依据机器学习算法的杉木干形模拟1)
2021-12-03梁瑞婷周来谢运鸿丁志丹孙玉军
梁瑞婷 周来 谢运鸿 丁志丹 孙玉军
(森林资源和环境管理国家林业和草原局重点开放性实验室(北京林业大学),北京,100083)
林木干形是描述树干不同高度处的截面直径随树干纵向位置的变化,是研究林木最重要的因子之一,它既与树干的出材量有关,又影响木材的质量[1]。通过削度模型可以精确估算单株林木的树干材积,对重建树干轮廓、估算林分蓄积和森林碳储量、评价森林经营水平和森林规划设计等方面具有重要意义[2]。确定干形,解析木截段测量是最精确的方法,但需要耗费大量人力、物力,而且破坏性大,因此,一般采用削度方程。削度方程即是利用树木胸径、树高、截面高等易测量的林木特征因子作为自变量预测截面直径的回归方程[3]。尽管过去已有多种统计学方法建立林木的削度方程,如:线性与非线性回归[4]、分位数回归[5-6]和混合效应模型[7]等,但这些方法在应用时对数据分布有很强的要求,需要满足一定的统计学假设前提,如数据的独立、正态、等方差等[8]。而林木生长是由多个因素交互作用、共同影响[9],其数据通常难以满足这些假设条件,需要探索新的建模方法作为补充。
机器学习是新近兴起的一门涉及多领域的交叉学科,作为一种数据驱动的算法,机器学习能够自动从数据中分析规律,并应用于新的样本,非常适合处理复杂的非线性问题[10-11]。与传统回归相比,机器学习对数据分布没有要求,能高效处理变量之间非正态、非线性和共线性关系[12]。而且机器学习可以通过一定措施改进模型,进一步提高模型精度,如增加训练集数据、调整学习参数或改变模型结构。近年来,机器学习逐渐开始应用于林学领域的研究,如:Martins Silva J P et al.[13]利用机器学习和混合模型估算了巴西大草原上单株林木的材积和生物量,Kilham P et al.[14]利用随机森林估测了德国西南部多种森林类型的林分蓄积,Ozcelik R et al.[15]人利用人工神经网络和非线性回归建立了红松树高曲线模型[16]。这些研究都取得了良好的结果,表明机器学习在森林生长收获和森林资源监测方面具有很大的应用潜力,也为研究林木干形提供了一种新思路。国外有学者展开相关研究,如Nunes et al.[16]采用随机森林和人工神经网络对巴西复杂雨林内多种林木的干形进行估测,发现人工神经网络的精度高于传统削度方程。Sanquetta et al.[17]采用K-近邻法和人工神经网络对巴西地区柳杉的干形进行模拟,发现最近邻法能够提高干形估测的精度,是一种简单明了的估测方法。Schikowski et al.[18]应用3种机器学习算法对黑松的树干削度和材积建立模型,表明机器学习一种估测森林参数可行的方法。迄今为止,国内应用机器学习对林木干形模拟的研究较少。
本文以福建将乐国有林场的杉木(Cunninghamialanceolata)为研究对象,利用最近邻算法、随机森林和人工神经网络3种机器学习模拟其干形,估测树干不同高度处对应的直径,并与传统削度模型进行比较。通过4个模型评价指标,结合残差图和相对偏差图进行排序,以得到高效、低偏的干形估计方法,为杉木干形的精确估测提供参考。
1 研究区概况
本研究的解析木数据来源于福建省三明市将乐县(117°5′~117°40′E,26°26′~27°4′N)的将乐国有林场,该地区的年均气温20°左右,年均降水量约2 700 mm,气候温暖湿润,雨热同期,以中、低山为主,海拔多在400~800 m范围内,土壤肥沃深厚。主要树种有马尾松(PinusmassonianaLamb.)、毛竹(Phyllostachysheterocycla(Carr.) Mitford cv.Pubescens)等。
2 材料与方法
选择不同龄组且有充分代表性的杉木人工纯林,并在林分内设置标准地(标准地面积为20 m×20 m或20 m×30 m),共29块。根据每木检尺的结果计算林分的平均胸径和平均树高,并选取生长健康的平均木,尽量使样木均匀分布于各个径阶,共得46株杉木解析木。伐倒前测量树高(H)和胸径(D)。伐倒后按1 m区分段截取圆盘,不足1 m的区分段作为梢头。同时,在树干基部和胸径1.3 m处也分别截取圆盘。然后测量每个圆盘东西、南北两个方向的直径,计算其平均值作为对应高度处的直径。共计获得793组数据,解析木的数据统计见表1。
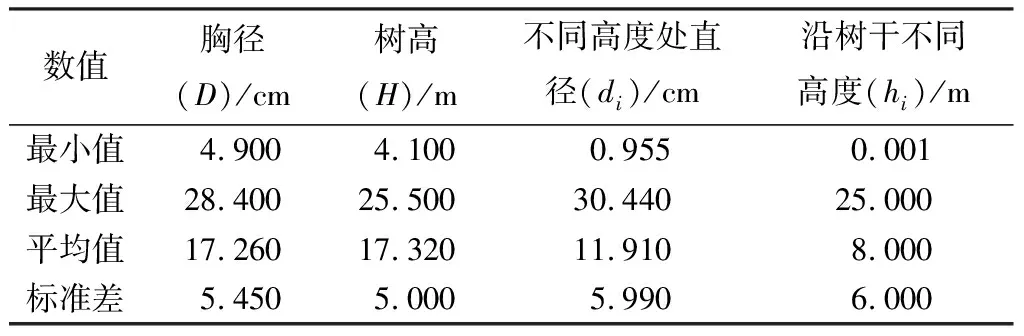
表1 杉木调查因子统计
2.1 应用非线性回归的杉木削度方程
本研究从前人对杉木干形的研究成果中,选取了精度最高的削度模型[3-4],该模型由曾伟生提出,其具体表达见公式(1),方程的参数通过非线性最小二乘法确定,利用R4.00的nls()函数拟合求得。
(1)
式中:a1、a2、a3和a4为模型参数,D、H、di、hi分别表示胸径、树高、树干直径和树干距离地面的高度。
2.2 机器学习算法
本研究采用的3种机器学习算法都是利用R4.0.0软件,为了避免单一测试集的偶然性和随机性,采用十折交叉验证,即把所有数据10等分,每次用9/10的数据作为训练样本,剩余1/10作为验证样本。这样重复10次,每次采用不同的训练样本和检验样本,最后以10次结果的平均值为评价标准。

