基于卷积神经网络的拖拉机工况识别*
2021-12-06孔庆好吐尔逊买买提赵梦佳
孔庆好,吐尔逊·买买提,赵梦佳
(新疆农业大学交通与物流工程学院,乌鲁木齐市,830052)
0 引言
随着中国农业机械技术水平的提高,新疆农业机械化水平逐年上升,2019年新疆农机总动力达到27 890 MW,新疆棉花、小麦等作物已经基本实现从耕种到收获全程机械化生产,但农业机械化带来的不仅有更加高效的生产效率,同时也带来了更严重的大气污染问题[1]。针对上述情况应用数据挖掘技术深入剖析农用拖拉机等移动源自身状态参数、识别并细化移动源作业状态可以帮助掌握区域污染物排放趋势并以此为基础制定更具针对性的治理措施,为实现这一目标建立具有高识别精度的农机工况识别模型显得尤为重要。
目前,农机领域数据挖掘技术的应用主要集中在农机空间状态识别[2]、农用机械污染物排放研究[3-5]、农用拖拉机故障检测和农机运行效率分析[6]等方面。在农机工况识别方面相关研究较少且多基于农机空间位置信息数据对农机运行工况展开研究,其中吐尔逊·买买提等提出基于密度聚类结合农业机械作业状态特征,通过对农机空间位置信息进行聚类实现农机工况识别。王培等[2]提出采用数据挖掘中聚类与空间数据分析方法,基于农机空间位置信息数据设计实现典型农机的运行状态识别方法。然而,上述研究均通过分析农机空间运行轨迹特点从空间层面间接判断农机运行状态,因此具有一定局限性。事实上,在农机作业过程中不仅会产生海量的农机空间信息数据,也会产生诸如速度、油耗以及发动机转速等反应农机运行状态的数据,深入挖掘这类数据实现农机作业工况的识别,可以进一步满足农机精细化管理与分析研究的应用需求。
1 研究方法
本研究通过研究农用拖拉机运行速度、发动机转速以及油耗等大量实测历史数据,提出利用农用拖拉机自身运行状态信息进行农用拖拉机工况识别,首先利用无监督学习算法支持向量机[7-8](Support Vector Machine,SVM)结合K-CV[9](K-fold Cross Validation)寻找最优参数训练模型实现拖拉机运行工况识别,并在此基础上对算法效果及农机作业状态识别结果进行数据处理与分析,分析该方法的适用性。同时,针对分析结果中发现的问题提出利用拖拉机运行速度与发动机转速来描述拖拉机运行状态,在此基础上应用卷积神经网络[10](Convolutional Neural Networks,CNN)进行拖拉机工况识别,并针对测试结果进行模型适用性分析。
1.1 农机实际工况下各参数分布特点
根据农用拖拉机的作业特点与文献[11]将农用拖拉机工况分为怠速、行走和耕作三种模式。其中,怠速模式主要指发动机保持在低转速状态下,且拖拉机处于静止的状态;行走模式是指拖拉机处于正常行驶当中,且不进行任何作业;耕作模式是指拖拉机对土地或农作物进行作业,旋耕犁处于工作状态。在实际作业中,当拖拉机处于怠速状态时,拖拉机发动机转速一般不会超过800 r/min,且运行速度为0,油耗较低;当拖拉机处于行走模式时通常会保持一个较高的移动速度,拖拉机发动机转速以及油耗均高于怠速模式,但低于耕作模式;在耕作模式下,拖拉机运行速度相较行走模式处于一个较低水平,但单位燃油消耗量以及发动机转速均为三种模式中最高的,具体实测数据变化范围如图1所示。

