基于RoBERTa模型的公众留言分类研究
2021-12-02孟晓龙任正非
孟晓龙,任正非
(1.上海旅游高等专科学校,上海 201418;2.上海师范大学旅游学院,上海 201418;3.科克大学数学学院,科克 爱尔兰)
0 引言
基于大规模文本语料库的预先训练模型能够学习通用语义表征,再根据给定数据集进行微调可以显著提升预先训练模型在各类自然语言处理任务的性能[1]。文本分类作为自然语言处理的一个基础任务,试图推断出给定的文本(或句子、文档等)的标签或标签集合,在如情感倾向分析、新闻主题分类、内容审核、问答系统等[2-3]诸多领域有广泛的应用。
本文基于某政务平台公众留言文本分类数据,分别从如何合理地选择给定数据集的特征来源,如何在效果损失较少的情况下显著地提升模型速率,如何有效地设计微调策略等三个方面进行研究。主要的贡献有:
(1)相对仅选取公众留言数据集的“主题”作为数据特征来源,采用“主题+详情”的效果可提高2%~3%;
(2)相对典型的预先训练模型BERT,本文采用的基于全词掩蔽的扩展模型RoBERTa-wwmext的效果提高2%左右,基于知识蒸馏的压缩模型RBT3的速率提升2~4倍;
(3)相对模型默认微调策略,本文采用的判别微调和倾斜的三角学习率等微调策略效果可提高2%~3%。
1 相关工作
1.1 上下文编码器
Peters等人2018年采用深度双向Bi-LSTM来实现上下文相关,提出[4]一种动态的、语境化的语言模型ELMo(embedding from language models),将目标任务处理转移到预先训练产生词向量的过程中。Devlin等人2018年提出基于多层双向Transformer结构的语义表征模型BERT(bidirectional encoder representations from transformers),同时利用掩码语言模型和下一句子预测任务[5]来获得高级别的语义表征。Liu等人2019年基于语义表征模型BERT,去掉下一句子预测任务,设计动态更新掩蔽模式,以及使用更大的语料库、设置更大的批次大小和更长的训练时间的训练策略[6],提出强力优化的BERT语义表征模型RoBERTa(robustly optimized bert pre-train-ing approach)。Cui等人2019年利用全词掩蔽WWM(whole word masking)来替代BERT模型采用的部分词掩蔽方法,提出更适合中文自然语言处理任务的BERT-wwm模型[7],并在综述文章[8]中介绍基于全词掩蔽的强力优化语义表征扩展模型RoBERTa-wwm-ext和基于知识蒸馏的压缩模型RBT3。
1.2 微调策略
随着预先训练模型深度的增加,其所捕获的语义表征使目标任务更加容易。然而,作为预先训练模型适应目标任务的主要方法的微调过程往往是脆弱的,即使有相同的超参数值,不同的随机种子就可导致实质上不同的结果[1]。
Sun等人的研究表明[9],对相关领域语料进行进一步的预先训练,可以进一步提高BERT的能力,并在文本分类数据集上取得SOTA的性能。Stickland等人在预先训练模型BERT添加额外的特定任务适应模块PALs(projected attention layers)[10],实现比标准微调模型少7倍参数,却在通用语言理解评估基准GLUE表现相当的性能。Goyal等人2017年提出预热方法[11],即在训练初期使用较小的学习率开始,并在训练后期逐步增大到较大的学习率。Howard等人2018年提出倾斜的三角学习率STLR(slanted triangular learning rates)方法[12],先线性地增加学习率,然后根据训练周期线性地衰减学习率。同时,Howard等人提出判别微调DF(discriminative fine-tuning)方法[12],即区分性地以不同的学习速率调整每个层的训练。
2 关键技术
2.1 强力优化的BERT语义表征模型
多层双向语义表征模型BERT的出现[5]使预先训练模型应用于自然语言处理领域真正走向成熟,并在工业界得到广泛的应用,也成为学术界的研究热点。基于BERT的改进版本也逐渐被提出,在各类任务中展现SOTA的表现。针对BERT的改进,主要体现在增加训练语料、增添预先训练任务、改进掩蔽方式、调优超参数和优化(压缩)模型结构等。
2.1.1 多层双向语义表征模型
多层双向语义表征模型BERT根据不同任务和输出,联合训练掩码语言模型MLM(masked language model)和下一句子预测任务NSP(next sentence prediction)来获得高级别的语义表征[5]。
其中:
掩码语言模型MLM:随机将输入中15%的词遮蔽起来,通过其他的词来预测被遮蔽的词,可以学习到词的上下文特征、语法结构特征和句法特征等,保证特征提取的全面性。
下一句子预测任务NSP:输入句子A和句子B,判断句子B是否是句子A的下一句,可以学习到句子间的关系。
2.1.2 强力优化方法
强力优化的BERT语义表征模型RoBERTa主要从动态掩蔽方式、移去下一句子预测任务NSP、超参数优化和更大规模的训练数据等方面对语义表征模型BERT进行改进[6],具体如下:
静态掩蔽变动态掩蔽:BERT在预先训练开始随机选择15%的词进行遮蔽,之后的训练不再改变,即静态掩蔽;而RoBERTa在预先训练开始时将数据复制10份,每一份都随机选择15%的词进行遮蔽,这种动态掩蔽可间接的增加训练数据,有助于提高模型性能。
移去下一句子预测任务:实验发现,移去下一句子预测任务在下游任务的性能上与原始BERT持平或略有提高。RoBERTa采用Full-Sentences模式,即支持每次输入连续的多个句子,直到最大序列长度等于512(可以跨文章),从而使模型能捕获更长的依赖关系,有助于模型在长序列的下游任务取得更好的效果。
更大的批次大小和更多的训练数据:实验发现,更大的批次大小配合更大的学习率可提升模型的优化速率和性能;更多的训练数据增加数据的多样性,同样能提升模型的性能。
2.1.3 全词遮蔽
BERT-wwm和RoBERTa-wwm-ext模型使用全词遮蔽WWM(whole word masking)的训练方式[7],将长单词整体进行遮蔽。特别针对中文,如果一个词的部分字被遮蔽,则同属该词的其他部分也会被遮蔽,即对组成这个词的汉字全部进行遮蔽。这种预先训练方式的改进,使模型能够学习到词的语义信息,已在多项中文自然语言处理任务上取得更好的效果。
2.1.4 知识蒸馏
利用知识蒸馏KD(knowledge distillation)的方法,RBT3模型[8]在训练中扮演学生角色,其Transformer层和Prediction层学习教师模型RoBERTa-wwm-ext对应层的分布和输出,以教师模型的参数初始化前三层Transformer层(包括Hidden层和Attention机制)以及Embedding层,并在此基础上继续训练,在仅损失少量效果的情况下大幅减少参数量,进一步提升推断速度并可在一些资源紧张的设备上有效执行。
2.2 微调
2.2.1 判别微调
本文使用判别微调DF(discriminative finetuning)方法[12],能够让模型在微调过程中不断减缓底层的更新速度,尽可能地保留模型习得的底层通用知识。
通常,根据随机梯度下降SGD(stochastic gradient descent)算法,第t次训练时模型参数θ更新如公式(1)所示:

