群规模的维护成本高[3];(3) 集群达到一定规模时的吞吐量可伸缩性问题。在大数据时代,随着高并发的实时流媒体数据处理的增加,上述问题变得越来越严重。因此,一个根本的解决方案是采用去中心化的框架。
最初设计用于记录交易的区块链[6]被认为是一种新的去中心化计算框架,具有很大的潜力来满足各种计算需求。在这种去中心化的框架中,没有中心实体,所有节点都是等效的参与者,并通过共识机制共同维护交易的一致性[7]。去中心化的本质允许无限的计算节点加入区块链系统,因此该系统能够聚合巨大的计算资源。例如,早在2013年,比特币网络[7]就已经比前500名超级计算机的总和强大[8]。区块链的去中心化特征和聚集的巨大计算资源是解决集中式框架的上述缺点所迫切需要的。
不幸的是,在主流的区块链系统中,例如比特币[7]和以太坊[9],巨大的计算资源主要消耗在共识机制中,例如工作量证明(Proof of Work, PoW),而不是解决有意义的实际问题(如统计流媒体视频中的汽车数量)。因此,提出了有用工作证明(Proof of Useful Work, PoUW)[10],以克服PoW的缺点,其目的是让这些计算资源解决实际问题,同时也达成共识。PoUW向前迈进,利用这些潜在的巨大计算资源进行有意义的数据处理。然而,要使用区块链进行数据处理,一项挑战是改造用于去中心化数据处理的交易记录区块链。本文致力于解决这一挑战。
在本文中,对于不需要激励机制且可以忽略网络延迟的私有网络(如数据中心),本文改造了用于交易记录的区块链框架,使其成为具有去中心化控制的数据处理框架。也就是说,本文提出了一个基于区块链的去中心化数据处理框架。在所提框架中(如图1所示),采用PoUW共识的区块链存储任务交易。每个区块链节点扮演3个角色:task manager(任务管理器)、worker(工作者)和scheduler(调度器)。task manager从数据源收集原始数据;worker首先从区块链中选择任务并从task manage下载任务,然后在本地处理它们并将结果返回给结果收集器,之后执行PoUW以竞争成为scheduler的角色;scheduler将任务信息分发到区块链中。最后,通过模拟验证了该框架的有效性。在系统吞吐量和任务响应时间方面,本文提出的框架优于传统的基于主/从的框架。同时,本文的解决方案实现了与基于主/从的框架类似的公平性。

图1 所提出的去中心化数据处理方案Fig.1 The proposed blockchain-based data processing framework
1 相关工作
本文提出了一种基于区块链的去中心化框架,用于公平数据处理。它涉及以下2个方面的相关工作。
(1) 数据处理框架。基于主/从的集中式框架已在大多数数据处理平台(例如MapReduce[1]、flink[3])中广泛采用,但它容易受到单点故障、性能瓶颈等的影响。这些缺点已引起人们的广泛关注。例如,文献[5]提出了一种热备份机制来解决单点故障(即建立一个备份节点来接管发生故障的主节点)。文献[11]提出了一种分层的主/工作器范式(Hierarchical Master-Worker,HMW),以克服主节点的性能瓶颈。但是,所有这些改进都关注集中式框架。一个基本的解决方案是采用本文所述的去中心化框架。在去中心化框架中,所有节点都是设备参与者,因此永远不会发生单点故障。此外,该去中心化式系统易于大规模扩展,因此在性能(如吞吐量和安全性)以及硬件升级方面具有良好的可伸缩性。
