算力网络中一种新颖的看门狗故障检测协议
2021-12-09徐方鑫李光程周郭许
梁 轰,冯 丽,徐方鑫,李光程,周郭许
(1. 澳门科技大学 资讯科技学院,澳门 999078;2. 广东工业大学 自动化学院,广东 广州 510006;3. 粤港澳离散制造智能化联合实验室,广东 广州 510006)
1 问题的提出
边缘计算是云计算的扩展,是一种流行的计算范式,能使计算设备更接近终端用户,旨在为用户提供便捷且快速的计算服务。它通过云中心来进行计算资源分配。如图1(a)所示,每当任务到达一个边缘节点时,该边缘节点就会向云中心发送资源请求。然后,云中心确定应为该任务分配哪种类型的资源(云中心的或边缘的),并将资源分配的结果反馈给相关的边缘节点。收到分配结果后,请求节点将任务卸载(offload)到目标边缘节点。但是,因为边缘和云之间的网络延迟,这种集中式分配机制可能导致从发起请求到任务开始处理所需的时间较长,这实际上违反了边缘计算的设计目标(例如,快速响应)。

图1 传统边缘计算及CFN中的资源分配框架Fig.1 Resource allocation framework in tranditional edge computing and CFN
近年来,学者提出算力网络(Compute First Networking, CFN)[1],以解决边缘计算中的上述问题,如图1(b)所示。CFN是一种用于计算资源分配的新颖分布式框架,它可以根据计算负载和网络状态将任务动态路由到最佳计算节点。CFN平等对待边缘节点和云节点,并将它们集成到分布式计算资源池中,然后引入一个新的控制平面来管理资源池,以便智能地分配资源,从而满足用户的需求。如果用户的请求是实时任务,则控制平面会综合考虑网络条件和可用的计算资源,智能地向用户分配邻近资源。否则,它将任务卸载到云中心进行处理。
CFN采用分布式框架为任务分配计算资源。它利用众多具有异构计算能力且在地理上分散的边缘/云节点构造一个公共计算资源池。在CFN中,一个任务可能被多个节点本地或远程地处理。这些节点之间网络连接的多样性和由此带来的网络延迟,以及节点计算能力的巨大差异,使得监控任务的处理状态非常困难。即使可以监控状态,在分布式框架中检测任务或虚拟机(Virtual Machine, VM)故障通常需要花费很长时间[2-3]。此处,故障是指当任务或VM的程序抛出运行时发生异常。另一方面,CFN要求本地或远程计算资源的可用状态应实时可见,以便有效地从计算池分配资源。因此,需要一种能够及时、远程地检测任务或虚拟机故障的机制,以快速回收这些故障所占用的资源。
1.1 动机
CFN现在处于起步阶段,并不提供获取本地或远程计算资源实时可用性的机制。IP网络或云计算中流行的故障检测方法也不适用于CFN。例如,IP网络中的双向转发检测协议[4]主要用于检测网络设备的故障,而不是任务或VM的故障。云计算中Hadoop的JobTracker[5]主要用于检测本地任务故障,而不是远程检测。因此,在CFN的分布式框架下,任务是在多个节点中本地或远程处理的,它需要一种新颖的远程故障检测设计以及时监控任务和VM的状态。
1.2 贡献
借鉴传统的Watchdog timer[6]思想,本文设计并分析了一种新颖的故障检测协议CFN-Watchdog(简称Watchdog),以解决上述CFN中本地或远程计算资源的可见性问题。本文的贡献总结如下。
(1) 提出Watchdog,这是第一个在CFN中的集中式任务和VM故障检测协议,可远程监视边缘计算中分布式计算资源的可用状态。在本文的协议中,许多Watchdog客户端定期向连接到CFN的一个Watchdog服务器报告其监视VM的状态。受益于集中协议的快速响应特点,CFN的控制平面可以实时显示其托管资源状态,并及时回收故障所占用的资源。
(2) 建立理论模型分析所提的Watchdog协议的性能。本文的模型考虑重要参数,包括检测阈值、任务处理时间和网络延迟,并阐述对系统吞吐量造成影响的误报(false alarm),以及错误事件的漏检(miss detection)。本文的模型能够为Watchdog协议选择最佳的参数设置。
(3) 运行大量的仿真,以验证该设计的有效性和理论模型的准确性。
