基于视觉词袋模型的稻曲病发病程度感知
2021-12-08梁睿杰陈丰农
梁睿杰 陈丰农


摘要:为了快速、精准地感知水稻稻曲病发病程度,以实现高度自动化的稻曲病大面积监测,结合高光谱成像和视觉词袋模型(BoVW)自动感知稻曲病发病程度。首先利用UHD185画幅式高光谱仪获取发病水稻光谱成像数据,利用主成分分析(PCA)筛选特征波段,再用正方格划分区域并获取区域特征,然后利用K-means算法聚类生成视觉词典,聚类中心作为视觉单词,最后利用矢量化和直方图统计得到视觉词袋模型表达。将198幅水稻高光谱图像的“视觉词袋模型表达-发病等级标签”作为数据集,随机选择3/5作为训练集,剩下的为测试集,采用支持向量机(SVM)建立稻曲病发病程度感知模型,感知精度为84.81%。结果表明,结合高光谱成像技术和视觉词袋模型可以有效感知稻曲病发病程度,为稻曲病大面积自动化监测提供参考。
关键词:稻曲病;高光谱成像技术;病害程度分析;视觉词袋模型;支持向量机;自动化监测
中图分类号: S127;TP391.4 文献标志码: A
文章编号:1002-1302(2021)22-0198-06
收稿日期:2021-03-18
基金项目:浙江省重点研发计划(编号:2021C02011);浙江省基础公益研究计划(编号:LGN18F030002)。
作者简介:梁睿杰(1995—),男,浙江台州人,硕士研究生,主要从事农业遥感图像处理研究。E-mail:1327571567@qq.com。
通信作者:陈丰农,博士,副教授,主要从事图像处理与模式识别等方面的研究。E-mail:fnchen@hdu.edu.cn。
水稻是我国主要粮食作物,其总产量占全国粮食总产量的50%,有65%的人口以水稻为主食[1]。近几年,稻曲病的发生范围和危害有逐年上升趋势,已逐渐成为水稻主要病害,对水稻产量、品质甚至人畜生命健康造成严重危害[2-3]。目前,稻曲病监测主要依靠农户、植保专家实地考察,进行人工评估。这种方法适用性低[4],不仅耗费大量人力物力,而且缺乏代表性,难以适用于大面积稻曲病的实时监测[5]。因此,开展稻曲病发病程度感知研究有现实意义。
不同植物对同一波段电磁波的反射和吸收能力不同,導致光谱特异性,当植物受到病虫害胁迫后,由于应激性,体内水分、色素含量以及内部结构会产生变化,从而光谱特性发生改变[6]。因此,光谱能够作为研究植物病害的重要依据。近年来,随着高光谱成像技术的发展并因其无接触、无损害、效率高等优点,高光谱分析成为稻曲病检测的重要手段。高光谱成像技术综合了光谱信息和图像信息,可以快速、准确地提供大量肉眼无法感知的信息特征[7],其中光谱信息能够反映物体内部物理结构和组成,图像信息能够反映物体外部特征,在稻曲病监测中具有独特优势。
目前,已有学者将高光谱成像技术应用于作物病虫害检测,并取得了成功。谢亚平筛选特征波段并构建支持向量机(SVM)模型,识别稻曲病发病区域,识别精度达到97.2%[8]。有学者基于可见光和近红外波段,构建识别模型,进行稻瘟病害分级,分级准确率均达到了95%以上[9-10]。黄双萍等提取稻瘟病的光谱词袋模型(BoSW)表达,并结合SVM识别病害程度,识别精度达94.72%[11]。有研究通过敏感波段构建特征集,实现小麦白粉病的监测[12-13]。由于不同病害的表现症状不同,不存在普适的病害判别标准[14],上述研究均利用特征波段构建模型识别病害,并取得较高的识别精度,证明了高光谱成像技术应用于作物病虫害检测的可行性,为基于高光谱的稻曲病发病等级感知提供了依据。
本研究根据稻曲病发病特点,提出基于视觉词袋模型的方法感知稻曲病发病程度。选择不同发病程度的水稻并获取高光谱图像,进行特征波段筛选和区域划分,并构建视觉词典,利用直方图得到每株水稻的视觉词袋模型表达,最后用SVM构建稻曲病发病程度感知模型。