(2) 区块链应用。区块链天然具有去中心化功能,因此受到越来越多的关注。例如,文献[12]为众包提供了一个基于区块链的去中心化框架,使请求者的任务可以由一群worker来解决,而无需依赖任何第三方信任的机构。文献[13]研究了基于边缘辅助的区块链的IoT,并建议使用基于信用的支付方式进行快速计算资源交易。文献[14]提出了一种用于车辆网络的基于区块链的去中心化式信任管理系统。文献[15]将区块链用于隐私保护,而用户则在陌生人之间共享信息。与上述工作不同,本文首次重塑区块链进行数据处理。这项研究有助于更好地设计通用的去中心化计算框架,以满足各种计算需求。
2 数据处理框架
本节主要介绍用于私有数据中心的基于区块链的数据处理框架。
在所提出的的框架中(如图1所示),底层区块链P2P网络由云/边缘节点组成。每个节点作为一个task manager(任务管理器),从数据源接收原始数据并将其组织成任务,其中每个任务(即最细粒度的可处理数据单元)被分配一个全局唯一的ID,并可以通过统一资源定位器(Uniform Resource Locator, URL)进行访问。属于同一服务的任务可被视为一种类型的任务,它们具有相同的属性(即资源需求、处理时间消耗、到达率)。
这些节点在充当worker或scheduler时,将通过PoUW共识机制[10]共同创建和维护区块链,每个区块都存储着待处理/处理中/完成的任务交易。也就是说,每个worker不断从区块链中选择待处理的任务交易,然后在本地处理相应的任务;在完成一个任务后(即完成一定量的有用工作),每个worker首先计算其执行的CPU指令的数量,作为完成有用工作的证明,然后依数量竞争成为scheduler的资格。成为scheduler后,节点将从task manager那里收集待处理的任务交易,从worker那里收集处理中/完成的任务交易,然后将它们发布到区块链上。
下面,将依次详细介绍区块链交易、scheduler和worker的功能,以及系统的工作流程。
2.1 区块链交易
在区块链中区块被用来存储任务交易,其中任务交易设定了一个任务的概况(如ID和类型)。如图2(a)所示,每个区块由2部分组成:区块头和区块体。

图2 区块的数据结构和示例Fig.2 The data structure of a block and a block sample
区块头用于识别区块链上的一个特定区块,由以下字段组成。
(1) hashPrevBlock:上一个区块的区块头的哈希,通过它可以将此区块连接到上一个区块。
(2) time:当前区块的生成时间(时间戳)。
(3) diff:worker在执行PoUW算法时获胜的难度系数(在算法1中进行了解释)。它控制区块链的区块生成速率,并且可以定期调整以稳定该速率。
(4) PoUW:worker在执行PoUW算法时获胜的凭证。有效的PoUW包含有关采矿成功的有用工作程序证明,以及该程序符合性检查的证明。
(5) hashBody:此区块的区块体部分的哈希,worker可利用此哈希验证区块体的正确性和完整性。
(6) transNum:包含在此区块中的交易数
区块主体存储任务交易。每个任务由其task manager分配一个全球唯一的ID。例如,假设有3个task manager:001、002和003。这些task manager分配的任务ID可以是001109、002087、003272。每个任务(以及每个任务事务)都有3种状态:待处理、处理中和完成。每个worker将根据任务属性和它的可用资源来选择和处理任务。每当一个worker选择或完成一项任务时,它将创建相应的任务交易。在收到这些交易后,其他worker将更新其本地任务列表中相应任务的状态,而scheduler将把这些交易收集到其新创建的区块中,新区块将被链接到区块链上。