(a)发动机转速变化范围
基于上述分析,可以发现处在不同运行模式下的拖拉机行驶速度、发动机转速以及燃油消耗量呈现出明显的差异,可以提取农机时间序列样本点的上述参数分析辨别农机运行状态,通过数据挖掘的方法实现农机工况的识别,满足农机使用机构对农机的精准管理与后续相关研究的要求。
1.2 基于参数优化的SVM识别模型
1.2.1 C-SVC算法
支持向量机的主要思想是在多维空间中建立一个分类超平面作为决策曲面,使得不同分类之间的隔离边缘最大化,其中C-SVC算法是最经典的SVM算法,通过引入惩罚参数C,软化超平面间隔,从而达到扩大分隔间隔的目的。C-SVC具体算法公式如下。
设已知训练集
T={(x1,y1),…,(xl,yl)}∈(X×Y)l
(1)
式中:xi——特征向量。
xi∈X=Rn(i=1,2,…,l),即为输入数据。yi∈Y={1,-1}(i=1,2,…,l),为类别标号。
选取适当的核函数K=(x,x′)和适当的参数C>0,构造并求解最优化问题。
0≤αi≤C,i=1,2,…,l
(2)
(3)
(4)
式中:b*——阈值;
sgn(·)——符号函数;
K(x,xi)——核函数。
C-SVC算法在设计之初是为了解决二值分类问题,在处理多类问题时,需要构建合适的多类分类器。因此,本研究采用一对一(one-versus-one)法来实现多类分类,其基本原理是在任意两个类之间构建一个SVM,因此k个类别样本需要构建k(k-1)/2个SVM分类器。
1.2.2 SVM的参数优化
在算法构建过程中通过交叉验证(Cross Validation,CV)的方法实现惩罚参数与核函数参数的寻优,该算法的基本思想是将数据集分为训练集与验证集,通过训练集对分类器进行训练从而建立模型,再使用验证集对该模型进行验证,判断该模型的分类效果。
在对多种CV方法进行对比后,本文选用K-foldCrossValidation(K-CV)法筛选最优参数,该方法将原始数据分为K组,将其中K-1组数据作为训练集用于模型训练,剩余一组作为验证集对模型进行验证,如此循环直到所有数据子集分别都被作为验证集使用,将得到的K个模型分类准确度的平均值作为分类模型的评价最终指标。
1.2.3 基于参数优化的C-SVC拖拉机工况识别模型
获取某一时间段内拖拉机作业时的参数数据,将其组成样本集,并将其作为输入数据构建拖拉机工况预测模型,具体步骤如下。
1)为了防止各项特征数值差距过大对分类精度造成影响,对数据集进行归一化处理,确保所有数据均处在区间[0,1]。
2)将样本集分为训练集与验证集,选择径向基核函数K(x,xi)=exp(-γ‖xi-x‖2),γ>0处理训练样本集,构建C-SVC模型。应用K-CV法确定惩罚参数与核函数参数的取值,最终得到最优参数。
