鸟类音频数据预处理方法
2021-11-30张猛李健
张猛,李健
1.中国科学院计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100049
引 言
作为森林生态系统的重要组成部分,鸟类群落是对森林生态系统进行健康监测和评估的关键物 种[1]。因此研究鸟类种群、分布以及区域生物多样性等工作具有重要的意义。这首先需要准确识别出鸟类物种,相比于鸟类图像数据、视频数据等,鸟类音频数据显然更容易被采集到,基于鸟类音频数据自动识别出鸟类物种则显得尤为重要。
来源于野外自然环境的鸟类音频数据,不会有针对性的仅仅采集鸟类音频,而是会将所处环境中的音频全部记录下来,因此难免会记录风声、水声及其他环境噪音,音频的信噪比较低。这些噪音显然会对鸟类物种识别产生干扰,显著降低鸟类物种识别的准确率,这使得噪声环境下的鸟类音频识别具有重要的现实意义。在进行后续处理之前,有必要对鸟类噪声数据进行处理,以获得更高质量的音频。
Bardeli[2]采用谱减法、功率谱分析及自相关分析进行噪声环境下的鸟鸣声识别。任芳[3]使用小波去噪和维纳去噪对鸟类音频信号进行去噪。谢将剑[4]等在信噪比较高的18 种鸟类音频数据集上,采用能量阈值法去除音频中的静音片段,通过计算每帧信号的能量,将能量小于最大能量60%的帧认为是静音片段予以去除,之后生成频谱图样本集输入到VGG16 网络中进行分类。冯郁茜[5]采用端点检测的方法去除静音片段,计算语音信号的过零率并调整能量的阈值,将低于指定阈值的音频片段去除,得到更具代表性的鸟类音频进行后续分析。董雪[6]对生成的频谱图应用对比度限制的直方图均衡化方法增强,增加了声纹信息和背景噪声之间的对比度,并且增强了纹理的细节特征。以上方法可以去除低音背景音噪声和静音片段,但是对于水流声、风声和人类活动的声音等音量较大的噪声难以去除。
随着深度学习技术的发展,利用卷积神经网络,对图像进行特征提取变得非常方便。鸟类音频频谱图的声音区域有着不同的轮廓,同一鸟类物种的音频频谱图又具有一定的相似性,非鸟类的噪音频谱图和鸟类音频频谱图之间差异很大。因此本文基于频谱图特征的差异性,提出了使用卷积神经网络和密度聚类的频谱图筛选算法,将噪音频谱图筛选出来,从而获得更为干净的鸟类音频频谱图样本集。
1 算法整体流程概述
本文算法的整体流程如图1 所示:
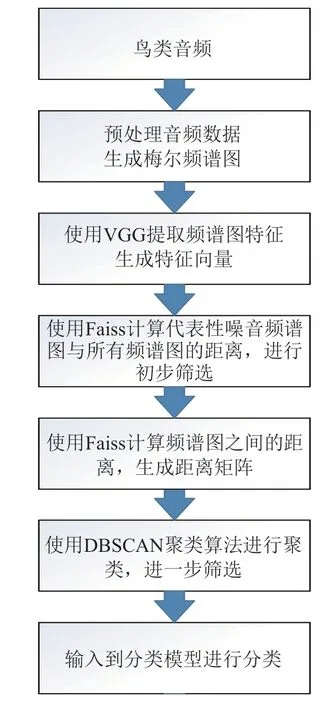
图1 本文算法整体流程图Fig.1 This algorithm overall flow chart
具体分为如下步骤:
(1)预处理鸟类音频数据,生成梅尔频谱图;
(2)使用VGG 网络提取频谱图特征,每张频谱图生成一个特征向量;
(3)选取有代表性的噪音频谱图(如风声、水声以及低音背景音等),利用Faiss 算法分别计算与所有频谱图的距离,将低于指定阈值的频谱图作为噪音数据筛选并剔除;
