基于目标检测的华为无人小车交通路况识别
2021-11-24秦慧颖雷晓春江泽涛
秦慧颖,雷晓春,2,江泽涛,2
(1.桂林电子科技大学 计算机与信息安全学院, 桂林 541004;2.桂林电子科技大学 广西图像图形与智能处理重点实验室, 桂林 541004)
0 引言
自动驾驶近年来备受关注,如激光雷达、目标检测等相关技术得到飞速发展。无人车自动行驶过程主要依靠车载的摄像头、激光雷达、已建好的高精地图等来完成。在指定场景下,如果没有高精地图,那么无人车将依靠激光雷达进行避障以及车载摄像头进行目标的识别与检测,从而能顺利有序地进行相应的行驶操作。本文使用华为无人车(下文简称无人车)作为实验对象,基于ModelArts平台进行数据集的制作与模型的训练。基本场景为模拟现实路况,采用红绿灯、斑马线、限速和解除限速等标志,设置行人等障碍物,车道线形状包括直线形、环形和S形,场景图如图1所示。

图1 华为无人车挑战赛模拟场景图
无人车模拟交通场景,通过目标检测算法识别与检测基本路况信息,来进行相应的控制操作。通过对不同数据集在不同算法以及不同参数下的几组实验找到优化模型,并实际应用于无人车模拟路况行驶。本文对训练得到的模型准确度进行了测试,同时选出较好的模型部署在小车上进行对比。同时,模拟路况的一些实际情况,对模型进行了改进,将颜色容易混淆的红绿灯进行位置划分,对比未改进之前的模型能更精确地判断红绿灯的状态。
1 基本场景介绍
无人车在行驶过程中,分别使用摄像头获取实时路况信息,激光雷达检测运行过程中是否存在障碍物。实际运行过程中,在激光雷达检测到有障碍物时,无人车应进行避障处理,应减速或者直接停下,图2为模拟行人过斑马线的场景。而实时路况则是在相应的路况下,无人车也应及时作出相应反应。基本路况信息包括红绿灯、斑马线、限速和解除限速。例如,根据红绿灯的规则,无人车在检测当时处于红灯则应在指定位置之前立即停下,遇到绿灯正常通行,在斑马线处和遇到限速标志后应减速等。

图2 模拟行人过斑马线
无人车的控制部分分为两个模块,激光雷达和摄像头获取的信息同时对无人车的运行情况进行控制。激光雷达主要检测前方障碍物;摄像头主要用于识别相应的基础路况信息。而基础路况信息是需要进行处理和识别的。容易观察到,基本路况信息中的目标比较稳定、容易识别,所以采用目标检测进行处理比较合适。使用目标检测算法训练出模型,在实时路况中,无人车可以进行路况识别检测,并作出相应的反应。无人车在运行过程中使用模拟环境,训练数据也采用从模拟环境采集的信息。在训练模型的过程中,选择几种性能比较好的算法进行训练,并通过比较训练模型的精度来进行较好的模型选择。
2 基于ModelArts的数据集制作与分类
通过无人车摄像头拍摄了3000多张模拟场景图片,将这些图片在ModelArts平台上进行数据标注,制作成了原始数据集DSv1(下文该原始数据集均使用DSv1表示)。标注目标分别为红绿灯中的红、黄和绿灯,斑马线、限速和解除限速六类目标。由于数据集数量较少,且训练出来的模型效果不是很理想,所以要对数据集进行图像处理和图像增强,以提高数据集的训练效果。同时,也对原始数据集进行了数据清洗,增加数据集的质量以及可用性,来训练出更适应模拟环境的模型。图像增强主要使用原始数据集进行旋转、叠加以及增加噪声等处理。原始数据集加上进行图像增强之后的数据集,制作成了8000多张的数据集DSv2(下文该数据集均使用DSv2表示)以及20 000张的数据集DSv3(下文数据集均使用DSv3表示)。