3)对数据集进行训练,获得最优分类器模型,将测试样本集输入模型当中,并将分类结果与实际值进行对比,依照对比结果判断模型的学习推广能力,若模型分类效果较差,则需返回步骤(2),直到建立具有较好分类准确度的模型。
1.3 基于卷积神经网络的农机工况识别
1.3.1 算法描述
选择卷积神经网络算法(CNN)来实现拖拉机工况的连续性识别,该算法是一种将卷积计算与前馈神经网络相结合的深度算法,目前在图像识别,人脸识别以及故障检测等领域应用广泛,具有较高的通用性与检测准确度[12-13]。本文采用CNN算法中的Alexnet模型,该模型是在LeNet模型基础上进一步深化建立的深度学习模型[12]。模型由输入层、输出层、5个卷积层以及3个全连接层组成主体结构,同时为了提高运行效率,在第3、5、9层构建Max-pooling池化层,整体网络结构如表1。
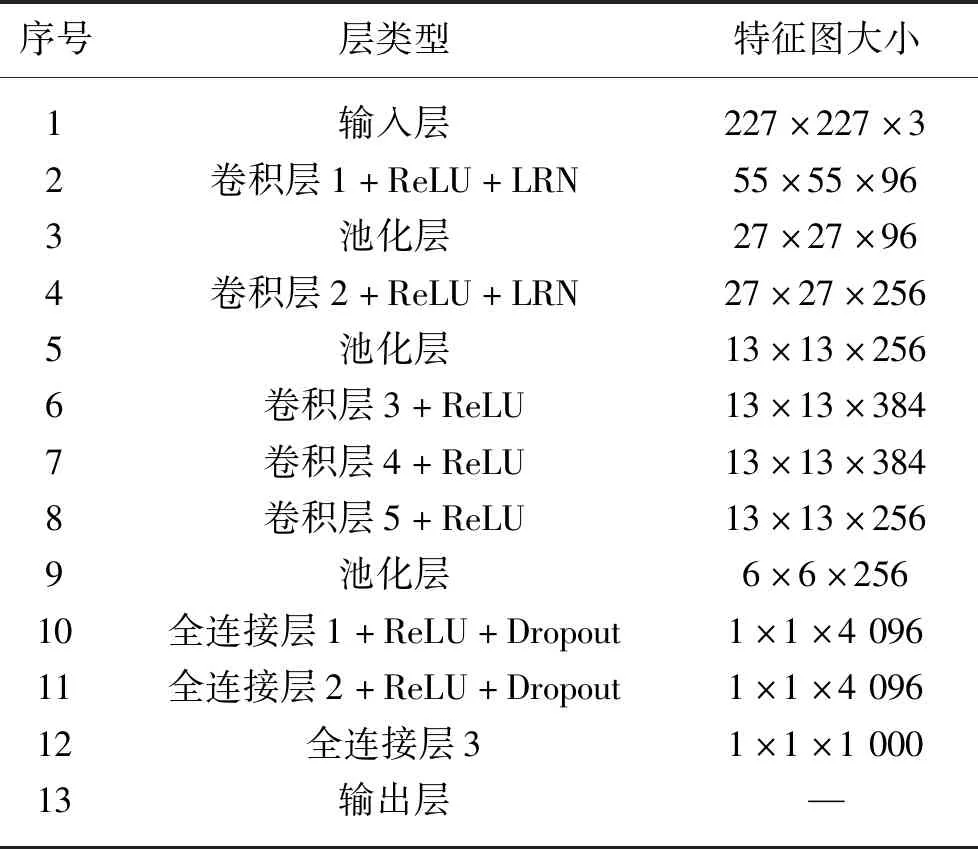
表1 模型网络结构Tab.1 Network structure of CNN model
在输入层选择227×227×3大小的图像作为输入,在第1卷积层,该层卷积核大小为11×11,即每次连接11×11的区域,获取一个特征,并使用ReLU作为激活函数,并进行降采样处理。
在第2卷积层,使用256个5×5的过滤器产生27×27×256个特征图,更进一步提取图像特征,过滤器对256个特征图中的某几个特征图中相应的区域乘以相应的权重,然后加上偏置之后所得到区域进行卷积,该层同样使用ReLU作为激活函数,并进行降采样处理。
第3、4卷积层通过特征提取获得384个13×13新特征图,第5卷积层得到256个13×13个特征图,并构建拥有4 096个神经元的第1与第2全连接层。
为了使网络具有更强的适用性及性能,因此第3全连接层选用1 000个神经元,并在输出层之前选用Softmax函数,如式(5),计算各工况的概率值。
(5)
式中:vc——分类器前级输出单元的输出;
c——当前类别索引;
t——总的类别个数;
Sc——目前元素的指数与全部元素指数和的比值,即当前工况类别的判断概率值。
1.3.2 识别精确度计算
在完成模型训练之后,还需利用测试集对识别精度进行量化,具体公式如式(6)。
(6)
式中:θ——识别精度;
nTP——某类状态预测正确的数量;
nFP——某类状态预测错误的数量。
2 农机试验及结果分析
2.1 数据获取
农用拖拉机上装载SEMTECH-DS气态污染物分析仪,该分析仪不仅可以实时采集污染物浓度数据、质量排放量和基于燃油消耗和时间的污染物排放量,还集成了转速仪,测速仪以及GPS等用于采集农机实时状态的专业配件。在进行田间作业排放试验时,将采样频率和采样周期分别设定为1次/s与45 min,并在采样周期的0~10 min 内将试验车辆设置为怠速模式,在10~20 min 内将试验车辆转变为行走模式,在20~45 min时间区间内试验拖拉机始终保持在耕作模式。