(4)将剩余频谱图按照物种分类,利用Faiss 算法计算每个物种内每两张频谱图之间的特征距离值,生成距离矩阵;
(5)利用数据挖掘的密度聚类算法DBSCAN 对每个物种的距离矩阵分别进行聚类,筛选并剔除孤立点(即噪音),对于簇(即分类)数多于1 个的情况,则从每个簇中选取数张有代表性的频谱图,甄别出真正代表该物种音频的频谱图像样本集。
2 生成鸟类音频频谱图样本集
2.1 鸟类音频数据集
本文使用的数据集来源于鸟类音频的网站www.xeno-canto.org,该网站汇集了来自世界各地鸟类爱好者上传的鸟类音频数据,由Bob Planque 和Willem-Pier Vellinga 一起创办。本文所用鸟类音频数据集包含云雀、喜鹊、大山雀、大斑啄木鸟、欧亚红尾鸲等31 个鸟类物种,鸟类音频文件的采样频率为44.1kHz。来自于德国、芬兰、斯洛伐克、捷克和立陶宛这5 个国家。每个音频文件的长度从几秒到几分钟不等。不同鸟类物种音频文件数量分布不一。最多的种类有2 856 个音频,最少的种类只有31 个音频。鸟类物种音频文件数量的分布图如图2 所示。
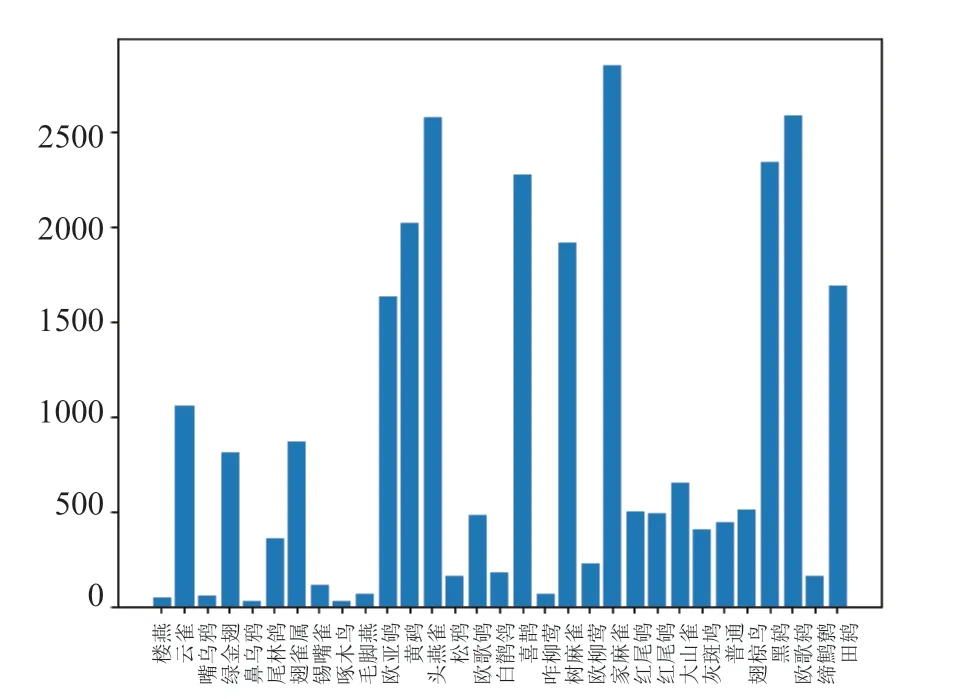
图2 .鸟类物种音频文件数量分布情况Fig.2 Distribution of audio files of bird species
2.2 鸟类音频的预处理
在计算频谱图之前,为了使语音信号具有可用性和提高信号的质量,声音信号要进行预处理,包括降噪、端点检测、预加重、分帧和加窗[7]。
2.2.1 降噪
本文采用谱减法对鸟类音频数据进行降噪处理。谱减法[8]是减少噪声的一种广泛使用的算法,主要是因为其实现简单。它是由Boll 在70年代后期提出的,然后由Berouti 进行了概括和改进。
该算法假设有一个噪声加法模型,短时平稳信号和噪声信号相互独立,语音信号中的噪声只有加性的噪声,将带噪语音减去噪声谱,就能够得到纯净的语音信号。
2.2.2 端点检测
端点检测就是在一段含噪语音中提取出语音段的起点和终点,将语音段和非语音段区分开。本文采取基于短时能量和过零率的双门限方法[8]。短时能量是语音的时域特征,通常指的是一帧时间内的语音能量,计算如公式1 所示:
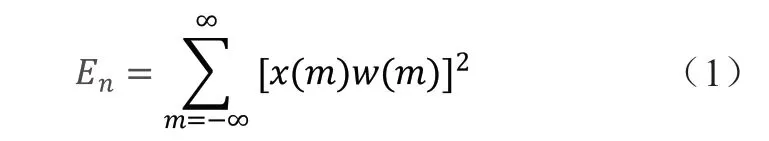
过零率就是单位时间穿过坐标系横轴的次数。计算如公式2 所示:

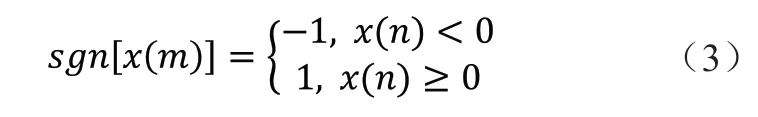
根据含噪语音信号设置三个阈值,分别是短时能量阈值TL和TH,过零率阈值ZCR。当某帧信号的短时能量大于TL或者过零率大于ZCR时,认为是信号的开始,当短时能量大于TH时,则认为是正式的语音信号。
2.2.3 预加重
