基于知识图谱的干部人事档案知识化服务研究
2021-12-03周娟娟李泽锋刘竟一
周娟娟 李泽锋 刘竟一


摘 要:本文提出运用语义分析、知识图谱等新技术,增强数据关联,提高干部人事档案服务质量,以促进干部人事档案知识化服务研究发展。以构建符合干部人事档案特征的知识图谱来精准识别干部,为领导班子配备和选用提供科学依据。
关键词:干部人事档案;知识图谱;语义分析;知识关联;知识服务
Abstract: Proposed the use of new technologies such as semantic analysis and knowledge graphs to enhance data association and improve cadres the service quality of personnel archive to promote the research and development of cadre personnel archive knowledge service. Construct a knowledge map that meets the characteristics of cadre personnel files, accurately identify cadres as a prerequisite for motivating and selecting cadres, and at the same time provide a scientific basis for the deployment and selection of the leadership team.
Keywords: Cadre personnel archives; Knowledge graph; Semantic analysis; Knowledge association; Knowledge service
1 整体概况
知识图谱构建总体可分为模式层和数据层,模式层构建是定义干部档案知识图谱所包含的实体类型及类的属性、实体类之间的语义关系等。然后,数据层是根据构建的干部档案知识图谱模式,匹配档案特征数据,用语义技术进行命名实体识别和语义关系抽取;通过实体消歧、实体筛选等过程进行知识融合,最后根据干部档案构建知识图谱情况选取合适的知识储存方式,完成对知识的管理和检索。
2 数据获取
干部人事档案数据获取的主要来源,一类是纸质档案数字化加工后的数据;另一类是干部学习经历、工作中直接产生的反映个人能力或经历等的电子数据。
本文将干部个人档案基本元数据划分为三大模块,其中包括人员元数据、来源元数据和支持类信息元数据。人员履历中涉及的主要元数据要素有姓名、出生年月、政治面貌、最高学历、学位、职务、职位、个人成果及参与活动情况等信息,作为反映干部个人工作经历和生活以及家庭关系等重要元数据集。
3 知识获取
本文将采用基于规则的档案实体识别方法[1]和实体词性关系抽取法。从干部人事档案的内容信息中抽取实体、关系和属性,进行语义揭示和知识组织,为干部选拔、提拔工作提供决策服务,增强系统功能同时拓展浏览的检索方式。做出以下方法实体抽取与关系关联,搭建干部人事档案知识图谱。[2]
3.1 实体识别。在进行关系抽取之前,将命名实体抽象成命名实体的词性,用实体的词性来替代实体本身。将数据进行词性替换预处理之后,再用深度学习方法对关系属性特征进行学习,最后完成实体关系的抽取。两种方法的结合,将自动化构建模板,同时加强人工审核,作为补充模板可用性。抽取实体构成可按主题类型进行划分,采取与干部人事档案分类标准相趋同的元数据集方案,分为履历材料、自传材料、考核材料、学历学位材料、政审材料、党团材料、奖惩材料和工资材料等十大类进行实体与词性标注。
本文重点以第一大类履历材料为例进行知识图谱构建,借助某中层干部履历材料中出现的信息,包括年度、奖项和主题等内容。某干部某年、某年N次入选为某市优秀教师,某年入选某市“培养跨世纪理论人才百人工程”,某年入选教育部“跨世纪优秀人才培养计划”,某年获某院颁发的政府特殊津贴。经过统计按照“×年”“入选”“×××”顺序模式进行编排。
按词性划分,规定词性标准。其中,n代表名词,c代表连词,v代表动词,a代表形容词,tn代表时间名词等。因此,为<时间名词-行为动词-专有名词>结构,分别用<-tn>、<-v>、<-zn>等进行表示。以此为标准建立词性规则,类推其他類型的何时何地获得何奖励、成果和技能等内容的实体词性,抽取实体特征数据,将实体映射到存放在数据库表字段中,减少实体识别过程效率低下等问题。
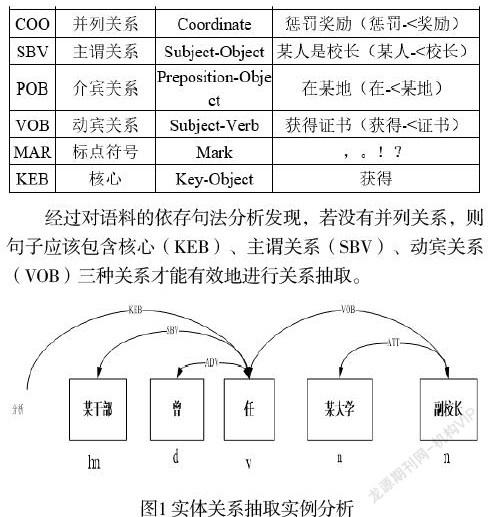
3.2 关系抽取。有了实体词性,接下来需要基于依存句法分析的档案关系抽取。依存句法分析的档案关系抽取是通过在语料进行分词、词性标注预处理之后提取出语料句法关系,基于句法关系对实体之间的关联关系特征进行学习的过程。句法结构关系包括核心(KEB)、主谓关系(SBV)、定语结构(ATT)、动宾关系(VOB)、并列关系(COO)等,如表1所示。
经过对语料的依存句法分析发现,若没有并列关系,则句子应该包含核心(KEB)、主谓关系(SBV)、动宾关系(VOB)三种关系才能有效地进行关系抽取。