1 材料与方法
1.1 研究区域概况
研究区域位于浙江省杭州市富阳区中国水稻研究所试验田(119°55′E,30°4′N),属亚热带季风气候,降水充沛,平均相对湿度70.3%,临近富春江,这种四季温暖、湿度较大的气候环境有利于稻曲病菌滋生和侵染。作为长期的病害试验基地,田块中菌源充足,稻曲病自然发生,无需人工接种。为获取发病程度不同的水稻,前后共进行7期播种,2019年6月15号为第1期,之后每期间隔5 d,试验组喷洒激素,对照组喷洒清水,每期有12个小区,6个小区作为试验组,其余6个作为对照组,每个小区长 35.0 m,宽1.8 m。
1.2 数据采集
2019年10月10日,天气晴朗,水稻处于灌浆成熟期,于当天上午10点至下午2点采集高光谱数据。使用UHD185画幅式高光谱仪获取高光谱数据,该仪器覆盖可见光波段到近红外波段的光谱(450~950 nm),图像空间分辨率为1 000 pixel×1 000 pixel,光谱分辨率为4 nm,共126个波段。由于暗电流和噪声,需黑白标定,扫描白板获取反射率为1的全白标定图像Iw,盖上镜头获取反射率为0的全黑标定图像Id,实际获取的第i个波段的图像为Is,则高光谱成像在第i个波段的矫正公式为
R(i)=Is(i)-Id(i)Iw(i)-Id(i)。(1)
数据采集时,根据稻曲病分级标准采摘发病程度不同的稻穗置于黑色幕布,以减少背景干扰,镜头距稻穗20~30 cm采集图像,获取的图像见图1,共采集198幅图像。
1.3 稻曲病分级标准
国际水稻研究所根据受侵染的小穗面积将稻曲病分成6个等级[15]:0级(未受到侵染),1级(侵染面积小于1%),3级(侵染面积为2%~5%),5级(侵染面积为6%~25%),7级(侵染面积为 26%~50%)和9级(侵染面积为51%~100%)。这是理想化的分级标准,在实际试验中,9级稻穗几乎不存在,1级和3级稻穗难以区分,因此本研究将稻曲病发病程度分为4个等级:健康(未受到侵染),轻度(侵染面积小于5%),中度(侵染面积为6%~25%)和重度(侵染面积为26%~100%)。
本研究采集的198个样本病害等级统计见表1。
1.4 视觉词袋模型构建
1.4.1 视觉词袋模型
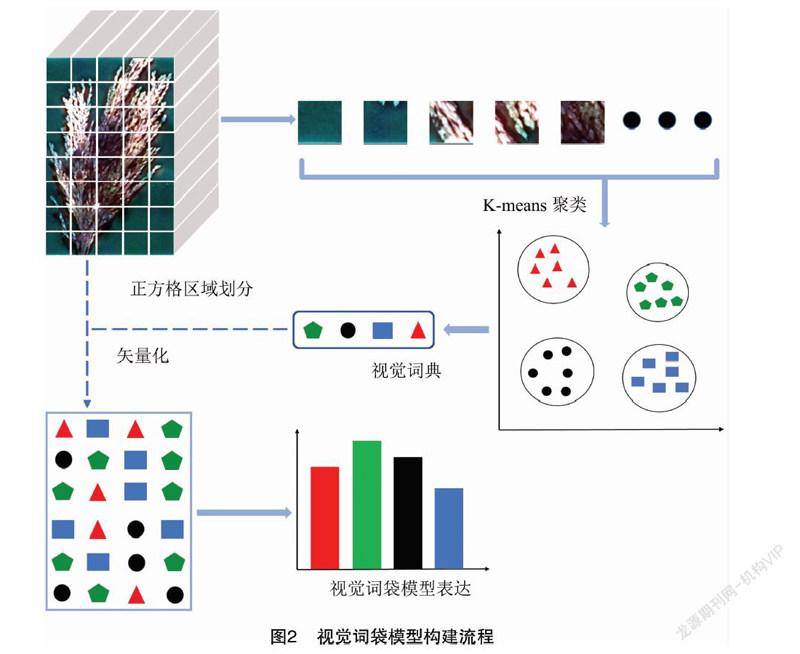
视觉词袋模型是一种中层特征编码方法,其算法杂度低、表征能力强,在图像分类中得到广泛应用[16],主要包括4个步骤:图像底层特征提取、视觉词典生成、视觉单词特征构建和分类器构造[17]。具体流程如图2所示,首先,采用主成分分析(PCA)筛选特征波段,用正方格对特征波段的组合图像划分区域;然后,利用K-means聚类方法对划分的区域聚类以生成视觉词典,聚类中心作为视觉单词;基于视觉单词对各区域矢量化,用视觉单词表征各区域;最后,用直方图统计每幅图像中视觉单词的频数,得到视觉词袋模型表达。
1.4.2 特征波段筛选
高光谱图像存在数据维度高、波段间相关性高、数据冗余等问题[18],因此需降维处理。PCA是常用的降维方法,通过计算原始数据的协方差矩阵以及特征值,选择对主成分贡献最大的前k个特征值和特征向量,通过线性变换将原始空间Rn映射到特征空间Rk,极大程度上保留了原始数据信息,同时消除噪声,实现数据降维[19]。对比前几个主成分图像,筛选发病区域与健康区域对比强烈的主成分图像,每个主成分图像可以看成由不同波段通过加权系数线性组合而成,选择加权系数大于0.1的波段作为特征波段。
1.4.3 正方格区域划分和光谱平均
高光谱成像同时包含空间几何信息和光谱信息,可以看作由图像XY 平面以及光谱Z轴组成的三维数据[20]。本研究在XY平面内利用正方格划分区域,并计算平均光谱作为该区域的特征。相比以像素为最小单位的方法,该方法存在以下优点:(1)大幅度减少像素点数量,计算复杂度低;(2)同一植株不同发病部位的光谱存在差异,通过区域划分增大光谱差异性;(3)充分考虑了XY平面内相邻像素点间的相关性,在一定程度上消除图像的冗余信息。
