耦合变分自编码器及其在图像对生成中的应用
2021-12-08侯璎真翟俊海申瑞彩
侯璎真,翟俊海,2,申瑞彩
1(河北大学 数学与信息科学学院,河北 保定 071002) 2(河北大学 河北省机器学习与计算智能重点实验室,河北 保定 071002) E-mail:mczjh@126.com
1 引 言
图像生成是深度学习研究的一个重要领域,主流的生成技术是生成对抗网络[1]和变分自编码器[2].Goodfellow等提出的生成对抗网络(GAN,Generative Adversarial Network)是一种隐式概率生成模型,GAN由生成器网络和判别器网络构成,通过这两个网络的对抗学习,实现用生成器网络逼近图像的分布,通过抽样可生成似真的图像.Radford等人[3]用卷积神经网络实现生成器和判别器,提出了DCGAN(Deep Convolutional GAN),DCGAN用深度卷积神经网络以无监督的方式学习图像的特征,进而生成高质量的图像.Yi[4]等人提出的DualGAN在原始的GAN模型基础上开发了一种新型的双重GAN机制,使图像翻译器可以从两个领域的两组未标记图像中进行训练.在DualGAN中,原始GAN学习将域U中的图像翻译成域V中的图像,而双GAN学习将任务反转.原始任务和双任务所做的闭环允许来自任一域的图像被翻译,然后重建.康云云等人[5]提出一种基于改进生成对抗网络的法律文本生成模型ED-GAN,该模型将案情要素的关键词序列编码成隐含层向量,并结合各时间步的输出生成文本序列,最后采用CNN网络来鉴别真假文本的差距,该模型的出现为法律文本的自动生成提供了新思路.Karras等人[6]提出了一种称为StyleGAN的生成对抗网络,他们将风格迁移至生成器网络中,StyleGAN生成的人脸图像能够自动地进行姿势和风格转换.在StyleGAN的基础上,Abdal等人[7]提出一种称为Image2StyleGAN的生成对抗网络,Image2StyleGAN能够将一幅给定的图像嵌入到StyleGAN的潜在空间中.Larsen等人[8]将VAE(Variational Auto-Encoder)和GAN合并为一个无监督生成模型,同时学习编码、生成和测量样本相似性.通过学习编码器网络能够生成视觉逼真的图像.石志国等人[9]通过对栈式自编码器深度学习算法进行研究,提出了一种深度学习降维信息损失度量方法,为深度学习算法的改进提供了数据支撑.Bao等人[10]提出了一种将变分自编码器与生成对抗网络相结合的通用框架CVAE-GAN,用于合成细粒度类别的图像.在CVAE-GAN中,将图像建模为一个概率模型中标签和潜伏属性的组成,通过改变输入到生成模型中的细粒度类别标签,可以在特定类别中生成具有随机抽取的潜伏属性向量值的图像,能够生成真实的、具有细粒度类别标签的多样化样本.一般而言,从已有的边缘分布中得出的联合分布有多种,Liu等人[11]提出了一种“共享潜在空间”的假定,假设不同域中的对偶图像可以映射到共享潜在空间中的相同潜伏对象.基于这个假设,作者提出了基于GAN和VAE的无监督图像转换的框架UNIT.Tan[12]针对单幅图像去雾算法无法有效处理天空区域的问题提出了一种天空识别的改进暗通道先验去雾算法,该算法不仅能对图像中的景物和天空进行准确的去雾处理,而且还显著的减少了运行时间.从这些工作可以看出,在图像生成领域,单一图像的生成问题研究的较多,取得了较好的发展,但是图像元组的问题却少有人研究.本文重点研究生成具有不同属性的图像元组问题,提出了耦合变分自动编码器(CoVAE,Coupled Variational AutoEncoder).
现有的数据集以及图像生成方法生成的图像大多都是单一的图像,无法生成两个具有不同属性的图像(比如微笑的人脸和不微笑的人脸)元组,为了生成图像元组,提出的CoVAE,通过训练耦合变分自编码器学习不同属性图像的特征表示,最后通过训练好的神经网络学习的特征表示生成具有不同属性的人脸元组.本文的贡献有如下3点:
1)提出了耦合变分自编码器,做出了模型上的创新.
2)通过学习不同属性的特征表示更精确的生成图像元组.
3)用模型实现了无监督的人脸属性转换以及图像相互转换.
CoVAE包含两个VAE元组,为了降低训练的复杂度,我们共享两个VAE的参数.在实现生成不同属性人脸元组时,我们用不同属性的数据集分别训练两个VAE元组,训练好的VAE元组可以学习到不同属性的特征表示,通过这个特征表示可以更精确严格的生成不同属性的人脸元组.变分自编码器可以用属性标签实现人脸属性转换,我们用完整数据集训练好的耦合变分自编码器分别训练两个不同属性的人脸数据集,不用属性标签而是用两个VAE分别取平均值相减求得属性表示,从而实现无监督的人脸属性转换.同时发现也可以用训练好的耦合变分自编码器实现人脸图像的相互转换.
2 基础知识
本文的工作基础是耦合生成对抗网络(CoGAN,Coupled Generative Adversarial Networks)[13],下面简要介绍CoGAN的基本思想.
CoGAN是Liu等人提出的一种学习多域图像联合分布的生成模型,CoGAN旨在学习两个不同域的联合分布.它由两个GAN模型组成(如图1所示),每个GAN负责在一个域中生成图像,通过生成器与判别器的部分权值共享在两个域中学习联合分布,从而生成图像元组.
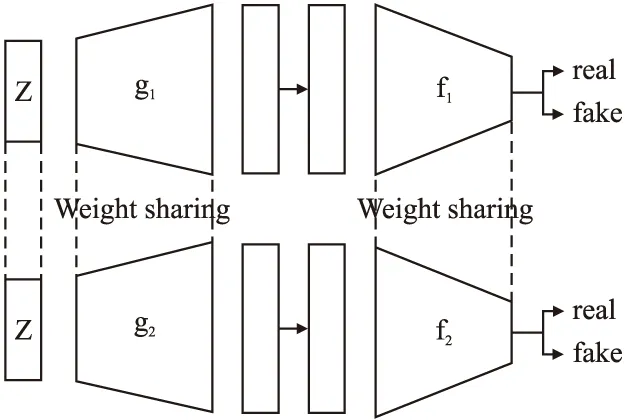
图1 耦合生成对抗网络结构示意图Fig.1 Structural sketch of coupled generative adversarial networks

