基于改进型C3D 网络的人体行为识别算法
2021-11-29席志红冯宇
席志红,冯宇
哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001
随着计算机视觉和人工智能领域的不断发展,越来越多的先进设备投入到人们的生产生活当中,给人们带来了巨大的便利。人体行为识别是计算机视觉领域的重要分支,该技术在视频监控、医学健康、智能家居、体育运动以及虚拟现实等领域应用极其广泛。传统的行为识别方法采用时空兴趣点[1](space-time interest points,STIP)表示人体局部时空特征进行姿态识别。Wang 等[2]将加速健壮特征 (speeded-up robust features,SURF)与光流特征结合,提出改进密集轨迹算法进行人体姿态识别。由于传统的识别方法大部分需要人工提取特征,所以较为耗时耗力。随着2012 年Hinton 等[3]提出深度卷积神经网络,不少研究人员把目光转向了卷积神经网络。Ji 等[4]首次提出基于3D 卷积网络结构的人体姿态识别方法。Tran 等[5]提出了C3D网络,通过系统化地研究找到了3D 卷积最合适的时序卷积核长度。丁红等[6]提出基于DBN 深度信念网络的人体行为检测系统。韩雪平等[7]则将人体局部信息与全局信息相结合提升整体识别率。黄潇逸[8]提出一种骨骼关节点投影特征并采用支持向量机进行分类识别。叶青等[9]采用3D 卷积层搭建DenseNet 来提高网络中的特征利用率。M.Kocabas 等[10]提出一种3D 人体姿态估计的自我监督学习方法。Li 等[11]提出动态尺度图神经网络(dynamic multiscale graph neural networks,DMGNN)来预测基于3D 骨骼的人体运动。Zhang[12]提出了一种上下文感知图卷积网络(CA-GCN) 用于骨骼的人体姿态识别。