基于关系指数和表示学习的领域集成实体链接
2021-12-01蒋胜臣王红斌余正涛线岩团王红涛
蒋胜臣 王红斌 余正涛 线岩团 王红涛
实体链接是指将文本中存在歧义的实体正确链接到知识库中无歧义的候选实体的过程[1−2],实体链接的相关研究有助于知识库的自动填充[3],也有助于信息检索的研究[4],同时实体链接与跨文本指代消解、词义消岐,实体消岐等诸多自然语言研究领域有着紧密联系.目前关于实体链接的研究方法,主要思想是通过计算实体指称项与其候选实体的多种特征相似度,选择知识库中无歧义实体进行链接.早期研究以单实体为对象,Bunescu[5]和 Ganea等[6]使用词袋模型计算指称项与候选实体的相似度,选取相似度最高的候选实体作为目标实体;Cucerzan[7]和Nguyen 等[8]通过维基百科页面锚文本、重定向页面等信息计算指称项与候选实体的相似度;Zeng[9]利用第三方知识库对候选实体特征进行扩充使得实体链接准确率提高.以单实体为对象的实体链接方法忽略了文本中共现实体间的语义关系,并且计算效率不高.针对以上问题,研究者们结合已有知识库中存在的信息,提出以集成实体作为对象进行实体链接的集成实体链接方法.Han 等[10]通过构建候选实体语义相关图进行集成实体链接;Liu 等[11]提出基于图的集成实体链接方法,以实体指称项和候选实体作为顶点构建有向图,通过计算出入度和语义相似度进行集成实体链接;Ferragina 等[12]引入了概率化链接的思想,提出了一个面向短文本的集成实体链接算法.这些研究在一定程度弥补了单实体链接忽视共现实体间语义相关性的不足,但是却在一定程度上忽略了指称项本身具有的文本特征,对文本信息利用率不高.
近些年随着深度学习在自然语言中的应用,利用表示学习计算语义相似度成为一种新的思路[13−14].随着Bengio 等[15]提出表示学习模型,通过表示学习表征实体深层语义信息计算相似度成为实体链接任务的新趋势[16−17].Mikolov 等[18]和Goldberg[19]对向量空间中词表示的有效嵌入进行了评估;Kar 等[20]将表示学习用于特定任务领域的实体消歧;Moreno等[21]等通过扩充锚文本对文本中的单词和知识库中的实体进行联合学习得到相应的向量表示形式,从而进行实体链接.
以上研究都是在通用领域,其有丰富的通用语料和消歧特征[22];而对于特定领域,往往存在语料不足,另外流行度等消歧特征不明显的问题,针对这些问题,本文提出了一种新的基于关系指数和表示学习的领域集成实体链接方法.首先,构建特定领域知识库,以作为实体链接的基础;其次,通过LDA主题模型、word2vec 模型和TransE 模型训练本文收集到的背景语料和特定领域知识库中的三元组,得到蕴含知识和主题信息的实体指称项和候选实体的向量表示;再利用得到的向量表示和LDA 主题模型抽取实体指称项所在主题的领域关键词;然后,结合词扩展,得到实体指称项的扩展词;再利用得到的特征,计算指称项与候选实体的上下文、领域关键字、扩展词三种特征相似度;同时利用知识库中丰富的关系信息,得到候选实体的关系指数;最后,将三种特征相似度和关系指数相融合,得到最后的相似度.本文的主要贡献主要有:1)利用表示学习,同时将文本词向量表示和知识库的知识表示嵌入到同一个语义空间,融合了文本信息和知识库信息;2)收集了语料,获取了特定领域相关知识,构建了特定领域知识库;3)将关系属性融入到实体链接 中,实现了实体的语义属性和关系属性的融合.
1 研究方法
本文提出的方法具体步骤是:首先,构建特定领域知识库,以作为实体链接的基础;其次,通过LDA 主题模型、word2vec 模型和TransE 模型训练本文收集到的背景语料和特定领域知识库中的三元组,得到蕴含知识信息和主题信息的实体指称项和候选实体的向量表示;再利用得到的向量表示和LDA 主题模型抽取实体指称项所在主题的领域关键词;其次,结合词扩展,得到实体指称项的扩展词;然后,利用得到的特征,计算指称项与候选实体的上下文、领域关键字、扩展词三种特征相似度;同时利用知识库中丰富的关系信息,得到候选实体的关系指数;最后,将三种特征相似度和关系指数相融合,得到最终相似度.将相似度最高的候选实体作为最终链接对象.
本文方法包括5 部分:特定领域知识库构建、融合知识和主题信息的词向量训练、候选实体的生成、多特征生成、实体链接.如图1 所示.