一个待处理的任务交易用来通知worker哪个任务需要被处理。它由以下字段组成。
(1) taskID:任务的唯一ID。
(2) taskState:其值设置为“ pending”,表示此任务需要处理。
(3) taskType:代表任务服务类型的整数。每种任务的处理流程、到达率、资源需求(例如CPU内核、内存、网络带宽)和处理时间都相同。
(4) srcURL:任务的URL,用于下载任务数据。
(5) fairIndex:一个正数,指示处理任务以实现某些公平性标准的顺序。如果系统希望确保不同任务类型之间的处理公平性,则应按公平指数的升序处理所有任务。
处理中任务交易用于声明正在处理的任务。它由以下字段组成。
(1) taskID:任务的唯一ID。
(2) taskState:其值设置为“processing”,表示该任务正被处理。
(3) blockHeight:该任务的待处理交易所处区块的高度。如果在超时后该任务仍未完成,则worker可以找到hight = blockHeight的块,并获取任务的srcURL进行重新处理。例如,假设blockHeight = 10。一旦任务超时,worker将找到第10个块并访问相应的待处理任务交易。
(4) workerID:选择该任务的worker的ID。
(5) selectedTime:该任务被选择并开始处理的时间。根据selectedTime和当前时间,worker可以推断该任务的处理是否已超时。
已完成的任务交易用于声明已经完成的任务。它包含以下字段:
(1) taskID:任务的唯一ID。
(2) taskState:其值设置为“ completed”,表示任务已完成。
(3) blockHeight:该任务的待处理交易所处区块的高度。
(4) workerID:完成该任务的worker的ID。
图2(b)显示了一个区块的例子,其中有2个待处理的任务交易,1个正在处理的任务交易和2个已完成的任务交易。
2.2 worker(工作者)
在所提出的去中心化框架中,每个worker主动从区块链上选择和下载任务,然后在本地处理,而不是像中心化框架那样被动地接收任务。每个worker不断将其本地区块链与系统的区块链同步。在收到一个新的区块后,worker将进行以下3个操作。
(1) 选择任务。首先,每个worker更新自己的可选择任务表,例如,添加待处理任务,标记处理中任务,删除已完成的任务。然后,它调用一个任务选择方案,根据一些标准(如处理公平性)选择任务。接着,它把选择的任务广播给P2P网络。当收到这些广播信息时,其他worker会选择其他任务,而下一个scheduler将为每个被选中的任务创建一个处理中任务交易(这意味着这个任务已经被选中并在处理中),并将其记录到一个新的区块中,一旦发现这个任务的相关信息被下载,相应的task manager将改变每个被选中任务的状态(从待处理到处理中)。
(2) 处理任务。下载选定的任务后,该worker在本地处理这些任务(例如,计算一个小视频中的汽车数量)。请注意,根据PoUW共识的要求,任务应该在可信执行环境(Trusted Execution Environment,TEE)[16-17]中处理,例如Intel SGX[18],以防止恶意worker报告虚假的工作量。当完成一个任务时,worker会计算处理该任务所执行的CPU指令的数量,并将任务的结果发送给收集器,最后将完成此任务的信息广播给P2P网络。
