适用于地铁异物前景检测的神经网络
——DifferentNet
2021-12-07刘伟铭温俊锐郑仲星戴愿李泓道
刘伟铭 温俊锐† 郑仲星 戴愿 李泓道
(1.华南理工大学 土木与交通学院,广东 广州 510640;2.广州地铁集团有限公司,广东 广州 510030)
地铁是大中型城市的主要交通工具之一,为了保障运营安全,地铁站在列车与站台之间安装屏蔽门,在保护了乘客的同时,也产生了新的问题。屏蔽门与列车门之间存在间隙空间,乘客通过屏蔽门时,不慎掉落的物品会遗留在间隙之中,车门关闭时,也可能将乘客随身物品夹在间隙空间中。这些物体属于间隙空间中的异物,会对地铁的运行带来安全隐患。为解决该问题,各大地铁公司开始安装异物检测系统,广州、深圳等地的地铁公司已开始部署相关设备,在间隙空间上方安装传感器和边缘计算设备对风险异物进行检测。屏蔽门与列车门的间隙空间环境复杂,干扰因素众多,列车来临时带来的高压气流、间隙空间内的光照变化、粉尘流动等因素都会对异物检测造成影响。因此,要求异物检测算法具备较强的抗干扰能力。
目前,检测屏蔽门与列车门间隙空间异物的方式可以分为两种:使用红外或激光传感器直接测量,使用图像传感器间接测量。基于直接测量传感器的方案[1-2]安装要求严格,成本高且受振动影响较大,对于间隙较大的站台存在检测盲区。基于图像传感器间接测量的方案主要通过计算机视觉方法分析间隙区域的图像来实现异物检测,该方案成本较低,易于安装与维护。
传统的计算机视觉技术常采用帧差对比的方式进行异物检测,文献[3]中通过帧差法结合形态学处理进行异物检测,这种方法的检测速度快,但要求参与对比的两幅图像在背景区域无明显变化,导致抗干扰能力低,为改善这个问题,文献[4]中使用了GMM[5]算法,对多帧图像进行高斯混合建模以建立背景模型,并通过3δ准则判断前景得到检测结果。文献[6]中使用了Vibe[7]算法,以邻域采样的方式对背景建模,为每个位置的像素建立背景样本库,通过对待检测图片与背景样本库的对比得到异物检测结果。文献[8]中提出SuBSENSE算法,通过Color-LBSP的像素级建模方式,进一步提高检测准确性。传统方法虽然在发展的历程中逐步提高了性能,但受限于模型的泛化能力,准确性和抗干扰能力仍较低,只能应对单一模式的干扰,无法适应光照、背景复杂多变的地铁环境。
基于深度学习的语义分割技术近年来发展迅速,该方法能对图像像素进行精细分类,并具有较强的泛化能力,适用于地铁异物检测。该场景的主要关注点在于区分图像中的异物与非异物部分,属于二分类问题,异物部分的像素视为前景,非异物部分的像素视为背景。