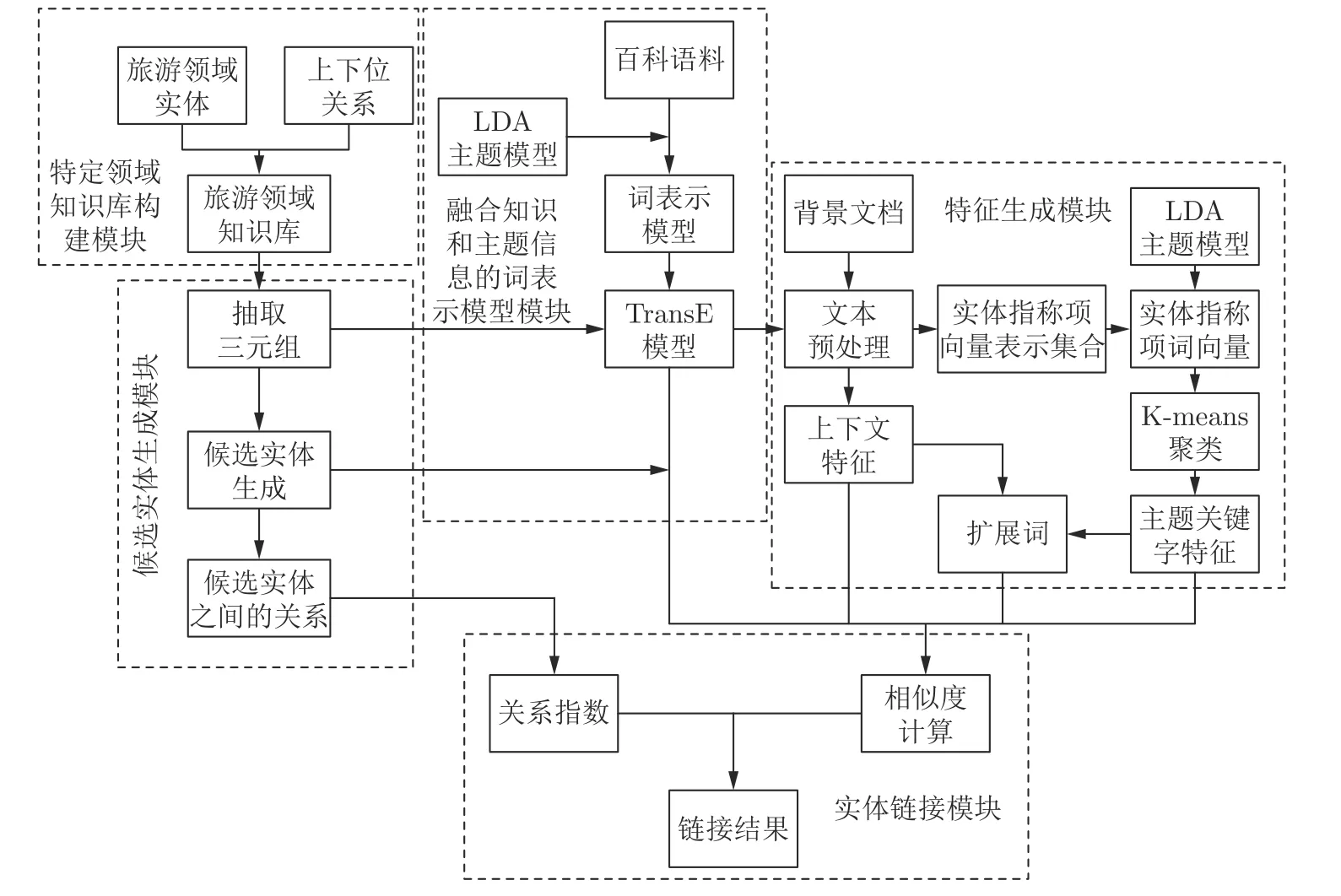
图1 模型框架图Fig.1 Frame diagram of the model
1.1 领域知识库构建
本文针对特定领域,在分析领域属性的基础上,通过人工定义知识体系,从百度百科等网站上收集了相关语料,包括旅游景点语料、野生菌语料、茶叶语料、中国少数民族语料,小吃语料和药材语料,交通方式和住宿信息语料共计96 674 个词条,构建了具有一定规模的特定领域知识库.然后将识别好的领域实体和实体间关系采用批量导入的方式导入到图数据库Neo4j 进行管理.本文使用自构建的特定领域知识库作为实体链接任务的支撑,并结合百度百科作为第三方知识库对自构建的特定领域知识库中的实体属性进行有效补充.具体方法是针对知识库中的每个实体,通过它在百度百科相应的概念页面,抓取页面中Infobox 的半结构化三元组数据.然后利用Neo4j 图数据库进行管理.对本地知识库中同名实体采用加后缀标签的方式进行区分,且后缀标签用小括号与实体隔离.例如:实体“香格里拉”.在本地知识库中有三个相应实体,分别加上后缀标签“地名”、“酒店”、“电影”,并用小括号进行隔离.如:香格里拉(酒店)、香格里拉(地名)、香格里拉(电影).
1.2 融合知识信息和主题信息的词向量模型训练
1.2.1 主题关键词特征提取
特定领域的实体链接可以利用领域特征进行实体链接[23−24],领域关键词表征了领域的主要语义信息和领域特征,但是基于领域关键词的相似度计算主要是从全局上下文信息出发,并没有考虑到文本局部的上下文信息,针对这个问题,本文提出利用LDA主题模型对训练语料上下文进行主题分类,通过在不同主题下对多义词与主题词结合进行语义扩充,计算词与词之间的余弦相似度进行K-Means 聚类,选 择离聚类中心最近的m个词作为主题关键词.