通过将句子的成分映射到知识图谱三元组中,从而实现关系的抽取。利用OCR扫描技术获得文本内容,分析句子成分,如,“某干部 曾任 某大学 副校长一职”例子中,属于“某干部”(人员实体)和“职位”(职位实体)之间的关系。
句子“某干部 曾任 某大学 副校长”,名词短语识别结果为“某大学 副校长”,句子结构类型属于〈主语,核心动词,宾语名词短语+宾语名词〉,语义依存关系如图1所示,抽取的关系为〈某干部,(曾)任,[某大学]副校长〉。
在图1中,带有方向的弧线代表依赖顺序,表示箭头终点词语依赖箭头起点词语;弧线上的标签文字代表依赖类型,矩形块表示变化识别的结果。依存句法分析的结果中指明了每一个词组的依存类型与其前序依存对象,可以从这些分析结果中提取出实体关系的特征数据。
通过识别数据预处理示例可以看出,原文经过预处理手段进行分词和词性标注的格式,对该部分内容进行实体识别。在干部人事档案十大类别中,尤其是第一大类履历类,包含了干部个人基本信息、工作经验以及获得成果和家庭情况等重要内容信息,按照实体抽取规则和模板进行关系识别抽取,为本体构建与知识表示打基础,尽可能地描述实体与实体之间关系,最后進行知识融合和消歧,构建知识图谱,更清晰形象地呈现干部履历材料的特征信息,为干部提拔和审核提供参考建议。
3.3 属性抽取。属性抽取一般是较为基础的属性信息,根据对履历类实际数据需求,从各类型元数据集类型中,抽取用户所需要的信息,如“何时”即什么时间点,“何地”即发生在什么地点,“事件”即发生了什么事儿,“奖励”即什么奖励类型。如,市级、省级或国家级类型的科技类、教育类等情况。通过属性抽取可以更准确地对抽取实体进行揭示。
干部人事档案知识图谱中实体属性抽取,总的来说,可分为两种,其中,第一种是实体所对应的概念所具有的属性,只需要抽取其属性值即可;第二种是没有所属的属性,完全依赖实体属性抽取,需要抽取其属性和属性值。针对第一种情况,模式层中的关系也是包括对属性间属性关系抽取,即属性与属性值范围的界定等信息;因此,在数据层中可以复用模式层部分数据概念与值域。
4 知识图谱构建
4.1 构建流程。RDFS 在 RDF 的基础上定义了一些功能标签,增加 RDF 的语义约束,提高语义信息能力。构建档案学领域本体,[3]为不同知识库与系统之间的数据与知识利用提供接口,增加知识的复用。
将不同结构的档案数据划分为类XML、表单、文档和术语的语义转换,[4]档案数据关联有助于弥补传统知识组织方式的不足,通过语义匹配和本体构建,可以将档案转换成关联数据,整体构建流程如图2所示。
4.2 知识关联。选用某干部的个人履历材料,由于干部档案性质的特殊,仅作为研究一个切入点进行探究。将抽取实体的关系进行梳理,整体关系描述如表2所示,包含某干部个人基本信息和工作信息以及成果等方面的数据。
分别为工作单位、性别、年龄、学历学位、职称、曾任职务和个人成果等实体之间的关联关系。进一步加快干部知识图谱的构建,用图谱形式清晰展现出个人特征信息。
将某干部个人特征信息用知识图谱形式展现,在档案数据化管理中,有助于档案数据之间关联和语义重组等相关元数据管理,作者所属单位、年龄、性别、工作、学术成果、奖励荣誉等数据,利用规则和词性进行关系分析和抽取,构建出“某干部个人履历知识图谱图”,如图3所示。
由于工作需要和管理模式的转变,促使干部档案数据以一种新的形式呈现,即知识的呈现。通过语义关系揭示事物与实体之间的关系属性,最终系统清晰地对档案数据进行呈现,更好地辅助决策者的利用。
5 知识融合
知识融合包含模式层和数据层,模式层阶段构建要注意概念、概念上下位和概念属性的统一,避免属性概念歧义,保证实体对齐,概念表征同一个真实对象,由此,方便实体包含的信息进行融合和聚类;数据层是针对不同来源数据进行实体对齐与消歧,出现多个实体表征统一对象,则需这些实体之间构建对齐关系。除不同数据源造成的档案资源中实体间相互冲突或者实体指向不明等问题。不同的数据源对所描述的知识方式各不相同,生成知识图谱元素也不同,描述不一致会致使数据冗余,检索效率降低。因此,有必要将多个不同来源且等价的知识图谱/本体/属性等元素进行合并。知识推理主要指对知识进行语义的拓展和一致性的检验过程。在构建中,按照规定约束规则对知识进行拓展,延伸知识意义。然而,拓展出的知识可能会产生与原有知识相矛盾的情况,此时,需要一致性检验,利用推理检验看是否与知识库中知识存在矛盾。数据语义化表达提供检索、分类、聚类与智能推荐。经过深度语义化的数据才可以支持上层语义功能。另外,尽可能地减少人工干预,降低人为因素的控制。在知识库中,通过知识推理对查询服务做补足。
参考文献:
[1]胡梦君.基于规则的蒙古文人物属性抽取研究[D].内蒙古大学,2018.
[2]刘峤,李杨,段宏,等.知识图谱构建技术综述[J].计算机研究与发展,2016,53(03):582-600.
[3]王应解,吕元智,聂璐.档案学领域本体的构建初探[J].档案学研究,2015(06):19-25.
[4]郭学敏,Ryan Shaw.基于关联数据的档案语义转换实践分析[J].档案学通讯,2019(05):50-57.
(作者单位:郑州航空工业管理学院信息管理学院 来稿日期:2021-07-10)