(3) 竞选scheduler。每当一个worker完成一个任务,它将执行PoUW共识,通过运行算法1来竞选scheduler。让m代表完成一个任务所执行的CPU指令数,让d代表区块链的当前难度系数。在这个算法中,worker生成一个随机数nonce(第4行),然后检查nonce是否满足与m和d有关的不等式(第5行)。如果是,竞争结果 win被设置为1,表示该worker在竞选中获胜,因此将成为scheduler;否则, win被设置为0,表示该worker将不改变其角色。


2.3 scheduler(调度器)
当一个worker在竞争中获胜时,它将充当scheduler。在任何时候,系统只有一个scheduler。scheduler将执行以下2个操作。
(1) 创建待处理任务交易。scheduler首先从任务池中收集新到达的任务的配置文件。然后,它通过调度算法计算每个新任务的fairIndex,最后创建待处理的任务交易。去中心化的调度算法是我们未来的研究工作。
(2) 创建并分发区块。scheduler首先构造一个块体。在此主体中,它打包了3种类型的任务交易:新创建的待处理任务交易、收集的处理中任务交易和已完成的任务交易(由worker广播)。然后,构造一个包含PoUW的块头。之后,通过将块头拼接到主体上来创建一个新块,最后将新块广播到区块链P2P网络。
2.4 工作流程
基于区块链的数据处理方案的工作流程如图3所示。
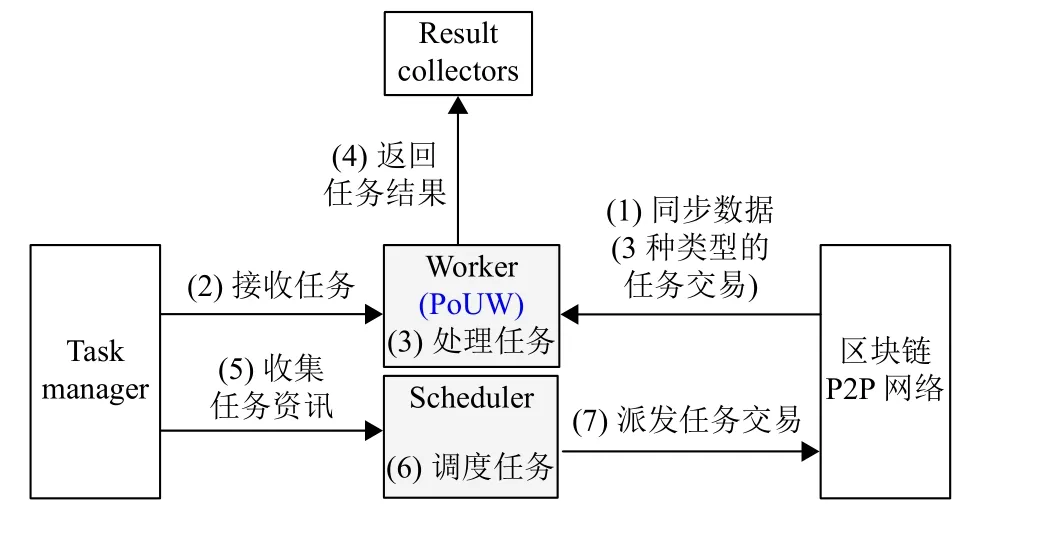
图3 本文所提去中心化系统的工作流程Fig.3 The workflow of the decentralized system
(1) 一个worker不断地与其他worker同步其区块链状态,并更新其本地任务表。
(2) 它根据任务选择方案从其本地任务表中选择待处理任务,然后从task manager中提取选定的任务,最后将其选择广播到P2P网络。
(3) 该worker处理所选任务。
(4) 每当一个任务完成后,它就会报告数据处理结果,然后执行PoUW共识(在算法1中解释)以竞选scheduler。如果获选,该节点将从worker转变为scheduler;否则,它将返回到第(1)步,继续处理任务。
(5) scheduler从所有task manager中收集新到达的任务。
(6) scheduler执行任务调度算法以计算所有新到达的任务的公平指数。
(7) scheduler创建一个新区块(包括待处理,处理中和已完成的任务交易),并将新块分发到P2P网络。
3 评估
本节通过广泛的模拟以评估本文的设计。在模拟中从系统吞吐量、响应时间和公平性方面比较了以下3个框架。
(1) Decentralization。这是本文件提出的框架。
(2) M/S。这是一个基于主/从结构的数据处理框架,主节点安排和分配任务给worker。一个主节点有12个资源份额,每个资源份额能够安排或分配15个任务/单位时间。
(3) M/S-failure。它也使用了一个基于主/从结构的框架。主节点会在一个随机的时间内失败一次,在此期间它不能安排和分配任务,但worker可以继续处理已经获得的任务。主节点将在10个单位时间后恢复。