由于C3D 网络能直接提取时空特征,并且结构由3D 卷积层和3D 池化以及全连接层简单堆叠而成,所以结构比较简单,广泛用于视频的人体行为识别研究[5]。但是原始C3D 网络的参数较为巨大,不利于模型迁移,并且识别率还有待提高。所以本文提出基于改进型C3D 网络的人体行为识别算法,该算法从卷积核以及网络结构入手,对模型尺寸进行压缩并且进一步提高在视频数据集中的识别率。
1 C3D 神经网络
1.1 C3D 网络结构
原始C3D 网络采用3D 卷积和3D 池化,并且由8 个通道分别为64、128、256、256、512、512、512、512 的3D 卷积层、5 个3D 最大池化层、2 个神经元为4 096 的全连接层以及softmax 分类器构成。Tran 等[5]经过大量实验证明3D 卷积核尺寸为(3×3×3)时会使得整体性能达到最好,所以原始C3D 网络中所有3D 卷积层中的3D 卷积核尺寸均为(3×3×3),步长以及填充(padding)均为(1×1×1),则经过该3D 卷积层的输入和输出的尺寸均未改变,尺寸的改变均由3D 最大池化操作进行。但是为了避免由于过早地丢失时间信息而造成识别精度的下降,所以仅有第1 层的3D 最大池化内核尺寸为(1×2×2),步长也为(1×2×2),padding 为0,其余3D 最大池化内核尺寸以及步长均为(2×2×2),该网络整体结构以及尺寸大小如图1 所示。
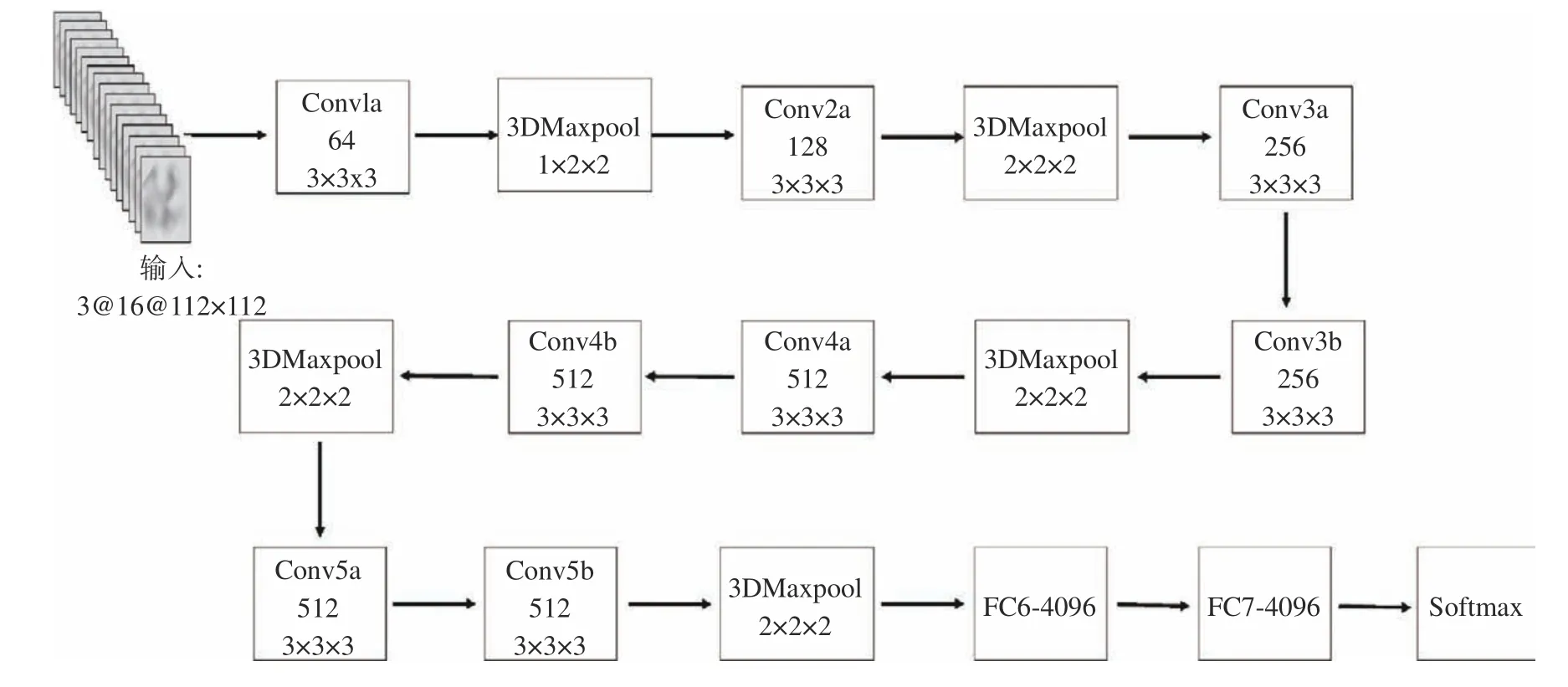
图1 C3D 神经网络结构
1.2 C3D 网络输出特征
该原始网络的输入尺寸为(3×16×112×112),可以写成通用形式为(c×l×h×w),其中c为图像通道数,l为视频帧长度,h为视频帧的高度,w为视频帧的宽度。3D 卷积滤波器内核尺寸可以写为(d×k×k),其中d为3D 卷积内核的时间深度,k为3D 卷积内核的空间大小。