基于深度循环神经网络的入侵检测方法
2021-11-26王佳坤缪祥华邵建龙
王佳坤 缪祥华,b 邵建龙
(1.昆明理工大学a.信息工程与自动化学院;b.云南省计算机技术应用重点实验室)
由于网络数据的快速增长和可用计算资源的有限性,传统的入侵检测技术已经难以维持较高的检测效率,基于人工智能技术的入侵检测技术比起传统的入侵检测技术具有更大的优势,因此该技术的发展至关重要。
攻击类型逐渐多样化,不再局限于攻击者的技术或知识水平,利用深度学习可以产生复杂的攻击,当然也可用于攻击的防御。 许多研究人员致力于用深度学习算法开发智能入侵检测系统,提高应对日益增长的网络威胁的能力。
入侵检测是发现网络数据中与正常数据存在差异的异常数据。 传统的机器学习方法,如监督异常检测方法,需要进行数据标记,可在平衡的数据集上获得较好的效果,然而,数据集中大多存在数据不平衡的现象。 数据集中的不平衡性会使得某些攻击类型数据偏少,降低了入侵检测技术在训练过程中对少数攻击类型的敏感性,最终导致入侵检测系统存在缺陷,易让攻击者利用少数攻击类型进行攻击。
入侵检测技术不仅是网络安全研究的重点领域,同时也是学术研究的重点领域。 Gao X W等使用NSL-KDD数据集通过自适应集成学习模型测试,其中包含决策树、随机森林、K邻近和深度神经网络,通过NSL-KDD测试集验证,决策树算法的准确率为84.2%, 自适应算法的准确率为85.2%,提高了检测精度[1]。文献[2]提出了一种用于异常检测的在线过采样主成分分析方法,利用在线平台解决大量数据的入侵检测问题,通过对数据类型中的少数攻击类型进行过采样,实现了对少数攻击类型检测的功能;通过对主成分分析方法与其他检测算法在适用性、有效性和准确性上的比较,可以看出,该方法减少了计算成本和内存需求。Taher K A等提出一种有监督的机器学习系统对网络流量进行分类,实验采用NSL-KDD数据集,通过使用支持向量机和具有特征选取的人工神经网络算法进行训练和测试,以对所检测的数据流量进行正常分类和恶意分类,实验结果显示具有特征选取的人工神经网络算法表现得更好[3]。 Chandra A等提出将一种混合模型用于KDD CUP99数据集,通过使用基于过滤器的属性选择来减少数据集的特征维数, 使用K-Means和序列最小优化算法对测试数据集进行检测,实验结果证明该模型可以有效提高检测效率[4]。 文献[5]测试了门控循环单元的学习能力,实验表明,其学习能力优于长短期记忆 (Long Short-Term Memory,LSTM) 和 循 环 神 经 网 络(Recurrent Neural Network,RNN)。 