在模拟中,固定任务属性,并改变worker的数量。假设任务的到达率遵循泊松分布,当一个任务被处理时,它需要占用worker的一部分资源并消耗一些时间。默认参数设置见表1。表1列出了8类任务的属性和5种类型的worker的属性。例如,当“worker类型”为1时,“类型1的worker数量”被设置为“5∶5∶50”。这里,“5∶5∶50”中的第二个参数5代表了步长。因此,“5∶5∶50”表示将第一类worker的数量从5以步长5依次增加到50。这相当于一个模拟序列,所有类型的worker总数从25、50、75、···增加到250,在图4、图5和图6的x轴上标出。每个模拟值是3次模拟运行的平均值,每次运行持续时间为1 200个时间单位。
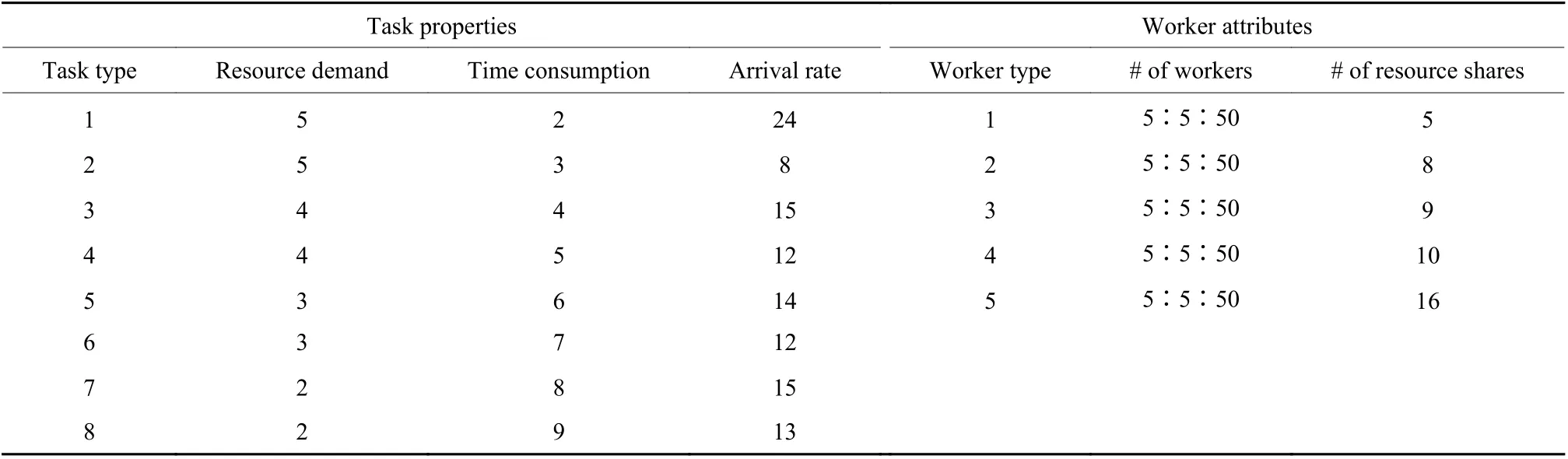
表1 默认参数设置Table 1 Default parameter settings
本文用单位时间内的原子任务数来衡量吞吐量。原子任务指只需要消耗1份资源且能在1个单位时间内完成的任务。
图4绘制了当worker数量从50到250变化时的系统吞吐量。从图中可看到本文的方案的吞吐量总是高于方案M/S和M/S-failure。当worker数量达到175人时,方案M/S和M/S-failure的主节点就会出现性能瓶颈。因此,M/S和M/S-failure的系统吞吐量不再随着worker数量的增加而增加。

图4 系统吞吐量与worker数量关系Fig.4 Relation of system throughput and number of workers
响应时间是指从任务生成到开始由worker处理的时间。响应时间越短,任务的处理就越及时。图5描绘了worker数量从25到250变化时的响应时间。从图中可看到,当worker数量少于150时,3种方案的响应时间几乎相同,并且随着worker数量的增加而几乎线性下降。当worker数量超过150人时,本文方案的响应时间下降得更快。由于主节点的瓶颈,当worker数量超过175时,M/S和M/S-failure的响应时间不再变化。

图5 响应时间与worker数量的关系Fig.5 Relation of response time and number of workers
在模拟中,通过Jain公平指数(Jain's Fairness Index)来衡量实现的公平性,其计算方法为

图6比较了Decentralization,M/S和M/S-failure之间的Jain公平指数。从图中可看到,去中心化框架的公平性总是低于2个中心化框架的公平性。这是因为在去中心化框架中,没有一个主节点来分配任务,worker自己从区块链上选择任务来处理。因此,公平性不能得到很好的保证。
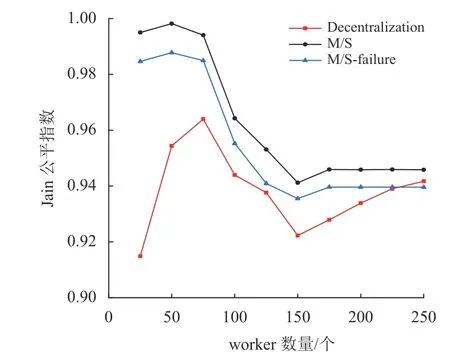
图6 Jain公平指数与worker数量的关系Fig.6 Relation of Jain's indexas and number of workers
4 结论
传统的集中式数据处理框架易受单点故障和性能瓶颈的影响。为了解决这些缺点,本文提出使用去中心化的数据处理框架重塑流行的区块链。在公共区块链中,工作量证明(PoW)共识消耗大量计算资源,主要是为了竞争领导者,而不是解决有意义的实际问题。为了避免浪费大量资源,在本文所提出的框架中,PoUW共识代替了PoW,并让区块链存储任务信息。通过执行PoUW,节点可以从区块链中选择和处理任务,同时竞争负责将待处理任务分配给区块链的领导者。仿真证明本文所提出的框架可以很好地实现设计目标。这项研究有助于更好地设计通用的去中心化计算框架,以满足各种计算需求。将来,我们将扩展所提出的框架,使其适用于高吞吐量的区块链协议,例如Bitcoin-NG[19],ELASTICO[20]和RapidChain[21]。