1.2.2 融合主题信息的词向量模型训练
Mikolov 等[18]提出Word2vec,通过神经网络将词表示在一个低维稠密的向量空间中,利用距离和角度反映出词语之间的语义信息;本文选择Google的开源工具包word2vec,采用Skip-gram 模型作为词向量训练的基本模型,其主要思想为根据中心词最大概率得到出其上下文:
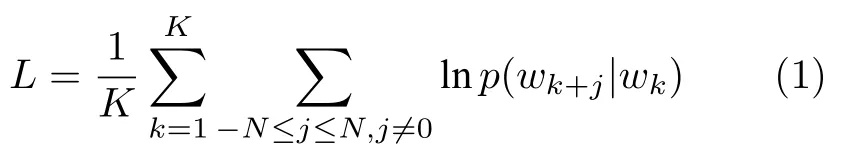
其中,wk是中心词,wk+j表示中心词的上下文,N是训练时窗口的大小,在本文中没有对窗口设置对比实验,按照实验经验,设窗口大小为5.p(wk+j|wk)表示在中心词wk的条件下,wk+j生成的概率,利用softmax 函数求得:
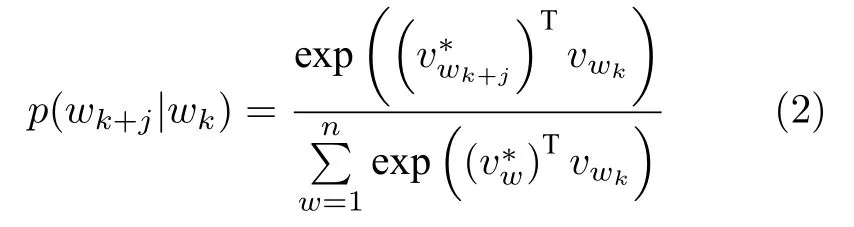

其中,d(wk,wj)表示词wk和wj向量表示的欧几里得距离,m表示词wk的主题词个数.将主题信息融入词向量表示中:

其中,α为权重值,我们的目标是最小化Jg,通过将主题关键词的距离融入词向量表达中,使得同主题词之间的向量表示更接近.对没有同主题关键词的词语,直接按照Skip-gram 模型训练出其向量表示形式.通过对训练出的词向量与同主题词计算相似度并参考Xu 等[25]的实验参数,设置α=0.8;m=6.
1.2.3 TransE 模型的联合学习
Bordes 等在Mikolov 的word2vec 词表示学习模型的基础上提出了TransE 模型[26],将知识库中的关系看作实体间的某种平移向量.通过TransE模型对构建的特定领域知识库中的三元组进行训练,得到知识库中实体和关系的向量表示.针对现有的实体链接方法,无法将知识库信息和文本信息更好的融合,造成在实体链接中无法利用更多的文本信息和知识库信息,在本文中,为了将知识库信息与文本信息融合,以达到更佳的实体链接效果,我们将第2.2.2 节中融合主题信息的词向量表示与知识表示模型TransE 联合学习.首先利用收集到的三元组语料预训练TransE 模型,得到实体与关系的向量表示,再将第2.2.2 节得到的融合主题信息的词向量表示形式,替换原有的实体向量表示,计算两者的尾实体的距离:
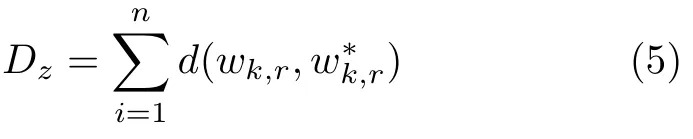
其中,wk,r表示TransE 模型得到的原实体wk和关系r的向量之和,wk∗,r表示wk在融合主题信息的词向量模型中的向量表示和关系r的向量之和,n表示实体个数.通过最小化Dz,使得词向量表示和知识表示相互约束训练模型,最终得到融合结构知识的词向量表示.对于在自构建的本地知识库中没有实体相对应的词语,将它们输入到训练好的模型中得到新的向量.我们称之为融合伪知识的词向量表示,这样做是将文本中的词与自构建本地领域知识库中实体向量表示嵌入到同一个语义空间中,达到融合文本信息和知识库信息的目的,也为后面的相似度计算提供方便.本文没有对TransE 模型的参数对实验结果的影响做特定实验,向量维数设为200,边缘超参数设为1,学习速率设为0.0001,选用L2 作为距离计算公式.在整个融合知识和主题信息的词向量表示过程中,向量维度统一设为200,整 体模型框架图如图2 所示.
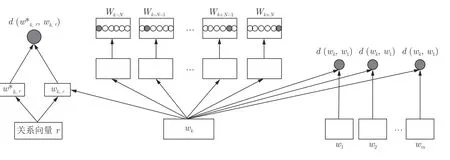
图2 融合知识和主题信息的词向量表示模型Fig.2 Word vector representation model that fuses knowledge and subject information
1.3 候选实体生成
1.3.1 候选实体的选取
对于候选实体的生成,首先要识别出文本中所有的实体指称项,将实体指称项组成集合M={m1,m2,···,mn},其中n表示文本中实体指称项的个数.然后针对每个实体指称项mi,在自构建的特定领域知识库中寻找与之同名实体(不包括括号内的实体后缀标签)并组合成集合,作为它的候选实体集合Ni={ni1,ni2,···}.如果知识库中没有同名实体,则把相应的实体指称项归为空实体;当候选实体个数小于等于4 时,选取指称项所有的候选实体作为它最终的候选实体;当候选实体个数大于4 时,计算指称项与候选实体的上下文相似度,选取相似度最大的4 个候选实体作为最终的候选实体.上下文相似度计算公式为:
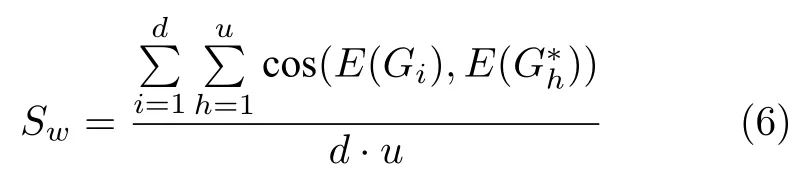
其中,E(Gi) 和分别表示实体指称项的上下文词和其候选实体直接三元组尾实体的向量表示;d和u分别表示实体指称项的上下文词的个数和其候选 实体直接三元组尾实体的个数.
