一种随机配置网络的模型与数据混合并行学习方法
2021-12-01李德鹏杨春雨马小平
代 伟 李德鹏 杨春雨 马小平
信息技术的迅速发展使得生产制造行业进入大数据时代,这为数据建模提供了大量的数据样本,使得数据驱动建模在不同领域产生广阔的应用空间[1−3].然而,系统复杂度和数据规模的日益增大为数据建模算法带来新的挑战.模型精度取决于样本的质量与数量,但超过一定规模的样本数据,会显著增加网络参数训练与优化的成本,且难以有效学习,导致模型的整体性能下降[4].在采用传统神经网络算法进行大数据建模时,所得到的模型往往存在训练耗时、网络结构复杂等问题,难以满足实际应用的需求.因此,建立一种能够从大量数据中快速、高效学习的策略具有重要意义.
上世纪90 年代,文献[5]提出的随机向量函数链接网络,与文献[6]提出的另一种具有随机权值的单层前馈神经网络等被统称为随机权神经网络(Random weight neural networks,RWNNs)[7−8].其特征在于隐含层参数(输入权值和偏置)在给定的区间内随机产生,只需解析求解网络输出权值.因RWNNs 实现简单、建模速度快等优势受到了广泛的关注.文献[9]设计了一种二维RWNNs 分类器,用于人脸识别,其使用两组输入权值直接以特征矩阵作为输入而不用转换成向量形式,能够有效保留图像数据的空间信息,具有良好的分类性能.文献[10]将非参数的核密度估计方法与加权最小二乘估计引入到RWNNs 的学习算法,通过评估每个训练样本对于建模的贡献度来抑制噪声数据或离群点的负面影响,从而建立了鲁棒RWNN 以及在线学习算法.在此基础上,文献[11]进一步引入正则项来防止过拟合现象,有效减小输出权值,在一定程度上降低了模型复杂度.然而,两个本质缺陷使得RWNNs的应用受到一定的限制:1)隐含层节点数不能先于训练而确定,即难以设定合适的网络结构;2)隐含层参数在固定不变的区间内产生,影响其实际逼近特性[12−13].
为了解决上述问题,Wang 等首次提出了一种随机增量学习技术,即随机配置网络(Stochastic configuration networks,SCNs)[14].SCNs 在一个可调区间内随机分配隐含层参数,并创新性地引入监督机制加以约束,确保了其无限逼近特性.作为一种增量学习算法,SCNs 在每次的增量学习过程中,均建立候选“节点池”以选出最佳节点,加快了收敛速度;同时,网络结构也可在增量学习过程中确定.针对SCNs 监督机制中关键参数的选择问题,文献[15]指导性地给出了两种不等式约束,从而提高了随机参数配置的效率,有助于候选“节点池”的建立.文献[16]以SCNs 作为基模型,采用负相关学习策略来配置输出权值,提出了一种快速解除相关异构神经元的集成学习方法.文献[17]针对隐含层输出矩阵可能存在的多重共线性等不适定情况,在计算输出权值时采用截断奇异值分解对重新构建的输出矩阵进行广义逆运算,建立了TSVD-SCN 模型.文献[18]通过引入正则化技术,进一步提升SCNs 的泛化性能.文献[19] 通过理论分析和算法实现将SCNs 推广到深度结构,即DeepSCNs.结果表明,相比其他深度神经网络,DeepSCNs 可以快速有效地生成,且学习特性和泛化性能之间具有一致性.此外,文献[20]和[21]分别提出了两种不同的鲁棒SCNs 算法用于受污染数据的建模问题.
然而,现有的SCNs 及其相关算法均采用点增量的构建方式.在大数据建模任务中,往往需要大量的迭代和耗时的伪逆运算.为解决采用传统计算方式将产生过大计算损耗的问题,本文研究SCNs并行学习方法,以提高SCNs 在大数据应用中的效率.
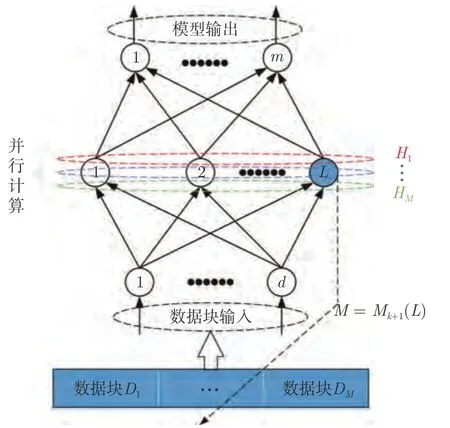
现有面向大数据的神经网络并行建模的研究成果可分为数据或者模型并行两类[22−24].数据并行是将数据集分成若干数据块以同时处理,模型并行是将参数进行并行划分以同时求解.本文针对SCNs增量学习过程中网络结构动态变化的特点,提出一种新颖的模型与数据混合并行的增量学习方法.主要贡献在于:将点增量和块增量两种增量模型构建方法进行并行,左侧为点增量SCN (PSCN),右侧为块增量SCN (BSCN).其中,PSCN 每次迭代隐含层节点单个增加,以准确地找到最佳网络结构,BSCN 每次迭代隐含层节点按块添加,具有较快的收敛速度.同时针对样本数据维数高、数据量大导致的计算耗时问题,采用一种基于动态分块策略的数据并行方法,其在增量学习过程的不同阶段,根据当前节点数将训练数据划分为不同的数据块,从而采用并行计算方式,同步进行运算;然后,在PSCN 与BSCN 计算输出权值时整合数据块,并通过比较残差,择优选取模型参数.对所形成的混合并行随机配置网络(Hybrid parallel stochastic configuration networks,HPSCNs)进行对比实验,结果表明,其具有资源利用率高、建模速度快、网络模型紧致等优点.