FCN[9]的提出奠定了语义分割神经网络的基本结构,即编码-解码结构,这一结构通过编码部分提取数据特征,再经解码部分对特征分类并恢复尺寸,从而实现对像素的划分。FCN提出后,后续的语义分割研究在该结构的基础上改进,UNet[10]与SegNet[11]调整了编码部分与解码部分之间的对称度,使得分割图恢复边缘信息更加精细,UNet++[12]通过密集连接结构提高了网络对不同尺度信息的利用率,GCN[13]权衡了分类与定位之间的精度矛盾,并提高了前景边界的定位精度,DeepLab系列网络[14-17]通过使用空洞卷积提高了编码部分的感受野。这些研究提高了语义分割网络的定位和分类性能,从中可以看到,神经网络拥有较强的前景检测能力,这一能力可应用于地铁异物检测任务中。
本文提出假设,在这一任务中,神经网络在额外获取背景图片作为参考的情况下,对异物的前景检测将更加准确。基于该假设,本文将差异对比的思想与语义分割方法相结合,提出一种新的异物前景检测方法,并在实验中验证了该假设。本文方法的核心是一个新的前景检测网络DifferentNet,通过对比背景图片和待检测图片的局部特征差异得到待检测图片的前景热力图,再经阈值分割并剔除面积较小的轮廓得到最终的前景检测结果。在地铁异物前景检测实验中,本文方法取得了比其他语义分割方法更好的效果。
1 地铁异物前景检测方法
屏蔽门与列车门间隙的监控摄像头安装位置如图1所示,摄像头从间隙空间上方垂直向下拍摄,以保证拍摄范围覆盖整个间隙区域。本文方法由3部分组成,包括前景热力图生成、置信度判断、前景轮廓筛选。
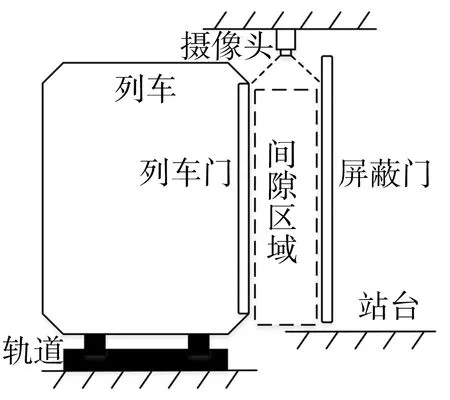
图1 摄像头安装位置示意图Fig.1 Schematic diagram of location of camera installation
本文的检测方案是:当列车进站后,将减速并停稳。在车门未开启时,间隙空间处在封闭且无异物的状态,采集此时图像作为背景图片。背景图片记录了列车门与屏蔽门等背景物的位置与形态信息,对前景判断起参考作用。列车停稳后列车门与屏蔽门将开启,并在上下乘客后再次关闭,完全关闭后间隙空间回到封闭的状态,此时列车门与屏蔽门的位置和形态与背景图片相同,但是否存在异物未知。采集此时的图像作为待检测图片,若存在风险异物,待检测图片与背景图片之间会存在局部信息差异,通过这种差异可检测异物。将背景图片和待检测图片输入本文提出的网络DifferentNet中,网络的编码部分通过骨干网络分别提取两幅图片的局部特征,解码部分通过局部特征的差异计算异物前景热力图。前景热力图表示了网络预测待检测图片中各像素为异物像素的置信度,使用全局阈值分割热力图初步判断前景,并通过筛选剔除面积较小的轮廓,得到最终的检测结果。整个前景检测总体流程如图2所示。
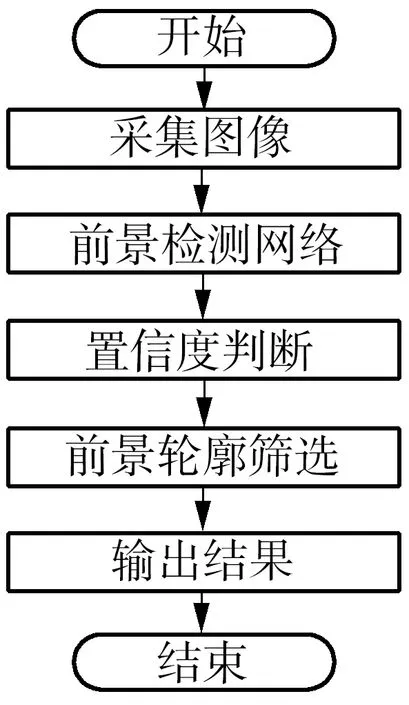
图2 前景检测流程图Fig.2 Flowchart of foreground detection
1.1 基于多尺度特征差异分析的前景检测网络