由于鸟类的声音在传播的过程中会受到辐射效应的影响,使得高频成分的衰减下降较为严重[9]。因此对于音频信号,采用预加重技术,对声音信号高频率部分进行补偿,减少声音信号内容的信息丢失。
经常使用一阶高通滤波器对声音信号预加重,处理的过程如公式4 所示:
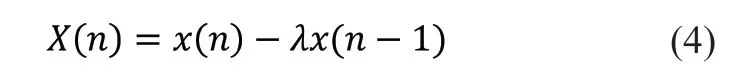
式中,λ是预加重系数。分别是预加重前后的第n 个采样值。本文中λ取为0.97。
2.2.4 信号分帧和加窗
声音信号在短时间内的变化才是平稳的。所以需将声音信号进行分帧操作,分为一段一段地来分析其特征参数,这样的每一段称为“帧”。分帧后,为了保证分帧信号两端的连续性,需要使用有限长度可移动的窗函数对信号进行处理。矩形窗、汉明窗是常用的窗函数。在本文中设置每一帧的帧长为2s,两帧信号之间重叠比例为50%,窗函数选择汉明窗。如公式5 所示:
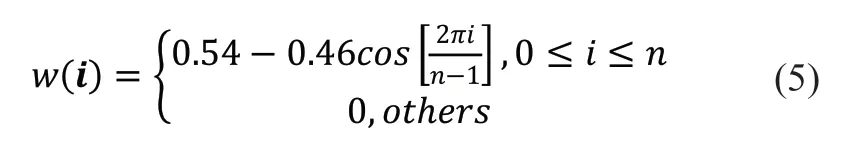
2.3 生成频谱图样本集
频谱图中的声音区域有着一些特定的形状和分布,通过识别这些差异化的形状和分布,可以实现鸟类音频的分类。本文提取鸟类音频的梅尔频谱图作为鸟类频谱图样本集。
2.3.1 梅尔频谱图人耳听到的声音高低与声音的实际频率不成线性正比关系[10]。 在声音频率低于1kHz 时,对于频率的感受是呈线性的,而当频率高于1kHz 时,人耳对于频率的感受会变成对数变化[13]。梅尔频率尺度通常用于模拟人耳的听觉系统,不仅充分考虑了人类的听觉特性,而且还能有效提高特征参数对于音频的表达能力[13]。公式6 表明了两种频率之间的关系:
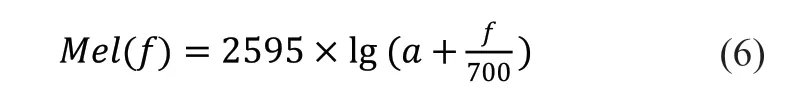
式中,f代表赫兹频率,单位是Hz。梅尔频谱图的提取过程如下:
步骤一:将音频信号经过降噪、端点检测、预加重、分帧和加窗的处理;
步骤二:对音频信号进行快速傅里叶的变换;
步骤三:对步骤二的输出进行取模平方的运算;
步骤四:将步骤三的输出放到若干个三角形梅尔频率滤波器组中进行处理;
步骤五:最后对所有输出进行对数运算就可以得到梅尔频谱图。
如图3 为梅尔频谱图提取过程流程图。

图3 梅尔频谱图提取过程Fig.3 Mel frequency spectrum diagram extraction process
从鸟类音频文件提取的梅尔频谱图,往往包含了风声、雨声等背景噪音,而且还包含多种鸟类的混合鸣声。选取不同情景下的梅尔频谱图如图4-7 所示。可以看出这些不同情景的梅尔频谱图具有一定的差异性,这为本文进行频谱图的筛选工作提供了可能性。
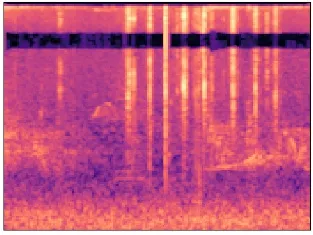
图4 风声背景音频频谱图Fig.4 Mel frequency spectrum of wind sound background audio

