分级智能工业互联网业务执行可靠性与时延性能分析
2021-11-24马俊超黄永明
马俊超,黄永明
(网络通信与安全紫金山实验室,江苏 南京 211111)
0 引言
工业互联网(Industrial Internet of Things,IIoT)是工业3.0向工业4.0演进的重要标志。工业4.0的一个趋势是将原有的有线设施更换为无线设备[1-2],这样可以提高网络的可扩展性、灵活性和移动性,也方便未来网络的升级,节约成本。但是设备的移动进一步加剧了传输环境的复杂性,无线设备替代有线设施也会带来负面的影响。比如,现阶段无线环境无法提供有线传输那样可靠且高速的传输。因此,如何为工业互联网提供高可靠低时延的传输环境是5G和6G网络的一个研究热点[3]。
工业4.0的另一个趋势是业务复杂度的大幅提升,同时业务执行趋向自动化。比如,在芯片生产中需要检查制造的芯片产品是否合格、是否存在瑕疵。在传统工业环境中,这个任务通常由人工执行,即检查员通过检查芯片的外表确定该产品是否合格。受益于人工智能的长足发展,基于自动化的工业互联网中,该任务则由系统计算节点自动化完成。具体来说,该计算节点存储、计算和训练人工智能模型(深度神经网络、卷积神经网络等)及相应参数[4-5]。当产品到达时,附近的相机通过拍照得到一组该产品的图像,这些图像作为人工智能模型的输入,经过一系列的计算和推演,可以得到芯片产品的特征并以此判定该产品是否合格[6]。
自动化的任务执行优势为:① 自动化任务执行节省了人力成本;② 随着计算和存储资源成本的降低,各网络节点均可承担一定计算任务,并且自动识别的计算时延可能低于人工识别。然而自动化也有其自身的挑战。首先,自动识别结果的可靠性依赖于人工智能模型性能和数据的完整性。如果人工智能模型的参数不精确或者输入的数据不完整、不充分,则推演的结果很可能出现错误或不精确的现象。一般而言,人工智能模型越复杂、参数越完整则需要的存储空间和计算容量越大;其次,任务执行的节点可能离相机很远,数据的传输会引发过长的时延,甚至传输中断,影响任务执行在可靠性和时延方面的性能[7]。
因此,人工智能计算节点的部署和计算及存储容量的配置对工业互联网任务执行的影响很大。未来的工业互联网普遍采用分级智能的网络架构,即将网络按照离用户的距离以及集中程度分配不同的智能[8-9]。具体来说,离用户较近的本地端节点只服务于小范围内的用户,遵循一种分布式的网络架构,可以处理近实时的业务,一般都配备有限的存储和计算资源;相反,离用户较远的云端节点组成了一种集中式的网络架构,一般处理非近实时的业务,并且配备相对丰富的存储和计算资源。
