基于随机森林的2019年澳大利亚东海岸森林火灾的PM2.5多源高分辨率反演方法
2021-12-08马宗禾骆哲文刘子炎杨睿诚
马宗禾,骆哲文,孙 铎,刘子炎,杨睿诚
(武汉理工大学,湖北 武汉 430070)
1 研究背景及意义
野火通常发生在农村地区或山区,监测站点数量有限且分布不均,因而难以实现整个火灾区域PM2.5的扩散方式和传输特性等研究。基于仿真的大气空气质量模式预报在空间上具有连续覆盖性,但分辨率较低,结果误差较大。另外,野火PM2.5有高浓度高度变化的特点,现有的统计模型对于PM2.5-AOD的关系在时间和空间上无法完全解释变化。
为解决现有野火PM2.5测算野火热辐射高、易受风影响的难点,引入哨兵二号影像、风向等新变量;另一方面,采用机器学习算法,使用高分辨率AOD数据,对野火PM2.5进行遥感反演,以期来填补高浓度PM2.5的估算领域的空白并尝试提高最终PM2.5反演结果的精度。
2019年9月以来澳大利亚东海岸森林火灾引起国际社会广泛关注,其产生的大量野火烟雾已环绕地球半周。因此,亟需高分辨率野火PM2.5浓度数据为环境科学、生态经济发展提供数据支撑,同时对公共卫生和流行病学的研究也有重要意义。
2 研究方案
2.1 技术路线(图1)

图1
2.2 实施方案
2.2.1 数据处理
由于各类数据的来源、数据类型、空间分辨率不尽相同,要对各类数据进行预处理。模型的时间分辨率是24h,所搜集的数据大多为每日均值,对于非标准格式的数据按照数学与统计方法进行处理与验证。
(1)填补AOD缺失:检查AOD缺失,将Aqua和Terra AOD进行融合,再以AO据为基准建立一公里格网。
(2)对哨兵2号数据,计算改进归一化燃烧指数(NBRT),分离燃烧区和非燃烧区。
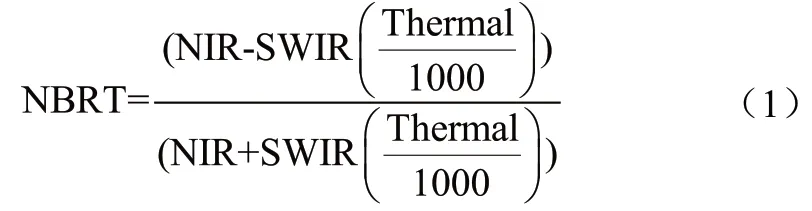
式中,NIR波段范围0.76-0.9µm;SWIR波段范围2.08-2.35µm;Thermal波段10.4~12.5µm。
接着采用双线性内插方法对其做降尺度处理,再用1*1km格网对其重采样。
(3)对于MODIS NDVI数据,因其分辨率比较低,用Aggregation函数对其进行数据整合,保证计算过程是一公里格网的均值。
(4)对每个MODIS火点数据创建多级缓冲区,计算每个网格单元MODIS的火点数,以15km缓冲区进行火点统计。
(5)使用最邻近分类算法为每个气象监测站点分配气象字段,从而获取区域内气象要素的连续表面,然后使用反距离加权方法插值到1*1km网格中。
(6)对于土地利用数据,以每个PM2.5监测站点为中心,建立1*1km的缓冲区,平均森林覆盖率、高程值、道路长度到缓冲区,并计算每个缓冲区的人口密度。
(7)对于PM2.5数据,将某一网格单元内所有PM2.5站点同一天的数据进行平均后赋值给该网格单元。
(8)对各因子与PM2.5浓度做多变量相关分析,并计算相关系数,移除会造成显著共线性的变量,选取最优预测变量。
2.2.2 模型构建
剔除了数据的缺失值及异常值后,将数据集按照7:3的比例随机划分为训练集和测试集。训练集用于建立模型,测试集用于精度评价。
我们使用随机森林对训练集进行构建模型。随机森林具有以下优点:运算量小,但预测精度高;可以高效的处理非线性过程;预测结果对非平衡数据和缺失数据较稳健。我们将预处理后的相关因子作为模型的特征,监测站点的PM2.5浓度作为监督值,使用Python的Scikit-Learn模块的算法训练。同时帮助我们判断本研究加入的哨兵2号数据、风向数据等是否真的提高了模型精度。
2.2.3 模型验证
用先前划分的测试集对建立的模型进行验证,在此阶段中,我们采用了模型预测值与地面观测值之间的决定系0数(R2)、平均预测误差(MPE)、均方根预测误差(RMSE)、相对预测误差(RPE)等统计指标来对模型拟合与交叉验证结果进行比较,从而对模型表现和过度拟合现象进行评估。