文献[6]提出了一种入侵检测防御系统ANIDINR,系统中使用了多种深度学习算法对KDD CUP99数据集和NSL-KDD数据集进行检测,通过多种学习算法的比较,选出更适合入侵检测领域的算法。 丁红卫等利用深度自编 码 网 络(DAN) 和BP 算 法, 提 出 了 基 于DAN-BP的入侵检测模型, 能够降低数据维度和消除冗余信息,并在学习过程中加入噪声,使训练的模型具有鲁棒性,进而提高入侵检测的准确率[7]。 李勇和张波提出了一种基于深度卷积神经网络的入侵检测算法, 并引入Inception模型和残差网络,获得较好的泛化能力,最终的检测准确率达到了94.37%[8]。 张思聪等提出了一种基于深度卷积神经网络的入侵检测方法,通过数据填充的方式将原始一维数据转换为二维“图像数据”,可以使网络有效学习特征,该方法提高了检测准确率[9]。 陈红松和陈京九将循环神经网络用于构建入侵检测模型,并针对训练数据样本不平衡的问题,提出了基于窗口的实例选择算法精简训练数据集,并进行综合优化实验,最终检测的准确率达到了98.66%[10]。 杨印根和王忠洋提出一种入侵检测模型LSTM-RESNET, 使用词嵌入和LSTM进行数据处理,使用残差网络进行训练,通过对NSL-KDD数据集的测试,证明其具有良好的检测能力[11]。 连鸿飞等提出一种基于混合神经网络的异常流量检测模型,使用SMOTE与ENN解决数据集的不平衡问题,使用双向长短时记忆网络进行训练,通过在NSL-KDD数据集上的实验,证实了该模型具有更高的准确率[12]。 刘月峰等提出了一种多尺度卷积神经网络的入侵检测方法,利用不同尺度卷积核对原始数据进行不同层次的特征提取,采用BN方法优化学习率,进而获得最优特征表示,通过对KDD CUP99数据集的实验,证明该方法可以取得较高的检测准确率[13]。
笔者提出了一种基于深度门控循环单元(Deep Gated Recurrent Unit,Deep GRU) 的入侵检测模型,每层密集连接的GRU使模型在学习和检测过程中将各个特征紧密连接起来,并且提出简化GRU, 在减少计算参数的同时保持学习能力。 同时,针对数据集中不平衡的问题,提出使用Borderline-SMOTE算法, 使得模型在面对少数攻击类型时,能够实现较高的检测效率。
1 实验模型
1.1 入侵检测模型
笔者提出的基于深度门控循环单元的入侵检测模型框架如图1所示。