randomForest包实现随机森林算法,随机森林算法的精度通常与“树”的个数有关,尽管设置的样本(树)数量越多,结果越稳定[19],样本(树)的设置需要依据具体的研究数据而定,默认的样本量为500,一般而言,样本(树)在500以后误差趋于稳定[20-21],但是考虑本研究的数据量较少,取100≤样本(树)≤500以50为间隔进行参数调优,最终确定样本(树)为300,以往的采用随机森林研究树干削度也采用样本(树)=300,模型表现最好[17]。根据周志华建议[19],枝(mtry)设置为输入变量数目的1/3左右,参考前人研究[22],枝(mtry)分别取1、2和3,结果表明不同的枝(mtry),模型拟合精度没有明显差异。
网络包实现人工神经网络,在学习过程中,通常采用人工神经网络建模时为了防止过拟合,一般都将权值衰减参数(decay参数)设为0.001,最大迭代次数(maxit)设为1 000次,如果达到目标,就会提前终止迭代[19,23],隐蔽单元个数则是(size参数)设置为15[18]。训练过程如图1所示,由输入层,2个隐藏层和一个输出层组成,上一层的输出通过权重转化后作为下一层的输入,不断迭代,通过梯度下降法寻找最小误差平方和。输入因子为树高(H)、胸径(D)和不同高度(hi),输出因子为沿树干不同高度处对应的直径(di)。

图1 ANN模型的结构图
2.3 模型评价指标
模型的评价包括拟合精度和拟合优度两方面,本研究采用决定系数(R2)、均方根误差(ERMS)、平均误差(EM)和平均绝对相对误差(EMA)4个模型评价指标,依据十折交叉验证,各指标的平均值来进行模型评价,具体计算公式如下:
(2)
(3)
(4)
(5)

3 结果与分析
为了比较3种机器学习算法和传统削度模型对杉木干形的拟合能力,采用评分法对模型进行排名[19],指标最优的模型得分最高,最后每个模型把所有指标的得分相加就是该模型的最终得分,结果见表2。各模型排名为人工神经网络、最近邻法、传统削度模型、随机森林,4个模型的R2在0.97~0.99,ERMS在1左右。最近邻法与人工神经网络的表现优于其他模型,其R2均是0.99,其余指标也都较小。人工神经网络模型的EM最小,但其EMA比最近邻法的高了65.3%。最近邻法是以K个最邻近的目标的平均值作为参考,因此,最近邻法生成的不是拟合曲线,而是类似实际数据分布的散乱的点云图,所以与平均回归相比,其误差往往更小。

