基于SVM的入侵检测识别系统
2021-11-30吴荻高大鹏
吴荻,高大鹏
(中国民用航空飞行学院计算机学院,广汉618300)
0 引言
互联网和移动互联网的普及,使得网络在生活中产生了巨大的作用,网络电子渠道成为目前为止人们获取外界信息最有效且最重要的方式。2018年公布了中国互联网使用情况统计,截至2018年6月30日,中国网络用户数目达到了80200万,在2018前半年新增网络用户2968万。与2017年比,增长了3.8%,移动网络的覆盖率达到了57.7%,人类生活的便捷度得到了巨大的改善。移动互联网的发展,推动了网络信息的传播,但也同时出现了一些安全问题。正因为网络信息是开放的、无国界的、公共的,因此如何守护网络的信息安全问题就成了一个严峻的挑战。
入侵检测系统是一种通过实时监测网络环境访问数据,以此确定合法访问和入侵活动。由于网络的快速发展导致网络环境中各种数据量急剧增加,网络环境复杂,计算机更容易受到攻击,比如用恶意代码对信息进行修改,窃取、揭露等。老式的检测技术依赖于大量的人力,时效性较差,防御未知入侵技术的能力也不出众,因此在现代检测技术中就更需要提升检测算法的高效性。机器学习算法是通过“学习”模拟人类的学习行为来检测未知攻击,因此在传统检测技术的基础上引入机器学习算法会更加适配现代复杂的网络环境。
1 支持向量机(SVM)
SVM是一种优秀的二分类算法,它是建立在统计学习理论和机构风险最小化原理的基础上,解决了很多传统机器学习算法中出现的过度拟合、维数灾难、低位模式等问题,在很多特殊问题上有独有优势,比如非线性、小样本和高位模式等问题。SVM算法的分类决策中最重要的一个部分就是支持向量,广义支持向量机分为线性可分和线性不可分两种。
1.1 线性可分SVM
假设解决一个分类问题,如果只有二维的特征向量,需要将正常访问的用户和恶意访问的黑客区分开来,如果可以只通过一个直线(或一个平面)区分,那么这个分类问题就是一个线性可分问题。这个区分的直线也可以是一个超平面,支持向量就是距离超平面最近的样本。