1.3.2 候选实体关系属性的计算
针对集成实体链接,关系属性是候选实体的重要属性之一,基于实体指称项语义相近,则它们在知识库中的无歧义实体也应该具有关系的思想.例如:实体指称项“香格里拉”和“丽江”,它们语义相近,则它们在知识库中的无歧义实体“香格里拉(旅游胜地)”和“丽江(旅游胜地)”也具有相应的关系.本文将候选实体的关系属性分为直接关系属性和间接关系属性.1)直接关系属性计算自构建的特定领域知识库中含有丰富的关系属性,根据第2.3.1 生成文本中实体指称项的候选实体集合H={N1,N2,···,Nn},其Ni表示第i个实体指称项的候选实体集合,n为背景文档中实体指称项个数.结合自构建的领域知识库,得到候选实体的直接关系属性,具体方法为:对候选实体集合Ni中的每个元素分别与其他n− 1 个候选实体集合中的每个元素进行关系查找,如果两者之间存在直接三元组,则两个元素之间的关系指数为1,不存在则关系指数为0.对于第i个实体指称项的第j个候选实体nij的直接关系指数,计算公式为:

其中,n为候选实体集合个数,Nj为第j个候选实体集合.
2)间接关系属性计算候选实体以三元组的形式存储在自构建的特定领域知识库中,通过实体、关系相连接成网路状,这种存储形式决定了候选实体间的间接关系同时存在垂直间接关系和水平间接关系.例如在自构建的本地知识库中存在三元组:(云南,地级市,玉溪),(玉溪,景点,抚仙湖),通过一条关系路径,将两个三元组连接在一起,则“抚仙湖“和”云南“存在间接关系,我们称之为垂直间接关系;同样的,例如本地知识库中也存在三元组:(云南,地级市,玉溪),(云南,地级市,曲靖),如果只考虑关系路径相连接的情况,则“玉溪”和“曲靖”之间并不存在关系,这样却与事实不符.两者之间对应同一个头实体,也存在间接关系,我们将这种间接关系称为水平间接关系;同时也可以同时存在两种间接关系,例如(中国,省份,云南),(中国,省份,江苏),(云南,地级市,丽江),(丽江,景点,玉龙雪山),“玉龙雪山”和“云南”存在垂直间接关系,“云南”和“江苏”之间存在水平间接关系,则“玉龙雪山”和“江苏”之间同时存在垂直和水平间接关系.间接关系指数的计算公式为:

其中,n为候选实体集合个数,Nj为第j 候选实体集合,k为路径长度,p为水平间接次数,例如“玉龙雪山”和“江苏”存在一次水平间接次数,当两者之 间存在多条路径时,取最短路径.
1.4 特征生成模块
1.4.1 上下文特征生成
实体指称项的上下文特征可以代表指称项的文本环境,对指称项的语义表达具有重要作用.通过实体指称项的背景文本,经过文本预处理(分词、去停用词),利用第2.2 节训练好的融合知识和主题信息的词向量模型得到指称项的上下文向量表示.具体方法为:选择实体指称项所在句子经过分词、去停用词后的词作为实体指称项的上下文,利用训练好的词表示模型得到它们的向量表示形式.利用式(6)计算上下文特征相似度.
1.4.2 主题关键词特征生成
特定领域的局部特征对实体消歧具有重要作用,例如:在旅游领域的背景文本中,实体指称项“金花”的上下文信息主题围绕“花卉名”来进行介绍,而在文档局部上下文中主要围绕“茶品”的金花来介绍,可以看出局部特征对消歧有重要意义.为了利用局部特征进行实体链接,本文提出通过LDA 主题模型对旅游领域背景文本的上下文进行主题分类,利用第2.2 节得到的融合知识和主题信息的词向量表示,计算相同主题下的词与词之间的余弦相似度,然后进行K-means 聚类,选择离聚类中心最近的w个词作为主题关键词,w的取值在实验部分具体说明.主题特征表示为:
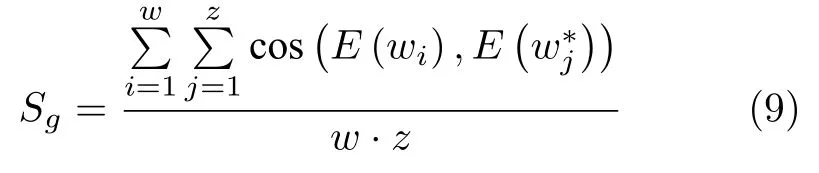
其中,E(wi) 和分别表示实体指称项主题关键词wi其对应候选实体在自构建的特定领域知识库中的类别标签的向量表示;w为实体指称项主题关键词的个数;z表示对应候选实体在知识库中的 类别标签个数.
