基于机器视觉的建筑垃圾填料物质组分图像分析方法
2021-12-07谢康陈晓斌尧俊凯苏谦陈龙吴梦黎
谢康 陈晓斌† 尧俊凯 苏谦 陈龙 吴梦黎
(1.中南大学 土木工程学院,湖南 长沙 410083;2.中国铁道科学研究院集团有限公司,北京 100081;3.西南交通大学 土木工程学院,四川 成都 610000)
随着我国城市化水平不断加快,建筑业得到了迅猛发展,但由此带来的建筑垃圾也与日俱增[1-3]。资源短缺、环境污染已成为我国可持续发展的制约瓶颈。将建筑垃圾资源化利用,不仅有利于节材减弃,进而产生客观的社会、经济效益,而且对环境保护和资源的优化利用起到重要的推进作用。其中建筑垃圾资源化利用的一个重要方面就是作为路基填料[4-5],我国公路、铁路建设正处于高峰期,将混凝土块、废砂石、水泥制品及基坑废土等建筑垃圾再生填埋都能应用于路基填筑工程,不仅可以大大减小对砂石等天然填料的开采,而且建筑垃圾将会得到充分的资源化利用[6]。
建筑垃圾是天然石材、粘土砖、沥青颗粒以及其他材料(例如玻璃、木材和塑料)的混合物[7]。由于产生位置的不同,建筑拆除废物的组成具有多样性[8]。此外,使用的破碎技术也会影响细粉含量和附着砂浆的比例[9]。由于在建筑混凝土制造中,使用严格质量的原材料至关重要,因此,再生填料的这种成分多样性是限制再生填料增值的主要原因。同时现有的建筑垃圾中较多的成分都是属于可以用于再循环或者重新利用的材料。但是这些材料,具有诸多不利的工程特征,转化为再生填料以后,与天然的填料相比还是有很大的差别[10]。为了保证路基填筑过程中安全性与稳定性,在选择建筑垃圾作为路基填料时,需要将建筑垃圾中的性能较好混凝土块、砖瓦块和碎石等再生填料筛选出来,以保证废渣路基填料具有较好的物理力学性能。
相关国内外学者已将建筑垃圾再生填料作为路基填料进行了大量的应用研究。徐宝龙[11]认为建筑垃圾土虽具有上述不良性状,但同时也具备了作为道路建筑材料的基本特性。Mahon等[12]研究了建筑垃圾作为填充物的特质,建议不同的分类垃圾、不同的材料应采用不同的技术对其进行技术提炼。万惠文等[13]围绕建筑垃圾再循环的利用途径,重点对再生骨料与再生砖瓦进行了详细的评估,认为其均满足路基填充的要求;Sobhan[14]研究了再生骨料能够提高路基因反复荷载而需的疲劳性能,验证了再生骨料是能够用于高级公路路基中的;Jonathan等[15]开展了垃圾杂填土的抗剪性能试验,为将垃圾杂填土用作路基回填料提供了参考依据;冯硕[16]剖析了和建筑渣土有关的基本性能以及建筑渣土某些力学性能,研究得出建筑渣土可用于道路路基工程中,并基于实际工程阐述了建筑渣土用于道路路基的施工工艺。姚志雄[17]提出了建筑渣土符合路基填料规定的标准。因此,将建筑垃圾作为路基填料具有广泛的应用前景。
建筑垃圾的处理主要分为分选和加工破碎[18],其中分选是建筑垃圾处理的关键步骤。与常规路基填料砂砾和灰土相比,建筑垃圾填料的特殊之处,就在于其组成成分的复杂性以及颗粒分布的不均匀性。首先通过分选将建筑垃圾中的无用料剔除,分离出可用的混凝土块、砖瓦块和碎石,其次才将分选出来的物料进行加工破碎,获得不同粒径组分的再生填料。本研究中主要是分离并保留再生材料中的混凝土块、砖瓦块和碎石作为路基填料。
深度学习是一种使用深度神经网络(DNN)对数据集进行分析和建模的机器学习方法。用于图像分类的深度神经网络称为卷积神经网络(CNN)。鉴于目前建筑垃圾筛选多采用人工筛选法进行获取,该方法耗时耗力,往往会限制建筑垃圾的二次利用应用前景。本文中提出了一种基于深度学习的实时自动确定建筑废物成分的方法。首先,创建了一个包含再生骨料图像的带标签的数据集,并在该数据集上进行卷积神经网络的训练。此外,自定义了一种常见CNN以改善其性能。经过训练后,CNN可以在再生填料图片上识别出每个颗粒,并分析整个样本的成分。最后,提出了一种根据其图像估算每个颗粒质量的方法。
1 试验材料及成分分析
本研究用到具有代表性的建筑垃圾,保证建筑垃圾中存在较多的性质较为稳定的惰性物料,主要包括:基坑土、混凝土块以及碎石,其中混凝土块、碎石等在经过筛选后均可作为路基填料[10]。文中建筑垃圾取自中南大学校园内岩土实验室的拆除垃圾,如图1所示。