2.2.4 模型应用
(1)澳大利亚野火烟雾PM2.5时空特征分析。因为地面监测站点的稀疏性,所以仅靠地面监测站的数据无法得知澳洲森林火灾中烟雾PM2.5的整体变化。而我们建立的模型可以反演澳洲野火日均尺度PM2.5的浓度,研究澳洲野火PM2.5浓度的空间分布特征,并对其形成原因进行探讨;同时会研究时间变化特征,并基于日时间序列和月均时间序列,分析澳洲野火期间PM2.5污染的时间变化趋势。
(2)人口野火烟雾PM2.5暴露风险评估。基于建立的模型对火灾期间的居民健康风险进行评估。我们将研究期分为以下三个子阶段:“火灾前”时期,即研究区域的PM2.5水平正常;“火灾中”时期,即研究区域内大多数AQ站中PM2.5的浓度急剧增加时;“火灾后”时期,即PM2.5浓度恢复到正常水平。在不同的时期内,我们将分别用空气质量浓度、人口暴露强度、人口加权浓度3种指标来对人口PM2.5暴露风险进行评估。
(3)野火颗粒物与相关疾病致死率关系研究。我们将澳大利亚全境范围的AOD与PM2.5浓度时空分布情况与WHO提供的相关疾病的致死率健康数据结合,通过反距离权重(IDW)插值与提取等方法得到澳大利亚森林火灾野火颗粒物与相关疾病致死率关系,从而对二者的关系进行分析与研究,为环境科学、生态经济发展提供数据支撑,对公共卫生和流行病学的研究与决策提供有价值的建议。
3 创新点与特色
3.1 区别于常规研究的多源数据
由于野火PM2.5相对于城市PM2.5更难估算,传统的建模变量不够,本文采用多源数据进行PM2.5浓度空间估算,除常用的AOD数据、气象数据(相对湿度、风速和行星边界层)、土地利用数据外,引入火点数据、哨兵二号数据和风向数据等辅助数据。既利用了AOD数据对于PM2.5良好相关关系,同时又考虑了野火烟雾所产生的高浓度高度变化的PM2.5难以被有效估算的问题。已有研究表明,风向对于PM2.5的分布有重要影响,但由于风向数据分析的复杂性,多数PM2.5浓度估算的研究没有将其考虑在内,因此,为了提高结果数据的准确性,加入风向数据,结合其他多源数据对PM2.5浓度估算的结果进行对比验证。
3.2 高时空分辨率
采用1km分辨率的AOD数据作为基础,将其他因素数据进行重采样配准到该数据上,保证高空间分辨率。MAIAC算法使用时间序列分析并同时处理固定的25*25 km2块中的像素组,以得出表面双向反射率分布函数和气溶胶参数,显示出增强的对比局部尺度气溶胶变化的能力,并提高了云雪探测和气溶胶检索的质量。
3.3 优化随机森林算法,开发能反映PM2.5-AOD关系时间和空间变异的模型
我们对随机森林算法进行优化,解决PM2.5-AOD关系的时空异质性问题,以提高模型的估算精度。对PM2.5人口暴露风险,我们利用随机森林优化模型估算的高精度PM2.5浓度空间分布数据进行评估,且利用多指标评价方法从多个角度对澳大利亚的PM2.5人口暴露风险进行评估。该评估方式的可信度高。
3.4 热点研究与现实应用
2020年7月28日,世界自然基金会(WWF)发布一份报告,显示2019年到2020年发生的澳大利亚丛林大火,造成了近30亿只动物死亡或流离失所。面对自19世纪中叶以来最严重的火灾,数据监测方法与管理体系在不断蔓延的火势面前也显得不尽人意。因此,针对本次火灾的研究不仅具有深刻的现实意义,更是对于澳大利亚与整个国际社会的火灾监管体系有着深远影响。我们的研究模型旨在为解决监测与反演方法中现存部分缺陷并设法为相关监管提出辅助决策与分析建议,而研究成果的应用则深化现实意义,在澳大利亚野火烟雾PM2.5时空特征分析、人口野火烟雾PM2.5暴露风险评估、野火颗粒物与相关疾病致死率关系研究等方面孵化研究成果。