训练的目标是分别识别红绿黄灯、斑马线、限速以及解除限速标志。于是对数据集进行筛选,去掉容易混淆的数据集:如绿灯和黄灯,以及红灯和黄灯容易混淆的图像。并让每个类别的数据量尽量相近。DSv2筛选之后剩余6000张图片,制作成数据集DSv4(下文该数据集均使用DSv4表示)。经过实验对比表明,训练集和验证集之间的比例参数在8∶2和9∶1时效果会较好。因此训练过程中,训练集和验证集之间的比例设置为8∶2或者9∶1,分别进行训练,观察模型的精度。不同的算法和不同的数据集获得较佳的训练效果使用的比例也不同。大量训练之后的结果显示,大多数算法中训练集与验证集的比值DSv1使用9∶1;DSv2使用8∶2进行训练效果较好。而在实际实验中,我们使用不同的参数值进行实验,对比得出较好的比例参数。
3 算法的选择与比较
数据集制作完成后,需要选择目标检测算法进行训练。不同的目标检测算法和相应的参数都会对模型的精度造成影响。通过实验采用不同的数据集对不同的算法以及不同的参数设置来对比得到精度较高的模型。选择使用并在ModelArts上进行训练的算法主要有:YOLOv3ResNet18,FasterRCNNResNet50,RetinaNetResNet50,YOLOv3 Darknet53。其中不同的算法使用不同的预训练模型,对数据进行迁移训练。下面将具体介绍算法的预训练模型,训练集与验证集的比值以及训练的效果(通过模型的参数值进行体现),其中所有的实验环境均使用Python3,Tensorflow的版本为1.13.1。
模型的参数值为Recall(召回率、查全率),Precision(精确率、查准率),Accuracy(准确率)和F1 Score(F1值)。其中具体含义及计算为:
Recall:预测为正确的正例数据占实际为正例数据的比例,R=TP/(TP+FN)
Precision:预测正确的正例数据占预测为正例数据的比例,P=TP/(TP+FP)
Accuracy:正确分类的样本个数占总样本个数,A=(TP+TN)/N
F1score:调和平均值,F=2/(1/P+1/R)=2*P*R/(P+R)
ResNet18网络搭载YOLOv3使用ImageNet-1k预训练模型进行训练。ResNet18中有18个带权值的层(convl有一个,conv1.x到conv2.x每一个含2×2个,池化层有一个),ResNet网络层次较深,故训练效果较好[2]。算法的流程见图3所示。YOLOv3[3]训练速度快,同时在训练效果上会有所下降。表1展示了不同数据集下使用不同训练集与验证集比值训练模型的参数值。YOLOv3对比起较新的YOLOv4[4]来看,还是具备很好的性能。YOLOv4提升的是训练速度,就训练效果来看,延用YOLOv3会更适合本模型的训练。