其中,η表示学习率,▽θJ(θ)代表模型目标函数的梯度。对于判别微调方法,将参数θ分成{θ1,…,θL},其中,L是模型的分层数,θl表示第l层的模型参数。同样,ηl表示第l层的学习率。
判别微调的随机梯度下降更新如下:

经验发现,若最后一层的学习率设定为ηL,将ηl=ηl-1/2.6作为较低一层的学习率是有效的。
3.2.2 倾斜的三角学习率
本文使用倾斜的三角学习率STLR(slanted triangular learning rates)方法[12],即先线性地增加学习率,再根据训练迭代次数线性地衰减学习率。具体表达如公式(3)所示。

其中,T是总的训练迭代次数,cut_fr ac是学习率上升在整个训练迭代次数的比例,cut是学习率转折时的迭代次数,p是学习率递增或将递减的放缩比例,ratio是最小学习率与最大学习率ηmax的比值,ηt是第t次迭代时的学习速率。
经验发现,当cut_frac等于0.1至0.2,ratio等于32时,具有短期增长和长衰减期特性,结果较好。
3 实验与分析
3.1 实验数据
本文实验选取某政务平台公众留言文本分类数据集作为实验数据集,该数据集来源于第八届“泰迪杯”数据挖掘挑战赛,包括“编号”“用户”“主题”“时间”“详情”和“标签”等六个字段,包含城乡建设、环境保护、交通运输等7个类别,共9210个样本。如表1所示。

表1 某公众留言文本分类数据集介绍
3.2 评价指标
马修斯相关系数MCC(matthews correlation coefficient)[13]是机器学习中被用来衡量分类质量的指标之一。它通常被认为是一个平衡的指标,即对样本不同类别数量差别较大时也适用。对于K分类问题,其定义如公式(4)所示。