该输入通过1 个数量为n、内核尺寸为(3×3×3)、步长以及padding均为(1×1×1)的3D 卷积滤波器,则输出的特征图尺寸为(n×l×h×w),并且在该原始网络中使用的优化算法为随机梯度下降(stochastic gradient descent,SGD),激活函数为修正线性单元[13](rectified linear unit,ReLU),并为防止过拟合现象而采用了Dropout 正则化方法。
2 本文结构设计方法
2.1 优化算法及激活函数
以往的优化算法常采用SGD,虽然该优化算法在计算梯度时随机选取一个样本更新梯度使得训练速度增快,但是SGD 会引入更多的随机噪声,使得准确度下降,在某些情况下还会陷入鞍点容易收敛到局部最优,并对学习率的选择较为敏感。考虑以上问题,本文采用另外一种改进型的梯度下降算法,即Adam 算法。该算法结合了动量和RMSProp算法的特点,能够为不同的参数计算不同的自适应学习率,并且能够快速跳出鞍点以及快速收敛,同时还能够解决梯度稀疏和噪音大的问题。目前最常用的激活函数为ReLU,由于该激活函数计算简单,并且计算过程中部分神经元为0,使得网络具有稀疏性,缓解过拟合现象,在反向传播过程还会解决梯度消失的问题,所以被广泛应用在各种网络结构中。但是该激活函数会造成神经元“坏死”,最终导致相应参数永远不会更新,而且ReLU 还缺乏概率解释,一些随机正则化能够让网络更好地提升精度,所以本文采用与随机正则化有关的新一类激活函数,即高斯误差线性单元[14](gaussian error linear unit,GELU),如图2 所示,其中该激活函数的输入x为输入信号加权及偏置总和,y为x经过GELU 激活函数的激活值,并且文献[14]中已经证明在多个任务实验里GELU 的激活效果要优于ReLU 的激活效果。
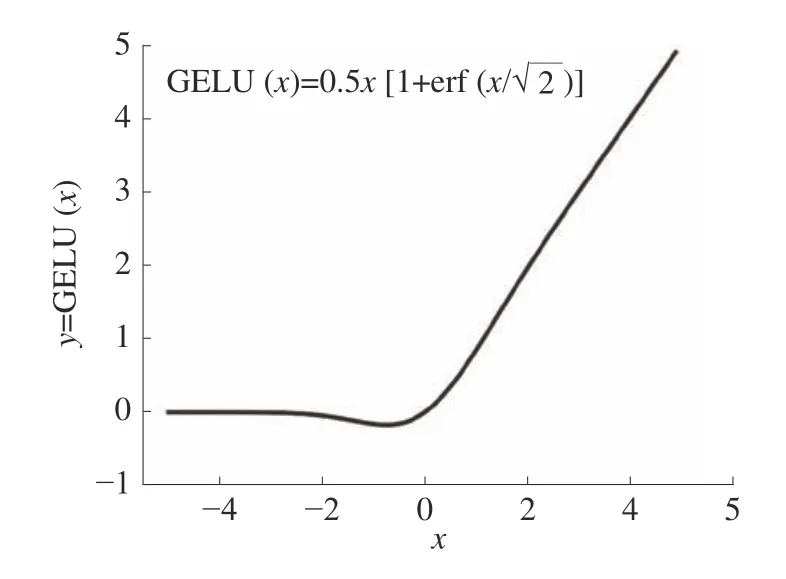
图2 GELU 激活函数
2.2 全局平均池化替代全连接层