本文的其余部分安排如下。第2节总结了相关工作。第3节概述了CFN。第4节设计了CFN-Watchdog协议。第5节从理论上分析了CFN的吞吐量。第6节评估系统性能。第7节总结了本文工作。
2 相关工作
在本节中,列出了有关传统网络、云计算和边缘计算中故障检测的相关工作。高可用性是计算框架的关键要求,其基本思想是检测故障或错误,然后执行恢复策略。
2.1 传统网络中的故障检测
在传统的网络体系结构中,可以使用某些方法来实现故障检测。典型的代表是Internet控制报文协议(Internet Control Message Protocol, ICMP)[7],双向转发检测协议(Bidirectional Forwarding Detection,BFD)[4],单向主动测量协议(One-way Active Measurement Protocol, OWAMP)[8]和连接故障管理(Connectivity Fault Management, CFM)[9]。
ICMP[7]协议通过判断接收方是否可以通过一次ping操作成功反馈其状态来检测故障。虽然ICMP可以用于检测任何设备,但其缺点是只能进行单向故障检测,并且检测频率很低。BFD[4]是一种双向检测机制,参与检测的双方都可以通过hello数据包确认对方是否仍在正常运作。BFD侧重于发现相距一跳邻居设备的故障,而无法处理相距多跳设备的场景。OWAMP[8]是基于TCP连接的网络性能测试协议。它不仅可以检测故障,而且可以高精度地测量网络性能。但是,OWAMP需要基于NTP的时间同步,因此需要更多的控制开销。CFM[9]是基于数据中心方案的连接故障检测协议,它采用定期检测的方式在更大的范围内维持所有网络的稳定运行。但是CFM过于复杂,不适合CFN场景。
所有这些故障检测方法都仅用于检测网络连接的问题,而不是检测任务执行的状态。因此,它们不能应用于CFN[1,10]。
2.2 云计算中的故障检测
随着网络技术的发展,云计算中心[11]取代了传统的数据中心,相关技术也在不断发展,其中包括故障检测。在云计算场景中,典型的故障检测技术是Hadoop下的JobTracker[5]或storm下的nimbus[12]。对于这种情况,典型的参考文献包括[5, 13-15]。
文献[5]提出了一种通过自适应检测心跳数据包来检测任务是否可以成功完成的解决方案。它通过匹配软件的统计状态和心跳条件的反馈来判断任务的执行是否失败,然后决定采用哪种失败处理策略。但是文献[5]并未考虑网络延迟的影响,这将导致误检率的提高。文献[13]提出了一种基于机器学习的故障检测方法,该方法通过检测节点的心跳反馈来判断运行状态。此外,通过调度方法,故障恢复将有序地执行。文献[14]提出了一种故障感知调度方法,可以避免故障造成的损失。该方法是预先预测任务是否有风险,并在任务失败时立即安排备份以进行替换,从而将故障损失降至最低。文献[14]则专注于优化故障恢复策略,而不是故障检测。它们的方法在云计算场景中具有一定的影响。但是,CFN场景不同于云计算场景,其拥有异构计算资源。因此,如果节点没有足够的计算能力来提供备份,则不建议使用此方法。文献[15]基于验收测试的思想,设计了大规模云场景中的故障检测机制。基于匹配检测的基本思想,它可以匹配包括软件故障、黑客攻击等不同故障场景,并建立了更直接的检测模型。但是它们没有考虑网络链接的影响。
上述方法专注于检测软件故障,而不是网络连接故障,不能应用于网络链路不稳定、时延波动范围大的CFN场景。
2.3 算力网络和边缘计算中的故障检测
雾计算[16]和边缘计算[17-18]扩展了云计算的功能并满足应用程序实时性和低延迟的要求。在雾计算中,通常在物联网网关或局域网的节点中处理任务。在边缘计算中,任务直接在边缘设备(例如传感器、智能手机、iPad)上处理。但是它们的两种集中式分配机制都可能导致从发起请求到任务开始处理的持续时间很长。为了解决该问题,CFN[1]被提出。作为用于边缘计算的新型分布式计算框架,它采用分布式方式为任务分配计算资源,其可以在本地或远程处理任务。但是,在分布式框架中检测任务或VM故障通常需要很长时间。一方面,CFN现在处于早期研究阶段,还没有这样的机制来获取本地或远程计算资源的实时状态。另一方面,常规网络中的传统故障检测协议(例如,BFD[4])主要用于检测网络设备的故障,而不是VM故障。Hadoop在云计算中的JobTracker[5]主要用于检测本地任务故障,而不是远程检测。因此,它们不能直接应用于CFN。本文首次提出名为CFN-Watchdog的故障检测协议,以检测本地和远程故障,从而可以及时回收故障所占用的资源。