表2 基于非线性回归与机器学习算法的拟合结果(训练集)
为了检验各模型的泛化预测能力,利用不参与模型构建的检验集对模型进行独立性检验(表3),模型在检验集上的表现略差于训练集,各模型的R2都有减小,但减小幅度很小,这与前人的结论一致[19]。人工神经网络模型的变化最小,说明人工神经网络模型的泛化预测能力更好,稳定性更强。人工神经网络模型的R2最大,为0.98,其ERMS、EM和EMA均是各模型间最小。最近邻法模型的EM比传统削度模型大0.046,但其EMA与ERMS分别比传统削度模型小了16.52%和2.53%。由于传统削度方程是采用平滑的数学函数描述干形轮廓,而人工神经网络与最近邻法算法直接受数据驱动,从数据中寻找规律,能最大限度逼近复杂的函数,所以精度一般会更高。
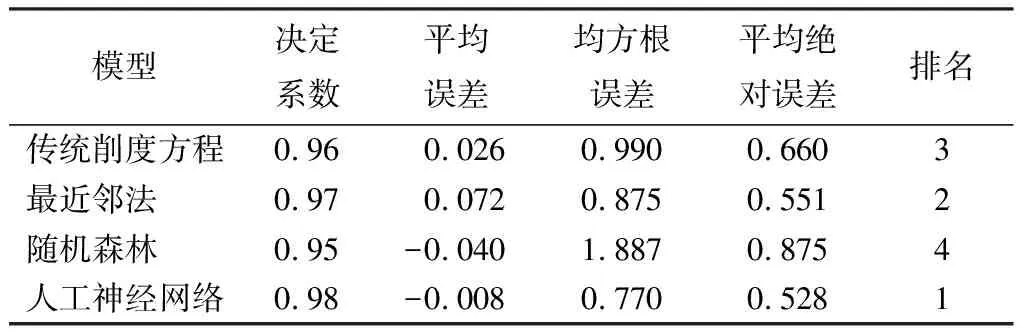
表3 基于非线性回归与机器学习算法的独立性检验(检验集)
各模型的残差分布情况如图2所示,整体来看,各个模型的残差均匀分布在y=0直线的两侧,且都没有出现极端残差,残差的波动范围正常,检验集的残差与训练集的残差分布非常接近,说明没有出现过拟合,这一现象在机器学习过程中很容易出现,通过合理地调参可以有效避免[17]。最近邻法与随机森林的残差散点图趋势表现相似,当di<2 cm时,残差大都小于0,而当di>25 cm时,残差都大于0。说明这两个模型对树干基部有预测偏小的趋势,而对树干上部,有预测偏大的趋势。但很明显最近邻法的残差很小,精度高于随机森林。尽管人工神经网络模型的拟合残差表现不是最好,但它的预测残差表现最优,有最好的预测泛化能力,这在实际应用中非常重要。

图2 不同模型的残差图
各模型的相对偏差分布情况如图3所示,可以看出,无论训练集还是检验集,各个模型的相对偏差分布都呈现单峰趋势,在x=0处为峰值,说明绝大多数预测的相对偏差都为0,或是非常接近0。最近邻法模型的峰值相差最大,相差0.15,随机森林模型的差值为0.10,说明这两个模型稳定性不好,能较好地描述已知数据,但不能准确地预测未知数据。人工神经网络模型的训练集和检验集的相对偏差分布几乎重合,其峰值相差极小,模型的拟合结果和预测结果较理想。人工神经网络模型由于具有大量的“神经元”,通过调整权重而不断逼近[24],采用误差反向传播算法训练的,能够对任何类型的输入尽可能映射到输出。研究采用提前终止,没有出现过拟合现象。