为了解决线性可分性问题,假设训练数据的样本量为l,该样本可以表示为{(xi,yi),i=1,2,3,…,l},训练数据样本集分为两个类别,如果xi为第一类,则yi=1;如果xi为第二类,则yi=-1。
假设有一个超平面的分类ωx+b=0。样本可以准确的分为两类,将不同的种类分别打入超平面的两侧,使得数据集线性可分。即对于(xi,yi)∈D,若yi=1,则 有ωTxi+b>0;若yi=-1,则有ωTxi+b<0。
样本空间中任意点到超平面的距离为r=
如图1所示,H即为判别类型的超平面,黑白两色的圆圈代表两个样本。若则黑白两种数据样本点之间的间隔是
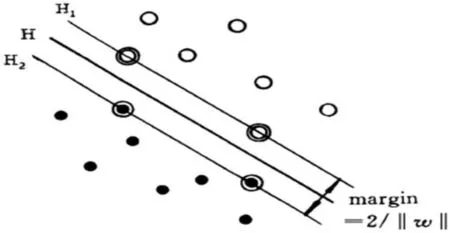
图1 线性可分SVM
1.2 非线性可分SVM
在解决实际问题的时候,在大多数的情况下,样本是不能完美的线性分开的,因此要使用非线性向量机来解决这个问题,升级到更高的平面进行区分,例如二维平面不能区分就升级到三维平面甚至更高。简单讲就是分为两步,第一步升高维度(样本空间向高维映射),第二步线性化。但是在升维的过程中,会出现新的问题,比如计算复杂度会增加,或者会引起维数灾难。而SVM会巧妙地解决升维带来的计算复杂化的问题,升级维度的依据就是核函数。
核函数种类决定了SVM的区别,常用的核函数有以下4种:
(1)线性核函数K(x,y)=x∙y。(用于线性可分的情况,没有需要专门设置的核函数,计算速度快)
(2)多 项式 核 函数K(x,y)=[(x,y)+r]^d。(低维空间映射到高位空间,参数多,计算复杂度高)
(3)径向基函数K(x,y)=exp(-|x-y|^2d^2)。(应用最广的核函数,将样本映射到高维空间,参数较少)
(4)二 层 神 经 网 络 核 函 数K(x,y)=tanh(a(x,y)+b)。(实现的是一种多层神经网络)
需要对数据有一定的研究和先验知识才能选出合适的核函数,利用先验来选择复合数据分布的核函数,如果无法选择的话,通常有两种解决办法:①交叉验证,使用多种不同的核函数运算出预测结果,选择误差最小的即为最优核函数;②混合核函数,通过结合多个基本核函数,形成混合函数,再加载数据运算。由于用的是核函数展开定理,在实际编写中不需要知道非线性映射函数的线性表达式,而且在维度空间中建立的线性学习机,因此与线性模型相比会在某种程度上避免维数灾难,而且几乎不会增加计算的复杂性。