在传统卷积神经网络中,全连接层往往处于整个网络结构的末尾,如图3 所示。用于将经过最后一层卷积层输出的特征图转换为一维向量,并且该层的每一个神经元都与上一层的每个神经元连接,即把前一层的所有输出特征全部综合起来,达到输出特征高度提纯的目的,有助于更好地识别有效特征。但是对输出特征综合的同时,该层的权重参数数量也是最多的,并且由于巨大的参数量则容易造成训练速度降低和过拟合现象发生。所以本文采用全局平均池化(global average pooling,GAP)来代替全连接层,如图4 所示。该方法在NIN 网络[15]中被提出,由于它不需要神经元而是直接对输入特征做下采样,得到的图像输出尺寸为(1×1×1),所以能够减少大量参数,并且可以避免在原始C3D 网络中因输入不同图像尺寸所带来的问题。它还可以对卷积层输出的每个特征图进行加权平均,使网络具有全局感受野避免损失空间位置信息,该方法还对整个网络的结构进行正则化防止过拟合现象。
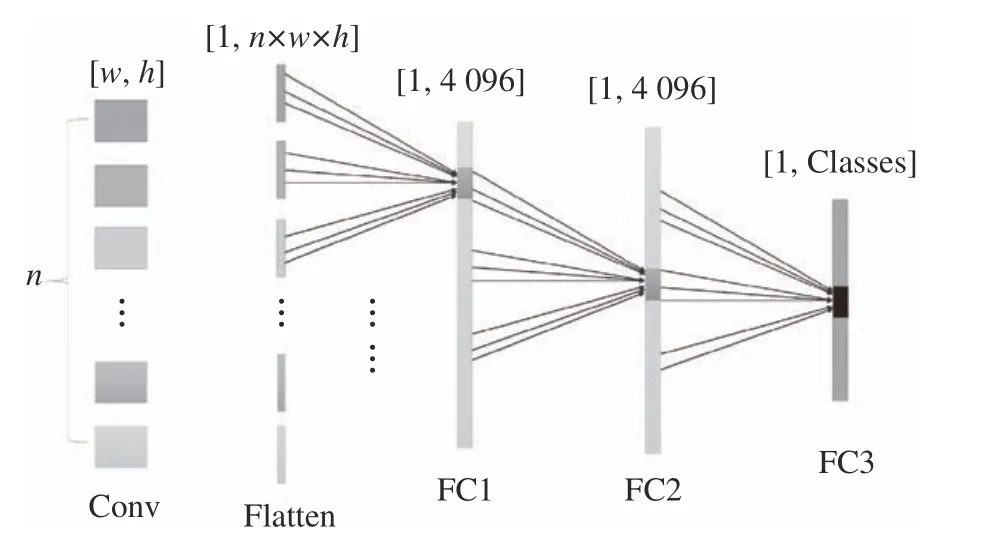
图3 全连接示意
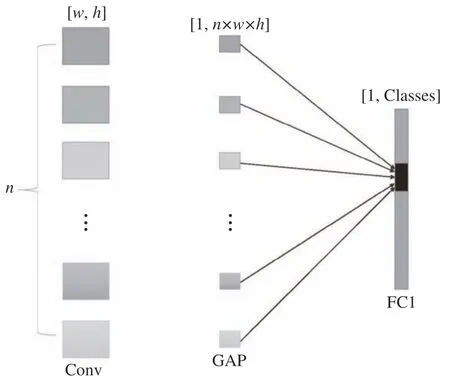
图4 全局平均池化示意
2.3 引入三维点卷积层及批归一化
在输入特征经过全局平均池化层后,需要将其输入到最后的分类全连接层中,并经过softmax分类器以输出类别得分。但考虑到全连接层会破坏视频帧图像的空间结构信息,所以在本文结构中引入三维点卷积层,即用(1×1×1)的三维点卷积核构成的三维卷积层作为分类卷积层来代替该全连接层,并实现了全卷积的网络结构。点卷积即卷积核为(1×1),最早出现在NIN 网络[15]中,用于加深网络结构并构建MLP卷积层。本文受到VGG网络[16]启发,采用堆叠卷积核为(3×3×3)的三维卷积层以及三维点卷积层来提高网络表达能力。本文结构中的三维点卷积层位于卷积核为(3×3×3)的三维卷积层之后,可以对三维卷积提取的时空特征进行网络通道间的跨通道组织信息,即用以通道之间的信息融合,并且增加卷积层可以加深网络,提高网络模型的非线性以及增加更多的特征变换来获取更深层次的有效行为特征,该方法能够有效地提高模型识别精度。