前景检测网络根据背景图片与待检测图片的局部特征信息差异产生前景热力图,需具备把两幅图片关联起来进行语义分割的能力。在已提出的语义分割网络中,UNet[10]是一个高效而简洁的网络,有着相对对称的“编码-解码”结构,能综合不同尺度的特征图信息,在图像分割任务中有着优秀的表现,广泛地应用在医学图像处理及其他领域当中[18-20]。FlowNet[21]及其它网络[22-24]采用了“双路图片输入与关联”结构,这种结构通常使用相同的骨干网络对两幅不同的输入图片进行特征提取,并在后续的部分对它们的特征进行分析,能有效地根据两幅图片之间的关联推断出任务所需信息。
本文将“双路图片输入与关联结构”融入“对称‘编码-解码’结构”之中,设计了一个新的前景检测网络DifferentNet。与UNet通过单帧信息推断前景不同,DifferentNet通过并行处理提取两幅图片不同尺度的特征,并将同一尺度的特征按位置相关联,这一关联能使网络根据两幅图片的内在特征信息及其对比差异推断前景像素。此外,与UNet相比,DifferentNet的编码与解码部分拥有更强的对称性,从而提升编码与解码部分之间的信息传递完整性。网络整体结构如图3所示。

图3 网络整体结构Fig.3 Structure of the whole network
DifferentNet以待检测图片和背景图片作为输入,在编码部分使用相同参数的骨干网络分别对两幅图片提取特征,得到一系列不同尺度的特征图,再把两幅图片中同一尺度的特征图连接,从而关联它们的特征。解码部分根据不同尺度关联后的特征图逐步上采样恢复尺寸,得到前景热力图。上采样通过转置卷积进行,并从尺度最小的特征图开始。每次上采样后得到的结果与上一尺度的特征信息相连并再次上采样,使解码部分能够根据不同尺度的特征信息分析并推断结果。在上采样过程中,为了减少信息丢失,在增大特征图尺度的同时减少其通道数。在多尺度特征融合过程中,先使用卷积层对关联后的特征图进一步提取特征,再与上采样后的特征图相连,从而使该过程具有更强的可学习性。

图4 VGG16的卷积部分Fig.4 Convolution part of VGG16

(1)


(2)

最后输出的特征图通道数为k,k由任务的分类数决定,当k>1时输出层使用Softmax激活函数。本文中的应用场景为前景/背景分类,是一个二分类任务,因此定义k=1,输出层使用Sigmoid激活函数。根据该定义,网络输出一幅与输入图片大小相同的前景热力图,记为M,M上每个元素的值代表了网络预测该处的像素点为前景像素的置信度。记图5中的输出层运算为ΨOut,则M的计算如下:
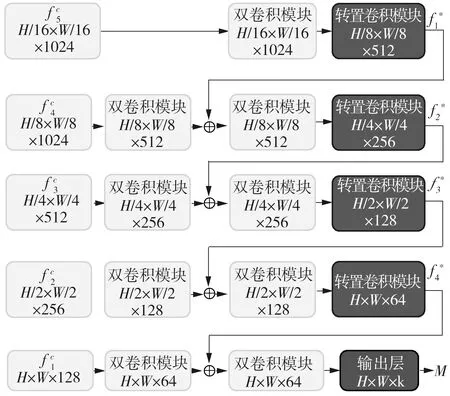
图5 解码部分结构Fig.5 Stucture of decoding part
(3)
1.2 损失函数
图像中背景区域的占比较大,造成正负样本不均衡,因此使用由Focal Loss[27]和线性权重损失组成的损失函数L:
L=βLfl+(1-β)Lfw
(4)
式中:Lfl代表Focal Loss,其计算如式(5)所示。Lfw代表线性权重损失,如式(6)所示,β代表Focal Loss的权重系数,取值范围为[0,1]。
(5)
(6)