图1 建筑垃圾Fig.1 Construction waste
现场建筑垃圾中含有大量的废弃混凝土块、砖块等固体成分,同时还可能含有其他的有害成分。本文中主要分4步对建筑垃圾进行处理:(1)采用铁锤将粒径最大的砖块、混凝土块进行预破碎;(2)将进行预破碎的建筑垃圾倒入破碎机中进行碾碎,得到粒径小于31.5 mm的填料;(3)将破碎的惰性材料吹干;(4)将以上阶段处理后的材料,经过拍照系统和深度学习系统筛分分选,才能得到最终有价值的路基填料。
2 卷积神经网络算法
卷积神经网络(CNN)[19]是用于图像分析的深度神经网络。为了正确地将图像进行分类,需要首先从带标签的数据集中学习。其中,带标签的数据集包含许多已经分类并赋予标签的图像。
学习过程包括训练和验证两个阶段。在训练阶段中,CNN接收图像并更新其滤波器的参数。此阶段,滤波器学着提取相关的视觉特征,以区分不同标签的图像。在验证阶段中,CNN接收与训练阶段图像不同的图像,来评估CNN的泛化能力。此外,在验证阶段中,滤波器的权重不会更新。
本文选择残差网络ResNet[20]作为基础CNN架构。当在标准数据集上进行测试时,34层残差网络ResNet34(RN34)的错误率低于旧的CNN(VGG等)。此外,RN34所需的算力仅为VGG的5%。
50层残差网络ResNet50(RN50)是RN34的一种变体。RN50中的每个构造块都具有3个卷积,且比RN34中的相应卷积输出的特征图更多。为了增加输出的特征图的数量,并限制所需的算力和内存的增加,RN50中的每个构造块都具有瓶颈配置。当在ImageNet上进行测试时,RN50的错误率比RN34更低,而所需的算力仅略有增加。
图2(a)展示了基于使用完全预激活的经典ResNet34网络的C-RN34体系结构。其主要区别在于C-RN34使用了深度可分离卷积(DSC[21])。与标准卷积相比,DSC所需的参数更少,因此计算量更小,但准确性仅略微下降。因此,不同于RN50的可能导致特征丢失的瓶颈策略,C-RN34增加了RN34的特征图的数量。
在输入层后,第1层为跨度为2的7×7卷积,然后是1层3×3卷积。这两个卷积均有128个滤波器。在C-RN34中,相同阶段的特征图数量分别为256、512、768和1 024。与RN50相比,阶段4和阶段5的特征图较少。因此,C-RN34中的参数总数(约2 080万)近似于RN50的参数总数(约2 360万)。但是,C-RN34中的每一阶段仍比RN34中的相应阶段的特征图更多。此外,在C-RN34网络的末端,全局平均池层和分类层之间添加了2 048个神经元的全连接层。
C-RN34的构造块(下采样块(图2(b))和恒等块(图2(c)))也有所不同。在经典ResNet中,在阶段3、4和5开始时,使用跨度为2的1×1卷积对特征图进行下采样。但是,当使用跨度卷积进行下采样时,会导致原始信息丢失。在C-RN34中,在下采样块中使用跨度为2的3×3 DSC。下采样块可以输出空间尺寸为初始一半的特征图。最后,在每个块的末尾添加了一个压缩-激励块[22],CNN只选择相关的特征图。