当Φ:Rn→D,原输入空间的样本数据被映射到高维空间D中寻找最优平面。
支持向量机的学习策略是间隔最大化,即正则化的合页损失函数的最小化问题,也就是一个求解凸二次规划的问题,所以SVM算法实际上是一种为了达到最小化风险的一种最佳算法。
图2 线性不可分SVM
2 入侵检测数据集
2.1 KDD99数据集
数据集与算法是网络安全入侵检测中不可缺少的两部分。著名计算机科学家、PASCAL语言的创始人Niklaus Wirth说,“程序=数据结构+算法”,而在入侵检测领域“入侵检测数据挖掘=算法+数据集”。很多时候数据比算法更重要,算法需要数据才能得到结果的验证。
本文在实验中选用的是由麻省理工学院林肯实验室在1998年模拟真实的军事网络访问环境得到的500万条KDD99数据集。与原始网络访问记录相比,此数据集已经是经过去除重复访问记录等预处理之后得到的数据集,相比原始集,KDD99只包含了网络流量统计特征
KDD99数据集是以CSV格式记录,除了本来的500万条数据外,还有一个10%的训练子集和测试子集。本文采用的是10%的训练子集作为分析对象。10%的数据自己包括了494021条数据,每一条数据都由1个标签和41个特征(TCP链接的基本特征,TCP链接的内容特征,基于时间的网络流量统计特征,基于主机的网络流量统计特征)构成,每一行有42项。其中前41项特征分为四个大类。
2.2 数据异常类型
数据集中每一行包含了1个类标识和41个固定的特征,一共42项,9个离散项,33个连续项。
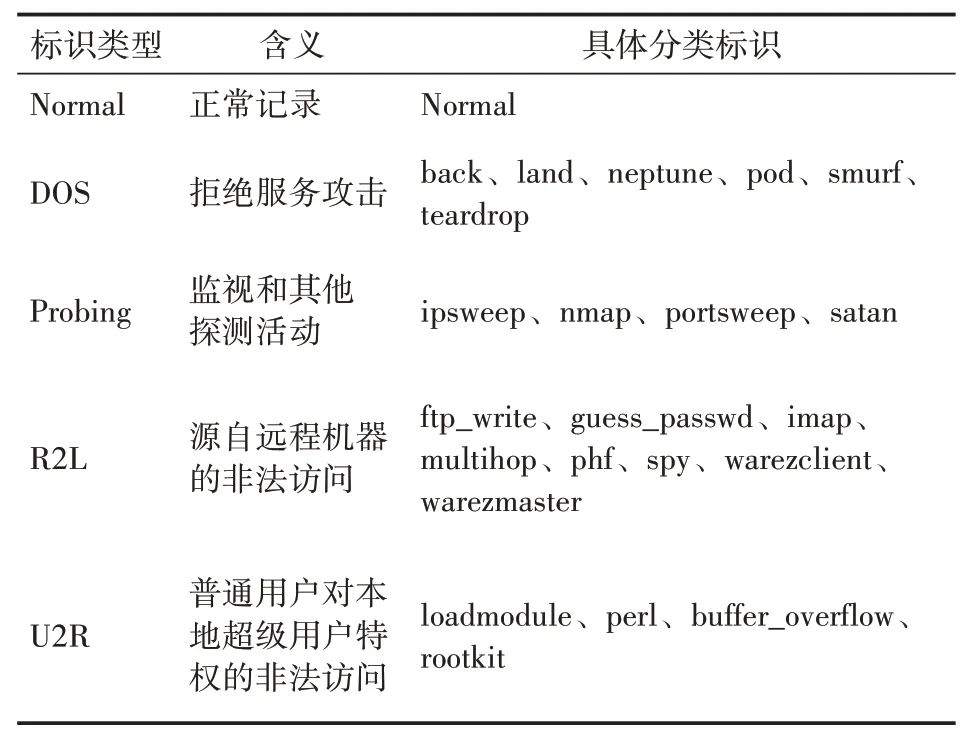
表1 数据异常类型
3 实验步骤与分析
3.1 数据预处理
原本的KDD99数据集中一部分标签是以字符串形式记录的,在SVM程序运行时,字符串和数值型一起处理时并不方便,因此对数据集做预处理。预处理的方式有很多种,比如统一将字符型和数值型全部化为二进制字符串,其优点是方便在结果中看到原本的标识类型;或者直接将数据集中的字符型特征转化为数值型特征(即符号特征数值化)。数值化会更加方便后续的数据处理。因此本文也使用数值化的方法进行预处理。数值化大致分为以下4个部分:
(1)源文件行中3中协议类型转换成数字标识;
(2)源文件中70中网络服务类型转换成数字标识;
(3)11中网络连接状态转化成数字标识;
(4)5大类型转换成数字标识,把未知攻击分入一个类型,单独标记。
3.2 样本分析
KDD99数据集数据量大,属性多,时间复杂度高。它是在DARPA98数据集中将部分数据,比如DoS攻击后产生的大量重复记录删除后,在KDD99中只提取了5分钟之内的记录写入。它的样本类别如表2所示。
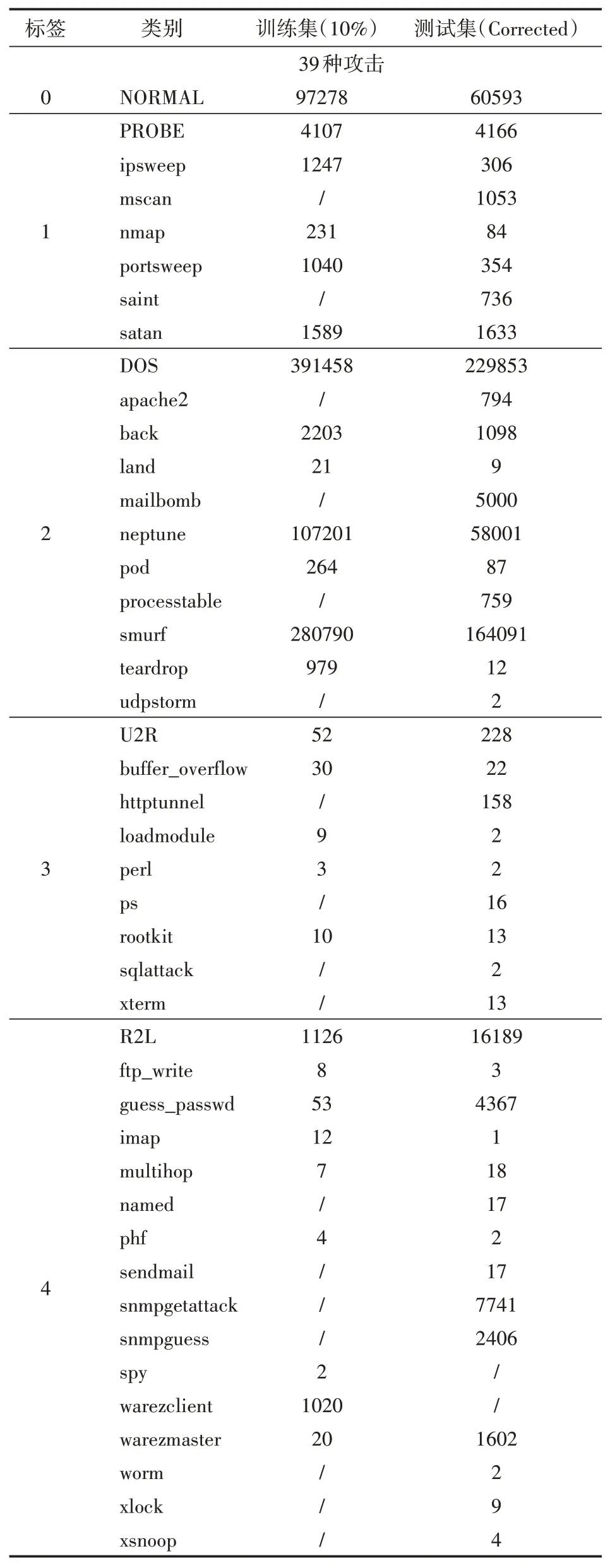
表2 样本类别
为了检测入侵检测系统的好坏,需要用未知的攻击来确定,因此在KDD99数据集存在39小类攻击类型中,训练集只出现了22种攻击类型,剩下的17只在测试集中出现的攻击类型对于训练集来说就是未知的攻击类型,以此划分来实现用一个数据集就可以检测系统对未知攻击的检测力。
3.3 数据集划分
为了进行交叉验证,减少过拟合风险,本文按照4∶1的比例,对训练数据集随机划分为训练集(Train)和验证集(Validation)。
X_train,X_val,y_train,y_val=train_test_split(X,Y,test_size=0.25)
由此分开的数据集,目标变量Y的分布大致相似,如表3所示,划分后的数据集中,某几种标签的比例大致相似。

表3 划分后的数据集中各标签的比例
3.4 特征设计与处理
如前文所示,数据表总共有41个特征,其中protocol_type、service、flag是 取 值 数 分 别 有3、70、11的三种离散特征,其余均为连续型数值特征。在SVM模型中,需要计算样本间距,离散型的取值无法直接进行距离计算。为了解决这个问题,在数据处理中对离散型的特征数据进行One-Hot编码,使每个整数都用二进制表示,除了整数索引标记为1之外,其余都用0表示,使得特征的计算更为合理。