由于本文是全卷积网络形式结构,所以去掉了原有的Dropout 正则化操作,但为能够更好地加快网络训练和收敛速度,并进一步有效防止过拟合以及梯度消失和梯度爆炸现象发生,本文引入批归一化处理[17](batch normalization,BN) 操作来对网络进行正则化处理。
2.4 卷积核合并
由于在网络结构中增加了卷积层和BN 层,则在提高网络识别能力的同时参数的数量也有所增加,所以本文采用了卷积核合并的方式减少网络参数数量。在Inception-v3 网络[18]文献中提到2 种卷积核分解方式:1)分解为较小卷积,例如将1 个(5×5) 的卷积核可以分解为2 个(3×3)卷积核。2) 空间分解为非对称卷积,例如将1 个(3×3) 卷积核可以分解为(1×3) 卷积核以及(3×1)卷积核。根据第1 种分解方式可知3 个(3×3)的卷积核可以合并为1 个(7×7)的卷积核,如图5所示。由第2 种分解方式可知1 个(7×7)的卷积核可以拆分成(1×7) 以及(7×1)的2 个非对称卷积核,如图6 所示。所以本文将结构中的3 个(3×3×3) 的三维卷积核合并成(3×1×7) 和(3×7×1)的2 个非对称三维卷积核。这种非对称形式的拆分能够节约大量参数,并且其结果要好于对称地拆分为几个相同的小卷积核,这种拆分结构能够处理更多以及更丰富的空间特征,能够增加特征的多样性,加快运算速率和减轻过拟合。改进型C3D 网络整体结构如图7 所示。
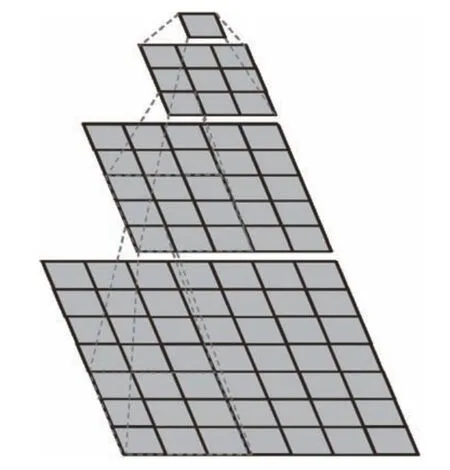
图5 合并(7×7)卷积示意
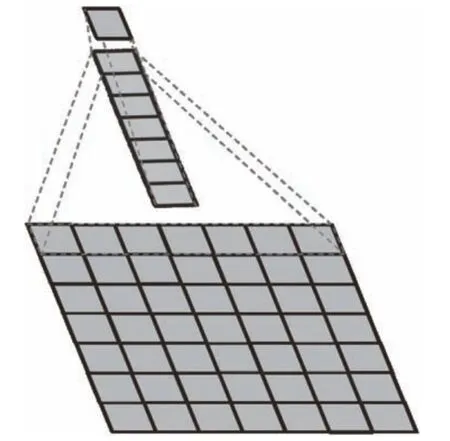
图6 拆分(7×7)卷积为非对称卷积示意
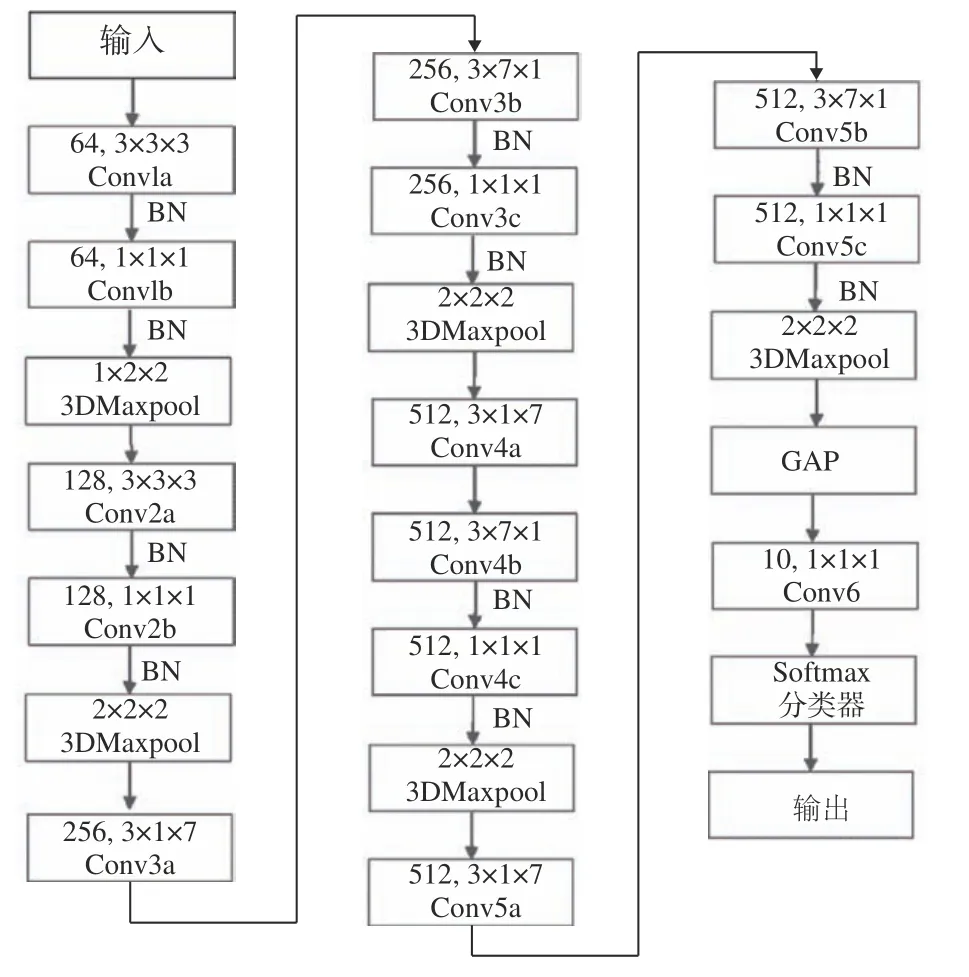