1.4.4 K-means聚类生成视觉词典
将正方格划分的区域作为样本利用K-means聚类。K-means算法是一种无监督的聚类算法[21],其核心思想是找到k个质心,使得每个样本到其所属质心的距离平方和最小,具体步骤如下:(1)初始化迭代次数I=1,随机选择k个区域作为聚类中心,并计算聚类中心的平均光谱C1;(2)计算每个区域到聚类中心的距离,并将该区域划分到距离最近的聚类族簇;(3)重新计算聚类中心以及聚类中心的光谱均值CI;(4)比较CI与CI-1的距离,若小于设定的阈值则结束迭代,否则迭代次数加1,重复步骤(2)和(3)。
K-means聚类保证了同一族簇内区域相似度最大,忽略光谱之间的细微差异,能在一定程度上增强BoVW模型的抗噪性能。
1.4.5 高光谱图像矢量化和直方图统计
矢量化通过计算特征之间的欧式距离将每个区域映射到对应的视觉单词,完成高层特征的提取[22]。对整幅图像所有局部区域矢量化,一幅图像可以看成是由视觉单词组成的文本,比较文本中不同单词所占比例可以区分不同文本。利用直方图统计矢量化后一幅图像中每个单词的频率并线性归一化处理,得到视觉词袋模型的表达。这种方法能够将难分类的文本特征转化成易分类的统计特征[23],精准地描述了发病部位和发病稻粒比例等原始特征,在一定程度上很好地表达了稻曲病发病情况。
1.4.6 SVM稻曲病发病等级感知模型构建
SVM基于统计学习理论,目的是构建一个最优分类超平面,保证支持向量到该分类面的距离最大,核心原则是结构风险最小化,即根据现有样本信息在模型复杂度和学习能力之间寻求折衷,以获得最佳泛化性[24]。本研究将“视觉词袋模型表达-发病等级标签”数据作为数据集,从不同发病程度水稻中随机选择3/5作为训练集,剩下的为测试集,则训练集总计119幅图像,测试集79幅图像。利用SVM分类器训练模型,并结合交叉验证法和网格搜索法筛选最优参数,同时采用一对一分类法[25]完成四分类识别,以测试集准确率和混淆矩阵作为模型性能评估指标。
2 结果与分析
2.1 基于PCA的特征波段提取
利用PCA分析高光谱全波段(450~950 nm)图像,获取前6个主成分图像,结果见图3,方差贡献率见图4-a,前6幅图像的方差总贡献率达到99.78%。PC1中正常区域和患病区域区分明显,稻粒轮廓清晰可见,噪声较少,方差贡献率为88.01%,因此选择PC1的權重系数做进一步分析。主成分图像由不同波段通过加权系数组合而成:
PCm=∑ni=1αiXi。(2)
式中:PCm为第m个主成分;αi为原始数据第i个波段的加权系数;Xi为对应波段的高光谱图像反射率。
第一主成分中各波段加权系数如图4-b所示,系数越大,其对应的原始波段对该主成分贡献越大。筛选权重系数大于0.1的波段为敏感波段,其对应波段范围为702~898 nm,共50个波段(图中黄色部分)。稻穗中色素含量较少,稻曲病菌对色素的破坏程度低,可见光波段受影响小,对稻穗内部结构的破坏大,近红外波段受影响大,702~898 nm 波段能有效反映受侵染区域内部结构的变化。
2.2 词典容量对模型感知准确率的影响
视觉词典对原始数据集的表征能力由K值决定,K值会影响稻曲病发病等级感知准确率[26],因此本研究对词典容量为50~600的稻曲病发病程度感知结果进行比较,结果见图5。