图5 水流背景音频频谱图Fig.5 Mel frequency spectrum of flow background

图6 低音背景音频频谱图Fig.6 Mel frequency spectrum of bass background audio

图7 正常的鸟声音频频谱图Fig.7 Mel frequency spectrum of normal bird sounds
3 基于卷积神经网络的频谱图特征提取
卷积神经网络是具有卷积结构的深层神经网络,具有局部感受野和权重共享的特性[11]。 它可以自动提取图像的复杂和重要特征,近些年来在很多领域得到应用。因此本文基于卷积神经网络提取频谱图特征。近些年来,深度学习发展迅速,也涌现了很多针对图像的新型高效的网络模型,如VGG,Inception,Resnet 网络等。
VGG[12]网络是2014年提出的。VGG 运用了更小的卷积核和更小的池化核,证明了加深网络的深度可以一定程度获得更好的网络性能。VGG 的泛化能力很好,提取特征能力强大,而且其结构很简单,应用场景很广泛,可以满足频谱图特征提取的需求,因此本文选取经典的网络模型VGG 来提取音频频谱图的特征。
VGG 的网络结构图如图8。不同结构添加不同数量的3*3 的卷积核进行卷积,VGG 的不同网络结构并没有本质上的区别,只是网络的深度不一样。
需要指出的是,图8 中包括了全连接层,而本文中使用的VGG 模型剪切掉了全连接层,主要目的是为了提取鸟类音频频谱图的关键特征,不需要进行分类。本文采用最大池化层的特征进行后续分析处理。

图8 VGG 网络结构图[15]Fig.8 VGG network structure diagram[15]
4 特征向量距离计算与数据清洗算法
基于卷积神经网络VGG 模型对频谱图进行特征提取之后,产生了大量的特征向量。为了衡量不同频谱图之间的相似程度,需要对不同频谱图特征向量进行距离计算,因为频谱图数量众多,需要进行的特征向量距离计算量会非常大,因此需要选择高效的距离计算方法,本文选取Faiss 算法作为频谱图特征向量的距离计算方法。
4.1 特征向量距离计算方法
Faiss[13]由Facebook 在2019年提出并开源,是一个高性能稠密向量相似性搜索框架。包含对任意大小向量集的搜索算法,可以在十亿数据集上进行最近邻搜索。Faiss 非常高效,能够利用多进程和多线程,还可以利用GPU 强大的计算能力。Facebook实现的最近邻搜索算法,在十亿级的数据库上,比当前已知的最好方法,以及目前文献中已知的GPU上最快的k 近邻搜索算法的速度快大约8.5 倍。Faiss的特点为:
(1)速度快,可存在内存和磁盘中;
(2)提供多种检索方法;
(3)由C++实现,提供了Python 封装接口;
(4)支持GPU。
