基于改进深度置信网络在医疗分类问题中的研究
2021-11-30蔡莉莉侯珂珂
蔡莉莉,侯珂珂
(1.中山大学新华学院生物医学工程学院,广州510520;2.中山大学新华学院健康学院,广州510520)
0 引言
分类问题作为数据挖掘和模式识别领域的重要问题之一,一直以来受到众多科研学者的广泛关注。在我们的生活实际应用中常常会遇到分类问题,最常见的如基于医疗数据集的疾病诊断问题,它是一种典型的分类问题。根据医疗仪器设备获取的疾病的生理指标数据,采用数据挖掘和机器学习算法可以构建出分类决策模型,从而实现对疾病类型的分类和诊断。
随着智慧医疗概念的提出,越来越多的人工智能算法技术被应用于医疗分类问题的研究中,用以辅助医生临床疾病诊断。杜权等人分别采用支持向量机、随机森林算法和1维卷积神经网络训练出心律失常检测模型,检测心律失常准确率高达97.17%[1]。苗丰顺等人提出了一种基于Cat⁃Boost算法的糖尿病诊断模型,取得了较为优异的预测结果[2]。神经网络具有强大的非线性映射能力,常用于分类问题研究中。吴燎将BP神经网络应用于中医疾病诊断中,实现了对高血压、胃病和冠心病的高效预测。王增辉构建出基于人工神经网络的心脏病预测模型,模型的分类准确率达到85.7%[3]。
医疗数据分类预测模型准确率的提高非常依赖模型能否有效挖掘出数据内在特征,将数据集的有效特征提取出来进行建模有助于改善模型分类精度。受限玻尔兹曼机(restricted boltzmann ma⁃chine,RBM)因为具有较为显著的特征表达能力,被广泛应用于神经网络中作为特征提取的有效手段[4]。2006年,Hinton提出由堆叠多个RBM构成的深度置信网络(deep belief network,DBN)架构,并将其应用于图像分类问题研究中,深度学习的概念由此被提出[5,6]。本文利用RBM强大的特征提取能力,在深度置信网络结构基础上进行改进,提出一种基于回归权的深度置信网络结构,并将其应用于医疗数据分类问题研究中。实验部分针对3个医疗数据集,分别利用改进网络结构和传统DBN网络进行预测,以验证其有效性。
1 改进深度置信网络结构
神经网络的参数学习算法一般使用反向传播算法,即BP算法。BP算法是一种经典的有监督学习算法,训练过程极度依赖有标签的样本数据。并且使用BP算法在训练过程中,其参数初始值通常采用随机初始化的方式获得,这种随机初始值很容易使得梯度下降寻优过程中陷入局部极值,导致结果较差。Hinton提出的深度置信网络是利用多个玻尔兹曼机进行堆叠形成的一种生成模型,利用RBM使用无监督算法训练的优势,不仅可以有效保留其优秀的特征提取能力,且预训练获得的参数可以作为BP参数寻优的初始值,从而提高收敛速度[6]。图1为RBM结构图,图2为由两个RBM堆叠形成的DBN示意图。
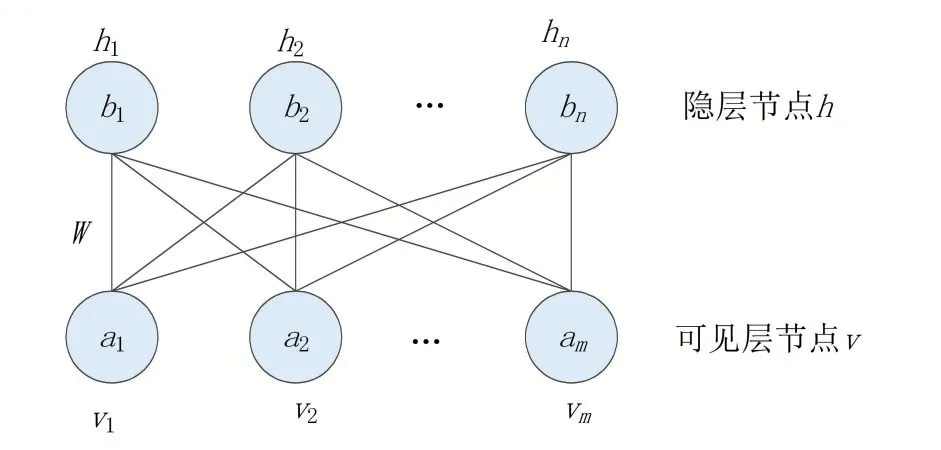
图1 RBM网络结构

图2 2个RBM构造的DBN结构
