基于电力负荷历史数据挖掘的负荷预测算法研究
2021-11-29梁锦来胡福金
梁锦来,胡福金
(广东电网有限责任公司 佛山供电局,广东 佛山 528000)
电力系统呈现市场化趋势,电力负荷的精准预测是其重点工作内容之一[1]。目前国内外大量研究学者针对电力负荷进行大量研究,支持向量机方法、回归预测法等方法均属于典型的传统时间序列法;模糊方法以及神经网络方法等均属于不确定预测方向[2-4]。大量研究学者研究结果表明,对其的预测结果受很多因素影响,如天气、温度、工作日与否等,不同影响因素之间具有较高的非线性关系。电力负荷预测研究领域中,需重点考虑由于非线性原因对结果预测的影响[5-6]。挖掘历史数据,利用挖掘结果中所蕴含的隐藏规律预测电力系统负荷,已成为目前电力领域主要的研究方向之一。
国外部分研究学者利用专家系统实现电力负荷预测,专家系统虽运算过程简单,但缺少智能学习能力,不适用于复杂环境中的电力负荷预测;李国庆等人将BP神经网络应用于电力负荷预测中[7],该方法处理非线性映射的能力较好,但容易出现极小值,缺少泛化能力;谢伟等人将模糊聚类算法应用于电力负荷预测中[8],该算法处理不确定性信息水平较差,对于具有较高非线性变化情况的电力负荷预测结果误差过高。
研究基于电力负荷历史数据挖掘的负荷预测算法,有效提升电力负荷预测精度。该算法利用数据挖掘方法充分分析电力系统历史数据中所蕴含规律以及数据异常情况,处理历史数据中存在的异常情况,避免预测结果受历史数据中异常数据影响,选取支持向量机方法作为预测模型,预测电力负荷数据。实验结果验证,采用该算法预测电力负荷具有极高的有效性,可应用于电力公司的管理部门实际应用中。
1 历史数据挖掘的电力负荷预测算法
1.1 历史数据挖掘的异常数据检测
选取K-means聚类算法聚类分析挖掘电力系统电力负荷历史数据中的属性特征量、聚类历史数据的负荷模式。不同历史数据样本内数据点具有相近的欧式距离时,海量电力负荷历史数据样本中数据点具有更高的相似程度[9]。该聚类算法利用欧式距离将样本数据中的数据样本划分为不同类别,同类别的数据相似度较高[10-12];利用该聚类算法挖掘电力负荷历史数据的最终目标为获取独立的簇,且所获取的簇需具有较高的紧凑性。
用{C1,C2,…Ci}表示全部数据样本分类所获取的簇,选取平方误差E最小作为聚类目标,可得聚类公式如下:
(1)

电力负荷历史数据具有平滑性以及相似性特征[13-14],依据所挖掘电力负荷历史数据可检测其中所包含的异常数据点。
Xd为单位时间内数据样本负荷特征曲线。分析固定时间段电力负荷数据样本负荷曲线特征Xd中待检测参数i,利用Xd(i)表示其特征值,用Xnorm与Xnorm(i)分别表示聚类中心以及聚类中心相应参数。计算Xnorm(i)与Xnorm(i)间变化率δ(i)公式:
(2)
利用所获取变化率确定负荷特征曲线是否存在异常数据[15],并在判定存在异常数据时及时修正。
选取灰色系统理论中的GM(1,1)模型修正电力负荷中异常数据。该模型修正电力负荷历史数据流程如图1所示。
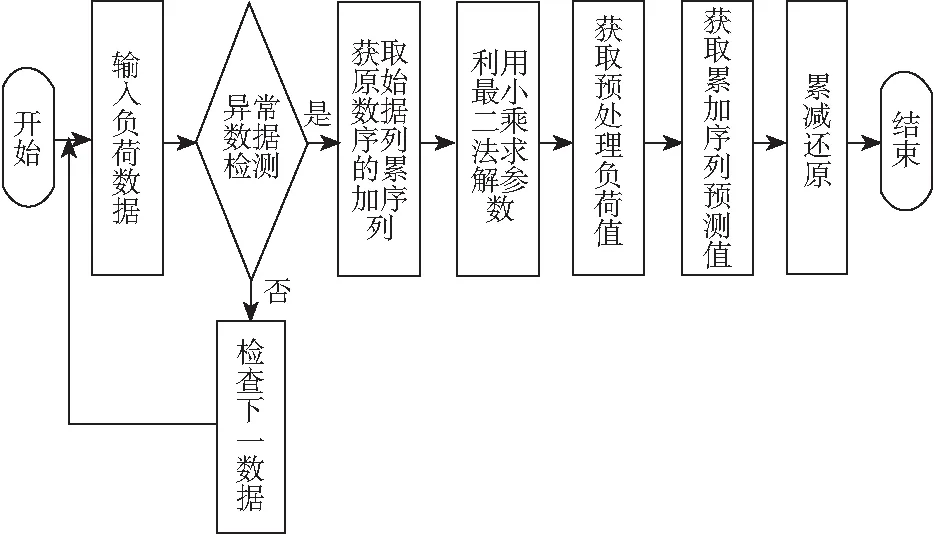
图1 异常数据修正流程
将电力负荷历史数据中不具有异常特征的数据设置为灰色序列,选取能量函数拟合公式实施累加序列预测[16]。利用灰色系统理论所具有的累减生成功能递推校正电力负荷历史数据中所包含的异常数据,完成数据预处理。
1.2 支持向量机的电力负荷预测
采用支持向量机预测电力负荷,利用高维空间内数据实施线性回归运算。