图2 模型架构(图中H,W,D表示输入图像的高度、宽度和深度)Fig.2 Model architecture(H,W,D in the figure represent the height,width,and depth of the input image)
3 再生填料组分图像分析方法
3.1 创建标签数据集
3.1.1 样本准备和人工筛选
本文中研究对象为粒径0~31.5 mm的再生填料。再生填料通常被细小物质所覆盖,掩盖其颜色和质地。因此,为了对再生填料进行识别,首先需要用水冲洗掉覆盖的物质。其次,将其在105 ℃的干燥箱中干燥。然后,将其筛选为4~10 mm和10~31.5 mm的两个部分,由于0~4 mm的颗粒太小而无法人工筛选,故不计入再生填料的成分。
然后,对再生填料进行人工筛选。NF EN 933-11标准定义了人工筛选的流程以及再生填料的成分类别。但其中一些成分较为混杂,不适合使用卷积神经网络进行图像分类,仍需将一些再生填料的成分进行细分。例如,天然石材类可分为6个子类:“石灰石”,“玄武岩”,“石英石”,“硅质石”,“冲积石”和“板岩”。表1列出了再生填料的类别和对应的细分子类,图3为每个子类中存在的颗粒示例。

表1 NF EN 933-11标准定义的再生骨料分类及其子类Table 1 NF EN 933-11 classification of reclaimed aggregate and its subclasses as defined in the standard

图3 子类颗粒示例Fig.3 Subclass particle example
NF EN 933-11标准规定任何含有砂浆的成分均属于混凝土成分。这主要是由于天然石材和附着的砂浆的比例不同,导致混凝土类中的元素混杂。同时,诸多混凝土也主要由天然骨料组成,其表面覆盖有少量砂浆,故与天然石材非常相似。
3.1.2 试验装置
为了确定所需的成分,利用图4所示的设备拍摄了300多张图像。
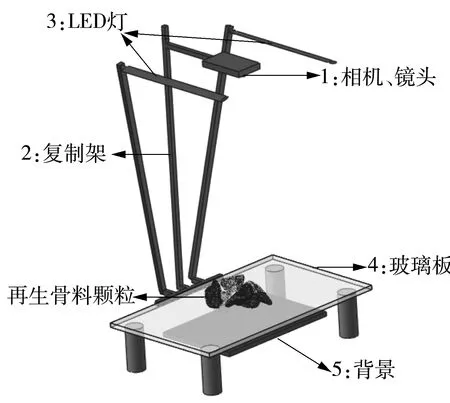
图4 试验设备Fig.4 Testing equipment
组件1:一台分辨率为2 400万像素(6 000×4 000像素)的富士X-T20相机及两个镜头:富士能XF60mm F2.4 R Macro和富士能XF35mm F2 R WR。由于设备精度原因,无法拍摄直径小于4 mm的颗粒。
组件2:将照相机稳定固定的一个可调距离的复制架。
组件3:两个由256个LED组成的灯,主要提供可控的照明条件。其具有均匀的散光性和良好的显色性。LED灯臂安装在复印机支架上,并垂直于每个LED灯的平面。将灯放置在透明塑料板上方45 cm处。此外,灯的侧面与复制架底座的侧面平行。将亮度设置为最大值时,色温为5 600 K。
组件4:高出底座10 cm的一个透明玻璃板,可以衰减再生骨料在背景产生阴影程度。此外,放置再生骨料时,必须保证相邻颗粒之间没有任何接触。阴影的减少和颗粒的特定摆放可提高识别单个颗粒的能力。
组件5:不同于再生骨料中常见颜色的背景颜色(如蓝色),以提高图像处理时单个颗粒的识别能力。
3.1.3 单颗粒的提取
为了建立数据集,共采样了约43 kg的4~31.5 mm再生填料,并根据子类别进行了手动筛选和拍摄,如图5(a)所示。然后,测量了图片上所有颗粒的总质量。其中,采样的质量是标准中定义的最小值(10 kg)的4倍以上。为了节省时间成本,此处不对颗粒进行单独称重。文中共拍摄了360多张照片,使用在实验室开发的基于数学形态学的软件分别提取了36 000多个颗粒,如图6所示。步骤如下:

图5 图像处理过程Fig.5 Image processing

图6 提取的颗粒Fig.6 Extracted particle
在CIE LUV颜色空间中通过阈值法进行二值化。由于RGB颜色空间仅考虑颜色差异,不适用于将浅色的填料从背景中正确分离;
通过交替的顺序形态滤波器进行过滤来去除噪声。图5(b)为经过二值化和滤波的图像示例;
通过标记控制的分水岭算法[23]对颗粒进行自动分割。为了识别可能相互接触的颗粒,将二值图像距离函数的扩展最大值作为标记。图5(c)展示了一个分割图像的例子。
人工识别图像上每个颗粒所属的子类。
自动识别每个颗粒,并生成易于识别的背景。在此步骤之后,获取每个颗粒的几何特征(如短轴和主轴的长度,边界框的位置和尺寸,投影面积和周长等)。通过评估细长度、扁平度、球形度、粗糙度等参数,可以计算再生填料的形状。
统计36 000个颗粒图像的子类分布,如图7所示。由于一些子类包含难以找到的元素,子类的分布并不平均。其中,“石英石”,“玻璃”和“其他”数量最少。这种分布的不均匀会影响CNN的精度。

图7 子类的颗粒数量分布Fig.7 Particle number distribution of subclasses
3.1.4 创建训练集和验证集
文中使用的自定义卷积神经网络要求图像大小固定。因此,需要调整上一节提取的单个再生填料的图像尺寸。为了保留良好的图像分辨率,并保持合理的计算时间,设置尺寸为256×256像素。小于该尺寸的颗粒保持不变,而较大的颗粒图像则缩放至该尺寸。如果生成的边界框的尺寸小于256个像素,则对填充丢失的像素进行填充。对于属于4~10 mm分类的颗粒,只有超过11.1 mm时才会缩放。而对于10~31.5 mm的颗粒,缩小之前的最大长度为21.3 mm。
此外,为了防止CNN产生偏差,在训练和验证集中,需将再生填料的每个子类设置为相同数量。因此,可以使用数据增强技术补充数量不足的子类。然而,这种扩充具有局限性。由于特征需要被识别,通过拉伸或更改颜色来修改颗粒不可行。为了使训练集中每个类别的图像数量均为2 000,验证集中均为500,本文对图像进行了随机噪声增加、随机旋转及随机伽马校正,来获得数据集。
由于数量较少,未使用子类Ru03、Ru06、Rg和X02-X05创建带标签的数据集。且上述数据增强技术并不适用。此外,玻璃碎片(Rg)是透明的,难以提取。数据集共有22 500张带标签图像:9个子类(Rc,Ru01,Ru02,Ru04,Ru05,Rb01,Rb02,Ra和X01)的数据集各包含2 500张图像。其中,训练集用于修改CNN的参数,来提高分类的准确性。验证集用于测试CNN的泛化能力,即不同于训练集颗粒的分类能力。故验证集中的颗粒与训练集中的颗粒不同。图8展示了部分带标签的再生骨料数据集。

图8 带标签的再生骨料数据集Fig.8 Data set of labeled recycled aggregate
3.2 质量估计
如上所述,经过训练的卷积神经网络能够根据图像预测再生填料的性质。此外,提取单个再生骨料图像的软件记录了每个颗粒的几何特征,如图9所示。但是,根据标准,通过人工筛选获得的再生骨料的成分是通过质量给出的。因此,为了将本文提出的方法与标准的人工筛选法进行比较,需要估计图像中的颗粒质量。