在基于分级智能的工业互联网环境下,执行任务节点的选择及对应的资源分配对任务执行性能有很大影响。比如,任务在离用户较近的近实时本地节点进行计算时,其时延主要来自于计算过程。此外,由于本地节点只能运行轻量级计算模型且没有太多数据进行训练计算,导致结果的精确度和可信度并不高[10]。相反,若任务内容数据被上传至离用户较远的非实时计算节点进行任务执行,时延主要来自于数据的传输过程及后续的计算过程[11-13],因为远端节点普遍有充足的计算资源及训练参数,因此计算结果的精确度和准确性普遍高于本地节点的计算可靠性。
从内容的角度出发,数据内容特点也会对任务的执行带来影响。比如,某些任务数据量较少,但是计算非常复杂;而有些任务数据量庞大,但是计算操作相对简单。工业视觉业务员的任务数据通常是以视频或图片等数据形式呈现,而经过编码技术(如可伸缩编码方案)部分数据即可表征视频/图片内容[14-15]。在这种情况下,网络可以传输和计算部分数据内容并返回计算结果,以降低任务执行时延,但相应计算结果的可靠性也随之下降。由此可以看出,在基于分级智能的网络中任务执行的时延性能和可靠性能之间此消彼长,存在一定矛盾。类似的,同样的内容在本地端计算往往有较好的时延性能,但是可靠性较差;反之,若在远端执行,则可靠性高而时延较大。执行任意一个任务的时延和可靠性性能主要取决于该任务计算节点的确定以及对应的计算资源和传输资源的分配、内容数据量的卸载。
在已有工业互联网业务执行相关文献中,大多数的工作都集中在传输侧,即提供高可靠低时延传输[7,16],却忽略了任务计算过程和任务数据对任务执行的影响;有些工作则专注于人工智能模型的训练和推演性能,以减少计算复杂度、提升计算可靠性[4,6]。这些工作普遍没有综合考虑任务计算和任务传输过程,并且忽略了任务内容的影响。文献[17]以内容为中心,分析了工业视觉中业务执行的挑战和可能的应对之策。文献[18]提出了一种轻量级的卷积神经网络模型计算,寻找工业视觉中重要视频帧以减少传输带宽占用,并降低传输对接下来的计算过程的影响。总之,考虑任务内容特点、任务传输及任务计算等过程对工业互联网业务,尤其是工业视觉业务影响的已有文献非常少。相关研究仍处在初步阶段,需要大量工作进行深入研究以最大化任务执行的性能。
1 系统模型
1.1 系统架构
本节介绍一种典型的基于分级智能的工业互联网场景。如图1所示,整个网络架构可以分为两层:本地边缘层和远程云计算层。其中本地边缘节点部署在用户附近,甚至可以和用户通过有线连接集成在一起,因此可以提供高速传输从而降低传输时延。由于部署的计算资源和存储资源非常有限,本地节点无法运行大规模人工智能模型,导致推演计算的结果可靠性较低且需要更长的计算时延。相对而言,远程云节点拥有丰富的计算和存储资源,可以运行大规模人工智能模型,并且推演结果的可靠性更高,所需的计算时延更短。然而,由于远程云节点普遍都部署在离用户较远的位置,内容的传输时延不可小觑。