(1)
(2)

假设f1和f2是GAN1和GAN2的判别器,分别用下面的公式(3)和公式(4)判别两个域的真假样本.
(3)
(4)

判别器将输入图像映射到概率分布,以估计输入是真实样本的可能性.因为生成器的前k层解码高级语义,后面的层解码低级细节,判别器前k层提取低级特征,而后面的层提取高级特征,所以将生成器的前几层权重共享,将判别器的最后几层权重共享.这种权重共享约束使CoGAN无需监督即可学习图像的联合分布.训练好的CoGAN可用于合成成对的对应图像,这些对应图像共享相同的高级抽象特征,但具有不同的低级细节.
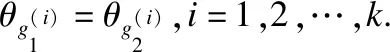
损失函数由的公式(5)定义.
(5)
其中,函数V由公式(6)定义.
V(f1,f2,g1,g2)=EX1~PX1[-logf1(X1)]+
Ez~Pz[-log(1-f1(g1(z)))]+EX2~PX2[-logf2(X2)]+
Ez~Pz[-log(1-f2(g2(z)))]
(6)
3 耦合变分自编码器
受CoGAN的启发,本文提出了耦合变分自编码器模型(CoVAE),旨在学习不同属性图像的高级特征表示,用于生成不同属性的图像元组.由于VAE可以学习图像的高级特征表示,具有坚实的数学基础,我们可以通过耦合变分自编码器学习不同属性图像的特征表示,从而更准确的生成不同属性的图像元组.CoVAE的结构如图2所示.