从图5可以得到,词典容量为300~350时,测试集和训练集的感知效果最好,精度分别达84.81%和94.12%。当词典容量小于300时,测试集和训练集的感知准确率均随着词典容量增大而增加。当K值过小时,部分差异较大的区域划分到相同的视觉单词簇中,导致不同单词间的关联度增加,词典无法有效表达原始特征。当词典容量大于350时,训练集准确率整体保持稳定,而测试集准确率随着词典容量增大缓慢下降。当K值过大时,聚类和矢量化过程过于精细,视觉词典结构庞大复杂,光谱特征类似的区域被划分到不同视觉单词类簇中[27],导致视觉单词间相似度增加,内聚度降低,模型抗噪性降低。
2.3 正方格大小对模型感知准确率的影响
正方格大小会对区域的平均光谱产生影响,从而影响模型感知准确率。本研究分别选择尺寸为 2 pixel×2 pixel,4 pixel×4 pixel,6 pixel×6 pixel,8 pixel×8 pixel,10 pixel×10 pixel的正方格划分区域,在视觉词典容量为300时,探究正方格尺寸对感知精度的影响,其结果见表2。
从表2中得到,當正方格尺寸逐渐增大时,训练集和测试集识别率均出现下降。当正方格大小为 4 pixel×4 pixel时,训练集和测试集均取得最高的识别精度,分别为94.12%和84.81%。正方格尺寸过小会导致划分的区域尺寸接近像素尺度,词典结构变得复杂,冗余度增加,位于交界处的区域难以区分。正方格尺寸过大,会导致区域内光谱平滑尺度过大,属于不同发病区域的像素光谱进行了平滑、组合,导致邻近的划分区域光谱相似度增大,划分的区域无法有效表达原始空间信息。
2.4 核函数对模型感知准确率的影响
SVM核函数决定模型的性能,相同的数据集,采用不同核函数能得到不同分类结果[28]。本研究分别选择核函数为线性核、径向基核、多项式核以及S型核的SVM进行感知,在视觉词典容量为300,正方格尺寸为4 pixel×4 pixel时,探究核函数对感知精度的影响。从表3中可以得到,RBF-SVM在训练集和测试集上效果均好于其他核函数,准确率分别达到94.12%和84.81%。
在视觉词典容量为300,正方格大小为4 pixel×4 pixel,核函数为RBF时,测试集和训练集感知结果的混淆矩阵见表4和表5。此时,该模型在测试集的感知准确率达84.81%,Kappa系数为0.79,训练集的感知准确率达94.12%,Kappa系数为0.92。数据采集时需人工标定稻曲病发病等级,由于缺乏经验,存在一定的标定错误,数据集中存在发病程度近似但发病等级标定不同的样本,导致该模型感知准确率不高。相邻的2个等级易发生错分,这是由于某些植株的发病程度恰好位于判别标准附近,且相邻等级的判别标准比较相近。模型总体感知准确率达到84%以上,分类结果具有高度一致性,能够有效、精准地感知稻曲病发病等级。
3 讨论与结论
本研究根据稻曲病的发病特征以及光谱图像数据,利用基于视觉词袋模型的方法感知稻曲病发病程度,该模型提取高层特征能够准确描述发病情况,具有较好的抗噪性和鲁棒性。
本研究将702~898 nm作为PCA特征波段,由于稻穗细胞色素含量少,受到稻曲病菌侵染后近红外波段发生的变化大,提取的特征波段能有效反映这种变化,并且在一定程度上消除了噪声、减少数据冗余度;同时考虑到高光谱图像在XY平面相邻像素之间的相关性,采用正方格划分区域,增加样本间的差异性,发挥了图谱结合的优势;利用K-means聚类算法生成视觉词典,忽略了区域光谱间的细小差异,增强了抗噪性;利用直方图统计视觉单词频率得到视觉词袋模型表达,将难分类的文本特征转化成易分类的统计特征,并能精确地描述发病情况。
试验结果表明,当视觉词典容量为300,核函数为RBF,正方格大小为4 pixel×4 pixel时,对稻曲病发病程度的感知效果最好,测试集准确率为84.81%,Kappa系数为0.79。本研究方法可为稻曲病大面积自动化监测奠定基础。
参考文献:
[1]李思平,曾路生,吴立鹏,等. 氮肥水平与栽植密度对植稻土壤养分含量变化与氮肥利用效率的影响[J]. 中国水稻科学,2020,34(1):69-79.