3 算力网络
本节阐述了CFN中边缘节点之间的交互逻辑。首先,给出边缘节点中组件的概述;然后,详细说明它们之间的交互,以分别说明边缘节点中的资源分配和任务处理。
CFN是用于边缘计算[10]的分布式计算框架,它由控制平面和统一的计算资源池组成(如图1 (b)所示)。控制平面负责将资源分配给任务,而资源池负责管理边缘/云节点的资源。控制平面由任务代理和VM管理器(VM manager)组件组成(如图2中所示)。任务代理(Task agent)组件缓冲任务并为任务分配资源。VM管理器组件创建用于任务处理的VM,并在任务完成或检测到故障后释放VM。此外,资源池由VM和IP底层(IP underlay)组件组成(如图2中所示),并负责资源管理。VM组件包含用于执行任务的多个VM。IP底层组件为边缘/云节点之间的通信(例如,卸载任务)提供网络资源。
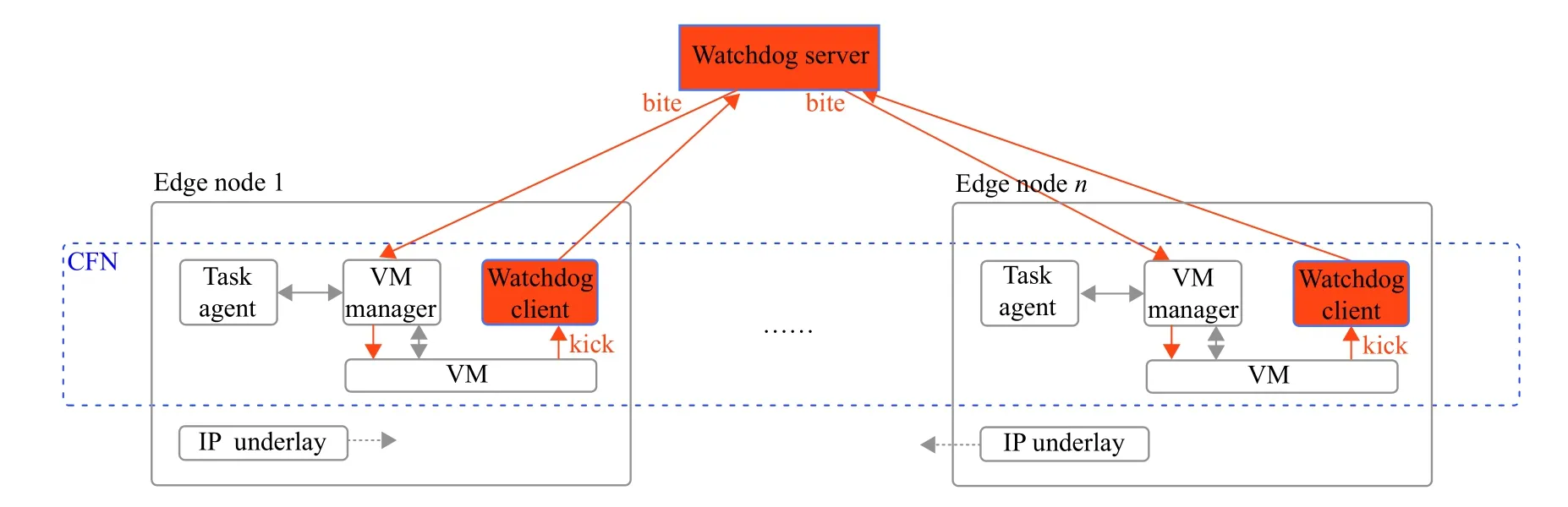
图2 CFN中看门狗协议的概览Fig.2 An overview of watchdog protocol for CFN
当任务到达CFN中时,任务代理首先会缓冲任务,然后,代理提取此任务的资源要求,再将可用资源查询请求发送到VM管理器。最后,代理判断可用资源量是否足以执行任务。如果有足够的可用资源,任务代理将处理当前节点中的任务处理请求。否则,代理会智能地考虑网络条件和可用资源的数量,找到可以执行任务的另一个节点,然后通过IP底层组件将其卸载到目标节点。
对于任务的处理,任务代理首先将具有任务资源需求的VM创建请求发送到VM管理器。然后,VM管理器将启动VM,并部署任务。任务完成后,任务代理将收集任务执行的结果。最后,代理将向VM管理器发送请求,以停止并释放VM。
3.1 Watchdog协议
为了在CFN中支持所提的Watchdog协议,VM需要添加新功能,通过kick数据包报告其状态。在VM的生命周期中,VM会定期将kick数据包发送到Watchdog客户端。本文基于用户数据报协议(User Datagram Protocol,UDP)设计kick数据包,从而无需接收相应的确认数据包,降低了通信成本,因此适用于边缘节点。其payload部分包括以下字段:
(1) kickID:标识kick数据包的唯一ID;(2) vmID:发送kick数据包的VM的唯一标识ID;(3) nodeID:发送kick包的VM所在宿主节点的唯一标识ID;(4) sendTime:VM发送kick数据包的时间。
Watchdog客户端是一个将kick数据包从VM中继到Watchdog服务器的进程。虚拟机启动后,它将在边缘/云节点的虚拟化管理平台(hypervisor)中运行。
一旦一个VM和相应的Watchdog客户端被创建,系统就通知Watchdog服务器开始监控VM,并连续向CFN控制平面报告其状态,直到该VM被释放。首先,服务器估算从其到托管VM的节点的平均网络延迟(例如,通过ping数据包)。其次,服务器根据延迟设置阈值r,以避免false alarm。然后,服务器执行位图机制,即持续地比较实际接收到的kick数据包和预期kick数据包的数量,以检测VM上是否发生故障事件。一旦检测到故障事件,服务器就会将bite数据包发送到VM管理器,以释放该VM。bite是一种通过调用管理程序API(应用程序编程接口)以达到释放/关闭VM目的的数据包。一旦收到来自Watchdog服务器的bite数据包,VM管理器就会执行释放/关闭VM的命令。
3.2 bitmap机制
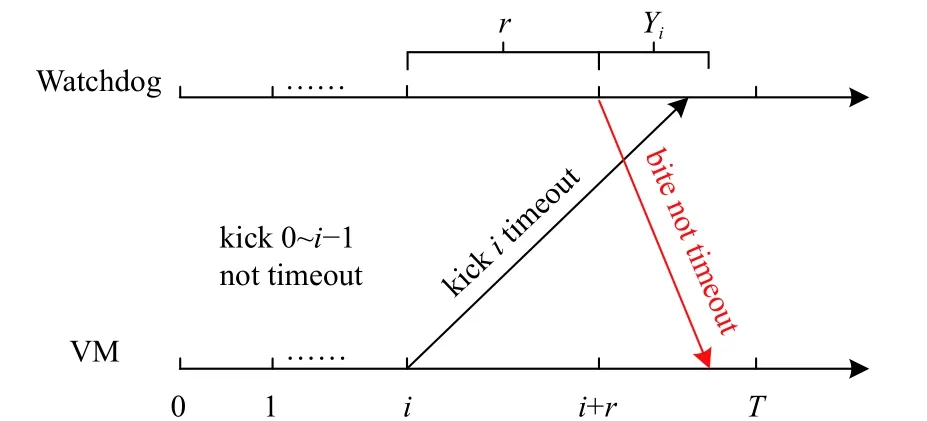