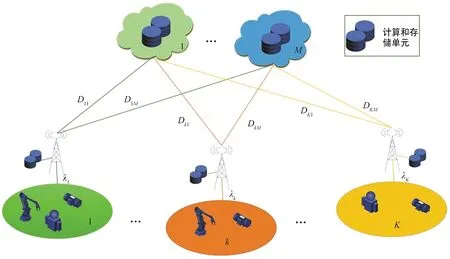
图1 分级智能网络系统架构Fig.1 Hierarchical intelligent system architecture
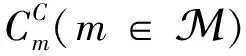
在用户侧,为了方便阐述,假设每一个用户附着在一个本地节点并且通过有线进行连接。在IIoT环境下,用户指的是IIoT设备,比如智能制造检验中的工业相机,其主要作用是拍摄生产线上的产品图像,并将其上传至计算节点(本地节点或远端节点)以检验产品是否合格或有瑕疵。假设第k(k∈K)条生产线上的检验任务到达服从速率为λk的任意分布,生成的任务可以由(s,v,)表征[13]。其中,s表示任务内容的数据量,v表示该任务单位数据量计算需要的算力,而Tmax表示任务可忍受时延的上限,一旦任务在经历Tmax之后仍没有返回结果则视为计算失败。假设任务数据量s和单位数据量需要的算力v分别服从[smin,smax]和[vmin,vmax]的Tmax均匀分布。每一个生成的任务被存储在等待队列等待后续任务执行。假设每个用户k最多能存储Qk个任务,一旦用户的等待队列超过了存储上限,后续到达的任务会自动被丢弃并认定计算失败。
对于获取的任务数据(图像或者视频内容),系统采用可分级编码的方式将其处理为多层数据层。根据之前的介绍,计算节点获取的数据层越多,则输入的信息越精确,画面越清晰。相应的,输出结果的可靠性也就越高,对应的计算时延及后续传输时延也会延长。
1.2 任务执行性能建模
在每一个时隙开始,网络根据各计算节点的情况和各用户队列状态采用合适的调度策略,将任务卸载至合适的计算节点进行后续处理。具体而言,该调度策略应当包括如下决定:① 队列中哪个内容应该被卸载;② 应当卸载至哪一个计算节点;③ 应当卸载多少数据;根据调度策略和用户与计算节点之间的信道情况及计算节点的计算能力,卸载的计算任务会有不同的时延和可靠性性能。具体来说,对于被卸载的任务i,其时延性能可表征为:
(1)
其中,Lwait(i)表征了该任务在用户队列中等待的时延,s(i)表征了任务i生成多层数据的总体数据量,而o(i)∈(0,1]为卸载的数据率。v(i)定义了任务i单位数据量需要的算力(单位为Mbit/转)。D(i)表示用户至计算节点的信道可提供的数据速率,而C(i)/N(i)表示计算节点提供的算力。这里需要指出的是,式(1)的D、C和N等都忽略了上下标,表明这些参数适用于所有边缘节点和远程节点,而其具体的取值主要取决于该任务被卸载至哪一个节点。同样,可靠性的性能可以表征为:
R(i)=r(i)o(i),
(2)
式中,r(i)表示任务i被卸载的计算节点输出结果的最大有效性。式(2)采用了线性模型来建模可靠性,但这并非是唯一的建模方式,其他的模型只需满足如下条件皆适用于该模型,所提出的分析方法,可以很好地扩展到其他建模中。这些条件包括:① 总体的可靠性取值不能超过该节点的上限r;② 任务计算结果的可靠性应该和输入的数据量成正比,也就是说输入的数据越多(数据层越多)则输出结果的可靠性更高。由式(1)和式(2)可以看出可靠性和时延之间的矛盾。比如说,被卸载的数据量越大,即o(i)的值越大,则该任务执行结果的可靠性越高,而其需要的传输时延及计算时延会相应增加。为了建模二者的矛盾,式(3)给出了一种效用函数(Utility Function)来表征二者的折中,即:
头颅CT示鞍区肿瘤呈均匀高密度影,边界清楚,其中64例呈圆形或类圆形,16例不规则。增强MRI示T1WI等或略低信号,T2WI高信号,均具有“脑膜尾征”[3],26例伴脑干水肿。所有患者视交叉、视神经管均存在不同程度的压迫或侵入,肿瘤向鞍旁发展,包绕颈内动脉,其中20例完全包裹,60例部分包裹。肿瘤直径≤3 cm 18例,3~5 cm 34例,>5 cm 28例。
(3)
式中,βr和βl∈[0,1]分别表示网络对可靠性和时延的重视度参数。Tmax保证时延性能的取值和可靠性均在0~1之间。加1操作的目的是保证任务i被执行的效用函数值优于其被丢弃的效用函数。
由时延和可靠性的建模过程(如式(1)和式(2))可以看到调度策略对效用函数的影响。具体而言,任务i的确定由调度方案中的问题①决定,即应该调度哪一个任务;D(i)、C(i)和N(i)则回答了问题②,即任务应该卸载至哪一个计算节点;最后,o(i)的确定体现了调度策略的问题③,即应该卸载多少数据至计算节点以达到效用函数的最大值。需要指出的是,为了方便阐述,假设各节点的计算资源平均分配给计算任务,在选取卸载节点时计算资源分配也在考量范围内;同理,传输信道对任务卸载的影响也在该调度策略中得到体现。
最后,本文的目的是最大化如式(4)所示的时间T(T→∞)内所有任务计算的效用函数值的平均值:
(4)
式中,X(t)表示在时隙t内生成任务的总量,Π={π1,π2,…,πT′}为一系列调度策略,T′为系统在T时隙内调度次数。
2 问题求解