1 增量式随机权网络
1.1传统RWNNs
对于给定的N组训练集样本 (xi,ti),其输入X={x1,x2,···,xN},xi={xi,1,···,xi,d}∈Rd,相应的输出T={t1,t2,···,tN},ti={ti,1,···,ti,m}∈Rm.其中i=1,2,···,N.具有L个隐含层节点的RWNNs 模型可以表示为:
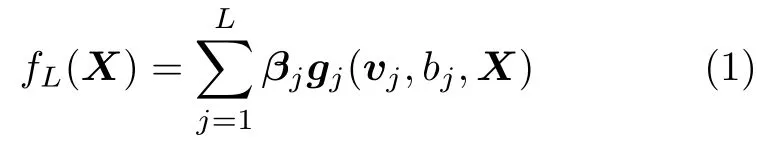
其中,gj(·)表示隐含层第j个节点的激活函数,隐含层参数(vj和bj) 分别在区间[−λ,λ]d和[−λ,λ]随机生成,βj=[βj,1,···,βj,q,···,βj,m]T为隐含层第j个节点与m个输出节点之间的输出权值,fL即当前网络的输出.模型参数可以通过求解如下的二次型优化问题获得.

上述等式可以进一步表示为矩阵形式:
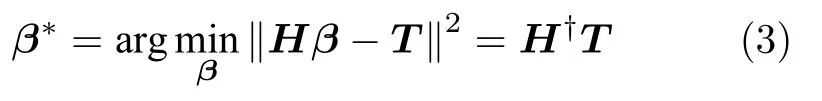
其中
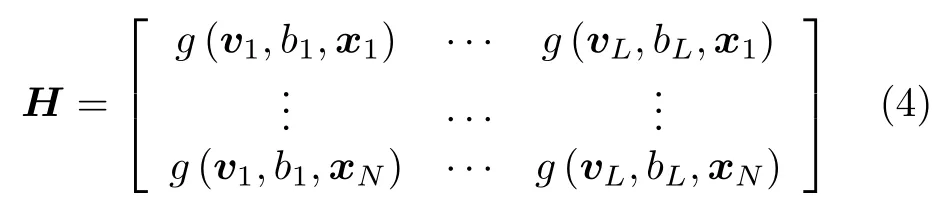
为隐含层输出矩阵,H†为其Moore-Penrose 广义逆[25].
通常,传统RWNNs 所需要的节点数往往只能针对特定建模任务采用交叉验证法确定,实验过程耗时,且网络结构的确定取决于交叉验证时所选择的参数.
1.2 增量构造学习算法
增量构造学习算法是解决网络结构的一种有效方法,从随机产生第一个节点g1=g(v1,b1,x) 开始,向网络中逐渐增加节点;相应地,输出权值为β1=〈e0,g1〉/‖g1‖2,其中e0=f;更新e1=f−β1g1[12].通过重复上述过程可以同时解决网络结构和参数优化问题,增量RWNNs 的构造过程如下.
首先,设定增量学习的期望精度,其输出fL可以表示为先前网络fL−1与新增节点gL(vL和bL)的特定组合,即:

其中,新增节点的输出权值依据下式

且先前网络的残差

增量RWNNs 虽然解决了传统RWNNs 难以确定网络结构的问题,但网络的输入权值和偏置通常选择在固定区间(如[−1,1])内产生,这种与样本数据无关的参数设定方式导致RWNNs 的逼近特性具有不确定性.因此,随机参数的产生应该依赖于建模数据并加以约束.
2 混合并行增量学习方法
SCNs 作为一种先进的随机学习技术,其本质特征在于随机产生的输入权值和偏置需要满足监督机制,并采用数据依赖策略动态调整随机区间,有效解决了RWNNs 及其增量构造学习算法的本质缺陷.然而,传统SCNs 均是采用点增量的方式来构建网络(PSCN),即一次迭代过程只能添加一个节点.采用这种方法,每一个新增节点都需要重新建模,当所需节点数较多时,网络的构建就会变得相对复杂、耗时.从特征学习的角度来说,前馈神经网络从输入样本空间去逼近复杂非线性函数的能力很大程度上取决于隐含层的特征映射,即从低维输入数据到高维特征空间.而节点可以被认为是高维空间的特征.那么,每次只增加一个节点则在很大程度上限制了特征的获取.因此,使用点增量方法构建SCNs 的过程往往需要较多的迭代,不可避免地增加了计算量、影响了建模效率.鉴于此,我们最近的工作[26]将传统点增量SCNs 推广为允许同时添加多个隐含层节点(节点块)的块增量网络(BSCN),用于加快构建过程.