图1 基于深度门控循环单元的入侵检测模型框架
检测时,先将原始数据预处理为模型训练时能被识别的数据, 再通过Deep GRU 网络和Dropout层的训练得到训练好的模型,利用测试数据集对模型进行检测,得到检测结果。
一个完整的Deep GRU网络包括输入层、隐藏层和输出层(图2)。 输入层为预处理之后的数据X1,X2,…,Xn。 隐藏层包含GRU网络和Dropout层,在每次隐藏层训练过程中,需经过两层的GRU网络, 第1层为2×256个GRU模块, 第2层为256个GRU模块,在经过Deep GRU网络训练后,Dropout算法通过自身的随机选择能力,解决训练过程中的过拟合问题,可以使训练之后的模型具有更好的泛化性。 输出层通过Softmax实现多分类并输出结果Y1,Y2,…,Yn。
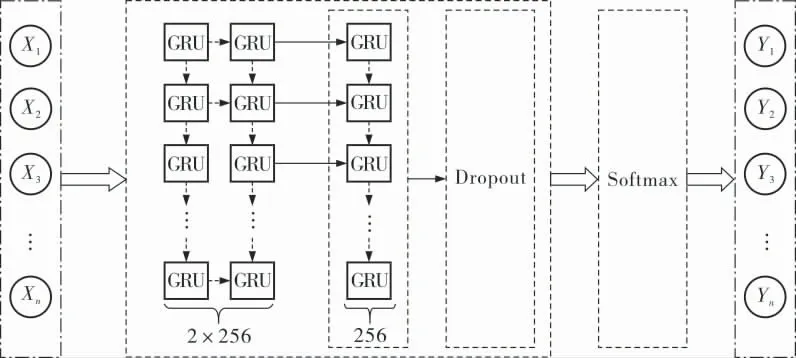
图2 完整的Deep GRU网络结构
1.2 门控循环单元
循环神经网络 (Recurrent Neural Network,RNN)适用于训练具有顺序属性的数据,典型的RNN模型中隐藏状态的计算公式为:
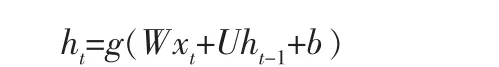
其中,ht是t时刻保留的n维隐藏状态;xt是t时刻的m维输入向量;g()是激活函数;W和U是两个权重参数,W为n×m的矩阵,U为n×n的矩阵;b是偏差,为n×1的向量。
典型的RNN模型很难获得长期的依赖关系,因为在训练过程中会产生梯度消失或梯度爆炸现象,因此,通过对RNN变形,提出了长短时记忆模型和门控循环单元。 笔者主要利用GRU进行实验,以下对GRU进行详细说明。
门控循环单元 (图3) 是循环神经网络的一种,它是为了解决循环神经网络中长期记忆和反向传播中的梯度消失问题而提出来的,与长短时记忆模型相比更易于计算。
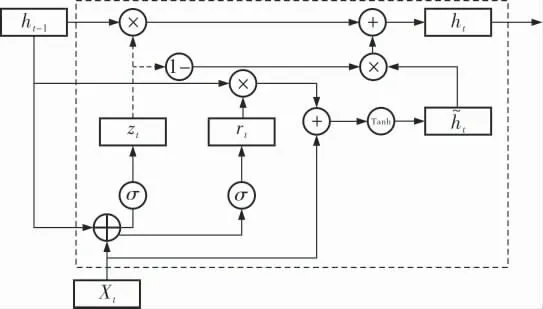
图3 GRU结构
在GRU中只有两个门,一个重置门和一个更新门。 直观来说,重置门决定了如何将新的输入信息与前面的记忆相结合,更新门则定义了前面记忆保存到当前时间步的量,这两个门控向量决定了哪些信息最终能够作为门控循环单元的输出。 它们能够保存长期序列中的信息,且不会随时间而清除或因为与预测不相关而移除。 重置门和更新门的计算公式如下:
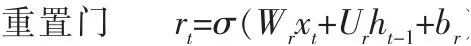