式中:y代表Ground Truth,y′代表预测值。式(5)中α1为正样本的权重系数,取值范围为[0,1],γ为调制系数。式(6)中α2为正样本的权重系数。
根据参考文献[27]给出的建议,定义损失函数各参数的取值:β=0.5,α1=0.98,α2=0.98,γ=2。
1.3 前景分割与筛选
获取前景热力图后,需要经过后端处理完成前景推断。首先进行前景/背景分类,使用全局阈值法分割热力图M,设定阈值t=50%,则置信度大于t的像素分类为前景,小于等于t的像素分类为背景。分割后的图像记为MS。
前景异物在图像中的轮廓具有一定面积,构成风险异物的最小尺寸[28-29]为50 mm×50 mm×50 mm。记物体在图片中的像素面积占图片像素总面积之比为δ,根据摄像机线性模型[30],物体离摄像机投影面越远δ越小,经测试,实验现场中最小风险异物在测试区域内最小的δ=0.055 339%,因此使用轮廓提取法[31]提取MS中所有前景轮廓,并剔除δ<0.05%的轮廓连通域,得到最终的前景分割结果。
2 数据集
2.1 数据采集
本实验在广州地铁公司的配合下进行专门的数据采集。每次采集前关闭列车门与屏蔽门,拍摄此时的图像作为背景图片,然后打开列车门与屏蔽门,在保证安全的前提下手动放置异物在间隙区域,再关闭列车门与屏蔽门,拍摄此时的图像作为待检测图片,由此得到一组样本,本实验一共采集了158组样本。
2.2 数据增广
对原样本进行以下3个步骤的处理:
步骤1 添加前景异物贴图。为了更好地引导模型学习通过对比特征差异推断前景的能力,在待检测图片中加入异物贴图。一共准备了16个异物贴图,在待检测图片的间隙区域中随机添加1~3个异物贴图,每个贴图随机旋转并覆盖在随机位置,根据其位置调整缩放尺寸,添加异物贴图的同时修改该区域的标签。
步骤2 添加高斯光斑。为提高模型抵抗光线干扰的能力,在背景图片和待检测图片中添加5个位置、尺寸、强度随机的噪声区域。每个噪声区域服从二维高斯分布。
步骤3 添加高斯噪声。为了提高泛化能力,对背景图片和待检测图片中的所有像素添加随机强度的一维微小高斯噪声。
为了更好地评估算法,增大测试集的选取比例,在所采集的样本中随机选取60组样本,每组样本应用以上方法生成20组新样本,由此得到1 200组样本,将这些样本作为训练集。将原样本中剩下的98组样本作为测试集,组成一共1 298组样本的数据集进行实验。图6展示了一组样本数据增广前后的对比图片。

图6 数据增广前后对比Fig.6 Comparison before and after data augmentation
3 实验
所有实验在一台计算机上进行,计算机的参数为:CPU,Intel 9700K;GPU,Nvidia RTX2070s;内存,16 GB。数据集中所有图片的分辨率均为480×640,将其调整为240×320输入网络,使用Adam[32]优化器对网络参数进行训练,初始学习率0.001,衰减率0.98。
3.1 评价指标