图2 耦合变分自编码器结构示意图Fig.2 Structural sketch of CoVAE
CoVAE模型包括两个VAE(VAE1和VAE2),VAE1和VAE2中的编码器网络分别记为q1和q2,VAE1和VAE2的解码器网络分别记为p1和p2.
编码器负责通过两个卷积神经网络拟合出专属于每个输入图像Xk的均值和方差,
μk=f1(Xk)
(7)
logσk2=f2(Xk)
(8)
再经过重采样算出Zk,
Zk=μk+σk*ε
(9)
其中,ε~N(0,1).
设X1,X2分别是两个不同属性数据集中的图像,X1~PX1,X2~PX2,编码器求出两个数据集分别对应的潜变量Z1、Z2.
(10)
(11)


(12)
(13)

CoVAE的损失函数如下:
LCoVAE=LVAE1+LVAE2
(14)
LVAE1=Lreg1+Lrecon1=DKL(q(Z1|X1)‖p1(Z1))-
Eq(Z1|X1)[logp1(X1|Z1)]
(15)
LVAE2=Lreg2+Lrecon2=DKL(q(Z2|X2)‖p2(Z2))-
Eq(Z2|X2)[logp2(X2|Z2)]
(16)
(17)

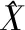
VAE的损失函数等于两部分之和,将LVAE分成两部分来看:Eq(Z|X)[logp(X|Z)]的期望和DKL(q(Z|X)‖p(Z))的期望,问题变成了两个损失值分别最小化.但是这样计算并不能达到理想的效果,DKL(q(Z|X)‖p(Z))=0表明Z没有任何辨识度,所以-Eq(Z|X)[logp(X|Z)]不可能小(效果不好);而如果-Eq(Z|X)[logp(X|Z)]小则logp(X|Z)大(效果好),此时DKL(q(Z|X)‖p(Z))不会小,所以这两部分的损失值是相互对抗的.应该从整体的看LVAE,整体的LVAE越小模型就越接近收敛,而不能单纯观察某一部分的损失值,而且VAE1和VAE2共享权重,不能分开计算损失函数,所以将CoVAE的损失函数设计为一个整体损失函数,即LCoVAE.
4 实验结果及分析
4.1 数据集
为了验证提出的模型的有效性,使用Celeba数据集集中进行了测试,该数据集包含了202599张人脸图片,每张人脸图片有40个属性标签,例如可区分是否微笑、戴眼镜、发色、性别、长短发等属性特征标签.某张图片具有该属性则属性标签为1,否则为-1,我们按照想要实现的实验效果对数据集按照属性标签做任意划分以训练CoVAE模型.数据集中的图片输入尺寸标准化成固定尺寸为128×128×3,潜变量空间设置成200维.本文的实验分成两部分,都是通过CoVAE模型实现,主要的实验是通过CoVAE模型生成不同属性的人脸元组,另一个实验是通过CoVAE模型实现无监督的人脸特征转换以及人脸相互转换.最后通过在MNIST数据集上的实验并与其他模型比较以证明其优势.
4.2 实现细节及结果分析
在第1个实验中,我们希望CoVAE模型生成不同属性的人脸元组,强调在训练集中的不同域中没有对应的图像,我们以不同属性的人脸数据集分别训练两个VAE.训练良好的CoVAE可以学习不同属性数据集的高级特征表示,最后输入任意一张人脸图片,CoVAE模型都可以生成不同属性的人脸元组.我们按照不同的属性将Celeba数据集分为两部分,第1部分记为数据集1,将人脸图片标准化成固定尺寸为128×128×3输入VAE1,第2部分记为数据集2,将人脸图片标准化成固定尺寸为128×128×3输入VAE2.两个数据集:一个是具有该属性的图片数据集,一个是不具有该属性的图片数据集,它们之间不存在任何对应关系或配对.我们输出了200维潜变量空间的前12维的正态分布图像如图3所示.生成的不同属性人脸元组如图4所示.