1.4.3 扩展词特征生成
集成实体链接相比于单实体链接充分考虑了实体之间的共现关系,同时提高了计算效率.利用词扩展的方法,同时考虑v个实体,充分发挥集成实体链接的优势,具体方法为:对于第i个指称项mi,分别计算其他n−1个指称项与第i个指称项的上下文特征和主题关键词特征的余弦相似度,将相似度最大的v个实体指称项选择作为第i个实体指称项的扩展词,依次迭代n次,得到背景文本中每个实体指称项的扩展词.实体指称项扩展词的计算公式为:

其中,Sw和Sg分别表示实体指称项的上下文相似度和主题关键词相似度;选取Qk最大的v个实体指称项作为本实体指称项的扩展词.v的取值在实验部分详细说明.扩展词特征表示为:
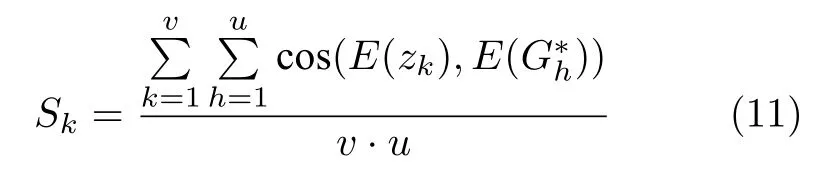
其中,E(zk) 和分别表示实体指称项扩展词和其候选实体直接三元组尾实体的向量表示;v和u分别表示扩展词和其候选实体直接三元组尾实体的 个数.
1.5 实体链接模块
1.5.1 关系指数计算
对于第i个实体指称项mi和它的v个扩展词,同时链接到本地特定领域知识库中的每个候选实体,根据第2.3.2 节的方法,得到实体指称项候选实体与其扩展词候选实体之间的关系指数,具体方法为:对于候选实体nij,分别对它与mi的v个扩展词的每个候选实体进行关系查找,得到它与v个扩展词候选实体的关系指数之和,最终通过归一化得到mi的每个候选实体的关系指数.计算公式表示为:

依次计算出实体指称项mi所有候选实体的关系指数ri1,ri1,···,riL,其中L为实体指称项mi的候选实体个数.通过归一化,得到最终的关系指数:
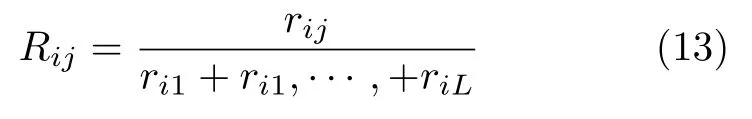
1.5.2 相似度计算
相似度计算是指利用实体指称项的文本特征与知识库中候选实体的相应特征,通过计算两者之间的余弦相似度,以此表征实体指称项与候选实体在文本信息方面的相似度.在本文中,充分利用上下文相似度、主题关键词相似度和扩展词相似度,最后得到特定领域实体指称项的相似度:
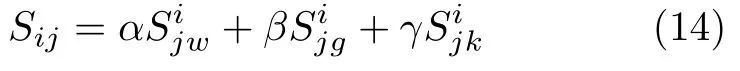
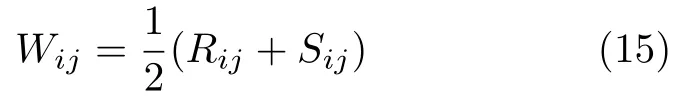
其中,Rij,Sij分别表示实体指称项mi与其候选实体nij的关系指数和特征相似度;1/2 表示两者的权重值.在文本中我们采用对等加权,也可以考虑不对等加权的情况,但通过初步实验结果并参考文献[11]表明,少量的权值修正对实体链接结果的影响不大,因 此本文采用1/2 作为两者的权重值.
2 实验
2.1 数据集
本文选择Google 的开源工具包word2vec,采用Skip-gram 模型作为词向量训练的基本模型,通过提取维基百科旅游、文化分类下的文本信息,并结合从旅游网站和百度百科、民族文化网站、中国中药杂志、中国中药材网爬取旅游信息文本136 749 篇,中国少数民族信息文本95 483 篇,药材信息文本114 673 篇作为词表示模型的训练语料.TransE 模型的预训练使用本地特定领域知识库中的163 759 组三元组为语料.实验所用的测试集是本文从爬取的旅游、少数民族文化、中药材三种领域中随机分别选取861 篇作为测试文本,然后分别从三种领域的测试文本中人工选取含有实体歧义的文本300 篇构建成旅游领域测试集、少数民族文化测试集和中药材测试集,并且在每一篇文本中人工标记出领域实体指称和其在自构建的领域知识库中的对应实体,在三个领域测试集中分别标注实体指称1 135 个、947 个和1 092 个,其中旅游领域测试集、少数民族文化测和中药材测试集在自构建的领域知识库中存在对应实体对象的分别有967 个、703 个、939 个实体指称.