选取试验数据中数据质量较高的一个采样周期,并提取其中的发动机转数、农机行驶速度以及油耗数据作为本研究的测试数据集。
2.2 C-SVC运行结果及分析
依照基于C-SVC算法识别模型的构建步骤,对测试数据进行归一化处理。随机选取3种工况中50%的数据作为训练集,剩余数据则作为测试集,用于验证模型的识别准确度。使用MATLAB平台实现识别模型的搭建,设置惩罚参数与核函数参数的取值范围为[2-10,210]。模型对惩罚参数与核函数参数的取值范围进行离散化处理,取不同的离散值使得支持向量回归机的训练误差最小。参数选择效果如图2所示,最终得到惩罚参数C与核函数参数g的最优值为0.25与12.125 7。

图2 参数选择效果图(3D)Fig.2 Effect drawing of the parameter selection(3D)
使用模型对测试样本集数据进行工况识别,并对识别结果进行可视化处理,结果如图3所示。

图3 识别结果图Fig.3 Recognition result
图3中标签1表示的是农机的怠速模式,标签2为行走模式,标签3为耕作模式,从中可以看出仅有2个样本点出现了识别错误,其识别准确度达到99.851 9%。识别模型将处于行走模式的样本点错误识别成怠速模式,进一步分析两个样本发现,样本数据并不符合农机正常行走模式下的数据范围,属于异常数据,因此出现了识别错误的情况。通过上述测试仅从识别效果来看,基于参数优化的C-SVC模型可以有效识别单个样本点的工况。
2.3 基于卷积神经网络的工况识别
结合前述内容可知,基于参数优化的C-SVC模型可以较好的对样本点进行工况识别,然而在实际应用中拖拉机作业是个长时间持续过程,此过程中会产生包含部分异常值的海量数据,通过C-SVC模型仅对单个样本点进行识别并不能有效分辨试验数据中的异常数据,从而造成大量的错误识别。并且,在实际作业中拖拉机会基于工作现场的复杂情况多频次转换作业工况,转换过程的识别同样无法通过单个样本点的工况识别实现。同时,由于数据集较大的体量,试图通过分析不同工况下农机数据的差异从而实现人工识别同样不可取。
实现拖拉机工况的连续性识别可以有效解决上述问题,本文以拖拉机运行速度与发动机转速等信息构建样本图像来描述农机工况变化的数据表达,并在此基础上应用卷积神经网络实现农机工况的连续性识别。
2.3.1 数据预处理
为了实现农机工况的连续性识别,为农机状态识别提供新思路,需进一步研究农机工况变化数据,寻找能够描述农机工况变化的数据特征。在1.1节中已经提到怠速、行走及耕作3种不同工况下发动机转速、油耗以及农机运行速度等数据具有较大的差异,在此基础上本文进一步分析实测数据的分布特点发现,随着农机工况转变发动机转速变化呈现明显的梯度上升趋势,耕作工况下转速最高,行走次之,怠速最小,这说明农机在整个采样周期内发动机转速保持阶段性加速状态,但当处于一种工况下时,发动机转速在较为固定的范围内波动变化。