图3 潜变量空间的前12维的正态分布图像Fig.3 First 12-dimensional normal distribution image of latent variable space

图4 微笑、眼镜、发色的人脸元组图像Fig.4 Smile,glasses,hair color face tuple image
从图3中可以看到200维潜变量的前12维的正态分布,每一维都是一个正态分布,这些所有的分布加起来是当前图片的高级特征,所以人脸图片的高级特征可以理解为是一个多元正态分布.
从图4中可以看到训练良好的CoVAE可以成功的捕获每个人脸的高级特征-比如是否微笑,是否带眼镜,发色.图4中,第1组图片中,VAE1可以捕获人脸笑的高级特征,VAE2可以捕获人脸不笑的高级特征,所以输入1张人脸图片,训练良好的CoVAE就可以生成不同属性的人脸元组,即第1组图像中第1行微笑的人脸图像,和第2行不笑的人脸图像,上下图像为同一个人对应微笑和不微笑的人脸元组.同样,第2组图像中,第1行是CoVAE生成的戴眼镜的人脸图像,第2行是第1行中的每个人脸分别对应的不带眼镜的图像.第3组图像中,CoVAE生成了第1行浅发色的人脸图像,第2行图像为第1行每个人脸分别对应的深发色图像.类似于此,训练良好的CoVAE可以生成任意属性的人脸元组.
此外,我们发现CoVAE模型可以实现无监督的人脸特征转换以及人脸相互转换效果.单个VAE可以通过属性标签学习实现人脸特征转换,在本文实验中,我们发现可以应用CoVAE模型中两个VAE的特点不需要属性标签也可以实现人脸特征转换,即用CoVAE模型实现无监督人脸特征转换.使用完整的Celeba数据集训练CoVAE模型,训练良好的CoVAE模型可以生成任意属性特征的人脸图片,然后将数据集按照不同属性划分为两个数据集,分别将两个数据集输入两个VAE,每个VAE提取出来对应数据集的高级特征表示Z,再以两个Z相减求出对应属性的特征向量,从而对任意输入人脸图片就可以实现该属性的加减变换.用VAE1实现该属性的相加,用VAE2实现该属性的相减.用CoVAE模型实现人脸属性相加及人脸属性相减结果如图5所示.随后又用训练良好的CoVAE模型实现了人脸的相互转换,实验结果如图6所示.

图5 微笑、发色、性别的人脸属性加减图像Fig.5 Smile,hair color,gender face attributes plus or minus images
从图5的第1组图片中可以看出,CoVAE中VAE1实现了微笑属性特征的相加,VAE2实现了微笑属性特征的相减,并且是对同一张人脸图像进行特征加减,是同一张人脸图像的不同属性元组.中间一组和下边一组的图片分别实现了发色和性别的属性加减.第1组图像中,第1行图片人脸图像从不笑到笑,第2行人脸图像从笑到不笑;第2组图像中,第1行人脸图像发色从黑色到棕色,第2行人脸图像发色从棕色到黑色图片;第3组图像中,第1行人脸图像从性别女到男,第2行人脸图像从性别男到女.可以清楚的看到,即使在潜空间中将一个特征移动很远的距离,除了我们想操控的这个特征,图像的核心几乎没有改变.这证明了CoVAE在捕获和调节图像中高级特征的强大能力.
从图6中的3组图片可以看到CoVAE中VAE1实现了左边图片到右边图片的转化,VAE2实现了反向的转化,并且转化的时候包含了多种特征属性(比如微笑,发色,性别等).这个实验显示了CoVAE的潜空间中应该是一个连续的空间分布,才能转化和尝试去生成一个多种属性的不同人脸.