在前一部分,本文提出了一种效用函数建模分析任务执行的可靠性及时延性能的折中,并期待找到一种最优的调度策略Π*以最大化效用函数取值。系统在每个时隙都需追踪和更新网络状态,并据此确定是否需要进行新的调度任务。因此,只有在计算节点空闲及用户队列非空的情况下,新的调度策略才有意义,而不是在每个时隙都需要一个调度策略。在提出最优调度算法之前,首先对网络状态和调度策略进行详细建模并确定调度间隙。
2.1网络状态及调度策略阐述
2.1.1 网络状态
在任意时刻t,系统的网络状态可以表示为St={Q,ndiscard,comp_e,comp_c}。其中Q={Q1,Q2,…,QK}表示各节点的队列,而Qk⊂Q×3是第k个用户的队列,由Q×3的矩阵表示且初始值为全零。对于每一个到达的任务,可以由[twait,s,v]表征并插入到队列首个非零行,进入排队队列等待卸载调度及后续计算。如果队列已满则该任务被直接丢弃。ndiscard∈表示系统丢弃的任务数。comp_e={comp_e1,comp_e2,…,comp_eK}记录了K个边缘节点的计算状态。当某一个任务被卸载到本地节点k的第i个计算空间时,该任务的情况可以有[comp_label,delay,reliability]T表征,其中comp_label为该计算任务的计算状态,可以取值+1、-1和0,分别表示该计算空间有任务正在计算、计算空间有任务已经完成计算并等待返回以及计算空间当前空闲可以接受新的任务;delay表示当前计算任务已经经历的时延;而reliability表示该任务结果的可靠性。在每个时隙结束前,网络节点将comp_label=-1对应的任务反馈给用户并将该网络空间重置为[0,0,0]T。在每个时隙开始时,只有comp_label=0对应的网络空间处于空闲状态,可以接受新的任务。comp_c={comp_c1,comp_c2,…,comp_cM}表征了远程云端的计算状态,和comp_e非常类似,在此不做赘述。
2.1.2 调度策略
每次调度过程中,采用的调度策略可以表示为πn={πn,1,πn,2,…,πn,K},而πn,k={task_IDk,comp_IDk,ratiok}是第k个用户的排队队列中的任务。需要注意的是,若用户k的排队队列空白,则该用户无任务可以调度,故取值为task_IDk=0,对应的后续comp_IDk和ratiok等参数都没有意义。comp_IDk是指调度任务应该卸载的网络空间,若和用户k相连的所有的网络空间繁忙(即所有的可能comp_IDk=1),则无任务可调度(即task_IDk=0)。最后,ratiok表征根据网络状态和信道情况应该卸载多少数据至comp_IDk。
2.2 基于贪婪的调度策略方案