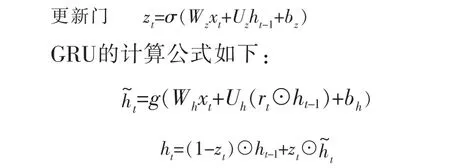
其中,rt代表重置门;zt代表更新门;σ为Sigmoid函数;Wr和Ur为重置门权重矩阵;br为重置门偏差;Wz和Uz为更新门权重矩阵,bz为更新门偏差;Wh和Uh为当前时刻状态的权重矩阵,bh为当前时刻状态的偏差;为t时刻暂时的隐藏状态。
通过GRU模型与RNN典型模型的计算公式对比可以看出,GRU模型的计算参数量是典型RNN模型的3倍,即3(n2+mn+n)。 重置门和更新门所对应的权值是通过时间反向传播随机梯度下降来更新的,在更新过程中试图找到损失函数的最小值。 因重置门和更新门会长期保存序列中的信息,在计算过程中会对同样的参数进行重复计算,产生不必要的冗余数据,若能有效去除冗余数据的计算, 那么就可以提升GRU的计算能力。因此, 笔者在原有重置门和更新门的基础上,提出通过应用简化重置门和更新门的计算结构来提升训练的速度。 通过简化GRU模型,提出将以下3种不同的简化模型应用到入侵检测。
GRU1。 在此简化中,仅使用之前隐藏状态和偏差计算两个门的信息, 在计算参数上减少了2mn:
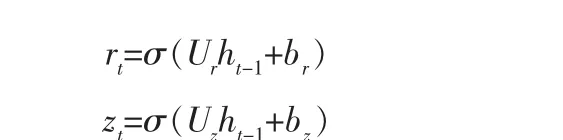
GRU2。 在此简化中,仅使用之前隐藏状态计算两个门的信息,在计算参数上减少了2(mn+n):
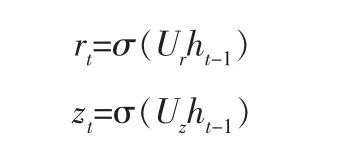
GRU3。 在此简化中,仅使用偏差来计算两个门的信息,在计算参数上减少了2(nm+n2):
通过以上3种简化的GRU模型对比可以看出,在计算参数上有不同程度的减少。为了检验简化后的GRU的计算能力, 笔者利用具有正面和负面评论的IMDB影评数据集进行性能测试,以作比较。 IMDB数据集是自然序列数据集,它由25 000 个训练数据和25 000 个测试数据组成。 笔者在10轮训练周期内使用10-2、10-3、10-4和10-5这4种学习率进行训练,在训练过程中,使用4层隐藏层,每层512个节点,并采用128的批处理大小。 在实验过程中,分别使用Relu、Tanh和Sigmoid激活函数对模型的性能进行对比,对比结果见表1~3。
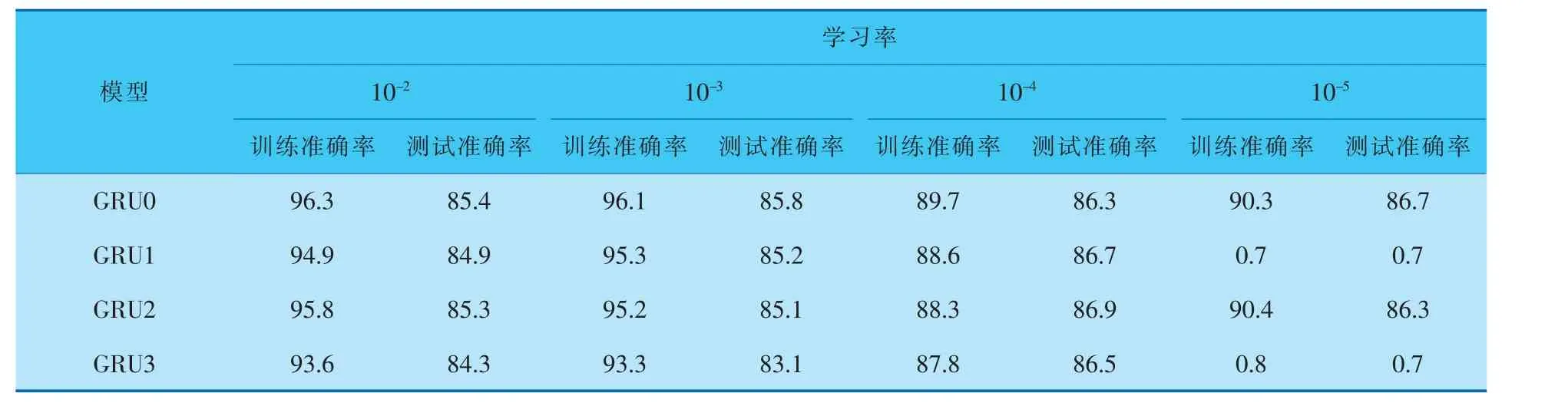
表1 使用Relu激活函数的准确率对比 %
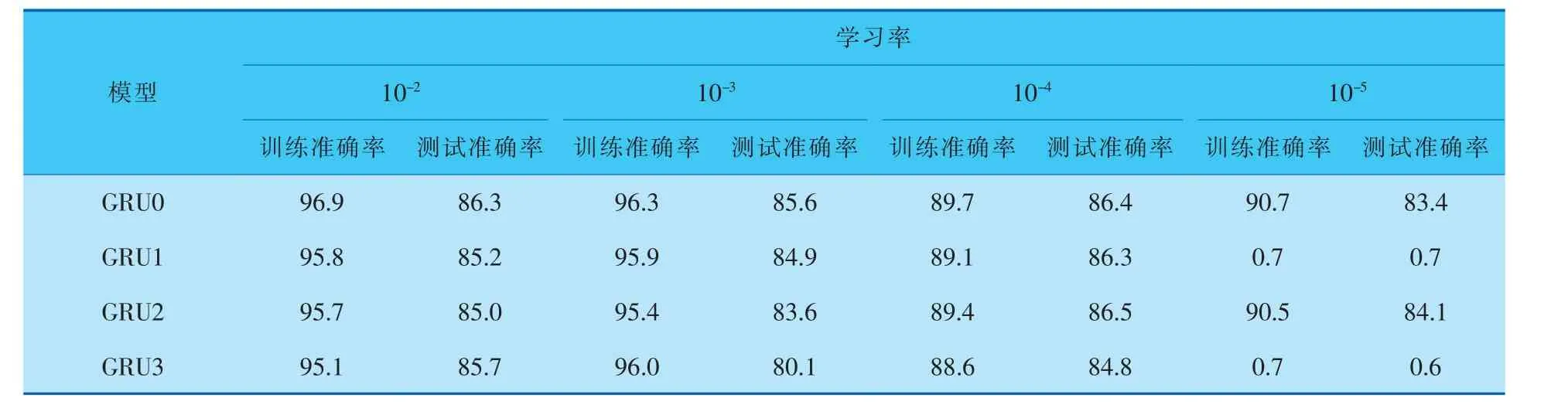
表2 使用Tanh激活函数的准确率对比 %
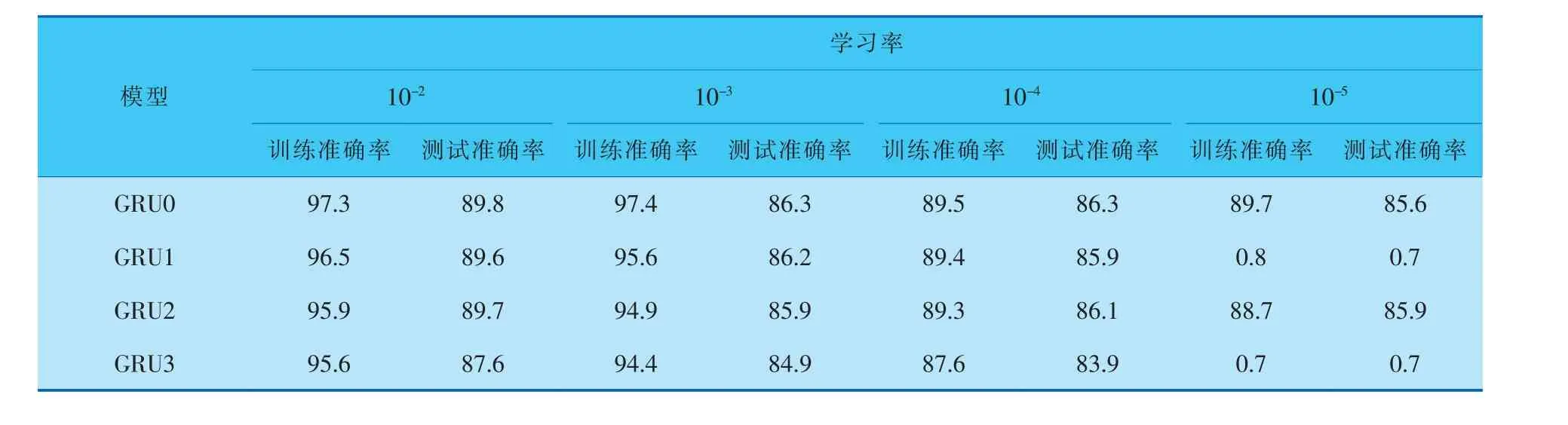
