基于网络行为分析的诈骗网站识别技术研究
2021-12-02连远博盛蒙蒙袁莹周胜利
连远博,盛蒙蒙,袁莹,周胜利
(浙江警察学院计算机与信息安全系,杭州 310000)
0 引言
由于互联网金融业的快速发展,涉网新型犯罪正逐渐取代传统的犯罪模式成为当前犯罪的主要形式,严重危害了广大人民的生命财产安全。当前尽管国家有关部门从互联网空间治理的角度,采用严防、严打的方式,对涉网新型犯罪的遏制初有成效,但缺少从流量端口对诈骗网站进行动态的检测和预防,对电信网络诈骗犯罪的打击与防范态势依然严峻。开展基于网络行为分析的诈骗网站识别模型研究,能够从涉网新型犯罪的源头出发,打击诈骗活动,预测用户的被害性风险,从而更好地进行预防诈骗等犯罪活动,更好地保护广大人民群众的生命财产安全。
1 相关研究
国内外对电信网络诈骗犯罪识别、防控、预测等已有较多研究。
1.1 用户网络行为分析
在对用户网络行为的分析研究上,传统的网络行为分析方法主要有基于协同过滤的方法[1-2]、基于矩阵分解的方法[3-4]、基于知识图谱[5]等方法。这些方法大多将单独的网络行为作为训练的目标,较为可靠理想,但此类模型缺少考虑连续行为间内在的关联性、结构性信息,难以反映一段时间内用户的连续性、动态性的行为变化,存在局限。近年来随着机器学习尤其是深度学习技术的快速发展,针对连续时间段内的网络行为序列建模问题,较多研究人员建立了基于神经网络的模型来求解。Cheng等[6]提出Wide&Deep模型,将线性模型和深度神经网络(deep neural network,DNN)结合起来,兼顾了模型的泛化能力和记忆性,具有可解释性强、泛化能力强、记忆能力优秀的特点。
Wang等[7]提出基于会话的全局上下文增强的图神经网络推荐模型,在全局层面更好地表征网络行为的特征,并将图论结合进去。此类方法大大提高了模型的准确性和可靠性,能够提取到深层次的网络行为特征,对后续的发展具有重要的借鉴意义。
综上所述,针对传统诈骗网站黑白名单检测方法难以时间滞后性大、检测精确度不足等问题,本文拟提取用户网络数据流中的显性数据特征以及隐性用户网络行为特征,并在BP神经网络模型的基础上,通过结合遗传算法优化参数,建立基于改进BP神经网络的诈骗网站识别模型,最终实现对诈骗网站的动态识别分析。
2 模型设计
2.1 总体架构
本文建立基于遗传算法改进的BP神经网络模型,结构如图1所示。收集用户上网时产生的流量数据作为数据样本,通过编程手段提取流量包中的显性流量特征编码以及隐性网络行为编码作为数据集。使用训练数据集训练BP神经网络并使用遗传算法优化神经网络的相关参数,最终得到最优模型,并投入测试数据集评估模型整体性能。
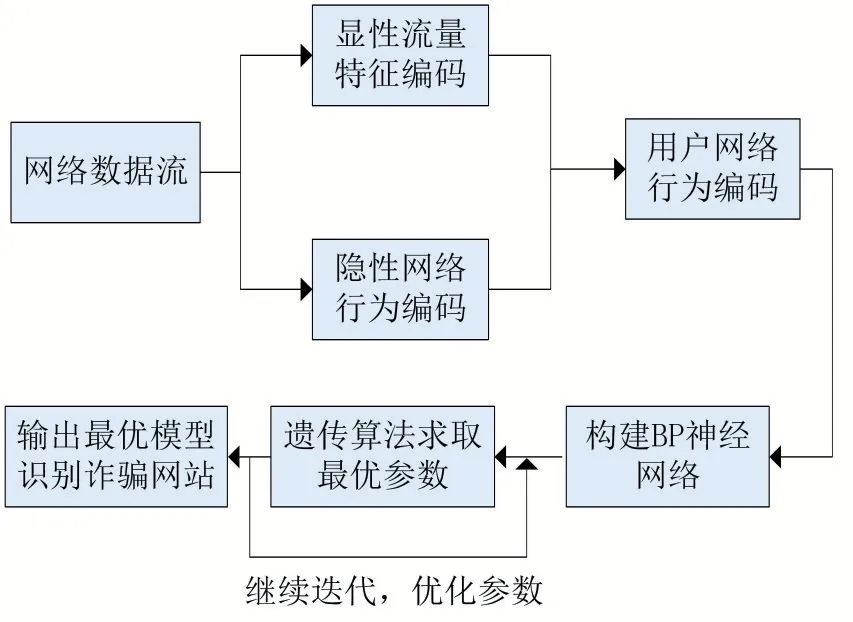
图1 总体结构图
本文基本思路框架如下:
(1)以抓取的流量数据包作为样本数据,并从中提取出显性流量特征编码集以及隐性网络行为编码集,将两者以及网站的诈骗属性人工标定结果汇总,作为训练数据集和测试数据集。
(2)建立BP神经网络模型,投入训练数据集进行训练的同时,结合遗传算法迭代优化参模型参数。
(3)输入测试数据集,测试模型。
2.2 训练测试数据集获取与构建
(1)流量数据获取。采用Wireshark软件动态抓取用户在访问目标网站时产生的各种HTTP数据包,并保存为pcapng文件。
(2)用户网络行为分类。对采集到的pcapng流量数据,分类出数据包中用户存在过的网络行为。网络行为分类主要有:登录、注册、借款、充值、投资等。
(3)数据初始特征挖掘。显性流量特征编码参数如表1所示。