3.3 对比实验
本文实验使用4.1节介绍的某政务平台公众留言文本分类数据集,并以4.2节介绍的马修斯相关系数MCC作为分类结果的评价标准。实验环境单卡16GB的Tesla V100显卡。实验结果括号内为20次运行结果的平均值,括号外为最高值。
4.3.1 特征选择实验与分析
本组实验分别以公众留言分类数据集的“主题”和“主题+详情”作为数据特征来源,基于3.1节中重点介绍的BERT、BERT-wwm、RoBERTa-wwm-ext和RBT3等4个预先训练模型,采用默认的微调策略,即采用自适应矩估计(Adam)优化器,批次大小等于16,全局学习率等于1e-4,微调迭代周期Epoch等于3,并根据两组文本输入长度不同,分别设置“主题”和“主题+详情”的最大序列长度等于32和512。实验结果如表2所示。

表2 特征选择实验结果对比
实验结果表明,采用“主题+详情”作为数据特征来源的效果可提高2%~3%,这说明合理地选择给定数据集的特征来源可以显著地提升效果。其中,RoBERTa-wwm-ext模型的效果提升尤为明显,这是由于该模型采用的Full-Sentences模式能捕获更长的依赖关系,有助于模型在长序列的下游任务取得更好的效果。RBT3模型的速率可提升2~4倍,且效果损失较少,特别是采用“主题+详情”作为数据特征来源时;同时也发现对于RBT3这类压缩模型,需要设置更长的微调迭代周期(如Epoch等于5或10时)才达到稳定。
4.3.2 判别微调策略实验与分析
本组实验以“主题+详情”作为数据特征来源,以压缩模型RBT3作为预先训练模型,采用判别微调DF策略,即设置模型分层超参数Dis_blocks分别等于0(即默认的微调策略),3,5和7,其他超参数与4.3.1中相同。实验结果如表3所示。
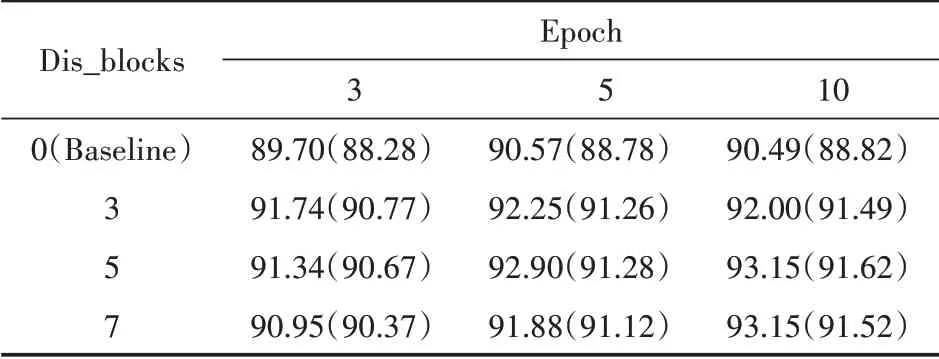
表3 判别微调策略实验结果对比
实验结果表明,适当的模型分层超参数设置可提高模型的效果2%~3%(如微调迭代周期Epoch等于5或10,分层超参数Dis_blocks等于5),这是由于判别微调策略会尽可能地保留模型习得的底层通用知识,避免微调过程中产生严重的遗忘;而过大的分层超参数设置会导致性能的下降(如微调迭代周期Epoch等于3,分层超参数Dis_blocks等于7),这是由于过大的分层超参数设置会降低模型底层的更新速度,影响模型的拟合能力。
4.3.3 倾斜的三角学习率策略实验与分析
本组实验以“主题+详情”作为数据特征来源,以压缩模型RBT3作为预先训练模型,采用倾斜的三角学习率STLR策略,即设置表示学习率上升在整个训练迭代次数的比例超参数cut_frac分别等于0(即默认的微调策略),0.1和0.2,表示最小学习率与最大学习率(即全局学习率)的比值超参数ratio等于32,其他超参数与4.3.1中相同。实验结果如表4所示。

表4 倾斜的三角学习率策略实验结果对比
实验结果表明,采用倾斜的三角学习率的“预热”策略,同样可提高模型的效果2%~3%,这是由于该策略有助于减缓模型在初始阶段的提前过拟合现象和保持模型深层的稳定性。同时也发现当微调迭代周期参数设置较大(如Epoch等于5或10)时,表示学习率上升在整个训练迭代次数的比例参数设置较小(cut_f rac等于0.1)时的实验结果更好。
4 结语
本文以某政务平台公众留言分类任务这一典型自然语言处理任务为例,分别从数据特征来源的选择、模型速率的提升、微调策略的设计等三个方便进行研究。本文的实验充分表明恰当的数据特征选择可明显提升模型的效果;本文采用的扩展模型RoBERTa-wwm-ext和压缩模型RBT3分别在效果和速率上都有明显提升;本文采用的判别微调DF和倾斜的三角学习率STLR等微调策略也有不俗的表现,同时也提出上述策略超参数的设置提出合理建议。