点增量与块增量算法分别具有网络结构紧致但收敛速度慢和收敛速度快但模型不紧致的特点.为了进一步提高算法的综合性能,本文对传统SCNs进行改进,提出了一种新的混合并行增量学习方法,即:HPSCNs,以应对大数据建模.主要思想是:在同一个建模任务中,使用点和块两种增量构建模型方法进行并行学习,且在学习过程中将样本数据随学习过程动态划分为多个数据块,从而采用并行计算择优选取模型参数.
2.1 模型并行策略
HPSCNs 由PSCN 和BSCN 组成,以单输出为例,其模型并行结构如图1 所示.这里添加节点的过程被称为迭代.在训练过程中,PSCN 的构建方式采用点增量方法(隐含层节点每次迭代单个增加),从而保证相对准确地找到最佳隐含层节点;BSCN 的构建方式采用块增量方法(隐含层节点每次迭代按块添加),以提高模型的收敛速度.
该策略采用平行网络并行计算.即在增量学习过程中,平行的PSCN 与BSCN 通过并行计算被独立地构建;每次迭代结束后,以当前网络残差为指标,保留其中较优的网络,并将其模型参数作为本次迭代的最终结果;同时将该结果赋值给另一个网络以更新其节点数,然后进行下一次迭代.
2.1.1 PSCN
图1 所示的模型并行增量学习方法,左侧采用传统点增量随机配置网络PSCN,其学习过程约束根据引理1 获得.

图1 模型并行结构图Fig.1 The structure diagram of model parallelism
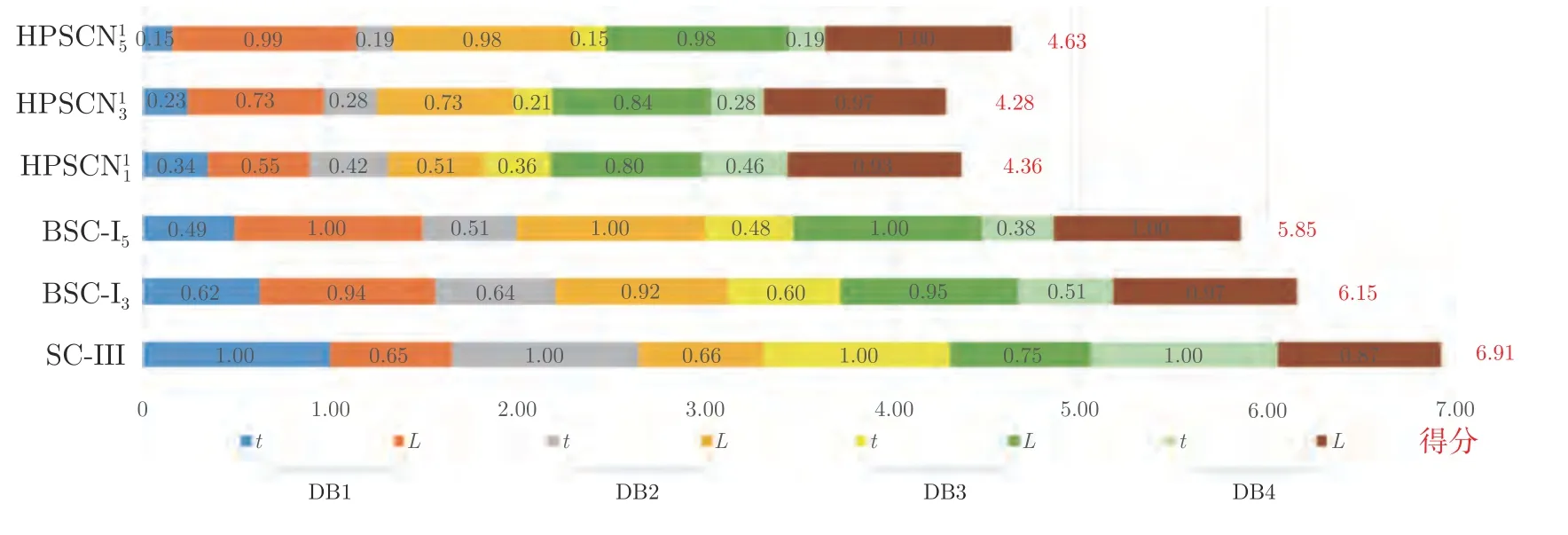
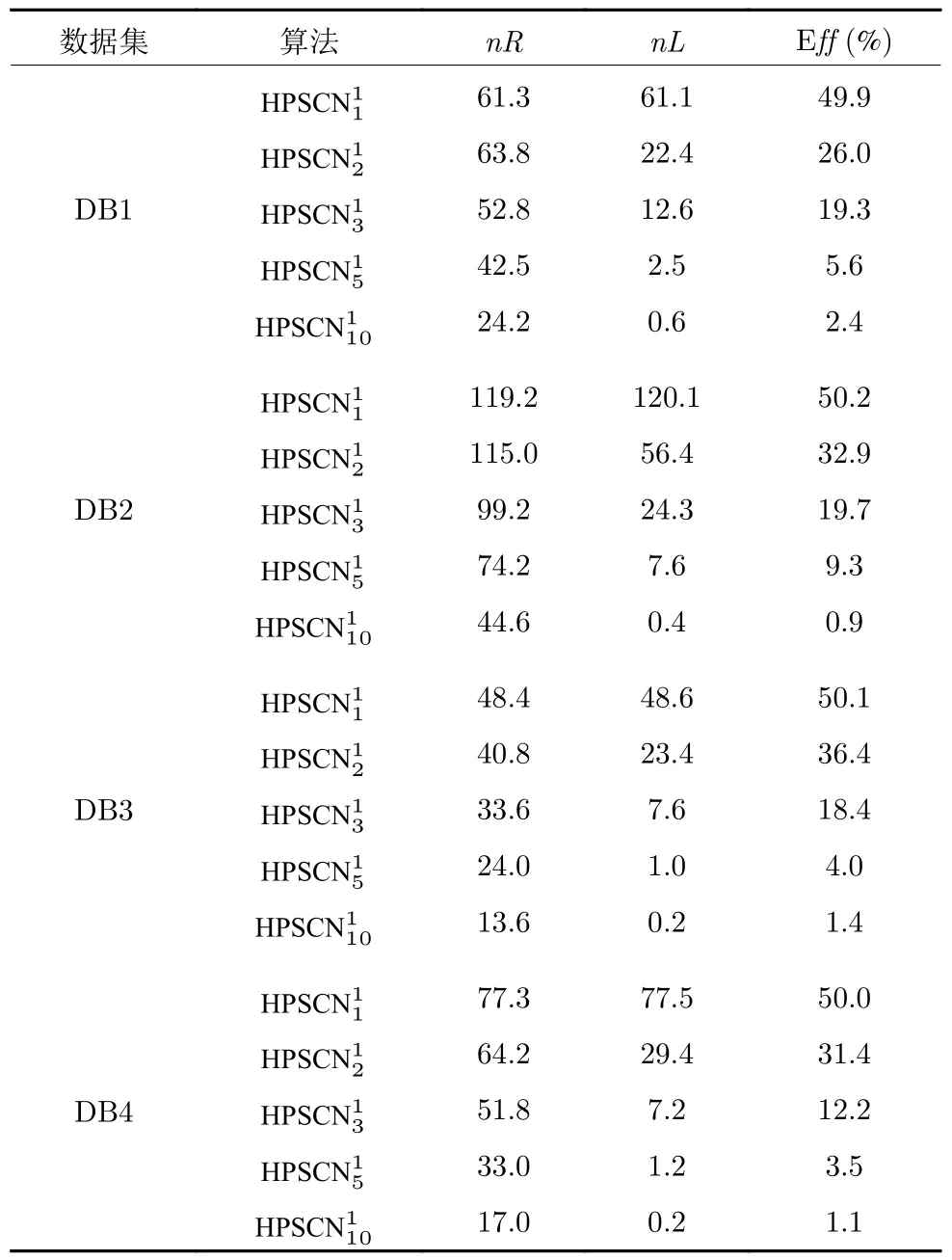
引理 1[14].令 Γ:={g1,g2,g3,···}表示一组实值函数,span(Γ)表示由 Γ组成的函数空间.假设span(Γ)稠密于L2空间且∀g ∈Γ ,0<‖g‖ 若激活函数gL满足下列不等式约束: 并且输出权值通过式(3) 计算,那么limL→∞‖f−fL‖=0恒成立. 在上述定理中,将式(8)代入(9),可以得到点增量学习的监督机制: 其中,q=1,2,···,m,µL=(1−r)/(L+1). 网络构建过程简述如下: 1) 在可调区间内随机产生隐含层参数 (vL和bL). 将满足式(10)的节点作为候选节点,并保留最大的ξL,q所对应的随机参数; 2) 输出权值β通过公式(3)求解全局最小二乘得到; 3) 计算PSCN 当前训练残差eL,判断是否满足 停止条件. 2.1.2 BSCN 按照块增量方法,将引理1 进行推广,有如下引理2. 引理 2[26].给定 0 那么 limL→∞‖f−‖=0恒成立.其中块宽∆k表示第k次迭代中新加入的节点块;表示第k−1次迭代结束时的训练残差;表示第k次迭代时的隐含层输出块;且 表示第k次迭代中的输出权值的中值. BSCN 的增量学习过程在PSCN 的基础上,根据式(11)在可调区间内随机产生新增节点块(和),从而实现了批量分配隐含层参数和按块增加隐含层节点. 