图9 颗粒与其几何特征Fig.9 Particles and their geometric characteristics
颗粒i的质量mi可以如下表示:
mi=Vi×ρi
(1)
式中:ρi为颗粒密度,g/cm3;Vi为颗粒体积,cm3,可以表示为:
Vi=Si×Le,i
(2)
其中:Le,i是考虑了颗粒的不规则形状的等效厚度,cm;Si是投影表面积,cm2。在具有统计意义的形状相同的骨料样本中,颗粒的平均厚度与片状度成正比,且与片状常数成正比[23]。因此,可用Le,i表示颗粒的短轴长度Lmin,i与形状因子(F)的乘积,即片状常数。此外,在给定的子类别k中,所有颗粒都具有相同的密度(ρk)和相同的形状,因此具有相同的形状因子(Fk)。因此mi可以表示为
mi=Si×Lmin,i×ρk
(3)
由于不可能单独测量每个颗粒的质量,本文测量给定子类别k(表示为Mjk)的每张照片j的所有颗粒的总质量。最终,对于每个子类别k,可以估计Fk和ρk之间的乘积:
(4)
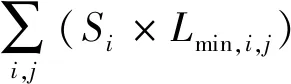
4 结果分析
4.1 图像分类
4.1.1 标准和自定义ResNet34的比较
使用第2节中创建的带标签的数据集,对标准ResNet50架构(RN50)和自定义架构(C-RN34)进行了测试。数据集包含22 500张在数据扩充后的9组均匀分布的图像。标记的数据集分为两组:
1)训练集(每个子类2 000张图像)
2)验证集(每个子类500张图像)
其中,用验证集包含的颗粒与训练集包含的颗粒不同。
CNN的学习是一个迭代的过程。在每次迭代期间,CNN都会进行一次训练和一次验证。在每次迭代结束时,评估训练和验证的精确度。当CNN达到其最大验证精度时,迭代停止。
由于CNN的迭代仅根据训练集的数据修改参数,训练精度均高于相应的验证精度。但是,如果这种精度差异太大,则意味着CNN过于贴合某个特定的训练集,因此无法正确地预测其他图像,即发生过度拟合。为了避免过度拟合,可以采用Dropout[24]等正则化方法。这可以在每次迭代后随机断开特定百分比的神经元连接,防止某些神经元在数据集上专一化。本文对两种神经网络架构,在全局平均池化层后采用了20%、40%和60%的Dropout比率。其中,40%的Dropout比率的验证准确性最高,故图10仅展示40%Dropout的训练和验证曲线。此外,设置RN50的初始学习率为0.04,设置C-RN34的初始学习率为0.1。如果连续5次训练,损失值都没有减少,则将学习率减半,直至最小值0.000 01。这使得损失函数可以在一定时间内收敛到最小。

图10 不同模型训练精度对比Fig.10 Comparison of training accuracy of different models
图10展示了训练测试超过250次迭代的训练和验证准确度的对比图。虚线表示训练曲线,而实线表示验证曲线。
经过100次迭代后,训练准确性均趋于100%。其中,Dropout率为40%的标准ResNet50架构发生了过度拟合。其验证准确性仅为90%左右,最高为92.0%。
而同样40%Dropout比率的自定义ResNet34架构比RN50_D40更优,其验证精度可达97.1%。对比缺少Dropout率的C-RN34_D0,可以发现,C-RN34_D40的验证精度始终大于C-RN34_D0,即40%的Dropout效果显著。综上,使用40%Dropout的C-RN34模型表现最优,因此后续研究使用该模型。
4.1.2 混淆矩阵
为了分析C-RN34_D40的预测,可以使用混淆矩阵,如图11所示。其纵轴为颗粒的真实子类,横轴为验证集中的预测结果。对角线的数值即为正确预测的百分比。