表1 YOLOv3_ResNet18实验参数及结果展示
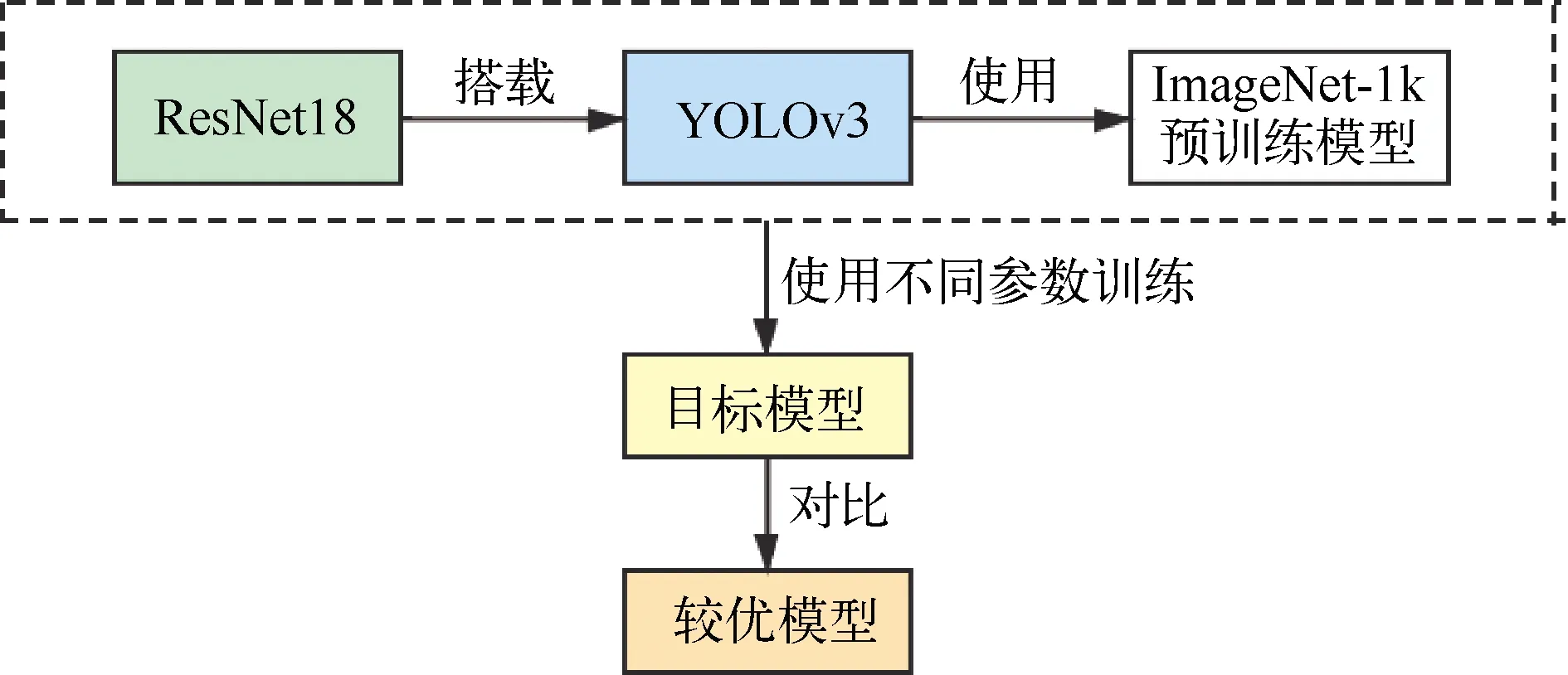
图3 使用YOLOv3ResNet18训练模型流程图
ResNet50网络搭载FasterRCNN使用Pascal VOC2007预训练模型进行训练。训练模型流程见图4所示。ResNet50分为5个Stage,其中Stage0的结构比较简单,相当于对输入进行预处理,后四个Stage由Bottleneck(瓶颈层,也称编码层)组成,Stage1~Stage5分别包含3、4、6,3个Bottleneck。表2展示了不同数据集下使用不同训练集与验证集比值训练模型的参数值。Faster RCNN是在Fast RCNN基础上的改进,使用区域建议网络(Region Proposal Network, RPN)。RPN是端到端训练的,生成高质量区域建议框,用于Fast RCNN来检测,这很好地改进了Fast RCNN在计算区域建议遇到的问题[5]。