Faiss支持内积(IndexFlatIP)、欧氏距离(IndexFlatL2)等多种向量检索方式,同时支持精确检索与模糊搜索。精确检索不需要对数据进行训练操作,通过提供的索引方式来遍历数据库,精确计算查询向量与被查询向量之间距离。Faiss 通过Index对象进行向量的封装与预处理。Index 中包含了被索引的数据库向量以及对应的索引值。在构建Index时,需预先提供数据库中每个向量的维度d,随后通过add()的方式将被检索向量存入Index 中,最终通过search()接口获取与检索向量最邻近topk 的距离及索引。
在本文中,使用Faiss 的精确检索,选择IndexFlatL2 类型的索引对象。该索引进行最近邻搜索采用的是欧氏距离。
4.2 频谱图筛选算法
4.2.1 基于典型噪音频谱图的快速筛选算法
首先从频谱图数据集中选取少量有代表性的噪音频谱图,提取其特征向量之后,利用Faiss 算法计算噪音频谱图与所有频谱图的特征向量之间的距离,将距离小于指定阈值的频谱图直接筛选出来,经过人工初步审核之后,即可从数据集中剔除,在进行聚类算法之前先进行此操作,可以快速筛选出大量的噪音频谱图,使得频谱图数据集的规模显著缩小,也可以让后续聚类算法的计算量显著减少。而且如果噪音频谱图的数量较多,导致能够通过聚类形成某些簇(即分类),也会给后续的数据筛选工作增加难度,因此有必要在聚类算法之前先快速筛选出部分噪音频谱图。
4.2.2 基于DBSCAN 算法的频谱图筛选算法
聚类是一种无监督学习的算法[14]。简单来说,聚类就是把相似的东西分到一组。如何计算相似度有不同的距离计算方法,核函数计算、距离计算、余弦相似度都是常见的计算方法。
DBSCAN 算法是一个基于密度的空间数据聚类方法,是MARTIN[15]等人在1996年提出的。它可以将数据分布为高密度的区域划分为簇,并且可以在含有噪声的数据中,找到噪声数据和形成的簇的集合。
DBSCAN 算法不需要预先定义类别个数,适用于任何形状的聚类簇的构建,甚至是无连接的环状聚类簇。由于存在最少点数的限制,相较于K-means[16]算法,DBSCAN 算法可以避免single-link影响,DBSCAN 算法对于任意形状的数据分布都具有较好的聚类效果,对噪声数据不敏感。因此本文选取DBSCAN 算法进行频谱图的筛选和剔除。
DBSCAN 算法的一些概念定义如下[17]:
① 密度阈值MinPts,定义了一个聚类簇需要的最少的数据点个数;
② 邻域阈值ε-邻域,某点作为中心点,以其为圆心、ε为半径的圆所覆盖的范围;
③ 中心点,即聚类簇的中心,其ε-邻域中包含的数据点比MinPts多;
④ 边缘点,即在聚类簇边缘的节点,其ε-邻域中包含的数据点比MinPts少,并且其在其他中心点的ε-邻域中;
⑤ 噪声点,既不是中心点,也不是边缘点的数据点。
节点定义的实例化描述如图9 所示。
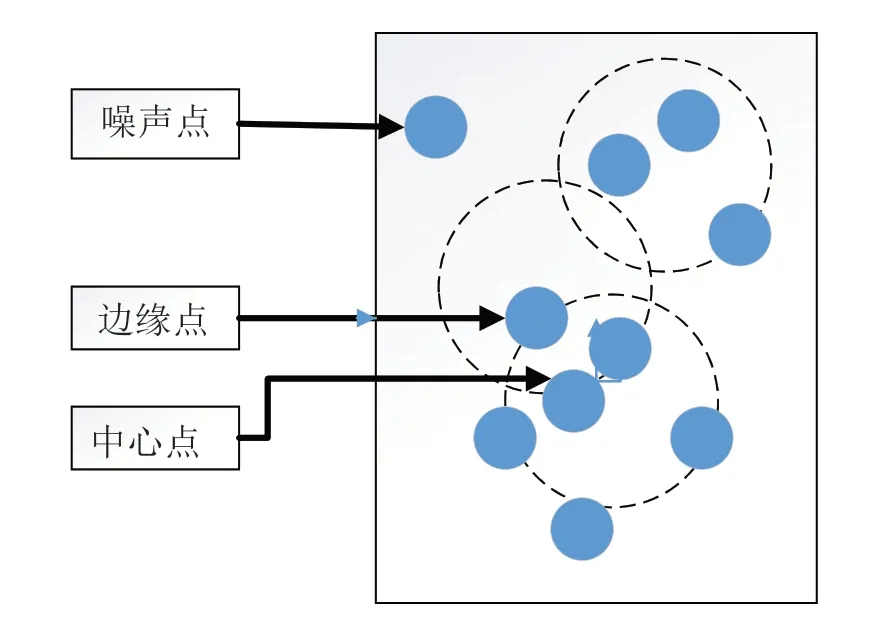