需要指出的是农机的运行速度指标也表现出明显的阶段性,但并不表现为梯度上升,而是由最开始的静止状态经过3~4 s的加速过程进入行走模式,而当农机处于行走模式下时由于实际路况以及驾驶员心理状态等因素的影响导致农机运行速度在速度—时间二维空间中分布较广,但总体上维持在一个较高水平。而当农机由行走模式转为耕作模式时由于旋耕犁的下放加大了与地面的摩擦,从而导致运行速度下降。此外,当拖拉机改变运行工况时,农机运行参数则会出现较大波动。
综上所述,本研究利用一段时间内农机发动机转速与运行速度作为数据样本,以这两项数据样本在农机不同运行工况的变化趋势为基本特征,结合计算机视觉采用图像识别方式进行农机工况识别。如图4所示,选取时间序列的若干样本组成数据集,将农机各工况的数据集以面积图的形式形成图像样本,用于计算机识别。其中蓝色区域的红色轮廓线表示转速的变化趋势,单位为r/min,橘色区域的绿色轮廓线可以理解为速度的变化趋势,单位为km/h。将表示转速与速度的图像区域分别涂上蓝色与橘色,用于增强计算机的视觉能力,提高后文深度学习算法识别效果。
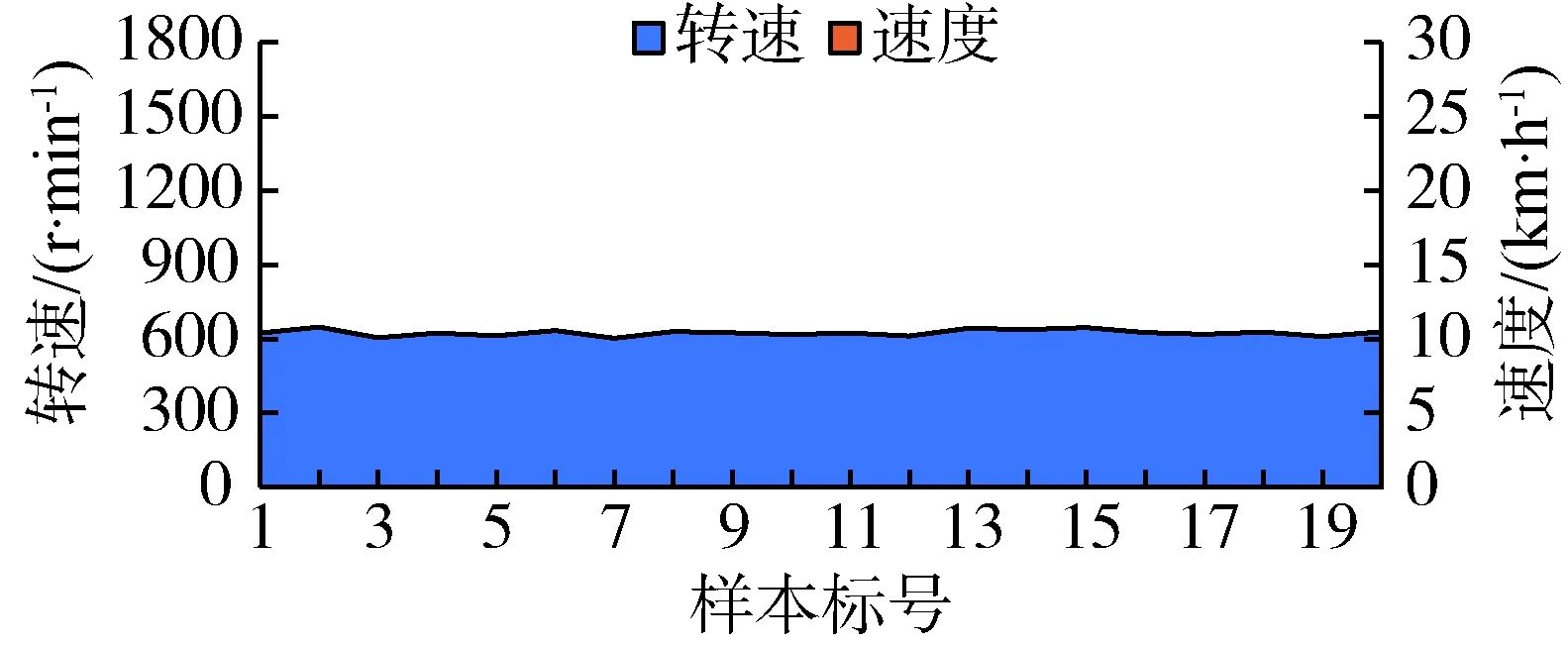
(a)怠速工况识别图像
图4(a)为农机处于怠速状态时发动机转速与农机速度的图像表示,由于怠速阶段农机速度为0,因此该阶段的图像只表现出蓝色区域用于表示农机发动机转速的变化趋势;行走状态下农机处于一个较高的运行速度,速度区域几乎覆盖转速区域如图4(b)。图4(c)则为农机处于耕作状态时发动机转速与农机速度在图像上的显示,与行走状态图像相比转速变化趋势更加平稳,且速度区域面积明显小于行走,表明拖拉机速度明显小于行走工况。图4(d)则表示两种工况转化时两项参数的变化,从中可以看出两者波动较大,且由于剧烈的波动可能会导致测量数据出现异常值。
分别选用10、15、20个样本形成数据集,分别训练识别模型并对比最终结果发现包含20个样本的数据子集训练得到的工况识别模型兼具高识别准确度与较快的运行速度,因此将总共2 700条样本数据,按照每组20个样本构成135个图像样本,并将其中60%作为训练集,25%作为验证集用于验证模型,剩下15%则当成测试集用来评估模型。同时,为了方便农机工况的识别,将农机工况分为4种,分别为怠速、行走、耕作以及其他,前三种已经在前文中提到,这里不再赘述,其他指代两种工况转换时农机的运行工况。
2.3.2 CNN模型运行及分析
通过不同模型超参数组合,在训练集上进行参数调优,获得该模型的主要超参数分别为迭代次数为900,学习率为0.000 1,设置初始权重系数与偏置为符合正态分布的随机值,迭代优化算法为Sgdm,同时为了提高模型训练效率,设置模型训练过程中验证数据最优分类准确度连续20次验证都没有提高时停止网络训练。运行之后训练集经过28 s训练建立模型,图5说明随着迭代次数的增加,模型准确率与损失值在训练集和验证集上的变化趋势。从中可以分析发现,随着迭代次数的增加模型识别准确度逐渐提高最后稳定在97.1%,同时损失值则随着迭代次数的增加呈现单调递减,逐步趋近于0,这表明该模型在训练集以及验证集上训练效果较好。