位图(bitmap)机制用于根据接收到的kick数据包连续检测故障事件,能够减少由于网络延迟或传输错误[19]而导致的false alarm。当需要监控一个执行任务的VM时,Watchdog服务器首先根据一个阈值r启动一个计时器(该阈值将在阈值设置部分详细介绍),并与该VM保持时间同步,这里,成功执行完一个任务的时长为T。然后,该服务器创建一个位图数组(bitmap array)以记录VM的状态。此后,对于VM的执行时间[0,T)中的每个时间单位,Watchdog服务器执行以下2个阶段。
(1) 构造bitmap数组。Watchdog服务器可能会收到在sendTime=i时刻发出的kick数据包。如果该数据包的接收时间在时间[i,i+r]以内,则服务器会将位图数组中的第i个元素设置为1,这表示VM在时刻i的状态是正常的。相反,如果服务器直到时刻i+r都没有收到kick数据包,它将把位图数组中的第i个元素设置为0,这表明在时刻i时,VM上发生了故障事件。以图3为例,假设阈值r设置为2,Watchdog服务器在时刻2之后收到在时刻0发出的kick数据包,以及在时间[1,3]内接收到了在时刻1发出的kick数据包。因此,位图的第0个元素为0,位图的第1个元素为1。
(2) 使用滑动窗口w检测故障事件[1,20]。位图数组中设置了0和1值并从第i个元素开始,Watchdog服务器检查w个元素(即从i到i+w−1的元素),其中i=0,1,···,T−1。如果在w个元素中存在一个0,则Watchdog服务器检测到VM上发生了故障事件;否则,如果w个元素的值都为1,则Watchdog服务器认为VM上没有故障事件发生。为简单起见,本文设计滑动窗口大小等于阈值,即w=r。以图3为例。假设边缘节点中的VM在持续T时间内执行任务,并且位图的第0个元素和第1个元素的值分别为0和1,并且滑动窗口w的值设置为2。由于在前2个元素中存在0,Watchdog判断VM遇到了故障。但是,如果将第0个元素设置为1,则Watchdog会认为VM正在正常运行。
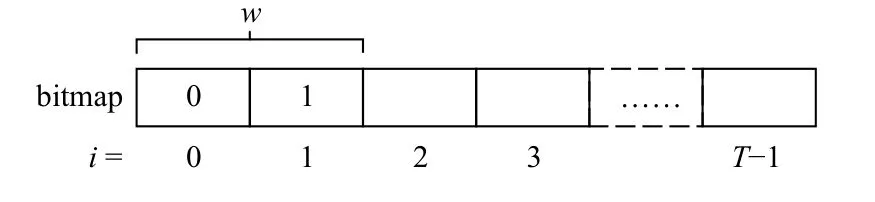
图3 看门狗监控的bitmapFig.3 Bitmap for watchdog monitoring
3.3 阈值设置
阈值用于避免false alarm问题。引入阈值设置的原因解释如下。边缘/云环境中的网络延迟在很大范围内变化,这会影响kick数据包的到达时间(例如,kick数据包可能无法及时到达)。在这种情况下,Watchdog服务器将错误地判断有故障事件发生(即false alarm)。因此,需要为Watchdog服务器设置一个阈值,以防止网络延迟对kick数据包的影响。
阈值的设置基于Watchdog服务器与受监控VM所在的边缘/云节点之间的网络延迟。首先,当创建并启动一个VM时,Watchdog服务器将通过ping数据包估计与该VM之间的网络延迟。其次,服务器将检查延迟阈值映射表以找到合适的阈值(该表可以手动维护,也可以使用机器学习方法维护)。最后,设置阈值并用于监控VM。
4 理论分析
本节将从理论上分析所提出的CFN-Watchdog协议的吞吐量。首先给出模型假设,然后定义VM和Watchdog之间的交互情况(interaction cases),最后给出吞吐量。
4.1 模型假设
首先进行模型假设:
(1) 每当任务到达时,系统都会为该任务创建一个VM,然后以T个时间单位正常处理它,并在完成后最终释放VM。此外,任务的数量是无限的,而且系统按顺序处理任务。为简单起见,本文忽略VM创建和发布的时间。
(2) Watchdog与VM保持完美的时间同步,以监控VM的状态。
① 对于VM,如果它可以正常运行以处理任务,它将在时刻0,1,···,T−1向监控程序发送一个kick数据包,其中包括一个时间戳和一个序列号。一旦VM出现错误,它将不会发送kick数据包。假设每次发生VM故障或错误的概率为perr。
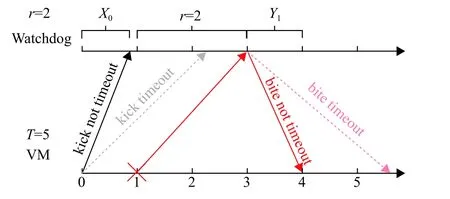
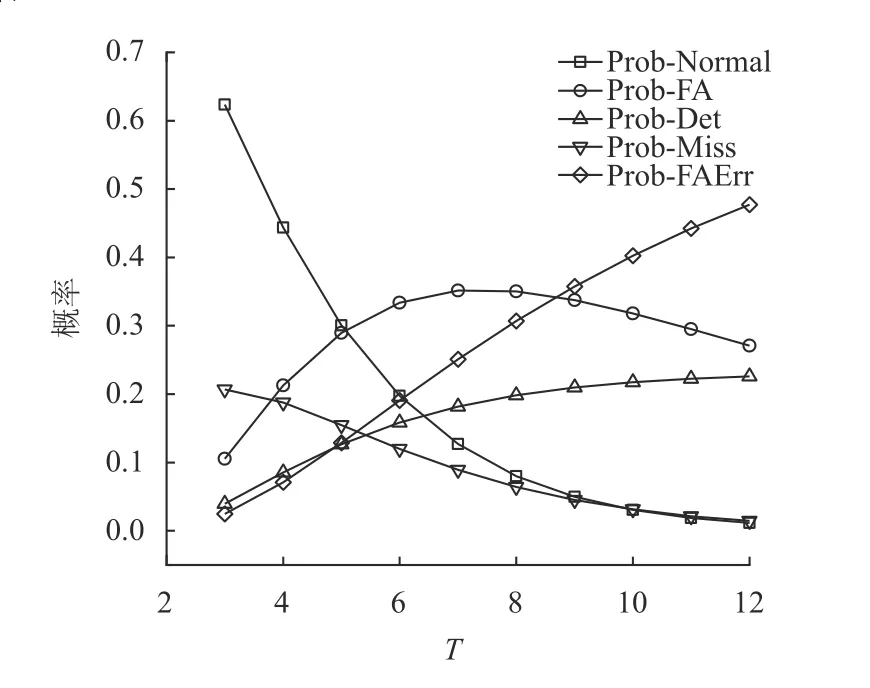
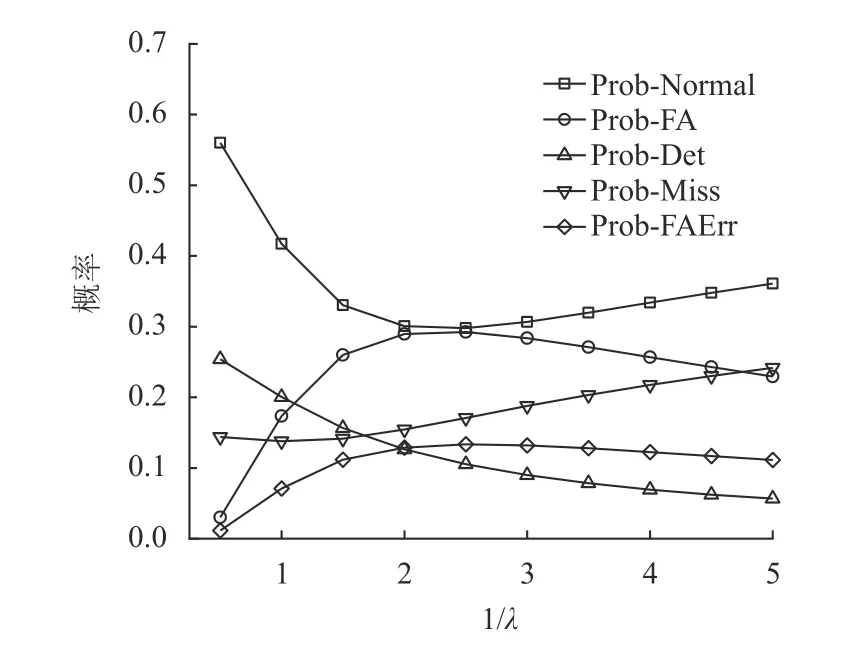
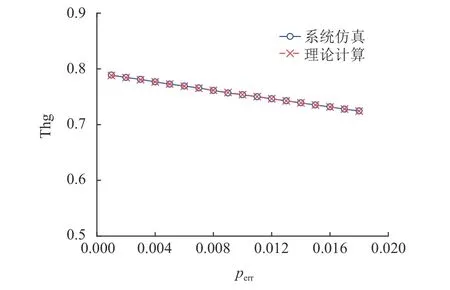
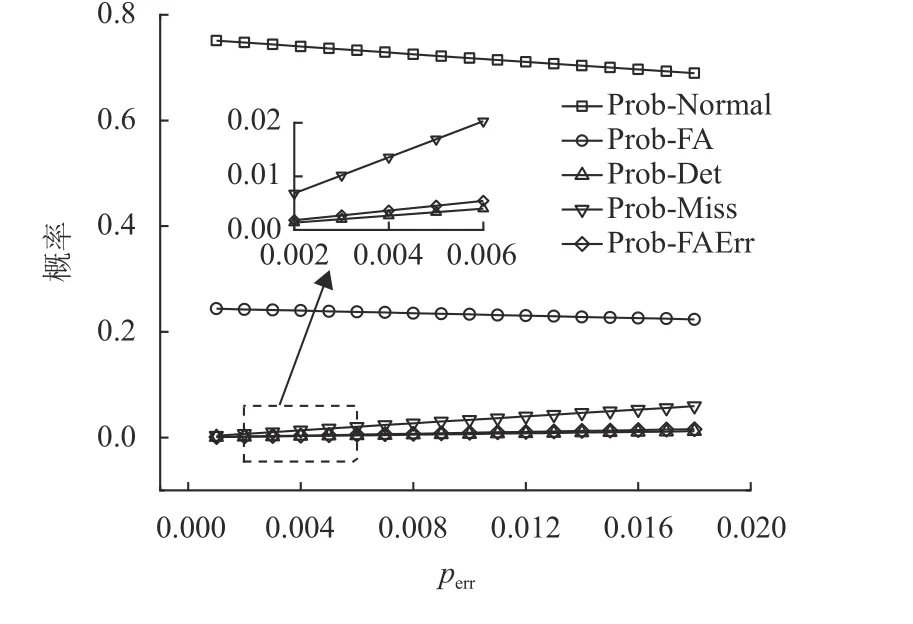