根据之前的表述,系统只有当用户侧的排队队列非空且存在空闲网络节点时进行一次调度策略,故调度间隔是不固定的,并且网络状态和调度策略空间非常庞大。基于此,要找到一种最优化的调度方案是非常困难且具有挑战性的。为了降低算法复杂度,提出了一种基于贪婪的调度方案,即每次调度仅考虑当前网络状态而忽略对后续调度的影响,如算法1所示。
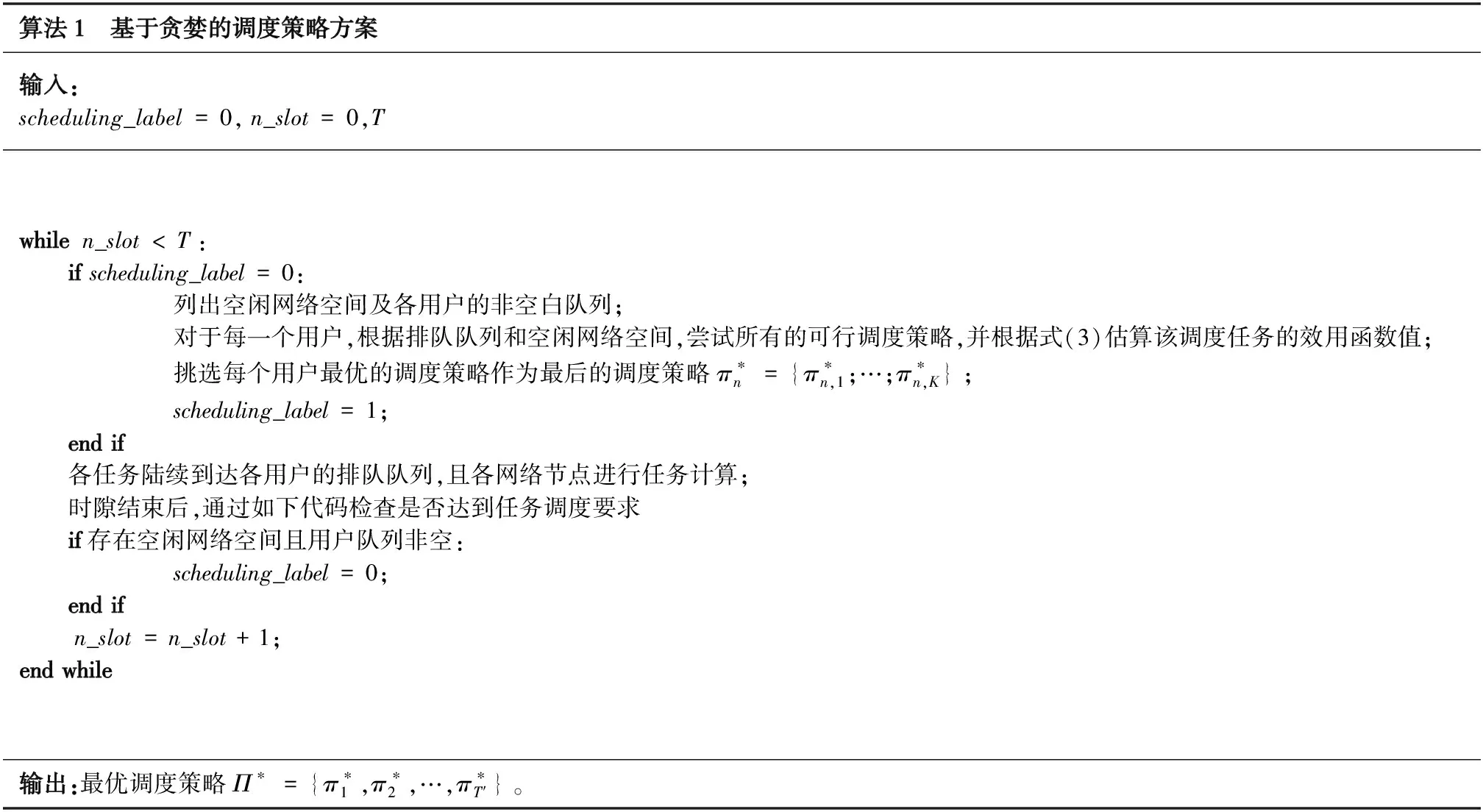
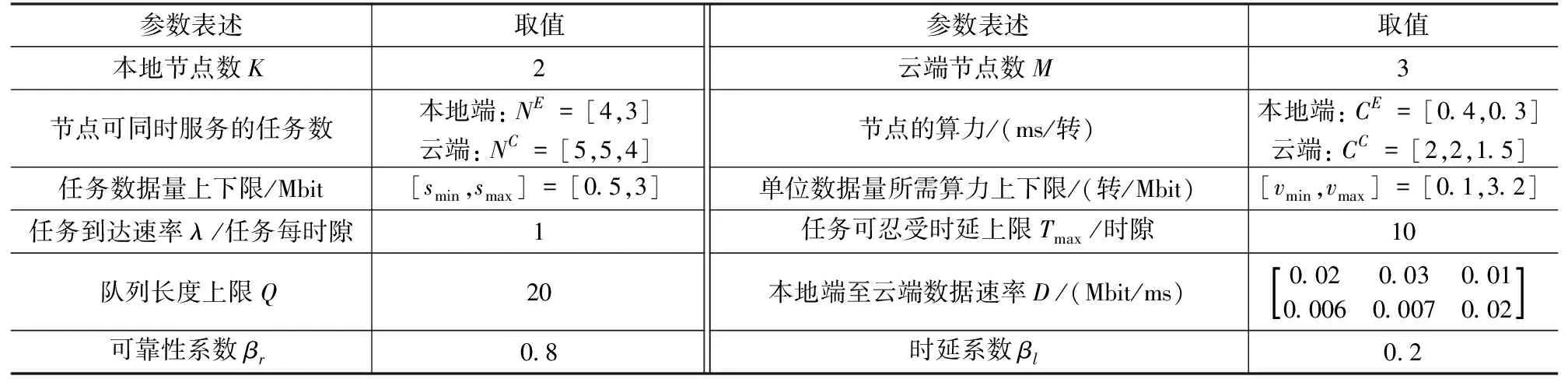
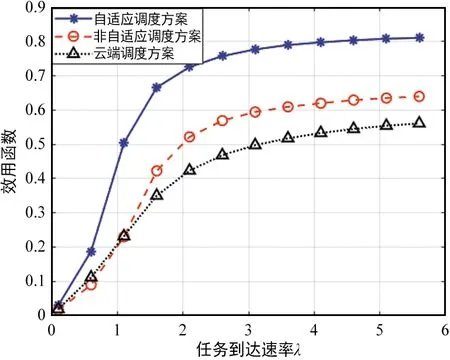
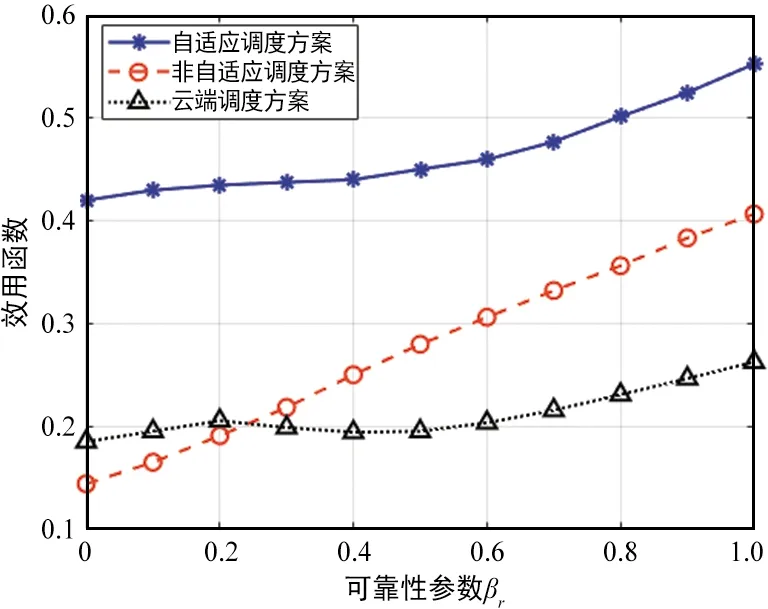
算法1 基于贪婪的调度策略方案输入:scheduling_label=0,n_slot=0,Twhilen_slot 在该调度策略下,可以统计所有计算任务的效用函数值,根据式(4)即可得到单位任务的效用函数的平均值以及对应的最佳调度策略。 上文分析和建模了自适应调度方案下用户任务执行的性能,接下来将通过一系列的仿真试验验证分析结果,并研究不同参数对效用函数的影响。仿真中的各参数如表1所示。 表1 性能仿真中参数设定 为了对比不同调度方案的性能,在仿真中加入了如下两种对比任务调度方案。 ① 非自适应任务调度方案 (Non-scalable Task Offloading Scheme):和提出的自适应任务调度方案(Scalable Task Offloading Scheme)相比,非自适应调度方案忽略了任务内容的可伸缩性,每次任务调度时都将所有数据卸载至计算节点。 ② 云端任务调度方案(Cloud Task Offloading Scheme):和提出的自适应任务调度方案相比,云端任务调度方案唯一的不同是需要将所有计算任务自适应地卸载至云端进行计算。 接下来给出不同参数对任务执行的影响以及不同调度方案的性能对比。 图2显示了3种任务调度方案随着服务到达速率λ的性能变化。之前提到各用户的任务到达服从速率为λ的任意分布(仿真中假设服从泊松分布),因此λ的值越大,两相邻任务到达间隔就越大,也就是说任务因排队队列无空闲位置而被淘汰的概率逐渐减少,即被成功计算的概率增加。鉴于此,图2的一个很明显的结论就是所有方案的效用函数都是关于λ的递增函数。 图2 不同任务调度方案效用函数与任务到达速率λ关系Fig.2 Utility performance of different scheduling schemes with task incoming rate λ 从该图可以看到,当λ值非常小的时候,所有方案的效用函数值都趋于0,这是因为此时几乎所有的任务都被丢弃掉。