图11 混淆矩阵Fig.11 Confusion matrix
可以看出,除了混凝土(Rc)为93%和石灰石(Ru01)为94%外,其他子类的验证精确度都在96%至100%之间。由于天然石材可用于制造混凝土,混凝土颗粒与天然石材会有预测误差。在天然石材中,由于外观上类似浅色砂浆,导致石灰石的混淆率最高。另外,在人工筛选过程时也可能会产生类似的混淆。
此外,该分类是根据NF EN 933-11标准进行的。因此,如果仅考虑类别,则相同类别的颗粒之间的混淆不算入误差,因此验证准确性会更高,如石灰石(Ru01)、硅质石(Ru04)都属于天然石(Ru)类。
4.2 基于深度学习图像分析的性能
再生填料的组成即每个子类的质量比例。测试批为3 kg的4~31.5 mm 的填料骨料,小于标准最小质量的10 kg。由于测试深度学习需使用可以表示9个子类的不同于标记数据集的再生填料,因此,它包含较少的混凝土颗粒和石灰石。
测试批中的再生填料需通过筛选超过4 mm的颗粒,并冲洗表面的细粉。然后,进行人工筛选作为组成成分参考。之后,对测试再生填料进行拍摄,并使用3.1.3节中的软件提取单个颗粒及其几何特征。还可以人工识别每个颗粒的子类别,通过与人工筛选得到的分类对比,评估卷积神经网络的分类准确性。需要注意的是本文所提出的方法是在人工识别分类的基础上,对已有的图像进行标注,确认图像的真实值,这一点与人工识别相同。人工识别需要对所有图像进行识别,任务量大、耗时久且容易出错。而本文提出的方法仅需要对训练集上的图像进行标注,通过训练模型后即可以对之后的图像进行快速准确的预测,节省时间和人力成本。
为了通过深度学习方法确定组成成分,有两个主要步骤。首先,对每个再生填料的图像进行分类。这可以确定再生填料中每种颗粒的性质。第2步是估计每种颗粒的质量。
4.2.1 测试集图像分类
前文提取的单个颗粒的图像被送到C-RN34_D40卷积神经网络,来预测颗粒的子类别。其分类的精确度为91.7%,低于验证集的97.1%。这是由于数据集中每个子类数量相同,但测试集中具有更多的混凝土和石灰石颗粒。这两个子类由于其元素之间的混淆而具有最高错误率,这与混淆矩阵得到的结果相一致。因此,增加Ru和Ru01颗粒的数量,会增加误差、降低分类的准确性。
4.2.2 测试集单颗粒质量
为了确定每种颗粒的质量,确定了9个子类的形状因子常数Fk·ρk,如表2所示。

表2 9个子类的形状因子常数Table 2 Shape factor constants of the 9 subclasses
假设颗粒在特定的子类中具有相同的形状和密度,则根据Fk·ρk常数与颗粒的子类和几何数据,可以通过式(3)估算每个颗粒的质量。
图12展示了人工筛选和深度学习得到的质量成分对比,其中混凝土颗粒(Rc)和石灰石(Ru01)的预测差异较大,约为5.6%和4.2%,而其余子类的预测差异均小于2%。此外,由于再生填料主要包含混凝土颗粒和石灰石,Rc和Ru01之间的混淆也会降低计算精度。
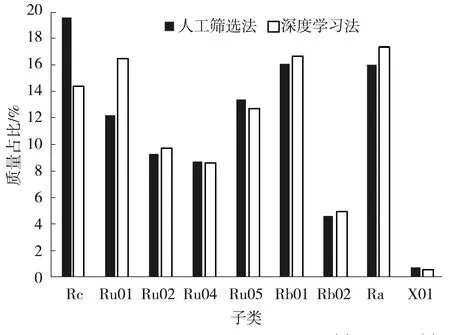
图12 人工筛选法与深度学习法对比Fig.12 Comparison of manual screening method and deep learning method
因此,可对错误分类的颗粒进行进一步训练。由于Rc和Ru01对紫外线和红外线的反应不同,因此在这两种光背景下,两种颗粒的图像差异较大,而数据集中的图像数量也可以增加。
5 结论
鉴于目前建筑垃圾筛选多采用耗时耗力的人工筛选法进行获取,本文提出一种基于深度学习的实时自动确定建筑废物成分的方法。该方法通过卷积神经网络(CNN)进行图像分析,可以自动实时地获取再生填料组成,而回收平台可以根据获取的成分质量对其进行分级。
对再生填料进行筛选得到大于4 mm的颗粒,冲洗掉表面阻碍识别的细粉,并通过人工筛选拍照记录,创建了一个包含36 000张单个再生填料图像的带标签数据集。利用数据集对ResNet50架构进行测试,发现其容易发生过度拟合。即使采用了Dropout正则化,ResNet50架构的最大验证精度仍低于92%。因此,本文提出了自定义的ResNet34架构,通过Dropout正则化,其验证精度可达97%;由于再生填料的组成通过子类的质量比例表示,本文还提出了一种根据子类和尺寸估算颗粒质量的方法。除混凝土颗粒和石灰石外,其估算结果与人工测量的质量相差不足2%。本文基于深度学习系统可对建筑垃圾进行系统详细的筛选,使最终得到的垃圾成分具有较高的使用价值,对建筑垃圾回填路基工程的推广应用具有重要意义。