表1 显性流量特征编码参数总表
对获取的流量数据,采用Python的pyshark模块进行解析,提取表1中的初始特征,作为显性流量特征编码集。
(4)网络行为特征挖掘。隐性网络行为编码参数表如表2所示。

表2 隐性网络行为编码参数总表
设计网络行为字典,通过对比字典,标注流量数据中存在的隐性网络行为,最终形成隐性网络行为编码集。
(5)数据集构建。将显性流量特征编码集与隐性网络行为编码集混合,并标注相关网站的诈骗属性,作为样本数据集。并以总样本数的0.7作为训练部分数据来训练模型、优化参数;并以总样本数的0.3作为测试部分数据。
2.3 BP神经网络模型和遗传算法
BP神经网络(back propagation neural network,反向传播神经网络)是一种经典、高效、精度较为理想的神经网络模型,其模型构造主要由输入层、隐藏层、输出层三层组合而成。图2为该模型的拓扑结构:

图2 BP神经网络拓扑结构
BP神经网络主要有存在前向传播和误差反向传播等过程组成,其焦点是利用梯度搜索技术,优化网络中各层级的权重参数,使得实际输出值与预期输出值之间的偏差最小化。设定义实际上的输出层的值与预期中输出层的值之间的误差值为字母E,则E的公式如公式(1)所示。
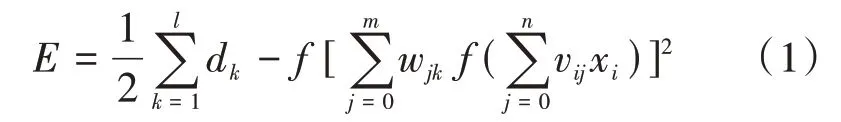
其中f(x)为传递函数Sigmod。图3为该函数的曲线图。w jk、v ij为各层的权值。