② 对于Watchdog,它将在每次i=0,1,···,T−1时启动阈值为r(0 (3) kick或bite数据包的网络延迟遵循指数分布。 考虑一个VM。本文定义以下变量。 (1) ξ:虚拟机的状态,其中ξ=0表示虚拟机正常运行,ξ=1表示虚拟机出故障。 (2)Xi:第i个(0 ≤i≤T−1) kick数据包的网络延迟,即从VM在时间i发送kick数据包的时刻至该kick数据包到达Watchdog的时间段。图4给出了X0的示例。假设Xi遵循带参数λ的指数分布,即其概率函数由式(1)给出。 (3)Yi:第i个(0 ≤i ≤T−r) bite数据包的网络延迟,即从Watchdog在时刻i+r发出bite数据包的那一刻起到该bite数据包到达VM管理器时刻的时间。在这里,Watchdog发送bite数据包的原因是:由于虚拟机错误或网络延迟,Watchdog没有收到预期的应该在时刻i发出的kick数据包,因此在r时间单位后触发了一个bite数据包。图4给出了Y1的示例。本文假设Yi也遵循带参数λ的指数分布,即其概率函数由g(x)=λe−λx,x≥0给出。 图4 X0和Y1的示例,其中r=2以及T=5Fig.4 Examples of X0 and Y1, where r=2 and T=5 (4)f(y;b):截断的指数分布的概率密度函数(Probability Density Function, PDF),即取值在0到b之间的指数随机变量的PDF,即式(2)。 然后根据VM是否出错(ξ=0),kick数据包超时是否发生(Xi>r)以及bite数据包超时是否发生,将所有VM和Watchdog交互分为8种情况,如图5所示。 图5 8种情况的树Fig.5 Tree of 8 cases 在分析每种情况下发生的概率以及VM在每种情况下消耗的时间之前,定义以下事件。 通常,VM在时刻0开始执行任务,并在时刻T完成任务,此后将释放VM的资源。但是,该期间可能会发生任务或VM故障,因此Watchdog服务器可能会与Watchdog客户端进行通信,以监控任务处理或VM的状态。Perri表示时刻i(i=0,1,···,T−1)发生任务或VM故障或错误的概率,Psuc表示在VM执行期间没有故障的概率。每个时刻VM故障或错误发生的概率为perr。Perri和Psuc分别如式(3)和式(4)所示,其中式(4)的T为完成一个任务所需的时间。 下文详细介绍情况1、2、3,其他情况的分析方法与之类似。 4.2.1 情况1和情况3 在这2种情况下(如图5所示),VM正常运行,并且正常事件(normal event)的发生使得VM由于未收到任何bite数据包而成功完成任务。未收到任何bite数据包的情况有2种:(1) 无bite数据包发送,对应情况1;(2) bite数据包超时,对应于情况3。下面,描述每种情况。 (1) 在情况1中,有两种因素导致无bite数据包发送:一种是任何kick数据包都没有超时;另一种是第i个踢包有超时,但i等于或大于T−r,即i≥T−r。图6给出了该两种因素导致正常事件发生的示例。在图6 (a)中,假设VM每次从0到T−1发送kick数据包,并且它们均未超时。因此,它们中的任何一个kick数据包都不会触发Watchdog发送bite数据包,并且VM将成功完成任务。在图6 (b)中,假设VM发送第i个kick数据包,其中i=T−r并且该kick数据包超时,这应该触发了Watchdog在阈值r单位时间后(即时刻T),发送bite数据包。但是,在时刻T及之后,VM结束并且Watchdog停止发送任何bite数据包。因此,无任何bite数据包发出以终止VM,这将导致任务成功执行。 图6 情况1的例子Fig.6 Examples of case 1 (2) 在情况3中,normal event是因为bite数据包超时而发生的。图7给出了情况3的正常事件的示例,该例子中由于第i个bite数据包的超时,Watchdog无法终止正常运行的VM,从而使得任务能够成功执行。假设VM在时刻i发送第i个kick数据包,并且该数据包超时。然后,在阈值r之后,Watchdog在[i,i+r]期间未收到预期的第i个kick数据包,因此发送第i个bite数据包尝试终止正常运行的VM。