文中采用5个指标对模型进行评价,包括准确性指标:精确率P、召回率R、调和均值F1、交并比cIoU,和速度指标:运行用时。
精确率、召回率、调和均值是机器学习常用的评价指标,计算式如下,
(7)
(8)
(9)
图像分割任务常使用交并比作为算法的准确性指标,它的计算如式(10)所示,本文任务更关心的是对异物的分类,因此计算前景类的交并比:
(10)
式(7)~(10)中:NTP表示分类正确的正样本数量,NFP表示分类错误的正样本数量,NFN表示分类错误的负样本数量,所有样本皆以像素为单位。
3.2 与传统方法对比
本文通过实验将DifferentNet与传统计算机视觉方法进行对比,参与对比的传统方法有:帧差法、GMM[5]、Vibe[7]、SuBSENSE[8]。实验结果如表1所示,其中传统方法在CPU环境中运行,基于深度学习的DifferentNet在GPU环境中运行。可以看出,传统方法的准确性较低,而DifferentNet在准确性上大幅领先于其他方法。图7展示了一组DifferentNet与传统方法的检测结果对比,从中可以看到,传统计算机视觉方法的抗干扰能力差,光照变化会对检测结果造成较大影响,其中帧差法的抗干扰能力最低,GMM、SuBSENSE的抗干扰能力略优于帧差法,但检测准确性仍非常低,而本文的方法DifferentNet较好地克服了光照干扰,并准确检测出了异物轮廓。

表1 DifferentNet与传统方法的性能对比Table 1 Performance comparison between DifferentNet and se-veral traditional methods

图7 DiferentNet与几种传统方法检测结果示例Fig.7 Examples of detection results from DiferentNet and se-veral traditional methods
3.3 不同网络对比
为证明本文假设,即:神经网络在有背景图片参考的情况下,对异物的前景检测将更加准确;并证明本文网络在地铁异物前景检测中的优势。将DifferentNet与6种语义分割网络进行对比,参与对比的网络有UNet[10]、GCN[13]、SegNet[11]、PSPNet[33]、RefineNet[34]、DeepLabV3+[16]。这些网络属于单图片输入网络,因此它们在只获取待检测图片作为输入的情况下进行训练和测试,输出前景热力图,并进行与1.3节相同的阈值分割和轮廓筛选步骤,实验结果如表2所示。通过更改前景分割的置信度阈值t,得到各网络的P-R曲线,如图8所示。由实验结果,较新的分割网络DeepLabV3+与RefineNet、GCN、PSPNet的表现优于UNet与SegNet,而本文中提出的网络在精确率、召回率、F1与cIoU上明显高于其他网络,准确性最高,但由于要对两幅图片进行特征编码与解码,运行用时比其他网络长,大约为其他网络的两倍。