2.1.3 收敛性分析 模型并行增量学习过程当前网络节点数为L时,令新增节点数为l∈{1,∆k}有: 1) 点增量 (l=1) 时: 2) 块增量(l=∆k)时: 由以上分析可知,式(13)‖eL+l‖−(r+µL+l)‖eL‖2≤0,残差序列‖eL+l‖单调递减且有界.进一步地, 注意到 limL→∞µL+l‖eL‖2=0 ,其中limL→∞µL+l=0.根据式(16)可以进一步得到limL→∞‖eL+l‖2=0,即 limL→∞‖eL+l‖=0.因此残差序列‖eL+l‖单调递减且收敛于0,说明本文所提HPSCNs 模型具有无限逼近特性. 在增量学习过程中,将数据进行分块处理,以建立一种数据并行计算策略,可进一步提高学习速度.因此,将训练输入样本X、训练输出样本T等分为M块,即 每个数据块的隐含层输出矩阵通过并行计算获得,第p个数据块与隐含层输出矩阵的对应关系: 这里gp,L表示节点数为L时第p个数据块的隐含层输出.此时,PSCN 的监督机制为: 相应地,BSCN 的监督机制为: 表示第k次迭代时输出权值的中值. 根据不同数据规模的学习任务,输出权值β可由下式计算获得: 对于大数据建模,这里只考虑N ≥L的情况,因此,数据并行学习方法中的输出权值可以表示为: 式(23)将不同数据块整合并得到输出权值. 注意到,随着学习过程中隐含层节点数的增加,网络尺寸逐渐增大,计算负荷也随之增加,因此,在增量学习过程的不同阶段,本文采用动态分块策略,逐渐增加数据块数量,以充分利用并行计算资源,提高学习的效率.所形成的数据并行策略如图2 所示,其中从隐含层到输入层的连接起到反馈作用,实现数据块M随学习过程中隐含层节点数L的增加而变化,具体动态分块方法如下: 图2 数据并行策略Fig.2 Strategy of data parallelism 注1.HPSCNs 继承了原始SCNs 自组织学习的特点,其隐含层节点在监督机制下自主构建,无需采用传统自组织学习的剪枝等算法即可保证模型的紧致性.此外,HPSCNs 中PSCN 和BSCN 的监督机制分别不同于传统SCNs 和块增量SCNs.以PSCN 为例,若根据M个不同的数据块同步获取一组隐含层输出g1,L,···,gp,L,···,gM,L后,直接带入SCNs 中得到M组满足条件的不等式约束,尽管该网络仍具有无限逼近特性,但收敛性会变差.这是因为监督机制的数据依赖特性.每组监督机制只包含当前数据块的信息而忽略了其他数据块,不可避免地放宽了约束的作用,导致所得到的输入权值和偏置"质量"变低,从而影响到模型收敛性.因此,隐含层参数的分配需要考虑全体数据块. 注2.RWNNs 与SCNs 均直接使用式(3)求解输出权值,导致广义逆运算成为构建过程中较为耗时环节,尤其针对大数据建模,即N >>L的情况,则需要对N ×L阶的矩阵进行广义逆运算;而基于数据并行采用式(23),则只需要计算L×L阶矩阵的广义逆,大大降低了计算量. 混合并行增量学习算法的具体实现描述如下: 给定训练输入X∈RN×d,输出T∈RN×m.