但是,该bite数据包超时,因此Watchdog无法终止VM,从而导致任务成功执行。 图7 情况3的例子Fig.7 An example of case 3 令Pnor表示normal event (即情况1和情况3)发生的概率,可以通过式(5)计算。 其中Pfa可在4.2.2章节的末尾计算得到。并且能够通过此公式计算Pnor的原因是当没有错误发生时,只有normal event或false alarm事件会发生。 令Tnor表示normal event(即情况1和情况3)发生时VM的平均占用时间,即从VM开始执行任务到VM成功完成任务的时间间隔。因此,很明显Tnor可通过式(6)计算。 4.2.2 情况2 在这种情况下(如图5所示),VM正常运行,但是false alarm事件的发生错误地终止了正常运行的VM的执行。假设VM发送第i个kick数据包(即在时刻i发出的kick数据包),而且由于网络延迟该数据包发生超时(即kick数据包未能在[i,i+r]时间内到达)。此超时将导致Watchdog发送bite数据包,并且该bite数据包会及时到达VM管理器,从而错误地终止了正常运行的VM。图8给出了情况2的示例,当Watchdog由于第i个kick数据包超时而错误地终止了正常运行的VM时,误报事件发生。 图8 情况2的例子Fig.8 An example of case 2 令Pfai表示第i个kick数据包超时而导致false alarm的概率。请注意,Pfai是在VM正常运行的情况下的概率。 在本节中,将进行广泛的仿真,以评估CFNWatchdog设计的有效性和理论模型的准确性。 令T表示成功执行任务的时间,1 /λ表示平均网络延迟,perr表示每次发生VM错误的概率。令Prob-Normal表示VM正常完成任务的概率,Prob-FA表示没有错误时(即情况2)false alarm的概率,Prob-Det表示情况4的成功检测(detection)的概率。Prob-Miss表示情况5、6和8漏检(miss detection)的概率,而Prob-FAErr表示发生错误时false alarm的概率(即情况7)。下面,展示了系统参数(即T,1 /λ和perr)如何影响Thg,Prob-Normal,Prob-FA,Prob-Det,Prob-Miss和Prob-FAErr。表1显示了4组仿真实验的参数设置(包括设置(a)、(b)、(c)、(d))。在这里,利用“a:b:c”模式表示参数值从a到c随着步长b的增加而增加。例如,“1:1:10”表示将参数值从1增加到10,步长为1。 图9和图10使用表1的设置(a)绘制了Thg和Normal,FA,Det,Miss,FAErr的概率趋势图。在此仿真中,将平均网络延迟1 /λ的值设置为2,错误概率perr的值设置为0.1,而Watchdog的阈值r设置为2,但是任务的执行时间T从3增长到12。 表1 参数设置Table 1 Parameter settings 图9绘制了T在3到12之间变化时系统仿真和理论分析的吞吐量(分别由蓝线和红线表示)。从图9可以看出,吞吐量随着T增加而减少。原因如下:一方面,当将perr设置为0.1时,随着T的增加,VM上发生错误的可能性也会增加。另一方面,如果T较长,则等于Watchdog阈值的固定平均网络延迟将导致FA和FAErr的概率更高,从而终止正常运行的VM,降低吞吐量。 图9 Thg随着成功执行一个任务时间的变化趋势Fig.9 System throughput varies as time of successfully executing a task varies 图10绘制了当T在3到12之间变化时,FA,Det,Miss和FAErr的概率变化图。从图10中,有以下观察结果。 图10 各种情况下事件发生的概率随着成功执行一个任务时间的变化趋势Fig.10 Probabilities of event of each case happening vary as time of successfully executing a task varies (1) 随着T增加,Normal概率降低。