表3 使用Sigmoid激活函数的准确率对比 %
通过表1~3的数据对比可以看出,3种简化的GRU模型在使用较少参数的情况下,性能与传统GRU模型的性能相当。 同时,从表中数据还可以看出,随着学习率的下降,训练和测试的准确率均下降, 尤其在学习率降低到10-5时,GRU0和GRU2模型还可以进行有效训练和检测,但GRU1和GRU3模型已经无法有效学习。 但总地来说,在有效学习率的支撑下,GRU1~GRU3模型减少了部分计算参数, 依然可以保证有效的计算性能。通过表中数据的对比, 笔者选择GRU2作为本项目模型。
2 数据集
2.1 数据集分析
NSL-KDD数据集由KDD CUP99数据集改进,被广泛视为入侵检测领域的基准数据,它通过删除KDD CUP99数据集中的冗余数据,使得学习过程具有更高的效率和更高的准确率。 NSL-KDD训练集和测试集分别包含125 973条和22 543条网络数据,除正常类型(Normal)外主要包括以下4种攻击类型的数据:
a. 拒绝服务攻击(Denial of Service,DoS)。 攻击者频繁占用计算机或服务器中的计算或内存资源,从而导致系统无法处理合法请求任务。
b. 探测攻击(Probing)。攻击者试图收集计算机网络的各种信息,以达到规避系统安全控制措施的目的。
c. 远程用户攻击(Remote to Local,R2L)。 攻击者在目标计算机或服务器中没有账号,通过网络将数据包发送到计算机或服务器中,根据系统漏洞非法获取本地用户访问权限。
d. 提权攻击(User to Root,U2R)。 攻击者使用普通账户进行计算机或服务器的访问,利用系统漏洞非法获取系统的最高访问权限。
NSL-KDD数据集的数据类型分布见表4。

表4 NSL-KDD数据集的数据类型分布 条
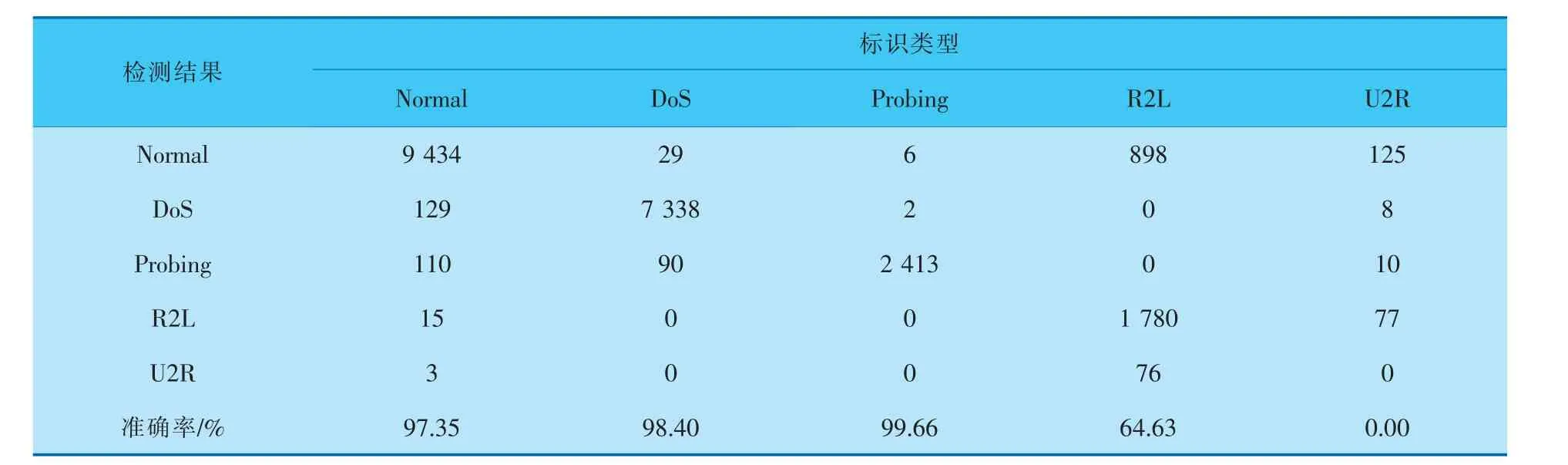
从表4可以看出,数据集存在不平衡性,影响模型对少数攻击类型的学习能力。 要提高入侵检测的性能,就应降低这种不平衡性。 笔者采用数据过采样算法来降低数据集中的不平衡性。 通过对少数攻击类型的过采样,人为地为少数攻击类型增添新的样本数据,将其用于模型训练,以提高模型训练时对少数攻击类型的敏感性。
2.2 数据预处理
2.2.1 数值化处理