2.2 实验设置与评价指标
实验的过程包括融合知识和主题信息的词向量模型训练、候选实体的生成、扩展词的生成、关系指数计算、相似度计算、实体链接等过程.使用jieba分词工具实现语料预处理;针对融合知识和主题信息的词向量模型训练,采用Skip-gram 模型作为词向量训练的基本模型,窗口大小设置为5,设置主题词距离权重α=0.8,主题词m=6,对于TransE模型的预训练,边缘超参数设为1,学习速率设为0.0001,选用L2 作为距离计算公式,向量维数统一设为200;本文采用准确率P(%)、召回率R(%)和F1 值来评估本文提出的方法,其中文本中的实体指称项在本地知识库中存在对应实体的集合为A;算法输出的链接到本地知识库中实体对象上的实体指称项集合为B.则准确率P(%)、召回率R(%) 和F1 值的计算公式如下所示:
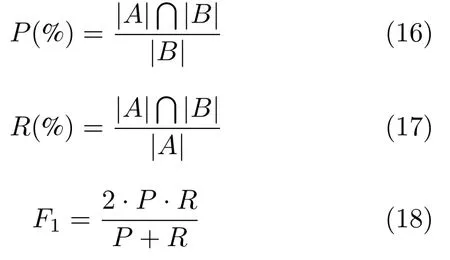
2.3 实验及其结果分析
2.3.1 实验设计
为了验证本文提出方法的可行性,本文设置以下6 组实验:实验1:不同相似度特征组合的实验对比.实验2:验证扩展词的数量v对实体链接结果的影响.实验3:验证主题关键词个数w对于实体链接准确率的影响.实验4:验证不同关系属性对实体链接结果的影响.实验5:本文提出的方法与目前主流的实体链接方法进行对比.实验6:验证本文提出的 方法在不同领域中的普适性.
2.3.2 实验结果与分析
1)实验1:为了验证不同特征对实体链接结果的影响,本实验使用旅游领域测试集,通过选取不同的特征组合进行对比实验,表1 所示为不同特征组合对实验结果的影响.
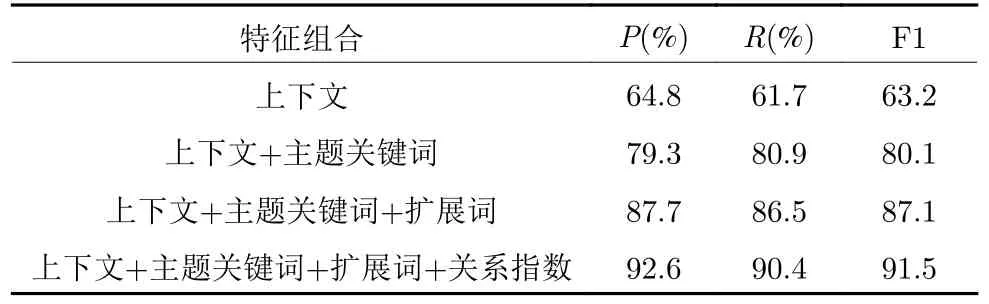
表1 不同特征组合实验结果统计Table 1 Statistics of experimental results of different feature combinations
在进行特征组合对比实验时,使用旅游领域测试集,主题关键词个数w=4,扩展词个数v=3.根据实验结果发现,只利用上下文相似度特征和主题关键词相似度特征,其准确率明显低于结合扩展词相似度特征和关系指数,F1 值相较于只利用上下文特征和主题特征也有明显提升,能够达到91.5.分析原因主要是上下文相似度特征和主题关键词特征仅仅是基于一个实体指称项信息出发,没有考虑一篇文章中实体指称项之间的共现信息,并且忽略了候选实体之间的关系属性.结合扩展词相似度特征和关系指数,在考虑单个实体指称项的同时也充分考虑了实体指称项的共现信息和候选实体之间的关系属性,因此准确率有了很大的提高.
2)实验2:本实验在旅游领域测试集上,分别测试扩展词个数v在取1,2,3,4 时对实体链接准确率的影响,实验结果如表2 所示.
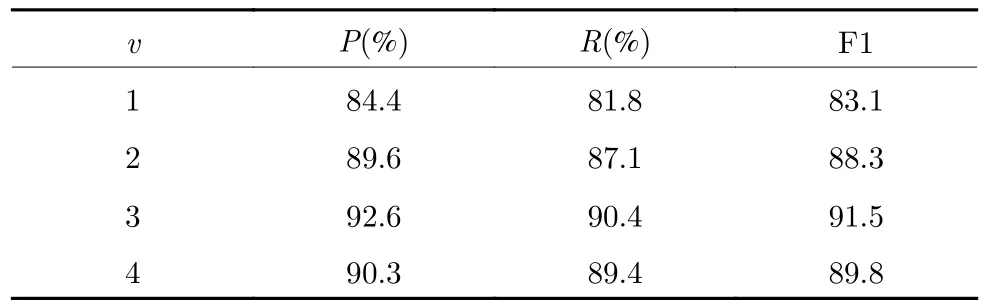
表2 不同v 值实验结果统计Table 2 Statistical results of different v values
在进行扩展词个数实验时,使用旅游领域测试集,同时考虑上下文特征、主题关键词特征、扩展词特征、关系指数,主题关键词个数w=4.根据实验结果发现,扩展词的个数对实体链接结果有较大影响,F1 值可以从最低的83.1 提升到91.5,并且相比于只利用上下文特征和主题关键词特征的F1 值,有了较大提升,说明加入扩展词特征可以对实体链接有较大帮助.从实验结果表明,当扩展词个数v=3时,F1 值达到最大值91.5.当个数大于3 时准确率和F1 值都有所降低.分析原因主要是因为当扩展词个数太小时,不仅没有充分利用实体指称项之间的共现信息,并且会影响候选实体的关系指数,所以准确率会降低,当扩展词个数太大,会出现冗余信息,对实体指称项的信息表达和候选实体关系指数计算都会产生不好的影响.所以本文扩展词个数取v=3.