图4 使用FasterRCNNResNet50训练模型流程图

表2 FasterRCNN_ResNet50实验参数及结果展示
ResNet50网络搭载RetinaNet使用VOC07预训练模型进行训练(在VOC07上mAP为83.15%)。训练模型流程如图5所示。该算法也使用ResNet50进行搭载,RetinaNet诞生于YOLOv3之前,针对One-stage模型中前景和背景类别不平衡的问题,提出Focal Loss损失函数,用来降低大量Easy Negatives(Easy Negatives指的是容易进行区分的负样本,相对应的为Hard Negatives是较容易被划分为正样本的负样本。Hard Negatives权重提高,对模型的训练是有好处的)在标准交叉熵中所占权重[6]。ReinaNet有效的检测了Focal Loss损失函数的有效性。表3展示了不同数据集下使用不同训练集与验证集比值训练模型的参数值。

表3 RetinaNet_ResNet50实验参数及结果展示
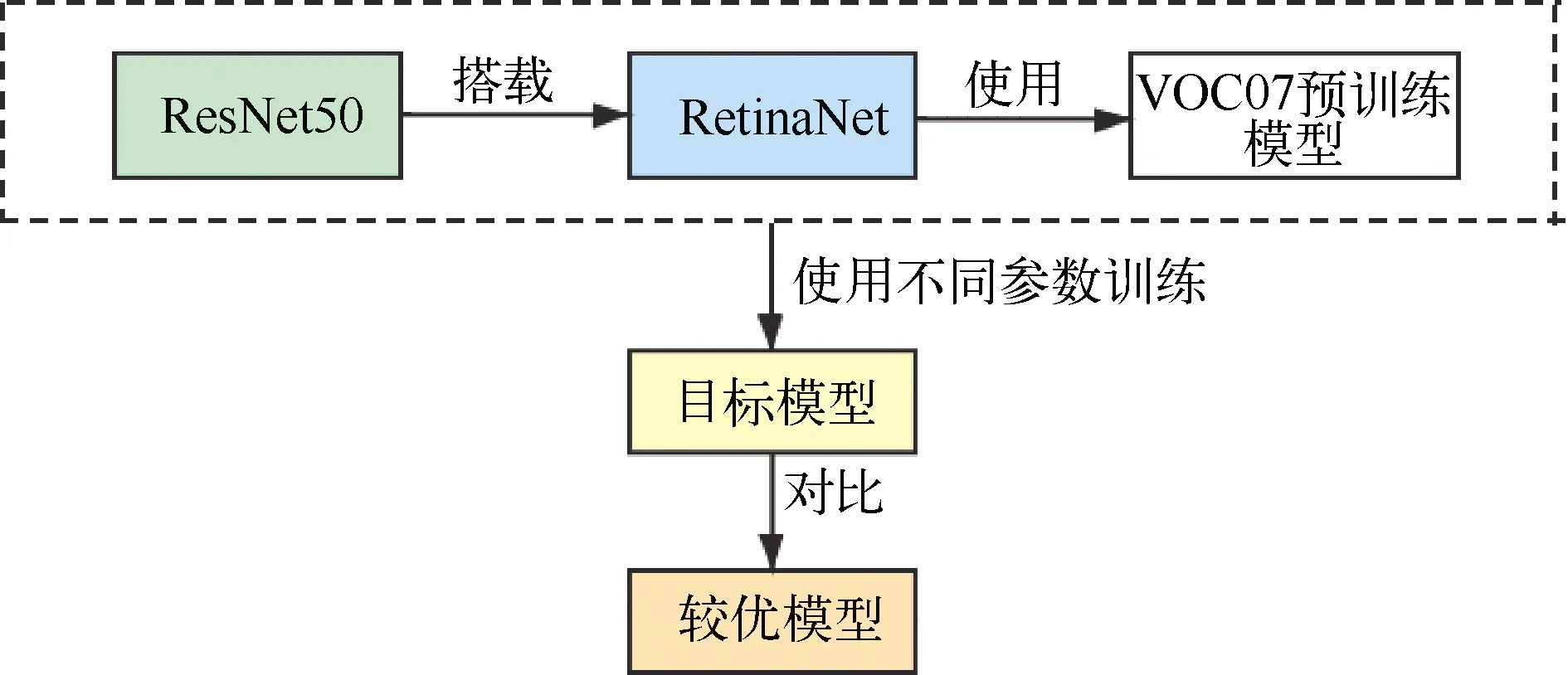
图5 使用RetinaNetResNet50训练模型流程图
Darknet框架下搭载的YOLOv3使用YOLOv3-Darknet53的COCO预训练模型进行训练。训练模型流程如图6所示。Darknet是一个较为轻型的完全基于C与CUDA的框架,易于安装,没有任何依赖项,移植性非常好,支持CPU和GPU两种计算方式。由此可以看出Darknet因为较轻型,没有很强大的API,但是相比起来也显得比较灵活。Darknet框架自身的这些特点,显得更适配YOLO,这也与前面使用的ResNet18形成了对比。表4展示了不同数据集下使用不同训练集与验证集比值训练模型的参数值。
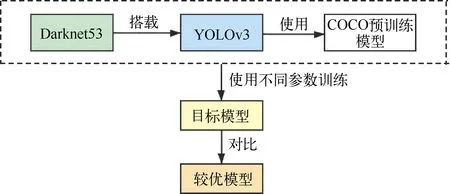
图6 使用YOLOv3Darknet53训练模型流程图

表4 YOLOv3_Darknet53实验参数及结果展示
从以上实验数值对比来看,RetinaNet_ResNet50的训练效果较好,同时观察到训练时间也不是最长的。将实验所得模型部署在ModelArts上并进行预测,得到预测结果如图7~图11所示。可以看到,使用模型预测所得的限速、解除限速、斑马线以及红绿灯的识别效果。展示结果为实验结果较好的模型,模型选择的为数据集为DSv3使用RetinaNet_ResNet50训练所得的模型。经比较使用该算法综合性能在四种算法最佳,较适合用来进行训练这类数据集。选择实验过程所得的几个训练较好的模型进行实际运行测试。