图9 节点定义的实例化描述Fig.9 An instantiation description of a node definition
DBSCAN算法具体的伪代码描述如下:

DBSCAN算法输入:D:输入数据集合MinPts:密度阈值E:邻域阈值输出:簇的集合方法:1.D中所有的数据点标记为“unvisited”2.执行3.随机选一个未访问过的数据点P,标记P为“visited”4.检查数据点P的ε-邻域内的数据点数量Pn 5.若Pn多于MinPts:6.则以P为中心点创建一个簇C 7.把P的ε-邻域中的数据点都放入集合N

DBSCAN算法8.对 N中每个点n:9.若n不属于其他簇,加到C 10.If n 是“unvisited”:11.把n标记为“visited”;12 若n的ε-邻域至少包含MinPts个数据点,则n的ε-邻域的数据点都被加到N中13.结束14.输出C 15.否则 标记P为噪声点;16.直到 所有点都被标记为“visited”。
5 实验结果与分析
5.1 实验平台和设置
本文实验均在Ubuntu16.04(64 bit)系统上运行。使用的数据集为2.1 小节提到的鸟类音频数据集。测试的硬件环境是英伟达1080ti。实验采用Keras 框架,Tensorflow 作为后端。
首先根据音频数据集生成频谱图样本集。为了保证各个物种频谱图数量的平衡,对于每个物种,只生成2 000 张频谱图用作训练,1 000 张频谱图用作测试。最终训练集包含62 000 张频谱图,测试集包含31 000 张频谱图。
因为鸟类音频中还包含风声、雨声、其他非鸟类的音频,因此会产生大量噪音频谱图,需要对频谱图样本集进行筛选,保留有效的频谱图,作为后续的训练和测试数据集。
频谱图筛选算法的实验基于Keras 框架。本文采用VGG-16 网络提取图像全连接层之前的特征向量。特征向量的维度是512*1。在得到特征向量后,使用Faiss 的IndexFlatL2 类型的索引对象计算频谱图特征向量的距离矩阵,最后使用DBSCAN 算法,其中邻域阈值选取0.25,密度阈值选取30。
为了进一步验证提出的频谱图筛选算法的有效性,本文把经过频谱图筛选算法的频谱图样本集和没有经过频谱图筛选算法的频谱图样本集分别输入到后续的分类模型中进行分类。
分类模型采用的是残差网络Resnet50,训练轮数100 轮,批大小为128。模型训练使用Adam 优化算法,初始学习率0.001,损失函数为交叉熵函数。
5.2 实验评价指标
为了更好地评估模型的分类效果,本文使用31种鸟类的平均分类准确率(Mean average precision, 简称MAP)和混淆矩阵作为评价和分析指标。
MAP 即每个物种的分类准确率再求平均值。MAP 的计算公式可以表述为公式7:
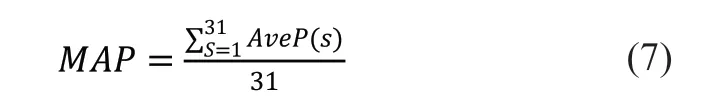