这是由于随着T增加,FA和FAErr发生概率增加且概率值增加到非常大,这意味着FA和FAErr事件都占用了整个系统运行的时间。 (2) FA的概率先缓慢增加然后降低,而FAErr的概率随着T的增加而急剧增加。原因可以解释如下:当错误概率设置为0.1时,随着T的增加,在任务执行过程中任何时间都不会发生错误的概率将迅速下降。结果,FA的概率首先缓慢增加到最大值,然后降低,因为没有遇到错误的VM数量迅速变小。但是,将错误概率设置为0.1时,发生错误的概率几乎不会降低,并且遇到错误的VM数量也不会改变太多。因此,FAErr的概率迅速增加。 (3) 随着T的增加,Det的概率增加而Miss的概率减小。这是因为平均网络延迟越接近CFN-Watchdog阈值,越容易出现kick数据包的网络延迟超过阈值的情况。因此,更容易触发bite数据包的发送。T越长,bite数据包就越有机会到达VM,这导致Det的概率增加而Miss的概率降低。 在表1的设置(b)下,图11和图12展示了Thg和Normal,FA,Det,Miss,FAErr的概率。本文将平均网络延迟1 /λ的值从0.5~5,同时将其余参数的每个参数保持为固定值。 图11显示系统吞吐量首先下降到最小值,然后随着平均网络延迟从0.5~5的变化而缓慢增加。下降的主要原因是FA和FAErr的概率都有所增加,而增长的主要原因是,FA和FAErr的概率都缓慢递减了。这意味着FA和FAErr事件占据整个系统运行时间的时间首先增加,然后缓慢减少。 图11 Thg随着平均网络时延的变化趋势Fig.11 System throughput varies as mean network delay varies 图12分别绘制了平均网络延迟1 /λ在0.5~5之间变化时Normal,FA,Det,Miss和FAErr的概率趋势,在此图中,有以下观察结果。 图12 各种情况下事件发生的概率随着平均网络时延的变化趋势Fig.12 Probabilities of event of each case happening vary as mean network delay varies (1) FA和FAErr的概率均随着1 /λ的增加先增长后递减。当平均网络延迟小于并接近阈值时,kick数据包发生超时的概率增加,这使得bite数据包的触发变得更加容易。因此,FA和FAErr的概率都首先增加。当平均网络延迟大于阈值时,即使kick数据包超时的概率较高,但bite包发生超时的概率也较高,这降低了FA和FAErr的概率。 (2) Normal的概率先降低,然后随着1 /λ的增加而缓慢增加。原因是使用固定的perr且没有错误发生时,将发生误报事件或正常事件。因此,Normal的概率趋势与FA的趋势相反,FA的趋势的原因已在上面说明。 (3) 随着1 /λ的增加,Det的概率降低,而Miss的概率增加。这是因为当平均网络延迟变大时,bite数据包将具有更高的网络延迟。这意味着bite数据包将晚于时间T到达VM管理器。因此,当1 /λ增大时,检测事件发生的概率就会降低,而丢失检测事件的发生概率会更高。 图13和图14分别绘制了Thg,Normal,FA,Det,Miss,FAErr的概率变化趋势。通过在表1中的设置(c)进行仿真和理论计算来获得这些结果。在此仿真中,设置参数T,1 /λ和r,但perr的范围为0.001~0.018,采用的值要比之前的实验小得多。 图13绘制了perr在0.001~0.018之间变化时的吞吐量图。从图中可以看出,吞吐量随着perr的增加而降低。原因如下:一方面,由于每次发生VM错误的概率非常小,因此Det,Miss和FAErr的概率非常小。但是,随着perr的增加,接近T的高平均网络延迟1 /λ导致Miss的概率增加,从而使吞吐量下降。另一方面,当平均网络延迟1 /λ等于阈值r时,发生虚假警报事件,这也降低了吞吐量。 