笔者采用LabelEncoder方式对字符型数据进行数值化处理,LabelEncoder可以将标签映射到[0,n_classes-1]的区间进行编码,给各种标签分配一个可数的连续编号。 例如,对正常类型和4种攻 击 类 型 [Type, “Normal”]、 [Type, “DoS”]、[Type, “Probing”]、 [Type, “R2L”] 和[Type,“U2R”]进行数值化后,可变为[Type,0]、[Type,1]、[Type,2]、[Type,3]和[Type,4]。 将非数值型的变量转化为可计算的数值形式,有利于更好地提取特征和进行计算。
2.2.2 归一化处理
为提高模型的学习速度、 改善模型分型性能, 需对部分数值过大的特征进行标准化处理。数据的标准化是指通过映射的方式,将特征所有取值映射到一个较小的数值区间内,从而消除特征单位对模型训练时间和检测性能的影响。 笔者采用StandardScale算法对数据进行标准化处理,具体公式为:
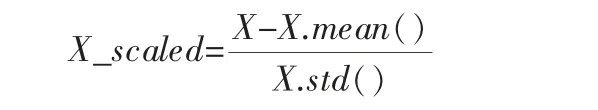
式中 X——原始数据;
X.mean()——数据集的均值;
X.std()——数据的标准差;
X_scaled——标准化后的数据。
利用StandardScale算法标准化处理过的数据符合标准正态分布,其均值为0,标准差为1。 并且StandardScale算法是针对每一个特征维度进行处理,避免对某个特征的重视程度过大或过小。 该算法因受异常点的影响较小, 所以适用于繁杂、量大的数据。
2.2.3 数据集平衡处理
笔者采用Borderline-SMOTE过采样算法对少数攻击类型合成新样本。 SMOTE算法对数据集中每个少数类样本产生相同数量的合成数据,没有考虑其邻近样本的分布特点,增大了类间发生重复的可能性。 Borderline-SMOTE算法改进了原有SMOTE算法存在局限性的问题,先根据规则判断少数类的边界样本,再对这些样本生成新样本。
设训练集为T,少数类样本为F={f1,f2,…,fn},Borderline-SMOTE算法具体步骤如下:
a. 计算少数类样本F中每一个样本在训练集T中的k个最近邻;
b. 根据k个最近邻对F中的样本进行归类;
c. 设边界样本集合B={f1′,f2′,…,fb′},计算B集合中的每个样本在少数类样本F中的k′个最邻近fij;
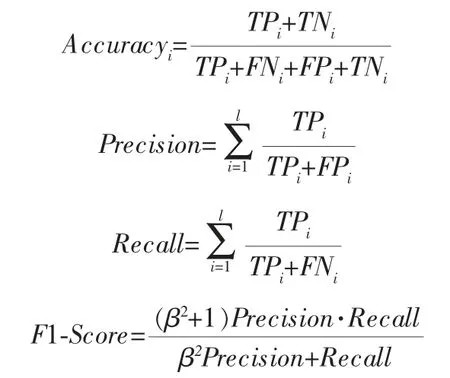
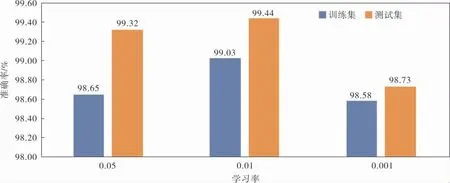
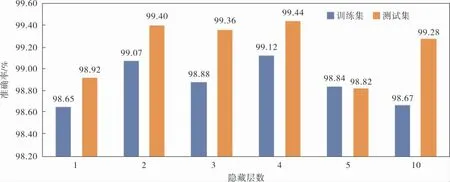