图7 使用模型预测限速、斑马线
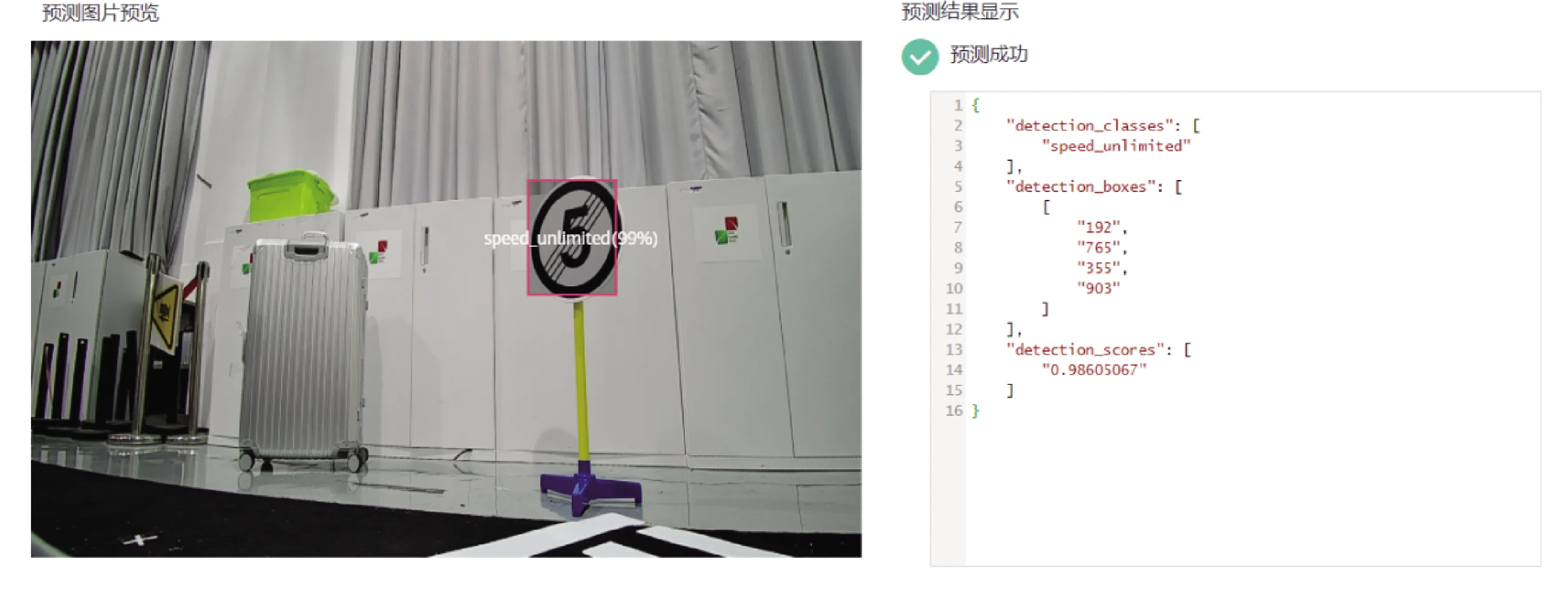
图8 使用模型预测解除限速

图9 使用模型预测黄灯

图10 使用模型预测绿灯
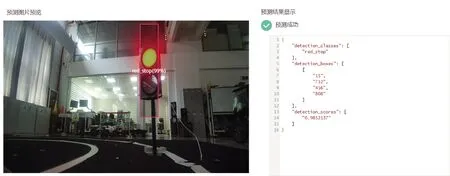
图11 使用模型预测红灯
4 模型的使用和改进
模型训练好之后,进行实际环境的运行来观察模型是否真正适用,即对模型进行实际场景下的测试。无人车在模拟路况下使用训练好的模型运行,而在实际运行过程中发现摄像头会对现场的场景进行二值化处理。由于红绿灯主要通过颜色进行区分,二值化处理之后模型效果会大幅下降。此时之前模型中对红绿灯的训练效果大打折扣,对此的改进为将标注的红绿灯转化为标注红绿灯所在的位置,如图12所示划分。因为红绿灯分为三块,每一块的位置都是固定的,这种情况下在二值化处理之后仍会有很好的识别和检测效果。在运行过程中记录运行数据,能起到类似测试的效果,会对模型的改进方向起到了指引的作用。

图12 红绿灯按区域进行划分
5 结论
同一个数据集在数据量较少的情况下,可以使用图像增强的方式对数据集进行扩充,使得训练的效果会更好。同时,在增大了数据集的情况下,需要适度地调整训练集和验证集之间的比例,以达到更好的训练效果以及更精确的模型。在同一个数据集下,不同的算法所得的精度也不同。不同的算法加上预训练模型适配的场景会有所差异,通过实验可以对比出差异,从而更好地训练出目标模型。同时,理论与现实存在着一些差异。由于模型的适用场景可能会不同,造成模型没有训练时显示的效果好。也会出现有些模型准确度较高,但是在实际运行环境中效果可能不如准确度稍低的模型,经过实际实验效果才能真正检验一个模型所适应的环境和它的优劣。
注:本文为华为云人工智能大赛无人车挑战杯比赛各阶段相关技术测试及验证介绍,使用的无人小车为赛事提供的比赛车辆,基于华为云的AI开发平台——ModelArts进行数据标注及模型训练。