其中,n 是每一个鸟类的编号,P(s)是相应鸟类的分类准确率。
混淆矩阵是分类任务中常见的一种评估标准。混淆矩阵对角线元素表示正确分类的数量,非对角线元素表示错误分类的数量。它可以帮助我们直观地看到每一个种类分类的情况。
5.3 实验结果
经过频谱图筛选算法处理后,31 个鸟类物种的训练集和测试集频谱图样本数量变化见表1。
表1 31 个物种筛选前后频谱图数量的变化Table 1 Changes in the number of spectral images of 31 species before and after filtering
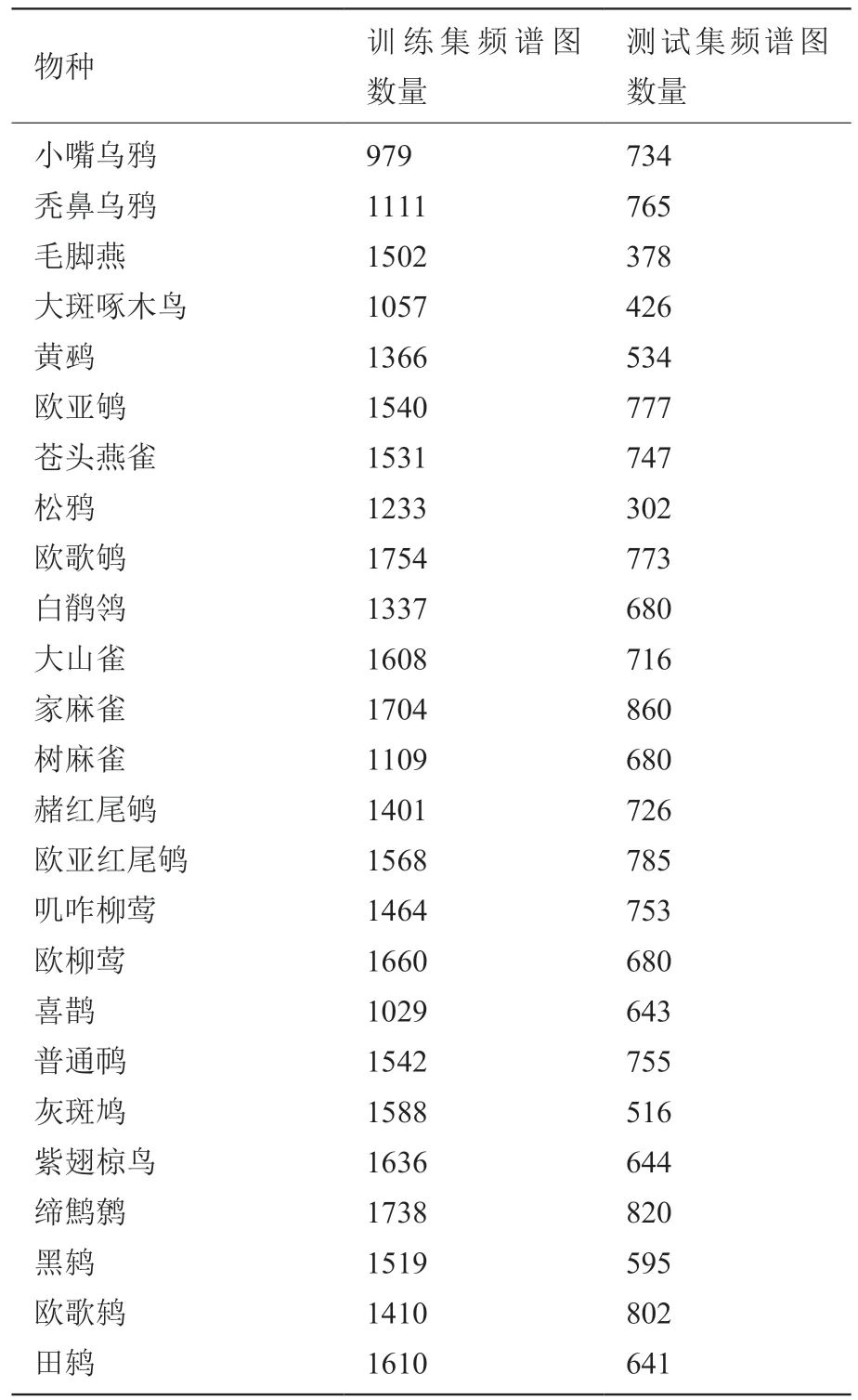
物种 训练集频谱图数量测试集频谱图数量小嘴乌鸦秃鼻乌鸦毛脚燕大斑啄木鸟黄鹀欧亚鸲苍头燕雀松鸦欧歌鸲白鹡鸰大山雀家麻雀树麻雀赭红尾鸲欧亚红尾鸲叽咋柳莺欧柳莺喜鹊普通䴓灰斑鸠紫翅椋鸟缔鹪鹩黑鸫欧歌鸫田鸫979 1111 1502 1057 1366 1540 1531 1233 1754 1337 1608 1704 1109 1401 1568 1464 1660 1029 1542 1588 1636 1738 1519 1410 1610 734 765 378 426 534 777 747 302 773 680 716 860 680 726 785 753 680 643 755 516 644 820 595 802 641
从表1 可以看到,经过频谱图筛选算法的处理后,31 个鸟类物种的频谱图的数量显著减少。训练集频谱图和测试集频谱图分别减少16 748 张和11 079 张,被剔除的频谱图大都是非鸟类音频片段产生的,这达到了自动筛选频谱图的预期效果。
然后把经过频谱图筛选算法的频谱图样本集和没有经过频谱图筛选算法的频谱图样本集分别输入到后续的分类模型中进行分类,获得了31 个鸟类物种的Top-1 和 Top-5 平均分类准确率,如表2 所示。
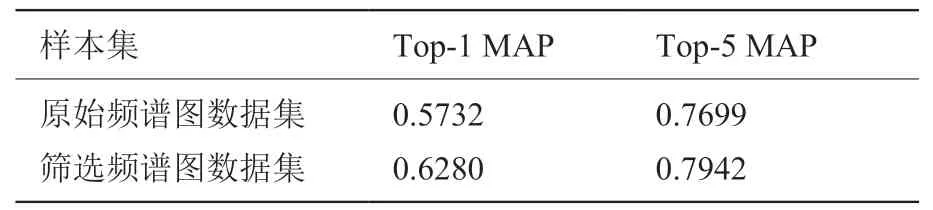
表2 筛选前后总体Top-1 和Top-5 分类准确率Table 2 The overall classification accuracy of TOP-1 and TOP-5 before and after filtering
由表2 可知,经过筛选后的频谱图样本集输入到分类模型中,31 类鸟类物种可以获得0.628 的Top-1 MAP 和0.7942 的Top-5 MAP,这比没有经过频谱图筛选算法的频谱图样本集的识别准确率有了明显提升。
本文31 个鸟类物种Top-1 分类准确率的变化情况如表3 所示。
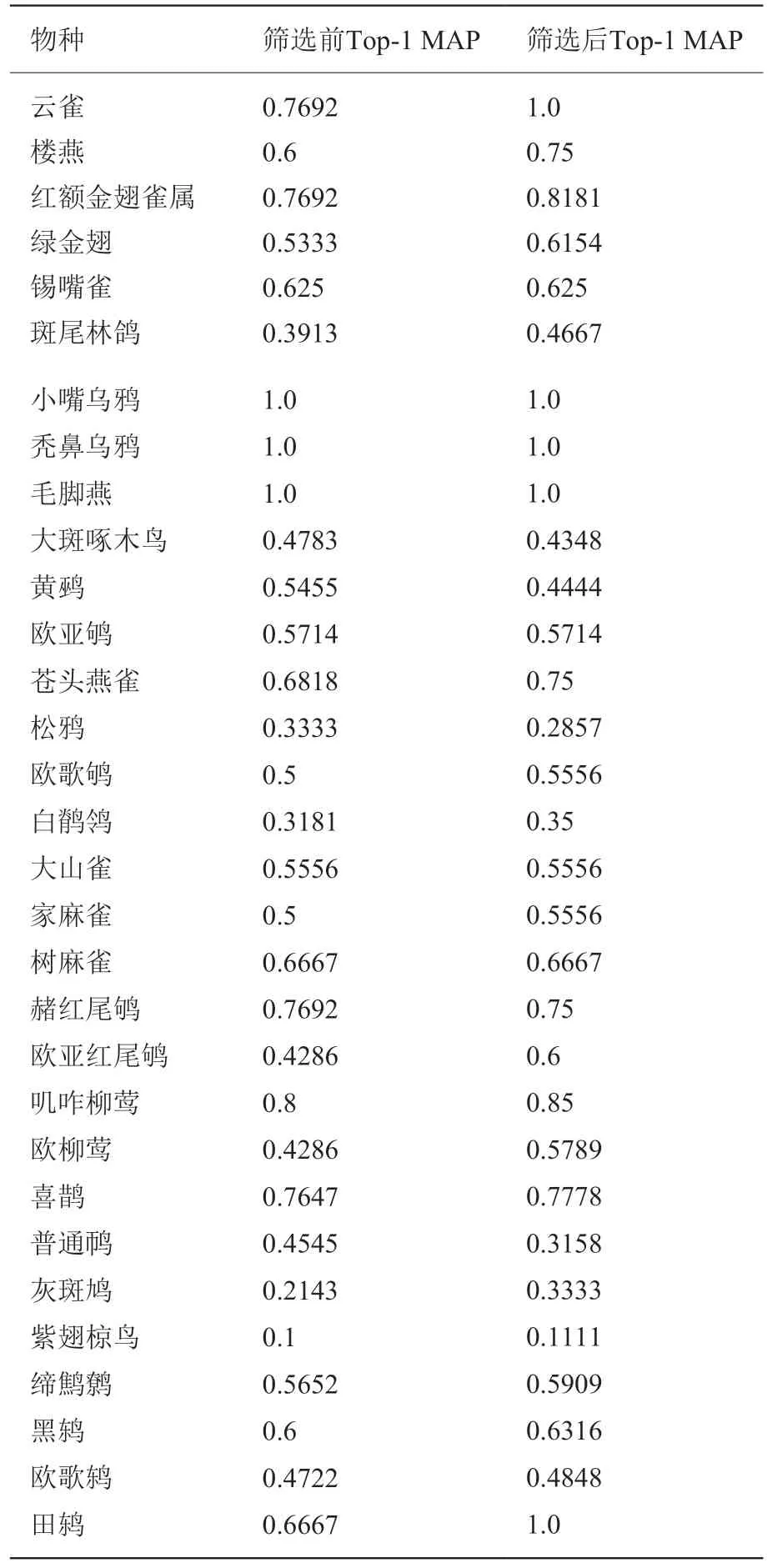