图7 改进型C3D 网络整体结构
3 实验与结果分析
3.1 实验环境
本文人体行为识别改进算法研究实验所采用的实验设备是Intel Core i7-8 700 CPU,主频为3.2 GHz,内存为16 GB,硬盘为1 T,GPU 为Nvidia Tesla T4,GPU 显存为16 GB。操作系统为Ubuntu16.04,编程语言选择Python3.7,深度学习框架采用PyTorch1.6.0,主要依赖库为Cuda10.1、Cudnn7.6、OpenCV4.4、Pillow7.2、NumPy1.19.2、Matplotlib3.3.2。
3.2 视频行为识别数据集
本文使用的人体行为识别数据集为UCF101和HMDB51,这两类数据集是目前被广泛使用并公认的人体行为识别算法基准数据集。UCF101数据集包含101 个类别,13 320 个视频剪辑,每个类别的剪辑视频数量都不小于101 个视频,并且每个视频的长度大多在2~10 s 之间,每个视频的空间分辨率为 3 20像素×240像素,帧速率为25 帧/s,该数据集的整体时长超过27 h,由于该数据集中的视频大多包含摄像机的运动、背景混乱、部分遮挡、光照条件差以及低质量帧的情况,所以在行为识别任务中具有一定的挑战性。HMDB51 数据集包含51 个类别,一共有6 766 个剪辑视频,每个类别至少包含101 个剪辑视频,每个视频的空间分辨率为 320像素×240像素,帧速率为30 帧/s,该数据集涉及到摄像机运动的有无、摄像机的不同拍摄角度、动作中的人员数量不同以及视频帧的质量不同等情况,所以该视频数据集同样具有挑战性。
3.3 输入数据预处理
首先,将视频数据集按照每隔4 帧截取1 帧的形式将视频转换为帧图像,但部分短视频无法按照此间隔数让网络架构的输入时序长度达到16 帧,则针对这部分较短视频可自动降低采样步长直到满足最少16 帧的要求,这样均匀采样后的视频帧序列能够比较好地代表整个视频的行为变化情况。