设置增量构建过程中的容忍误差ε和最大迭代次数kmax;隐含层参数分配区间集Υ={λ1,λ2,···,λend};最大随机配置次数Tmax;BSCN 中的块宽 ∆k等. 步骤1.初始化训练集数据分块数M=M1; 步骤2.开始模型与数据并行学习; PSCN: 1) 在区间 [−λi,λi]d和 [−λi,λi] 内随机生成隐含层参数vL和bL,λi∈Υ,i=1,2,···,end; 2) 使用不同数据块同步获取PSCN 的隐含层输出g1,L,···,gp,L,···,gM,L; 3) 根据式(19)建立候选“节点池”,并找出使得ξL,q最大的随机参数和 4) 根据式(23)整合数据块并评估PSCN的输出权值. BSCN: 1) 在区间 [−λi,λi]∆k×d和 [−λi,λi]∆k×1内随机生成隐含层参数v∆k和b∆k,λi∈Υ,i=1,2,···,end; 2) 使用不同数据块同步获取BSCN 的隐含层输出块h1,k,···,hp,k,···,hM,k; 3) 根据式(20)建立候选“节点池”,并找出使得ξL,q最大的随机参数和 4) 根据式(23)整合数据块并评估BSCN 的输出权值. 步骤3.计算PSCN 和BSCN 的训练残差; 步骤4.通过比较残差择优选取模型参数并用于更新另一个模型的隐含层节点数L; 步骤5.更新下一次迭代中训练数据的分块数M=Mk+1(L); 步骤6.重复上述步骤,直至模型达到停止标准; 步骤7.返回最终模型参数v∗,b∗和β∗. 注3.神经网络的模型精度会随隐含层节点数的增加而逐渐提高,但当节点数过多时会使训练误差变小而测试误差增大,即过拟合现象.本文所提方法达到停止条件时立即结束迭代,不再继续增加隐含层节点,在一定程度上避免了过拟合现象. 注4.为尽可能地提高学习效率,需要多次随机配置隐含层参数,以建立候选"节点池",从而寻找出最佳的隐含层节点.Tmax决定着随机配置隐含层参数的次数,过大增加计算损耗、过小不利于候选“节点池”的建立[14].此外,隐含层参数分配区间集Υ={λ1,λ2,···,λend}可设置从λ1到λend逐渐增长,学习过程从λ1开始逐次选择.以PSCN 为例:首先在[−λ1,λ1]d和[−λ1,λ1]内随机生成Tmax组隐含层参数vL和bL,并从后续所建立的候选"节点池"中找出最佳的一组随机参数和;若候选"节点池"为空,则从参数集Υ中选择λ2,调节分配区间,进而重复上述步骤. 本文选取收敛性和紧致性作为衡量模型质量的评价指标.其中收敛性在数值上表现为残差序列的递减程度,可采用达到期望容忍误差时的学习时间来衡量,收敛性好有利于建模的快速性.紧致性表现为网络尺寸,可采用达到期望容忍误差时的隐含层节点数来度量,模型不紧致往往包含不必要的冗余节点,不利于泛化性能,且会显著增加计算空间和硬件实现的成本.此外,采用均方根误差(Root mean squares error,RMSE)计算建模精度,均值(Mean)和标准差(Standard deviation,Std)则分别用来反映模型性能的平均值和离散程度. 