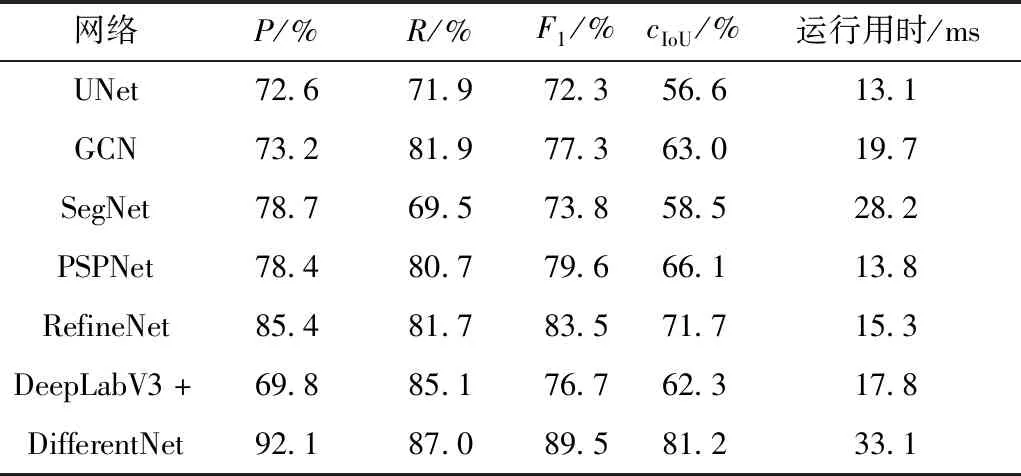
表2 DifferentNet与几种语义分割网络的性能对比Table 2 Performance comparison between DifferentNet and se-veral semantic segmentation networks
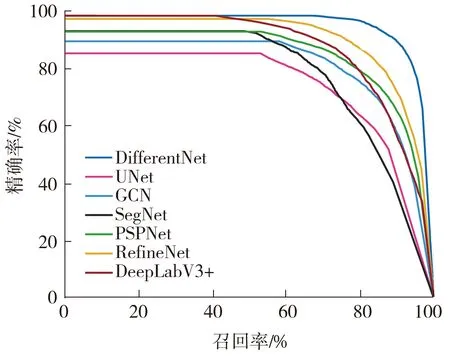
图8 DifferentNet与几种语义分割网络的P-R曲线Fig.8 P-R curves of DifferentNet and several semantic segmentation networks
图9展示了各网络的部分检测结果。可以看到,DifferentNet检测到的前景轮廓更加准确。图中第1、2行各图片之间的光照有很大变化,这种变化是间隙区域内的照明设备运作变化导致,是对异物检测造成干扰的因素之一。图中的第1、2、6列,待检测图片中,屏蔽门与列车门的间隙底部的照明灯打开,而背景图片中,照明灯未打开,使得待检测图片的亮度偏高,并出现了蓝色的灯带区域,在第4列中,侧面的红色照明灯闪烁造成背景图片色调偏红。这些光照因素会对检测造成干扰,而由第4行的检测结果看到,DifferentNet能很好地克服这一干扰。而其他网络,在无照明灯直射的情况下,有较好的检测效果(如第3列),但在有照明灯干扰的情况下,会出现较多的伪阳性误检区域(如第6列)。

图9 DifferentNet与几种语义分割网络的检测结果示例Fig.9 Examples of detection results from DifferentNet and several segmentation networks
3.4 有无背景参考对比
为了进一步证明本文的假设,将DifferentNet在移除背景图片影响的情况下进行训练与测试,但原网络在只输入待检测图片的情况下无法正常进行前向传播,因此按以下思路分别设计两组实验。
实验A:更改网络结构。将原网络结构中与背景图片有关的部分移除。对待检测图片在编码部分进行特征提取后,直接将特征图输入解码部分进行后续计算。此时由于缺少背景图片的特征图与之连接,输入解码部分的各特征图通道数减少一半,与原网络解码部分结构不兼容,因此将解码部分各卷积层的卷积核通道和数量缩减一半,使网络能正常运行。
实验B:保留原网络结构。在不改动原网络结构的情况下,将背景图片输入替换为同尺寸的随机噪声输入,噪声强度服从均匀随机分布,从而在训练过程中使网络与背景图片有关的参数向零回归。
按以上思路分别进行实验,以相同的超参数重新训练与测试,实验结果如表3所示,P-R曲线对比如图10所示。分析实验结果可得,实验A与实验B的各项准确性指标相对于原实验都有一定程度的下降,其中实验A的准确性下降幅度更大,但速度得到了明显提升,该现象可能是减少通道数所导致的。由此得出,在缺少背景图片作为输入的情况下,网络的准确性有所下降。实验A由于缩减了网络规模,运行速度得到提升,但更改了网络结构,因此本文认为实验B与原实验的对比更具公平性。