支持向量机函数估计表达式如下:
y=f(x)=ωφ(x)+b
(3)
式中,φ(x)与ω、b分别为非线性映射以及法向量、位移量。通过最小化处理公式估计支持向量机系数ω与b:
(4)
利用ε不敏感损失函数的特性,即稀疏数据点,对公式(3)的决策函数进一步表达如下:
(5)
式(4)属于正则化风险泛函,其由经验风险以及正则化2部分组成[17],利用常数c平衡正则化以及经验风险。

(6)
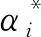
(7)
通过拉格朗日乘子的引入,利用搜寻二次优化向量ω问题表示凸优化问题,可得向量ω计算公式如下:
(8)

(9)
将参数利用二次优化方法调整,控制支持向量机的泛化能力。
式(9)中,K(xi,xj)为核函数,其获取公式如下:
K(xi,xj)=φ(xi)×φ(xj)
(10)
式中,φ(xi) 与φ(xj)表示特征空间内向量xi与向量xj映射的像。
当函数满足Mercer条件时,即可认作核函数[18],利用核函数构造机器学习决策算法。流程图如图2所示。由图2可知,基于电力负荷历史数据挖掘的负荷预测算法预测流程如下。

图2 负荷预测流程
(1)预处理电力负荷历史数据。采用K-means聚类法对海量电力负荷历史数据实施聚类,通过聚类检测样本中的异常数据[19],利用灰色模型修正历史数据中的异常数据,利用完成修正的数据建立具有高度相似性特征的训练样本集以及测试样本集合。
(2)对支持向量机的参数进行初始化处理。
(3)利用所获取的训练样本建立负荷预测的目标函数[20],求解目标函数,获取阈值结果。
(4)将所获取阈值结果代入式(7)中,输入测试样本,获取所需预测的固定时间负荷结果。
(5)计算预测结果的误差函数,所计算误差绝对值结果低于已设置正数或迭代次数满足运算要求时,终止支持向量机学习过程,输出预测结果;否则转回至步骤(3)继续迭代。
2 算法测试
为验证所研究基于电力负荷历史数据挖掘的负荷预测算法预测电力负荷有效性,选取某电力公司2017—2019年电力负荷历史数据作为实验数据。
采用本文算法挖掘该电力公司2018年8月15日15:00—16:00的电力负荷曲线,如图3所示。

图3 电力负荷曲线
从图3实验结果可以看出,所挖掘电力公司电力负荷历史数据建立的电力负荷曲线中存在明显的数据异常情况,需对其校正后,提升电力负荷预测结果精度。
本文算法采用K-means聚类算法挖掘历史数据,并采用灰色系统理论中的GM(1,1)模型校正异常数据,完成校正后的负荷曲线如图4所示。
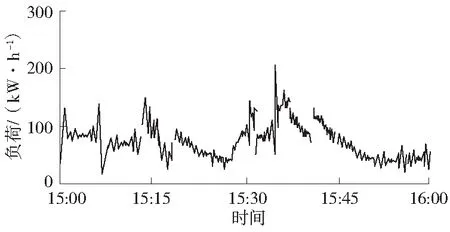
图4 校正后负荷曲线
采用校正后的电力负荷历史数据预测电力系统电力负荷,选取文献[7]算法以及文献[8]算法进行对比,不同训练次数情况下的平方误差结果见表1。

表1 平方误差对比
从表1实验结果可以看出,采用本文算法预测电力负荷的平方误差明显低于另2种方法,伴随训练次数的提升,不同算法预测电力负荷误差函数均有所降低。本文算法在不同训练次数情况下,误差函数均明显低于另两种算法,说明本文算法具有较高的电力负荷预测性能,本文算法采用支持向量机模型作为电力负荷预测的分类器,有效提升电力负荷预测精度。
采用3种算法预测2020年1月10日—14日的电力负荷预测结果如图5所示。采用3种算法预测2020年1月21日11:00—15:00的电力负荷预测结果,如图6所示。采用3种算法预测2020年1月21日10:00—11:00的电力负荷预测结果如图7所示。