为进一步验证识别模型的可靠性,将测试集应用于训练好的模型,并引入精准率(Precision)、召回率(Recall)以及F1值(H-mean)等3项指标对验证集与测试集的识别结果进行评价,结果如表2所示,针对不同工况3项评价指标均能达到0.8以上,这表明该识别模型识别精度较高,分类效果良好。并最终获得识别结果如图6与图7,图6中标签分别表示图像所属的农机工况与该工况的概率值,测试结果显示随机选取的4个样本的工况类别判断概率值均为100%。分析图7混淆矩阵发现,该模型在识别怠速与其他工况时并未出现识别错误,仅出现一例耕作与行走状态的识别混淆,这种识别错误对于实际工况识别是可以接受的。根据式(6),该模型针对不同工况识别准确率可以达到93.3%,虽然在识别精度上比参数优化的C-SVC算法略有下降,但处在可接受范围内。同时通过提高训练集以及验证集的数据样本规模可以进一步提高模型识别准确度。

(a)准确率
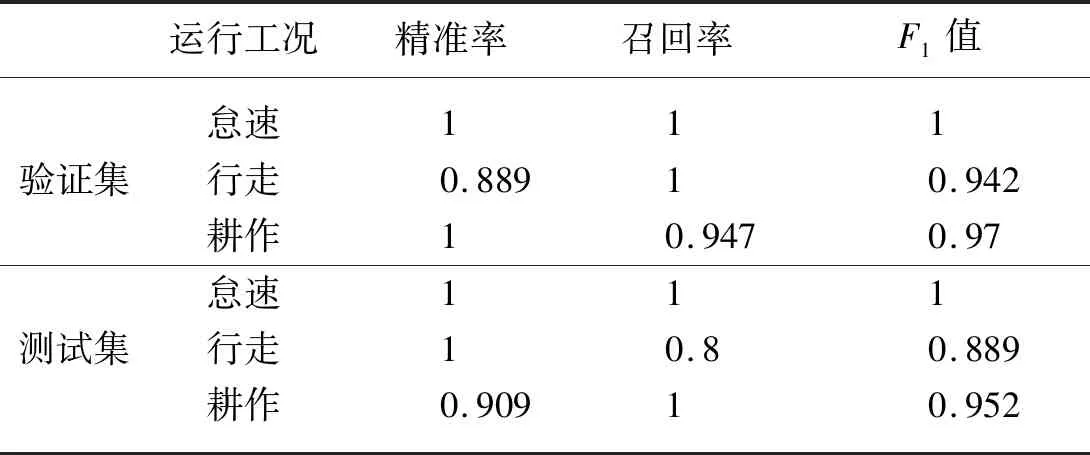
表2 模型不同工况下精准率、召回率及F1值Tab.2 Precision,recall and H-mean of the model under different working conditions

图6 部分测试集识别结果Fig.6 Part of the test set recognition results

图7 模型应用于测试集的识别结果混淆矩阵图Fig.7 Confusion matrix of result of testing set
3 结论
1)设计采用无监督学习参数优化的C-SVC算法,通过参数优化选取惩罚参数与核函数参数最优值0.25与12.125 7对样本点进行工况识别,结果表明识别效果较好,且识别准确度可以达到99.851 9%,但无法实现时间序列的工况连续性识别,且无法有效识别两种工况转换时的农机状态。
2)提出以包含农机发动机转速与运行速度等信息图像样本来描述农机工况连续变化的数据表达方式。
3)采用拖拉机运行速度与发动机转速等信息构建样本图像并利用深度学习卷积神经网络基于Alexnet网络结构,并选用迭代优化算法Sgdm进行最高900次迭代建立了农机工况识别模型,通过测试集评估该模型,发现该模型识别准确率达到93.3%,且测试集3种运行工况下精准率、召回率及F1值三项指标均能达到0.8以上,表明该模型可以有效识别农机运行工况,为农机工况识别模型的建立提供新思路。
本次研究虽通过卷积神经网络进行农机工况识别,但受数据规模等因素的限制,所建立的工况识别模型可以进一步优化模型结构并提高识别精度,在后续工作中,将在实际工况下的数据测度规模和工况分析方面做进一步研究。