为验证本文所提混合并行增量学习模型的有效性,将传统SCNs (SC-III)[14]、块增量SCNs (BSCI)[26]和混合并行随机配置网络(HPSCNs)分别对大数据建模并根据评价指标进行性能评估.仿真实验在MATLAB 2016a 环境下运行,所用PC 的CPU为i5,3.4 GHz,内存为16 GB RAM. 4 个不同领域的基准数据:DB1 (SGEMM GPU Kernel Performance Data Set)、DB2 (Electrical Grid Stability Simulated Data Set)、DB3(Mv Data Set) 和DB4 (Pole Telecommunications Data Set)来自UCI (University of California at Irvine)[27]和KEEL (Knowledge Extraction based on Evolutionary Learning)[28]. 所选数据集信息见表1.针对每个大规模数据,我们随机选取80 %的样本作为训练集,余下的20 %作为测试集. 表1 基准数据集说明Table 1 Specification of benchmark data sets 在数据预处理阶段,输入输出样本均被归一化至[−1,1].实验参数设定如下: 最大迭代次数kmax=300; 最大随机配置次数Tmax=10; 随机参数范围λ∈{1,10,50,100,150,200}; 学习参数r∈{0.9,0.99,0.999,···}; 容忍误差ε=0.1(DB1 和DB2),ε=0.01(DB3 和DB4); 不同BSCN 每次迭代的块宽分别取固定值∆k=1、3、5; 大规模训练集分块基数M0=4,第k次迭代时分块数递增区间长度取50,100,150,···,具体对应关系见表2. 表2 分块数递增区间长度及其上下界Table 2 Incremental interval length of block number and its upper and lower bounds 因此,根据式(24)可得 为了便于描述,本文以下标的形式表示BSC-I算法中的块宽,以上下标的形式分别表示HPSCNs中左侧随机配置网络PSCN 和右侧随机配置网络BSCN 的块宽.如BSC-I3表示其每次迭代添加3个隐含层节点;表示本文所提方法中PSCN每次迭代添加1 个隐含层节点,而BSCN 每次迭代添加3 个隐含层节点.需要指出的是,点增量构建方式是块增量中 ∆k取1 的特例. 表3 记录了不同算法50 次独立实验结果的均值和标准差(Mean±Std).通过比较SC-III、BSC-I3和BSC-I5可以看出,随着块宽∆k取值的增加,达到期望容忍误差ε时所需要的迭代次数k明显降低,建模时间t显著减少,即块增量的构建方式可以有效加快传统SCNs 的收敛速度;然而,块增量SCNs 需要更多的节点数L,导致网络复杂度增加,不利于模型泛化性能.