图13 Thg随着单位时间VM出错概率的变化趋势Fig.13 System throughput varies as probability of VM error per unit time varies 图14显示了当perr从0.001增加到0.018时,FA,Det,Miss和FAErr的概率趋势,具体如下: 图14 各种情况下事件发生的概率随着单位时间VM出错概率的变化趋势Fig.14 Probabilities of event of each case happening vary as probability of VM error per unit time varies (1) 随着perr的增加,FA的概率会缓慢下降,因为随着perr的增加,VM没有错误发生的概率会降低。 (2) 当perr减小时,漏检的概率增加。这是因为VM的执行过程中发生错误的概率随perr的增加以及与T和阈值r接近的平均网络延迟而增加,使得bite数据包的超时更容易发生。 (3) Det和FAErr的概率相对较小,因为此仿真实验中采用的perr非常小。并且随着perr的增加,Det和FAErr的概率不断增加,因为发生错误的概率也随之增加。 图15绘制了系统吞吐量,其中Watchdog的阈值r在1~11之间变化,其中T=12,1/λ=0.3和perr=0.01,如表1的设置(d)所示。从该图可以看出,吞吐量首先增加到最大值,然后减小,并且有一个Watchdog的最佳阈值设置,即r=2。原因如下:在固定的平均网络延迟设置为0.3的情况下,当r≤2时,吞吐量会由于虚警事件的概率降低而增加。当r>2时,吞吐量降低,因为r越大,漏检事件的概率就越高。 图15 Thg随着看门狗阈值的变化趋势Fig.15 System throughput varies as threshold for watchdog varies 图16绘制了系统正常完成的任务数量变化图,该数量变化随着单位时间VM的perr从0.01~0.15变化(如横轴所示)。实验中,将设置T=12,1/λ=0.3。图中:灰色矩形框表示无Watchdog配置情况下系统正常完成的任务数量(简称为No-Watchdog-Scheme);蓝色线条表示配置了本文所提出的Watchdog情况下系统正常完成的任务数量(简称为Watchdog-Scheme),其中Watchdog的阈值r设置为2;带圆圈的虚线为Watchdog-Scheme相对于No-Watchdog-Scheme的系统正常完成的任务数量增长比。 图16 正常完成任务的数量随着单位时间VM出错概率的变化趋势Fig.16 Amount of normally finished tasks varies as probability of VM error per unit time varies 从图16中,可以看出: (1) 随着perr的增加,No-Watchdog-Scheme和Watchdog-Scheme的正常完成任务数量均减小,但Watchdog-Scheme的系统正常完成任务数量一直比No-Watchdog-Scheme多。这是因为Watchdog能够提前检测出发生故障的VM,及时将其资源释放用于执行下一个任务,从而使Watchdog-Scheme能够获得更多正常完成的任务数量。 (2) 随着perr的增加,Watchdog-Scheme相对于No-Watchdog-Scheme的系统正常完成的任务数量增长比不断增大,当perr达到0.15时,该比例可达0.748 1(即74.81%)。从此可看出,Watchdog-Scheme在perr增大时有显著的优势,即能够显著增加系统正常完成的任务数量,使系统的吞吐量增加。 此外,由于仿真结果与理论结果之间的平均相对误差在图9,图11,图13和图15中均低于0.4%,因此本文的理论模式的准确性很高。 在边缘计算中,CFN最近被提出以加速资源调度和任务分配。它要求实时了解本地和远程计算资源的可用状态。本文首先提出了一种名为CFN-Watchdog的集中式故障检测协议,提供CFN所需的可见性。本文的Watchdog协议可以及时回收故障所占用的资源,并显著地提高系统吞吐量。建立了一个理论模型,分析各种设计参数对系统吞吐量的影响。进行了大量的仿真,验证了本文提出的协议非常有效,并且理论模型非常准确。4.2 交互情况
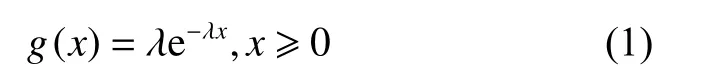



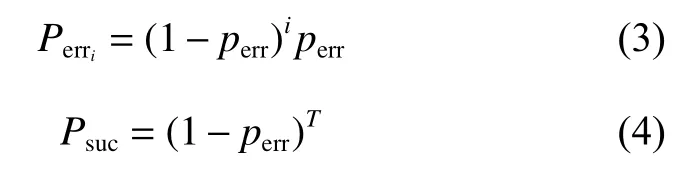






4.3 吞吐量


5 性能评估





6 总结