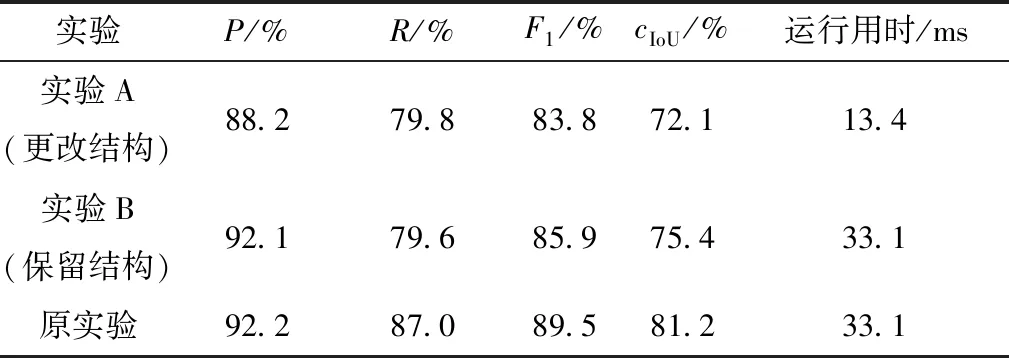
表3 DifferentNet有/无背景参考的性能对比Table 3 Performance comparison of DifferentNet with or without background reference
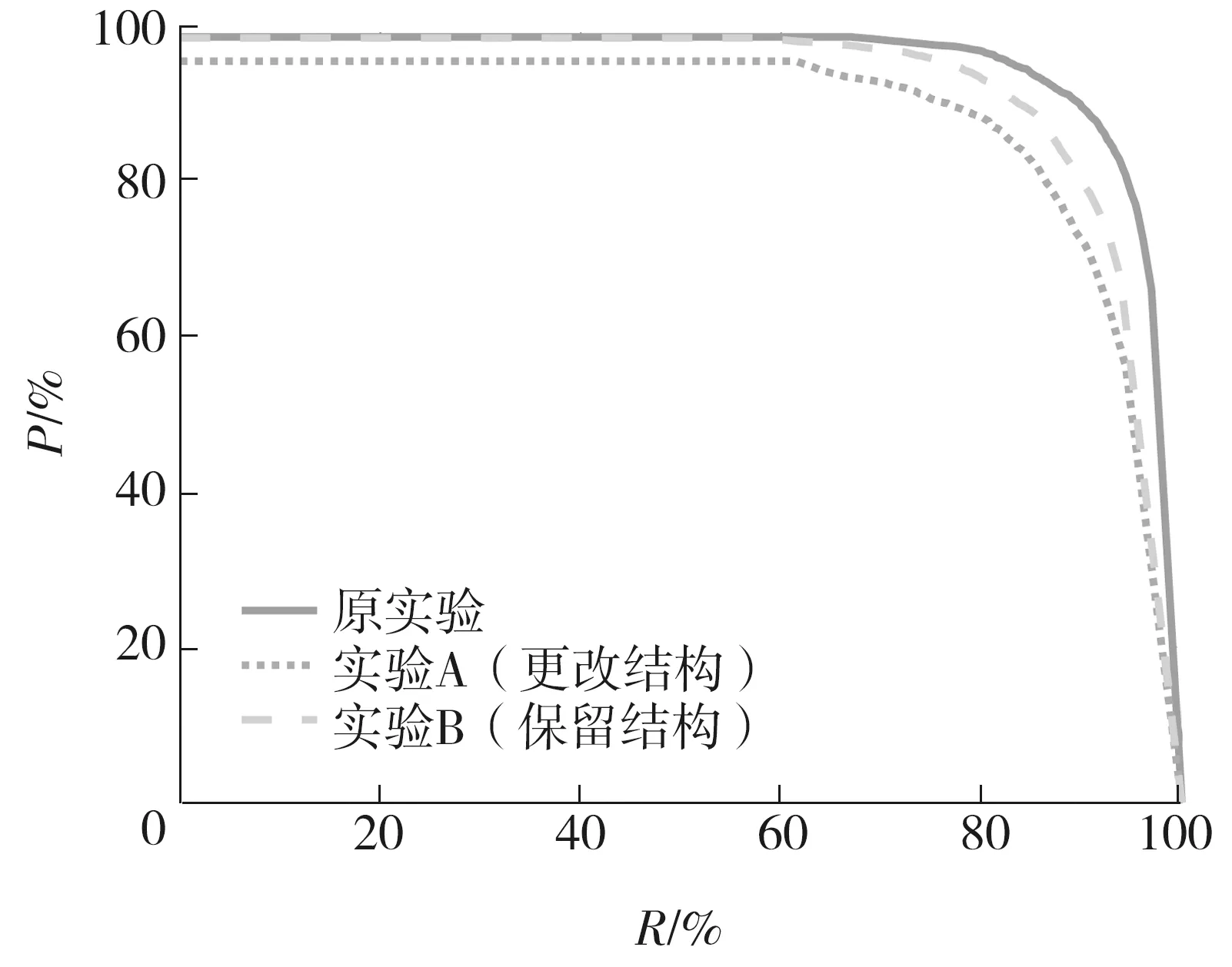
图10 DifferentNet有/无背景参考下的P-R曲线Fig.10 P-R curves of DifferentNet with or without background reference
实验A的方法与3.2节中的其他单图片输入网络相比,在速度较快的同时在各项准确性指标上总体处于领先位置。实验B与原实验对比,精确率下降并不明显,但召回率、cIoU都有较大下滑,这表明在缺少背景参考的情况下,神经网络的前景检测性能有所下降,虽保持较高的精确率,但会遗漏部分前景区域。通过分析,该现象的原因可能是在缺少背景参考的情况下,网络无法辨别部分与背景差异不明显的前景区域所导致。图11展示了一个上述情况的案例,图中异物的边缘部分与背景区域相似,在缺少背景参考的情况下,网络对边缘部分的检测效果不佳,而在有背景参考的情况下,网络能更准确地判断这部分区域。

图11 DifferentNet有/无背景参考下的检测结果示例Fig.11 Examples of detection results for DifferentNet with or without background references
3.5 解码部分卷积核数量对比
通过3.2节的实验发现,DifferentNet在准确性指标上有着较好的表现,并达到了实时运行的要求,但速度低于表3中的其他网络。通过3.3节实验A发现,在移除网络中与背景图片有关的部分并减少解码部分卷积核数量的情况下,网络的准确性下降但运行速度得到了较大提升。通过对表3的分析,得知性能下降的主要原因与缺少背景参考有关,同时,本文认为网络的准确性与卷积核数量之间可能存在联系。为了在保持准确性的同时提高DifferentNet的运行速度,并探究卷积核数量对原网络的影响,设计了以下实验:保留背景图片作为参考,并保持编码部分与原实验相同,减少解码部分的卷积核数量与通道数,以相同的步骤重新进行训练与测试,一共进行了2组实验。
实验C:通过减少解码部分的卷积核通道与数量,将图5中各模块输出特征图的通道数减少到原来的1/4,此时解码部分的卷积核数量为原来的39.3%。
实验D:通过减少解码部分的卷积核通道与数量,将图5中各模块输出特征图的通道数减少到原来的1/2,此时解码部分的卷积核数量为原来的57.0%。