这是因为从特征学习的角度来说,残差序列单调递减,尚未学习的特征也会随着增量学习的过程减少,然而BSC-I3和BSC-I5在每次迭代中采用固定的块宽,不可避免地导致了特征(节点)的冗余.尤其在构建过程后期,每次迭代中节点块对于建模的贡献近似于单个节点,却徒增了网络复杂度.因此,块增量SCNs 是一种以牺牲模型紧致性为代价的极速建模方法. 表3 不同算法性能比较Table 3 Performance comparison of different algorithms 1)数据并行通过使用动态分块策略并同步获取隐含层输出,加快了候选“节点池”的建立;同时,针对大数据本文所提方法采用式(23)整合数据块并计算输出权值,在很大程度上降低了广义逆运算负担; 2)模型并行通过单次迭代中PSCN 与BSCN独立地同步建模,完成当前迭代后选择获得残差较小的模型参数.其中,HPSCNs 中的BSCN 采用块增量的构建方式,具有较快的收敛性;PSCN 采用点增量的构建方式,从而准确地找到最佳隐含层节点数.模型并行增量学习也有效减少了迭代次数. 为了评估模型的综合性能,图3 给出不同算法对数据集DB1-DB4 的建模时间(t)和隐含层节点数(L).其中,t和L均归一化处理至[0,1],并表示对应性能指标的得分情况.如:在DB1 建模任务中,SC-III 相比其他算法用时最长,其t对应的得分为1、BSC−I5所需节点数最多,其L对应的得分为1.显然,分数越低,性能越好.因此,由图3 可以看出,本文所提混合并行增量学习方法具有较好的综合性能,且最佳. 图3 不同算法综合性能比较Fig.3 Comparison of comprehensive performance of different algorithms 其中nL和nR分别表示每次迭代PSCN 和BSCN贡献最佳模型参数的次数,则Eff正比于nL. 表4 记录了HPSCNs 中BSCN 选择不同块宽∆k时的模型并行情况.可以看出,对于DB1-DB4,随着 ∆k的增加,Eff的数值越来越小,如∆k=10时,的Eff最低,此时PSCN 基本上失去了其在模型并行中的作用.因此,考虑模型的综合性能,使用HPSCNs 进行大数据建模时,其BSCN的块宽建议取 ∆k∈{1,2,3}. 表4 不同块宽的算法性能比较Table 4 Performance comparison of algorithms with different block sizes 将所提方法应用在典型一段磨矿过程,建立以磨机给矿量、磨机入口给水量和分级机溢流质量浓度为输入,以磨矿粒度为输出的软测量模型.从磨矿半实物仿真平台[29]中采集20 000 训练样本和5 000 测试样本,设置容忍误差ε=0.05,块宽∆k=3,其余实验参数设定同比较实验部分. 图4 和图5 分别为基于HPSCNs 的磨矿粒度软测量模型的收敛特性和逼近特性.