从图1中可以看出,RBM共包含两层:可见层和隐含层。观察RBM的网络结构可以发现,其层内节点间无连接,层间节点为全连接。图1中ai、bi分别表示可见层节点和隐含层节点的偏置,W为层间节点的连接权。可见层作为数据输入,可以为二进制数据或者实数型。RBM采用基于对比散度学习算法训练可见层和隐含层之间的连接权和偏置,使得RBM可以最大概率表征输入数据的分布特征[7]。图2描述了两个RBM堆叠构建DBN网络的过程。核心是将第1个RBM的隐含层的输出作为第2个RBM的输入层,通过逐个训练RBM内部层之间的连接权,就获得了权值的初始化参数。此种训练算法称为逐层贪婪预训练算法[8]。
为了在DBN网络基础上实现分类的目的,往往需要在网络后新增一个输出决策层,用于输出分类结果。一般情况下,输出层与上一层的连接权默认采用常数权。在此基础上,本文考虑将回归权系数作为最后输出层与上一层的连接权,而其他层的权值仍为常数权形式,在少量增加网络训练复杂度的情况下,以提高网络的泛化能力,如图3所示。
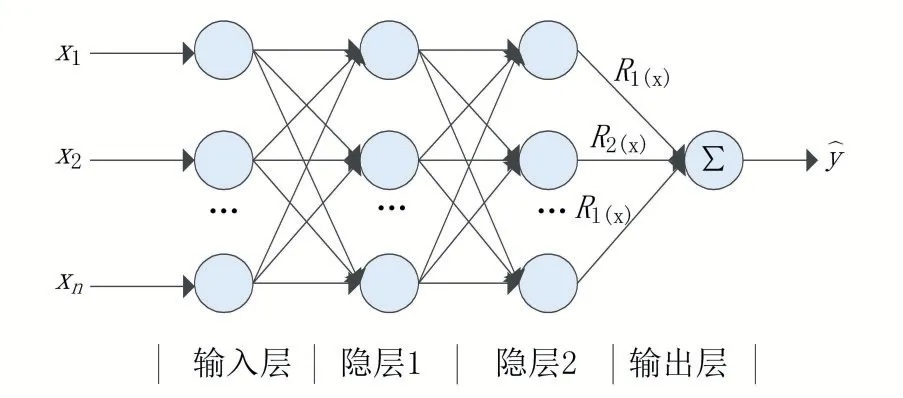
图3 基于回归权的改进DBN结构
假设输入x=(x1,x2,…,xn),隐层2的节点个数为l,其第k个节点的输出值为Hk。则有回归权系数表达式如(1)所示,决策层的输出如式(2)所示。
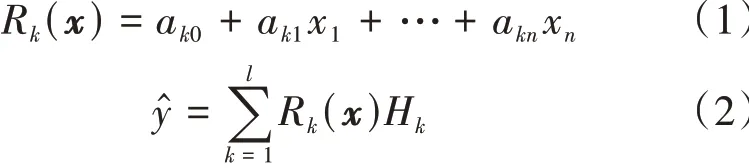
这里aki(i=1,2,…,n)表示各回归权值的系数因子。
针对上述改进网络的学习算法包括如下两步:
(1)基于训练数据使用逐层贪婪预训练算法逐个训练RBM,获得DBN网络权值的初始化参数。
(2)在初始化参数的基础上,利用BP算法进行全局调优,其中输出层的回归权系数因子使用最小二乘法计算,其他各层的权值参数寻优使用梯度下降算法调整。
2 基于改进DBN结构的医疗数据建模
2.1 数据集介绍
本文选用UCI机器学习库中常用于分类研究的三个医疗数据集进行建模分析。他们分别是Wisconsin Breast Cancer数据集、Heart Disease数据集以及Mammographic masses数据集。其中Wis⁃consin Breast Cancer数据集和Mammographic mass⁃es数据集均为乳腺肿瘤图像样本数据集,可用于预测乳腺肿瘤的良恶性类别。Heart Disease数据集是一组病人体质数据,可用于预测患者是否患有心脏病。
Wisconsin Breast Cancer数 据 集 共 有569个 样本数据,无缺失数据,其中良性样本357例,恶性样本212例。该数据集具有32个属性,其中前两个字段为病例编号和肿瘤良恶性标签值。本文中用于建模的特征为30个,记录了肿瘤病灶组织细胞核半径、周长、面积、平滑性等10个特征量的平均值、标准差和最差值。Mammographic masses数据集共有961条数据,样本中含有缺失数据,剔除缺失数据样本后,共有830条数据。该数据集提供了X射线照射乳腺肿瘤组织影像获取的肿瘤形状、密度、BI-RADS评级标准值以及病人年龄等5个输入特征,最后一列记录了良恶性类别。该样本集共包含良性样本427例,恶性样本403例。Heart Disease数据集含有303条数据,无缺失值,包含患病样本138例,未患病样本165例。每个输入样本记录了病人的年龄、性别、血压、血糖、胆固醇及心电图相关的数据共计13个。针对各数据集中包含的值域比较分散的属性,在下文进行建模时分别进行了归一化的操作。