在对KDD99数据集数值化预处理的过程中,是用不同的整数数值来代替不同的特征类型,因此用的数值大小不一样就会对模型、对不同特征的敏感度不一样,比如一个特征用数值1代替,另一个特征项用数值100代替,则用100代替的特征项就会对结果产生更大的影响,不利于模型收敛。因此需要将数值特征归一化,各个特征大小范围一致就可以使用距离度量等算法。在sklearn中,是默认把数值归一化到[0,1]或者[-1,1]之间,因为不同的机器学习算法所需要的数值范围不一样,因此在实际应用中可以通过调参来实归一化后的数值大小固定在某一区间之内。归一化后能加速梯度下降算法的收敛速度,在SVM算法中,一致化的特征能加速寻找支持向量的时间。
本文程序中,特征处理的主要代码如下所示:

3.5 模型训练
SVM有多种参数,包括核函数、正则化系数等。可以使用交叉验证调参选择最优参数让结果达到最理想的结果,在本文中使用train_test_split()函数将训练集随机划分成“用于训练”和“用


4 实验结果
经交叉验证进行参数调优,模型的预测精度可以达到99.9%,所使用的参数为:

通过设置交叉验证集,还可以绘制混淆矩阵,将结果以表格化的形式展现出来,它是一种可视化工具,使得模型验证结果更加明了。每一列标识预测类别,每一行表示数据真实归属类别;每列总数是预测为该类别的数据个数,每行数据总数是该类别的数据实例的数量。在sklearn中,已经内置混淆矩阵的API。使用matplotlib,将混淆矩阵可视化:

如图3所示,混淆矩阵会清晰的反应出模型的检测能力,该模型对于大多数的类别预测都有很高的准确率。对于个别类显示分类准确率不正常,因为其所对应的样本只有两三个,增加所对应的样本即可。
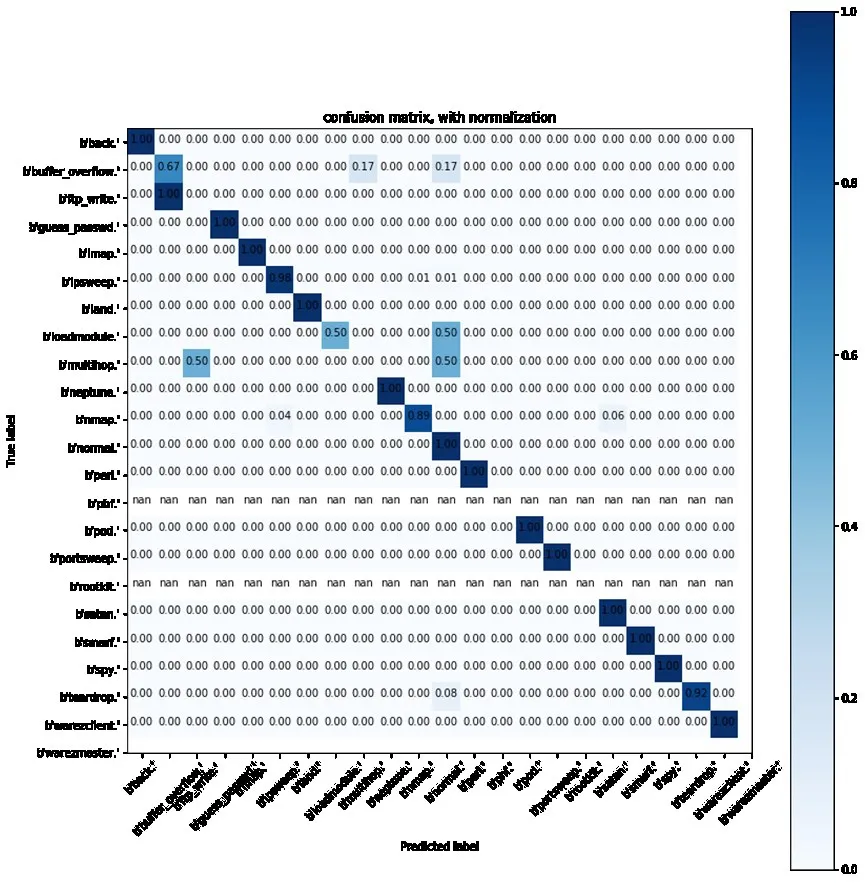
图3 混淆矩阵
5 结语
SVM算法本身具有处理小样本、高维度、非线性分类的特点,把SVM算法应用在入侵检测当中,可以发挥它的特点,克服目前入侵检测技术中,如运行速度较慢、检测准确率比较低、实时性较差等明显缺陷。但是,SVM在基于网络的入侵检测系统的实际应用中,仍然有很多需要完善和提高的地方,如核函数的选择参考问题、高维数据如何有效降维,等。