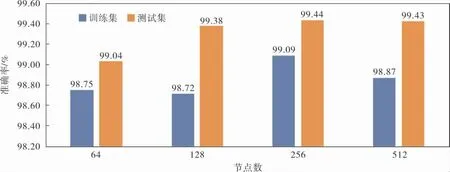
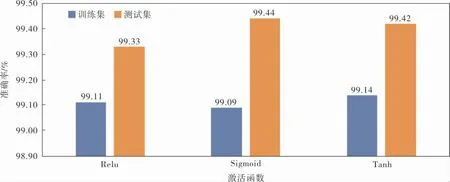
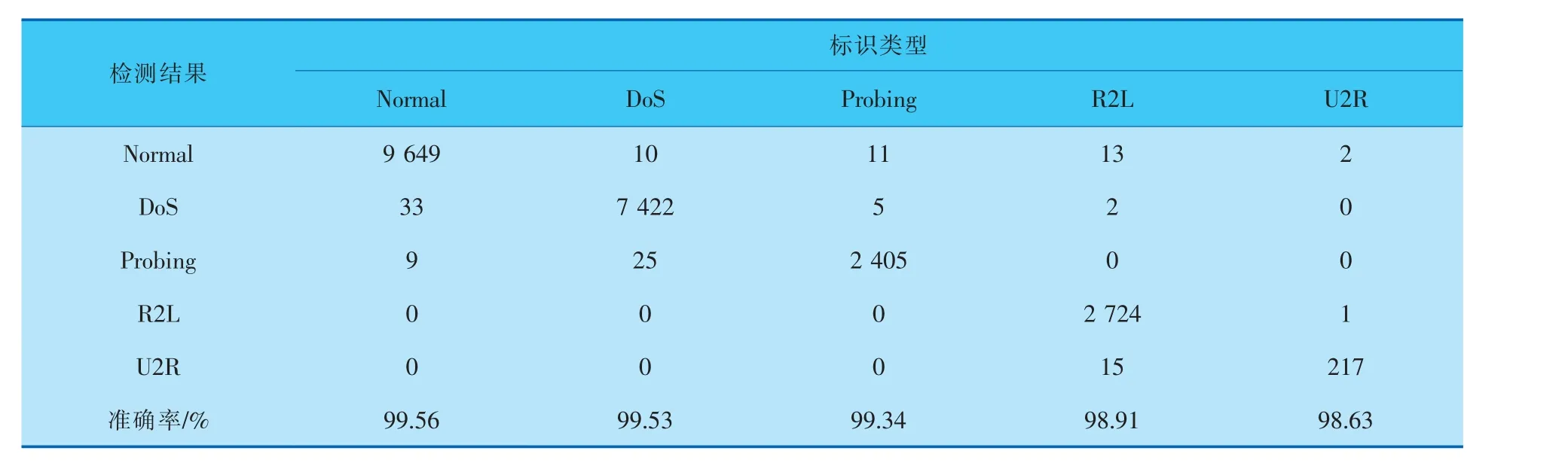
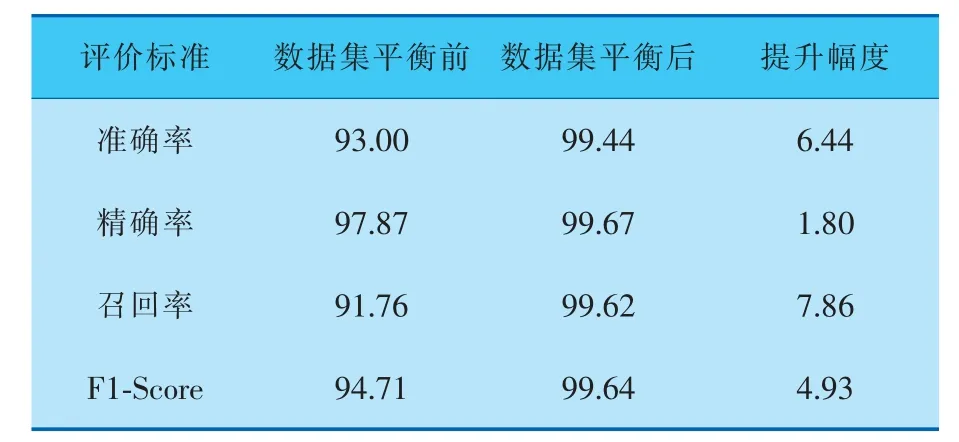
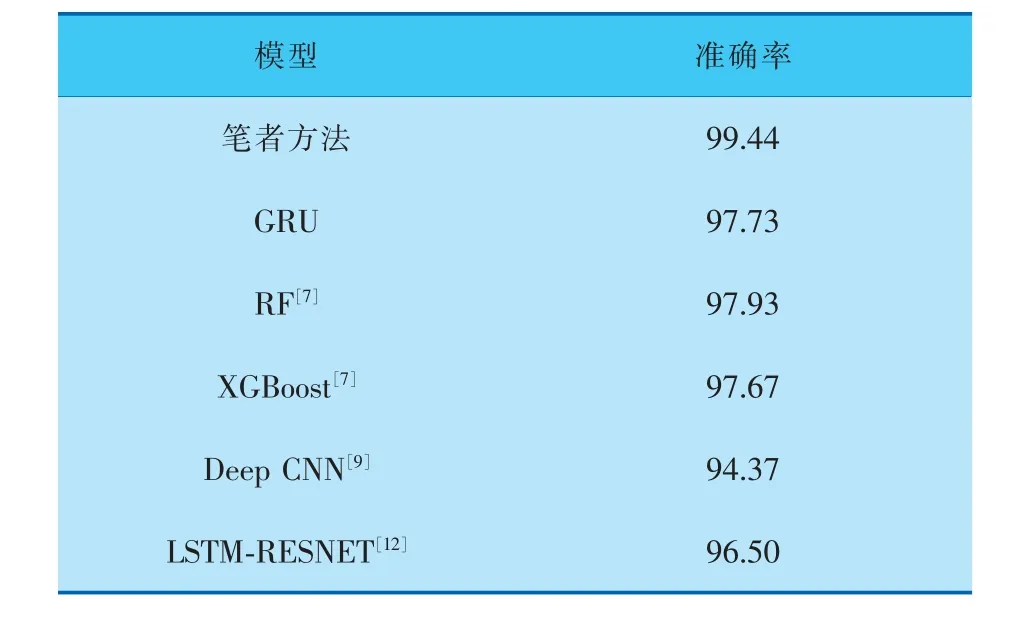
d. 随机选出s(1 e. 计算出它们各自与该样本之间的全属性插值dij; f. 选择一个随机数rij与dij相乘,rij∈(0,1); g. 最后生成人工少数类样本hij=fi′+rijdij。 循环执行步骤c~g, 可生成满足要求的少数类样本数目。 其中,步骤b中的细分步骤如下: a. 若k个最近邻的样本都是多数类样本,则将该样本定义为噪声样本,存放于集合N′中; b. 若k个最近邻的样本超过一半是多数类样本,则称之为边界样本,将该样本定义为危险样本,存放于集合B中; c. 若k个最邻近样本超过一半是少数类样本,则将该样本定义为安全样本,存于集合S中。 笔者选择的检测效能评价标准有准确率Accuracy、 精确率Precision、 召回率Recall和F1-Score,具体计算公式如下: 其中,TP表示数据为异常且预测也为异常的数据量;FP表示数据为正常而预测为异常数据的数据量;TN表示数据为正常且预测也为正常的数据量;FN表示数据为异常而预测为正常的数据量;l为类型数量;β为平衡因子, 最常见的选择为1,由检测精确率和召回率平衡得到。 准确率是用来衡量检测有效性的最重要的标准,可准确表达每一种攻击类型。 本项目的实验环境是内存为16 GB的Intel Core i7-9750H CPU, 内 存 为8 GB 的NVIDIA GeForce GTX1050Ti显卡,Win10 64 bit操作系统的Dell笔记本电脑。 选择软件Python3.7的Keras框架来构建Deep GRU模型。 通过设置不同的参数以获得最佳的性能,例如学习率、隐藏层数、节点数及激活函数等。 参数均经过10次实验后取其平均值所得。 学习率选取范围为{0.05,0.01,0.001},根据图4实验结果,模型在学习率为0.01时,具有更高的准确率。 图4 不同学习率下的准确率 隐藏层数选取范围为{1,2,3,4,5,10},根据图5实验结果,模型在隐藏层数为4时,具有更高 的准确率。 