图3 传递函数Sigmod曲线图
观察误差E的公式易知,如果想调整并尽可能的缩小误差E,则需要调整输入层、隐藏层、输出层各层的权值,相关公式如公式(2)、(3)所示。
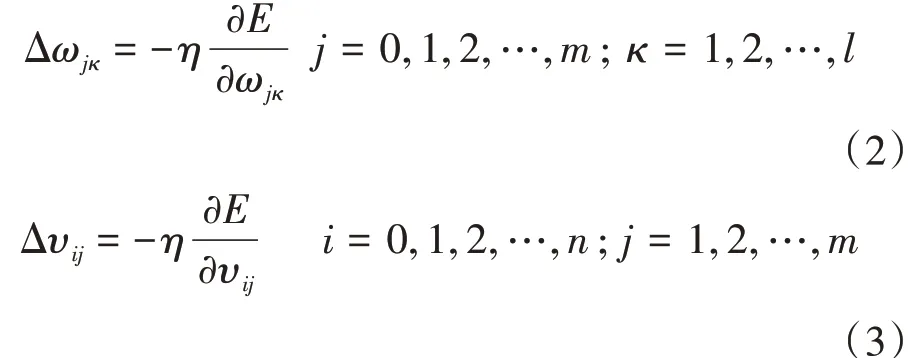
在模型一开始时设置初始权值,并将权值输入遗传算法当中,初始化遗传算法。建立BP神经网络,用训练数据集训练模型,并计算误差值E,调整权值,更新当前最优解。当迭代停止之后,从中将最优权值参数输出,获得整体最佳模型,并投入测试数据集评估模型。
遗传算法结构如图4所示。
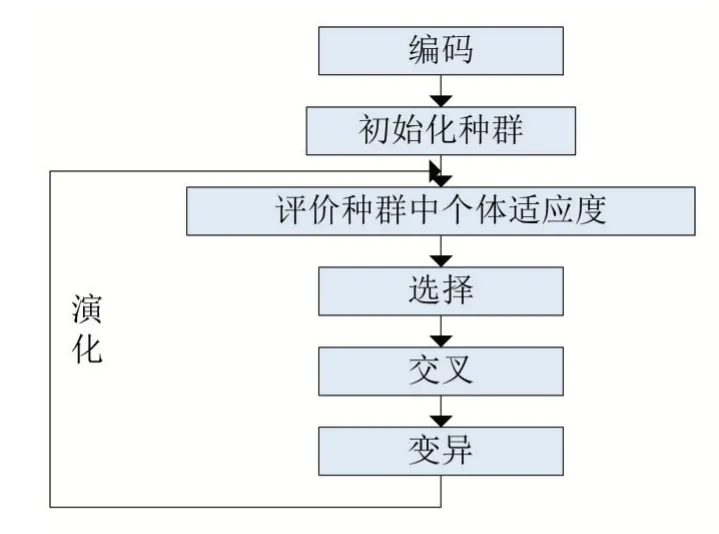
图4 遗传算法结构图
3 实验与分析
3.1 实验训练集与测试集
本实验使用搜集到的用户网络数据流作为样本数据,并从中进行显性流量特征编码,分析并提取隐性网络行为编码,将两个编码集以及手动标注的网站诈骗属性编码集合并,作为总的数据集。总计8676条数据。训练数据集有6073条数据,其中网站的诈骗属性为“TRUE”的有3036条,网站的诈骗属性为“FALSE”的有3037条;测试数据集有2603条数据,其中网站的诈骗属性为“TRUE”的有1301条,网站的诈骗属性为“FALSE”的有1302条。表3为本次实验的具体数据情况。

表3 实验数据情况总表
3.2 实验环境
数据库类型与版本:MySQL 5.7.26。
系统环境:8 GB内存,处理器8个。
操作系统版本:Kali Linux 2021.1。
编程语言环境:Python 3.7.9,g++。
3.3 评价体系
3.3.1 精确率与召回率
公式(4)为精确率P(Precision)的计算公式。其中TP含义是将正类预测为正类的情况,TP含义是将负类预测为正类的情况,FN含义是将正类预测为负类的情况。
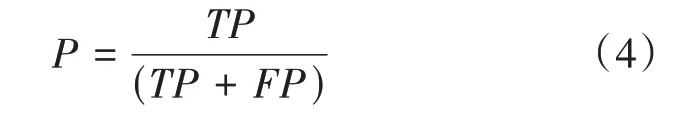
召回率R(Recall)计算公式如公式(5)所示。

3.3.2 ROC曲线
ROC曲线是指以虚报概率P1=y/N为横坐标,以击中概率P2=y/SN为纵坐标,绘制而成的曲线图。若绘制得到的曲线离对角线越近,则说明该模型的识别分类能力比较差,反之,若绘制得到的曲线里对角线比较远,则说明该模型的识别分类能力比较优。
3.4 实验步骤
(1)通过抓包手段获取用户流量数据包,作为样本数据,并将其保存在数据库中。数据情况如图5所示。

图5 流量数据包
(2)编写Python脚本,解析数据包文件,提取显性流量特征编码,如图6所示。
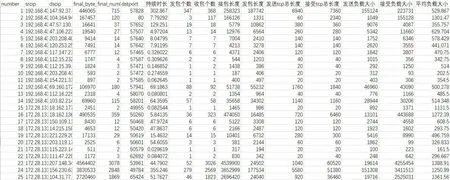
图6 显性流量特征编码图
(3)设计用户网络行为字典,分析并提取隐性网络行为编码,并合并得到训练数据集和测试数据集。隐性网络行为编码情况如图7所示。