由图4 可以看出,在训练过程中所提方法具有较好的收敛效果,且在接近容忍误差前残差序列能够快速下降.为了便于观察,这里仅取500 个测试数据的逼近效果(如图5 所示),从中可以看出模型输出与真实值基本吻合,可以实现磨矿粒度的准确估计. 图4 模型的收敛曲线Fig.4 Convergence curve of HPSCNs 此外,从图5 可知,所建立磨矿粒度软测量模型在达到期望精度时,建模时间较快,网络结构简单,具有良好的泛化性能;Eff=25.0 %,其中左侧点增量网络(PSCN)、右侧块增量网络(BSCN)贡献最佳模型参数的次数分别为3 和9,说明模型具有较高的有效性.需要指出的是,上述矿粒度软测量模型是通过输入特性维数较少的样本建立的,本文所提方法应用到其他数据维数较多的工业案例中,将会取得更好的优势.同时在多维大数据应用时,还可以考虑并行节点池构建策略,以提高学习速度. 图5 模型的逼近特性Fig.5 Approximation performance of HPSCNs 本文基于随机配置网络提出了一种模型与数据混合并行的增量学习方法.实际数据仿真研究表明:与传统SCNs 和块增量SCNs 相比,本文所提方法大大降低了计算量,提高了资源利用率,所建立模型综合性能好,且利于硬件实现,具有良好的实用价值.然而,HPSCNs 直接根据PSCN 和BSCN 的残差选择新增节点,在BSCN 获得残差优势不明显的情况下,选择了增加节点块构建模型,不利于模型紧致性.下一步的研究目标是进一步提高算法的综合性能,如针对HPSCNs 模型的有效性,建立新的模型参数交互准则;在保留块增量SCNs 极速建模优势的情况下,削减其中的冗余隐含层节点.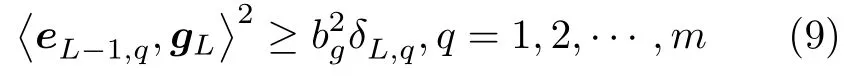
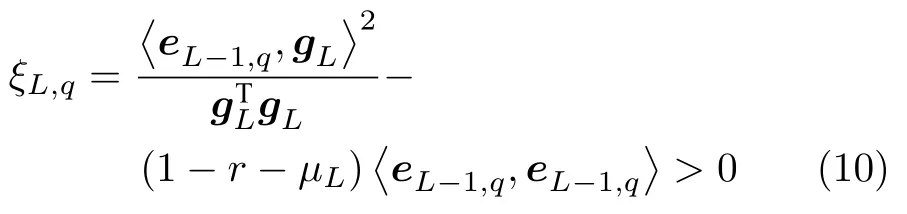
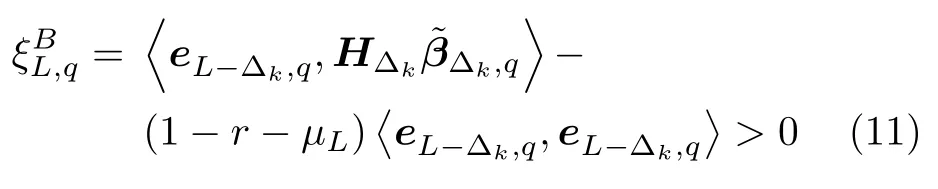
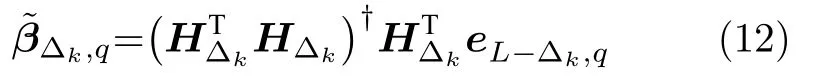
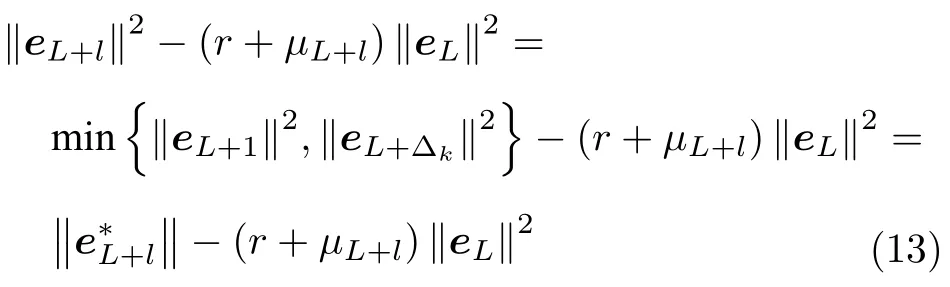


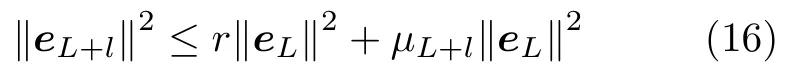
2.2 数据并行策略
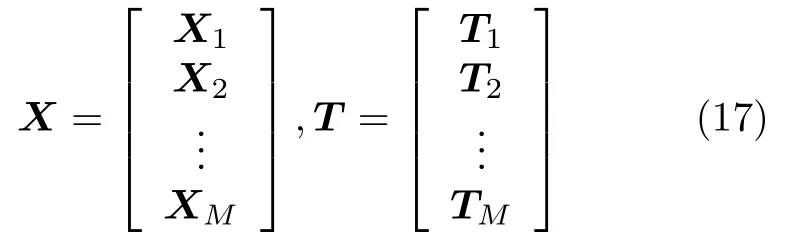

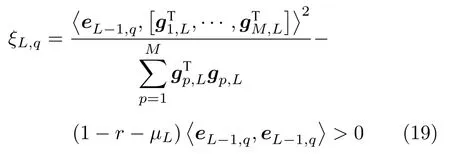


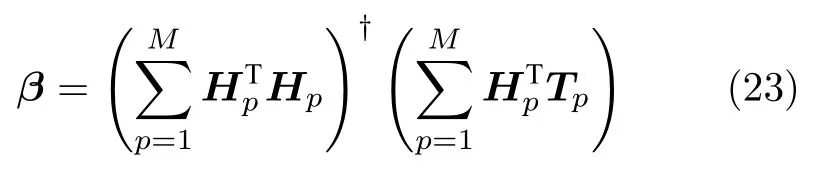

2.3 HPSCNs 实现步骤
3 性能评估
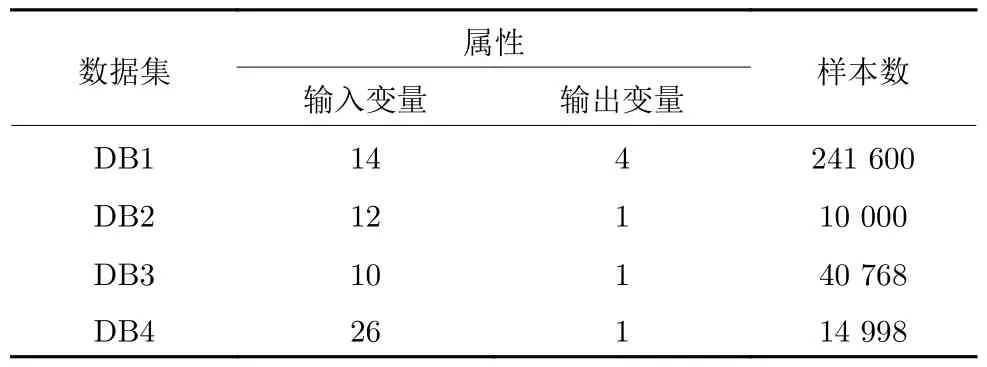
3.1 建模数据
3.2 比较实验

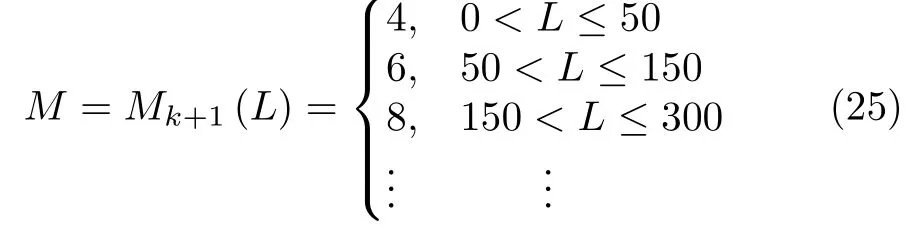

3.3 参数讨论与选择

3.4 工业案例


4 结语