图6 人脸图像的相互转换Fig.6 Face image conversion
本文使用卷积网络来实现CoVAE,两个编码器、解码器具有相同的结构,为了减少训练参数加快训练速度我们共享两个VAE的编码器解码器权重,每一个卷积层之后都有一个归一化层去加快训练.训练人脸的CoVAE层数如表1所示.使用ADAM算法进行训练,学习率设置为0.0005,最小批量设置为32.并对CoVAE进行了200次迭代训练.

表1 生成人脸的CoVAETable 1 CoVAE for face generation
本文最后将模型应用于MNIST数据集并与相关模型作比较,根据指标显示,CoVAE模型生成图像优于其他模型.我们选用的评价指标包括SSIM、PSNR、MSE、NRMSE.SSIM是一种衡量两幅图像相似度的指标,用均值作为亮度估计,标准差作为对比度估计,协方差作为结构相似程度的度量.PSNR是峰值信号的能量与噪声的平均能量之比.MSE是真实值与预测值的差值的平方然后求和平均.NRMSE就是将MSE的值开方后变成(0,1)之间.我们将正域和负域的MNIST数据集分别训练两个VAE,数字图像在潜变量空间分布如图7所示,生成图像如图8所示.我们将CoVAE模型与其他比较流行的模型作比较,CoVAE模型优于其他的模型生成效果,结果数值如表2所示.

图7 正域及负域数据在潜变量空间的分布图Fig.7 Distribution diagram of positive and negative domain data in latent variable space
图7中的三角形的点代表正域数字图像在潜变量空间中的分布,圆形的点代表负域数字图像在潜变量空间中的分布,这些点中每个点都代表了原图像在潜变量空间中的坐标,就是提取出来的高级特征,我们通过这个特征可以重构图像.图8中每组图片第1行的图像都是CoVAE中VAE1生成的正域数字图像,第2行的图像是VAE2生成的负域数字图像.

图8 CoVAE生成正负域的数字图像Fig.8 CoVAE generated digital images of positive and negative fields
在表2中,结构相似性SSIM数值越接近于1,相似度越高,代表融合质量越好;峰值信噪比PSNR用于衡量图像有效信息与噪声之间的比率,能够反映图像是否失真,PSNR值越大融合图像质量越好;均方误差MSE反映的是变量间的差异程度,用于衡量融合图像与理想图像之间的差异,MSE越小,表示融合图像质量越好;归一化均方根误差NRMSE是将一个翻译空间细节信息的评价指标的值变成(0,1)之间,越小越好.我们可以从上表数值得知,在生成数字图像上CoVAE的性能优于其他模型,分析原因其一是因为变分自编码器在提取图像高级特征上表现的强大能力,利用两个卷积神经网络拟合出来对应的均值方差,经过重采样求出对应的潜变量,正如同数学函数一样准确严谨,精致迂回的数学推导使其相对于生成对抗网络粗狂的对抗训练更准确;其二CoVAE将潜变量维度扩展为100维,更多维的潜变量意味着更加准确的多维正态分布,每一维正态分布都对应了图像的一维特征,多维的正态分布更能细致精准的刻画每一张图像的高级特征,所以生成的数字图像更清楚准确.

表2 MNIST数据集上不同模型的相关指标结果Table 2 Correlation index results of different models on MNIST data set
5 结 论
受CoGAN思想的启发,提出了用于生成不同属性人脸元组的CoVAE模型.该模型学习不同属性数据集高级特征的表示,从而更精确的生成不同属性的人脸元组,严格控制元组中人脸主体的一致性,相较于CoGAN生成的人脸图像元组结果更精准.此外,本文也实现了CoVAE在无监督人脸属性转换及人脸相互转换的应用.但是VAE在生成人脸图像上并不是很清楚,这也是本文需要进一步研究提高的地方.