在转换为帧图像的同时,将整个数据集按照比例为6∶2∶2 的形式分为训练集、验证集以及测试集,并将帧图像转换为1 71像素×128像素保存到指定位置。在网络输入数据过程中,为提高模型精度以及增强模型稳定性,将输入尺寸为171像素×128像 素的图像帧随机裁剪为112像素×112像素,并通过在以上数据处理生成的视频帧中指定选择网络输入视频帧的起始位置,然后在该位置采用一个滑动窗口选取16 帧的网络输入视频帧,则网络输入尺寸为(3×16×112×112),并且还对每个输入数据进行概率为0.5 的水平翻转以及沿着图像帧RGB 三条通道分别做均值减法操作来进行数据增强。
3.4 实验超参数设置
本实验中网络的迭代周期(epoch) 为50 次,学习率(learning rate)初始设置为0.000 01,并且每迭代10 次学习率将以0.1 进行衰减,每次训练采用的批量大小(Batch_size)为8。
3.5 UCF101 实验结果分析
本实验通过在UCF101 数据集进行训练,总训练时长大约为18.5 h,训练的epoch 为50,准确率变化曲线以及损失变化曲线分别如图8、图9所示,最终识别准确率可达到86.4%,原始C3D 网络模型在本实验中达到的准确率为77.5%。可见本文改进方法可以有效改进准确率,并且本文改进后的模型参数量为25.82×106,原始C3D 网络模型参数量为78.41×106,所以本文方法也可以有效地压缩模型参数量。
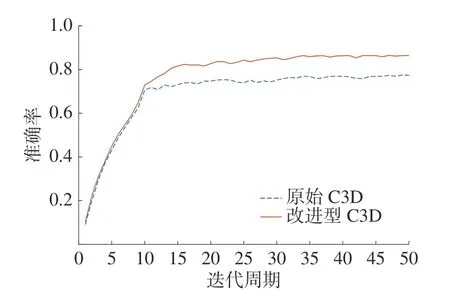
图8 UCF101 准确率变化曲线
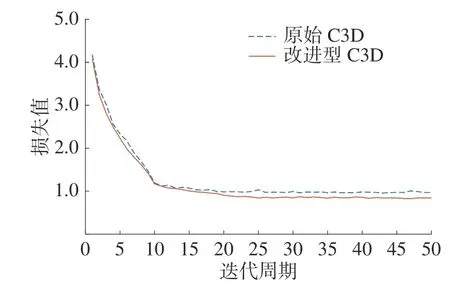
图9 UCF101 损失变化曲线
本文还与Res3D[19]、Spatial Stream-Resnet[20]、LSTM Composite Model[21]等当前流行的3 种方法进行准确率以及模型参数量的结果比较,证明本文方法在提高准确率以及模型压缩方面有很好的效果,如表1 所示。