2.2 模型构建
为了对比改进DBN网络结构是否能有效改善分类模型的泛化能力,针对以上三个医疗样本数据集,分别构建出普通DBN结构预测模型和回归权DBN结构模型进行对比分析。网络结构均采用由两个RBM堆叠形成,各层网络节点个数通过粒子群优化算法确定。参数初始化阶段训练RBM采用对比散度快速学习算法,这里的学习率设定为0.1,迭代次数为50次。全局参数调整阶段使用梯度下降算法进行调优,损失函数为均方误差。学习速率设定为0.1,迭代次数为500次。
模型评价指标采用分类模型常用指标,包括分类准确率、查准率、查全率和F1分数,定义公式如式(3)—式(6)所示[9]。

这里,TP表示样本真实类别为正例,且预测为正例的样本个数,TN表示样本真实类别为负例且预测为负例的样本个数;FN表示样本真实类别为正例但被错判为负例的样本个数;FP表示样本真实类别为负例但被错判为正例的样本数。
本文中为了方便对比,将良性类别记为P,恶性类别用N表示。
3 实验与分析
针对以上3个医疗数据集,分别构建出基于常数权的DBN网络和基于回归权的DBN网络分类模型。实验中训练集和测试集的数据划分比例均为7∶3。另外,为了减少训练随机性对模型性能的影响,性能指标皆取10次仿真结果的平均值。由此得到三个数据集中各测试集的性能指标结果分别如表1、表2、表3所示。

表1 Wisconsin Breast Cancer实验结果对比
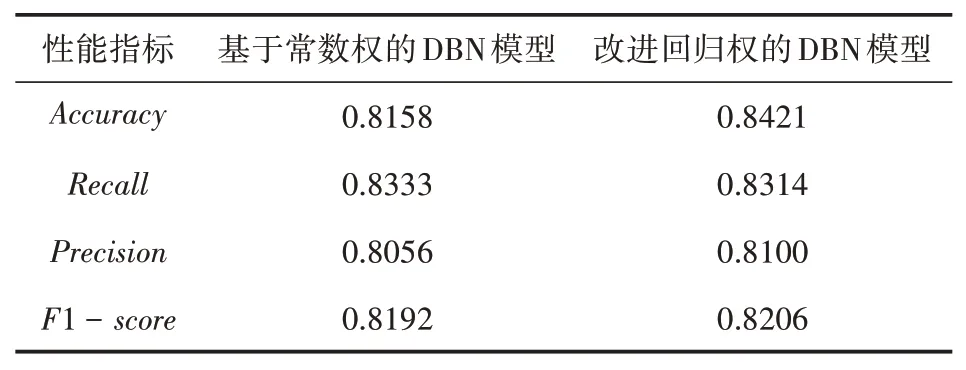
表2 Heart Disease实验结果对比
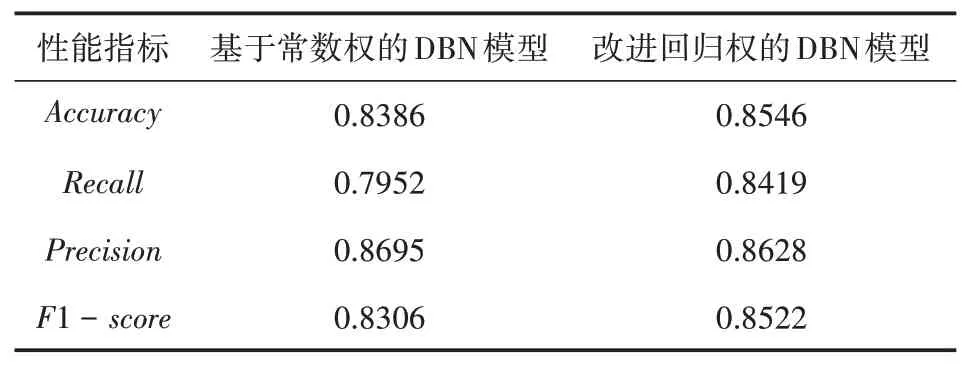
表3 Mammographic masses实验结果对比
由表1—表3的仿真结果可以看出,采用改进回归权的DBN网络构建的分类模型在分类准确率和F1分数上较之原始DBN网络结构均有一定提升。且各分类模型的性能指标值均达到80%以上,其中在Wisconsin Breast Cancer数据集上的分类准确率高达96.7%,取得了较好的预测效果。
4 结语
本文在原始DBN网络结构的基础上,提出一种改进回归权的DBN网络结构用于实现对医疗数据分类问题研究。借助于RBM强大的特征提取能力,实现对高维医疗数据特征的有效挖掘,从而构建出性能较为优异的决策模型。在三个医疗数据集上的仿真结果表明,改进权值的DBN网络结构较之原始DBN结构在各性能指标上均有一定程度提升。因此,未来将考虑进一步优化网络结构和模型参数,并将该模型应用于更多的医疗数据建模问题中,为临床医生提供辅助决策。