随着λ的增加,3种方案的性能出现了差异。考虑了分级智能和视觉数据的可伸缩性等特点,提出的自适应调度方案性能优于其他两者。而云计算任务调度算法和非自适应任务调度方案在λ较小时表现的依然非常接近,但是当λ较大时,前者的性能更差,而自适应调度算法依然表现最佳。随着λ的提高,各方案的性能趋于平稳。这是因为当λ很大时,任务到达比较慢,几乎所有的请求都被服务而不存在资源不足的困扰。因此λ的增加不会继续引起任务执行性能发生太大变化。从图2可以看到自适应调度算法带来的增益,尤其是当任务到达较慢,网络负载不高时,增益更明显。 可靠性系数βr对各对比方案的性能影响如图3所示。βr表征了网络对可靠性的重视程度,即βr值越大,则系统更在乎任务执行的可靠性;而反之若βr值越小则说明对时延性能要求更高。从图3可以得到如下结论:首先,可以看到所有方案的性能随着βr的提高而增加。从式(3)的效用函数的表征中可以看到,βr的提高可以直观地提高效用函数的取值。但是可靠性性能的提高不可避免地引起时延性能的恶化。因此,整体的效用函数不是关于βr的线性函数。另外,随着网络更注意可靠性的性能,每次调度更倾向卸载全部数据以提高可靠性,因此自适应调度方案和非自适应调度方案的差距随着βr的提高而缩小。非自适应调度方案和云计算任务调度方案相比,当βr值较小时,前者性能不如后者;而随着βr的增大,其性能逐步优于后者。这说明当βr值较小时,考虑内容数据特点带来的增益高于计算节点的选择,而随着βr的增加,选取最佳计算节点可以带来更高增益。最后,对比3种方案的性能可以发现,自适应调度方案的性能明显优于其他两种,特别是当βr值较小,网络更在意时延性能时该增益达到最高。 图3 不同任务调度方案效用函数与可靠性参数 βr的关系Fig.3 Utility performance of different scheduling schemes with reliability coefficient βr 本文在基于分级智能的工业互联网环境下研究了工业视觉业务执行的时延性和可靠性的折中。首先提出一种基于自适应的任务调度方案,分析对时延和可靠性的影响。提出一种效用函数建模时延和可靠性的折中并作为用户任务执行的性能指标,通过贪婪算法得到一种局部最优的任务调度方案以最大化效用函数取值。通过一系列的仿真,分析了不同参数对用户任务执行的影响并对比了不同算法的性能。仿真结果表明,相比于其他调度方案,自适应调度方案能得到更高的效用函数值,即用户任务执行的可靠性和时延得到更好的折中。3 性能分析
3.1 任务到达速率λ的影响
3.2 可靠性系数βr的影响
4 结论