实验结果如表4所示,其P-R曲线如图12所示。由实验结果得知,在实验D中,相较于原实验,除召回率有轻微提升外,准确性指标总体有较小下降,而运行速度有明显提升,参数量也大幅降低。在实验C中,相较于原实验,准确性指标总体降幅较大,相较于实验D,运行速度虽有提升,但提升的幅度较小。本文认为造成该现象的原因是,随着卷积核数量的下降,当其低于必要的数目后,解码部分的分析能力会出现明显下降,而且,输入解码部分的特征图通道数不变,导致解码部分中一部分卷积核的通道数无法缩减,使得参数量和运行用时的降幅也受到制约。

图12 DifferentNet在不同卷积核数量的解码器下的P-R曲线Fig.12 P-R curves of DifferentNet decoder with different number of convolution kernels

表4 DifferentNet在不同数量卷积核的解码器下的性能对比Table 4 DifferentNet performance comparison for decoders with different number of convolution kernels
综合以上分析,原实验中的卷积核数量是必要的,在算力充足的情况下应采用原实验的方案,在实时性要求较高的场合可采用实验D的方案。
3.6 不同上采样方式对比
在计算机视觉算法中,通常使用上采样操作对特征图进行解码,一些文献中[33-34]使用双线性插值+卷积的方式进行上采样,而另一些文献中[10-12]则通过转置卷积上采样。本文在解码模块的设计中,通过实验探究了DifferentNet在两种上采样方式下的性能差异,实验结果如表5所示,P-R曲线如图13所示。实验表明,本文方法采用转置卷积进行上采样具有更好的效果。

表5 DifferentNet在不同上采样方式下的性能对比Table 5 DifferentNet performance comparison in different upsampling modes
4 结语
为解决地铁屏蔽门与列车门间隙区域异物检测问题,本文中提出假设:在有背景参考的情况下神经网络能更好的检测异物,并基于该假设提出了一种新的前景检测方法,主要通过深度神经网络对比待检测图片与背景图片的差异,从而分割得到前景区域。为了有效关联两幅图片的特征并计算特征差异,本文网络在各尺度上连接两幅图片在编码部分得到的特征图,在解码部分通过跳跃连接和逐步转置卷积的方式恢复特征尺寸,得到前景热力图,最后经阈值分割和轮廓筛选得到前景检测结果。为有效训练和测试网络,在地铁现场进行了专门的数据采集,并通过一系列数据增广方法提高网络的泛化能力。通过实验,证明了本文的假设,并在与传统方法及其他分割网络的对比中证明了本文方法在准确性上的优势。本文方法在RTX2070s上的运行速度为30帧/s,可实时运行,但与其他方法相比,运行速度仍较慢,因此本文探讨了缩减解码部分卷积核数量对本文方法的影响,并得到一种较为可行的优化方案。本文方法在地铁异物检测任务中取得了较好的效果,同时为其他前景检测任务算法设计提供了新的参考。