图3 相对偏差的密度图

各模型对干形的模拟精度随着相对高度的变化而变化(表4),在相对高度为0.1~0.6时,各模型的EMA较小。说明削度模型对树干中部的预测精度更高,对树干基部的和树干上部的直径的预测误差较大,这与前人结论一致[18],符合林木树干的形态特征,树干基部与上部的削度变化较大,而树干中部类似圆柱体,更为规律。在相对高度≤0.1时,传统削度模型对干形的模拟精度最高,而在相对高度为0.2~1.0时,人工神经网络模型与最近邻法模型对干形的模拟精度较高。说明不同模型对树干不同部位的模拟效果不同,如果多个模型互为补充,配合使用,其预测精度会更高。人工神经网络模型对树干绝大部分的预测精度最高,可以较精确地模拟杉木干形,但对树干基部的预测效果略差于传统削度模型,若采用传统削度模型作为补充可能会进一步提高预测精度。
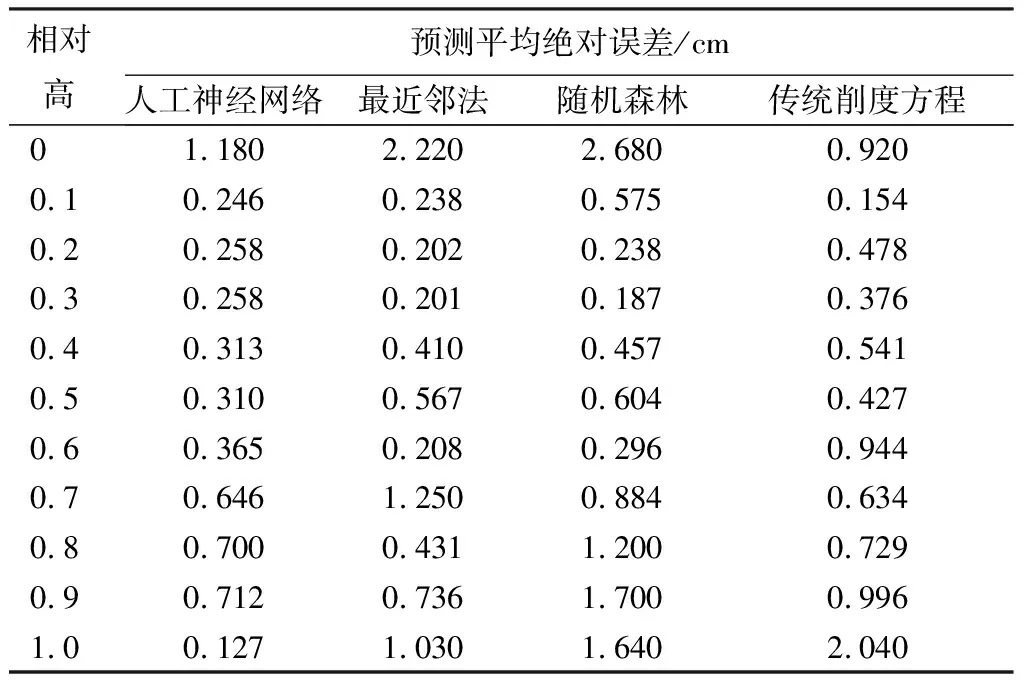
表4 各模型对不同树干部位预测的平均绝对误差(EMA)
4 结论与讨论
传统回归在处理复杂的非线性问题时,尤其当变量个数较多、变量间关系复杂时,往往出现不收敛的情况[14,25-27]。树木干形的影响因素很多,采用传统的模型增加自变量会使模型结构复杂,实际应用不便。机器学习是一种能够自主发现变量间的关系、给出模型结果的算法,而且可以处理有噪声、缺失等低质量数据。
本研究以我国重要的用材树种的杉木为对象,引入机器学习,分别采用最近邻法(KNN)、随机森林(RF)和人工神经网络(ANN)3种算法对干形进行模拟,同时构建了传统非线性削度方程作为比较。结果表明:人工神经网络模型是4个模型间表现最优的,R2最大,残差范围和残差密度范围最小,对树干绝大部分的干形模拟都较为精确,特别是其预测泛化能力,优于其他模型,这与Schikowski et al.的对巴西草原的黑松干形的研究结果一致[18]。人工神经网络模型之所以表现如此出色,是因为该算法能够自动发掘“真实数据”之间的复杂关系,考虑变量之间的相互依赖性,这对传统非线性回归模型来说,是不容易实现的。其次表现较好的是最近邻法模型,最近邻法模型的拟合能力是4个模型间最好的,但是其预测能力不如人工神经网络,在Sanquetta et al.利用最近邻法模型估测材积时也发现这一特点[17]。最近邻法模型与传统回归模型之间的误差非常相近,甚至在某些情况下,最近邻法的误差更小。最近邻法模型能够通过若干邻近值进行预测[20],不需要任何回归拟合过程,具有简单通用和较强的可塑性等优点。随机森林模型能够有效处理生态领域的分类和回归问题,具有很好的泛化能力和统计可靠性[22]。但本研究中,随机森林对杉木不同高度处直径的预测不高,尤其在检验集内,该模型有对较小直径的预测偏小,对较大直径的预测偏大的趋势。这种特殊趋势是基于回归树模型特有的,在其他的研究中也有类似发现[17]。随机森林表现不如人工神经网络,是内在算法不同导致,随机森林的每个节点由平均值给出,可能会低估较低值而高估较高值。
机器学习模型和传统削度模型都表现出良好的拟合能力,训练集的决定系数(R2)均高于0.97,均方根误差(ERMS)在1 cm左右波动。尽管传统回归能够满足干形预测精度,但是在模型选型和参数估计上仍是比较复杂。此外,最近邻法模型与人工神经网络模型在没有引入更多变量的前提下,拟合精度与预测精度均高于传统削度模型,比传统回归能更精确地预测杉木沿树干不同高度处的直径,最近邻法与人工神经网络更适合模拟杉木干形,具有更好的适用性。未来的研究可以基于机器学习算法研究其他森林参数,扩展其应用范围,以提高森林参数的估测精度。