图7 隐性网络行为编码图
(4)设置初始阈值,使用训练数据集训练BP神经网络。
(5)初始化遗传算法,并开始迭代更新最优参数。
(6)结束迭代,输出最优模型,并使用测试数据集测试模型。
3.5 实验结果分析
训练BP神经网络模型并采用遗传算法对参数进行不断优化,最终模型的整体精确度为0.954,召回率为0.963。图8为拟合回归的情况,图中拟合优度R=0.97848,说明回归直线的拟合情况整体良好,符合预期。
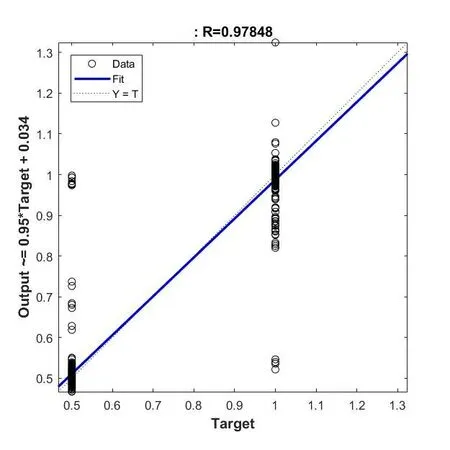
图8 拟合回归图
正态概率图如图9所示。图中蓝色点为样本数据的分布情况。
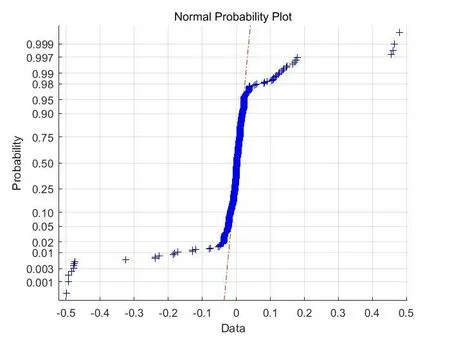
图9 正态概率图
误差变化如图10所示。从图中可知,训练测试过程中误差总体可控,大部分情况下误差变化不大。
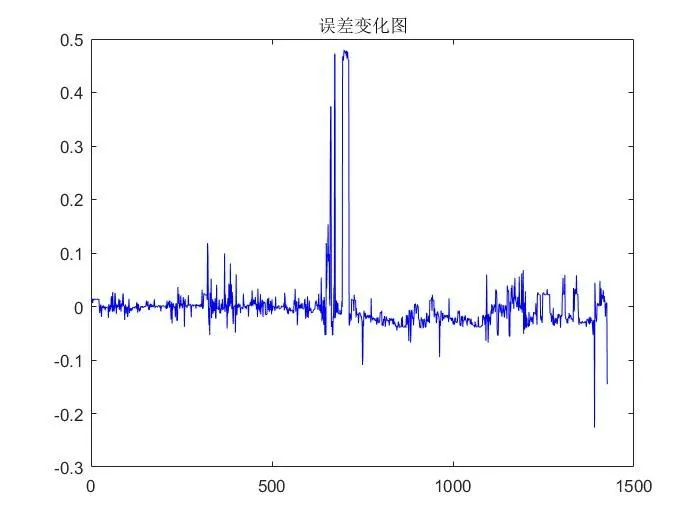
图10 误差变化图
误差相关图、频数直方图、样本偏相关函数如图11~图13所示。

图11 误差相关图

图12 频数直方图
4 结语
本文针对传统诈骗网站识别与预防技术存在的时间滞后性严重、精确度不足、模型开销过大的问题,提出基于网络行为的诈骗网站识别模型,从流量数据中分析并挖掘显隐性网络行为编码,建立了遗传算法优化的BP神经网络模型,实现了识别、分析网站诈骗属性的功能和目的。模型可以从动态的流量数据中有效识别出诈骗网站。下一步的研究将聚焦于时序网络行为的分析预测方向,实现对用户诈骗被害性风险的动态识别,并提高模型鲁棒性,从电信网络诈骗犯罪受害端进行预防和发掘。