3)实验3:本实验在旅游领域测试集上,分别测试主题关键词个数w在取1,2,3,4,5 时对实体链接准确率的影响,实验结果如表3 所示.
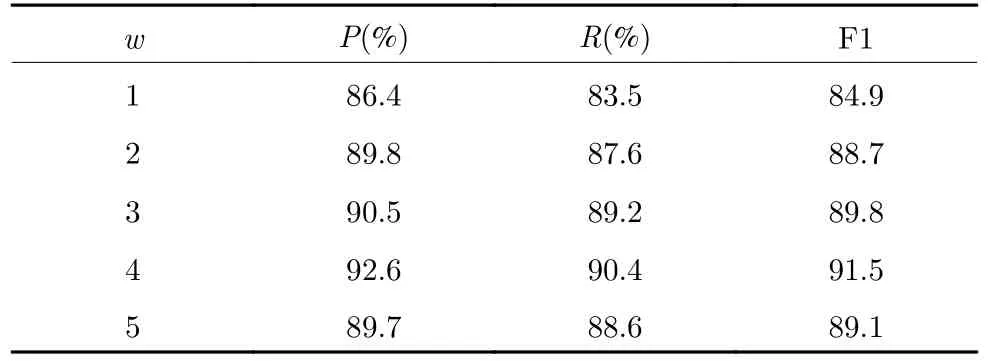
表3 不同w 值实验结果统计Table 3 Statistical results of different w values
在进行主题关键词个数实验时,使用旅游领域测试集,同时考虑上下文特征、主题关键词特征、扩展词特征、关系指数,扩展词个数v=3.通过对比不同主题词个数w和不同扩展词个数v的对比实验表明,扩展词特征与主题词特征的作用基本相当,最小F1 指分别为83.1 和84.9,但是主题词不同个数之间F1 值的差距没有不同扩展词个数之间明显.根据实验结果发现,当主题关键词个数w=4 时,F1值达到最大值91.5,当个数大于4 时准确率降低.分析原因在于提取主题关键词时采用聚类的方法,当主题关键词个数太小时,无法代表领域特定信息,当个数大于4 时,又造成信息冗余,将多余信息引入到相似度计算中,从而导致实体链接的F1 值下降.所以本文主题关键词个数取w=4.
4)实验4:为了验证关系属性中每个子属性的效果对实体链接结果的影响,本实验使用旅游领域测试集,通过依次增加关系属性中各个子属性来设置对比实验,观察实验结果如表4 所示.
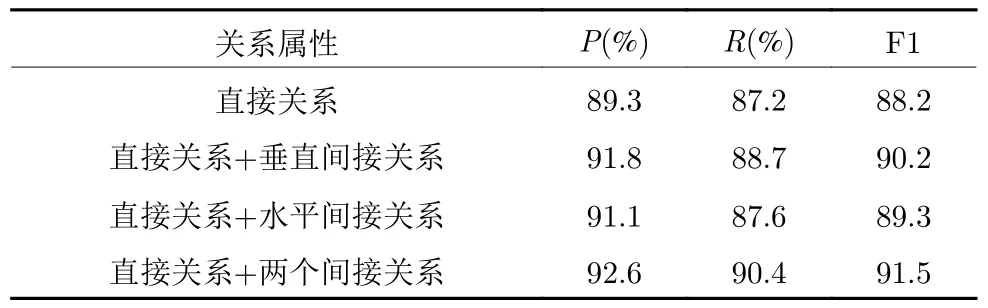
表4 各个关系子属性的实验结果统计Table 4 Statistical results of experimental results for each relationship sub-attribute
在进行各关系子属性的实验时,使用旅游领域测试集,同时考虑上下文特征、主题关键词特征、扩展词特征,扩展词个数v=3,主题词个数w=4.实验结果表明,利用候选实体之间的直接关系使得实体链接的F1 值有了较小提升,分析原因是自构建的特定领域知识库中并不完整,只利用直接关系信息对实验结果帮助有限,同时通过水平间接关系和垂直间接关系的实验结果对比,垂直间接关系对实体链接结果影响更大,说明通过关系路径相连的候选实体之间的关系信息对实体链接更有帮助,但是通过最终的实验结果表明,将两种间接关系同时考虑,更能增加候选实体的关系信息,对实体链接帮助更大.
5) 实验5:为了验证本文提出方法的可行性,在旅游领域测试集上,将本文的方法与其他几种实体链接方法进行比较,实验结果如表5 所示.