图5 不同隐藏层数下的准确率 节点数选取范围为{64,128,256,512},根据图6实验结果,模型在节点数为256时,具有更高的准确率。 图6 不同节点数下的准确率 激活函数在{Relu,Sigmoid,Tanh}中选取,根据图7实验结果,模型在激活函数为Sigmoid时,具有更高的准确率。 图7 不同激活函数下的准确率 通过实验对平衡前、 后的数据集进行检测,实验结果均由100次实验取平均值所得。 未平衡数据集的实验结果见表5。因训练集中U2R攻击类型的数量过少,导致在测试时未对此类攻击进行有效检测。对R2L攻击类型的准确率为64.63%,同其他攻击类型的准确率相比,表现较差。 表5 未平衡数据集的检测结果 因此, 笔者采用Borderline-SMOTE过采样算法, 针对数据集中R2L攻击类型和U2R攻击类型数据量过少的问题, 通过过采样算法进行扩充。经过平衡后的数据类型分布见表6。 表6 平衡后NSL-KDD训练集数据类型 在解决数据集中少数攻击类型数量不足的问题后,实验结果见表7,对U2R攻击类型的准确率达到了98.63%。并且,对R2L攻击类型的检测准确率提高了34.28%。 表7 平衡后数据集的检测结果 经过100次实验,从准确率、精确率、召回率和F1-Score这4个评价标准通过取平均值来评价,结果见表8,可见分别提高了6.44%、1.80%、7.86%和4.93%。 表8 数据集平衡前后对比 % 通过以上模型参数的选择和对数据集的平衡化,使训练得到的模型具有更好的检测能力。其中最优模型的参数选择是,学习率为0.01,隐藏层数为4,节点数为256,激活函数为Sigmoid。最终笔者提出的Deep GRU模型的准确率为99.44%,与其他文献方法相比有一定的提升(表9)。 表9 不同模型实验结果对比 % 为提高入侵检测技术的检测能力,提升对少数攻击类型的检测率,提出了一种具有多层堆叠的Deep GRU入侵检测模型,通过密集连接神经元对特征有效学习,并且简化GRU,在减少计算参数的同时保持学习能力。 同时, 使用Borderline-SMOTE算法对不平衡数据集进行过采样,增强了模型对少数攻击类型的学习能力。 通过实验可以看出,笔者提出的入侵检测方法在准确率、精确率、召回率和F1-Score这4个评价标准上都有所提升。 并且与其他文献方法进行比较,具有较高的检测能力。 因使用堆叠的Deep GRU模型,所以在训练和检测的时间效率上有所降低,后续工作可以以提高时间效率为着力点,进一步提高检测效率。2.3 评价标准
3 实验分析

4 结束语