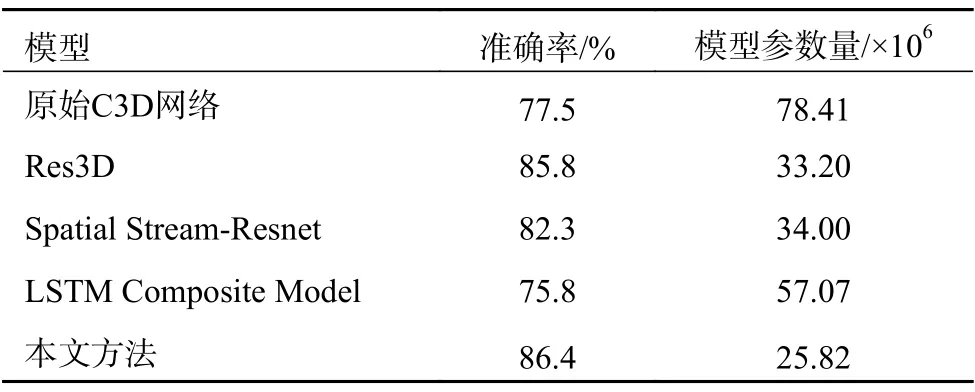
表1 UCF101 数据集各模型方法结果对比
3.6 HMDB51 实验结果分析
本实验在HMDB51 数据集上同样进行相应的训练,该训练时长大约为9 h,准确率变化曲线以及损失变化曲线分别如图10、图11 所示。准确率由图10 可知为54.3%,原始C3D 网络在本实验中准确率结果为46.4%,可见本文方法对于该数据集的准确率也有一定的提高。
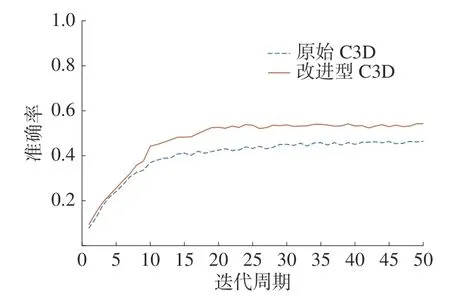
图10 HMDB51 准确率变化曲线

图11 HMDB51 损失变化曲线
本文对于该数据集同样进行本文方法与多种其他方法的准确率以及模型参数量的结果比较,证明了本文方法确实在改善识别率和模型压缩方面有很好的效果,如表2 所示。
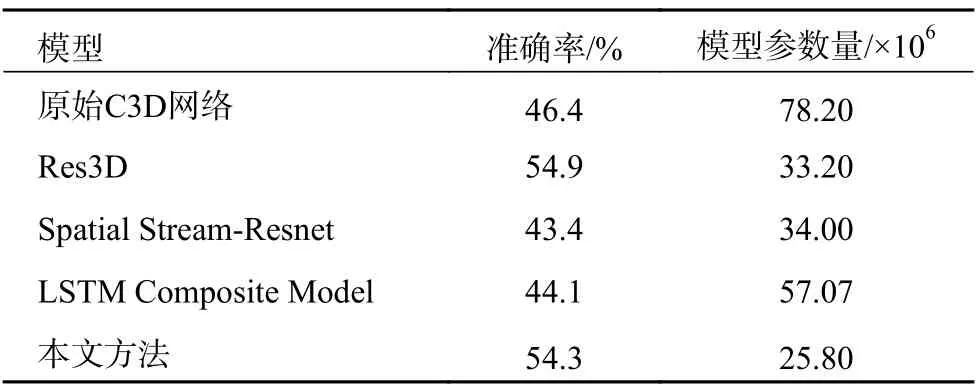
表2 HMDB51 数据集各模型方法结果对比
4 结论
本文针对C3D 神经网络进行改进,并通过进一步分析实验研究结果得出以下结论:
1)本文提出的基于改进型C3D 网络的人体行为识别算法经过UCF101 和HMDB51 数据集的验证,在识别准确率和模型压缩方面均优于原始C3D 网络以及其他流行算法;
2)虽然本文方法在识别精度和模型压缩方面都有一定的改善,但是改进后的整体模型结构却比较复杂,容易产生过拟合,并且增加了模型的整体计算时间;
3)在之后的研究中考虑引入注意力机制以及对网络进行残差形式的连接,来进一步增强对于有效特征的关注,并且防止由于模型过于复杂导致的过拟合现象发生;
4)本文引入的三维点卷积、卷积核合并形式以及构建的全卷积网络结构可以为之后改善模型识别效果提供很好的改进思路,并且本文的模型压缩方法可以让人体行为识别系统更方便地嵌入到移动设备中,对于实际应用具有很好的价值。