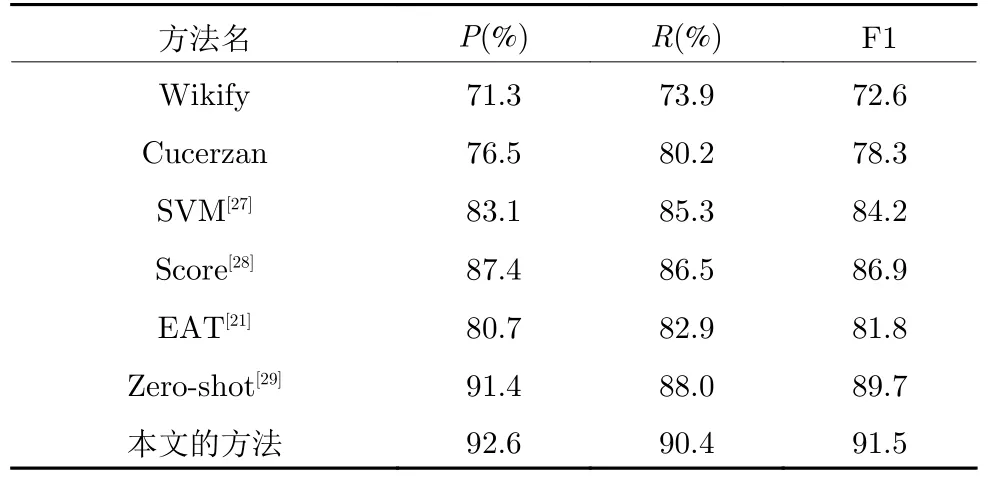
表5 本文方法与其他方法的比较Table 5 Comparison of methods in this paper with other methods
在旅游领域测试集中将以上基线方法复现,其中参数设置与其论文中相同.根据实验结果表明,本文提出的方法与传统的统计机器学习的方法相比较F1 值有明显的提升,并且不需要标注语料,更简洁高效;与EAT[21]方法相比较,Moreno 等[21]通过扩充知识库中实体的锚文本对文本中的单词和知识库中的实体在同一个向量空间中学习指称项与候选实体的向量表示,并通过训练分类器进行实体链接,两种方法都是基于词嵌入,本文的方法准确率有较大提升,我们分析原因在于我们的语料主要是针对特定领域,语料数据集规模相较于公共数据集偏小,所以词嵌入效果没有达到最佳,但是我们的方法在词嵌入的基础上,将知识和主题信息融入词向量表示中,将文本信息和知识库信息融合,同时综合考虑了上下文特征、主题特征、词扩展特征、关系指数特征,所以比EAT[21]方法在F1 值上有了较大的提高,也验证了本文的方法更适应于语料偏少的特定领域;与Zero-shot[29]相比较,前者利用的是最新的神经网络模型,与它相比较F1 值有较小提高,证明了本方法达到了较高水平,也证明了本方法在对特定领域实体链接任务的可行性.
6)实验6:为了验证本文提出的方法在不同领域中的普适性,将本文的方法在旅游领域测试集、少数民族文化测试集和中药材测试集中进行比较,实验结果如表6 所示.
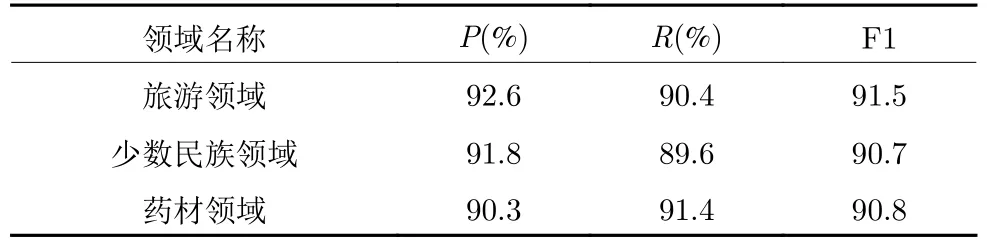
表6 不同领域的实验结果统计Table 6 Statistics of experimental results in different fields
由实验结果表明,在不同的领域语料中的F1值变化不大,其中在旅游领域中的F1 值最大,在少数民族和药材领域F1 值基本一致,分析原因:在旅游领域中,由于其关系类别少、实体个数多的特点,其扩展词可以很好地表征其语义信息,利用扩展与实体指称项的候选实体之间的关系信息也比较明显.但是在少数民族和药材领域,关系种类更加复杂,实体与实体之间的关系信息也不明显,所以在这两种领域中,扩展词特征和关系指数不如在领域领域中明显,造成了F1 值略有下降.但是从不同领域的对比实验中表明,本文方法针对标注语料少,流行度等消歧特征不明显的问题,在不同特定领域中的效果基本稳定并且有较好的F1 值.
3 总结和展望
本文针对现有的实体链接方法无法将文本信息和本地知识库信息充分相结合,提出了一种简单高效的基于关系指数和表示学习的特定领域集成实体链接方法.利用表示学习将文本信息和知识库信息相融合,简单高效且适应于特定领域语料偏少的特点.实验结果表明,该方法与现有的实体链接方法相比,不需要标注语料,其实体链接准确率和F1 值比较理想,同时更适应于语料偏少的特定领域.下一步的工作是对已经构建的小规模特定领域知识库进行扩充和完善,同时不断挖掘领域文本中特有的属性特征,改进实验效果.