图5 长期电力负荷预测结果

图6 短期电力负荷预测结果

图7 电力负荷预测结果
从图5—图7实验结果可以看出,采用本文算法可有效预测电力系统的长期、短期、超短期电力负荷,采用本文方法预测不同阶段电力负荷的预测结果均与实际电力负荷相差较小。本文算法具有较高的拟合精度,验证本文算法具有较高的电力负荷预测有效性。本文算法具有预测精度高的优势,不仅可预测超短期电力负荷,对于电力系统短期、长期电力负荷同样具有较高预测效果。
统计采用不同算法预测长期、短期、超短期电力负荷预测结果的平均相对误差以及预测时间,进一步验证本文算法预测电力负荷可靠性以及实时性,统计结果见表2。
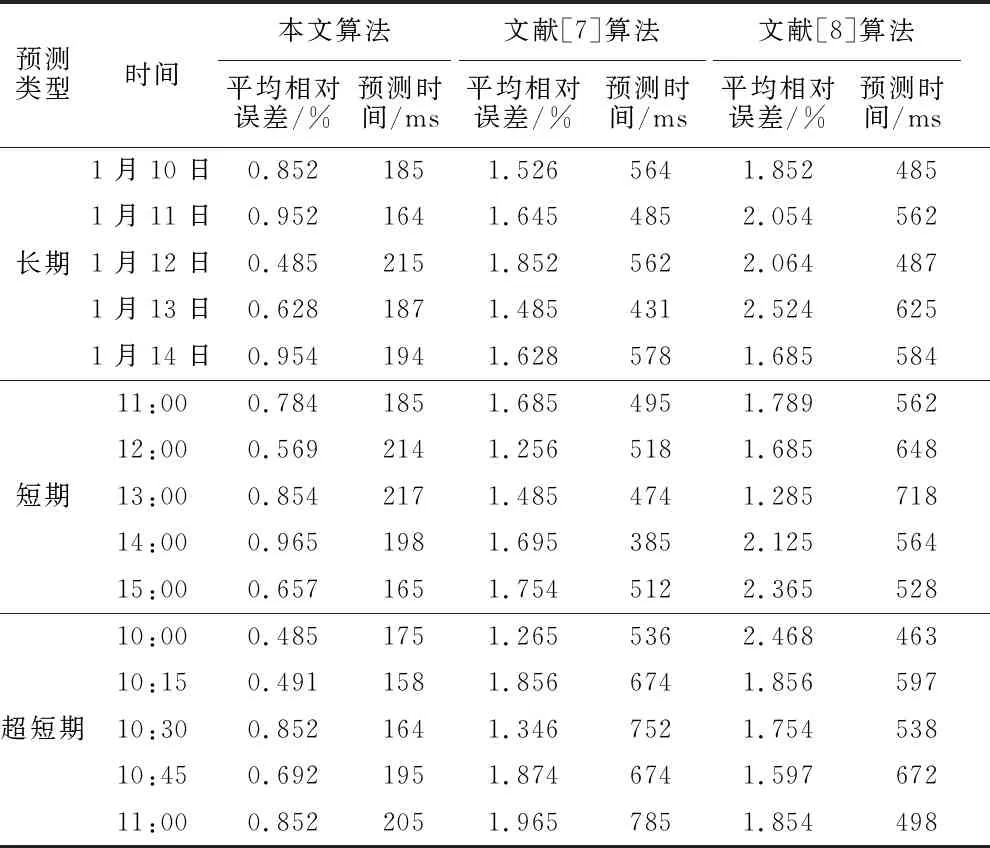
表2 电力负荷预测性能
从表2实验结果可以看出,采用本文算法可在较短时间内快速预测长期、短期、超短期电力负荷,预测结果的平均相对误差明显低于另2种算法,验证本文算法具有极高的预测可靠性以及预测实时性。本文算法采用数据挖掘方法充分挖掘电力负荷历史数据中异常数据,并采用灰色系统理论对异常数据实施校正,利用完成校正后的数据获取电力负荷精准预测结果,有效提升电力负荷预测性能,提升电力系统管理性能。
3 结论
利用数据挖掘方法挖掘电力负荷历史数据,对电力负荷历史数据实施聚类处理,通过聚类处理判断数据中存在的异常,针对异常及时修正,利用修正后数据集建立训练样本以及预测样本,获取精准的电力负荷预测结果。实验结果验证了采用该算法预测的不同时间段电力负荷预测误差均较低,具有较高的应用性能。所研究算法利用数据挖掘方法处理电力负荷历史数据,将完成处理的数据输入支持向量机中,可以实现电力负荷的精准预测。所研究算法具有易于实现、实用性高的优势,可应用于电力系统管理工作中。