[2]陈月娣,王 超,徐铁平,等. 籼粳交超级晚粳稻稻曲病药剂控制时机的探讨[J]. 浙江农业科学,2013,55(11):1451-1453.
[3]杨健源,曾列先,陈 深,等. 我国稻曲病研究进展[J]. 广东农业科学,2011,38(2):77-79.
[4]张 初. 基于光谱与光谱成像技术的油菜病害检测机理与方法研究[D]. 杭州:浙江大学,2016:4-5.
[5]陈 兵,王克如,李少昆,等. 蚜虫胁迫下棉叶光谱特征及其遥感估测[J]. 光谱学与光谱分析,2010,30(11):3093-3097.
[6]张竞成,袁 琳,王纪华,等. 作物病虫害遥感监测研究进展[J]. 农业工程学报,2012,28(20):1-11.
[7]王红霞,李 霞. 遥感技术在农业中的应用[J]. 农业科技与信息,2019,36(23):67-69.
[8]谢亚平. 基于高光谱技术的水稻稻曲病监测研究[D]. 杭州:杭州电子科技大学,2018:1-57.
[9]冯 雷,柴荣耀,孙光明,等. 基于多光谱成像技术的水稻叶瘟检测分级方法研究[J]. 光谱学与光谱分析,2009,29(10):2730-2733.
[10]郑志雄,齐 龙,马 旭,等. 基于高光谱成像技术的水稻叶瘟病病害程度分级方法[J]. 农业工程学报,2013,29(19):138-144.
[11]黄双萍,齐 龙,马 旭,等. 基于高光谱成像的水稻穗瘟病害程度分级方法[J]. 农业工程学报,2015,31(1):212-219.
[12]沈文颖,冯 伟,李 晓,等. 基于叶片高光谱特征的小麦白粉病严重度估算模式[J]. 麦类作物学报,2015,35(1):129-137.
[13]Cao X R,Luo Y,Zhou Y L,et al. Detection of powdery mildew in two winter wheat cultivars using canopy hyperspectral reflectance[J]. Crop Protection,2013,45(3):124-131.
[14]杨 燕. 基于高光谱成像技术的水稻稻瘟病诊断关键技术研究[D]. 杭州:浙江大学,2012:8-17.
[15]张正炜,陈 秀,沈慧梅,等. 我国稻曲病分级标准的研究与应用現状[J]. 中国稻米,2020,26(4):18-21.
[16]Wu L,Hoi S C,Yu N. Semantics-preserving bag-of-words models and applications[J]. IEEE Transactions on Image Processing,2010,19(7):1908-1920.
[17]朱道广.基于视觉词袋模型的图像分类研究[D]. 郑州:解放军信息工程大学,2013:2-10.
[18]倪茜茜. 基于高光谱成像技术的红酸枝品种识别[D]. 杭州:浙江农林大学,2015:11-13.
[19]陈 佩. 主成分分析法研究及其在特征提取中的应用[D]. 西安:陕西师范大学,2014:7-15.
[20]杜培军,陈云浩,方 涛,等. 高光谱遥感数据光谱特征的提取与应用[J]. 中国矿业大学学报,2003,32(5):500-504.
[21]Jain A K,Dubes R C. Algorithms for clustering data[J]. Technometrics,1988,32(2):227-229.
[22]胡屹群,周绍光,岳 顺,等. 利用视觉词袋模型和颜色直方图进行遥感影像检索[J]. 测绘通报,2017,63(1):53-57.
[23]张梦姣. 基于显著性检测和词袋模型的农作物害虫图像分类研究[D]. 雅安:四川农业大学,2019:21-33.
[24]Smola A J,Scholkopf B. A tutorial on support vector regression[J]. Statistics and Computing,2004,14(3):199-222.
[25]秦 溱. 基于SVM核函数和参数选择的高光谱图像分类研究[D]. 武汉:华中科技大学,2015:21-23.
[26]刘 东,邱博宇,方 芳,等. 基于空间共生词袋模型与卷积神经网络的医学影像分类方法[J]. 湘南学院学报,2020,41(2):26-31.
[27]王 娇,罗四维,邹 琪. 图像分类中基于分类矢量量化的视觉词袋模型[J]. 计算机工程与应用,2019,55(10):141-145.
[28]王 刚. 基于SVM的高光谱遥感图像海面溢油分类方法研究[D]. 长沙:国防科学技术大学,2016:16-25.