表3 筛选前后各个物种Top-1 分类准确率Table 3 Top-1 classification accuracy of each species before and after filtering
由表3 可知,经过频谱图筛选算法后,大部分物种的Top-1 MAP 都有所提高,其中云雀和田鸫两个物种的MAP 提高到了1.0。MAP 在0.7 以上的物种由8 种提高到了11 种。原本因为这些噪音频谱图预测错误的音频,在经过频谱图筛选算法处理后,获得了正确的预测结果,从而使得该鸟类物种的MAP 得到提高。
经过频谱图筛选算法处理后频谱图样本集在在分类模型种获得的分类情况混淆矩阵如图10 所示。
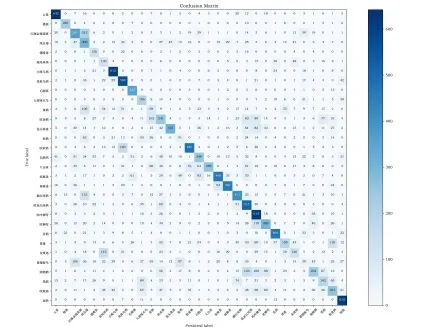
图10 频谱图筛选后分类混淆矩阵 Fig.10 Classification confusion matrix after spectrum filtering
通过观察混淆矩阵,发现红额金翅雀属有212张频谱图被错误预测为绿金翅,绿金翅也有47 张被错误预测为红额金翅雀属。通过查看两个类别音频的频谱图,发现这两个类别频谱图相似性大,音频也较为相似,区分难度较大,所以导致错误的预测。缔鹪鹩有153 张、100 张、88 张频谱图分别被预测为欧亚红尾鸲、叽咋柳莺和欧柳莺三个物种。在该物种的音频文件里面,混有这三种鸟类的声音,所以导致了错误的预测。经过本文频谱图筛选算法的处理,31 种鸟类物种的频谱图样本集减少了大量噪音频谱图,可是因为音频文件的质量不高,有些音频混合多种鸟类音频,有些鸟类之间叫声相似,还是会出现部分错误的预测。但是本文提出的频谱图筛选算法减少了非鸟类声音产生的频谱图,减少了鸟类的噪声数据,所以最终的预测和分类得到了更好的效果。
6 结论
鸟类音频的原始数据来自于自然环境,往往包含了风声、雨声和其他环境噪音数据,传统的音频降噪等方法对于音量较大的噪声难以去除。针对此问题,本文提出了一种基于鸟类音频频谱图的特征向量进行距离计算的数据清洗算法,这其中不仅高效使用了Faiss 算法快速计算特征向量之间的距离值,而且利用DBSCAN 聚类算法进行频谱图筛选,剔除了大量音量较大噪声产生的频谱图。实验证明,该方法可以从频谱图样本集中有效自动地筛选出噪音频谱图,保留有效的鸟类音频频谱图作为实验和测试的数据集,为后续进一步的鸟类物种识别提供了更高质量的数据集,有助于后续分析与评价,有较大的应用前景。
由于DBSCAN 算法聚类的效果受到邻域阈值(ε)和密度阈值(MinPts)参数的影响比较大,而这两个参数仍然需要人为去设定,这需要我们结合待分析数据的具体情况,尝试比较不同的参数组合以找到较为理想的聚类效果,这将会大大增加工作量。未来本文的研究方向应该去探索自适应的方法去获得邻域阈值(ε)和密度阈值(MinPts)这两个参数值。
利益冲突声明
所有作者声明不存在利益冲突关系。
